



2. 中国测绘科学研究院, 北京 100830
2. Chinese Academy of Surveying and Mapping, Beijing 100830, China
视频拼接是图像拼接的外延,是指将数个有重叠部分的视频序列(多时相、多视角、多传感器获取)无缝拼接成宽景乃至全景视频的技术[1-2]。依据相机设置和应用场景的不同,视频拼接方法可分为3大类:第1类是静态场景下固定多摄像头的视频拼接方法,如室内监控摄像头、公安监控摄像头等,这类情况需要避免重叠区域过小;第2类是运动场景下固定摄像头的视频拼接方法,如无人机视频、移动测量车视频等,这类情况需要避免运动产生的视差;第3类是动静场景混合状态下的非刚性固连摄像头的视频拼接方法,如手持摄像设备等,这类情况需作平滑运动轨迹的稳定处理[3]。本文的研究属于第1类范畴。
静态场景下视频拼接多基于特征匹配算法,常见的特征配准方法有:Moravec[4]、SIFT(scale invariant feature transform, SIFT)[5]、Harris[6]、Harris-Laplacian[7]等。其中尺度不变特征变换匹配SIFT算法因其对平移、旋转、尺度变化等均具有不变性,同时对噪声、光照变化、视角变化具有较强的稳健性,成为当前主流的图形拼接算法,但存在计算量巨大、耗时长等问题,近年来研究学者进行了很多改进与优化。如文献[8]将主成分分析法(principal component analysis,PCA)与SIFT结合,提出了PCA-SIFT算法;文献[9]将分块Harris特征与SIFT算法结合,引入图像角点对特征点选取进行约束;文献[10]基于SIFT算法,提出了一种控制帧约束下的固定摄像头视频拼接方法。上述算法在一定程度上提高了SIFT算法的准确度和效率。此外,也有学者考虑到室外环境的监控经常受到多模式背景的干扰,如随风摇动的树枝、草坪及运动目标等,采用高斯混合模型对各个视频序列进行背景建模,然后利用背景图像实现多个视频序列的拼接[11]。然而,这些方法多适用于视频间重叠区域较大的情况,且在特征点匹配过程中由于仅考虑图像几何特征,导致准确度较低。交通监控视频有其自身的特点,同一监控区域内不同摄像头之间重叠区域范围变化较大,经常出现重叠度较小的情况且主光轴之间的夹角大,当采用传统方法进行视频拼接时,会因重叠区域过小而导致无法拼接或图像变形过大。
为此,本文提出一种交通监控视频图像语义分割及其拼接方法,以正射影像作为拼接背景影像,并基于全卷积神经网络对视频图像及正射影像进行语义分割,据此建立融合图像语义的特征匹配算法,实现交通监控视频的高质量拼接。
1 现有研究及不足 1.1 基于SIFT算法的视频拼接方法基于SIFT特征匹配的图像拼接算法是目前主流的视频拼接方法,其基本步骤是[12-13]:
(1) 特征点匹配:采集两幅重叠度在30%~50%的图像,建立图像的高斯多尺度空间,邻近层之间进行图像减法,得到高斯差分DOG(difference-of-Gaussian)金字塔,基于DOG金字塔提取图像特征点,采用BBF(best bin first)等算法进行特征点匹配。
(2) 计算单应矩阵:依据提取的特征点通过RANSAC(random sample consesus)算法估计单应矩阵H(式(1)),迭代剔除误差点,进而实现两幅图像几何关系的变换
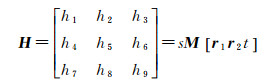 (1)
(1)
式中,hi(i=1, 2, …, 9)为坐标转换参数;s为比例因子;M为相机内参数矩阵;r1、r2为相机外参数中旋转矩阵的列分量;t为外参数的平移向量。
(3) 图像融合:依据式(2)按照反距离加权的方式进行图像融合,融合方向采用对角线方向[14]
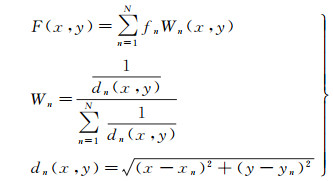 (2)
(2)
式中,F为图像融合函数;点(x, y)为对应点(xn, yn)在对角线方向的重叠区域边界点;fn为像素灰度值;Wn为权重值;dn是点(x, y)与点(xn, yn)之间的欧氏距离。
1.2 现有方法的不足由上述分析可以发现,基于SIFT特征匹配的视频拼接算法依赖于邻近图像之间的重叠度,而交通监控视频有其自身的特点,虽然各个监控视频的主光轴朝向同一区域,但同一监控区域内不同摄像头之间重叠区域范围变化较大,应用传统方法进行图像拼接会出现以下问题:
(1) 对于重叠区域较小的监控视频,传统方法不能在重叠区域内找到适当的匹配特征点,从而不能对其进行拼接。
(2) 对于有一定重叠区域的监控视频,由于不同摄像头主光轴之间的夹角较大,导致匹配后图像变形较大。如图 1所示,图 1(a)为某一监控场景平面,矩形框内分别为摄像头A和B的监控范围,假设摄像头主光轴与地面夹角成60°,则摄像头A和B内图像分别为图 1(b)和1(c)所示,对两个图像进行拼接,结果如图 1(d)所示,可以看出,矩形框A1和A2内初始形状一致的房屋,在拼接后产生明显变形(A2),矩形框B1内规则排列的房屋,也出现了较大的拉伸与形变(B2)。

|
| 图 1 现有方法存在不足 Fig. 1 Limitations of existing methods in traffic monitoring video |
(3) 传统方法中特征点匹配过程中仅考虑图像几何特征,容易产生特征点误匹配,如图 1(b)和1(c)中红色连接线所示,其对应的特征点因为几何特征相似而误匹配为连接点对。
2 交通监控视频图像语义分割及其拼接方法基于交通监控视频自身特点,本文提出一种交通监控视频图像语义分割及其拼接方法。核心内容是:①正射影像位置检索:利用交通监控视频附带地名信息粗定位视频对应的正射影像位置,进而利用边缘角度二阶差分直方图精确识别与交通监控视频最佳匹配的正射影像;②基于全卷积神经网络的图像语义分割:使用全卷积神经网络识别监控视频和正射影像中的交通专题信息区域,如斑马线、道路等;③图像语义分割约束下的特征点匹配:以正射影像作为中间背景平面,利用语义分割信息作为约束,将待拼接视频分别与背景正射影像进行特征匹配;④分别计算待拼接视频与正射影像之间的单应矩阵,并对重叠区域进行反距离加权融合。本文方法完整处理流程如图 2所示。

|
| 图 2 交通监控视频图像语义分割及其拼接方法处理流程 Fig. 2 The flowchart of proposed method |
2.1 正射影像位置检索
正射影像是城市基础地理信息数据,具有信息齐全饱满、色调清晰均匀、反差适中平衡的图像特点,为此,本文选取高精度正射影像(分辨率 < 0.1 m)作为拼接背景,实现对于交通视频的高质量拼接。依据视频具有的地名地址信息并结合图像中地物形状特征精确获取目标区域的正射影像。通常,每一个交通监控视频属性数据中都蕴含其对应的地名地址信息,例如北京市某十字路口的监控视频中附带“莲花池西路万丰路枪向南”信息,基于此地名地址可获得初步的位置信息(经纬度),实现正射影像的粗定位。为获取最佳正射影像位置,本文基于交通监控视频中的地物形状特征作进一步精细检索。
图像中地物边缘的几何结构是捕捉地物形状特征的关键,边缘角度二阶差分直方图是对图像全局形状特征的统计描述[15-17],本文以直方图相交距度量交通监控视频与正射影像之间的相似性,其计算步骤为:
步骤1:由于交通视频图像和对应区域的正射影像的形状信息大部分由图像中的亮度信息体现,为了提取图像的形状特征,首先根据式(3)将彩色推向转化成亮度图像,即从RGB(red-green-blue)空间转化到YIQ(luminance-in-phase-quadrature-phase)空间
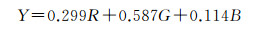 (3)
(3)
步骤2:基于亮度分量采用Canny算子提取图像边缘特征,进而利用Sobel算子,根据式(4)计算各个边缘像素点(x, y)在像素坐标系中水平及竖直方向上的灰度梯度(dx, dy)
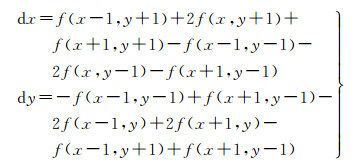 (4)
(4)
式中,f(x, y)代表像素点(x, y)的灰度值。
步骤3:根据式(5)计算交通视频图像和对应区域的正射影像的边缘角度θ(x, y)
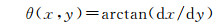 (5)
(5)
步骤4:交通视频图像和对应区域的正射影像之间若出现旋转,则会引起图像边缘角度变化,导致同一地物的边缘角度直方图出现圆平移(circle shift)。为此,根据式(6)对边缘角度进行二阶差分运算,使结果具有旋转不变性
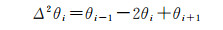 (6)
(6)
式中 θi为第i个边缘点对应的边缘角度;θi-1和θi+1是边缘方向上与该点邻近的两个边缘点的边缘角度。
步骤5:统计图像中边缘角度二阶差分直方图,并归一化为频率直方图,根据式(7)利用直方图相交距定义两幅图像p、q之间相似性
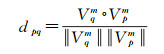 (7)
(7)
式中,Vqm=Vq-Vq;Vpm=Vp-Vp;Vq是待匹配的正射影像直方图特征;Vp是交通视频图像的直方图特征;dpq代表待二者之间的相似性程度,数值越高则两幅图像的相似性越高。
在通过地名地址信息粗定位的区域,依据监控视频覆盖范围及地物自然特征,本文选取120 m×120 m作为单元格大小、1 m为步长和交通视频图像进行匹配,图像相似度最高的单元格为最佳背景正射影像;监控区域内,对各个交通视频分别计算其对应的最佳背景正射影像,将这些影像进行镶嵌,并将镶嵌结果的最小外包矩形范围影像作为最终匹配结果。
2.2 基于全卷积神经网络的图像语义分割特征点匹配是拼接过程中最复杂的一环,现有方法多依据图像几何特征进行特征点匹配,这种方法容易出现误匹配的现象。图像语义分割技术是指使用一定的分类方法对图像进行像素分类,分割结果可以提供图像的高阶语义信息,对环境有更高的解析,为了提高现有视频拼接技术的准确性与鲁棒性,本文利用图像语义分割的结果对特征点提取和匹配的区域进行约束,进而提高匹配的速度和准确率。
文献[18]通过将卷积神经网络最后的全连接层改为反卷积层,提出了全卷积神经网络(fully convolutional network,FCN),该网络模型可实现图像像素级精细分类[18]。FCN使用影像和标签影像作为训练数据,通过调整网络中的卷积权值和阈值学习数据的特征,可以处理任意大小的输入图像并输出相同大小的语义分割图[19-20]。
本文选取全卷积神经网络FCN-8s[21-22]分别对交通监控视频和背景正射影像进行语义分割,提取关键交通专题地物作为特征点匹配约束,如斑马线、道路等。FCN-8s网络包含5个卷积层、3个全连接层,各层所用的滤波器大小、步长、神经元个数等关键参数见表 1。
| name | type | filter size-stride-pad | Num |
| Conv1 | convolution | 3×3-1-100 | 64 |
| Conv2 | convolution | 3×3-1-1 | 128 |
| Conv3 | convolution | 3×3-1-1 | 256 |
| Conv4 | convolution | 3×3-1-1 | 512 |
| Conv5 | convolution | 3×3-1-1 | 512 |
| Fc6 | convolution | 7×7-1 | 4096 |
| Fc7 | convolution | 1×1-1 | 4096 |
| Fc8 | convolution | 1×1-1 | n |
激活函数的功能是定义神经元在线性变换后的非线性输出结果,RELU函数相较传统的Sigmoid函数有着单侧抑制、收敛快、稀疏激活性、导数简单等优点,为此,本文选择RELU函数作为激活函数,当输入小于0时,输出为0;当输入大于0时,输出等于输入,数学表达式为
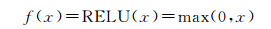 (8)
(8)
全卷积神经网络使用的池化层一般有两种,分别是均值池化和最大值池化,采用邻域内的均值或最大值作为池化输出。均值池化能减小邻域大小受限造成的估计值方差增大,更多地保留图像的背景信息;最大值池化能减小卷积层参数误差造成估计均值的偏移,更多地保留纹理信息,本文识别的交通视频和正射影像中交通专题语义特征需要保留更多的纹理信息,故本文选择使用最大值池化方式。
在经过卷积层、激活函数及池化操作后,可以获得输入影像的一个小尺寸特征影像。再通过反卷积对其进行上采样(upsampling)操作,得到所需的与原影像大小一致的特征影像。本文进行上采样过程中,将第4、5层池化累加的结果放大两倍,与第3层池化的结果相加,进而通过反卷积得到和原始影像大小一致的语义分割结果。图 3为交通视频图像和对应的语义分割标签数据示例。

|
| 图 3 交通视频图像和语义分割标签数据 Fig. 3 Traffic video image and its semantic segmentation label data |
2.3 图像语义分割约束下的特征点匹配
传统匹配方法中,当最小欧氏距离与次最小欧氏距离的比值小于设定阈值时,认为某一特征点与对应的最小欧氏距离的特征点为匹配点对[23],但匹配过程仅利用了特征点的邻域点信息。本文将语义分割结果与传统基于特征向量欧氏距离的匹配方法相结合,将二者共同作为特征点匹配约束条件。
首先匹配语义一致区域:分别统计交通视频图像和背景正射影像中各个语义区域的边缘角度二阶差分直方图,依据其自身的语义信息,分类别逐一匹配,获取最佳匹配关系;进而对匹配的分割区域进行SIFT特征点提取,并将语义分割结果与传统基于特征向量欧氏距离的匹配方法相结合进行特征点匹配。
假设点xi与点xj为一对特征匹配点集,则特征匹配函数为
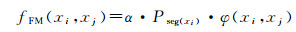 (9)
(9)
式中,α为特征匹配系数,其取值如式(10)所示;seg(xi)表示进行语义分割后xi所属的分类结果;Pseg(xi)为xi所属类别在语义分割中的查准率;φ(xi, xj)表示匹配点对应特征向量欧氏距离相似概率。
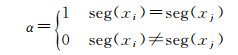 (10)
(10)
当某一匹配点对的fFM(xi, xj)值大于匹配阈值时TFM认为该匹配是正确的。根据匹配的特征点,利用RANSAC算法进行单应矩阵计算及误差剔除,将各待拼接视频变换至背景正射影像,进而对重叠区域采用反距离加权的渐入渐出融合方法进行图像融合。
3 试验与分析 3.1 试验数据与试验环境为了验证本文算法的有效性和合理性,利用山东省临沂市部分交通监控视频和正射影像等实际数据进行拼接试验,并与基于SIFT的视频拼接算法进行对比。试验环境为Intel Core i7-6700K处理器,主频4.00 GHz,内存16 GB,C++编程实现,Caffe深度学习框架。
试验数据选取临沂市54个典型路口,132个高清摄像头,视频图像大小为1920×1080像素;正射影像分辨率0.1 m。其中100个高清摄像头的视频帧和36个路口区域正射影像用于制作训练集,20个高清摄像头的视频帧和10个路口区域正射影像用于制作测试集,12个高清摄像头的视频帧和8个路口区域正射影像用于制作验证集。
3.2 语义分割准确度验证对交通专题特征进行人工解译获得标签数据,对原始数据和标签数据用大小为256×256像素、步长为256的滑块截取图像块,然后进行旋转和镜像实现数据增强,最终得到4000张训练数据集,1000张测试数据集,600张验证数据集。训练超参数最大迭代次数(max_iter)为10 000次,基础学习率(base_lr)为0.000 01,伽马系数(gamma)为0.1,学习率变换步长(stepsize)为2500,动量系数(momentum)为0.99,权重衰减(weight_decay)为0.000 5。图 4为语义分割结果。

|
| 图 4 语义分割结果 Fig. 4 Semantic segmentation result diagram |
以验证集全体的查准率和查全率作为语义分割的精度评定标准,根据式(11)、式(12)计算查准率(precision ratio,PR)和查全率(recall ratio,RR)
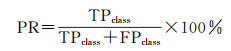 (11)
(11)
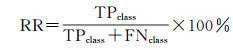 (12)
(12)
式中,TPclass为预测为某类地物且正确的像素数(true positive);FPclass为预测为某类地物但错误的像素数(false positive);FNclass为实际为某类地物但未被检索为该类地物的像素数(false negative)。
应用本文提出的基于全卷积神经网络FCN-8s进行语义分割的查全率、查准率见表 2。步行道因与其他区域边界过渡区域分割特征并不明显,查全率和查准率相对较低,分别为86%和89%,其他交通专题特征查全率和查准率精度均较高,在92%以上。
| (%) | |||||||||||||||||||||||||||||
| 准确率 | 目标类型 | ||||||||||||||||||||||||||||
| 道路 | 步行道 | 斑马线 | 草坪 | ||||||||||||||||||||||||||
| PR | 94.412 | 89.641 | 93.341 | 88.635 | |||||||||||||||||||||||||
| RR | 96.235 | 86.176 | 97.183 | 90.257 | |||||||||||||||||||||||||
3.3 特征提取结果可靠性验证
选取3个交通监控视频场景,分别用传统SIFT匹配算法以及本文提出的区域约束特征点匹配算法对该区域进行特征提取试验,其中传统特征点匹配算法使用BF(bruteforce)暴力匹配及KNN(k-nearest neighbor)匹配点对筛选算法,试验结果如图 5-图 7所示。从图 5(b)、图 6(b)、图 7(b)中可以看出,传统SIFT算法仅使用特征向量欧氏距离的相似度进行匹配,不可避免地会产生一些错误匹配,同时还有部分特征点散落在图像边缘,直接降低了特征点匹配的准确性;图 5(c)、图 6(c)、图 7(c)是本文提出区域约束特征点匹配算法试验结果,由于融合了图像高阶语义信息,提取的特征点集中分布在各个交通特征专题语义空间内,从而剔除了图像中大量的误匹配,优化了特征匹配点数量。

|
| 图 5 特征匹配场景1 Fig. 5 Image feature matching scenario 1 |

|
| 图 6 特征匹配场景2 Fig. 6 Image feature matching scenario 2 |

|
| 图 7 特征匹配场景3 Fig. 7 Image feature matching scenario 3 |
在比较两种匹配算法的性能时,本文对两幅图像中同名点进行了人工标定,精度为1/3像素,利用人工标定的点集由RANSAC算法计算两幅图像的参考单应矩阵,然后使用两种匹算法分别进行特征点匹配,获得的匹配点对逐个依据参考单应矩阵计算欧氏距离偏移量,将欧氏距离偏移量大于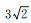
| 场景 | 监控视频图像 分辨率 | SIFT+BF+KNN | 本文算法 | |||||
| 正确率 | 特征点数量 | 时间/s | 正确率 | 特征点数量 | 时间/s | |||
| 1 | 1920×1080 | 0.335 | 1135 | 4.19 | 0.724 | 656 | 3.92 | |
| 2 | 0.475 | 898 | 3.87 | 0.752 | 634 | 3.64 | ||
| 3 | 0.534 | 1625 | 4.33 | 0.801 | 1125 | 4.11 | ||
3.4 视频拼接结果有效性验证
为检验本文方法对于交通监控视频拼接的有效性,分别选取视频之间重叠度不足20%、重叠度位于20%~60%之间及重叠度在60%以上的3处典型区域进行试验,如图 8-图 10所示。不同试验场景的拼接结果对比如图 11-图 13所示,值得注意的是,在图像融合阶段,本文选取正射影像和视频图像中灰度直方图分布最均匀的图像作为匀色基准,通过直方图规定化[24-25]算法将其他图像灰度直方图匹配至该基准,以提高拼接图像色彩质量并消除各图像之间的颜色差异。

|
| 图 8 试验场景1 Fig. 8 Experimental scenario 1 |

|
| 图 9 试验场景2 Fig. 9 Experimental scenario 2 |

|
| 图 10 试验场景3 Fig. 10 Experimental scenario 3 |

|
| 图 11 试验场景1拼接结果对比 Fig. 11 Comparison of stitching results for experimental scenario 1 |

|
| 图 12 试验场景2拼接结果对比 Fig. 12 Comparison of stitching results for experimental scenario 2 |

|
| 图 13 试验场景3拼接结果对比 Fig. 13 Comparison of stitching results for experimental scenario 3 |
图 8所示交通监控视频区域,视频之间的重叠度约为82%,图 11为该场景拼接结果对比效果。由图 11(a)和11(c)可以看出,对于重叠度较大的图像,两种方法均可得到较好的拼接结果,拼接区域无明显变形和接缝,此时增加中间影像对拼接结果无明显影响,如图 11(b)和11(c)所示。
图 9所示交通监控视频区域,视频之间的重叠度约为31%,图 12为该场景拼接结果对比效果。由图 12可以看出,两种方法均可对此区域进行拼接处理,但因各个交通视频与地面偏角相差较大,基于SIFT的拼接结果图像变形较大,如图 12(a)所示;将SIFT算法与中间影像结合,所得结果如图 12(b)所示,可以发现图像质量更为清晰,但因特征点匹配准确率较低,拼接结果存在一定程度变形;本文算法拼接结果则基本无变形,如图 12(c)所示。
图 10所示交通监控视频区域,视频之间的重叠度约为8%,图 13为该场景拼接结果对比效果。由图 13(a)可以看出,由于重叠区域过小,SIFT算法无法进行拼接;将SIFT算法与中间影像结合,所得结果如图 13(b)所示,可以发现,中间影像有效解决了因重叠度较低而无法拼接的问题,但该拼接结果中地物存在较大程度变形,且接缝明显;而本文算法不仅实现了该区域的正确拼接,且看不到明显接缝,如图 13(c)所示。
统计两种方法在特征匹配阶段寻找正确匹配点对的耗时,对于试验场景1,基于SIFT算法进行拼接所用时间为4.13 s,本文算法因需将两幅监控视频分别与正射影像进行匹配,故进行两次拼接,总用时为6.21 s(不包括语义分割时间);对于试验场景2、3,基于SIFT算法进行拼接所用时间分别为7.86 s、8.43 s,基于本文算法进行拼接所用时间分别为9.84 s、11.65 s(不包括语义分割时间),对应的直方图如图 14所示。由图 14可以看出,3种场景下两种方法耗时基本一致。此外,本文方法在SIFT匹配前还需要进行背景正射影像位置估计、语义分割及语义图块的匹配,降低了算法的实时性,但由于交通摄像头属于静态场景下固定监控点,本文算法只需进行首次正射影像位置估计、神经网络训练和特征匹配,计算获得单应矩阵后,后续的视频帧即可直接与正射影像利用该单应矩阵进行拼接,从而不会对视频拼接效率产生较大影响。

|
| 图 14 不同试验场景下两种拼接方法耗时对比 Fig. 14 Time-consuming comparison of two stitching methods in different experimental scenarios |
4 结论与讨论
传统视频拼接算法多适用于视频间重叠区域较大的情况,且特征点匹配过程中仅考虑图像几何特征,准确率较低,而交通监控视频有其自身特点,同一监控区域内不同摄像头之间通常重叠区域较小、主光轴之间夹角较大,为此,本文提出一种交通监控视频图像语义分割及其拼接方法。实际数据验证表明,相较于传统SIFT算法,对于重叠区域较小(<20%)的监控视频,本文方法可获得更好的拼接图像,且特征点匹配正确率由44.8%提高至75.9%,提升约31.1%;基于全卷积神经网络FCN-8s进行交通专题特征语义分割的查全率和查准率较高,均在86%以上,随着样本库的丰富,准确度还会继续提高。然而,由于本文方法引入了正射影像识别及图像语义分割过程,降低了算法的实时性,此外,正射场景是本文方法应用的前提条件,对于缺少正射影像的城市交通监控区域本文方法不再适用,且本文要求正射影像与交通监控视频时相基本一致,以保证匹配精度。对于上述不足,均有待在未来的工作中改进,如研究采用基于多线程的分时并行处理拼接方法,提高拼接效率;扩大中间背景影像的数据源,增加语义分割类型,并提高图像语义特征分割精度,以减小地物变化对本文方法的影响。
| [1] |
NIE Yongwei, SU Tan, ZHANG Zhensong, et al. Dynamic video stitching via shakiness removing[J]. IEEE Transactions on Image Processing, 2018, 27(1): 164-178. |
| [2] |
KRISHNAKUMAR K, GANDHI S I. Video stitching using interacting multiple model based feature tracking[J]. Multimedia Tools and Applications, 2019, 78(2): 1375-1397. |
| [3] |
杨毅, 王冬生, 宋文杰, 等. 融合图像语义的动态视频拼接方法[J]. 系统工程与电子技术, 2018, 40(12): 2845-2854. YANG Yi, WANG Dongsheng, SONG Wenjie, et al. Dynamic video stitching method embracing image semantics[J]. Systems Engineering and Electronics, 2018, 40(12): 2845-2854. |
| [4] |
MORAVEC H P. Obstacle avoidance and navigation in the real world by a seeing robot rover[D]. Stanford: Stanford University, 1980. http://www.researchgate.net/publication/243765273_Obstacle_Avoidance_and_Navigation_in_the_Real_World_by_a_Seeing_Robot_Rover
|
| [5] |
LOWE D G. Object recognition from local scale-invariant features[C]//Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra: IEEE, 1999: 1150-1157.
|
| [6] |
HAGGUI O, TADONKI C, LACASSAGNE L, et al. Harris corner detection on a NUMA manycore[J]. Future Generation Computer Systems, 2018, 88: 442-452. |
| [7] |
LI Jian, GUO Binxuan, PENG Zhe. Image matching of junction-type feature points based on the third-order moment[J]. Optik, 2015, 126(4): 411-416. |
| [8] |
KE Yan, SUKTHANKAR R. PCA-SIFT: a more distinctive representation for local image descriptors[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE, 2004: II-506-II-513.
|
| [9] |
杨宇博, 程承旗. 基于分块Harris特征的航拍视频拼接方法[J]. 北京大学学报(自然科学版), 2013, 49(4): 657-661. YANG Yubo, CHENG Chengqi. Block Harris based mosaic method for aerial video[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2013, 49(4): 657-661. |
| [10] |
刘畅, 金立左, 费树岷, 等. 固定多摄像头的视频拼接技术[J]. 数据采集与处理, 2014, 29(1): 126-133. LIU Chang, JIN Lizuo, FEI Shumin, et al. Video stitching technology based on fixed multi-camera[J]. Journal of Data Acquisition and Processing, 2014, 29(1): 126-133. |
| [11] |
苗立刚. 视频监控中的图像拼接与合成算法研究[J]. 仪器仪表学报, 2009, 30(4): 857-861. MIAO Ligang. Image mosaicing and compositing algorithm for video surveillance[J]. Chinese Journal of Scientific Instrument, 2009, 30(4): 857-861. |
| [12] |
HSU S, SAAWHNEY H S, KUMAR R. Automated mosaics via topology inference[J]. IEEE Computer Graphics and Applications, 2002, 22(2): 44-54. |
| [13] |
杨涛, 张艳宁, 张秀伟, 等. 基于场景复杂度与不变特征的航拍视频实时配准算法[J]. 电子学报, 2010, 38(5): 1069-1077. YANG Tao, ZHANG Yanning, ZHANG Xiuwei, et al. Scene complexity and invariant feature based real-time aerial video registration algorithm[J]. Acta Electronica Sinica, 2010, 38(5): 1069-1077. |
| [14] |
ACHARYA T, RAY A K.数字图像处理: 原理与应用[M].田浩, 葛秀慧, 王顶, 译.北京: 清华大学出版社, 2007. ACHARYA T, RAY A K. Principle and application of digital: image processing[M]. TIAN Hao, GE Xiuhui, WANG Ding, trans. Beijing: Tsinghua University Press, 2007. |
| [15] |
SALMAN N. Image segmentation based on watershed and edge detection techniques[J]. The International Arab Journal of Information Technology, 2006, 3(2): 104-110. |
| [16] |
刘嗣超, 李成名, 孙林. 基于边缘角度二阶差分直方图的城市遥感图像检索方法[J]. 山东科技大学学报(自然科学版), 2019, 38(2): 36-43. LIU Sichao, LI Chengming, SUN Lin. Remote sensing image retrieval based on histogram of edge angular second-order difference[J]. Journal of Shandong University of Science and Technology (Natural Science), 2019, 38(2): 36-43. |
| [17] |
包倩, 郭平. 基于直方图的遥感图像相似性检索方法比较[J]. 遥感学报, 2006, 10(6): 893-900. BAO Qian, GUO Ping. Comparative studies on similarity measures for remote sensing image retrieval based on histogram[J]. Journal of Remote Sensing, 2006, 10(6): 893-900. |
| [18] |
SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651. |
| [19] |
戴玉超, 张静, PORIKLI F, 等. 深度残差网络的多光谱遥感图像显著目标检测[J]. 测绘学报, 2018, 47(6): 873-881. DAI Yuchao, ZHANG Jing, PORIKLI F, et al. Salient object detection from multi-spectral remote sensing images with deep residual network[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 873-881. |
| [20] |
KRUTHIVENTI S S S, AYUSH K, BABU R V. Deepfix:a fully convolutional neural network for predicting human eye fixations[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4446-4456. |
| [21] |
NOH H, HONG S, HAN B. Learning deconvolution network for semantic segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1520-1528.
|
| [22] |
ZHOU Hao, ZHANG Jun, LEI Jun, et al. Image semantic segmentation based on FCN-CRF model[C]//Proceedings of 2016 International Conference on Image, Vision and Computing (ICIVC). Portsmouth: IEEE, 2016: 9-14.
|
| [23] |
PALENICHKA R M, LAKHSSASSI A, ZAREMBA M B. Outlier-resistant dissimilarity measure for feature-based image matching[C]//Proceedings of the 20th International Conference on Pattern Recognition. Istanbul: IEEE, 2010: 846-849.
|
| [24] |
GRUNDLAND M, DODGSON N A. Color histogram specification by histogram warping[C]//Color Imaging X: Processing, Hardcopy, and Applications. San Jose: SPIE, 2005: 610-621.
|
| [25] |
XIAO Bin, TANG Han, JIANG Yanjun, et al. Brightness and contrast controllable image enhancement based on histogram specification[J]. Neurocomputing, 2018, 275: 2798-2809. |