



2. 国土资源部城市土地资源监测与仿真重点实验室, 深圳 518000
2. Key Laboratory of Urban Land Resources Monitoring and Simulation, Ministry of Land and Resources, Shenzhen 518000, China
近20年来,随着多视立体(multi-view stereo,MVS)基准评价集[1-3]的提出,利用高分辨率多视图影像进行三维重建的研究取得了重大进展[4]。相比于借助激光雷达等主动测距的方法,基于影像的被动式的多视立体方法具有重建成本低、速度快、非接触和无伤害等优势,适用于高精度大规模户外场景重建[5-6]。车载移动测量技术[7]与无人机航拍技术[8]的发展使得更多科研人员将其应用于地面与航拍影像的三维重建,促进了智慧城市等的建设。对此,文献[9]提出了一套由带有相机标定参数的影像进行多视立体重建的完整流程,主要包括密集匹配、网格重建与网格优化3个步骤。其中,网格重建是指利用密集匹配得到的稠密点云进行构网操作。常用的方法有:Poisson表面重建[10-11]等隐式拟合法,即通过Poisson方程建立指示函数与表面法向间的关联,进而提取零交叉等值面;Delaunay四面体图割的方法[12],即先对点云进行Delaunay四面体空间剖分,再基于可视性信息进行最小s-t图割,从而提取三角网格。Poisson表面重建等方法没有考虑点在影像上的可视性信息,且重建结果的平滑程度较高,不能很好地重建出复杂表面;Delaunay四面体图割的方法则加入了点的可视性,对噪声、异常值以及点云密度的变化更稳健,故文献[9]在其提出的多视立体重建流程中选用此方法进行网格重建。
网格重建得到的三角网格通常存在噪声且缺少细节,因此需要进行网格优化以提升网格质量。对此,国内外已有一些相关研究进展。早期,文献[13]用偏微分方程定义水平集,在变分框架下利用影像一致性进行网格优化。文献[14]将影像一致性的积分范围从三维网格转到二维影像,得到了更准确的优化结果。文献[15]进一步用梯度代替偏微分方程,提高了优化的稳健性。然而以上基于水平集的优化方法通常较为复杂、难以理解,故文献[16-17]利用基于网格的多视立体变分方法,通过相机与网格间的观测关系以及相应的影像数据,对网格的顶点位置进行调整。同样地,文献[9]通过定义表面能量函数对连续水平集进行离散化,将优化直接作用于网格顶点,在网格的准确性与完整性上均取得了较佳的效果。
诸多学者进一步对该网格优化方法进行了各方面的改进:文献[18]在表面能量函数中添加轮廓匹配项以强化边缘,并将影像一致性作为正则项的权重以实现自适应平滑;文献[19]利用光束法平差同时优化相机标定参数与表面网格;文献[20]使用各向异性的影像一致性测度与表面降噪方法,更好地保持尖锐特征;文献[21]对网格区域进行活动或非活动的二元标记,仅对标记为活动的网格区域进行优化,提高了优化效率;文献[22]结合影像一致性与语义一致性,同时进行网格几何优化和语义分割优化;文献[23]在优化前进行移动物体检测,避免相应影像区域影响场景中静态模型的优化;文献[24]利用深度图获取遮挡感知掩膜,得到有效像素,处理由深度的不连续性造成的遮挡问题。
尽管上述方法从能量函数构成、网格分割、遮挡检测等各方面对网格优化的方法进行了完善,但仍然在一定程度上忽视了影像信息的冗余以及视图的质量对网格优化的影响。对此,本文提出在计算影像一致性的过程中,为网格每个顶点的邻接三角面进行视图的选取,从而使更优质的视图更多地参与网格优化。虽然密集匹配已提出在像素级别上进行视图选取以得到准确点云[25-26],但是网格优化方面的文献总是局限于选取公共的、有合理视差的三维点数目最多的视图对。如文献[9]直接采用稀疏点云估计中的视图对;文献[6, 19, 23]则利用摄影基线、主视方向间的夹角、影像重叠度等对视图对在全局范围内进行选取;文献[27]利用图简化方法对大规模、不规则采样的影像集进行压缩,得到影像子集。而本文提出的为每个三角面选取视图的变分优化方法,是从网格中每个面的角度出发,进行局部视图选取。
1 基础方法文献[9]提出的网格优化方法在多个标准数据集上得到的结果均具有较优的准确性与完整性,故本文将其作为基础方法。该方法借助带有相机标定参数的影像数据对网格进行优化:利用相机与表面间的观测关系构建表面能量函数,表示表面在多张影像上的投影的匹配程度,并将网格重建得到的三角网格作为函数自变量的初值,通过应用梯度下降法使能量最小化,从而实现网格优化,达到减少噪声、增强细节的目的。
表面能量函数包括影像一致性项与正则项
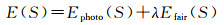 (1)
(1)
式中,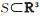
影像一致性用于度量同一位置的表面在可视的不同影像上的投影间的相似性,为此,定义x∈S为表面上一点,N为表面在该点处朝外的法向量,gi, j(x, N)描述(x, N)在视图i与视图j间的影像一致性(其中视图包括影像及对应的相机标定参数信息),vi, jS(x)∈0, 1描述x在i和j上的可视性[13]。则描述影像一致性的原始能量函数为
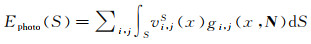 (2)
(2)
式(2)在三维空间上积分困难,为了更方便、有效地计算影像一致性,引入重投影误差,将积分空间转换到二维影像上[29]。如图 1所示,xi为视图i对应的影像上的一个像素点,反投影到表面S上得到点x,再由点x投影到视图j对应的影像上得到像素点xj,xj与xi的匹配程度即反映重投影误差。本文称i为主视图,j为主视图的从视图。由此,式(2)可改写为

|
| 图 1 重投影误差示意图 Fig. 1 Illustration of reprojection error |
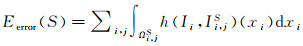 (3)
(3)
式中,Ii为视图i对应的影像;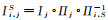
为了对能量函数进行离散化,将表面S表示为三角网格,有n个顶点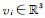
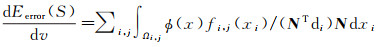 (4)
(4)
式中,fi, j(xi)=∂2M(xi)DIj(xj)DΠj(x)di;di为由i对应的相机中心指向x的向量;∂2M为M关于第2张影像(即从视图对应的影像)的导数,D表示对应函数的雅可比矩阵。
综上可知,基础方法对每一个视图对(i, j),由主视图i对应的影像Ii逐像素xi反投影到表面点x,借助重投影误差计算(i, j)关于xi的影像一致性的梯度,并将该梯度按重心坐标分配到x所在三角面的3个顶点上。换言之,获取的每个顶点的最终梯度,即为可视的所有视图对关于该顶点对应的投影点的影像一致性的梯度和。再应用梯度下降法,按梯度反向迭代移动网格顶点,使顶点移动到更准确的位置,同时能量迭代下降至最小化,最终得到影像一致性最优的优化网格。
2 本文方法根据上述基础方法,在影像一致性的计算过程中,将需要经由网格进行重投影操作的视图定义为主视图,并将主视图重投影的对象视图定义为从视图,主视图与对应的从视图构成视图对。由式(4)可知,在基础方法的优化过程中,顶点的所有可视视图对均同等地参与其影像一致性的计算。考虑到视图的质量对影像一致性计算的影响,本文方法提出视图选取的策略,即从三角面的角度出发,新增主视图选取与从视图选取两个步骤。
如图 2所示,本文方法的主要输入为初始网格与带有相机标定参数的校准影像,首先在所有视图中为网格的每个三角面f选取最佳视图作为主视图i,即主视图选取(图中不同颜色代表选取的不同主视图);然后根据观测条件为主视图i的所有从视图j设置相应权重,以此排序进而选取从视图,同时为被选取的i与j构成的视图对(i, j)关于三角面f的3个顶点的影像一致性计算进行归一化加权,即从视图选取;最后,按照基础方法求取能量函数在网格顶点上的梯度,并利用梯度下降法进行迭代求解,由初始网格得到优化网格。

|
| 图 2 本文方法概览 Fig. 2 Overview of the proposed method |
据此,在本文方法中,基础方法中的式(4)可改写为
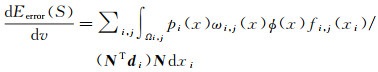 (5)
(5)
式中,pi(x)∈{0, 1}表示主视图i是否为点x所在的三角面f的最佳视图,若是,则值为1,否则值为0;ωi, j(x)表示视图对(i, j)关于点x所在的三角面f的3个顶点的影像一致性的归一化权重。接下来分别详细介绍主视图选取与从视图选取。
2.1 主视图选取构建关于三角面的最佳视图的马尔科夫随机场,为网格的每个三角面fi分配标签li,以此为每个三角面选取最佳视图,并将其作为用于计算影像一致性的视图对的主视图。为此,定义能量函数
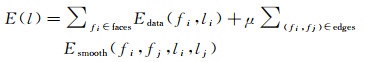 (6)
(6)
式中,l为所有面的最佳视图标签集;fi和fj为有公共三角边的邻接面;μ为比例参数,用于平衡数据项Edata与拓扑平滑约束项Esmooth。数据项用于度量利用影像一致性进行优化时,三角面在其可视视图上的质量;拓扑平滑约束项用于使邻接面的最佳视图标签尽可能保持一致。
创建无向图,将三角面作为图的节点,邻接三角面的公共边作为图的边,利用基于图割的α扩张算法[31]最小化能量函数(6),得到最优标签集,从而得到每个三角面的最佳视图,实现主视图选取。
基于波特模型,拓扑平滑约束项定义为
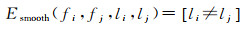 (7)
(7)
式中,[·]为艾弗森括号,若li≠lj,则值为1,否则为0。
综合影像梯度幅值与轮廓检测,将轮廓因子C作为惩罚项与梯度幅值M相乘,由此可定义三角面f在其可视视图i上的质量
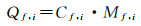 (8)
(8)
由面f在其所有可视视图中的最大质量max(Qf)与最小质量min(Qf)得到归一化质量
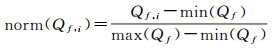 (9)
(9)
则数据项定义为
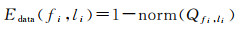 (10)
(10)
接下来,分别对数据项中的影像梯度幅值与轮廓检测进行具体说明。
2.1.1 影像梯度幅值为了反映三角面在其可视视图上的质量,考虑影像分辨率以及相机与被观测表面间的邻近性,尽量为三角面选取影像分辨率较高的、相机距被观测表面较近的视图,为此计算三角面在影像上的投影所占的像素的梯度幅值之和[32]。利用索贝尔算子近似获取影像梯度:索贝尔算子包含横向Sx与纵向Sy,如图 3所示,将之与视图i对应的影像进行平面卷积,分别得到影像在横向与纵向上的梯度,即▽(i)x=Sx*i与▽(i)y=Sy*i。故像素点p的梯度幅值为

|
| 图 3 索贝尔算子 Fig. 3 Sobel operator |
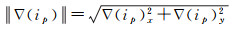 (11)
(11)
则三角面f在其可视视图i上的影像梯度幅值之和表示为
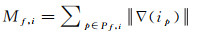 (12)
(12)
式中,Pf, i为f在i的影像上的投影所占的像素集合。若三角面的投影区域不足一个像素,则按其投影重心对梯度幅值进行采样,再乘以其投影面积。
2.1.2 轮廓检测注意到当表面转折处在影像上的投影表现为轮廓时,该投影区域的梯度将对应为影像梯度的局部最大值[33],对于此种情形,仅依赖上述影像梯度幅值来为三角面选取主视图是不完全可靠的。如图 4所示,三角面f位于表面转折处,视图i1和视图i2均为f的可视视图。由于f在i2影像上的投影表现为位于轮廓附近,故该处影像梯度较大,此时若仅根据影像梯度幅值判断f在i1和i2上的质量,可能会得到i2优于i1的错误结论。因此,本文提出,为三角面在其可视视图上作轮廓检测。

|
| 图 4 轮廓检测 Fig. 4 Contour detection |
为进行轮廓检测,定义v1、v2和v3为S的3个顶点,vf=(v1+v2+v3)/3为f的中心,Nf为f朝外的法向量,Nv1、Nv2和Nv3分别为表面在v1、v2和v3处朝外的法向量,ci为视图i对应的相机中心,vview=vf-ci为由三角面的中心到相机中心的向量。则Nf与vview间的夹角α为
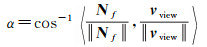 (13)
(13)
式中,〈, 〉表示向量内积。Nv1、Nv2和Nv3两两间的平均夹角β为
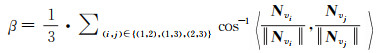 (14)
(14)
当α大于某一阈值αc且β大于某一阈值βc时,认为三角面f在视图i的影像上的投影表现为位于轮廓附近。由此定义轮廓因子Cf, i为
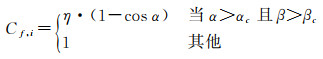 (15)
(15)
式中,η为比例参数。至此,综合轮廓因子与梯度幅值,即可得到式(8)。
2.2 从视图选取主视图选取后,为进一步提升优化效率及质量,在主视图的所有从视图中,考虑从视图联合主视图对三角面的观测条件,据此为两者构成的视图对关于该三角面的影像一致性设置权重,即式(5)中的ωi, j(x),并依据该权重进行从视图的选取。
为选取从视图,本文主要考虑主、从视图间的视差以及相机到三角面的距离差。如图 5所示,三角面f的主视图为i,与该主视图构成视图对的从视图为j,用主、从视图视线间的夹角表示主、从视图间的视差,即θi, j=∠(civf, cjvf)。相机到三角面用相应焦距fi、fj归一化后的距离分别为li=||civf||/fi、lj=||cjvf||/fj,用||civf||归一化后的距离差为Δli, j=|li-lj|/||civf||。则分别由视差、距离差定义权重wp、wl

|
| 图 5 从视图选取 Fig. 5 Illustration of the slave view selection |
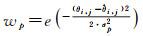 (16)
(16)
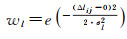 (17)
(17)
式中,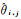
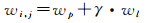 (18)
(18)
式中,γ为比例参数。因此,当三角面的主、从视图间的视差越接近参考视差、相机到三角面的距离越一致时,该视图对该三角面的影像一致性的贡献越大,使得优化过程更为合理、有效。
假设三角面f的主视图有n个从视图,对该n个从视图按其权重进行降序排列,若n大于参考最大从视图数N,则选取前N个从视图。对选取的从视图的权重归一化后得到式(5)中的ωi, j(x)
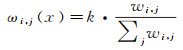 (19)
(19)
式中,k表示选取的从视图数,当n>N时,k=N,否则k=n。至此,将选取的主、从视图构成视图对,实现了对影像一致性计算的归一化加权。
3 试验及分析OpenMVS开源库实现了多视立体重建的完整流程[9],故本文利用OpenMVS,在CPU i7-6700,3.40 GHz;RAM 31.96 GB的环境下进行试验。试验数据采用Strecha提供的fountain-P11、Herz-Jesu-P25与castle-P30 3套数据集[2],分别含有11、25与30张影像,影像分辨率均为3072×2048。与文献[9]相同,本文初始网格的构建方法采用引言部分提到的Delaunay四面体图割的方法[12]。对于不同数据集,本文涉及的各参数统一设置如下:比例参数λ=0.2,μ=0.1,η=0.2,γ=1;角度阈值αc=75°,βc=15°;参考视差
为论证本文方法的各组成部分在提升网格优化质量方面的有效性,对fountain-P11的优化细节逐步进行对比分析:图 6和图 7(a)-(f)依次为fountain-P11的真实网格、初始网格、基础方法优化网格、只考虑影像梯度幅值选取主视图的优化网格、综合影像梯度幅值与轮廓检测选取主视图的优化网格、主视图选取加从视图选取的优化网格(即本文方法)。图 6和图 7(c)相比于图 7(b),利用影像一致性对初始网格进行优化,恢复了更多细节;(d)相比于(c),凹陷与凸出等纹理细节得到了增强;而(e)由于考虑了轮廓检测,更好地保持了边缘轮廓;(f)则通过对视图对的影像一致性计算进行归一化加权,进一步丰富了细节同时减少了噪声。值得注意的是图 6(d)由于仅考虑影像梯度幅值为部分三角面选取了不恰当的主视图,(e)则通过加入轮廓检测,有效地解决了该问题。

|
| 图 6 fountain-P11优化细节对比i Fig. 6 Comparison i of refinement details on fountain-P11 |

|
| 图 7 fountain-P11优化细节对比ii Fig. 7 Comparison ii of refinement details on fountain-P11 |
为进一步说明主视图选取在网格优化中所发挥的作用,选取Herz-Jesu-P25 3个不同部位的优化细节进行对比分析:图 8(a)为25张输入影像中的两张,(b)为主视图选取结果,(c)和(d)分别为基础方法与本文方法的优化网格。(b)中不同颜色代表为三角面选取的不同主视图,黑色代表对应的三角面无主视图,即位于地面等处的三角面在其所有可视视图上的质量均未达到最佳视图选取条件,从而忽略对这些三角面的影像一致性优化,在一定程度上实现了自适应分辨率优化,提高了优化效率。分析(c)和(d)中3个部位的优化细节图:位于模型正面及中部的三角面在多个视图上均呈现为较优观测,故基础方法与本文方法得到的优化结果在细节上的差异不是特别突出,如门廊上的人形雕塑;而靠近模型边界或位于模型侧面的三角面仅在少数几个甚至一个视图上呈现为较优观测,在其他可视视图上则质量较差,此时本文方法相比于基础方法在细节恢复上效果有显著提升,如门廊立柱及右上角的精细纹饰。说明通过综合影像梯度幅值与轮廓检测为每个三角面选取主视图,减少了冗余视图的影像一致性的计算,不仅提高了优化效率,还在一定程度上避免了质量较差的视图对优化造成干扰。

|
| 图 8 Herz-Jesu-P25试验结果概览及优化细节对比 Fig. 8 Overview of experiment results and comparison of refinement details on Herz-Jesu-P25 |
3.1.2 与其他方法对比
利用castle-P30将基础方法、本文方法与其他主流方法进行结果对比:表 1为不同方法得到的网格顶点数与三角面数;图 9(a)为30张输入影像中的一张,图 9(b)和(c)分别为基础方法与本文方法的优化网格,图 9(d)-(g)依次为Poisson、MVE、Photoscan和ContextCapture(原Smart3D)方法得到的结果(各参数均按超高精度进行设置)。对比图中的窗户及墙壁上的纹饰等处,本文方法相比于其他方法细节更清晰、丰富。可见本文方法能更有效地利用影像信息,恢复更多精细细节。
| 方法 | 基础方法 | 本文方法 | Poisson | MVE | Photoscan | ContextCapture |
| 顶点数 | 1 953 689 | 1 953 771 | 1 786 827 | 1 302 189 | 1 904 564 | 114 566 |
| 面数 | 3 905 517 | 3 905 670 | 3 573 050 | 2 520 668 | 3 791 432 | 228 350 |

|
| 图 9 castle-P30不同方法结果对比 Fig. 9 Comparison of results by different methods on castle-P30 |
3.2 定量分析 3.2.1 优化时间对比
表 2为fountain-P11、Herz-Jesu-P25与castle-P30在相同环境下分别使用基础方法与本文方法进行优化的执行时间,本文方法相比基础方法优化时间缩短了约40%,且输入影像数目越多,时间缩短比例越高。可见通过对主视图与从视图的选取,本文方法减少了不必要甚至不可靠的视图对的数量,从而简化了影像一致性的计算,加快了能量函数梯度下降的收敛过程,故本文方法可提高优化效率。
| 方法 | fountain-P11 | Herz-Jesu-P25 | castle-P30 |
| 基础方法 | 21 min 53 s 20 ms | 1 h 19 min 8 s 175 ms | 1 h 8 min 354 ms |
| 本文方法 | 13 min 44 s 544 ms | 44 min 50 s 374 ms | 37 min 20 s 564 ms |
3.2.2 优化精度对比
为定量评价网格优化的精度,利用fountain-P11的激光雷达扫描数据作为真值(ground truth),比较从每个相机中心出发、经影像每个像素的视线分别到待测优化网格与真实网格的距离(即像素的待测深度值d与真实深度值dGT),具体表现为将深度值差值Δd=|d-dGT|与标准差σ(本文设为0.001 5)进行比较,且令maxσ=30σ。据此绘制误差分布直方图,如图 10所示,表示深度值差值在一定误差范围内的像素数占影像总像素数的比例,第i组即满足(i-1)·3σ≤Δd < i·3σ,i=11时则表示Δd≥maxσ。在误差图上表现为:当Δd < maxσ时,对应像素的灰度值为255-255·Δd/maxσ,即优化结果越准确,越接近白色;当Δd≥maxσ时,对应像素为红色;当dGT=0时,表示真值缺失,对应像素为绿色。图 11(a)-(d)第一行依次为初始网格、基础方法优化网格、本文方法优化网格及Poisson网格,第2行依次为第1行的网格所对应的误差图。

|
| 图 10 fountain-P11误差分布直方图 Fig. 10 Histogram of error distribution on fountain-P11 |

|
| 图 11 fountain-P11试验结果及误差图 Fig. 11 Experiment results and error maps on fountain-P11 |
为评价优化精度,重点分析图 10中i=1时,即深度值差值在3σ内的像素占比:使用基础方法优化后的网格相比初始网格,比例提升了约6%;而本文方法在基础方法之上,比例再度提升了约5%,且本文方法相比Poisson(八叉树深度设为10,其他参数默认),比例提升了约12%。对应于图 11中(c)与(a)、(b)和(d)相比,在墙面、雕饰等处更接近白色。可见通过对主视图与从视图的选取,本文方法降低了质量较差的视图对的影像一致性对网格优化的干扰,故本文方法可提高优化精度。另外,图 10中i=11时,即深度值差值大于或等于30σ的像素占比可用于表示优化完整性,该比例越小,则优化完整性越好,可见本文方法的完整性略低于基础方法。结合图 11进行分析,在地面部分,(c)的红色区域略多于(b),因为本文方法在较大程度上依赖视图的质量,对于地面部分,观测角度倾向为斜视,缺少优质的下视视图对这些三角面进行影像一致性优化,故本文方法在优化完整性上还有待提高。
4 结语本文在多视立体变分优化的基础方法之上,提出了影像一致性优化的视图选取策略。首先综合影像梯度幅值与轮廓检测,为网格中的每个三角面选取主视图。其次,根据从视图的观测条件为其设置权重,进而选取从视图。再对选取的主、从视图所构成的视图对的影像一致性计算进行归一化加权,得到能量函数在网格顶点上的梯度。最后,利用梯度下降法进行迭代求解,由初始网格得到优化网格。试验结果及其分析表明本文方法通过视图选取提高了优化效率、强化了网格细节。同时也存在一定的局限性,如优化结果较依赖视图质量、优化的完整性有待提高。下一步将继续研究如何在视图选取与优化完整性上更好地取得平衡,以及尝试结合几何基元提取[34]与影像一致性优化,进一步提升优化的视觉效果。
| [1] |
SEITZ S M, CURLESS B, DIEBEL J, et al. A comparison and evaluation of multi-view stereo reconstruction algorithms[C]//Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). New York, NY: IEEE, 2006: 519-528.
|
| [2] |
STRECHA C, VON HANSEN W, VAN GOOL L, et al. On benchmarking camera calibration and multi-view stereo for high resolution imagery[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK: IEEE, 2008: 1-8.
|
| [3] |
SCHÖPS T, SCHÖNBERGER J L, GALLIANI S, et al. A multi-view stereo benchmark with high-resolution images and multi-camera videos[C]//Proceedings 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI: IEEE, 2017: 2538-2547.
|
| [4] |
ZENG Gang, LHUILLIER M, QUAN Long. Recent methods for reconstructing surfaces from multiple images[C]//Proceedings of the 6th International Conference on Computer Algebra and Geometric Algebra with Applications. Xian, China: Springer-Verlag, 2004: 429-447.
|
| [5] |
TOLA E, STRECHA C, FUA P. Efficient large-scale multi-view stereo for ultra high-resolution image sets[J]. Machine Vision and Applications, 2012, 23(5): 903-920. DOI:10.1007/s00138-011-0346-8 |
| [6] |
EBNER T, SCHREER O, FELDMANN I. Fully automated highly accurate 3D reconstruction from multiple views[C]//Proceedings of 2017 IEEE International Conference on Image Processing (ICIP). Beijing, China: IEEE, 2017: 2528-2532.
|
| [7] |
徐振亮. 轴角描述的车载序列街景影像空中三角测量与三维重建方法研究[J]. 测绘学报, 2015, 44(10): 1178. XU Zhenliang. Research on aerial triangulation angle/axis representation and 3d recon-struction for vehicle-borne street-level image sequence[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(10): 1178. DOI:10.11947/j.AGCS.2015.20150113 |
| [8] |
肖雄武. 具备结构感知功能的倾斜摄影测量场景三维重建[J]. 测绘学报, 2019, 48(6): 802. XIAO Xiongwu. Oblique photogrammetry based scene 3D reconstruction with structure sensing functions[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(6): 802. DOI:10.11947/j.AGCS.2019.20180319 |
| [9] |
VU H H, LABATUT P, PONS J P, et al. High accuracy and visibility-consistent dense multiview stereo[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(5): 889-901. DOI:10.1109/TPAMI.2011.172 |
| [10] |
KAZHDAN M, BOLITHO M, HOPPE H. Poisson surface reconstruction[C]//Proceedings of the 4th Eurographics Symposium on Geometry Processing. Aire-la-Ville, Switzerland: SGP, 2006: 61-70.
|
| [11] |
KAZHDAN M, HOPPE H. Screened Poisson surface reconstruction[J]. ACM Transactions on Graphics, 2013, 32(3): 61-70. |
| [12] |
LABATUT P, PONS J P, KERIVEN R. Robust and efficient surface reconstruction from range data[J]. Computer Graphics Forum, 2009, 28(8): 2275-2290. DOI:10.1111/j.1467-8659.2009.01530.x |
| [13] |
FAUGERAS O, KERIVEN R. Variational principles, surface evolution, PDEs, level set methods, and the stereo problem[J]. IEEE Transactions on Image Processing, 1998, 7(3): 336-344. |
| [14] |
YEZZI A, SOATTO S. Stereoscopic segmentation[J]. International Journal of Computer Vision, 2003, 53(1): 31-43. |
| [15] |
SOLEM J E, OVERGAARD N C. A geometric formulation of gradient descent for variational problems with moving surfaces[C]//Proceedings of the 5th International Conference on Scale Space and PDE Methods in Computer Vision. Hofgeismar, Germany: Springer-Verlag, 2005: 419-430.
|
| [16] |
HIEP V H, KERIVEN R, LABATUT P, et al. Towards high-resolution large-scale multi-view stereo[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL: IEEE, 2009: 1430-1437.
|
| [17] |
张春森, 张萌萌, 郭丙轩. 影像信息驱动的三角网格模型优化方法[J]. 测绘学报, 2018, 47(7): 959-967. ZHANG Chunsen, ZHANG Mengmeng, GUO Bingxuan. Refinement of the 3D mesh model driven by the image information[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(7): 959-967. DOI:10.11947/j.AGCS.2018.20170733 |
| [18] |
TYLECEK R, SARA R. Refinement of surface mesh for accurate multi-view reconstruction[J]. International Journal of Virtual Reality, 2010, 9(1): 45-54. DOI:10.20870/IJVR.2010.9.1.2761 |
| [19] |
DELAUNOY A, POLLEFEYS M. Photometric bundle adjustment for dense multi-view 3D modeling[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH: IEEE, 2014: 1486-1493.
|
| [20] |
LI Zhaoxin, WANG Kuanquan, ZUO Wangmeng, et al. Detail-preserving and content-aware variational multi-view stereo reconstruction[J]. IEEE Transactions on Image Processing, 2016, 25(2): 864-877. |
| [21] |
LI Shiwei, SIU Singyu, FANG Tian, et al. Efficient multi-view surface refinement with adaptive resolution control[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer-Verlag, 2016: 349-364.
|
| [22] |
BLÁHA M, ROTHERMEL M, OSWALD M R, et al. Semantically Informed Multiview Surface Refinement[C]//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017: 3839-3847.
|
| [23] |
ROMANONI A, FIORENTI D, MATTEUCCI M. Mesh-based 3D textured urban mapping[C]//Proceedings of 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Vancouver, BC, Canada: IEEE, 2017: 3460-3466.
|
| [24] |
ROMANONI A, MATTEUCCI M. Mesh-based camera pairs selection and occlusion-aware masking for mesh refinement[J]. Pattern Recognition Letters, 2019, 125: 364-372. DOI:10.1016/j.patrec.2019.05.006 |
| [25] |
SCHÖNBERGER J L, ZHENG Enliang, FRAHM J M, et al. Pixelwise view selection for unstructured multi-view stereo[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer-Verlag, 2016: 501-518.
|
| [26] |
ZHENG Enliang, DUNN Enrique, JOJIC Vladimir, et al. Patch match based joint view selection and depthmap estimation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH: IEEE, 2014: 1510-1517.
|
| [27] |
ZHU Siyu, FANG Tian, ZHANG Runze, et al. Multi-view geometry compression[C]//Proceedings of the 12th Asian Conference on Computer Vision. Singapore: Springer-Verlag, 2014: 3-18.
|
| [28] |
KOBBELT L, CAMPAGNA S, VORSATZ J, et al. Interactive multi-resolution modeling on arbitrary meshes[C]//Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques. New York, NY: ACM, 1998: 105-114.
|
| [29] |
PONS J P, KERIVEN R, FAUGERAS O. Multi-view stereo reconstruction and scene flow estimation with a global image-based matching score[J]. International Journal of Computer Vision, 2007, 72(2): 179-193. |
| [30] |
DELAUNOY A, PRADOS E. Gradient flows for optimizing triangular mesh-based surfaces:applications to 3D reconstruction problems dealing with visibility[J]. International Journal of Computer Vision, 2011, 95(2): 100-123. |
| [31] |
BOYKOV Y, VEKSLER O, ZABIH R. Fast approximate energy minimization via graph cuts[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(11): 1222-1239. DOI:10.1109/34.969114 |
| [32] |
WAECHTER M, MOEHRLE N, GOESELE M. Let there be color! large-scale texturing of 3D reconstructions[C]//Proceedings of the 13th European Conference on Computer Vision. Cham: Springer-Verlag, 2014: 836-850.
|
| [33] |
KOENDERINK J J. What does the occluding contour tell us about solid shape?[J]. Perception, 1984, 13(3): 321-330. DOI:10.1068/p130321 |
| [34] |
ZHANG Liangpei, ZHANG Yun, CHEN Zhenzhong, et al. Splitting and merging based multi-model fitting for point cloud segmentation[J]. Journal of Geodesy and Geoinformation Science, 2019, 2(2): 78-89. |