



2. 火箭军工程大学导弹工程学院, 陕西 西安 710025
2. The Rocket Force University of Engineering, College of Missile Engineering, Xi'an 710025, China
从遥感影像中提取道路等地物目标具有很大的社会经济价值,可以在灾害勘察、自动导航和地理信息系统建设等方面发挥重要作用。然而经过几十年的研究,道路的自动提取问题尚未完全解决,尤其是道路提取方法的泛化性能还远不能满足应用要求。
传统的方法通常使用人工设计的特征来提取道路区域。这些特征大致可分为局部特征和统计特征。局部特征包括直线、平行的双边缘和交叉口等,而统计特征可以是梯度、颜色、阈值或曲线演化技术中的能量[1]。这些传统方法的主要问题是存在多个参数需要详细给出,这限制了其在大规模应用中的泛化能力[2]。近年来,机器学习方法,特别是深度学习方法在计算机视觉领域取得了很大的成就。通过大量的训练数据和强大的特征表示能力,深度神经网络可以应用于大规模数据集。受益于此,遥感领域的信息处理也获得了长足的进步。将道路提取问题视作语义分割问题进行研究,文献[3]利用深度卷积神经网络(convolutional neural network, CNN)从卫星图像中检测道路和建筑物,并建立了相应的数据集。近年来,类似的基于分块图像的CNN方法用于道路提取屡有报道[4-5]。虽然这些方法大大提高了道路提取的精度,但其采用的滑动窗策略速度慢、效率低,难以满足实际应用需求。全卷积网络(Fully convolutional network, FCN)[6]采用卷积层代替全连接层,能够在保留目标空间信息的同时提取语义文本信息,因此可以实现端到端的语义分割,克服了基于分块图像的CNN方法的低效性。在道路提取方面,有许多基于FCN架构的突出工作[7-8],这些基于FCN的工作的缺点是输出的空间分辨率不够,不能适应细节丰富的遥感图像。编解码网络作为改进的FCN网络,如U-net[9]、Segnet[10]等,可以很好地解决这一问题。编解码器网络可以通过多次向上采样和从低级特征图中收集信息,逐步将分辨率恢复到输入图像的分辨率。基于编解码网络的基本结构,结合道路的特点,文献[11—14]等工作取得了良好的道路提取效果。
然而,深度学习是一种数据驱动技术,其泛化性能受到训练数据多样性的制约。一旦使用的图像与训练集不同,深度学习方法的性能将受到很大影响。在实际应用中,由于城市景观风格、光照、传感器等方面的差异,采集到的新图像往往与训练集有所不同。因此,急需具有强泛化能力的道路自动提取方法,以适应跨数据域应用中较大的数据特征差异。
目前的研究主要采用域适应来解决这个问题,即学习一个模型,以减小源域和目标域之间的差异,使得在源域上训练的模型在目标域上能够很好地工作。尽管域适应研究,尤其是域对抗方法,已经取得了不小的进展,但是这些方法仅适用于特征非常相似的普通图像,而遥感数据十分复杂,不同来源的遥感图像差异巨大,目前的域适应方法用于跨数据域道路提取的效果并不明显。笔者尝试了一些近两年的域对抗方法[15-16],均没有得到有意义的结果,无法实现跨数据域道路提取的任务。
本文提出了一种跨数据域道路提取方法,克服了深度语义分割方法泛化能力不足的缺点,实现了跨数据域的道路提取。该方法主要由两部分组成:道路提取编解码网络和跨数据域图像特征迁移网络。基于含标注的源域数据和道路提取网络,训练能够有效提取源域图像道路的预训练模型。该预训练模型只学习到了源域数据的特征,而目标数据与源域数据的特征差异较大,因此该预训练模型并不能有效处理新的数据。为解决这一问题,本文通过循环生成对抗网络来实现跨数据域图像的特征迁移,使得目标域数据与源域数据共享特征空间。由此,道路提取网络的预训练模型能够有效处理经过特征迁移后的目标域图像,从而实现跨数据域的道路提取任务,而不需要使用目标域图像及其相应的标注信息对道路提取网络重新进行训练。
1 跨数据域道路提取方法 1.1 模型总体结构给定源数据XS,源数据标签YS和目标数据XT(无标注),本文的目的是得到目标数据的标签信息YT。基于源数据XS和其标签YS,可以通过机器学习方法获得XS向YS的映射模型F。但是,由于XT与XS特征分布差异较大,映射模型F并不能有效处理目标数据XT。而且,在实际应用中,受限于时间和人力成本,人们并不能立即获得目标数据XT的标签数据YT,因此也难以做到对F重新训练或者参数精调。
本文通过对目标数据XT进行特征迁移来解决这一问题:学习XT向XS的映射模型G,以及XS向YS的映射模型F,从而预测目标数据XT的标签信息YT。该过程可表示为式(1)
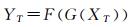 (1)
(1)
式中,XS为某城市包含道路标签的图像数据;XT为另一城市不包含道路标签的图像数据。映射模型G是一个可实现图像转换任务的生成器网络,在训练阶段该模型由XS和XT相互训练完成,在应用阶段则是将XT数据映射向XS特征空间,产生与XS相似的结果数据。映射模型F是一个深度语义分割模型。该模型在训练阶段由源数据XS和YS训练完成,在应用阶段则用于处理转换后的目标域数据,生成相应的道路提取结果YT。所提出的总体方案如图 1所示。

|
| 图 1 基于特征迁移的跨数据域道路提取方案 Fig. 1 A schematic diagram of feature-representation-transfer based approach for cross domain road extraction |
1.2 道路提取模型
道路目标具有丰富的细节信息,因此需要道路提取网络具有较强的细节留存能力。编解码网络结构通过多次上采样和向低层特征图采集信息,可以有效地还原特征图分辨率,达到精细的分割效果。U-net[9]作为经典的编解码网络结构,在遥感影像处理领域被广泛使用。同时,道路又是几乎无限延伸的网络结构,这意味着道路目标具有不同尺度的特征分布。为了兼顾道路提取网络的细节留存能力和多尺度特征整合能力,使用课题前期研究成果,一种结合空洞卷积金字塔池化(atrous spatial pyramid pooling, ASPP)和U-net的网络[17]作为本文的道路提取模型,其基本结构如图 2所示。

|
| 图 2 用于道路提取的ASPP-U-net结构 Fig. 2 The structure of ASPP-U-net for road extraction |
该网络由编码器、ASPP模块和解码器3部分构成。编码器部分是一个典型的CNN网络,可以通过若干次重复的卷积模块来提取输入图片的语义特征。网络的输入为512×512大小的RGB图,输出为原图大小的二值图像,基本结构如图 2所示。本文所采用的编码器网络由4组重复的卷积模块构成,该卷积模块由两层3×3卷积和一次最大池化构成,每层卷积层后都使用了指数线性单元(exponential linear unit, ELU)作为激活函数[18],并添加批规范化层(batch normalization, BN)[19]以抑制梯度消失或梯度爆炸。ASPP模块则可以通过不同尺度的空洞卷积核,同时提取特征图中的多尺度特征,模块细节展示在图 2中。本文采用文献[20]的ASPP方法,该模块由一组平行的多尺度空洞卷积和全局平均池化构成。CNN网络使用池化层来汇合上下文信息和减小计算量,这使得产生的特征图尺寸较小,细节分辨率不足。解码器部分通过反卷积进行上采样,并将处理后的特征图与相应大小的编码器中间特征图组合,以整合高级语义信息和局部细节信息。通过4次这样的操作,解码器将特征图还原至输入图片大小,从而实现高分辨率的语义分割。最后,特征图经过1组1×1卷积和Sigmoid激活函数,得到道路提取的概率表示结果。
作为二元语义分割问题,道路提取一般使用二分类交叉熵损失函数
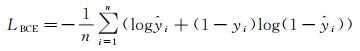 (2)
(2)
式中,n为像素总数;yi∈0, 1为标注中第i像素的值;ŷi∈(0, 1)为对应第i像素的预测输出。
1.3 特征迁移模型 1.3.1 损失函数特征迁移模型的主要任务是学习得到目标域向源域的映射函数,将目标数据特征迁移至源数据的特征空间。本文引入循环生成对抗的思路,同时学习目标域向源域的映射GT→S和源域向目标域的映射GS→T。另外,引入两个用于对抗训练的判别器DS和DT,其中DS用于区分数据是来自于XS还是GT→S(XT),DT用于区分数据是来自于XT还是GS→T(XS)。目标函数包括两部分,用于欺骗判别器、使生成图与原图尽量相似的对抗损失,和用来防止映射GS→T和GT→S相互矛盾的循环一致性损失[21]。
对于映射函数GS→T和其对应的判别器DT,其对抗性损失为
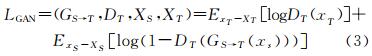 (3)
(3)
式中,生成器GS→T用于生成图像GS→T(XS),使其与目标域图像XT尽量相似;判别器DT用于区分生成样本GS→T(XS)和真实样本XT。判别器的输出为1表示True,即判别器判定图片来自目标域,输出为0表示Fake,即判别器认为图片不是来自于目标域,而是来自源域。在训练中,生成器G要使对抗损失达到最小,作为对抗,判别器D要使得对抗损失最大化。对于式(3),其训练目标为minGmaxD LGAN(GS→T, DT, XS, XT)。同理,对于映射GT→S和判别器DS,其训练目标为minGmaxD LGAN(GT→S, DS, XT, XS)。
单独训练GT→S是不稳定的,为了更好得到目标域向源域的映射,笔者在训练生成器时增加一个约束,即图片经过正向和反向转换之后,还能与原图保持相似性。因而,笔者引入循环一致性损失,同时训练GS→T和GT→S。对于源域XS的每一个样本XS,经过图像的循环映射应使得其回归到原始图片,即满足公式GT→S(GS→T(XS))≈XS。同理,对于目标域XT中的样本XT,应有GS→T(GT→S(XT))≈XT。循环一致性损失函数如式(4)所示
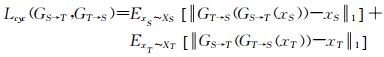 (4)
(4)
综合对抗损失和循环一致性损失,特征迁移训练过程最终使用的损失函数为
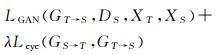 (5)
(5)
式中,λ是控制两类损失权重的参数。循环生成对抗网络训练的目标是求取两个映射函数GS→T*和GT→S*,有
 (6)
(6)
特征迁移网络的结构如图 3所示,由两个生成器网络G和两个判别器网络D组成。特征迁移网络的输入为目标域图片和源域图片,其对应的输出则分别为生成的虚假源域图片和虚假目标域图片。

|
| 图 3 特征迁移网络 Fig. 3 A schematic diagram of feature transfer network |
两个生成器网络GS→T和GT→S均采用1.2节的道路提取网络结构。需要注意的是,由于生成器生成的图片仍然为彩色RGB图片,因此,不同于道路提取网络输出端通道数为1,生成器网络输出端通道数为3。
判别器网络D,本文采用70×70的PatchGAN[22]。该判别器为一个全卷积网络,其网络结构如图 4所示。该判别器只对整张图的70×70大小图块进行判别,再以滑动窗口方式在输入图像上运行该判别器,取平均值作为判别器的最后输出。相较于全图级别的判别,该模型可显著减少需要训练的参数。

|
| 图 4 判别器网络结构 Fig. 4 The structure of the discriminator |
2 试验及结果分析 2.1 数据集
试验选用了双城航拍图像数据集[23]以及Massachusetts Road数据集[3]。双城航拍数据集包含了两个欧洲城市(分别称为A城市和B城市)的航拍图像,每张图像大小为600×600像素,分辨率约1m/像素,各城市覆盖面积约70km2。其中A城市共有4027张图片,B城市共有3177张图片,其对应道路标注采集自开放街道地图(open street map, OSM)。Massachusetts Road数据集采用美国马萨诸塞州(称为Massachusetts)的航拍图片,标注同样来自OSM。每张图像大小为1500×1500像素,分辨率约1m/像素,覆盖面积超过2600km2,包含训练集1108张图片,测试集49张图片,每张图片都有相应的道路标注。两个数据集的图像示例如图 5所示。

|
| 图 5 跨数据域图像和道路标注 Fig. 5 Cross-domain images and road labels |
2.2 结果评价方法
将道路提取视为二元语义分割问题,即属于道路区域的像素归类为正,而非道路区域归类为负。这里,定义TP(True-Positive)代表正确分类的道路像素数目,TN(True-Negative)代表正确分类的非道路像素数目,FP(False-Positive)代表将非道路像素分类为道路像素的数目,FN(False-Negative)代表将真实道路分类为非道路的数目。评估道路提取系统最常用的指标是精度(Precision)和召回率(Recall),在遥感领域,这两个指标也被称为正确率(Correctness)和完整性(Completeness)。精度是所有预测为正的像素中正确分类的道路像素的百分比,如式(7)所示
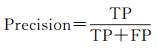 (7)
(7)
召回率是正确分类的道路像素在所有实际道路像素中的百分比,如式(8)所示
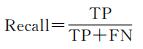 (8)
(8)
F1是精度和召回率的综合体现,其计算方式如式(9)所示
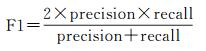 (9)
(9)
由于道路的标签数据一般来源于OSM等矢量数据,因而其宽度信息往往不够准确,因此采用松弛化的评价方式[24]。在试验中,召回率表示在预测道路像素(TP+FP)附近ρ像素范围内的真实道路像素(TP)的百分比,而精度表示在真实道路像素(TP+FN)的ρ像素范围内的预测为道路像素(TP)的百分比。依据一般道路检测的文献[2-3, 12],本文设置ρ=3。
2.3 试验结果和分析 2.3.1 单一数据域的道路提取Massachusetts Road数据集利用测试集的49张照片作为测试图片,双城航拍数据集由于未设置测试集,笔者分别随机挑取A城市、B城市数据500张作为测试集,其余数据用作训练集。本文使用Adam优化器训练道路提取网络,并根据文献[25]配置了优化器参数,即学习率r=0.001,衰减系数β1=0.99,β2=0.9,常数ε=10-8。
用1.2节道路提取网络分别单独训练A城市、B城市和Massachusetts数据,利用测试集对训练好的网络进行测试,得到的量化分析结果如表 1所示,部分测试结果可视化示例如图 6所示。双城航拍数据集的道路目标相对简单,测试得到的综合指标F1均达到了96%以上。而Massachusetts Road数据集中的道路场景复杂,测试得到的F1为83.2%。可以看出,本文所使用的道路提取网络能够有效地提取单一数据域中的道路目标。
| 数据集 | Recall | Precision | F1 |
| A城市 | 96.5 | 96.9 | 96.7 |
| B城市 | 96.3 | 96.9 | 96.6 |
| Massachusetts | 81.1 | 85.6 | 83.2 |

|
| 图 6 单一数据域道路提取可视化结果 Fig. 6 Visualization result of road extraction |
2.3.2 跨数据域图像的特征迁移
根据1.3节的特征迁移网络,使用两个不同城市的数据来训练特征迁移模型。特征迁移模型是一个循环生成对抗网络,由使用两个数据集训练的两个映射模型组成,因而可同时训练源域到目标域以及目标域到源域的这两个生成模型。笔者设计了两组试验来验证特征迁移模型的效果。第1组试验是双城航拍数据集内A城市与B城市之间的特征迁移。第2组试验是双城航拍数据集中的B城市与Massachusetts Road数据集之间相互特征迁移。根据文献[21]的配置,使用Adam优化器来训练循环生成对抗网络,并设置参数为学习率r=0.0002。所得结果的部分示例如图 7所示。

|
| 图 7 跨数据域图像特征迁移结果 Fig. 7 Feature representation transfer results for cross-domain images |
可以看出,特征迁移网络将目标域图像映射向源域图像的特征空间,使得目标域城市图像与源域城市图像相似,局部特征差异变小。因此,在源域数据上训练的预训练模型可以在一定程度上处理特征迁移后的目标域图像。
2.3.3 跨数据域图像的道路提取试验1:对双城数据集中A城市、B城市数据进行交叉验证的道路提取试验。首先,用A城市数据训练道路提取网络,利用B城市数据直接在A城市的道路提取网络上测试,以及将B城市数据向A城市特征迁移后再在A城市网络上测试,比较道路提取的效果;同理,用B城市数据训练道路提取网络,利用A城市数据直接在B城市网络上测试,以及将A城市数据向B城市数据特征迁移后再在B城市网络上测试,比较道路提取的效果。
试验2:对双城数据集中的B城市数据与Massachusetts Road数据集数据进行交叉验证的道路提取实验。首先,将Massachusetts数据作为训练数据,训练道路提取网络,验证其对B城市数据和B城市数据向Massachusetts特征迁移后数据的道路提取能力;同理,将B城市数据作为训练数据,训练道路提取网络,验证其对Massachusetts数据和Massachusetts向B城市特征迁移后数据的道路提取能力。
所得到的量化结果见表 2。表 2中,B→A、A→B、B→M、M→B分别表示B城市向A城市,A城市向B城市,B城市向Massachusetts,Massachusetts向B城市进行特征迁移后的图像作为测试数据。
| 网络的训练数据 | 测试数据 | Recall | Precision | F1 |
| A城市 | B | 0.8 | 38.3 | 1.5 |
| B→A | 63.2 | 88.2 | 73.6 | |
| B城市 | A | 10.8 | 83.7 | 19.1 |
| A→B | 63.6 | 90.2 | 74.6 | |
| Massachusetts | B | 23.5 | 19.8 | 21.5 |
| B→M | 74.9 | 72.2 | 73.5 | |
| B城市 | Massachusetts | 15.8 | 35.3 | 21.2 |
| M→B | 73.6 | 70.1 | 71.8 |
图 8展示了部分的可视化结果实例。图 8中,(a)、(b)列表示A城市训练,B城市测试;(c)、(d)列B城市训练,A城市测试;(e)、(f)列为Massachusetts训练,B城市测试;(g)、(h)列为B城市训练,Massachusetts测试。可以看出,直接将预训练模型应用于跨数据域的图像并不能提取有效的道路信息:不进行特征迁移的试验中F1分别只有1.5%、19.1%、21.5%和21.2%。综合而言,当两个城市间图像差异较大时,传统道路提取模型的泛化性能不足,直接使用预训练模型无法有效地提取新数据中的道路。图 8的前两行可视化结果示例展示了在跨数据域的图像上直接应用预训练模型的道路提取结果,可以看出其召回率偏低的实际效果。

|
| 图 8 基于特征迁移的跨数据域道路提取结果 Fig. 8 Road extraction results of feature-representation-transfer method for cross-domain images |
对目标域数据进行特征迁移,使其映射向源域数据所处的特征空间后,使用源域数据训练的道路提取网络能够有效提取目标域的道路。特征迁移后的4个试验的F1分别达到73.6%、74.6%、73.5%和71.8%,较未迁移数据分别提高了72.1%、55.5%、58.0%、50.6%。图 8的第3、4行展示了特征迁移后道路提取的可视化效果。可以看出,道路提取网络能够准确有效地提取其中的道路网,较未迁移数据的提取结果有十分明显的改善。
两组试验中,试验1采用双城数据集内的两个城市之间进行特征迁移,这两个城市的道路图像之间存在较大的辐射差异,从特征迁移后的图像就可以基本反映出,这种辐射差异在特征迁移后明显缩小。而试验2由于试验数据来自于不同的数据集,数据各方面差异更大。
图 9展示了Massachusetts与B城市之间特征迁移的道路提取中几种复杂情况的道路提取结果。图 9(a)、(b)、(c)、(f)中,含有双车道、立交桥,道路出现较多交叉重叠的情况。图 9(d)为海边的盘山公路,但路与背景极为相似,出现混淆的情况,甚至以人眼也难以分辨。图 9(e)为乡间小路,且也与背景土地光谱特性相似。而图 9(f)中显示了公路与土路不同材质道路的对比。提取结果显示,在经过特征迁移后,本文方法能较好提取这些复杂情况下的道路。这是由于目标域图像在经过特征迁移后,其特征都能较好转化为在原训练集上学习得到的道路特征。

|
| 图 9 复杂情况道路的提取结果 Fig. 9 Extraction results of roads in complex situations |
图 10显示了道路被树木遮挡时的提取结果,图 10(a)、(b)、(d)都能较好提取出完整的道路,但图 10(c)道路被遮挡部分出现了部分中断现象。这是由于被遮挡道路在源域中也较难识别,进行迁移后在目标域就更难被识别出来,可以考虑通过后处理方法改善效果。

|
| 图 10 被遮挡道路的提取效果 Fig. 10 Extraction results of obscured road |
将目标域图像迁移至源域后,必然要损失部分道路信息,且本文的迁移模型在迁移过程中没有特定保留道路的特征。这是导致笔者将目标域图像迁移至源域后,得到的道路提取结果比在有标签情况下直接训练网络得到的道路提取结果差不少的最主要原因。尤其是当道路密集、背景复杂且有其他地物与道路特征相似时,表现得尤为明显,有时会出现提取的道路杂乱无章、无法有效连成道路网的情况,如图 11所示。

|
| 图 11 密集道路的提取效果 Fig. 11 Extraction results of dense road |
3 结论
针对道路提取的语义分割网络泛化能力差,难以跨数据域应用的实际问题,本文通过特征迁移的思路将目标域图像映射入源域特征空间,使其能够被源域上预训练的道路提取网络有效处理,从而实现准确、有效的跨数据域道路提取。首先,通过源域数据训练道路提取的预训练模型。然后,通过循环生成对抗网络将目标域映射图像向源域图像特征空间,使两者接近。基于道路提取的预训练模型和特征迁移后的目标域图像,即可实现准确有效地跨数据域道路提取。通过两个交叉验证试验,证明了本文方法可以大幅改善跨数据域图像的道路提取效果,其综合指标F1提升了50%以上。
本文方法只需训练由目标域向源域的特征迁移模型,即可直接使用由源域训练的道路提取网络处理目标域数据。由于不需要对目标域城市进行道路标注,也不需要改变已训练完成的道路提取网络模型,本文方法可以及时有效地从新的数据中提取道路,且能够基本保持原网络的道路提取能力,改善了道路提取的泛化性能。
本文方法可能存在的不足是特征迁移过程中的不可控性。由于特征迁移并非指向道路目标的特定特征,而是基于循环一致性的一般性特征,因此在迁移过程中可能导致道路有效特征的损耗甚至丢失。在下一步研究中,笔者将基于道路特征约束图像特征迁移过程,使得其量化、可控,从而抑制上述问题的发生。此外,本文限于同分辨率的航拍图像之间的跨数据域道路提取,对于跨分辨率、跨模态的道路提取也有待进一步研究。
| [1] |
吴亮, 胡云安. 遥感图像自动道路提取方法综述[J]. 自动化学报, 2010, 36(7): 912-922. WU Liang, HU Yun'an. A survey of automatic road extraction from remote sensing images[J]. Acta Automatica Sinica, 2010, 36(7): 912-922. |
| [2] |
MNIH V, HINTON G E. Learning to detect roads in high-resolution aerial images[C]//Proceedings of European Conference on Computer Vision: Part VI, September 5-11, 2010, Heraklion, Crete, Greece. Heraklion: Springer, 210-223. https://www.researchgate.net/publication/221304427_Learning_to_Detect_Roads_in_High-Resolution_Aerial_Images
|
| [3] |
MNIH V. Machine learning for aerial image labeling[D]. Toronto: University of Toronto, 2013. https://tspace.library.utoronto.ca/handle/1807/35911
|
| [4] |
WANG Jun, SONG Jingwei, CHEN Mingquan, et al. Road network extraction: a neural-dynamic framework based on deep learning and a finite state machine[J]. International Journal of Remote Sensing, 2015, 36(12): 3144-3169. DOI:10.1080/01431161.2015.1054049 |
| [5] |
ALSHEHHI R, MARPU P R, WOON W L, et al. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 130: 139-149. DOI:10.1016/j.isprsjprs.2017.05.002 |
| [6] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, June 7-12, 2015, Boston, MA. Boston: IEEE, 2015: 3431-3440. https://ieeexplore.ieee.org/document/7298965
|
| [7] |
ZHONG Zilong, LI J, CUI Weihong, et al. Fully convolutional networks for building and road extraction: preliminary results[C]//Proceedings of 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), July 10-15, 2016, Beijing, China. Beijing: IEEE, 2016: 1591-1594.
|
| [8] |
WEI Yanan, WANG Zulin, XU Mai. Road structure refined CNN for road extraction in aerial image[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(5): 709-713. DOI:10.1109/LGRS.2017.2672734 |
| [9] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich: Springer International Publishing, 2015: 234-241. https://www.oalib.com/paper/4075466
|
| [10] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. DOI:10.1109/TPAMI.2016.2644615 |
| [11] |
贺浩, 王仕成, 杨东方, 等. 基于Encoder-Decoder网络的遥感影像道路提取方法[J]. 测绘学报, 2019, 48(3): 330-338. HE Hao, WANG Shicheng, YANG Dongfang, et al. A road extraction method for remote sensing image based on Encoder-Decoder network[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(3): 330-338. DOI:10.11947/j.AGCS.2019.20180005 |
| [12] |
PANBOONYUEN T, JITKAJORNWANICH K, LAWAWIROJWONG S, et al. Road segmentation of remotely-sensed images using deep convolutional neural networks with landscape metrics and conditional random fields[J]. Remote Sensing, 2017, 9(7): 9070680. |
| [13] |
SUN Tao, CHEN Zehui, YANG Wenxiang, et al. Stacked U-nets with multi-output for road extraction[C]//Proceedings of 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), June 18-22, 2018, Salt Lake City, UT. Salt Lake City: IEEE Computer Society, 2018. https://www.researchgate.net/publication/329750281_Stacked_U-Nets_with_Multi-output_for_Road_Extraction
|
| [14] |
HE H, WANG S C, YANG D F, et al. Light encoder-decoder network for road extraction of remote sensing images[J]. Journal of Applied Remote Sensing, 2019, 13(3): 034510. |
| [15] |
LI Yunsheng, YUAN Lu, VASCONCELOS N. Bidirectional learning for domain adaptation of semantic segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 1-8, 2019, Long Beach, USA. Long Beach: IEEE, 1-10. https://www.researchgate.net/publication/332630377_Bidirectional_Learning_for_Domain_Adaptation_of_Semantic_Segmentation
|
| [16] |
TSAI Y H, HUNG W C, SCHULTER S, et al. Learning to adapt structured output space for semantic segmentation[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 18-23, 2018, Salt Lake City, UT, USA. Salt Lake City: IEEE, 2018. https://www.researchgate.net/publication/323471130_Learning_to_Adapt_Structured_Output_Space_for_Semantic_Segmentation
|
| [17] |
HE Hao, YANG Dongfang, WANG Shicheng, et al. Road extraction by using atrous spatial pyramid pooling integrated encoder-decoder network and structural similarity loss[J]. Remote Sensing, 2019, 11(9): 1015. DOI:10.3390/rs11091015 |
| [18] |
CLEVERT D A, UNTERTHINER T, HOCHREITER S. Fast and accurate deep network learning by exponential linear units (ELUs)[C]//Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: [s.n.], 2016. https://www.researchgate.net/publication/284579051_Fast_and_Accurate_Deep_Network_Learning_by_Exponential_Linear_Units_ELUs
|
| [19] |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]// Proceedings of the 32nd International Conference on Machine Learning, July 6-11, 2015, Lille, France. Lille: JMLR, 2015: 448-456. https://arxiv.org/abs/1502.03167
|
| [20] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation. arXiv: 1706.05587, 2017.
|
| [21] |
ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of IEEE International Conference on Computer Vision, October 22-29, 2017, Venice, Italy. Venice: IEEE, 2017: 2242-2251.
|
| [22] |
ISOLA P, ZHU Junyan, ZHOU Tinghui, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, July 21-26, 2017, Honolulu, USA. Honolulu: IEEE, 2017: 5967-5976. https://www.researchgate.net/publication/310610633_Image-to-Image_Translation_with_Conditional_Adversarial_Networks
|
| [23] |
COSTEA D, LEORDEANU M. Aerial image geolocalization from recognition and matching of roads and intersections[C]//Proceedings of British Machine Vision Conference, September 19-22, 2016, York, UK. York: BMVA, 1-12. https://www.researchgate.net/publication/317192627_Aerial_image_geolocalization_from_recognition_and_matching_of_roads_and_intersections
|
| [24] |
WIEDEMANN C, HEIPKE C, MAYER H, et al. Empirical evaluation of automatically extracted road axes[C]//Proceedings of the 9th Australasian Remote Sensing Photogrammetry Conference. Sydney: The University of New South Wales, 1998: 172-187.
|
| [25] |
KINGMA D P, BA J. Adam: a method for stochastic optimization[C]//Proceedings of the 3rd International Conference on Learning Representations. CA, San Diego: [s.n.], 2015. https://arxiv.org/abs/1412.6980
|
| [26] |
GONG Jianya. Photogrammetry and deep learning[J]. Journal of Geodesy and Geoinformation Science, 2018, 1(1): 1-15. DOI:10.11947/j.JGGS.2018.0101 |