



2. 国土资源部城市土地资源监测与仿真重点实验室, 广东 深圳 518000
2. Key Laboratory of Urban Land Resources Monitoring and Simulation, Ministry of Land and Resources, Shenzhen 518000, China
随着无人机的飞速发展,航拍多角度倾斜影像已逐步成为城市三维重建的主要数据来源。基于倾斜影像的城市三维重建流程主要包括相机标定、密集点云生成、表面三角网格重建、纹理映射等步骤。
目前,其余3个主要流程已经有很多成熟且稳定的计算方法[1-5],而对于表面三角网格重建流程,由于噪声点的存在使得重建的网格质量不高。主流的表面重建方法有泊松重建和Delaunay四面体表面重建方法两种。泊松重建计算速度快[6],但是在重建城市场景时,会使墙线等锐利区域变得过于平滑。Delaunay四面体表面重建方法能抵抗一定的噪声影响,但计算效率低,所以泊松重建是现在最常用的表面重建算法。目前对泊松重建算法的研究聚焦于提高计算效率及减少噪声影响。文献[7]提出了经过屏蔽的泊松表面重建算法,对输入点云进行插值约束,实现更快、更高质量的表面重建。文献[8]在此基础上引入广义Tikhonov正则化,减少噪声点的影响。文献[9]用Huber惩罚项替代最小二乘,使得重建结果对噪声和外点更加稳健。
在城市三维建模中,针对表面重建结果缺乏丰富细节信息的问题,需要采用网格精化方法进一步提高表面模型的精度,国内外已有一些相关的研究进展。文献[10-11]系统地讨论了基于变分法的网格精化算法,并深入探讨了如何将可视信息用于到网格精化中,提出最小化影像重投影误差来精化表面。文献[12]也提出了一种基于影像一致性的网格精化方法,提高了网格的质量,但是此算法效率较低。在此基础上,文献[13]在处理基于变分法的网格精化算法时加入额外的判断步骤以避免不必要的采样迭代,加快变分公式的精化。文献[14]提出了自适应分辨率控制算法,能够在保证几何精度的前提下,尽可能提高网格优化的效率。文献[15]也利用了影像信息,利用梯度下降法求解能量方程最小化从而优化三角网格模型。文献[16]针对网格精化中会选择大量冗余相邻影像的问题,通过视图选择方式,仅选择少量成像效果较好的视图用于网格精化,可以大幅度提高网格精化效率。除此之外,有学者提出另外的优化策略。文献[17]采用一种非迭代的增量式重建方法。首先根据法线变化识别出嵌入锐利特征的区域,然后预测锐利区域顶点的位置,最后通过区域收缩使顶点移动到锐利边缘。文献[18]将语义信息引入到网格精化中,统筹考虑几何信息与语义信息。文献[19]提出一种基于图像边缘、超像素和二阶平滑约束的曲面重建方法,与传统的MVS(multi-view stereo,多视立体)方法相比,重建质量相当,但速度更快。文献[20]利用了曲线和点云结合来进行细地物的建模。从相关论文的研究结果来看,这些方法都没有考虑城市建筑物的边缘特征,而在三维城市场景建模中,噪声点的存在导致重建的城市建筑物模型边缘过于平滑,不能表现建筑物墙线边缘平直锐利的特点,使重建模型视觉效果下降。
针对以上问题,本文提出一种带线约束的摄影测量网格变分精化方法,将网格模型精化问题转换为最小化能量函数问题。
1 带线约束的摄影测量网格变分精化算法本文算法流程如图 1所示。

|
| 图 1 算法流程 Fig. 1 Algorithm flow chart |
1.1 构建初始网格模型
本文将网格精化问题转换为能量最小化问题,即通过使顶点移动到更精确的位置的方式使能量下降。首先要得到初始网格模型。采用官网提供的泊松重建可执行程序,设置八叉树深度为10,其余参数默认,得到三角网格模型作为初始网格模型。
1.2 构建能量函数将网格表面能量记为E,类似于E(S)=Edata(S)+λEsmooth(S)。本文能量函数由影像一致性项、正则化项、线约束项三部分构成,可以表示为
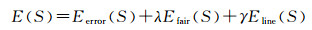 (1)
(1)
式中,Eerror(S)表示数据项,对应影像一致性项,具体可参见1.3节;Efair(S)表示平滑项,对应正则化项,实际求解时采用拉普拉斯平滑,具体可见第1.4节;Eline(S)表示附加能量项,对应线约束项,具体可见1.5节;λ、γ为平滑项和附加能量项的权重值。求解过程是首先输入初始网格模型,然后引入影像一致性约束、正则化约束和线约束3个能量项,离散化得到网格顶点的梯度变化值,采用梯度下降法,使顶点移动来达到能量下降的目的。能量函数降低即网格顶点移动到更精确的位置,使模型能够保持边缘特征,从而提升重建模型的视觉效果。
1.3 影像一致性约束影像一致性约束是衡量网格表面上的一个三维点投影到其可见的两张或多张影像上像素间的相似程度。NCC(normalized cross-correlation,归一化互相关)与ZNCC(zero-normalized cross-correlation,零均值归一化互相关)都是影像立体匹配中评价相似性较为常见的互相关计算方法。ZNCC相较NCC更为稳健,因为它在公式中减去了窗口内的均值,更能抵御光照的变化,因此本文采用ZNCC作为影像一致性计算测度。具体描述如下:
将网格表面记为S,x是表面S上的点,本文利用文献[21]中的重投影误差能量方程
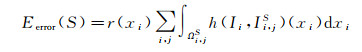 (2)
(2)
式中,Ii, jS=Ij○∏j○∏i-1表示影像Ii通过表面S重投影到Ij的部分;Ωi, jS是重投影的定义域,如图 2所示。h(I, J)(x)是衡量两幅影像I、J在对应像素点x处的影像一致性度量。采用ZNCC零均值归一化互相关匹配算法,利用两个待匹配像素点邻域窗口内的像素,通过零均值归一化度量公式来计算两个待匹配像素之间的相似程度
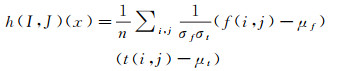 (3)
(3)

|
| 图 2 重投影 Fig. 2 The sketch of reprojection |
式中,i、j是匹配窗口内像素点的坐标;n是匹配窗口内像素点的个数;f(i, j)和t(i, j)是两张影像对应像素的像素值;μf和μt是匹配窗口内像素值的平均值;σf和σt是匹配窗口内像素值的标准差。
1.3.1 离散化由式(1)可知,影像一致性能量是位于连续空间上的。为了最小化影像一致性能量函数并应用到网格模型中,需要将连续的能量函数离散化到每个网格顶点上。在实际计算时,先寻找影像对,即如果两张影像拍摄到同一区域则加入影像对集合。遍历所有影像对,选择其中一张影像,遍历所有像素点,投影到三维网格模型中得到其三维点,然后再反投影到第2张影像上。从影像空间计算重投影误差后,根据重心坐标将此对应三维点的影像一致性能量添加到其三角面所在的3个顶点上。最终每个顶点的梯度改正值等于所有包含这个顶点的三角形在所有影像对I、J上投影的像素加权之和。
1.3.2 可靠性因子由于影像一致性约束与两张影像匹配的准确度有关,在纹理少或者弱纹理的地方(如建筑物的白色墙体部分)匹配误差较大。针对这种情况,在每个影像对I、J的对应像素点x处加入可靠性因子权重项
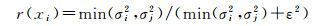 (4)
(4)
式中, σi2和σj2是像素xi在影像Ii和影像IijS上像素窗口大小为7×7内计算的局部方差;ε2是一个常数,本文设为0.001 5。可靠性因子越大,说明两张影像匹配越准确,影像一致性约束更加可靠,所占权重更大。
1.4 正则化约束由于噪声点的存在,重建的模型会产生凹凸不平的表面,墙面重建的结果并不理想,无法表现出其平整光滑的真实表面,因此引入正则化约束对网格表面进一步平滑。计算两个拉普拉斯平滑项,将归一化后的能量值加权加入每个顶点的梯度改正值。正则化约束项包含两部分
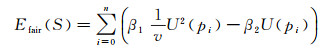 (5)
(5)
式中,pi是网格的顶点;β2是一阶拉普拉斯离散模拟的权重,本文试验设为0.02;β1是二阶拉普拉斯离散模拟的权重,本文试验设为0.18。具体描述如下。
1.4.1 一阶拉普拉斯离散模拟假设平面上存在一个噪声点,而周围点是正常点,则表面会出现异常凸起。对于网格模型的三维点,经典的做法是取其一阶环邻域的所有点坐标的平均值作为一阶拉普拉斯离散模拟的结果,异常凸起点会被踏平,达到平滑效果,即所谓的伞算子[22],如图 3所示。

|
| 图 3 顶点一阶环邻域 Fig. 3 1-ring neighborhood of a vertex |
本文引入距离因子,距离中心点越远的邻域点应该具有较低的权重,因此采用邻域点到中心点的距离倒数加权求取平均位置
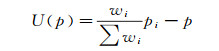 (6)
(6)
式中,pi是中心点p的一阶环邻域的点坐标;wi是中心点到邻域点的距离,wi=||p-pi||-1。顶点的更新策略为:pi←pi+U(pi)。
1.4.2 二阶拉普拉斯离散模拟不同于一阶计算,二阶拉普拉斯离散模拟加入了二阶环邻域的点信息。对于一个平面特征,若表面上有噪声点,仅依靠一阶环邻域的点进行平滑可能会使得表面点错误凸起或者凹陷。引入二阶环邻域的点进行平滑可以减少噪声的影响,比一阶拉普拉斯离散模拟更加可靠,因此权重也较大
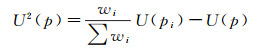 (7)
(7)
式中,U(pi)是中心点p的一阶环邻域的一阶拉普拉斯离散模拟结果。同样引入距离因子加权计算平均值。此时顶点的更新策略为pi←pi-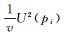
采用文献[23-24]的方法,首先用LSD(line segment detector,线段检测)方法从影像上提取二维线特征,计算相关影像上的线段对应关系,确定最相关二维线段计算其对应的三维空间线段,最后利用联合光束法平差来优化三维线段。
如图 4所示,图 4(a)是原始影像中的其中一张影像,图 4(b)是用这些影像提取出来的三维线段示意图,主要线特征都已被正确提取出来,具体线精度的分析可见2.1节。

|
| 图 4 原始影像及其三维线段 Fig. 4 Original image and line segments |
1.5.2 确定待调整的网格顶点
在得到了一系列三维线段后,调整处于三维线段附近的网格顶点{v},改善建筑物边缘锐利平直的视觉效果。对于一条三维线段,选取其附近的网格点需满足以下3个条件:
(1) 选取的网格顶点到三维线段的投影点应位于线段两个端点之间。
(2) 选取的网格顶点到三维线段的欧氏距离应该小于阈值λ。
(3) 选取的网格顶点不能是同一三角形内的3个顶点。
对于条件1,满足条件的顶点有两种,P在三维线段AB上或者P的投影点在三维线段AB上;不满足条件的顶点是P的投影点在AB的延长线上。此类顶点是需要滤除的,即∠PAB为钝角,满足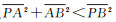
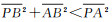
对于条件2,网格顶点到三维线段的距离采用顶点P到其投影点的欧氏距离公式计算。阈值λ的设置应保证离线段最近的点尽可能被选择,而又不能选择太多周围点,故本文选择采用整个三角网格模型边长的平均值作为阈值λ。
对于条件3,如果一个三角面的3个顶点同时满足条件1和条件2,则这3个顶点都会加入三维线段的周围点集,在进行线约束后会产生狭长三角形,不利于后续纹理映射步骤。因此需要做如图 5所示的操作,若存在这样的三角形,则筛选3个顶点,只将其中距离该线最近的两个顶点加入到待调整网格顶点集{v}中。图 5(a)中黑色实心点表示符合条件1和条件2的候选点集,黑色实心点构成的三角形是满足条件3的三角形,图 5(b)中黑色实心点为最终确定的待调整的网格顶点,灰色实心点为不调整的网格顶点。

|
| 图 5 确定待调整的网格顶点 Fig. 5 Determine the vertices to be adjusted |
1.5.3 三维线约束
经1.5.2节确定了三维线段附近待调整的网格顶点集合{v}后,计算这些网格顶点到其对应最近的三维线段的投影点之间的坐标差值。线约束能量函数如下
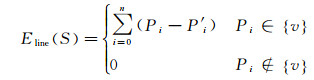 (8)
(8)
式中,Pi是待调整的网格顶点坐标;P′i 是该网格顶点到其最近的三维线段的投影点坐标。对于网格表面的其他顶点,线约束能量设为0。如图 6所示,此图仅表示三维线约束过程,图 6(a)与图 5(b)一致,点的含义也相同,箭头表示点移动的方向,即沿着点到线段的垂线移动。在每次迭代精化的过程中,线附近的网格顶点(图中黑色实心点)通过最小化点到线的距离,调整后的网格点会越来越接近直线,而其余点(图中灰色实心点)在线约束调整时位置不变。

|
| 图 6 线约束 Fig. 6 The line constraint |
2 试验与结果分析
为了验证本文算法的可行性和效果,分别采用标准数据集和实际场景数据集进行试验。标准数据集采用Strecha等提供的3套数据集Fountain-P11、Herz-Jesu-P8、Herz-Jesu-P25,为地面近景数据,影像采用Canon D60拍摄,影像分辨率为3072×2048像素。从官网上下载得到Fountain-P11、Herz-Jesu-P8两套数据集的真实点云,使用Zoller+Forhlich IMAGER 5003采集,Fountain-P11数据有11张影像,Herz-Jesu-P8有8张影像。实际场景数据拍摄于武汉市洪山区武大园二路,用Sony A500组成的五镜头相机采集了114张分辨率为5456×3432的下视影像。
2.1 三维线精度分析采用包含GROUND TRUTH的两组标准数据集Herz-Jezu-P8和Fountain-P11进行三维线精度分析。首先采用文献[23-24]中的Line3d++线提取算法得到试验的原始三维线数据。将三维线段均匀8等分,包含两个端点在内共9个顶点,计算每条线的每个顶点到参考模型的最短距离。取每条线上9个顶点所求距离的平均值作为这条线到参考模型的最短距离。三维线距离以5 mm为间隔从0到3 cm划分为6个区间,距离大于3 cm可认为是精度不可靠的线。
输入两组标准数据集的原始影像,生成投影差精度在2 cm以内的三维线段,如图 7所示。将LiDAR数据作为参考模型,图 7(a)是Herz-Jezu-P8数据共生成1061条三维线段;图 7(b)是Fountain-P11数据共生成862条三维线段。具体区间的三维线条数和占比见表 1。

|
| 图 7 激光扫描模型和三维线段 Fig. 7 Ground truth and 3D line segments |
| 精度 区间/cm | Herz-Jezu-P8 | Fountain-P11 | |||
| 条数/条 | 占比/(%) | 条数/条 | 占比/(%) | ||
| (0,0.5) | 11 | 1.036 758 | 139 | 16.125 29 | |
| (0.5,1) | 588 | 55.419 42 | 474 | 54.988 4 | |
| (1,1.5) | 257 | 24.222 43 | 110 | 12.761 02 | |
| (1.5,2) | 81 | 7.634 307 | 45 | 5.220 418 | |
| (2,2.5) | 38 | 3.581 527 | 18 | 2.088 167 | |
| (2.5,3) | 11 | 1.036 758 | 4 | 0.464 037 | |
| (3,∞) | 75 | 7.068 803 | 72 | 8.352 668 | |
| 总数 | 1061 | 100 | 862 | 100 | |
由图 8可以看出,超过50%的三维线集中在5 mm到1 cm精度之间,大约90%的三维线精度在2 cm以内,只有大约7%的线精度大于3 cm被认为是不可靠的线。这部分线通常包括两部分:未重建出来的场景三维线(如栏杆、房顶吊环等)、错误匹配的三维线。第1类的线真实存在,但由于GROUND TRUTH模型未将这部分重建出来,所以计算出来的线精度低。第2类线是由于在影像空间进行线特征提取时遇到相似纹理导致的错误线匹配造成的,这类线通常与模型偏差较大,在后续进行三维线约束的试验时,本文能通过距离阈值λ有效地将这类点筛除。

|
| 图 8 三维线精度直方图 Fig. 8 The histogram of line precision |
2.2 网格精度分析
采用包含GROUND TRUTH的两组标准数据集Herz-Jezu-P8和Fountain-P11进行网格精度分析。文献[25]中的精度评定方法需模型的空三在同一坐标系下,因此本节将八叉树深度设为10,其余参数默认的泊松重建算法与参数全默认的OpenMVS算法与本文算法结果列入对比试验中,验证本文算法的有效性。
评估重建模型的数值精度DSij采用建立相对误差直方图hk的方法
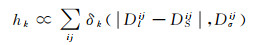 (9)
(9)
式中,Dlij是像素i和相机j的LiDAR深度估计期望值;DSij是从三维三角网格模型获得的,通过计算第1个三角形穿过像素i的第j个相机光线相交的深度;Dσij是对应的方差。当深度差异|Dlij-DSij|介于[kDσij, (k+1)Dσij]范围内时,δk(·)等于1,反之,δk(·)等于0。图 9所示是基于单张影像展示的方差加权深度差异图(红色部分表示误差大于30σ,绿色部分表示LiDAR数据缺失,灰度从255~0即颜色从白到黑表示相对误差从0~30σ,误差越大颜色越深),上排是Herz-Jezu-P8数据,下排是Fountain-P11数据,图 9(a)是八叉树深度为10的泊松重建结果,图 9(b)是OpenMVS重建结果,图 9(c)是本文算法的结果。从方差加权深度差异图中可以发现,在P8数据中泊松重建算法与OpenMVS算法几乎看不出差别,而本文算法在楼梯扶手、横杆等细节处重建精度更好,在Fountain-P11数据中OpenMVS与本文算法相差不大,但均优于泊松算法,因为泊松算法地面和墙面的噪声更多,具体精度数值分析见表 2。图 9中参考影像的相对误差直方图显示如图 10所示,横坐标k从1到10,以3σ为间隔,绝对差距大于30σ以及没有深度估计值的都归入到k=11类里。

|
| 图 9 方差加权深度差异 Fig. 9 The images of the variance weighted depth difference |
| 数据 | 试验 | k=1占比/(%) | k=2占比/(%) | 平均误差/3σ | 完整度/(%) |
| Herz-Jezu-P8 | 泊松重建(深度10) | 8.229 4 | 17.321 3 | 4.175 2 | 79.654 3 |
| OpenMVS | 10.037 5 | 19.874 9 | 3.961 3 | 80.593 8 | |
| 本文算法 | 15.580 3 | 24.375 8 | 2.700 1 | 82.960 1 | |
| 最大差值 | +7.350 9 | +7.054 5 | -1.475 1 | +3.305 8 | |
| Fountain-P11 | 泊松重建(深度10) | 28.963 8 | 16.440 6 | 2.406 5 | 92.196 0 |
| OpenMVS | 33.007 2 | 19.980 9 | 2.284 2 | 94.851 3 | |
| 本文算法 | 37.284 1 | 21.153 5 | 2.115 4 | 95.438 3 | |
| 最大差值 | +8.320 3 | +4.712 9 | -0.291 1 | +3.242 3 |

|
| 图 10 相对误差发生率 Fig. 10 The histogram of the relative error occurrence |
表 2列出了两组数据列出了图 10中的k=1、2时的具体数值以及平均相对误差值和完整度。两套数据的计算结果均表明,本文试验使得k=1,即相对误差小于3σ的比例相比泊松算法升高8%左右,相比OpenMVS算法升高5%左右,k=2,即误差位于(3σ, 6σ)的比例也有所增加,但比k=1时比例增加的幅度小。k=1、2反映了精度最高的点占比,本文算法有效地提高了这两部分比例。随着k的增加误差增大,比例减少,说明本文有效地提高了精度高的点数量,同时减少了精度低的点数量。平均相对误差计算了相对误差小于30σ部分的加权平均值,完整度计算了相对误差小于30σ所占比例。本文算法相比另外两种算法平均相对误差更小,完整度更好,因此说明本文算法生成的三维三角网格模型质量更好。
2.3 3个约束项作用分析本节以Herz-Jesu-P25数据集为例,对比说明3个约束项的作用。影像一致性项是使模型的细节部分更加精确,正则化项是确保三角面形状规则以及表面平滑,线约束项使模型具有线特征的部分变得更加平直锐利。
如图 11所示,(a)、(b)两组的左侧为无影像一致性约束结果,右侧为有影像一致性约束结果。可见影像一致性约束主要作用是使模型细节更加丰富,比如雕塑的轮廓、鼻子、衣服、动作等特征得以显现。

|
| 图 11 影像一致性约束项作用对比 Fig. 11 Contrast of photo-consistency constraint |
如图 12所示,(a)、(b)两组左侧为无正则化约束结果,右侧为有正则化约束结果。可见正则化约束主要作用是使表面在保持形状的同时变得平滑,比如平整的地面由于噪声点的存在会异常凸起,经过正则化约束后,平面变得更加平整,表面噪声点也相应地减少。

|
| 图 12 正则化约束项作用对比 Fig. 12 Contrast of regularization constraint |
如图 13所示,(a)、(b)两组左侧为无线约束结果,右侧为有线约束结果。可见线约束项主要作用是使1.5节中提取出三维线特征的区域变得更加平直锐利,而未加线特征约束时,这些直线特征难以显现,真实感较差。

|
| 图 13 线约束项作用对比 Fig. 13 Contrast of line constraint |
2.4 网格精化效果分析
本文以标准数据集Fountain-P11和实景三维城市模型进行网格精化效果分析,对比试验包括泊松重建结果、MVE(multi-view environment)结果、Photoscan结果、OpenMVS结果、本文算法结果以及GROUND TRUTH对比。Photoscan软件各项参数精度都设为high,泊松算法八叉树深度为10,其余参数默认,MVE算法和OpenMVS算法均采用默认参数。图 14所示是Fountain-P11数据集的网格精化效果对比。从结果中可以看出泊松重建算法较平滑,MVE算法数据缺失较多,photoscan和OpenMVS结果较好,但都不如本文算法细节丰富,尤其可见墙壁上装饰物的竖线条区域。其余算法都无法显现出线特征而本文算法线特征明显,本文算法结果也最接近GROUND TRUTH。

|
| 图 14 Fountain-P11数据集局部网格精化效果对比 Fig. 14 Local contrast of mesh refinement of Fountain-P11 data sets |
图 15所示为实景三维模型试验结果,第1行为房屋侧面对比图,第2行为房顶对比图。因为房屋和树木距离较近,泊松算法出现了大量错误重建,墙线处有大量异常凸包,而MVE算法产生了大量空洞,完整性差,Photoscan异常凸包减少,但细节较差,而且房顶轮廓未被重建出来,OpenMVS算法房顶重建质量较好,房顶轮廓很清晰,但细节不如本文算法,其侧面重建效果也不如Phhotoscan和本文算法,并且以上所有算法都不能保证墙线处的线特征。综上,本文算法能有效地减少噪声的影响,在保证表面一定程度平滑的情况下细节更为丰富,并且在加入线约束后能有效地保留边缘特征的尖锐特性,更接近于真实表面。

|
| 图 15 实景三维城市模型局部网格精化效果对比 Fig. 15 Local contrast of mesh refinement of real 3D urban model |
图 16展示了本文算法重建的网格表面模型以及纹理映射后的结果,网格质量越高,纹理映射效果越好。本文算法不仅提高了网格质量,而且在有线特征的边缘区域较好地保持了其平直锐利的特点,使得最终贴图质量也得到了提升,视觉效果更好。

|
| 图 16 实景三维城市模型重建和贴图全局效果 Fig. 16 Global effect of real 3D urban model reconstruction and texturing |
3 结论
本文针对三维实景城市模型重建过程中出现的细节不够丰富、边缘区域过于平滑的问题,提出一种带线约束的摄影测量网格变分精化方法。引入影像一致性约束项、正则化项、线约束项,为每个三角网格顶点计算坐标改正值,采用迭代变分精化的方法,上一次迭代的结果作为下一次迭代的初值,使模型顶点逐渐向模型真实表面移动。试验结果表明,本文算法使得网格的精度有所提高,并且使具有墙线、楼梯、雕塑细节等具有线特征的模型边缘区域的锐利特征得以保持,视觉效果更好。相应的,算法也存在一定的局限性,比如模型重建精度与三维线段的精度密切相关,而且本文只考虑了直线特征,但实际场景中包含大量曲线特征。如何高精度的提取直线或者曲线特征,实现高精度建模将是下一步的研究方向。
| [1] |
MOULON P, MONASSE P, MARLET R. Adaptive structure from motion with a contrario model estimation[C]//Proceedings of the 11th Asian Conference of Computer Vision.Daejeon: Springer, 2012: 257-270.
|
| [2] |
WAECHTER M, MOEHRLE N, GOESELE M. Let there be color! large-scale texturing of 3D reconstructions[C]//Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014: 836-850.
|
| [3] |
欧阳欢, 范大昭, 纪松, 等. 结合离散化描述与同名点约束的线特征匹配[J]. 测绘学报, 2018, 47(10): 1363-1371. OUYANG Huan, FAN Dazhao, JI Song, et al. Line matching based on discrete description and conjugate point constraint[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(10): 1363-1371. DOI:10.11947/j.AGCS.2018.20170231 |
| [4] |
李明, 张卫龙, 范丁元. 城市三维重建中的自动纹理优化方法[J]. 测绘学报, 2017, 46(3): 338-345. LI Ming, ZHANG Weilong, FAN Dingyuan. Automatic texture optimization for 3D urban reconstruction[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(3): 338-345. DOI:10.11947/j.AGCS.2017.20160467 |
| [5] |
姜翰青, 王博胜, 章国锋, 等. 面向复杂三维场景的高质量纹理映射[J]. 计算机学报, 2015, 38(12): 2349-2360. JIANG Hanqing, WANG Bosheng, ZHANG Guofeng, et al. High-quality texture mapping for complex 3D scenes[J]. Chinese Journal of Computers, 2015, 38(12): 2349-2360. |
| [6] |
KAZHDAN M, BOLITHO M, HOPPE H. Poisson surface reconstruction[C]//Proceedings of the 4th Eurographics Symposium on Geometry Processing.Aire-la-Ville: ACM, 2006: 61-70.
|
| [7] |
KAZHDAN M, HOPPE H. Screened Poisson surface reconstruction[J]. ACM Transactions on Graphics, 2013, 32(3): 61-70. |
| [8] |
GUARDA A F R, BIOUCAS-DIAS J M, RODRIGUES N M M, et al. Improving point cloud to surface reconstruction with generalized Tikhonov regularization[C]//Proceedings of the 19th International Workshop on Multimedia Signal Processing. Luton: IEEE, 2017: 1-6.
|
| [9] |
ESTELLERS V, SCOTT M, TEW K, et al. Robust Poisson surface reconstruction[C]//Proceedings of the 5th International Conference on Scale Space and Variational Methods in Computer Vision.Lège-Cap Ferret, France: Springer, 2015: 525-537.
|
| [10] |
DELAUNOY A, PRADOS E. Gradient flows for optimizing triangular mesh-based surfaces:applications to 3D reconstruction problems dealing with visibility[J]. International Journal of Computer Vision, 2011, 95(2): 100-123. DOI:10.1007/s11263-010-0408-9 |
| [11] |
DELAUNOY A, POLLEFEYS M. Photometric bundle adjustment for dense multi-view 3D modeling[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 1486-1493.
|
| [12] |
VU H H, LABATUT P, PONS J P, et al. High accuracy and visibility-consistent dense multiview stereo[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(5): 889-901. DOI:10.1109/TPAMI.2011.172 |
| [13] |
HEISE P, JENSEN B, KLOSE S, et al. Variational Patch-Match multiview reconstruction and refinement[C]//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 882-890.
|
| [14] |
LI S, SIU S Y, FANG T, et al. Efficient multi-view surface refinement with adaptive resolution control[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 349-364.
|
| [15] |
张春森, 张萌萌, 郭丙轩. 影像信息驱动的三角网格模型优化方法[J]. 测绘学报, 2018, 47(7): 959-967. ZHANG Chunsen, ZHANG Mengmeng, GUO Bingxuan. Refinement of the 3D mesh model driven by the image information[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(7): 959-967. DOI:10.11947/j.AGCS.2018.20170733 |
| [16] |
MORREALE L, ROMANONI A, MATTEUCCI M. Predicting the next best view for 3D mesh refinement[C]//Proceedings of the 15th International Conference Intelligent Autonomous Systems. Berlin: Springer-Verlag, 2019: 760-772.
|
| [17] |
WANG C C L. Incremental reconstruction of sharp edges on mesh surfaces[J]. Computer Aided Design, 2006, 38(6): 689-702. DOI:10.1016/j.cad.2006.02.009 |
| [18] |
BLÁHA M, ROTHERMEL M, OSWALD M R, et al. Semantically informed multiview surface refinement[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 3839-3847.
|
| [19] |
BÓDIS-SZOMORU' A, RIEMENSCHNEIDER H, VAN GOOL L. Superpixel meshes for fast edge-preserving surface reconstruction[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 2011-2020.
|
| [20] |
LI Shiwei, YAO Yao, FANG Tian, et al. Reconstructing thin structures of manifold surfaces by integrating spatial curves[C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2887-2896.
|
| [21] |
PONS J P, KERIVEN R, FAUGERAS O. Multi-view stereo reconstruction and scene flow estimation with a global image-based matching score[J]. International Journal of Computer Vision, 2007, 72(2): 179-193. DOI:10.1007/s11263-006-8671-5 |
| [22] |
KOBBELT L, CAMPAGNA S, VORSATZ J, et al. Interactive multi-resolution modeling on arbitrary meshes[C]//Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM, 1998: 105-114.
|
| [23] |
HOFER M, MAURER M, BISCHOF H. Line3D: efficient 3D scene abstraction for the built environment[C]//Proceedings of German Conference on Pattern Recognition. Aachen: Springer-Verlag, 2015: 237-248.
|
| [24] |
HOFER M, MAURER M, BISCHOF H. Efficient 3D scene abstraction using line segments[J]. Computer Vision and Image Understanding, 2017, 157(4): 167-178. |
| [25] |
STRECHA C, VON HANSEN W, VAN GOOL L, et al. On benchmarking camera calibration and multi-view stereo for high resolution imagery[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage: IEEE, 2008: 1-8.
|