



高精度定位是自动驾驶的核心技术[1]。传统的GNSS(Global Navigation Satellite System)定位技术易受树木、建筑和隧道等障碍物遮蔽的影响。这时,同时定位与地图构建(simultaneous location and mapping,SLAM)成为自动驾驶技术的定位方案之一。视觉SLAM不仅成本低、易维护,还可以获得丰富的色彩、纹理信息,逐渐成为该领域的重要补充[2-3]。
PTAM[4]是其中第1个采用并行方式实现跟踪和建图的SLAM方案,它通过非线性的BA(bundle adjustment)优化,能够实时获得图像关键帧的轨迹和姿态。ORB-SLAM[5-7]在此基础上新增了回环检测线程,并利用改进的图像特征,实现了基于单、双目相机和RGB-D相机的定位和跟踪,它也是当前基于特征点法中最成熟的开源视觉SLAM方案。除此之外还有基于像素灰度变化的直接法[8]和半直接法[9]等方案。
这些方法在定位过程中普遍存在“静态世界”的假设,即假设像素或特征点的空间位置是不变的,而造成图像灰度和视角变化的唯一原因是相机的位姿变化。然而自动驾驶场景是动态的,行人、汽车等移动物体会影响视觉特征关联的准确性。虽然这种影响可以通过RANSAC[10]或者核函数[11]过滤,但这是一种被动机制,并没有从根本上改变这一假设。因此,如何在动态场景中寻找更稳健的特征是视觉定位技术应用于自动驾驶的关键之一。
解决上述问题有两种思路[12]。一种是把动态目标的运动囊括进SLAM的估计过程,例如采用粒子滤波方法克服错误估计的影响[13],但是粒子的数量选择和维持实时计算较困难。另一种更普遍,是让SLAM方法结合深度学习技术[14-15],分割图像中的动态区域,从而把它转换为静态环境的SLAM问题。例如,DS-SLAM[16]算法使用SegNet[17]识别环境中的物体,并将人体去除;DynaSLAM[18]算法采用Mask-RCNN[19]检测动态物体,过滤目标的同时补全被遮挡部分;MaskFusion[20]实现了一种实例级别的语义分割,以更加完全地过滤动态特征。DetectionFusion(arXiv: 1707.09127, 2019.)在实例分割的基础上识别了未知运动目标,从而实现更为完整的动态过滤。还有学者结合道路结构化特征,设计了带有改进金字塔池化模块的语义分割神经网络[21]。这些方法通过设计精巧的神经网络完成动态环境中的目标识别,但它们依赖于动态目标的分类规则,忽略了物体可能有“动态”和“静态”双重属性的事实。例如行驶的汽车是动态的,但是停靠的汽车是静态的;并且静态的物体仍能为视觉SLAM过程提供丰富的特征。因此有学者提出Detect-SLAM的方法[22],考虑了物体上特征点的运动特性,在识别出语义目标的基础上为其分配运动概率,每一帧位姿在估计时都更新概率值并去除高于阈值的运动点,但这方面研究较少。
综上所述,目前视觉定位SLAM技术存在受动态目标影响大,且在复杂环境中不易准确分辨动态目标。为此,笔者提出了基于语素关联的方法,并且基于经典的ORB-SLAM方法建立了动态环境中的视觉定位优化流程。
1 语素关联约束的定位优化方法传统视觉定位的原理是:通过帧间匹配计算相同关键点之间的像素差异,从而估计产生这种差异的位置和姿态(简称位姿)变化,同时辅以闭环优化以减少误差,其流程如图 1(a)所示。然而提取的特征点可能位于动态目标上,但基于“静态世界”假设,这些特征点不利于位姿估计,具体说明如图 2所示。因此,本文提出的视觉定位优化方法在传统流程基础上,通过语义关联识别环境中的动态语义要素(简称动态语素),并且形成特征掩膜用于“特征匹配”过程,从而帮助过滤动态特征点以获得“稳定的特征”,进而优化后续位姿估计,如图 1(b)所示。

|
| 图 1 基于语义要素关联优化的动态环境定位流程 Fig. 1 Flowcharts of location optimization in dynamic scenes by semantic association |
1.1 动态环境的影响
一般SLAM算法认为环境中的地标点(图像中关键点所对应的物体)是固定的,空间中同一个地标在前后两帧图像中的像素差异,仅源于相机的位置和姿态改变。因此,当相机内参已知时,它的位姿和地标点之间存在如式(1)的关系
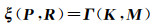 (1)
(1)
式中,K是用像素坐标表达的关键点;M是相机的内参数;ξ为相机的位姿,是一个与位置P和旋转R有关的矩阵;Γ(·)是一个抽象函数,具体的表达可参考文献[23-24]。
动态目标上的关键点会影响视觉定位结果,图 2以二维空间中的方向观测为例介绍了该过程。在t-1时刻,相机通过观测s和kt-1两种关键点确定了初始位置pt-1。t时刻相机和关键点k均发了移动,但是传统算法认为关键点位置仍然位于kt-1,即产生了平行于真实观测(pt, kt)的估计观测(p′t, kt-1),它与来自对静态关键点s的观测(pt, s)相交于估计位置p′t。同理,t+1时刻的估计位置为p′t+1,由此得到的估计轨迹与真实轨迹存在偏差。针对这一现象,现有的视觉定位方法普遍将可能运动的目标全部剔除掉,但这种处理忽略了目标具有“动”“静”双重属性的事实—汽车可能是运动的也可能是静止的,静止的汽车反而能够为视觉定位提供特征参考;对此不加考虑可能会剔除具有高响应值的特征点,反而削弱定位效果。因此准确识别环境中的动态语素并消除其影响,这对于视觉定位算法尤其重要。

|
| 图 2 场景的动态物体对于视觉定位的影响 Fig. 2 Negative effects of moving objects in dynamic scenes |
1.2 语义实体识别
获得动态语素的第1步是识别出视觉图像中的语义实体。假设环境中的语义实体G由位置L、大小S和类别M表达,即G={L, S, M},根据相机的投影模型,图像中的像素点(x, y)和g∈G存在如下的映射关系
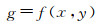 (2)
(2)
语义实体识别就是确定映射f(·)的过程。本文利用了以YOLO(arXiv: 2004.10934, 2020)为代表的目标识别算法和以SegNet[17]为代表的语义分割算法。在YOLO算法中,M为识别出的目标类别,L和S分别是目标最小外包矩形(bounding box)的边界和大小。在语义分割方法中,M为分割出的目标类别,L和S分别是图像中的属于指定类别的像素坐标和数量。
1.3 语义要素抽象和关联语义要素约束是通过语素抽象和关联实现的,其形式是动态特征掩膜。本文中,语素抽象就是提取语义实体识别出的元素,例如图 1(b)中列出的人、道路、汽车、自行车等元素。语素关联就是通过建立不同元素之间的关系,判断关联后的语义是动态或静态。例如“汽车”和“道路”关联的结果是“行驶的车”这种动态语素,而“汽车”和“车位”关联的结果是“停放的车”这种静态语素。语素关联能体现“汽车”具有“动”“静”双重属性的事实。
在视觉图像中,关联性通过像素区域的位置关系和面积大小计算得到。设有两个语义实体g1, g2∈G,它们在图像中的关系可以按照式(3)计算
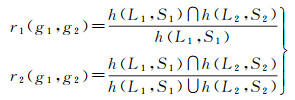 (3)
(3)
式中,h(·)表示计算实体在图像上的像素区域和面积;∩表示计算重叠像素区域的面积;∪表示计算合并后像素区域的面积;L表示像素位置;S表示像素大小;r1、r2为两种指标计算方法;r1是相交区域面积比其中一种实体区域面积的指标,它侧重体现动态部分与其中一种语义实体的关系;r2是相交区域面积比两种实体合并后区域面积的指标,它侧重体现动态部分与两种实体之间的关系。当关联的两者仅有一个具有动态性时,例如“人和道路”中“人”具有动态性,更加适用于r1指标,此时g1代表“人”;而当关联的两者都具有动态性的时,例如“人和自行车”,更加适用于r2指标。
2 试验与分析 2.1 试验环境和数据采集为了验证提出的方法,本文基于自主研发的移动视觉机器人平台在校园道路场景开展了试验。该平台为小型轮式移动机器人(图 3(a)),搭载了双目RGB相机,相片分辨率为640×400像素,采样频率30 Hz。

|
| 图 3 试验数据采集平台和过程 Fig. 3 Equipment and data collection |
如图 3(b)所示,试验行驶路线全程约2.4 km,途经食堂、教学楼和校门,全程48 min,共得到约8万对图像;其中,除校门前的路段为机动车道路外,其他路段均为非机动车道路。如图 3(c)所示,SOI-1至SOI-6是典型动态场景的图像兴趣序列(sequence of interest)。由于“汽车”“自行车”“行人”是该环境中影响视觉定位的主要语义实体,因此本文利用YOLO目标识别方法识别这3种目标,利用SegNet语义分割方法分割与之相关的“道路”“停车位”。
表 1以6个兴趣序列为例,不分实例地统计了每段中各个实体出现的总频次。从表 1中可以看出,SOI-1和SOI-2所对应的食堂、教学楼附近人、自行车较密集,机动车道路段中的SOI-4序列中有汽车驶过。环境中的停车区让汽车或自行车具备了“动”“静”双重属性,这给动态要素的准确识别带来困难。
| 序列 | 时长/s | 人数/人 | 自行车数/辆 | 汽车数/辆 |
| SOI-1 | 4.6 | 342 | 102 | 0 |
| SOI-2 | 6.9 | 710 | 42 | 0 |
| SOI-3 | 19.9 | 1052 | 29 | 1 |
| SOI-4 | 4.0 | 4 | 0 | 513 |
| SOI-5 | 14.6 | 847 | 0 | 0 |
| SOI-6 | 12.2 | 473 | 52 | 0 |
2.2 语素关联和定位约束
根据场景的语义特点,参考图 1(b)拟提取3种动态语素,其含义见表 2。同时为了确定动态语素关联的阈值,从兴趣序列中选择样本,根据式(3)计算了3种动态语素的r指标的分布,并把它们从大到小排序,结果如图 4所示。其中,根据指标特性在动态语素1和动态语素3上统计r1指标,而动态语素2上统计r2指标。需要说明的是,由于环境中车辆少、机动车路段集中,动态语素3的样本不够,因此相似场景下计算得到的r值较为接近。
| 名称 | 关联对象 | 关联含义 | r阈值 |
| 动态语素1 | 人/道路 | 行人目标 | r1∈[0.155 3, 1) |
| 动态语素2 | 人/自行车 | 骑行目标 | r2∈[0.269 7, 1) |
| 动态语素3 | 车/道路 | 车行目标 | r1∈[0.045 2, 1) |

|
| 图 4 r指标统计结果 Fig. 4 Statistics for r value |
考虑到阈值应满足筛选出大部分动态语素的要求,试验中以成功筛选出90%样本为目标确定了r的阈值,得到取值区间见表 4。对于本试验的图像序列,如果计算出的r落入当前指定区间,则认为该语素对应的像素区域属于动态语素区域,则构建特征掩膜以过滤相应特征点;反之则不构建掩膜。需要说明的是,在以样本估计总体阈值的过程中,本文方法基于两个前提:不考虑静态语素的关联性和动态语素关联性越强r值越大。
| 序列 | 最大距离差/m | 平均距离差/m | 语素关联计算耗时/s |
| SOI-1 | 1.003 | 0.666 | 5.2 |
| SOI-2 | 2.174 | 1.218 | 4.5 |
| SOI-3 | 2.463 | 1.454 | 4.2 |
| SOI-4 | 0.429 | 0.207 | 0.1 |
| SOI-5 | 2.118 | 0.605 | 0.1 |
| SOI-6 | 0.129 | 0.055 | 3.8 |
| 序列 | 均方根误差 | 偏差均值 | 偏差中位数 | 偏差标准差 | 最小偏差 | 最大偏差 |
| 原始轨迹 | 20.426 | 19.252 | 18.375 | 6.825 | 4.967 | 44.544 |
| 对比方法 | 15.359 | 14.506 | 14.042 | 5.046 | 2.790 | 29.332 |
| 本文方法 | 12.691 | 12.148 | 11.656 | 3.671 | 3.576 | 24.572 |
动态语素关联通过特征掩膜参与定位过程,如图 5所示。在图 5(a)中,通过语义实体识别可以得到“自行车”和“人”两种语义实体,由最小外包矩形标注;通过语义分割方法可以得到“道路”实体,由多边形标注。根据人与自行车的关联性可以判断出图像存在“骑行目标”语素,如图 5(b)中红色区域;根据人与道路的交集可以判断图像中存在“行人”语素,如图 5(b)中蓝色区域。它们在视觉定位中都属于动态语素,因此根据其范围形成特征掩膜,如图 5(c)所示。在SOI-4中,通过语义实体识别可以得到“汽车”“停车位”“道路”3种语义实体。通过“汽车”与“停车位”的交集判断出“停放的汽车”语素,通过“汽车”与“道路”的交集判断出“车行目标”语素,如图 5(e)中黄色区域。后者在视觉定位过程中属于动态语素,因此根据其范围形成特征掩膜,如图 5(f)所示。

|
| 图 5 语素关联优化过程 Fig. 5 Semantic elements association |
视觉定位过程中,高响应值的特征点优先参与位姿解算过程。然而它们中有一部分会落在动态语素目标上,这些点并不利于位姿计算。语素关联约束过程会过滤掉动态语素上的关键点,如图 5(b)、(e)所示,绿色的关键点被保留并参与位姿估计,而红色的关键点被特征掩膜过滤。
2.3 试验结果和分析 2.3.1 局部优化结果分析本文以SOI-1至SOI-6 6个场景的兴趣序列为例,详细说明在局部场景中语素关联优化对视觉定位结果的提升。图 6展示了序列中代表性的图像,标注了主要动态对象的移动方向和优化前后的定位轨迹。其中,本文方法指经过语素关联约束得到的定位轨迹,对比方法指过滤所有人、车、自行车目标后的定位轨迹,原始轨迹指不过滤任何目标的定位轨迹。机器人的实际运动状态为向前行驶(SOI-1、SOI-2和SOI-4)和转弯(SOI-3、SOI-5和SOI-6)两种状态。

|
| 图 6 动态场景和语素关联优化前后视觉定位轨迹对比 Fig. 6 Performance of semantic elements filtering in dynamic scenes |
从试验对比中可看出,动态目标通过特征点影响视觉定位结果,识别和消除其影响可以获得更稳定的视觉定位结果。在SOI-1中,有运动的自行车和行人。其中一辆自行车从右后方驶入视野,为了避让行人而左拐进入步行道。自行车相对于机器人移动速度快,刚开始占据相机大部分视野,随后逐渐消失。由于车身尾部颜色对比明显,部分关键点落在自行车上。另一辆自行车由远处迎面驶来,但目标较小,其上的关键点不多。视野中还有很多停放在路边的自行车,它们提供了一些可用于定位的关键点。从轨迹对比结果可以看出,虽然机器人实际保持向前行驶,但是原始轨迹表现为先后退、再右转。造成这种现象的原因是:相对于机器人,主要运动自行车上的关键点发生了向左前方的快速移动,按照视觉定位算法“静态世界”的假设,如果认为关键点是静态的,那么相机就应该发生向右后方向的移动。相对比地,无论是本文方法还是对比方法得到的轨迹都一直保持向前,比较符合机器人的行进路线。
这种情况在其他场景序列中也表现明显。SOI-2序列中有行人从右向左横穿视野,其书包和衣服纹理丰富,提供了大量视觉关键点。但是在运动目标的影响下,原始轨迹发生了向右的移动;经过特征掩膜过滤后,优化后定位轨迹不再存在这种情况。SOI-3序列中机器人缓慢向左拐弯,有人骑车从右向左穿过视野,经过优化后的轨迹更加平滑。SOI-5序列中采集车缓慢左拐弯,有人在视野中先向右前方移动,然后转向左前方;由于行人运动的影响,算法认为机器人提前开始左转,而在优化后的轨迹中,机器人先保持向前行驶一段距离后再左转。
然而虽然本文方法和对比方法都能减少运动目标的影响,但是本文提出的语素关联方法能够在定位时保留更多具备高响应值的特征点。例如SOI-4序列中只有1辆汽车从视野中驶过,由于其上特征点少而且仅4 s就驶出视野,原始轨迹与本文方法轨迹差别不大。但由于对比方法丢失了一些静止汽车上的高响应特征,其定位轨迹在尺度上与前两者具有明显差别。需要特殊说明的是,如果动态语素区域的关键点少,那么三者的定位轨迹区别也不大,例如SOI-6序列中特征点集中于植被和树枝,而不在骑行人身上。
表 3记录了上述动态场景序列的时长,并且从本文方法和原始轨迹中采样了受影响的定位点,计算相应两个采样点的差距。由表 3可以看出,采样点的最大差距在0.1~2.5 m之间;最大平均差距出现在SOI-3序列中,为1.454 m,该序列中机器人正在转弯,并且有行驶快的自行车横向穿过。最小平均差距在SOI-6中,该场景的关键点集中在非动态区域,优化作用不大。
分析表明,语素关联约束对动态场景的视觉定位结果有一定的提升作用,尤其在相机转弯时或者动态目标在视野中产生横向移动时优化效果明显。然而,由于动态目标是通过关键点影响视觉定位的,如果运动目标本身视觉特征不明显、出现时间不长或者运动幅度不大,优化前后定位轨迹没有明显差异。
2.3.2 整体优化结果和分析因激光传感器具有精度高、不易受动态环境影响的优势,定位结果更稳定可靠[25],故以激光雷达数据计算得到的轨迹为真值,采用了EVO(https://github.com/Michae(Grupp/evo))轨迹评价工具,对比了原始轨迹(不处理动态目标)、对比方法(剔除所有“人”“车”目标)和本文方法的二维轨迹结果,结果如图 7所示。图 7(a)说明视觉轨迹与真值之间存在仿射变换差异,X轴是初始状态的左右方向,Y轴是初始状态的前后方向。经过旋转、平移和缩放变换后,本文方法更加贴近真值。图 7(b)的“小提琴图”展示了绝对位姿误差(absolute pose error, APE)中位移分量的分布,本文方法平均误差更小,而且分布更加集中,这说明轨迹差更加稳定。表 4为视觉优化前后轨迹与真值误差对比。

|
| 图 7 语素优化前后视觉定位整体轨迹对比 Fig. 7 Full trajectory before and after semantic elements filtering |
由表 4和图 7(b)的误差柱状图可以看出,本文方法定位轨迹在均方根误差、偏差均值、偏差中位数、偏差标准差和最大偏差多个指标都小于对比方法,远小于原始轨迹。相对于原始轨迹和对比方法,均方根误差分别降低了38%和17%。
2.3.3 精度和效率分析以6段兴趣序列为基础,观察和统计了语素关联结果的正确性,得到预测与观察结果的混淆矩阵见表 5。同时选择了精确率P、召回率R和综合指标F1来反映方法的精度,计算过程如式(4)-式(6)所示
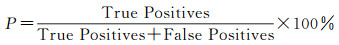 (4)
(4)
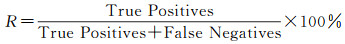 (5)
(5)
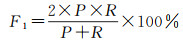 (6)
(6)
| 观察结束 | 预测结果 | |
| Positive | Negative | |
| true | 3134 | 584 |
| false | 321 | 128 |
经计算,P约为91%,R约84%,平均精度F1约为87%。
为了评价计算效率,以6个兴趣序列为例,统计了其中语素关联步骤(计算和判断r值)的耗时,由表 3可以看出,该步骤的效率与场景中语义的复杂性有关,序列要判断的动态语素种类越多耗时越高。同时对比序列的时长可以看出,语素关联步骤能够与数据采集同步。但是,语素关联计算的前提是语义实体识别,即目标识别和语义分割过程。在单核2.2 GHz CPU的计算平台上进行,处理每张图片的耗时约0.8 s。因此,由于语义实体识别耗时过大,当前方法仍不能达到实时计算的效果。
3 结论和展望本文提出的动态环境视觉定位优化方法,能够解决现有的特征点法受动态目标影响大、视觉定位结果准确度下降的问题。在保留更多高响应值特征点的基础上,能够较好地抑制由于动态实体横向穿越相机视场而导致的定位误差。
视觉定位是自动驾驶场景定位方案的重要补充,但环境中的动态目标不是影响其的唯一因素,图像匹配误差、相机标定误差和深度估计误差都会影响视觉定位结果[26]。另外,由于语义识别耗时,当前方法无法达到实时优化效果,并且受平台限制本文未能讨论其在城市级道路的定位提升能力。在更复杂的无人驾驶场景中,如何更好地优化视觉定位结果仍有待深入研究。
致谢: 感谢武汉大学郭迟教授团队在结果分析的对比方法中提供帮助。
| [1] |
PADEN B, ČÁP M, YONG S Z, et al. A survey of motion planning and control techniques for self-driving urban vehicles[J]. IEEE Transactions on Intelligent Vehicles, 2016, 1(1): 33-55. DOI:10.1109/TIV.2016.2578706 |
| [2] |
张一, 姜挺, 江刚武, 等. 特征法视觉SLAM逆深度滤波的三维重建[J]. 测绘学报, 2019, 48(6): 708-717. ZHANG Yi, JIANG Ting, JIANG Gangwu, et al. 3D reconstruction with inverse depth filter of feature-based visual SLAM[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(6): 708-717. DOI:10.11947/j.AGCS.2019.20180421 |
| [3] |
王晨捷, 罗斌, 李成源, 等. 无人机视觉SLAM协同建图与导航[J]. 测绘学报, 2020, 49(6): 767-776. WANG Chenjie, LUO Bin, LI Chengyuan, et al. The collaborative mapping and navigation based on visual SLAM in UAV platform[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(6): 767-776. DOI:10.11947/j.AGCS.2020.20190145 |
| [4] |
KLEIN G, MURRAY D. Parallel tracking and mapping for small AR workspaces[C]//Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality. Nara, Japan: IEEE, 2007: 225-234.
|
| [5] |
MUR-ARTAL R, MONTIEL J M M, TARDÓS J D. ORB-SLAM: a versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics, 2015, 31(5): 1147-1163. DOI:10.1109/TRO.2015.2463671 |
| [6] |
MUR-ARTALR, TARDÓS J D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262. DOI:10.1109/TRO.2017.2705103 |
| [7] |
CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al. ORB-SLAM3: an accurate open-source library for visual, visual-inertial, and multimap SLAM[J]. IEEE Transactions on Robotics, 2021, 37(1): 1-17. DOI:10.1109/TRO.2020.3005547 |
| [8] |
NEWCOMBE R A, LOVEGROVE S J, DAVISON A J. DTAM: Dense tracking and mapping in real-time[C]//Proceedings of 2011 International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011: 2320-2327.
|
| [9] |
FORSTER C, PIZZOLI M, SCARAMUZZA D. SVO: Fast semi-direct monocular visual odometry[C]//Proceedings of 2014 IEEE International Conference on Robotics and Automation (ICRA). Hong Kong, China: IEEE, 2014: 15-22.
|
| [10] |
BAHRAINI M S, BOZORG M, RAD A B. SLAM in dynamic environments via ML-RANSAC[J]. Mechatronics, 2018, 49: 105-118. DOI:10.1016/j.mechatronics.2017.12.002 |
| [11] |
STRECKE M, STUCKLER J. EM-fusion: Dynamic object-level SLAM with probabilistic data association[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019: 5864-5873.
|
| [12] |
弋英民, 刘丁. 动态环境下基于路径规划的机器人同步定位与地图构建[J]. 机器人, 2010, 32(1): 83-90. YI Yingmin, LIU Ding. Robot simultaneous localization and mapping based on path planning in dynamic environments[J]. Robot, 2010, 32(1): 83-90. |
| [13] |
ÖZKAN E, WAHLSTRÖM N, GODSILL S J. Rao-Blackwellised particle filter for star-convex extended target tracking models[C]//Proceedings of the 19th International Conference on Information Fusion (FUSION). Heidelberg, Germany: IEEE, 2016: 1193-1199.
|
| [14] |
龚健雅, 季顺平. 摄影测量与深度学习[J]. 测绘学报, 2018, 47(6): 693-704. GONG Jianya, JI Shunping. Photogrammetry and deep learning[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 693-704. DOI:10.11947/j.AGCS.2018.20170640 |
| [15] |
邸凯昌, 万文辉, 赵红颖, 等. 视觉SLAM技术的进展与应用[J]. 测绘学报, 2018, 47(6): 770-779. DI Kaichang, WAN Wenhui, ZHAO Hongying, et al. Progress and applications of visual SLAM[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 770-779. DOI:10.11947/j.AGCS.2018.20170652 |
| [16] |
YU C, LIU Z X, LIU X J, et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]//Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Madrid, Spain: IEEE, 2018: 1168-1174.
|
| [17] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. DOI:10.1109/TPAMI.2016.2644615 |
| [18] |
BESCOS B, FÁCIL J M, CIVERA J, et al. DynaSLAM: tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 4076-4083. DOI:10.1109/LRA.2018.2860039 |
| [19] |
HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017: 2980-2988.
|
| [20] |
RUNZ M, BUFFIER M, AGAPITO L. MaskFusion: real-time recognition, tracking and reconstruction of multiple moving objects[C]//Proceedings of 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). Munich, Germany: IEEE, 2018: 10-20.
|
| [21] |
李琳辉, 张溪桐, 连静, 等. 结合道路结构化特征的语义SLAM算法[J]. 哈尔滨工业大学学报, 2021, 53(2): 175-183. LI Linhui, ZHANG Xitong, LIAN Jing, et al. Semantic SLAM algorithm combined with road structured features[J]. Journal of Harbin Institute of Technology, 2021, 53(2): 175-183. |
| [22] |
ZHONG F W, WANG S, ZHANG Z Q, et al. Detect-SLAM: Making object detection and SLAM mutually beneficial[C]//Proceedings of 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, NV, USA: IEEE, 2018: 1001-1010.
|
| [23] |
KONOLIGE K, AGRAWAL M. FrameSLAM: From bundle adjustment to real-time visual mapping[J]. IEEE Transactions on Robotics, 2008, 24(5): 1066-1077. DOI:10.1109/TRO.2008.2004832 |
| [24] |
WESTOBY M J, BRASINGTON J, GLASSER N F, et al. "Structure-from-Motion" photogrammetry: a low-cost, effective tool for geoscience applications[J]. Geomorphology, 2012, 179: 300-314. DOI:10.1016/j.geomorph.2012.08.021 |
| [25] |
黄瑞, 张轶. 高适应性激光雷达SLAM[J]. 电子科技大学学报, 2021, 50(1): 52-58. HUANG Rui, ZHANG Yi. High adaptive LiDAR simultaneous localization and mapping[J]. Journal of University of Electronic Science and Technology of China, 2021, 50(1): 52-58. |
| [26] |
HULETSKI A, KARTASHOV D, KRINKIN K. Evaluation of the modern visual SLAM methods[C]//Proceedings of 2015 Artificial Intelligence and Natural Language and Information Extraction, Social Media and Web Search FRUCT Conference (AINL-ISMW FRUCT). St. Petersburg, Russia: IEEE, 2015: 19-25.
|