



2. 南京师范大学虚拟地理环境教育部重点实验室, 江苏 南京 210093;
3. 武汉大学测绘遥感信息工程国家重点实验室, 湖北 武汉 430079;
4. 江苏省地理信息资源开发与利用协同创新中心, 江苏 南京 210023;
5. 地理环境演化模拟国家重点实验室建设培育点, 江苏 南京 210093
2. Key Laboratory of Virtual Geographic Environment, Ministry of Education, Nanjing Normal University, Nanjing 210093, China;
3. State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan 430079, China;
4. Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing 210023, China;
5. State Key Laboratory Cultivation Base of Geographical Environment Evolution, Nanjing Normal University, Nanjing 210093, China
随着三维空间信息的可用性不断提高,为了更好地理解现实世界,基于三维激光点云的场景智能解译近几年受到广泛关注[1]。其中,激光点云语义分割将每个点进行分类并分配语义标签给相同对象或区域,是场景建模、定位导航和城市规划等应用的基础[2]。
由于数据采集设备和方式的差异、场景复杂等,点云数据往往密度差异大、空间离散且分布不均、目标点云间存在重叠、遮挡、相似等,使得点云数据不完整或可用性不高、反射强度具有多样性等。众多学者围绕三维场景激光点云的语义分割展开了大量的研究。目前,对激光扫描数据进行语义分割方法从简单到复杂可以分为,逐点、逐块、逐对象分类以及整体场景空间平滑。
逐点分类[3-5]是将每个点作为处理的基本单元,以每个点邻域计算该点的局部描述子[6],将该点与上下文环境的关系作为特征,放到合适的分类器或概率估计模型中进行语义标签分配。近几年3D卷积神经网络(convolutional neural networks, CNN)的迅速发展,一些学者开始将CNN应用到逐点语义分割任务中[7-9]。基于CNN逐点分类一般采用端到端网络的逐点特征提取和池化操作解决无序点云问题,并结合了逐点低层次几何和高层次语义信息进行对象识别。逐点分类是三维点云分类中最基础、简单且易于实现的方式,具备一定推广性。但仍存在一些难以忽视的缺点:以点为对象导致计算量过大,并且分类结果往往伴随着椒盐噪声;缺少目标邻域间上下文和全局信息,无法有效提取细节信息。后续卷积神经网络少许解决了上述缺陷,但逐点卷积神经网络难以高质量地应用于大规模点云场景。
针对上述问题,逐块分类[10-11]首先将某些具有相似属性的点聚类为独立几何单元,然后对几何单元进行处理,最后各个块组合得到分类结果。其中,最常用的方法就是通过超体素[12-15]分割实现点云分块,该方法基于超体素的局部邻域代替点作为基本单元,通过监督分类地方式对点云进行语义标记,从而在复杂城市三维点云场景处理中取得了较好的效率。划分得到的点云块包含更多信息,有助于提高海量点云语义分割的精度;但点云分块操作将场景割裂、碎片化,使得难以有效提取上下文信息;同时在点云分块过程中涉及较多参数,不同场景需要采用不同的参数才能达到较好的结果。
逐点和逐块分类方法往往只利用了有限邻域范围内的信息,而且对一些特征表达较弱或者尺度较大对象难以实现精确识别与分类。逐对象方式[16-17]一般先从整个复杂场景提取某个目标,从而包含更加丰富的信息,然后综合局部、全局和上下文等多层次特征进行语义分割。该方法典型流程为确定目标的位置,分割得到单个对象、计算对象的特征及最后的分类。这种方式比较依赖先前目标提取的正确性,容易影响后续语义分割的精度。在先验信息或者模板匹配的辅助下,可以提高某些待识别地物目标的分割精度。一些方法[18-19]将城市场景中多对象进行了语义规则的概括与总结,从而提高了在遮挡和重叠的混乱情况下对象提取的准确性。相比之下,语义约束下的逐对象分割计算效率较高、识别速度较快、对特定目标识别率高;但只能应用于特定目标类别和场景,对于多目标复杂场景往往需要对每一类目标设定专门的语义规则,可推广能力较弱。
为了增强语义标签分配后的空间平滑度,需要考虑到相邻点之间的上下文联系[20]。该方法将相邻点之间构建一条特征边,每个点作为节点,从而构建出一个无向图。分类的同时考虑相邻边之间类别的作用关系,以图模型的形式导出上下文信息。对于多类别区域点云语义标记存在错误问题,一些后处理步骤(如马尔可夫随机场(Markov random field, MRF)[21]、全局图正则化[22]和条件随机场[23]等)利用上下文信息对初始语义标注结果进行优化,得到更准确的三维点云语义分割结果。由于在导出的标签上添加了空间平滑度,因此相应分类结果通常会得到显著改善。但是,在整体场景平滑过程中,推理策略的选择将对语义标记精度以及计算时间产生深远影响;同时相关图模型[24]的学习与推导是相当复杂且难以计算的。
尽管现有学者对点云语义分割方法展开了大量研究,但相比于硬件设备的进步,相关自动化算法研发仍处于发展的地位。针对一些算法在复杂场景中只能以较低精度进行有限类型对象的分类,本文提出一种从激光扫描数据中融合残差学习和MRF优化的层次化语义分割方法。
1 三维场景层次化语义分割方法本文的激光点云层次化语义分割方法主要包括数据预处理、建筑物提取、基于残差学习的逐点语义分割和MRF后端优化等4个步骤,如图 1所示。

|
| 图 1 本文算法流程 Fig. 1 Workflow of the proposed method |
1.1 预处理
点云数据存在各种系统和随机误差导致的噪声点,本节先采用点云库(point cloud library)封装的去噪算法[25]进行剔除。同时,鉴于三维激光扫描系统对地面有较为直接的扫描视角,三维激光点云数据中存在海量、高密度的地面点,这将增加三维语义分割时间和空间复杂度。为了从三维场景中快速、有效地滤除这些地面点,本节采用现有较为前沿的开源算法(布料模拟滤波算法[26]),从而有助于后续点云语义分割算法在数据搜索范围的减少和性能的提高。图 2示例了室外大规模点云场景地面点滤除的结果。

|
| 图 2 地面点滤波结果 Fig. 2 Illustration of the results for ground filtering |
1.2 建筑物提取
尽管对三维点云场景进行了地面点分离,避免非地面地物分类受到地面点的影响,然而后续处理中仍会受到三维点云复杂、遮挡等问题的影响。本文借鉴现有工作[27],先提取出场景中的建筑物点云以降低场景复杂度,同时提高与建筑物连接紧密对象的语义分割精度。针对不同结构建筑物之间紧密分布且被诸如植被等杂乱地物包围、遮挡的情形,本节提出了一个“两步法”框架对建筑物进行提取,结果见图 3。

|
| 注:绿色点表示建筑物点云。 图 3 建筑提取结果 Fig. 3 Illustration of the results for building segmentation |
(1) 利用立面特征进行建筑物目标检测。首先利用随机采样一致性(random sample consensus, RANSAC)算法[28]进行平面分割,然后在先验知识(如,墙体是垂直的;常规建筑是连接或者间隔分布且不重叠;城市道路环境的建筑结构基本上是严格符合城市规划规范)的约束下保留墙体结构;接着将墙体点云自上而下的映射得到二维线框,优化生成满足要求的矩形;最后利用该矩形在非地面点云场景中嵌套建筑物。
(2) 对初步检测的建筑物进一步提取以和周围复杂环境分离。第1步提取的建筑物点云混入了一些碎片化的地物,因此采用k最近邻(k-nearest neighbor, KNN)算法进行优化。KNN算法不需要类别判断来对待测数据进行标签分配,主要根据包含地物碎片的建筑物点云(待测数据)有限邻域范围内建筑物点云(已知数据)的特性,较为适用数据间存在较多重叠、交叉情况的处理。根据式(1)将局部几何特征、邻域之间的相似性以及平面形状特征构建k-NN图,转化成能量模型
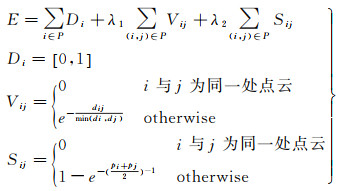 (1)
(1)
式中,利用高层次几何约束——平面形状先验知识来辅助建筑物目标的提取,避免基于局部邻域几何属性的点云分割中邻域大小的选择对于性能的影响,从而在目标间彼此靠近的情况下较为有效地确定相邻目标间边界。最后,通过基于最小化能量函数图割算法[29]对目标函数进行优化,剔除平面结构边缘或者附近的少量点。构建k-NN图后,基于最小化能量函数的建筑物分割示意见图 4。

|
| 图 4 最小化能量函数的建筑物分割 Fig. 4 2D example of segmentation by minimizing the energy function |
1.3 基于残差学习网络的点云分类
对于剩下的非结构化点云,本节对其输入到一种动态空间置换网络(spatial transform network, STN)[30]中,STN机制由回归网络T-Net和矩阵运算两部组成,为三维点云主动生成适当的空间变换。在三维点云上应用空间置换后,本文模型基于点的KNN搜索(式(2))[9]获取点邻域范围内的低层次几何特征
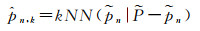 (2)
(2)
式中,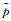
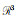
通过邻域搜索和坐标统一操作后,将n×k×6张量(其中n表示点的数量,k表示每个点的邻域数,维数6是点p的坐标和第k个最近邻点的统一坐标)通过全连接层添加到KNN模块以获得足够的表达能力从而将每个点特征转换为高维特征,然后应用逐点局部池化层以生成低层次几何特征。在逐点局部池化层之后,每个点都表示为一个64维向量。因此,三维点云可以表示为n×64维特征,即{v1, v2, …, vN|vn∈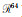
网络的第2个模块中,输入端(n×128张量)投到一系列点卷积连接层,以获取高层次语义特征。在多连接卷积层构建过程中,考虑到现有方式逐渐增加每一层内核半径会花费更多时间收敛,本节对所有层使用固定核半径进行点特征学习,然后在每一层空洞卷积中逐步增加步幅(stride)。
为了避免梯度消失,往往需要进行更深层次的训练。本节引入残差学习[31]的概念,添加了跳跃层(skip)来加强信号间的身份(identity)映射,如图 5所示。在学习过程中,本文模型将每一个残差学习结果又添加到多个卷积层,从而保证了每个层的身份映射。更具体地说,映射函数H(x)在输入信号x到第1个堆叠的卷积层后进行拟合。那么可以通过多个非线性堆叠层渐近地逼近残差函数,即当输入与输出的维数相同时,H(x)-x。本节在拟合过程中,将残差函数F(x)代替映射函数H(x),与具有多个非线性堆叠层的拟合相比,具有残差函数的近似身份映射更容易。最主要的是,设计一个最佳函数并且更接近于身份映射(而不是零映射),那么求解器将更容易找到参考身份映射的扰动。

|
| 图 5 基于残差学习的语义分割网络架构 Fig. 5 Proposed Deep Point based Residual Network architecture for semantic segmentation |
通过在多个卷积层之间搭建跳跃连接层,对特征图之间的每个通道执行逐信号添加。这不需要额外的参数或训练时间,并且允许较低的层通过跳过中间层而直接跳向较高的层。因此,这种跳跃连接层的添加允许在网络结构中集成更多基于点的卷积层,从而提高性能。
随机梯度下降(stochastic gradient descent, SGD)算法在训练过程中一般使用批处理归一化。与之不同的是,本节采用的是比例指数线性单元(scaled exponential linear units, SELU),这是一种自归一化激活函数[32],通过激活神经元以自动方式收敛至零均值和单位方差来诱导自归一化特性。与其他激活函数相比,它们具有更快、更好的学习能力。如前文所述,本文逐渐增加了每层卷积步幅参数,并在第3层中简单地将第1层的输出添加到下一层,使网络模型具备了对应的残差。虽然,每层的步幅参数逐渐增加会扩大内核的感知范围,但不会改变层的输出尺寸。通过训练SELU激活函数之前和之后增加层以及使用激活前的剩余模块(其中激活层)在卷积层之前来分析了基于点的残差网络的性能,对网络中信号传导进行约束。最后将串联的所有层输出要素传递给全连接层。
全连接层的输出张量(n×256)馈入逐点局部池化层,该层为每个点生成高层次语义特征。逐点局部池化后,每个点都表示为512维向量。残差学习模块学习从输入点云中提取(n×512)维高层次语义特征。最后的全局池化层操作获取了1024维全局特征以保留更多的语义信息,池化操作降低了由高维特征向量引起的计算复杂性,使本文模型对于输入排列不变。
特征学习过程将3个输出向量(低层次几何向量,高层次语义向量和全局特征向量)连接为1664维特征向量。然后,将此向量输入到4个全连接层中,以获得最终的分类结果,该结果由n个点的和l个语义类别的n×l分数组成。
1.4 后端优化复杂三维场景中对象间的相似性,使得标签分配结果中往往存在小部分类别错误。因此,大范围三维点云语义分割的准确性不仅依赖于对象的高层次特征,也需要完全理解中层次或低层次细节信息,这对于确保每个点标签预测的一致性是至关重要的。大多数工作采用条件随机场获取场景中目标的上下文信息来改善局部相似性导致的错误分类。但是先前工作只利用临近物体间小范围上下文信息,本节则构建马尔可夫随机场有效利用远距离上下文信息,拟合三维点云场景中目标间标签。本节算法引入区域标签惩罚项,减少一定区域使用过多标签来优化语义分割精度。马尔可夫随机场能量函数定义如下
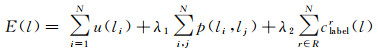 (3)
(3)
式中,u(li)和p(li, lj)是一元能量项和二元能量项;一元能量项表示来自分类器的预测,二元能量项主要用于对类别预测结果的平滑。第3能量项clabelr(l)是通过对区域标签的惩罚来约束每一个类别的目标识别率与其语义标签之间的相互一致性,使语义识别率高的对象被赋予正确标签。R是三维点云场景中所有区域的集合,r表示区域集合中的一个区域。参数λ1和λ2是平衡各个能量项的权重。本节通过网格搜索来学习这些权重,并在所有试验中保持它们不变。最后,通过最小化式(3)中定义的能量函数E(l)来实现语义分割。
2 试验与分析 2.1 测试数据本文在3个不同的大规模室外点云场景上进行测试来验证所提方法的性能。这3个数据分别是湖北省黄石市城区MLS点云数据[33](被测道路总长度为33.5 km,原始数据集大小为11.7 GB)、Semantic3D激光点云公开基准数据集[34](数据集由30个地面激光扫描组成,具有40亿个点,并且包含城市和乡村场景)和某大学校园多视TLS点云配准数据(该场景数据范围达0.62 km,总点数为2.6亿,平均点密度2034 points/m2)。这些数据集具有代表性和较大的挑战性:①数据集由不同视角、测量范围和测量精度的激光扫描系统采集得到;②数据海量,每个数据集包含几亿到数10亿个点;③测试数据集涵盖了城区、高速和校园等多种场景,这些场景在土地覆盖类型和地物表面几何结构上都存在显著差异;④点云数据集中包含常见的多种目标,且相互遮挡。
2.2 评价指标本文利用精确度(precision)、召回率(recall)、F1分数(F1-score)3个指标对语义分割结果进行质量评价,计算公式如下
 (4)
(4)
式中,TP、FP和FN分别为语义标注正确的目标个数、错误标注的目标个数和漏标注的目标个数。召回率越高,说明模型对正样本的标注性能越好;精确度越高,说明模型对负样本的区分能力越强。F1-score是两者的综合,F1-score越高,说明分类模型越稳健。
2.3 试验结果和分析为了测试本文方法的性能,本节首先分析了超参数k对试验结果的影响。然后在以下条件对结果进行了比较:①比较多个模块对性能的影响;②为了验证设计用于优化分类结果的MRF的可行性,在有和没有MRF的情况下进行了比较。定量和定性结果均证明了本文方法的有效性。最后,本文分别在3种不同类型三维激光点云数据集展示本文提出框架在大场景点云语义分割的结果。
2.3.1 超参数分析本节主要分析KNN模块中k对模型性能的影响。具体来说,在Semantic3D数据集上进行了多次试验。k的大小与分类精度之间的关系如图 6所示。随着k值的增加,分类精度也增加。但是,当k值超过16时,分类精度只会非常缓慢地提高。根据这些试验结果,设置KNN的值为16。

|
| 图 6 KNN模块中k不同设置的定量比较 Fig. 6 Quantitative comparisons of different settings in the KNN module |
2.3.2 消融试验
考虑到本文采用的网络架构由多个模块组成,为了研究关键模块的性能,本节在Semantic3D数据集上进行了消融分析,即对神经网络体系结构的不同设计进行了比较。结果报告在表 1中(◎表示所测试网络集成了该模块),第1行显示仅带有STN模块的基本版本的结果,第2行显示STN和KNN模块的集成结果,第3行显示STN和残差学习模块的集成结果。结果表明,单独引入KNN和残差学习模块可以将性能分别提高(4.1%,3.9%,3.7%)和(5.5%,6.3%,6.2%)。当所有3个模块集成在一起时,如最后一行所示,各项指标分别达到88.5%、90.5%和89.2%。
| STN模块 | KNN模块 | 残差模块 | 召回率/(%) | 精确度/(%) | F1值/(%) |
| ◎ | 80.6 | 81.9 | 81.5 | ||
| ◎ | ◎ | 84.7 | 85.8 | 85.2 | |
| ◎ | ◎ | 86.1 | 88.2 | 87.7 | |
| ◎ | ◎ | ◎ | 88.5 | 90.5 | 89.2 |
通过表 1分析,不难发现:①不同的模块对分类性能都有着一定的贡献,通过增加更多的模块可以进一步提高最终分类性能。②在具体语义分割任务中,高层次语义特征比低层次几何特征更重要,这充分说明残差模块有效地提取了高层次语义特征。该结果再次证实了本文网络在3D语义分割中提取多层次特征的有效性。
2.3.3 后端优化性能分析为了评估后端的有效性,本节测试了基于马尔可夫随机场以获得最佳全局结果。在此,平衡各个能量项的权重参数λ1和λ2皆被设置为1.0。表 2给出了初始分类结果和优化分类结果的比较。可以看出,后端优化使各项指标分别提高了0.3%、0.4%和0.6%,总体性能显示出明显的改善。
| 结果 | 召回率 | 精确度 | F1值 |
| 初始结果 | 87.9 | 89.7 | 88.8 |
| 优化结果 | 88.2 | 90.1 | 89.4 |
2.3.4 试验结果展示
图 7、图 8和图 9分别展示了本章所提出算法在湖北省黄石市MLS数据集、Semantic3D数据集和校园多视配准数据集的三维语义标记结果,表 3显示了在这3个数据集上的语义分割各项指标。总体来说本文算法在大规模高分辨率点云语义标记上取得了较为满意的结果。尽管由于目标间的局部相似性及同类物体的差异性,导致初始点云语义分割的结果存在一定错误标注,但是基本上还是正确分类的。

|
| 图 7 黄石市城区MLS点云数据集原始点云和语义分割结果 Fig. 7 Semantic segmentation outcomes from MLS data in Huangshi |

|
| 图 8 基于本文算法的Semantic3D数据集语义标记结果 Fig. 8 Semantic segmentation outcomes from Semantic 3D data |

|
| 图 9 某大学校园多视TLS点云试验区域点云语义分割结果 Fig. 9 Semantic segmentation outcomes from TLS data in campus |
| 物体 | 黄石市MLS数据 | Semantic 3D数据 | 校园TLS数据 | ||||||||
| 召回率 | 精确度 | F1值 | 召回率 | 精确度 | F1值 | 召回率 | 精确度 | F1值 | |||
| 车辆 | 65.7 | 88.4 | 77.9 | 83.5 | 83.4 | 83.4 | 88.9 | 87.3 | 88.5 | ||
| 建筑 | 99.1 | 96.5 | 97.0 | 98.1 | 94.5 | 96.2 | 93.8 | 93.9 | 93.8 | ||
| 护栏 | 90.1 | 82.5 | 86.4 | 5.7 | 10.6 | 7.2 | 84.8 | 86.1 | 85.7 | ||
| 路灯 | 77.0 | 78.9 | 78.0 | — | — | — | — | — | — | ||
| 地面 | 96.7 | 98.1 | 97.3 | 98.2 | 98.8 | 98.5 | 98.9 | 98.1 | 98.5 | ||
| 杆状 | 90.1 | 91.8 | 91.2 | — | — | — | 89.2 | 87.1 | 88.4 | ||
| 标牌 | — | — | — | — | — | — | 90.1 | 93.5 | 92.4 | ||
| 路肩 | 97.5 | 89.1 | 93.2 | — | — | — | — | — | — | ||
| 树木 | 95.1 | 97.5 | 96.8 | 98.4 | 85.7 | 91.9 | 86.7 | 80.9 | 84.3 | ||
| 灌木 | — | — | — | 48.7 | 93.8 | 62.2 | — | — | — | ||
| 草坪 | — | — | — | 96.2 | 94.5 | 95.2 | — | — | — | ||
| 花坛 | — | — | — | 73.1 | 51.8 | 61.2 | — | — | — | ||
| 电线 | 77.9 | 90.5 | 85.4 | — | — | — | — | — | — | ||
| 其他 | 86.6 | 98.2 | 92.3 | 89.3 | 88.7 | 89.0 | 69.3 | 80.1 | 75.2 | ||
| 平均 | 94.6 | 96.8 | 95.7 | 88.5 | 90.5 | 89.2 | 92.3 | 92.2 | 92.3 | ||
2.4 试验设置
本文采用召回率、精确度、F1值和时间消耗定量评估本文方法的性能。深度神经网络的训练和测试是通过TensorFlow实施的,且利用开源工具(CloudCompare)手工标记训练数据和定量分析的真值。
在训练深度神经网络之前,训练和测试场景点云被划分为没有重叠且数量相同的3D子点集,子点集中的每个点都由具有三维坐标和强度的4D向量表示。同时生成了多尺度点集并进行网络训练,从而获得了不同层次信息。为了评估本文网络在训练过程中的性能,直接选择10%的训练样本进行验证。本文网络配置设置如下:损失函数为 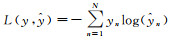
为了进一步分析本文框架的性能,在3种不同类型点云数据集,用上述4个指标与当前较前沿的三维点云语义分割算法[17-18]进行了比较。从表 4不难发现,本文提出的结合残差学习和后端优化的层次化语义分割方法在城区、高速和校园等多类型激光点云场景中取得了较高精确度和召回率,相比对比算法[17-18]提高了3%~5%。而且在上述类型场景的三维激光点云语义分割中取得了较高计算效率。总体而言,本文三维激光点云语义分割结果基本满足数字城管、道路基础设施入库、城市规划和高精驾驶地图生产等应用需求。
3 结语
本文以激光点云数据为研究对象,提出了一种适合复杂环境的结合残差学习和MRF优化的层次化语义分割方法。该方法:①提出多目标层次化提取,特别是地面点和建筑物的提取,减少了数据冗余并加快了运算速度;②提出了基于残差学习的卷积网络结构,不需要额外的体素化步骤,能够执行逐点语义分割;③使用MRF优化算法,确保逐点语义标签分配的一致性并改善语义分割结果,提高了语义分割的正确率。采用3个不同类型的大规模激光点云场景对方法进行了测试并对其精度、效率进行了评价与比较。试验验证结果佐证了上述结论,同时通过相关指标比较表明,在3个不同场景中,本文在分割精度和计算复杂度方面优于比较方法。总体而言,本文提出的框架在大型点云场景下可以更有效地实现语义分割。
| [1] |
杨必胜, 董震. 点云智能研究进展与趋势[J]. 测绘学报, 2019, 48(12): 1575-1585. YANG Bisheng, DONG Zhen. Progress and perspective of point cloud intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(12): 1575-1585. DOI:10.11947/j.AGCS.2019.20190465 |
| [2] |
杨必胜, 梁福逊, 黄荣刚. 三维激光扫描点云数据处理研究进展、挑战与趋势[J]. 测绘学报, 2017, 46(10): 1509-1516. YANG Bisheng, LIANG Fuxun, HUANG Ronggang. Progress, challenges and perspectives of 3D LiDAR point cloud processing[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(10): 1509-1516. DOI:10.11947/j.AGCS.2017.20170351 |
| [3] |
WEINMANN M, JUTZI B, HINZ S, et al. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 105: 286-304. DOI:10.1016/j.isprsjprs.2015.01.016 |
| [4] |
LANDRIEU L, RAGUET H, VALLET B, et al. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 132: 102-118. DOI:10.1016/j.isprsjprs.2017.08.010 |
| [5] |
熊艳, 高仁强, 徐战亚. 机载LiDAR点云数据降维与分类的随机森林方法[J]. 测绘学报, 2018, 47(4): 508-518. XIONG Yan, GAO Renqiang, XU Zhanya. Random forest method for dimension reduction and point cloud classification based on airborne LiDAR[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(4): 508-518. DOI:10.11947/j.AGCS.2018.20170417 |
| [6] |
ZHU Zan, GAN Shu, WANG Jianqi, et al. A Novel airborne 3D laser point cloud hole repair algorithm considering topographic features[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 29-38. |
| [7] |
赵传, 郭海涛, 卢俊, 等. 基于深度残差网络的机载LiDAR点云分类[J]. 测绘学报, 2020, 49(2): 202-213. ZHAO Chuan, GUO Haitao, LU Jun, et al. Airborne LiDAR point cloud classification based on deep residual network[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(2): 202-213. DOI:10.11947/j.AGCS.2020.20190004 |
| [8] |
HUA B S, TRAN M K, YEUNG S K. Pointwise convolutional neural networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 984-993.
|
| [9] |
ZHANG Dejun, HE Fazhi, TU Zhigang, et al. Pointwise geometric and semantic learning network on 3D point clouds[J]. Integrated Computer-Aided Engineering, 2020, 27(1): 57-75. |
| [10] |
LUO Huan, WANG Cheng, WEN Chenglu, et al. Patch-based semantic labeling of road scene using colorized mobile LiDAR point clouds[J]. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(5): 1286-1297. DOI:10.1109/TITS.2015.2499196 |
| [11] |
罗海峰, 方莉娜, 陈崇成, 等. 基于DBN的车载激光点云路侧多目标提取[J]. 测绘学报, 2018, 47(2): 234-246. LUO Haifeng, FANG Lina, CHEN Chongcheng, et al. Roadside multiple objects extraction from mobile laser scanning point cloud based on DBN[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(2): 234-246. DOI:10.11947/j.AGCS.2018.20170524 |
| [12] |
WANG Hanyun, WANG Cheng, LUO Huan, et al. 3-D point cloud object detection based on supervoxel neighborhood with Hough forest framework[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(4): 1570-1581. DOI:10.1109/JSTARS.2015.2394803 |
| [13] |
董震, 杨必胜. 车载激光扫描数据中多类目标的层次化提取方法[J]. 测绘学报, 2015, 44(9): 980-987. DONG Zhen, YANG Bisheng. Hierarchical extraction of multiple objects from mobile laser scanning data[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(9): 980-987. DOI:10.11947/j.AGCS.2015.20140339 |
| [14] |
李明磊, 刘少创, 杨欢, 等. 双层优化的激光雷达点云场景分割方法[J]. 测绘学报, 2018, 47(2): 269-274. LI Minglei, LIU Shaochuang, YANG Huan, et al. Bilevel optimization for scene segmentation of LiDAR point cloud[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(2): 269-274. DOI:10.11947/j.AGCS.2018.20170493 |
| [15] |
XU Yusheng, YE Zhen, YAO Wei, et al. Classification of LiDAR point clouds using supervoxel-based detrended feature and perception-weighted graphical model[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 72-88. DOI:10.1109/JSTARS.2019.2951293 |
| [16] |
BABAHAJIANI P, FAN Lixin, GABBOUJ M. Object recognition in 3D point cloud of urban street scene[C]//Computer Vision-ACCV Workshops. Singapore: Springer, 2014: 177-190.
|
| [17] |
YANG Bisheng, DONG Zhen, LIU Yuan, et al. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 126: 180-194. DOI:10.1016/j.isprsjprs.2017.02.014 |
| [18] |
YANG Bisheng, DONG Zhen, ZHAO Gang, et al. Hierarchical extraction of urban objects from mobile laser scanning data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 99: 45-57. DOI:10.1016/j.isprsjprs.2014.10.005 |
| [19] |
TEO T A, CHIU C M. Pole-like road object detection from mobile LiDAR system using a coarse-to-fine approach[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(10): 4805-4818. DOI:10.1109/JSTARS.2015.2467160 |
| [20] |
LIU Xiaoqiang, CHEN Yanming, LI Shuyi, et al. Hierarchical classification of urban ALS data by using geometry and intensity information[J]. Sensors, 2019, 19(20): 4583. DOI:10.3390/s19204583 |
| [21] |
WANG Yongjun, JIANG Tengping, YU Min, et al. Semantic-based building extraction from LiDAR point clouds using contexts and optimization in complex environment[J]. Sensors, 2020, 20: 3386. DOI:10.3390/s20123386 |
| [22] |
LI Nan, LIU Chun, PFEIFER N. Improving LiDAR classification accuracy by contextual label smoothing in post-processing[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 148: 13-31. DOI:10.1016/j.isprsjprs.2018.11.022 |
| [23] |
WANG Y, JIANG T, LIU J, et al. Hierarchical instance recognition of individual roadside trees in environmentally complex urban areas from UAV laser scanning point clouds[J]. ISPRS International Journal of Geo-Information, 2020, 9(10): 595. DOI:10.3390/ijgi9100595 |
| [24] |
ZHANG Liangpei, ZHANG Yun, CHEN Zhenzhong, et al. Splitting and merging based multi-model fitting for point cloud segmentation[J]. Journal of Geodesy and Geoinformation Science, 2019, 2(2): 78-89. |
| [25] |
RUSU R B, COUSINS S. 3D is here: Point cloud library (PCL)[C]//2011 IEEE International Conference on Robotics and Automation. Shanghai, China: IEEE, 2011: 1-4.
|
| [26] |
ZHANG Wuming, QI Jianbo, WAN Peng, et al. An easy-to-use airborne LiDAR data filtering method based on cloth simulation[J]. Remote Sensing, 2016, 8(6): 501. DOI:10.3390/rs8060501 |
| [27] |
XIA Shanbo, WANG Ruisheng. Extraction of residential building instances in suburban areas from mobile LiDAR data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 144: 453-468. DOI:10.1016/j.isprsjprs.2018.08.009 |
| [28] |
SCHNABEL R, WAHL R, KLEIN R. Efficient RANSAC for point-cloud shape detection[J]. Computer Graphics Forum, 2007, 26(2): 214-226. DOI:10.1111/j.1467-8659.2007.01016.x |
| [29] |
KOLMOGOROV V, ZABIN R. What energy functions can be minimized via graph cuts?[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(2): 147-159. DOI:10.1109/TPAMI.2004.1262177 |
| [30] |
QI C R, SU Hao, MO Kaichun, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 77-85.
|
| [31] |
ARSHAD S, SHAHZAD M, RIAZ Q, et al. DPRNet: Deep 3D point based residual network for semantic segmentation and classification of 3D point clouds[J]. IEEE Access, 2019, 7: 68892-68904. DOI:10.1109/ACCESS.2019.2918862 |
| [32] |
KLAMBAUER G, UNTERTHINER T, MAYR A, et al. Self-normalizing neural networks[C]//31st Conference on Neural Information Processing Systems. Long Beach, CA: [s.n.], 2017: 971-980.
|
| [33] |
XIANG Binbin, YAO Jian, LU Xiaohu, et al. Segmentation-based classification for 3D point clouds in the road environment[J]. International Journal of Remote Sensing, 2018, 39(19): 6182-6212. DOI:10.1080/01431161.2018.1455235 |
| [34] |
HACKEL T, SAVINOV N, LADICKY L, et al. SEMANTIC3D.NET: A new large-scale point cloud classification benchmar[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2017, IV-1/W1(91): 98. |