



2. 南京林业大学林学院, 江苏 南京 210037;
3. 马萨诸塞大学阿默斯特分校地球科学系, 美国 马萨诸塞州 01003;
4. 安徽省地理信息智能感知与服务工程实验室, 安徽 滁州 239000;
5. 滁州学院地理信息与旅游学院, 安徽 滁州 239000
2. College of Forest, Nanjing Forestry University, Nanjing 210037, China;
3. Department of Geosciences, University of Massachusetts, Massachusetts 01003, USA;
4. Anhui Engineering Laboratory of Geographical Information Intelligent Sensor and Service, Chuzhou 239000, China;
5. School of Geographic Information and Tourism, Chuzhou University, Chuzhou 239000, China
随着遥感技术和对地观测技术的快速发展,来自卫星、无人机等对地观测海量数据不仅含有丰富的纹理、空间信息,还包含了海量场景语义信息,因此高分辨率遥感影像的信息提取已经逐步从像素层的光谱解译、结构层的基元纹理分析以及面向对象的分割处理发展向规则知识、语义识别和场景建模等影像高层理解与认知方向发展[1]。高分辨率遥感影像分类从传统像素级和对象级分类渐渐转向场景语义级分类[2-4]。
目前,已有场景分类方法可概括为两类:①基于底层特征和中层特征的方法。早期基于传统的底层特征或者手工特征,通过提取纹理、颜色、形状等特征进行图像分类。与早期方法相比,基于BoVW模型[5]的中层特征方法通过手工制作的底层特征构建图像直方图,对图像聚类分析,虽简单高效,但表达能力有限。②深度学习模型方法。卷积神经网络(convolutional neural network, CNN)一经提出,便凭借其强大的特征提取能力很快成为众多领域学者关注的焦点[6-8]。针对高分辨率场景分类问题,大量深度学习模型网络被构建,如GoogleNet、VggNet和ResNet等,使得深度学习在场景分类中的准确率不断得到提高。同时遥感的一个重要里程碑仍然是对来自于不同传感器和地理区域的未知数据进行分类的模型的可移植性[9],迁移学习则可以有效解决这些问题[10],基于具有1500万张已标注高清图片和22 000多种场景类别的ImageNet[11]图像库,可以让计算机具有跨领域学习的能力,同时使得信息可以得到高效重复利用[12]。文献[13]首次将深度学习卷积网络应用于高分辨率遥感影像场景分类问题,将ImageNet图像数据上预训练的深度卷积神经网络模型迁移至遥感场景数据集,得到较好的分类效果。文献[14]采用两个小尺度遥感影像场景数据集测试了不同深度的卷积神经网络分类性能,有效解决了高分辨率遥感影像数据量大、信息复杂、特征信息提取难度高等难题[15]。
卷积神经网络模型对大型、未知形状变换的建模存在固有的缺陷,这种缺陷是因为标准卷积神经网络卷积核为方形,在特征图谱上的固定位置进行采样,对于复杂不规则的目标或者大小不一的目标检测是不合理的。文献[16]提出了一种可变形卷积方法,提升了CNN的形变建模能力,首次证明了学习密集空间变换对复杂的视觉任务是有效的。文献[17]基于VggNet模型采用可变形卷积层得到图像特征进行图像语义分割方法,表明引入可变形卷积的分割方法可有效克服遥感影像中分割对象的复杂结构对分割结果的影响。可见在图像分割中引入可变形卷积的CNN模型在性能上得到了较大提升。而在遥感场景分类中同样面对同种物体在图像中可能呈现出不同的形态、大小、视角变化甚至是非刚性形变的问题,在分类任务上采用固定方形的卷积核对具有复杂目标的特征识别是不合理的,仅使用传统的深度特征无法学习到对遥感场景几何形变具有稳健性的特征表示。基于以上分析,本文提出了一种场景分类方法,利用大型自然场景数据集ImageNet上训练的模型提取遥感影像深度特征,然后引入可变形卷积层,增强空间采样位置能力进而提高场景分类精度。
1 原理与方法本文提出的深度迁移可变形卷积神经网络(deep transfer deformable convolutional neural networks, DTDCNN)模型结构如图 1所示。该结构主要分为两大部分:①利用大型自然场景数据集ImageNet对基础模型进行训练得到预训练模型;②在对目标数据集进行训练时,首先利用预训练模型中全连接层(fully connected layer, FC)前的模型提取特征作为图像特征表达,然后添加可变形卷积层进一步学习遥感影像的几何形变信息,提高感受野对目标物体的有效感受范围以得到最终图像特征,最后输入到分类器进行分类。

|
| 图 1 DTDCNN模型结构 Fig. 1 Structure diagram of DTDCNN model |
1.1 深度特征提取
卷积神经网络作为深度学习的一个重要算法,在模式分类领域有着出色表现。经典卷积神经网络主要包括卷积层、池化层和全连接层,其中卷积层通过计算输入影像中的局部区域与滤波器的点积输出特征[18]。本文中遥感影像场景分类数据是三通道的,每个卷积核的尺寸为r×s×e,其中e为通道数,本文中e=3,卷积操作如式(1)所示
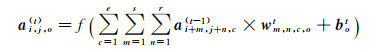 (1)
(1)
式中,f(·)为逐元素运算的激活函数(activation function);s和r是感受野的空间尺寸;b为偏置项;a(t-1)、a(t)分别为t-1层和t层的响应;w为权值。
经过多次卷积导致特征数据量不断增加,故在卷积后须添加池化层,通过计算局部区域上的聚合值,沿着特征图的空间维度进行下采样操作,在减少参数数量的同时能较好地保留原始有用信息,防止过拟合问题发生[19]。经过特定的第t层的池化层后,第t层第o个特征图在空间位置(i, j)处的元素可表示为
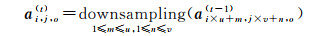 (2)
(2)
式中,u×v大小的区域成为池化邻域,也称为池化感受野,通常情况下u=v。
最后,基于卷积和池化操作的特征进行压缩,所得压缩特征与全连接层所定义权重参数相乘,将输入图像分类为基于数据集的各类别,第t层的每个神经元和第t-1层的每个神经元都连接,即每个神经元的输入是上一层所有神经元的输出线性组合。全连接层第i个神经元的值可表示为
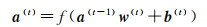 (3)
(3)
多项研究表明,在大型自然图像数据集ImageNet上学习到的图像特征对遥感图像也有很好的适用性[20-22],因此,本文利用预训练模型提取遥感场景的深度特征,将该深度特征作为整个遥感场景特征的一部分。
1.2 可变形特征学习由于传统二维卷积核通常首先在输入的影像特征图上采用网格R进行采样,并且在每个采样点处乘上权值k并求和,因此仅使用传统的深度特征无法学习到对遥感场景几何形变具有稳健性的特征表示。以二维3×3卷积核采样为例R=(-1, -1), (-1, 0), …, (0, 1), (1, 1),对于输出特征图y上的位置P0为
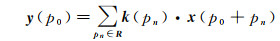 (4)
(4)
式中,Pn为网格R中所列位置的枚举,固定了感受野的大小与步长,则无法对易产生变形的物体特征进行准确描述,使得传统CNN在一定程度上限制了建模能力。
因此,本文利用可变形卷积(deformable convolution)增加模型对于物体几何变化的适应能力[23],学习对影像中几何形变稳健的深度特征,具体的,通过对卷积采样点添加偏移量{Δpn|n=1, 2, …, N},其中N=|R|,使得式(4)变形为
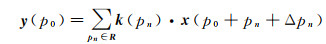 (5)
(5)
式中,pn表示卷积窗口中任意一个像素点;k(pn)表示像素点pn的权重;x表示输入层像素点的集合;Δpn表示像素点pn的偏移量,且通常为小数形式。因此式(5)通过双线性插值变换之后变为
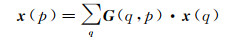 (6)
(6)
式中,p表示任意一个位置p=p0+pn+Δpn;q则表示特征图中的空间位置;G(·, ·)表示双线性插值核,二维卷积则可分解成2个一维内核
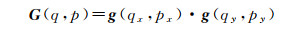 (7)
(7)
式中,g(a, b)=max(0, 1-a-b)。
标准卷积在对稀疏住宅场景进行特征提取时的采样点是固定的(图 2(a)),而本文通过引入可变形卷积层会根据影像中目标的尺度和形状进行自适应调整(图 2(b)),可以高效地提取不同形状、不同方向的稳健特征,从而增强对影像中的场景辨别能力。图 2中圆点表示读取图像特征图中的激活单元点,箭头后单元点表示分别对应于前面特征图上突出显示的单元点,可变形卷积收敛后的单元点与物体位置的相关性则更高,可以更高效地利用对象特征。

|
| 图 2 采样位置 Fig. 2 Sampling position |
为了学习对遥感场景几何形变具有稳健性的特征表示,本文在预训练模型的基础上添加了可变形卷积层,联合传统场景深度特征以及可变形场景深度特征对整个场景影像进行特征表达,提高模型的稳健性的泛化能力。
1.3 模型优化深度学习算法中损失值用来度量模型在分类时预测值和真实值之间的差距,也是用来衡量模型泛化能力好坏的重要指标,损失函数合理性则决定模型的拟合能力。对于遥感影像场景分类任务,本文采用交叉熵损失函数,表示为
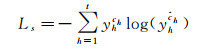 (8)
(8)
式中,t为每批次样本数;yh为第h个样本的编号;ch是样本的目标类。利用随机梯度下降(stochastic gradient descent, SGD)方法对该损失函数进行优化,通过从样本中抽取一组进行训练得到函数局部最优值,再按照梯度方向不断进行更新、再抽取训练、更新,最终获取全局最优损失值。本文中随机梯度下降的学习率使用固定大小值,初始学习率大小设置为0.002,速度衰减因子设为0.9。
2 试验分析 2.1 试验设置 2.1.1 参数设置与试验环境本文试验环境为Windows10 64 bit操作系统,CPU为Core i5-7500@3.40 GHz,16 GB内存,GPU为Nvidia GeForce GTX 1060, 6 GB显存。深度学习工具采用PyTorch 1.3.1,编程语言采用Python 3.7.3,集成开发环境使用PyCharm。参数设置上,训练速率衰减周期设置为100 epoch;批处理(batch)大小设置为64。本文主要试验部分基于ResNet-50[24]作为基础模型进行预训练,增加网络的特征提取性能。
2.1.2 评价指标对于精度检验,分类任务中多采用总体精度(OA)和混淆矩阵[25]进行试验结果评价。总体精度为
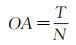 (9)
(9)
式中,N为测试样本总数;T为正确分类的图像。该种衡量方法可以较好地反映出分类方法在整个测试图像上的性能。为了更加直观地评估模型性能,本文将添加精准率(Precision)和召回率(Recall)进一步进行模型评价。精准率与召回率主要基于试验结果中所得到的真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)进行描述,即
 (10)
(10)
AID数据集是用于航空场景分类的大型数据集,具有较大的组内差异,援助目标是提高遥感图像场景分类的技术水平[26]。2017年由武汉大学和华中科技大学发布,由Google Earth影像上采集的不同分辨率、不同地区的影像,每幅影像大小为600×600像素,包含30类场景,每个类别包含220~420张影像,整个数据集共10 000张影像(图 3)。

|
| 图 3 AID数据集示例 Fig. 3 Example images of AID dataset |
本文所提出的方法在AID数据集(50%训练集比率,每个类别110~210张训练样本)上进行试验得到结果见表 1,在采用本文所提出的基于迁移可变形卷积的网络模型方法后精度提高了4.25%,Kappa系数提高了0.04,同时对模型的计算力(flops)和参数量(params)进行计算,本文方法仅添加了较少参数量使得模型性能得到了较好提升。最终得到分类精度如图 4所示,从初始精度上看两种方法就有很大的差距,本文所提模型比普通模型精度提高近20%,模型可以更快收敛。从整体上看所提方法都较原始方法精度有较大提高。具体的,根据图 5所示的两个混淆矩阵可发现,基础模型在池塘和河流,体育场和体育馆,度假村和公园等都产生了较为严重混淆现象。这些场景都基于相似特征的基本组成单元,仅在空间分布、密度等方面产生区别,易产生混淆现象,是场景分类中的一大难点。但基于DTDCNN模型,由于该模型中对目标采用非方形卷积核进行特征提取,可以发现体育馆较体育场仅多出周围建筑物,原始模型则不能将其区分开,通过所提方法添加了一层过滤器,大大提高了目标数据集的分类性能。而对于具有较为相同几何特征的场景,模型即使对场景具有很好地识别效果,但分类上部分未能得到较好的提升。但总体上大部分场景的分类精度都得到不同程度的提高,表明所提方法可以有效减少混淆现象。
| 方法 | OA/(%) | Kappa | 精准率(平均每个类别)/(%) | 召回率(平均每个类别)/(%) | 计算力(G) | 参数量(M) |
| ResNet-50 | 85.01 | 0.852 9 | 86.37 | 85.17 | 4.10 | 23.55 |
| DTDCNN(ResNet-50) | 89.26 | 0.888 9 | 89.19 | 88.70 | 4.12 | 34.25 |

|
| 图 4 AID数据集分类精度变化曲线 Fig. 4 Classification Accuracy Variation Curve of AID dataset |

|
| 图 5 AID数据集混淆矩阵结果 Fig. 5 Classification confusion matrix of AID dataset |
2.2.2 UC-Merced数据集分类试验结果与分析
UC-Merced数据集是一个广泛的手动标记的地面真值数据集(图 6),用于定量评估[2]。该数据集每幅影像大小为256×256像素,涵盖了21类不同场景类别。每一类场景包含100张影像,共2100张影像。该数据集由于类间差距小,类内差距大,具有较大的挑战性,在遥感影像场景分类领域极具代表性,广泛用于场景分类研究[27]。

|
| 图 6 UC-Merced数据集示例 Fig. 6 Example images of UC-Merced dataset |
本文所提出的方法在该数据集上进行试验(80%训练集比率,每类别80张作为训练样本,20张作为测试数据)得到结果见表 2,在采用本文所提出的基于迁移可变形卷积的网络模型方法后精度提高了1.9%,Kappa系数提高了0.021。最终得到分类结果如图 7所示,从中看出两种方法同样都很快开始收敛,前20个epoch时添加可变形卷积方法的分类精度相较于初始模型提高较为明显。根据图 8所示的两个混淆矩阵可以发现,建筑和中密度住宅区,网球场和中等密度住宅区等都产生了较轻程度的混淆,所提方法较普通模型则有更好的分类效果。同样与AID试验结果相似,所提方法精度提高的主要来源是具有相似特征的场景混淆现象的减少。UC-Merced数据集具有较小的类间差距,而同一类别的场景数据具有更大的差异,更好地验证了所提方法对特征分布不同的场景数据分类的有效性。
| 方法 | OA/(%) | Kappa | 精准率(平均每个类别)/(%) | 召回率(平均每个类别)/(%) |
| ResNet-50 | 94.76 | 0.943 0 | 94.69 | 94.52 |
| DTDCNN(ResNet-50) | 96.67 | 0.964 0 | 96.24 | 96.19 |

|
| 图 7 UC-Merced数据集分类精度变化曲线 Fig. 7 Classification accuracy variation curve of UC-Merced dataset |

|
| 图 8 UC-Merced数据集混淆矩阵结果 Fig. 8 Classification confusion matrix of UC-Merced dataset |
2.2.3 NWPU-RESISC45数据集分类试验结果与分析
NWPU-RESISC45数据集[28]是由西北工业大学创建的遥感图像场景分类可用基准,比AID和UC-Merced数据集更为复杂,该数据集包含像素大小为256×256,涵盖45个场景类别, 其中每个类别有700张图像, 共计31 500张图像。该数据集涵盖了全球100多个具有发展中、转型中和高度发达经济体的国家和地区,是目前属于较大规模的数据集,同时场景影像在平移、空间分辨率、视点、物体姿势、照明、背景和遮挡方面存在很大差异,具有很大的组内差异性和组间相似性。
基于本文所提出方法对更具有挑战性的大型场景数据集NWPU-RESISC45(图 9)上进行场景分类试验(20%训练集比率,每类别140张作为训练样本,560张作为测试数据)得到结果见表 3,可见在采用本文所提出的基于迁移可变形卷积的网络模型方法后精度提高了4.83%,Kappa系数提高了0.041 1。在更具有挑战性的数据集上可变形卷积的优势更为明显,不仅在初始精度上有非常明显的提升,在整体上精度都得到了明显提升(图 10)。由图 11所给出的混淆矩阵可以看出,宫殿与教堂场景由于存在相似建筑风格而导致产生混淆现象较为严重,露天体育场与田径场同样由于相似的结构也产生了混淆现象,但相对于ResNet-50模型本文所提出的添加可变形卷积层的方法都对易产生混淆现象的场景辨别有不同程度的提高,如篮球场和网球场、岛屿和河流等场景都减少了混淆现象的发生。

|
| 图 9 NWPU-RESISC45数据集示例 Fig. 9 Example images of NWPU-RESISC45 dataset |
| 方法 | OA/(%) | Kappa | 精准率(平均每个类别)/(%) | 召回率(平均每个类别)/(%) |
| ResNet-50 | 80.02 | 0.803 9 | 82.11 | 81.78 |
| DTDCNN(ResNet-50) | 84.85 | 0.845 0 | 85.10 | 84.73 |

|
| 图 10 NWPU-RESISC45数据集分类精度变化曲线 Fig. 10 Classification accuracy variation curve of NWPU-RESISC45 dataset |

|
| 图 11 NWPU-RESISC45数据集混淆矩阵结果 Fig. 11 Classification confusion matrix of NWPU-RESISC45 dataset |
2.2.4 与其他方法对比结果
综上所述,基于3个具有不同挑战性的场景数据集分类试验结果可以看出:利用迁移学习的基础模型在高分辨率遥感场景分类上已经具有一定的泛化能力,而本文所提出的DTDCNN模型在基础网络模型上添加具有偏移量的采样模块,更好地学习目标特征,有效解决了同类物体不同位置、不同类具有相似特征等容易产生混淆的现象,提高了目标数据集分类精度。与近年其他场景分类方法进行对比,为方便比较模型整体性能,选择了与本文在数据集的选择和试验设置较为接近的研究方法,结果见表 2。由表 2中可以看出,本文所提方法在各数据集上的精度相比于其他方法精度都具有一定优势,与MF-WGANs[29]相比,在较大型数据集上表现更为优秀,与Siamese ResNet-50[30]相比则在小型数据集上更占优势;DCA Fusion[31]采用特征融合策略较好地提高了分类精度,与DTDCNN模型精度较为接近;VggNet-16-EMR[32]基于CNN模型获得的特征采用EMR和VLAD进行处理后分类,在UC-Merced数据集上表现优秀,但对于其在大尺寸遥感数据集上的表现是未知的。高分遥感场景数据集分类任务对于场景特征的学习和判别尤为重要,本文所提方法通过将预训练模型与可变形卷积层进行结合,明显提高了对场景特征的学习能力,与其他方法相比则具有更高的性能。因此总体上说明DTDCNN在场景分类上仍是具有较大潜力,验证了其在遥感场景分类任务上的有效性。
同时,为验证DTDCNN在不同模型基础上是否具有普适性,本文采用该方法基于VggNet-16模型进行试验,如表 4结果显示,所提DTDCNN模型对于不同数据集得到结果都较原始模型有不同程度的提高,验证可变形卷积与其他CNN模型组合时优势仍然存在,说明所提方法具有普适性。
| 方法 | DenseNet[33] | MRBF[34] | MF-WGANs[29] | Siamese ResNet-50[30] | DCA Fusion[31] | VggNet-16-EMR[32] | VggNet-16[35] | DTDCNN | ||
| VggNet-16 | ResNet-50 | |||||||||
| AID(50%) | 87.58 | 87.26 | 80.35 | - | 89.71 | - | 82.40 | 84.53 | 89.26 | |
| UC-Merced(80%) | 92.38 | 94.19 | 98.40 | 94.29 | 96.90 | 98.14 | 90.95 | 95.24 | 96.67 | |
| NWPU-RESISC 45(20%) | 81.16 | 68.87 | 79.49 | 92.28 | - | - | 76.34 | 80.82 | 84.12 | |
| 注:MF-WGANs[31]在NWPU数据集上训练集比例为50%。 | ||||||||||
3 结论
针对现有深度卷积神经网络对遥感场景影像的几何形变不具有稳健性等问题,本文提出了一种面向高分遥感影像场景分类的DTDCNN模型。该方法首先基于大型自然场景数据集ImageNet上训练的深度模型提取遥感影像的深度特征,通过添加可变形卷积层增加了模型对遥感影像中几何形变稳健深度特征的学习能力,在AID、UC-Merced和NWPU-RESISC45数据集上都取得了较好的结果。该方法仅增加很少的模型复杂度和计算量,在精度上较普通模型有明显提高,使得模型性能得到较为明显的提升。根据试验结果不难发现,精度提升主要来源于一些具有明显相同特征的场景类别,例如池塘和河流、体育场和体育馆、中等密度住宅区和高密度住宅区等,验证了所提方法在高分辨率遥感场景分类具有较为明显优势,同时所提方法在时间性能上也同样有着较为出色的表现。在接下来的研究中可针对该方法进一步优化提升分类精度,同时也可将该方法应用于高分辨率遥感影像土地利用分类、遥感特征地物的提取[36]等实际问题的解决或结合光谱数据[37]获取图像特征进行分类作为下一步研究目标。
| [1] |
李德仁, 童庆禧, 李荣兴, 等. 高分辨率对地观测的若干前沿科学问题[J]. 中国科学(地球科学), 2012, 42(6): 805-813. LI Deren, TONG Qingxi, LI Rongxing, et al. Current issues in high-resolution Earth observation technology[J]. Science China Earth Sciences, 2012, 42(6): 805-813. |
| [2] |
YANG Yi, NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. [S.l.]: ACM, 2010: 270-279.
|
| [3] |
CHERIYADAT A M. Unsupervised feature learning for aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(1): 439-451. DOI:10.1109/TGRS.2013.2241444 |
| [4] |
张帆. 面向高分辨率遥感影像分析的深度学习方法研究[D]. 武汉: 武汉大学, 2017. ZHANG Fan. Deep learning for very high resolution remote sensing data analysis[D]. Wuhan: Wuhan University, 2017. |
| [5] |
ZHU Qiqi, ZHONG Yanfei, ZHAO Bei, et al. Bag-of-Visual-Words scene classifier with local and global features for high spatial resolution remote sensing imagery[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(6): 747-751. DOI:10.1109/LGRS.2015.2513443 |
| [6] |
钱晓亮, 李佳, 程塨, 等. 特征提取策略对高分辨率遥感图像场景分类性能影响的评估[J]. 遥感学报, 2018, 22(5): 758-776. QIAN Xiaoliang, LI Jia, CHENG Gong, et al. Evaluation of the effect of feature extraction strategy on the performance of high-resolution remote sensing image scene classification[J]. Journal of Remote Sensing, 2018, 22(5): 758-776. |
| [7] |
闫苗, 赵红东, 李宇海, 等. 基于卷积神经网络的高光谱遥感地物多分类识别[J]. 激光与光电子学进展, 2019, 56(2): 021702. YAN Miao, ZHAO Hongdong, LI Yuhai, et al. Multi-classification and recognition of hyperspectral remote sensing objects based on convolutional neural network[J]. Laser & Optoelectronics Progress, 2019, 56(2): 021702. |
| [8] |
龚希, 吴亮, 谢忠, 等. 融合全局和局部深度特征的高分辨率遥感影像场景分类方法[J]. 光学学报, 2019, 39(3): 0301002. GONG Xi, WU Liang, XIE Zhong, et al. Classification method of high-resolution remote sensing scenes based on fusion of global and local deep features[J]. Acta Optica Sinica, 2019, 39(3): 0301002. |
| [9] |
MARMANIS D, DATCU M, ESCH T, et al. Deep learning earth observation classification using ImageNet pretrained networks[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(1): 105-109. DOI:10.1109/LGRS.2015.2499239 |
| [10] |
庄福振, 罗平, 何清, 等. 远移学习研究进展[J]. 软件学报, 2015, 26(1): 26-39. ZHUANG Fuzhen, LUO Ping, HE Qing, et al. Survey on transter learning research[J]. Journal of Software, 2015, 26(1): 26-39. |
| [11] |
DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-Scale hierarchical image database[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009). Miami, FL: IEEE, 2009.
|
| [12] |
谭琨, 王雪, 杜培军. 结合深度学习和半监督学习的遥感影像分类进展[J]. 中国图象图形学报, 2019, 24(11): 1823-1841. TAN Kun, WANG Xue, DU Peijun. Research progress of the remote sensing classification combining deep learning and semi-supervised learning[J]. Journal of Image and Graphics, 2019, 24(11): 1823-1841. DOI:10.11834/jig.190348 |
| [13] |
PENATTI O A B, NOGUEIRA K, SANTOS J A D. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Boston, MA: IEEE, 2015.
|
| [14] |
BASU S, GANGULY S, MUKHOPADHYAY S, et al. DeepSat: a learning framework for satellite imagery[C]//Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems. [S.l.]: ACM, 2015.
|
| [15] |
蔡博文, 王树根, 王磊, 等. 基于深度学习模型的城市高分辨率遥感影像不透水面提取[J]. 地球信息科学学报, 2019, 21(9): 1420-1429. CAI Bowen, WANG Shugen, WANG Lei, et al. Extraction of urban impervious surface from high-resolution remote sensing imagery based on deep learning[J]. Journal of Geo-information Science, 2019, 21(9): 1420-1429. |
| [16] |
DAI Jifeng, QI Haozhi, XIONG Yuwen, et al. Deformable convolutional networks[C]//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017.
|
| [17] |
ZUO Zongcheng, ZHANG Wen, ZHANG Dongying. A remote sensing image semantic segmentation method by combining deformable convolution with conditional random fields[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 39-49. DOI:10.11947/j.JGGS.2020.0304 |
| [18] |
ZHANG Wei, TANG Ping, ZHAO Lijun. Remote sensing image scene classification using CNN-CapsNet[J]. Remote Sensing, 2019, 11(5): 494. DOI:10.3390/rs11050494 |
| [19] |
QI Kunlun, GUAN Qingfeng, YANG Chao, et al. Concentric circle pooling in deep convolutional networks for remote sensing scene classification[J]. Remote Sensing, 2018, 10(6): 934. DOI:10.3390/rs10060934 |
| [20] |
GONG Jianya, JI Shunping. Photogrammetry and deep learning[J]. Journal of Geodesy and Geoinformation Science, 2018, 1(1): 1-15. DOI:10.11947/j.JGGS.2018.0101 |
| [21] |
滕文秀, 温小荣, 王妮, 等. 基于深度迁移学习的无人机高分影像树种分类与制图[J]. 激光与光电子学进展, 2019, 56(7): 072801. TENG Wenxiu, WEN Xiaorong, WANG Ni, et al. Tree species classification and mapping based on deep transfer learning with unmanned aerial vehicle high resolution images[J]. Laser & Optoelectronics Progress, 2019, 56(7): 072801. |
| [22] |
PAN S J, YANG Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359. DOI:10.1109/TKDE.2009.191 |
| [23] |
ZHU Xizhou, HU Han, LIN S, et al. Deformable ConvNets V2: more deformable, better results[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA: IEEE, 2019: 9308-9316.
|
| [24] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV: IEEE, 2016.
|
| [25] |
叶利华, 王磊, 张文文, 等. 高分辨率光学遥感场景分类的深度度量学习方法[J]. 测绘学报, 2019, 48(6): 698-707. YE Lihua, WANG Lei, ZHANG Wenwen, et al. Deep metric learning method for high resolution remote sensing image scene classification[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(6): 698-707. DOI:10.11947/j.AGCS.2019.20180434 |
| [26] |
XIA Guisong, HU Jingwen, HU Fan, et al. AID: a benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965-3981. DOI:10.1109/TGRS.2017.2685945 |
| [27] |
滕文秀, 王妮, 陈泰生, 等. 基于深度对抗域适应的高分辨率遥感影像跨域分类[J]. 激光与光电子学进展, 2019, 56(11): 112801. TENG Wenxiu, WANG Ni, CHEN Taisheng, et al. Deep adversarial domain adaptation method for cross-domain classification in high-resolution remote sensing images[J]. Laser & Optoelectronics Progress, 2019, 56(11): 112801. |
| [28] |
CHENG Gong, HAN Junwei, LU Xiaoqiang. Remote sensing image scene classification: benchmark and state of the art[J]. Proceedings of the IEEE, 2017, 105(10): 1865-1883. DOI:10.1109/JPROC.2017.2675998 |
| [29] |
WEI Yufan, LUO Xiaobo, HU Lixin, et al. An improved unsupervised representation learning generative adversarial network for remote sensing image scene classification[J]. Remote Sensing Letters, 2020, 11(6): 598-607. DOI:10.1080/2150704X.2020.1746854 |
| [30] |
LIU Xuning, ZHOU Yong, ZHAO Jiaqi, et al. Siamese convolutional neural networks for remote sensing scene classification[J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(8): 1200-1204. DOI:10.1109/LGRS.2019.2894399 |
| [31] |
CHAIB S, LIU Huan, GU Yanfeng, et al. Deep feature fusion for VHR remote sensing scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(8): 4775-4784. DOI:10.1109/TGRS.2017.2700322 |
| [32] |
WANG Guoli, FAN Bin, XIANG Shiming, et al. Aggregating rich hierarchical features for scene classification in remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(9): 4104-4115. DOI:10.1109/JSTARS.2017.2705419 |
| [33] |
HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI: IEEE, 2018.
|
| [34] |
WANG Chen, LIN Wei, TANG Pengfei. Multiple resolution block feature for remote-sensing scene classification[J]. International Journal of Remote Sensing, 2019, 40(17-18): 6884-6904. |
| [35] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//Proceedings of International Conference on Learning Representations. San Diego: ICLR, 2015: 1-5.
|
| [36] |
WANG Yuliang, LI Mingshi. Urban impervious surface detection from remote sensing images: a review of the methods and challenges[J]. IEEE Geoscience and Remote Sensing Magazine, 2019, 7(3): 64-93. DOI:10.1109/MGRS.2019.2927260 |
| [37] |
WANG Yuliang, SU Huiyi, LI Ming. An improved model based detection of urban impervious surfaces using multiple features extracted from Rosis-3 hyperspectral images[J]. Remote Sensing, 2019, 11(2): 136. DOI:10.3390/rs11020136 |