



2. 中国电子科技集团公司第二十七研究所, 河南 郑州 450047
2. China Electronic Technology Group Corporation 27 th Research Institute, Zhengzhou 450047, China
随着遥感技术的飞速发展,可见光、红外、合成孔径雷达(synthetic aperture radar,SAR)等多类型传感器对地观测影像[1]日趋丰富。不同平台和传感器获取的异源影像之间具有一定互补性,为遥感信息的深入挖掘、大数据分析提供了海量的数据来源[2]。影像之间的匹配是异源影像进一步处理及分析的核心问题。由于成像机理、波段、时相等不同,异源影像在辐射特征、几何特征上都存在巨大差异,它们之间的匹配一直都是影像匹配的研究难点。
国内外学者针对这一问题提出了多种匹配方法。主要包括两大类,一类是基于特征的匹配方法,另一类是基于模板匹配的方法。图像特征匹配通常提取关键点周围一定邻域内的局部特征信息描述符,通过比较描述符来确定匹配点,其中最著名的是尺度不变特征转换(scale invariant feature transformation, SIFT)描述符[3]。SIFT描述符能够很好地抵抗影像间的旋转和尺度差异,但由于基于影像局部邻域的梯度分布描述关键点,对异源影像的匹配效果较差。因此,众多学者试图通过改进SIFT算法或者结合其他约束信息开展异源影像匹配研究[4-8]。但是当异源影像间的辐射和几何差异较大时,特别是存在较大的非线性误差时,由于较小的邻域强度和梯度信息不能提供稳定的特征[9],因此很难获得良好的效果。
与SIFT及其改进算法相比,基于模板的匹配可以获得更大影像范围内的不变量。其中,在异源影像匹配方面比较成功的相似性测度包括互信息(mutual information,MI)以及相位一致性[9-13]。此外,文献[14]提出了一种顾及灰度和梯度信息的多模态影像配准算法,文献[15]提出了基于相位一致性和最大索引图的辐射不变特征匹配方法RIFT,都取得很好的匹配效果。
以上算法都依赖人工设计的描述符,当面对的遥感影像在来源、模式和波段等方面变化越来越多的情况下,其扩展和表达能力有限,基于模板的匹配效率也相对较低。近几年,深度学习方法特别是卷积神经网络(convolutional neural network,CNN)在计算机视觉任务如图像分类、目标检测和分割方面取得了巨大的进步和性能提升。自2014年文献[16]首次引入以来,学者们就开始将CNN应用于图像特征提取过程,并逐渐从SIFT特征向CNN特征转变[16-22]。传统的人工设计的描述子只能提取和表示影像相对低层的特征,而CNN通常被认为能够提取更高层、更抽象的语义特征。利用高层的语义信息进行匹配,有着很强的泛化性,更接近人类视觉观察原理,理论上应该更能够抵抗由于波段、成像模式、季节变换等带来的干扰,有望在匹配适应性方面获得较大提升。
早期提出的CNN特征提取方法大多使用全连接层展平提取整幅图像或者图像块的特征向量,通常用于图像分类或者识别,不进行关键点特征的匹配。2016年以后,学习型关键点特征检测和描述算法得到了迅速发展,相继提出了LIFT[23]、SuperPoint[24]、DELF[25]、D2-Net[26]等。其中,D2-Net利用30多万个预匹配的立体像对进行训练,在解决变化场景下影像匹配方面取得了重要进展,且表现出巨大的潜力。但这些算法模型提出的主要目的是用于光照和视角变化的地面近景可见光影像,多用于地面车辆视觉导航等。文献[27]专门针对跨模态异源的影像匹配问题,提出了用跨模态上下文增强的局部描述子,取得了积极进展。
本文试图在引入D2-Net特征提取基本思想的基础上,提出一种基于深度学习特征的异源遥感影像匹配算法(cross modality matching net,CMM-Net),希望能够通过CNN提取的高层语义局部特征,自动学习和寻找异源影像同名点之间几何和辐射不变量,形成一种稳健的端对端的异源遥感影像匹配方法。
1 异源遥感影像不变局部特征提取与匹配原理 1.1 算法基本思想要实现异源遥感影像稳健的特征匹配,核心问题在于如何减小异源影像辐射和几何差异带来的影响,找到不变特征表示方法。为达到这一目的,本文提出的CMM-Net着重在以下3个方面进行考虑。①构建一个适合特征关键点提取和描述的CNN网络和提取算法。来自CNN较深层的特征图可以看作是更高层的语义信息,高层抽象的语义信息要比低层梯度信息更能够适应辐射和几何上的变化;适当扩大提取特征对应的原始输入影像范围(感受域),有利于异源影像不变特征的提取。②利用已经配对好的光照和拍摄角度都存在较大差异的数据对CNN网络进行训练,让CNN特征提取器能学习到光照、几何等变化影像的不变性特征。③采取“以多求可靠”的策略。异源影像差异大,即使考虑到以上两点,对于模式不同的影像(如SAR和光学影像)进行匹配还是存在很大困难。因此,本文考虑“以多求可靠”的策略,让提取的候选特征具有较多的数量,通过提升匹配过程的筛选机制进行有效约束,以获得更多可靠、更均匀的匹配对。
此外,特征定位也是特征匹配过程中不可忽视的问题。通常CNN经过卷积抽象后,输出特征图分辨率会成倍下降。CNN深度越深,特征的不变性表达能力越强,但定位精度越差,特征的抽象和精确定位在CNN中是一对矛盾。本文在特征提取过程中,选择抽取CNN网络的中间层,并通过改变池化步长方法来保证网络最后一次池化输出分辨率不降低,同时,与SIFT等传统算法一样,采用关键点内插的方式,获得更高的定位精度。
1.2 异源遥感影像深度学习不变特征提取 1.2.1 网络模型为使CNN网络适合特征提取,CMM-Net选取经典VGG16网络模型[28]并对其进行适应性改造。经典的VGG16模型共5个卷积网络,主要用于分类任务。通常,网络的前几层感受域很小,得到的特征是相对底层的边缘、角点等局部特征,但定位精度较高;网络层数越深,提取的特征越抽象,信息越全局,越能抵抗异源影像带来的干扰,但定位精度越差。因此,为了能够使特征点既有足够抽象性、也可以获得较高的定位精度,本文算法丢弃VGG16的最后一个卷积层,选取中间第4层中的最后一个(第3个)卷积层(Conv4_3)输出作为关键点提取的特征图,网络结构如图 1所示。特征图是原始影像经过CNN网络多层卷积、池化后得到的输出,其维度和同一层卷积核数量相同。选取Conv4_3的输出作为特征图,既具有较深的CNN不变性表达能力,又能保留一定的分辨率。

|
| 图 1 网络结构 Fig. 1 The neural network structure |
卷积神经网络每一层经过池化后,分辨率一般都会下降,为了保持特征图的分辨率,本文将最后一个(第3个)池化层窗口滑动步长从2像素,替换为1像素,并且池化方法也由最大池化,替换为平均池化。第4层3个卷积(Conv4_1至Conv4_3)采用空洞卷积率(dilation)为2的空洞卷积,这样可以扩大感受域,提高特征表达泛化能力,有利于异源图像特征的不变性表达。经过改造后,相对经典的VGG16网络,输出的特征图从原始图像的1/8扩大到1/4,定位精度提高一倍[26]。
1.2.2 深度和平面局部极值点选择与特征描述利用上节设计的网络结构,如果直接使用Conv4_3输出的特征图全部像素作为特征,特征将过于密集,且大部分特征不够显著。因此需要从特征图中选择一些特征明显的关键点用于异源影像匹配,这一步称为特征筛选。
假设输入原始影像为I,尺寸为w×h,设网络输出特征图为3D张量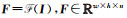
为了在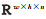
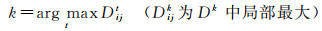 (1)
(1)
式中,Dk为第k层特征值,且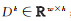
同时,在特征图F上提取(i, j)处的512维通道向量,并进行L2范式归一化,得到特征描述符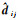
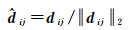 (2)
(2)
式中,dij=Fij,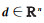
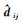
虽然CNN模型使用尺度上有差异的训练样本进行训练,特征描述符能够学习一定程度的尺度不变性,但也难以应对尺度变化较大的情况。因此,CMM-Net采取了离散影像金字塔模型来应对尺度的较大变化。对输入图像I,金字塔影像Iρ,本文采用0.25、0.5、1.0、2.0倍分辨率(即ρ=0.25, 0.5, 1, 2)4个离散尺度层来适应两幅图像分辨率的剧烈变化。与通过有一定尺度差异的训练数据学习到的CNN模型一起构成算法对输入影像连续且较大尺度变化的适应性。
金字塔的每一层分别提取CNN特征Fρ,然后利用式(3)进行累加融合[26]。关键点的特征描述将通过累加得到的融合特征图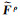
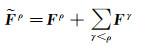 (3)
(3)
由于金字塔分辨率不同,低分辨率特征图需要线性内插成与高分辨率特征图相同大小才能进行累加。此外,为了防止不同层级检测特征的重复,CMM-Net从最粗的尺度开始,标记检测到的位置;这些位置将被上采样到高一个尺度的特征图中作为模板,如果高一级分辨率特征图提取的关键点落入该模板中就会被舍弃。
1.3 损失函数与模型训练ImageNet预训练的VGG16网络模型不具备对异源影像相似性的表达能力。为让CNN网络模型能够在辐射与几何差异较大的异源遥感影像上学习共同特征的表达,需要重新设计损失函数并利用合理的训练数据进行模型微调。
1.3.1 三元组距离排序损失函数CMM-Net采用了三元组距离排序函数(triplet margin ranking loss,TMRL)[29]作为损失函数。因为在特征检测过程中,希望特征点具有一定通用性,以适应不同环境光照辐射和几何差异的影响;但同时,在特征描述过程中,又希望特征向量尽可能具有独特性,以便寻找同名像点。针对这个问题,三元组距离排序损失函数通过惩罚导致错误匹配的任何不相关描述符来增强相关描述符的独特性。此外,为寻求检测特征的可重复性,将检测项添加到损失函数中[26],公式为
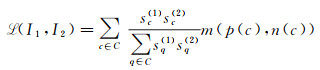 (4)
(4)
式中,p(c)和n(c)分别代表同名像点的正对距离和负对距离;sc(1)和sc(2)为在影像I1和I2上A、B两个点处得到的特征检测得分,具体计算方法可参照文献[26];C是影像I1和I2上所有同名像点的集合。
上述损失函数会基于所有匹配项的检测得分来生成距离因子m的加权平均值。因此,为了使损失最小化,具有较低的距离因子的最相关的对应关系,将获得较高的相对得分,并让具有较高相对得分的对应关系获得与其余特征不同的相似描述符,提高匹配的稳健性。
1.3.2 训练数据利用式(4),为了让CNN模型能够学习到辐射和几何差异下像素级特征相似性的表达,训练数据除了数量要足够外,还必须同时具备以下两个条件:①训练影像具备较大的辐射和几何差异;②训练影像具备像素级的对应关系。文献[30]构建了一种MegaDepth数据集。该数据集提出的初衷是进行单张影像的深度恢复,由100多万幅从互联网获得的地标影像组成,这些影像拍摄光照、尺度差异都比较大,还包含了大量昼夜影像对,如图 2所示。此外,该数据集还从这些影像中筛选出约10万幅优质影像,使用开源运动恢复结构软件COLMAP[31]构建了近200个不同全球地标的三维场景,包括了相机内/外部参数、场景结构信息及深度图。从这些三维场景中,可以获得立体影像对,并利用场景三维信息和相机参数,第2幅影像上的像点可以投影到第1幅中,建立像对像素级的对应关系。由此可见,MegaDepth数据集可以满足上述两个条件。因此,本文算法选用该数据集进行模型训练。

|
| 图 2 训练数据示例 Fig. 2 Examples of training data |
1.3.3 模型训练方法
CMM-Net骨干网络采用了基于海量ImageNet数据集进行预训练的VGG16模型,对网络模型中最后一个密集特征提取器Conv4_3采用迁移学习微调训练的方法训练网络模型。初始学习率设置为10-3,然后每10个Epoch减小一半,对于每对同名像点,分别选择以同名像点为中心的256×256像素的随机影像区域送入到网络进行训练。通过训练可以使网络能从较大辐射和几何差异的异源遥感影像上获得相似特征的良好性能。
1.4 异源遥感影像深度学习不变特征匹配方法 1.4.1 基本思想与流程CMM-Net匹配算法主要思想为:将1.2节算法作为特征提取器,在原始影像上提取深度特征。特征匹配方法采用快速最近邻搜索(FLANN)方法。由于异源影像差异较大,提取的候选特征点数量较多,不可避免地会存在大量误匹配的情况,本文提出了动态自适应距离约束条件和随机采样一致性(random sample consensus,RANSAC)约束相结合的误匹配点剔除方法,实现“以多求可靠”策略中有效筛选这关键一环。算法流程如图 3所示。

|
| 图 3 异源遥感影像匹配算法流程 Fig. 3 Overview of the proposed matching method pipeline |
1.4.2 动态自适应阈值匹配点提纯
采用RANSAC或者类似几何约束算法是行之有效的匹配点提纯方法,但如果待提纯的匹配点对中含有大量差异较大的误匹配,RANSAC的随机取值迭代方法受这些错误匹配点的影响,算法变得极不稳定。因此,在几何约束之前,需要进行匹配点对的粗提纯。通过FLANN算法搜索出来待筛选的匹配对中,包含欧氏距离最近的第1匹配点和次近的第2匹配点。通常认为,对于待筛选的匹配对中的第j个匹配对,第1匹配点距离disj比第2匹配点距离disj′越小,说明匹配质量越好。传统的算法都采取固定比例因子t作为阈值,即当满足disj < t·disj′时,选入候选匹配对。但由于不同传感器和时相的影像差距较大,CNN特征进行欧氏空间距离搜索时,欧氏距离差分布范围很难预料。因此,每一对影像通常需要不断手动调整阈值t到合适数值,才能筛选出优质的匹配对。为解决这一问题,提高算法的适应性,本文设计了动态自适应欧氏距离约束方法。该方法针对待提纯的匹配对数据进行统计,根据数据特点自动的配置相应参数。首先,从FLANN搜索出来的N个包含大量误匹配的匹配对中统计第1匹配点和第2匹配点距离差的均值
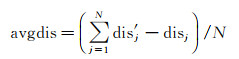 (5)
(5)
对于每一个待筛选匹配对,剔除的条件为第1距离小于第2距离与距离差均值avgdis之差,公式为
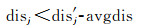 (6)
(6)
算法通过从数据中统计得到的距离差均值,作为判别比较标准,可以很好地适应不同来源的像对之间的差异,能够很好地进行第1轮筛选,保留优质匹配点,提高RANSAC输出的稳定性。
RANSAC中几何约束关系要根据待匹配影像的成像几何关系选择合适的模型。在实际工程应用中,应尽可能采用严格的约束模型。如画幅式面阵影像通常可用单应矩阵、本质矩阵等约束模型;线阵卫星影像多采用基于PRC模型或者多项式模型的核线约束。本文试验中,由于选取的试验遥感影像摄影距离较远、地面相对高差不大、选取的影像区域也较小,故采用仿射变换模型,以适应不同成像模型的像对之间的缩放、平移、旋转和错切等变换。
2 试验与分析本节首先对CMM-Net算法提取的异源影像同名特征的相似性进行验证,并分别针对尺度和方向上的性能进行试验;然后,为评价CMM-Net的性能,与多个异源影像匹配算法进行对比试验;最后,利用实际异源遥感影像进行配准试验,考查在影像配准上的实际应用效果。试验过程中,CMM-Net深度学习模型在PyTorch框架下实现,试验用计算机为华硕ROG笔记本,CPU为i7-9750H,显卡为GeForce RTX 2060(6 GB显存),内存为32 GB;实现语言为Python,操作系统为Ubuntu 18.04。
2.1 特征相似性试验提取的多源影像上的同名特征是否具有相似性,是异源影像匹配的关键。本文选取了高分三号SAR卫星、资源三号光学卫星、谷歌地球以及无人机等几种来源的异源影像,见图 4。测试数据中成像模式不同、时相不同、分辨率也不同,具有代表性。几幅图像的中心位置经过人工配准,试验通过该中心提取的特征向量的相似度进行评估。

|
| 图 4 特征不变性测试数据 Fig. 4 Image data for feature invariance test |
试验分别利用SIFT算法与本文方法提取了4幅试验图像中心同名像点的特征向量,统一进行L2范式归一化,并以曲线的形式绘制,横坐标为特征向量维度,纵坐标为归一化的特征值。这种特征曲线走向可以反映异源影像特征之间的相似程度。为显示清晰,随机截取了其中一段范围,如图 5所示。

|
| 图 5 特征向量不变性测试结果 Fig. 5 Vector invariance test result |
对比图 5直观展现出的4个异源图像同名像点的特征向量的走向。很明显,本文算法相对于SIFT算法明显具有比较高的相似性,在很多维度坐标(横轴)上,曲线的波峰波谷变化规律接近。特别需要指出的是,差异最大的SAR图像(红色实线)和其他几个特征曲线走向相似度也很高。为了量化特征向量直接的差异,统计了特征向量之间的余弦距离如表 1所示。由于SIFT与本文算法提取的特征维度和量化标准不同,相对于欧氏距离,代表向量之间角度差异的余弦距离更能反映不同维度向量之间的相似度。
| 算法 | 影像对 | GF-3 | ZY-3 | |
| SIFT 算法 |
GF-3 | — | — | — |
| ZY-3 | 0.52 | — | — | |
| 0.68 | 0.73 | — | ||
| UAV | 0.58 | 0.61 | 0.31 | |
| CMM-Net 算法 |
GF-3 | — | — | — |
| ZY-3 | 0.37 | — | — | |
| 0.31 | 0.28 | — | ||
| UAV | 0.34 | 0.28 | 0.15 |
前期通过大量正确匹配点和错误匹配点的特征向量的余弦距离统计得出一个经验,相似特征的余弦距离通常小于0.4。根据这个原则,表 1的结果可以发现,试验中SIFT算法无法描述差异较大的异源图像的不变特征。而本文算法提出的特征表现出很好的相似性。同时,不同的成像模式和高噪音的SAR图像和光学影像的特征相似度虽然要弱于光学影像之间的相似度,但也在一个比较高的相似性水平。通过本节的试验,说明利用本文的CNN模型和训练方法,特征提取器可以为异源影像提出不变特征,能够适应由于成像模式和环境造成的辐射非线性畸变的影响。
2.2 特征尺度和方向适应性试验为验证CMM-Net的离散金字塔多尺度模型的可行性,并测试特征在方向上的性能,本文设计了两个试验分别验证。试验以图 4(d)为基准,人工缩小或绕中心旋转图 4(c),得到在尺度和旋转上连续变化的图像,再通过比较两幅图像中心点提取的特征向量之间的余弦距离来评估算法在尺度和方向上的性能。试验结果如图 6和图 7所示。

|
| 图 6 尺度和旋转不变性评估 Fig. 6 Scale and rotate invariance test result |

|
| 图 7 旋转适应性评估结果 Fig. 7 Rotate invariance test result |
图 6为尺度不变性评估结果。横轴表示影像在尺度上缩小的倍数,试验按照每隔0.1倍取样;纵轴为尺度变化后提取的特征与基准影像上同名特征之间的余弦距离。图中可以反映尺度变化,所提取的特征描述符相似性的变化情况。其中,实线为应用本文离散金字塔多尺度模型后特征相似性的变化。虚线是没有采用多尺度模型的结果。从图 6可以看出,采用离散金字塔多尺度模型后,两幅图像上同名特征提取的相似度水平提升显著。虽然会随着尺度差异变大而有所下降,但下降相对缓慢,且在缩小近10倍的情况下,特征余弦距离仍然保持在0.3左右;相反,没有采用多尺度模型情况下,相似性随尺度改变变化剧烈,尺度变化2~3倍后,特征相似性基本消失(余弦距离大于0.4)。通过这个试验还可以看出,虽然本文采取的是4层离散(0.25, 0.5, 1, 2倍)金字塔模型,但整个相似性曲线变化是连续的,并没有出现阶跃现象。这说明,本文算法具备良好的连续多尺度适应能力。分析其原因,主要在于CNN模型本身具备一定范围的尺度适应能力,离散金字塔模型扩大了算法尺度适应的范围。
算法的旋转适应性试验结果如图 7所示。试验对第2幅影像以1°为步长,旋转360°,计算旋转后影像提取的特征和基准图上特征的余弦距离作为相似度指标。
图 7(b)为图 7(a)曲线的局部放大,从中可以看出,总体上算法不具备旋转不变性,但是在一定角度范围(约15°)内,特征相似性可以保持一个较好的水平。原因在于,本文算法并没有对CNN特征旋转不变性进行专门的设计,小角度下的不变性是CNN网络从具备一定角度变化的训练图像上学习得到的。因此,本文算法只适用于较小角度(约15°)变换影像的匹配。说明本文算法还有很大的提升空间,下一步对训练数据进行旋转增广,有可能改善这一性能。
另一方面,在工程应用中,遥感影像通常具有相对准确的轨道位姿态或者PRC等先验信息,预先可在一定的精度范围内计算影像之间在尺度和旋转角度上的几何差异,并进行消除。因此,匹配算法能够适应一定角度旋转和尺度变化即可满足实际要求。
2.3 关键点筛选试验由于异源影像特别是模式不同的影像(例如SAR和光学)特征相似性相对较弱,因此,筛选较多待选特征点的“以多求可靠”的策略是有必要的。试验选择250×250像素大小的SAR影像和无人机(UAV)光学影像进行特征点筛选,并可视化提取的特征图和关键点筛选结果,如图 8所示。

|
| 图 8 关键点选择试验结果 Fig. 8 Results of key points selection test |
从特征图可视化结果图 8(b)、图 8(e)可以看出,CNN通过多层卷积、池化后,提取出了更为抽象的局部特征。利用深度和局部极大值的原则,CMM-Net算法在无人机影像块上筛选出了436个特征,如图 8(c)所示;在SAR影像上筛选了358个特征,如图 8(f)。都提取出了较多的待选特征点,这为下一步特征匹配奠定了基础。
2.4 匹配性能对比试验 2.4.1 试验数据试验数据情况如表 2所示。测试数据源涵盖了星载传感器、无人机传感器、谷歌地球影像,波段和模式上包括了可见光、SAR、热红外、夜光遥感图像、栅格地图图像和深度图等。分辨率不同,影像模式多,时间与季节跨度大,对测试算法适应性具有很好的代表性。
| 组别ID | 1 | 2 | 3 | 4 | 5 | 6 |
| 参考影像类型 | 谷歌光学影像 | ZY-3 PAN光学影像 | 光学影像 | 光学影像 | 谷歌光学影像 | WorldView-2光学影像 |
| 分辨率/m | 0.5 | 2.5 | — | — | 15 | 2.0 |
| 影像尺寸/pix | 1500×1500 | 1000×1000 | 800×800 | 1000×1000 | 500×500 | 500×500 |
| 待匹配影像类型 | 谷歌光学影像 | GF-3 SL SAR影像 | 红外影像 | SNPP/VIIS夜光影像 | OpenStreetMap栅格地图 | Lidar深度图 |
| 分辨率/m | 0.5 | 1.0 | — | — | 15 | 2.0 |
| 影像尺寸/像素 | 1500×1500 | 2500×2500 | 800×800 | 1000×1000 | 500×500 | 500×500 |
| 特点 | 冬季与夏季、地物变化大 | 光学-SAR,尺度差异2.5倍 | 可见光-红外,不同波段,有一定旋转 | 昼夜不同 | 可见光-栅格地图不同模式 | 深度图-可见光不同模式 |
图 9为测试影像的缩略图。其中,第1组均为光学影像,但时间与季节跨度大、地物变化明显。第2组为资源3号全色影像和高分3号SAR影像,SAR影像分辨率为光学影像的2.5倍,并且SAR影像上存在较大噪音。第3组为气象卫星获取的可见光和红外波段影像,地物反射率明显不同,还存在一定旋转关系。第4组为光学影像与夜光遥感影像,在辐射上存在明显非线性畸变。第5组和第6组分别为光学影像与栅格地图影像、光学图像与LiDAR构建的深度晕渲图,具有完全不同的模式。

|
| 图 9 试验影像对数据 Fig. 9 Image pairs in the test |
2.4.2 评价指标
试验采用正确匹配点数量(NCM)、匹配准确率(SR)、匹配点均方根误差(RMSE)和匹配消耗时间(MT)来评价算法性能。指标说明如下。
2.4.2.1 正确匹配点数量(NCM)正确匹配点判断如式(7)所示
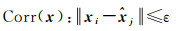 (7)
(7)
参考影像上通过算法匹配出的一个特征点位置xi,和理论点位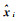
正确匹配点的数量为整幅影像上,满足上述条件的所有匹配点对的数量。影像配准等其他应用对正确匹配点的数量都有一定要求,该指标可以反映匹配算法的性能。
2.4.2.2 匹配准确率(SR)准确率表达为满足式(7)的正确匹配点数占算法给出的所有匹配点数(NTP)的百分比,这个指标可以反映出算法得到的匹配点对成功率。
2.4.2.3 匹配点均方根误差(RMSE)匹配点均方根误差RMSE可以反映匹配点的准确程度,计算公式为
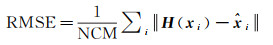 (8)
(8)
式中,NCM为正确匹配点的数量;H代表两张影像的真实变换模型,本文采用人工检查点拟合的仿射变换模型代替,该指标可以反映匹配点在像素上的位置偏移误差。
2.4.3 试验结果与分析试验比较了多种在多源影像匹配中比较有代表性的匹配算法,包括基于传统的影像互信息(MI)的匹配算法(商业软件ENVI v5.3实现)、基于深度学习特征的DELF与ContextDesc算法。其中,ContextDesc是专门为多模态影像设计的深度学习匹配算法。试验统计了各算法的正确匹配点数NCM、总匹配点数NTP以及正确匹配点的均方根误差RMSE,并计算了匹配点的准确率。精度阈值ε取3个像素,结果如表 3所示。
| 组别ID | 1 | 2 | 3 | 4 | 5 | 6 | |
| CMM-Net | NCM | 97 | 31 | 255 | 68 | 208 | 197 |
| NTP | 413 | 105 | 479 | 184 | 467 | 492 | |
| SR/(%) | 23 | 30 | 53 | 37 | 41 | 40 | |
| RMSE | 2.07 | 2.02 | 1.92 | 1.97 | 1.91 | 1.87 | |
| 耗时/s | 6.8 | 8.4 | 5.6 | 3.3 | 3.1 | 3.4 | |
| ENVI-MI | NCM | 19 | 0 | 0 | 37 | 163 | 68 |
| NTP | 75 | 38 | 26 | 129 | 213 | 98 | |
| SR/(%) | 25 | 0 | 0 | 29 | 77 | 69 | |
| RMSE | 1.75 | — | — | 1.86 | 1.39 | 1.64 | |
| 耗时/s | 35 | 38 | 30 | 26 | 24 | 25 | |
| RIFT | NCM | 127 | 0 | 141 | 121 | 336 | 342 |
| NTP | 539 | 336 | 436 | 385 | 1232 | 1094 | |
| SR/(%) | 23 | 0 | 32 | 31 | 27 | 31 | |
| RMSE | 1.737 | — | 3.24 | 1.091 | 1.856 | 1.120 | |
| 耗时/s | 7.9 | 8.6 | 6.7 | 4.8 | 4.3 | 4.2 | |
| DELF | NCM | 75 | 5 | 15 | 2 | 27 | 5 |
| NTP | 188 | 32 | 143 | 16 | 33 | 27 | |
| SR/(%) | 40 | 16 | 10 | 12 | 82 | 19 | |
| RMSE | 1.94 | 2.12 | 2.08 | 2.45 | 1.01 | 1.87 | |
| 耗时/s | 13.6 | 18.4 | 5.6 | 7.5 | 3.2 | 3.2 | |
| Context-Desc | NCM | 3 | 0 | 111 | 0 | 0 | 6 |
| NTP | 61 | 42 | 158 | 22 | 40 | 82 | |
| SR/(%) | 5 | 0 | 70 | 0 | 0 | 7 | |
| RMSE | 3.64 | — | 1.38 | — | — | 2.13 | |
| 耗时/s | 3.9 | 4.3 | 3.4 | 3.8 | 3.7 | 3.9 | |
通过对比分析表 3数据可知,在试验采用的6种不同模式的像对匹配中,本文提出的CMM-Net算法对所有像对均能给出一定数量的正确匹配点,匹配点均方根误差约2个像素。而ENVI-MI、RIFT、ContextDesc 3种算法对差异较大的SAR图像和可见光影像都没能匹配出正确的点。RIFT算法在尺度相同的多模式影像上,都取得了非常好的匹配效果。DELF算法虽然也有一定适应性,但匹配点数量明显偏少。ENVI-MI算法对红外和可见光的试验数据也未能正确匹配,ContextDesc算法对昼夜影像、地图与卫星影像的试验数据匹配未能成功。由此说明,在以上5种算法中,CMM-Net在多模态影像匹配适应性方面性能最为稳定。
从正确匹配点数量和精度上看,采用传统相位一致性匹配算法的RIFT总体上要优于CMM-Net。这是由于基于窗口模板匹配的定位精度要高于CNN特征,而基于滑动窗口的算法,可以提取更加密集的待匹配点。但从匹配准确率(SR)上看,CMM-Net相对高一些。此外,与适应性较强的RIFT和DELF算法相比,CMM-Net算法耗时最短。
2.4.4 匹配效果对比图 10、图 11和图 12直观显示了几种匹配算法的匹配效果。从中可以看出,CMM-Net除了可以匹配出数量较多的匹配点外,其分布也较为均匀。

|
| 图 10 可见光与红外影像(第3组)匹配结果 Fig. 10 Matching results of visible light and infrared images(Group 3) |

|
| 图 11 可见光与夜光遥感影像(第4组)匹配结果 Fig. 11 Matching results of visible light and luminous remote sensing images(Group 4) |

|
| 图 12 高分3号SAR影像与资源三号全色影像(第2组)匹配结果 Fig. 12 Matching results of GF-3 SAR image & ZY-3 image(Group 2) |
图 10的结果表明,对于有一定旋转的影像,CMM-Net获得了比RIFT更多的匹配点,主要原因在于,训练数据具有一定的视角变化,使得CMM-Net具有一定范围内的旋转不变性。从图 11也可以看出,CMM-Net和RIFT对夜光影像都取得了较多的匹配数量,DELF只匹配了很少数量的点,而ContextDesc算法则完全失效。图 12为尺度差异2.5倍的SAR影像和可见光影像,由于模式不同且噪音较大,参与比较的算法中,只有DELF和CMM-Net有效,并且CMM-Net在匹配数量和点位分布均匀性上都优于DELF,说明CMM-Net算法对噪音、模式变化适应性较好。
2.5 影像配准效果异源影像匹配的主要目的之一是影像配准,为了更好地说明CMM-Net算法的有效性,本文还在匹配算法的基础上,进行了影像配准试验。首先,根据CMM-Net匹配给出的匹配点组,计算仿射变换参数,再利用该参数对第一幅影像进行纠正,得到与第2幅影像配准的图像。配准的效果可以很好地反映匹配算法的精度,为便于检查,试验采用叠加开窗的显示方式。图 13为4组影像的配准效果图,配准图右侧为局部放大图。

|
| 图 13 影像配准结果 Fig. 13 Image registration results |
从配准结果可以看出,算法对SAR、红外、夜光以及栅格地图图像与可见光的配准图像上各区域的配准误差基本都控制在2像素以内,肉眼很难看出明显的错位,说明CMM-Net匹配效果良好。
3 结论与展望异源遥感影像之间由于成像模式、时相、分辨率等存在差异,匹配工作面临巨大的挑战。本文提出了一种基于卷积神经网络的匹配方法。试验结果表明,该异源影像匹配算法具有较强的稳健性,在适应性方面要强于其他几种算法,且在匹配点数量、分布、效率等方面都有一定优势。虽然该算法目前还无法完全超越基于人工设计的相位一致性匹配算法,但也为异源遥感影像稳健匹配提供了一种思路。但是,本文仅仅在利用卷积神经网络特征进行异源影像不变特征的提取与搜索匹配方面进行了探索和试验,还存在如下局限性:①受限于GPU内存,单次无法处理大像幅的影像;②从试验结果看,本文提出的CNN特征还很难做到子像素级精度的匹配;③算法流程中考虑先验几何约束信息较少。
因此,在进一步研究中,可以采用分块特征提取方法,突破GPU内存的限制;改进特征提取网络,做到子像素级的特征检测;在匹配算法流程中,还可以综合考虑先验的RPC或位姿参数、由粗到精的金字塔匹配策略以及物方约束等多种条件,提高匹配速度,并最大程度减小误匹配率,以增强工程实用性。
本文匹配算法源代码和测试数据开源在Github上(https://github.com/lan-cz/cnn-matching),供感兴趣的同行做进一步研究。
| [1] |
ZHAO Y, JIANG M, MA Z F. Integration of SAR polarimetric features and multi-spectral data for object-based land cover classification[J]. Journal of Geodesy and Geoinformation Science, 2019, 2(4): 64-72. |
| [2] |
李德仁. 展望大数据时代的地球空间信息学[J]. 测绘学报, 2016, 45(4): 379-384. LI Deren. Towards geo-spatial information science in big data era[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(4): 379-384. DOI:10.11947/j.AGCS.2016.20160057 |
| [3] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. DOI:10.1023/B:VISI.0000029664.99615.94 |
| [4] |
戴激光, 宋伟东, 李玉. 渐进式异源光学卫星影像SIFT匹配方法[J]. 测绘学报, 2014, 43(7): 746-752. DAI Jiguang, SONG Weidong, LI Yu. Progressive SIFT matching algorithm for multi-source optical satellite images[J]. Acta Geodaetica et Cartographica Sinica, 2014, 43(7): 746-752. DOI:10.13485/j.cnki.11-2089.2014.00 |
| [5] |
王峰, 尤红建, 傅兴玉, 等. 应用于多源SAR图像匹配的级联SIFT算法[J]. 电子学报, 2016, 44(3): 548-554. WANG Feng, YOU Hongjian, FU Xingyu, et al. Cascade SIFT matching method for multi-source SAR images[J]. Acta Electronica Sinica, 2016, 44(3): 548-554. |
| [6] |
叶沅鑫, 单杰, 熊金鑫, 等. 一种结合SIFT和边缘信息的多源遥感影像匹配方法[J]. 武汉大学学报(信息科学版), 2013, 38(10): 1148-1151, 1260. YE Yuanxin, SHAN Jie, XIONG Jinxin, et al. A node localization method in wireless sensor network based on k-means cluster[J]. Geomatics and Information Science of Wuhan University, 2013, 38(10): 1148-1151, 1260. |
| [7] |
王瑞瑞, 马建文, 陈雪. 多传感器影像配准中基于虚拟匹配窗口的SIFT算法[J]. 武汉大学学报(信息科学版), 2011, 36(2): 163-166. WANG Ruirui, MA Jianwen, CHEN Xue. SIFT algorithm based on visual matching window for registration between multi-sensor imagery[J]. Geomatics and Information Science of Wuhan University, 2011, 36(2): 163-166. |
| [8] |
DELLINGER F, DELON Julie, GOUSSEAU Y, et al. SAR-SIFT: a SIFT-like algorithm for SAR images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(1): 453-466. DOI:10.1109/TGRS.2014.2323552 |
| [9] |
凌志刚, 梁彦, 程咏梅, 等. 一种稳健的多源遥感图像特征配准方法[J]. 电子学报, 2010, 38(12): 2892-2897. LING Zhigang, LIANG Yan, CHENG Yongmei, et al. A robust multi-source remote-sensing image registration method based on feature matching[J]. Acta Electronica Sinica, 2010, 38(12): 2892-2897. |
| [10] |
KOVESI P. Image features from phase congruency[J]. Journal of Computer Vision Research, 1999, 1(3): 1-26. |
| [11] |
WONG A, CLAUSI D A. ARRSI: automatic registration of remote-sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2007, 45(5): 1483-1493. DOI:10.1109/TGRS.2007.892601 |
| [12] |
陈敏, 朱庆, 朱军, 等. 多光谱遥感影像亮度空间相位一致性特征点检测[J]. 测绘学报, 2016, 45(2): 178-185. CHEN Min, ZHU Qing, ZHU Jun, et al. Interest point detection for multispectral remote sensing image using phase congruency in illumination space[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(2): 178-185. DOI:10.11947/j.AGCS.2016.20150030 |
| [13] |
叶沅鑫, 单杰, 彭剑威, 等. 利用局部自相似进行多光谱遥感图像自动配准[J]. 测绘学报, 2014, 43(3): 268-275. YE Yuanxin, SHAN Jie, PENG Jianwei, et al. Automated multispectral remote sensing image registration using local self-similarity[J]. Acta Geodaetica et Cartographica Sinica, 2014, 43(3): 268-275. DOI:10.13485/j.cnki.11-2089.2014.0039 |
| [14] |
闫利, 王紫琦, 叶志云. 顾及灰度和梯度信息的多模态影像配准算法[J]. 测绘学报, 2018, 47(1): 71-81. YAN Li, WANG Ziqi, YE Zhiyun. Multimodal image registration algorithm considering grayscale and gradient information[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(1): 71-81. DOI:10.11947/j.AGCS.2018.20170368 |
| [15] |
LI Jiayuan, HU Qingwu, AI Mingyao. RIFT: multi-modal image matching based on radiation-variation insensitive feature transform[J]. IEEE Transactions on Image Processing, 2020, 29: 3296-3310. DOI:10.1109/TIP.2019.2959244 |
| [16] |
DOSOVITSKIY A, FISCHER P, SPRINGENBERG J T, et al. Discriminative unsupervised feature learning with exemplar convolutional neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(9): 1734-1747. DOI:10.1109/TPAMI.2015.2496141 |
| [17] |
龚健雅, 季顺平. 摄影测量与深度学习[J]. 测绘学报, 2018, 47(6): 693-704. GONG Jianya, JI Shunping. Photogrammetry and deep learning[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 693-704. DOI:10.11947/j.AGCS.2018.20170640 |
| [18] |
ZAGORUYKO S, KOMODAKIS N. Learning to compare image patches via convolutional neural networks[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 4353-4361.
|
| [19] |
范大昭, 董杨, 张永生. 卫星影像匹配的深度卷积神经网络方法[J]. 测绘学报, 2018, 47(6): 844-853. FAN Dazhao, DONG Yang, ZHANG Yongsheng. Satellite image matching method based on deep convolution neural network[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 844-853. DOI:10.11947/j.AGCS.2018.20170627 |
| [20] |
YANG Zhuoqian, DAN Tingting, YANG Yang. Multi-temporal remote sensing image registration using deep convolutional features[J]. IEEE Access, 2018, 6: 38544-38555. DOI:10.1109/ACCESS.2018.2853100 |
| [21] |
YE Famao, SU Yanfei, XIAO Hui, et al. Remote sensing image registration using convolutional neural network features[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(2): 232-236. DOI:10.1109/LGRS.2017.2781741 |
| [22] |
GONG J Y, JI S P. Photogrammetry and deep learning[J]. Journal of Geodesy and Geoinformation Science, 2018, 1(1): 1-15. |
| [23] |
YI K M, TRULLS E, LEPETIT V, et al. LIFT: learned invariant feature transform[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016: 467-483.
|
| [24] |
DETONE D, MALISIEWICZ T, RABINOVICH A. SuperPoint: self-supervised interest point detection and description[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, UT: IEEE, 2018: 224-236.
|
| [25] |
NOH H, ARAUJO A, SIM J, et al. Large-scale image retrieval with attentive deep local features[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 3456-3465.
|
| [26] |
DUSMANU M, ROCCO I, PAJDLA T, et al. D2-Net: a trainable CNN for joint description and detection of local features[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA: IEEE, 2019.
|
| [27] |
LUO Zixin, SHEN Tianwei, ZHOU Lei, et al. ContextDesc: local descriptor augmentation with cross-modality context[C]//The Processdings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA: IEEE, 2019: 2522-2531.
|
| [28] |
KAREN Simonyan, REW Zisserman. Very deep convolutional networks for large-scale image recognition[C]//Proceedings of the International Conference on Learning Representation. San-diego, California, USA: [s.n.], 2014.
|
| [29] |
MISHCHUK A, MISHKIN D, RADENOVIĆ F, et al. Working hard to know your neighbor's margins: local descriptor learning loss[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: Curran Associates Inc., 2017.
|
| [30] |
LI Zhengqi, SNAVELY N. MegaDepth: learning single-view depth prediction from internet photos[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, 2018.
|
| [31] |
SCHÖNBERGER J L, FRAHM J M. Structure-from-motion revisited[C]//The Processdings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 4104-4113.
|