



2. 根特大学地理学院, 比利时 根特 9000
2. Department of Geography, Ghent University, Ghent 9000, Belgium
对环境的感知和理解是智能驾驶领域的一个重大挑战。视觉是驾驶过程中驾驶员感知和理解道路场景信息的主要途径。在驾驶过程中,驾驶员会选择性地关注场景中感兴趣的信息,而忽略不重要的信息,这种机制称为驾驶过程的视觉选择性注意机制,选择性注意的区域称为视觉显著区域。在智能驾驶系统开发中,引入人类的视觉选择性注意机制能够降低处理的信息量,提高智能驾驶系统对驾驶环境的理解效率,并有助于预测和定位潜在的风险。视觉显著性建模方法能够模拟人类的视觉注意机制提取场景中的显著区域,从而支持信息处理和决策。对驾驶员在驾驶过程中的视觉注意机制进行研究,开展真实道路场景下动态道路场景的视觉显著性建模,能够准确和快速地提取动态驾驶场景的视觉显著区域,从而提高智能驾驶系统的环境理解效率和能力。
目前,国内外对道路场景视觉显著性的研究已有不少的经验,特别是在行人导航领域。人类的视觉注意机制被归结为场景的低级视觉特征和高级视觉特征[1]。低级视觉特征是图像对视觉的直接刺激,这类特征包括颜色、亮度和纹理等[2]。高级视觉特征一般指语义特征,这种特征与人类的认知相关,比如在某些场景中人脸等物体对视觉具有引导作用[3]。道路场景的视觉显著性分析可以用来评价导航任务下场景中地标的有效性[4]、用户的寻路策略[5]、地图的可用性[5]等。视觉显著性的测量流程主要包括设计眼动跟踪实验,收集眼动数据和分析注视点的分布[6]。视觉显著性模型可以模拟人类的视觉注意机制自动计算和提取场景的视觉显著区域,在导航系统设计[7]、用户导航任务推理[8]和地标设计[9]等方面具有广泛的应用。
虽然场景的视觉显著性在遥感影像检测[10]和行人导航领域等地理信息领域研究比较成熟,但驾驶环境下道路场景的视觉显著性建模的研究相对较少,主要原因是驾驶场景相对复杂。首先,驾驶过程具有动态性[11]。动态性包括3个方面:场景的动态变化、驾驶关注区域的变化和车辆的运动。场景的动态指车辆位置的改变使得驾驶场景不断变化,驾驶关注区域的变化是指驾驶员的视觉注意区域的改变,车辆的运动指车辆的速度,加速度和位置随时间的改变。场景动态特征通常用光流图表征[12],定义为后一个时刻场景像素相对于前一个时刻场景像素位移的方向和强度。其次,驾驶场景的复杂性来自道路场景的多样性[13],主要表现在道路类型、道路结构、交通状况和空旷度等方面, 而这些道路属性也是自动驾驶所需要的基本信息[14]。再次,驾驶环境下驾驶员具有双重任务,驾驶员不仅要保证行驶方向的正确,更要确保行车过程的安全。研究表明,驾驶环境下道路场景的动态性[15]、道路场景特征[16]和任务[17]都是影响驾驶员视觉行为的重要因素。
驾驶员的视觉注意力会受到多种因素的影响。其中驾驶速度是一个关键因素。有研究显示高速行驶时驾驶员的视线更集中[18],同时驾驶员的视觉认知负荷也越大[19]。道路结构也影响驾驶员的视觉注意和认知负担。文献[20]通过模拟器试验发现,驾驶员在交叉口驾驶时注意力分散是导致事故多发的主要原因;文献[21]通过设计40名受试者观察100张静态交通图的眼动试验发现受试者倾向于观察道路消失点;文献[19]发现道路曲率越大,驾驶员的视觉负载越重。不同的语义信息也会导致驾驶员的视觉注意差异。道路场景中出现的车辆、行人和路标等目标都能不同程度地吸引驾驶员的注意,因此现有的辅助驾驶系统大都包含行人检测模块[22]、车辆检测模块[23-24]、道路和车道检测[25-26]及交通信号识别模块[27]。上述分析表明,建立驾驶员的视觉注意机制模型需要考虑多种因素的影响。目前对于驾驶环境道路场景视觉显著性建模的研究大多是在静态桌面环境和虚拟环境为试验平台下进行,见表 1。对于文献[18]开展的真实环境中道路场景显著性的模型研究,虽然考虑了车辆速度的作用,但没有考虑道路结构对驾驶员视觉注意机制的影响。
| 研究者 | 研究材料 | 任务描述 | 特征 | 方法 | 指标和评价 |
| 文献[21] | 100张静态城市场景图 | 以驾驶员视角观察图片 | GBVS、AIM、SR、SUN、Itti模型显著图消失点 | 线性加权 | AUC[28]:0.78-0.82 |
| 文献[18] | DR(eye)VE数据集 | 从指定地点开车到终点 | 原始图片、语义分割图和光流图 | 多分支深度学习模型 | 准确性0.56以上 |
| 文献[29] | 驾驶模拟器 | 以驾驶员视角观察 | 低级视觉特征:颜色、纹理和亮度、GBVS、AIM、SR和SUN高级视觉特征:消失点和中心偏差 | 随机森林 | AUC: 0.87 NSS[30-31]: 2.4 |
| 文献[32] | DR(eye)VE数据集 | 从指定地点开车到终点 | 原始图片 | 贝叶斯框架和全卷积神经网络 | 相关系数:0.55以上 |
| 文献[33] | 200张交通场景图 | 自由观察图片 | 颜色、纹理和亮度 | HOG和SVM | 交通标志检测 |
| 文献[34] | 模拟器环境 | 任意驾驶 | 原始图片 | 神经网络模型(监督学习和非监督学习) | 平均误差平方和:0.01~0.03 |
| 文献[35] | 模拟器环境 | 带有驾驶操作的驾驶 | 任务和场景 | SEEV模型 | 相关系数:0.92 |
| 文献[36] | 驾驶视频 | 观看视频并根据视频做特定的任务 | 语义任务 | 眼动指标统计 | 增强区域提取:道路、行人、道路线 |
本文在分析驾驶员视觉特征的基础上,引入了表征动态性的驾驶速度和表征场景类型复杂性的道路结构为建模要素,提取了道路场景的低级视觉特征、以语义信息为主的高级视觉特征和动态特征,构建了驾驶环境下动态场景的视觉显著性计算模型。
1 数据预处理 1.1 数据本文所使用的数据为意大利摩德纳大学发布的DR(eye) VE驾驶场景数据集[18]。该数据集记录了8名驾驶员(7男1女)74次驾驶过程,每个驾驶过程持续5 min。这组数据包含了驾驶员的注视点、行车录像、GPS轨迹和驾驶速度等信息。驾驶员位置每秒更新一次,驾驶速度每秒记录25次。数据收集的硬件配置和数据格式如图 1所示。车顶摄像头Garmin配置为1080p/25 fps,用于固定观察视角,车辆配有GPS。驾驶员驾驶过程中佩戴眼镜式眼动仪ETG,该眼动仪注视点采集频率为60 Hz,眼动仪的摄像头配置为720p/30 fps, 可同步记录驾驶员视角下的场景。

|
| 图 1 视频与眼动数据采集 Fig. 1 The equipment and process of movement collection |
1.2 标准显著图
标准显著图是由眼动数据生成的用于训练视觉显著性模型和检验模型精度的显著性真值。本文研究使用了驾驶员1 s内的注视点构造道路场景的标准显著图。该过程首先用二维高斯函数对注视点进行平滑,然后累加注视点的平滑结果得到标准显著图。该过程的描述如下
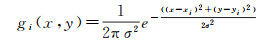 (1)
(1)
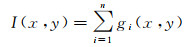 (2)
(2)
式中,(x, y)为像素坐标;(xi, yi)为第i个注视点坐标;gi(x, y)表示第i个注视点对于像素(x, y)显著性的贡献大小;σ为表示高斯函数的影响范围的参数,本文根据经验取值70 px。n表示1 s内注视点的数量;I(x, y)表示像素(x, y)的显著值。主要的数据格式如图 2所示。

|
| 图 2 标准显著图 Fig. 2 Standard visual saliency image |
1.3 道路曲率提取
道路曲率由原始的GPS点位数据计算得到(图 3)。GPS定位的偏差使得轨迹无法直接用于计算道路曲率,因此本文采用了指数多项式平滑算法(PAEK)来平滑原始轨迹点然后将平滑后的线条重新采样成点,最后用三次B样条法[37]计算曲率,计算方法为
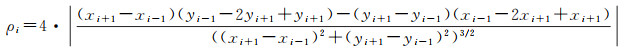 (3)
(3)

|
| 图 3 道路曲率计算过程 Fig. 3 Calculation of road curvature |
式中,ρi为第i个点的曲率;(xi+1,yi+1)为前一个点的坐标;(xi-1,yi-1)为后一个点的坐标。
1.4 道路消失点提取道路消失点的计算方法主要有直线交点法和纹理特征法两种。直线相交法检测场景中所有直线,并统计直线相交点从而得到道路消失点[38]。此法适用于具有明显边界线和车道线的结构化道路,如城市道路、高速路等。基于纹理特征的提取方法[39-40]计算所有点的纹理方向,并统计纹理方向以获得最佳消失点。基于纹理特征的方法适用于几乎所有的道路场景,但相对于直线相交法计算更为复杂。鉴于本文研究的数据中含有非结构化道路(乡下道路),直线法难以精确地提取场景中的直线,本文引用文献[41]基于Gabor计算纹理和使用投票机制得到道路消失点的方法。提取结果表明,大部分的道路消失点提取准确(图 4),少数提取错误的场景采用人工方法进行了修正。

|
| 图 4 道路消失点提取示例 Fig. 4 Examples of vanishing point detection |
1.5 场景语义分割
场景语义信息属于视觉高级特征。人工提取注视点语义信息耗时耗力,计算机视觉技术的发展使自动提取场景语义信息成为可能。本文引入了由Google公司开发的Deeplab V3+图像语义分割模型[42],该模型将深度卷积神经网络和概率图模型相结合,融合多尺度信息,并引入了encoder-decoder架构,对图像和场景的分割有很强的效果。该模型的训练数据集为CityScape[43],模型的Iou精确度可达82.1%。Deeplab V3+模型对本文道路场景的分割结果例子如图 5所示,其精度可以满足本文研究的使用要求。

|
| 图 5 语义分割结果 Fig. 5 Result of the image segmentation |
2 视觉显著性建模 2.1 视觉特征选取
本文结合3种类别的特征构建动态道路场景的视觉显著性:低级视觉特征、由驾驶环境和驾驶任务决定的高级特征和人眼对动态场景感知的动态特征。表 2列出了本文特征的选取及其描述。低级视觉特征中,除了颜色,纹理和亮度之外,还选取了Itti,SUN和GBVS 3种显著性模型的显著图。高级视觉特征包括语义特征和道路消失点。动态特征则为光流图的方向和强度分量的组合。
| 特征类别 | 特征名称 | 特征描述 |
| 低级视觉特征 | 颜色特征 | 按照RGB颜色空间将原始图片分解成RGB通道的灰度特征图 |
| 多尺度纹理特征 | 构建高斯差分金字塔,并利用Gabor算子对差分图像不同尺度的滤波, 本文选取的尺度为7、9、11、13、15、17 | |
| 亮度特征 | 亮度特征为RGB通道求和 | |
| Itti显著图 | 由Itti显著性模型计算得到 | |
| SUN模型显著图 | 由SUN显著性模型计算得到 | |
| GBVS显著图 | 由GBVS显著性模型计算得到 | |
| 高级视觉特征 | 语义特征 | 包括车辆、行人、标识牌和道路 |
| 道路消失点 | 基于图像纹理信息提取的道路消失点 | |
| 动态特征 | 运动方向 | 光流图的方向分量 |
| 运动强度 | 光流图的强度分量 |
2.2 模型设计
场景的视觉显著性是多特征共同作用的结果,本文采用了机器学习中的逻辑回归(LR)模型[44]计算场景显著性,处理流程如下。
(1) 分析了速度、曲率与驾驶员视觉注意的关系(见附录),以考虑驾驶场景的动态性和路面结构特性。分析结果表明,速度和曲率对人的视觉注意的位置和语义信息具有重要的影响。为此,本文在LR模型中引入速度和道路曲率2个因素。
LR模型的基本原理是将特征线性组合,然后根据Sigmoid函数对组合结果进行二分类。本文以像素为单位计算显著图,其公式如下
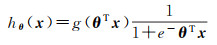 (4)
(4)
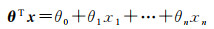 (5)
(5)
式中,hθ(x)为目标函数;g为Sigmoid函数;x为像素的特征向量;xn表示第n个特征;θ为特征向量的系数,表示特征的线性组合。
(2) 对上述经典逻辑回归模型中的系数增加以下的定义
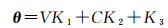 (6)
(6)
式中,V为驾驶场景的速度;C为驾驶场景道路曲率;K1、K2、K3分别为速度系数、道路曲率系数和常数项。
(3) 运用训练数据对模型进行最小二乘法拟合,求得各特征系数。残差平方和成本函数用于拟合度的评估为
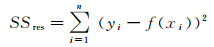 (7)
(7)
式中,SSres为残差平方和;n为测试样本数;f为训练模型;xi为测试像素特征;yi为像素的显著性。
2.3 LR模型计算框架LR模型运行流程如图 6所示,主要包括特征提取,随机像素抽样、模型训练和模型测试评价。

|
| 图 6 LR模型显著图计算框架 Fig. 6 Framework of LR model for calculating visual saliency |
本文从74段视频中共提取出22 200个场景,由图片和注视点生成的标准显著图大小为1920×1080像素,为方便计算重采样成大小为480×360像素的图片。训练数据集占全部数据集的70%,即15 540个场景。本文数据场景数量太多,为了保证每一个场景都能参与模型训练,且训练的样本足够,本文在每一场景中随机选取10个显著的像素点和10个不显著的像素点作为模型的输入。此外本文选用了广为接受的指标ROC(receiver operating characteristic curve)和AUC(area under curve)来评估模型的预测结果。
3 结果 3.1 模型结果验证数据集占全部数据集的30%,即6660个场景。本文提取验证数据集的3类特征,并逐像素地输入训练好的LR模型,将输出的像素值组合成预测显著图。LR模型计算得到的显著图是一张连续的灰度图像,灰度的大小表示像素的显著程度。部分视觉显著图计算结果如图 7所示。灰度值高的区域能够与注视点生成的标准显著图显著区域对应。在不同的驾驶情况下,LR模型对道路消失点、车辆和指示牌等目标的显著性都能准确预测,模型的AUC值达到90.43%。

|
| 图 7 注视点分布和预测显著图的比较 Fig. 7 Comparison of the gaze point distribution and visual saliency prediction |
3.2 视觉特征分析
LR模型将视觉显著性看作是特征的线性组合,因此LR模型的系数能较好地反映各特征对场景显著性图的贡献大小(表 3)。
| 特征类别 | 系数 | 特征类别 | 系数 |
| 红色通道 | 0.594 1 | 车辆 | 0.155 2 |
| 绿色通道 | 0.097 0 | 行人 | 0.281 2 |
| 蓝色通道 | 0.122 2 | 道路 | 0.136 2 |
| 亮度 | -0.792 8 | 交通标识 | 0.112 0 |
| 纹理(多尺度均值) | -0.185 3 | 消失点 | 0.832 1 |
| GBVS模型 | 0.524 0 | 运动强度 | 0.210 1 |
| Itti模型 | -0.133 9 | 运动方向 | -0.507 0 |
| SUN模型 | 0.043 6 |
在所有特征中,消失点对视觉显著图的贡献最大;红色通道的系数明显大于绿色和蓝色通道;在经典显著性模型生成的特征显著图中,GBVS特征系数远大于Itti和SUN特征,仅次于红色通道的系数;高级视觉特征中的4种语义特征均为正值,其中行人特征图对显著图的贡献最大,其次为车辆特征图。运动强度的系数为正值。
对特征系数进行分析,亮度特征对驾驶环境下的场景视觉显著性为负,主要原因可能是整个场景中天空的亮度值最大,然而驾驶员在驾驶过程中并不关注天空。红色通道系数大于绿色和蓝色通道的系数,一个主要的原因在于颜色通道特征和语义特征的关联性。在所有场景中植被区域的绿色通道比重大,天空区域的蓝色通道比重大。而这2类语义信息并不显著,从而导致了RGB 3通道系数的差异。GBVS模型显著图的显著区域集中于图像的中心区域如图 8所示,与道路消失点特征有一定的关联,所以GBVS模型显著图对场景的视觉显著性的贡献较大。Itti模型显著图和SUN显著图对最终显著图的贡献不大,这可能是因为这2个模型侧重于检测边缘信息,然而这类信息在驾驶过程中对视觉引导作用很弱。

|
| 图 8 Itti、GBVS和SUN模型显著特征图对比 Fig. 8 Comparison of significant features of Itti, GBVS and SUN models |
行人特征图的系数在各系数中最大,其次是车辆语义系数,这2个系数较高的原因可能是2者都是动态的,驾驶员需要判断这2个语义类别是否对自己的驾驶过程有影响;而道路由于覆盖范围较广,只是在消失点处显著,因此总体系数值不大;交通标志贡献不大的主要原因在于有经验的驾驶员熟悉驾驶环境之后并不会特别关注交通标志。运动强度对视觉显著性有正向影响,反映了在驾驶环境下人们对移动目标有一定程度的敏感性。
3.3 不同速度和曲率下的精度对比分析为了探索不同速度和曲率下模型的显著性计算结果,本文验证了模型在不同的速度和曲率下的精度。
不同曲率下的ROC曲线如图 9所示,其预测精度在不同曲率下相差很大,当曲率大于1000时,ROC曲线比曲率小于1000的ROC曲线低。各种曲率下的AUC见表 4。

|
| 图 9 不同的曲率下的ROC曲线比较 Fig. 9 Comparison of ROC under different road curvature |
| 曲率 | AUC/(%) |
| 0~200 | 91.02 |
| 200~400 | 90.75 |
| 400~600 | 90.38 |
| 600~800 | 90.49 |
| 800~1000 | 90.81 |
| 1000~1200 | 89.93 |
| 1200~1400 | 88.62 |
| 1400~1600 | 86.41 |
| 1600~1800 | 88.31 |
| 1800~2000 | 86.57 |
不同速度下的ROC曲线如图 10所示。当速度为0时,ROC曲线最高,而其他速度下的ROC曲线比较接近。各种速度的AUC值见表 5。

|
| 图 10 不同速度下的ROC曲线比较 Fig. 10 Comparison of ROC under different speeds |
| 速度/(km/h) | AUC/(%) |
| 0~10 | 94.52 |
| 10~20 | 90.13 |
| 20~30 | 89.02 |
| 30~40 | 91.42 |
| 40~50 | 89.02 |
| 50~60 | 90.87 |
| 60~70 | 90.65 |
| 70~80 | 90.79 |
| 80~90 | 90.31 |
| 90~100 | 90.84 |
3.4 模型对比分析
与Itti、GBVS、SUN,传统LR模型相比较, 本文的扩展的LR模型精度最高(表 6),而Itti和SUN模型预测精度均小于0.5。结果表明,本文所提出的模型预测道路场景视觉显著性具有可行性和优越性。
| 模型 | AUC |
| Itti | 0.45 |
| GBVS | 0.56 |
| SUN | 0.46 |
| LR | 0.85 |
| 扩展的LR | 0.90 |
4 结论与讨论
对场景重要的物体和区域检测对智能驾驶系统至关重要。本文提取了低级视觉特征、高级视觉特征和动态特征,构建带有速度和曲率系数的LR视觉显著性检测模型。研究结果表明提出的LR模型的ROC曲线AUC值为90.43%,模型预测区域和视觉关注区域匹配准确。通过特征系数分析发现,消失点对视觉显著性贡献最大,场景的红色通道和GBVS显著图次之,同时亮度、纹理、Itti和运动方向特征在LR模型中的系数值为负值,说明这些特征与视觉显著性呈负相关。本文提出的模型有助于智能驾驶系统的环境理解,并在特定对象跟踪检测、驾驶训练,安全警告和交通标志检测等方面有重要作用。
数据可用性是本文的一个限制。每段驾驶场景仅包含单个驾驶员的注视点,个体偏差会影响模型的预测准确性。另外,注视时长和注视点均为视觉显著性评价的重要眼动指标,由于数据集没有提供注视时长数据,所以本文仅根据注视点的个数和分布进行建模。而加入注视时长数据能更加准确地表达视觉显著性。驾驶员的年龄、性别和驾龄等因素也是影响道路场景视觉显著性建模的重要因素,本文所收集的数据仅来自8名驾驶员,其中7名为男性,没有年龄和驾龄等信息,因此无法发掘个体信息对视觉注意机制的影响。试验并探究不同环境下的视觉显著性,其主要原因是在光线较暗的下雨天和晚上采集的图像语义分割效果不理想。今后还会完善驾驶数据收集过程,增加驾驶员数量和注视点自身的注视时长信息,发布全面的驾驶数据集,还需要深入探讨驾驶员个体差异对真实驾驶环境中道路场景视觉显著性的影响,并对不同驾驶环境的差异进行探索,包括道路类型、驾驶时间、天气条件等。这些将服务于构建结合人的属性、环境属性和车辆状态构建人-车-环境一体化的道路场景视觉注意模型。
附录 曲率和速度对动态场景的视觉显著性影响 1 不同道路曲率的视觉显著性区别附图 1显示了不同道路曲率的情况下,所有注视点在图片位置的分布情况。

|
| 图 附图 1 道路曲率与驾驶员的注视点位置分布 Fig. S1 Visualization of drivers' gaze point position distribution at different curvatures |
为讨论曲率对注视点位置的定量影响,本文计算得到每个曲率范围下的注视点离散度的均值(附图 2)。当曲率为100时的离散度仅为32 px, 而在0~1600区间内,随着曲率的增大,注视点离散度也随之缓慢增大,当曲率达到1500时,注视点的离散度达到55 px。而当离散程度在1600以上时,注视点离散程度急剧增大,并保持在70像素左右。

|
| 图 附图 2 注视点离散度与曲率的关系 Fig.S2 The relationship between gaze point dispersion and curvature |
附图 3统计了不同曲率下各目标类型的注视概率。道路的注视概率仍然是最高的,其次为车辆的注视概率。随着道路曲率的增大,道路和建筑的注视概率增大,其中道路的注视概率从低曲率下的74%提高到高曲率下的85%,而建筑的注视概率从低曲率下的27%提高到了高曲率下38%;交通标志的注视概率随着曲率增大而减小,从低曲率下的19%降低到高曲率下的12%。植被、天空的注视概率无明显变化规律。而行人在高曲率下的注视概率降低到了低曲率下的1/3,其低曲率下的注视概率为30%左右,高曲率下仅为10%以下。车辆、天空和植被的注视概率没有明显变化。

|
| 图 附图 3 各类别注视概率随曲率变化情况 Fig. S3 Fixation probability for each category at different curvatures |
2 不同速度的视觉显著性区别
附图 4显示了不同速度的情况下,所有注视点在图片位置的分布情况。

|
| 图 附图 4 速度与注视点分布的关系 Fig. S4 Visualization of drivers' gaze point position distribution at different speeds |
定量计算各速度下的注视点离散度, 如附图 5所示,当速度达到70 km/h之前,注视点离散程度逐渐减小,离散程度和速度呈现线性递减。而当速度达到70 km/h之后,随着速度的增加,注视点离散度保持在50 px左右且不再改变。

|
| 图 附图 5 速度与离散程度 Fig. S5 The relationship between gaze point dispersion and speed |
不同速度注视概率统计结果如附图 6所示。道路的注视概率最大,车辆的注视概率次之;随着速度的增大,车辆和建筑的注视概率减小,车辆的注视概率由低速下的78%减小到高速下的59%,建筑的注视概率由低速度下的38%减少到高速下的20%;随着速度增大,高速下行人的注视概率提高到低速下注视概率的4倍,由低速下的13%提高到高速时的53%;道路、交通标志、植被和天空的注视概率无明显变化规律。

|
| 图 附图 6 各类别注视概率随速度变化情况 Fig. S6 Fixation probability for each category at different speeds |
| [1] |
BORJI A. Boosting bottom-up and top-down visual features for saliency estimation[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012: 438-445.
|
| [2] |
NOTHDURFT H C. Salience of feature contrast[M]. Amsterdam: Elsevier, 2005: 233-239.
|
| [3] |
HENDERSON J M, HOLLINGWORTH A. High-level scene perception[J]. Annual Review of Psychology, 1999, 50(1): 243-271. DOI:10.1146/annurev.psych.50.1.243 |
| [4] |
CADUFF D, TIMPF S. On the assessment of landmark salience for human navigation[J]. Cognitive Processing, 2008, 9(4): 249-267. DOI:10.1007/s10339-007-0199-2 |
| [5] |
LIAO Hua, DONG Weihua, PENG Chen, et al. Exploring differences of visual attention in pedestrian navigation when using 2D maps and 3D geo-browsers[J]. Cartography and Geographic Information Science, 2017, 44(6): 474-490. DOI:10.1080/15230406.2016.1174886 |
| [6] |
LIAO Hua, DONG Weihua. An exploratory study investigating gender effects on using 3D maps for spatial orientation in wayfinding[J]. ISPRS International Journal of Geo-Information, 2017, 6(3): 60. DOI:10.3390/ijgi6030060 |
| [7] |
OHM C, MVLLER M, LUDWIG B, et al. Where is the Landmark? Eye tracking studies in large-scale indoor environments[C]//Proceedings of the 2nd International Workshop on Eye Tracking for Spatial Research (in conjunction with GIScience 2014). Vienna, Austria: CEUR Workshop Proceedings, 2014: 47-51.
|
| [8] |
LIAO Hua, DONG Weihua, HUANG Haosheng, et al. Inferring user tasks in pedestrian navigation from eye movement data in real-world environments[J]. International Journal of Geographical Information Science, 2019, 33(4): 739-763. DOI:10.1080/13658816.2018.1482554 |
| [9] |
WANG Shuihua, TIAN Yingli. Indoor signage detection based on saliency map and bipartite graph matching[C]//Proceedings of 2011 IEEE International Conference on Bioinformatics and Biomedicine Workshops(BIBMW). Atlanta, GA, USA: IEEE, 2011: 518-525.
|
| [10] |
DAI Yuchao, ZHANG Jing, HE Mingyi, PORIKLI Fatih, LIU Bowen. Salient Object Detection from Multi-spectral Remote Sensing Images with Deep Residual Network[J]. Journal of Geodesy and Geoinformation Science, 2019, 2(2): 101-110. |
| [11] |
BROUWER W H, WATERINK W, VAN WOLFFELAAR P C, et al. Divided attention in experienced young and older drivers: lane tracking and visual analysis in a dynamic driving simulator[J]. Human Factors, 1991, 33(5): 573-582. DOI:10.1177/001872089103300508 |
| [12] |
VIDAL R, RAVICHANDRAN A. Optical flow estimation & segmentation of multiple moving dynamic textures[C]//Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). San Diego, CA, USA: IEEE, 2005: 516-521.
|
| [13] |
JENSEN S S. Driving patterns and emissions from different types of roads[J]. Science of the Total Environment, 1995, 169(1/2/3): 123-128. |
| [14] |
LIU Jingnan, ZHAN Jiao, GUO Chi, et al. Data logic structure and key technologies on intelligent high-precision map[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 1-17. |
| [15] |
DOSHI A, TRIVEDI M. Investigating the relationships between gaze patterns, dynamic vehicle surround analysis, and driver intentions[C]//Proceedings of 2009 IEEE Intelligent Vehicles Symposium. Xi'an, China: IEEE, 2009: 887-892.
|
| [16] |
PALINKO O, KUN A L, SHYROKOV A, et al. Estimating cognitive load using remote eye tracking in a driving simulator[C]//Proceedings of 2010 Symposium on Eye-Tracking Research & Applications. Austin, Texas, NY, USA: ACM Press, 2010: 141-144.
|
| [17] |
RECARTE M A, NUNES L M. Effects of verbal and spatial-imagery tasks on eye fixations while driving[J]. Journal of Experimental Psychology Applied, 2000, 6(1): 31-43. DOI:10.1037/1076-898X.6.1.31 |
| [18] |
PALAZZI A, ABATI D, CALDERARA S, et al. Predicting the driver's focus of attention: the DR(eye)VE project[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(7): 1720-1733. DOI:10.1109/TPAMI.2018.2845370 |
| [19] |
吴晓峰. 基于驾驶员工作负荷的公路线形安全性评价[D]. 西安: 长安大学, 2009. WU Xiaofeng. Highway geometry safety evaluation based on driver workload[D]. Xi'an: Changan University, 2009. |
| [20] |
WERNEKE J, VOLLRATH M. What does the driver look at? The influence of intersection characteristics on attention allocation and driving behavior[J]. Accident Analysis & Prevention, 2012, 45: 610-619. |
| [21] |
DENG Tao, YANG Kaifu, LI Yongjie, et al. Where does the driver look? top-down-based saliency detection in a traffic driving environment[J]. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(7): 2051-2062. DOI:10.1109/TITS.2016.2535402 |
| [22] |
SHASHUA A, GDALYAHU Y, HAYUN G. Pedestrian detection for driving assistance systems: single-frame classification and system level performance[C]//Proceedings of 2004 IEEE Intelligent Vehicles Symposium. Parma, Italy: IEEE, 2004: 1-6.
|
| [23] |
ZHONG Zhun, LEI Mingyi, CAO Donglin, et al. Class-specific object proposals re-ranking for object detection in automatic driving[J]. Neurocomputing, 2017, 242: 187-194. DOI:10.1016/j.neucom.2017.02.068 |
| [24] |
MILANÉS V, LLORCA D F, VILLAGRÁ J, et al. Intelligent automatic overtaking system using vision for vehicle detection[J]. Expert Systems With Applications, 2012, 39(3): 3362-3373. DOI:10.1016/j.eswa.2011.09.024 |
| [25] |
RISACK R, KLAUSMANN P, KRVGER W, et al. Robust lane recognition embedded in a real-time driver assistance system[C]//Proceedings of 1998 IEEE International Conference on Intelligent Vehicles. Piscataway, NJ, USA: IEEE, 1998: 35-40.
|
| [26] |
JEONG S G, KIM C S, LEE D Y, et al. Real-time lane detection for autonomous vehicle[C]//Proceedings of 2001 IEEE International Symposium on Industrial Electronics. Pusan, Korea (South): IEEE, 2001: 1466-1471.
|
| [27] |
PAULO C F, CORREIA P L. Automatic detection and classification of traffic signs[C]//Proceedings of the 8th International Workshop on Image Analysis for Multimedia Interactive Services. Santorini, Greece: IEEE, 2007: 11.
|
| [28] |
LOBO J M, JIMÉNEZ-VALVERDE A, REAL R. AUC: a misleading measure of the performance of predictive distribution models[J]. Global Ecology and Biogeography, 2008, 17(2): 145-151. DOI:10.1111/j.1466-8238.2007.00358.x |
| [29] |
DENG Tao, YAN Hongmei, LI Yongjie. Learning to boost bottom-up fixation prediction in driving environments via random forest[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(9): 3059-3067. DOI:10.1109/TITS.2017.2766216 |
| [30] |
PETERS R J, IYER A, ITTI L, et al. Components of bottom-up gaze allocation in natural images[J]. Vision Research, 2005, 45(18): 2397-2416. DOI:10.1016/j.visres.2005.03.019 |
| [31] |
HORREY W J, WICKENS C D, CONSALUS K P. Modeling drivers' visual attention allocation while interacting with in-vehicle technologies[J]. Journal of Experimental Psychology: Applied, 2006, 12(2): 67-78. DOI:10.1037/1076-898X.12.2.67 |
| [32] |
TAWARI A, KANG B. A computational framework for driver's visual attention using a fully convolutional architecture[C]//Proceedings of 2017 IEEE Intelligent Vehicles Symposium (Ⅳ). 2017, Los Angeles, CA, USA: IEEE, 2017: 887-894.
|
| [33] |
XIE Yuan, LIU Lifeng, LI Cuihua, et al. Unifying visual saliency with HOG feature learning for traffic sign detection[C]//Proceedings of 2009 IEEE Intelligent Vehicles Symposium. Xi'an, China: IEEE, 2009: 24-29.
|
| [34] |
MOHANDOSS T, PAL S, MITRA P. Visual attention for behavioral cloning in autonomous driving[C]//Proceedings of 11th International Conference on Machine Vision (ICMV 2018). Munich, Germany: SPIE, 2019: 361-371.
|
| [35] |
HORREY W J, WICKENS C D, CONSALUS K P. Modeling drivers' visual attention allocation while interacting with in-vehicle technologies[J]. Journal of Experimental Psychology: Applied, 2006, 12(2): 67-78. DOI:10.1037/1076-898X.12.2.67 |
| [36] |
EYRAUD R, ZIBETTI E, BACCINO T. Allocation of visual attention while driving with simulated augmented reality[J]. Transportation Research Part F: Traffic Psychology and Behaviour, 2015, 32: 46-55. DOI:10.1016/j.trf.2015.04.011 |
| [37] |
毛征宇, 刘中坚. 一种三次均匀B样条曲线的轨迹规划方法[J]. 中国机械工程, 2010, 21(21): 2569-2572, 2577. MAO Zhengyu, LIU Zhongjian. A trajectory planning method for cubic uniform B-spline curve[J]. China Mechanical Engineering, 2010, 21(21): 2569-2572, 2577. |
| [38] |
李泳波. 基于RANSAC的道路消失点自适应检测算法[J]. 中国科技信息, 2017(13): 80-82, 13. LI Yongbo. An adaptive detection algorithm for road vanishing points based on RANSAC[J]. China Science and Technology Information, 2017(13): 80-82, 13. DOI:10.3969/j.issn.1001-8972.2017.13.029 |
| [39] |
MOGHADAM P, STARZYK J A, WIJESOMA W S. Fast vanishing-point detection in unstructured environments[J]. IEEE Transactions on Image Processing, 2012, 21(1): 425-430. DOI:10.1109/TIP.2011.2162422 |
| [40] |
RASMUSSEN C. Grouping dominant orientaions for ill-structured road following[C]//Proceedings of 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC, USA: IEEE, 2004: I.
|
| [41] |
KONG Hui, AUDIBERT J Y, PONCE J. Vanishing point detection for road detection[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009: 96-103.
|
| [42] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. DOI:10.1109/TPAMI.2017.2699184 |
| [43] |
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 3213-3223.
|
| [44] |
MAULUD D, ABDULAZEEZ A M. A review on linear regression comprehensive in machine learning[J]. Journal of Applied Science and Technology Trends, 2020, 1(4): 140-147. DOI:10.38094/jastt1457 |