


智慧城市建设、城市精细化管理、自然资源立体监测等国家重大战略对城市立体空间内人事物发生发展的全过程精细刻画、仿真建模、模拟预测等需求强烈,尤其对全域、全要素、实时、高质量的三维地理信息需求尤其迫切。长期以来,以地图和影像为代表的二维空间数据表达已经远远不能满足多种应用需求[1],迫切需要从以4D测绘产品(数字正射影像DOM、数字高程模型DEM、数字线划地图DLG、数字栅格地图DRG)为基础的信息化测绘走向智能化测绘,从而满足智慧社会、智慧城市等对高质量、精细化三维地理信息的紧迫需求。近年来,智能小卫星、低空无人机、地面移动三维扫描测量等对地对观测技术的创新发展快速提升了全空间、全时域的感知能力[2],尤其是以点云为代表的三维数据获取能力,有力促进了三维地理信息快速提取的进步[3]。不同于自然地表空间要素,城市立体空间要素具有高度的复杂性、动态性、交错性和多态性,对三维精准提取城市立体空间地理信息要素提出了巨大挑战。点云作为矢量地图和影像数据后的一类独特的时空数据,已成为物理空间实体对象三维数字化结果的重要表达方式[4]。如何利用人工智能手段,高度提升点云的解译能力,实现城市地物目标的语义标识与三维精准提取成为亟待攻克的难题。
尽管目前一些研究者提出了诸多基于模型拟合或特征聚类的方法[5-6],但是这些方法仅限于较为简单的实体目标,且对于具有弱泛化性的目标结构需要较多的先验知识。深度学习在处理具有规则结构的二维图像领域(如目标识别、分割等)取得了长足的进步。近年来,点云深度学习日益受到关注,且发布了一定规模的点云数据集,如ShapeNet[7]、ModelNet[8]、ScanNet[9]、Semantic3D[10]、KITTI[11]、WHU-TLS[12]、WHU-MLS[13]等,使得深度学习模型从三维点云中学习有效特征成为可能。然而,传统的卷积神经网络(CNN)难以直接应用于空间分布不规则的点云[14],并且大多数点云语义分割的方法都难以处理大规模的点云[15],尤其是城市场景大规模点云的语义标识。部分学者尝试将点云投影到不同视角的图像中,然后利用CNN从图像中提取特征[16-18],但是在投影过程中,有限的投影视角不可避免地丢失有用的细节,因此不利于目标的准确提取。也有学者将点云体素化为3D网格,通过3D CNN提取目标特征[19-20]。然而,此类方法计算成本高且难以满足大规模点云语义分割的需求。显然,原始点云可以更准确和直接地刻画目标的几何结构,为此有学者相继提出了PointNet[21]和PointNet++[22]用于直接学习逐个点的特征。除此之外,图卷积[23, 24]、核卷积[25-27]被提出用于学习不规则点云的特征。尽管上述方法可以从不同角度有效地学习点云的特征,但它们主要适用于具有简单结构的模型或室内场景点云,难以有效地学习更为复杂的结构。文献[28]通过融合2D图像和3D点云对大规模三维场景进行语义分割,但是需要基准数据集(同时包括2D和3D室外数据)的支撑,且两者融合的质量严重影响语义分割结果。文献[29]提出了一种具有注意力嵌入模块的递归顺序切片网络,从不同的角度学习空间关系并使用CNN提取高级信息,但是该网络模型规模较大,且泛化能力较弱。
不同于规则格网的二维影像,城市场景大规模点云具有点位空间分布不均、因遮挡导致的数据缺失及目标多样且尺度差异大等独特性。点云深度学习需要突破现有的深度学习网络在点云采样、局部特征提取与聚合,以及训练样本不均衡方面存在的缺陷,从而有望实现点云场景的全面精准感知。为此,本文旨在构建一种直接用于城市场景大规模点云的目标语义标识深度学习网络,用于解决大规模点云的有效采样、点云局部特征自主学习与聚合,以及训练样本不平衡等难点,实现多类目标的正确语义标识,为高质量三维地理信息的快速提取提供核心支撑。
1 端到端城市大规模点云语义标识深度学习网络点云深度学习的本质是基于训练样本学习点云特征并予以表达,然后通过损失函数度量数据预测值与训练样本真值之间的差异(两者之间的差异越小说明模型与参数对训练样本的拟合越好)。由于城市点云场景的复杂性(点位分布不均且量大、目标多样等),为保证点云深度学习网络的高效和准确,必须首先对大规模点云进行采样,降低点云的数据量,从而减少计算量,保证网络的高效性;其次,要克服点位不均匀分布和因遮挡导致的不完整对点云特征准确学习的影响;同时要尽量减少由于训练样本不均衡而对网络预测结果的影响。为此,本文重点围绕点云深度学习的效率和结果的准确性,从高效的点云空间降采样策略,基于点特征抽象表达与传播以及提升总体表现的损失函数3个方面出发,构建了点云语义标识深度学习网络。该深度学习网络直接输入点云数据,并端到端地标识每个点的语义类别,其总体框架如图 1所示。

|
| 图 1 端到端的点云语义标识深度学习网络架构 Fig. 1 An end to end deep learning framework for point cloud semantic labeling |
1.1 下采样与上采样
该网络使用下采样-上采样结构和跳跃连接的U形结构作为骨干网络。下采样过程包括空间下采样和特征聚合,空间下采样用于减少点数,而特征聚合则得到空间采样后的点云特征。下采样过程将特征逐层映射到更高的特征空间,并扩大感受野以获得更高层次、更抽象的特征,而上采样过程旨在逐步将抽象特征传播到每个点,从而获得逐点特征。
为兼顾计算效率和不同目标间尺度的差异性,在点云空间下采样过程中首先对整个场景进行较小分辨率的均匀格网采样,然后在网络的低层特征使用随机采样降低计算的复杂度,高层特征使用最远点采样策略,用于克服随机采样无法很好地覆盖点密度稀疏小目标的缺陷。由于网络下采样的后几层处理的点数少,因此使用FPS对效率不会有显著影响。在每层空间下采样之后,进行局部特征聚合,以获得下一层的采样特征。在点云上采样阶段,为了获得lth层特征,同文献[22],使用lth层坐标进行三线性插值,获得加权特征作为插值点。然后,使用跳跃连接在聚合过程中将插值点与对应层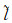
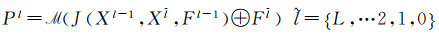 (1)
(1)
式中,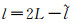
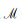
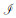
在每层点云空间下采样后,进行特征融合、空间映射和空间与通道的聚合。对于给定输入点集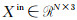
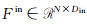
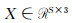
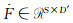

|
| 图 2 特征聚合模块 Fig. 2 Module of feature aggregration |
在每个聚合过程之前,对每个下采样点通过K近邻(KNN)分组得到用于特征聚合的局部单元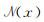
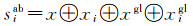 (2)
(2)
式中,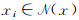
相对空间位置定义为
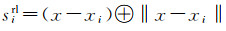 (3)
(3)
式中,‖·‖表示欧几里得距离的计算。
边特征定义为
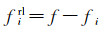 (4)
(4)
式中,f∈F(空间下采样后的特征集);fi∈Fin(原始特征集)。
最后,通过简单的级联操作获得位置x的ith邻域点的融合特征
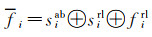 (5)
(5)
但是,不同于其他使用蒙特卡罗估计尝试得到近似的连续卷积核的方法[26-27],本文方法则直接学习一个空间映射函数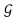
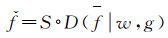 (6)
(6)
式中,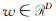
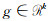
对于位置x的ith邻域点的dth特征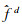
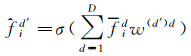 (7)
(7)
式中,w(d′)d表示d'th个w的dth个权值;σ是一个非线性激活函数。
对此过程重复多次以获得更高层次特征。然后,通过映射函数
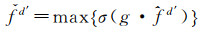 (8)
(8)
式中,·表示逐元素相乘;max是最大池化操作。
1.3 代价函数由于城市点云场景中目标类别数量差异大,且训练样本不均衡,简单地分配不同的类权重平衡网络的监督信号难以有效控制深度学习网络的整体性能。如何控制不同类别目标的权重变得尤为重要。基于加权交叉熵的代价函数更专注于单个类的精度,而不关注特定类中的错误,这意味着如果为小样本分配了更大的权重,则这些类的错误点数也可能更大。为此,本文提出的深度学习网络主要根据训练过程中存在的点数,合理提高对小样本学习的关注,定义了代价函数L,旨在平衡少数类的表现和整体表现
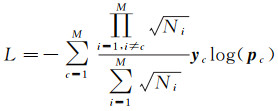 (9)
(9)
式中,Nc是训练过程中出现的cth类的总点数;M表示类别数;yc、pc分别表示cth类的真实标签向量和预测标签向量。
2 试验分析 2.1 测试数据集和评价指标整个场景在训练期间被分成10 m×10 m的块,每个块被随机采样到20 000点,使用0.8 m半径的邻域范围进行法向量计算。输入点的特征包含全局坐标、分块内标准化坐标、法向量和强度。本文构造的网络采用0.05 m网格作为分块前规则采样的分辨率,然后是采样比为0.25、0.25、0.25、0.25、0.25、0.5、0.5的下采样层。该网络在PyTorch平台上实现。在网络训练期间,Adam优化器用于更新模型,动量和初始学习率分别设置为0.9和0.001,衰减率设置为0.000 1,学习速率每16个遍历(epoch)降低一半。该模型在NVIDIA GTX 1080Ti的GPU上训练了100个批量大小为28的迭代,并且选择使用具有最佳mIoU的模型进行测试。
为验证本文构建的深度学习网络性能,使用WHU-MLS数据集[13]进行测试。WHU-MLS数据集包括40个场景,超过3亿点,其中30个场景作为训练场景和10个场景作为测试。其中的地物目标类包括:行车道(driveway)、非驾驶车道(nd.way)、道路标线(rd.mrk)、建筑物(building)、围栏(fence)、树木(tree)、低矮植被(low veg)、路灯(light)、电线杆(tel.pole)、市政立杆(mun. pole)、交通信号灯(trff. light)、监控探头(detector)、广告牌或提示牌(board)。动态目标类包括:行人(pedestrian)和车辆(vehicle)。
为评估本文构造网络的性能,采用如下的几类指标:精度(Precision)、召回(Recall)、F1-Score、IoU和总体精度(OA)
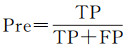 (10)
(10)
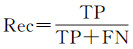 (11)
(11)
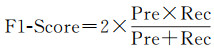 (12)
(12)
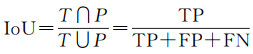 (13)
(13)
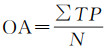 (14)
(14)
式中,TP是预测正确的该类别样本数量;FP是将其他类别样本错预测成该类别的样本数量;FN是将该类比样本错预测成其他类别的样本数量;N是样本总数。精度、召回、F1-Score和IoU在每个类别中分别计算,然后计算平均值。
2.2 语义标识结果不同测试场景的预测结果如图 3所示。图 3(a)所示场景具有较为复杂的结构。图 4和图 5分别从更细节的角度和驾驶角度展示了语义标识的结果。从示例结果可以看出,该网络语义标识的整体表现较好,但也存在一定的错误标识,如图 6所示。造成此类错误分类的原因有几种:①语义模糊性,如某些类定义较为模糊,这意味着一个点可能既属于某一类,同时也属于另一类,例如由提示牌和路灯连接的杆状结构,如图 6(a)所示;②多个目标相互重叠,例如在树丛中竖立的灯,如图 6(b)所示;③局部位置预测出了不同的类别,由于场景在点被送入网络之前被划分为块,推测主要是因为相邻的区块在重叠区域内预测结果存在不同,如图 6(c)所示。

|
| 注:左侧为人工标记的结果;右侧为预测结果。 图 3 WHU-MLS数据集4个场景的预测结果 Fig. 3 Prediction results from four scenarios of WHU-MLS dataset |

|
| 图 4 WHU-MLS数据集中部分类别的预测结果 Fig. 4 Prediction results from several classification of WHU-MLS dataset |

|
| 图 5 WHU-MLS数据集中单个场景的预测结果 Fig. 5 Prediction results from one scenario of WHU-MLS dataset |

|
| 图 6 WHU-MLS数据集上错误的语义标识 Fig. 6 Wrong semantic labeling cases from WHU-MLS dataset |
为定量地评价本文构建的深度学习网络的效果,分别计算了WHU-MLS数据集中17个精细类别(树木、非机动车道、建筑物、箱状地物、路灯、电线杆、市政立杆、低矮植被、提示牌、驾驶车道、道路标线、车辆、行人、信号灯、探头、围栏和电线)和6个粗分类(动态物体、杆状目标、植被、建筑和地面)的IOU、F1-Score、精度、召回率,见表 1。由表 1可以看出,本文的深度学习网络在一些大尺寸目标,如车道(IoU:83.6,F1-Score:91.0)、建筑(IoU:77.1,F1-Score:87.1)和树(IoU:84.5,F1-Score:91.6),以及一些运动目标,如行人(IoU:60.8,F1-得分:75.6)和车辆(IoU:79.1,F1-得分:88.3)上取得较好结果。
| 类别 | IoU | F1-Score | 精度 | 召回 | |
| 动态目标 | 人 | 60.8 | 75.6 | 77.9 | 73.4 |
| 车 | 79.1 | 88.3 | 90.5 | 86.3 | |
| 杆状物 | 路灯 | 71.8 | 83.6 | 79.9 | 87.7 |
| 信号灯 | 31.0 | 47.3 | 46.0 | 48.6 | |
| 探头 | 31.3 | 47.7 | 40.6 | 57.8 | |
| 电线杆 | 49.9 | 66.6 | 64.8 | 68.4 | |
| 市政杆 | 26.5 | 41.8 | 35.6 | 50.8 | |
| 标牌 | 20.2 | 33.7 | 31.1 | 36.7 | |
| 植被 | 树 | 84.5 | 91.6 | 88.8 | 94.5 |
| 低矮植被 | 34.1 | 50.8 | 52.9 | 48.9 | |
| 构筑物 | 护栏 | 57.9 | 73.3 | 90.9 | 61.5 |
| 建筑物 | 77.1 | 87.1 | 85.2 | 88.9 | |
| 地面 | 行车道 | 83.6 | 91.0 | 94.8 | 87.6 |
| 非机动车道 | 58.4 | 73.7 | 58.4 | 100 | |
| 标线 | 38.1 | 55.2 | 52.1 | 58.6 | |
| 其他 | 箱子 | 45.4 | 62.5 | 65.0 | 60.1 |
| 电线 | 47.2 | 64.1 | 63.9 | 64.3 | |
表 2比较了本文构造的网络与其他几个主流的点云深度学习网络在17个类别语义标识中的表现。可以看出,本文的深度学习网络在非机动车道、建筑物、箱体、灯、电线杆、市政立杆、提示牌、机动车道、道路标线、车辆、行人、探头和电线等大多数类别中优于其他几种方法。
| 类别 | Point Net++ | PointConv | RandLA | 本文的深度学习网络 |
| 树 | 83.3 | 85.9 | 86.8 | 84.5 |
| 非机动车道 | 42.0 | 48.9 | 55.6 | 58.4 |
| 建筑物 | 72.7 | 73.5 | 76.3 | 77.1 |
| 箱体 | 6.6 | 28.2 | 32.4 | 45.4 |
| 灯 | 59.1 | 59.7 | 61.2 | 71.8 |
| 电线杆 | 30.8 | 35.7 | 43.1 | 49.9 |
| 市政立杆 | 7.8 | 20.0 | 15.2 | 26.5 |
| 植被 | 33.1 | 32.4 | 37.4 | 34.1 |
| 提示牌 | 13.9 | 16.0 | 18.1 | 20.2 |
| 机动车道 | 80.0 | 82.0 | 80.6 | 83.6 |
| 道路标线 | 29.5 | 30.6 | 29.3 | 38.1 |
| 车辆 | 76.7 | 76.2 | 74.9 | 79.1 |
| 行人 | 38.9 | 53.8 | 50.7 | 60.8 |
| 信号灯 | 25.0 | 28.7 | 21.6 | 31.0 |
| 探头 | 11.0 | 27.6 | 22.2 | 31.3 |
| 护栏 | 56.3 | 52.6 | 55.8 | 57.9 |
| 电线 | 32.7 | 36.5 | 39.2 | 47.2 |
| 平均性能 | 41.1 | 46.4 | 47.1 | 52.8 |
表 3给出了本文构建的深度学习网络在不同网络层中的参数个数和推理时间。时间为使用一百万个点单次前向传播的耗时。可见本文的深度学习网络可以在2 s内预测100万个点,表明了该网络的轻量级和高性能。
| 网络层 | 参数个数 | 时间/s |
| sa1 | 6000 | 0.299 |
| sa2 | 27 000 | 0.278 |
| sa3 | 103 000 | 0.365 |
| sa4 | 402 000 | 0.113 |
| sa5 | 1 592 000 | 0.068 |
| fp5 | 1 051 000 | 0.052 |
| fp4 | 263 000 | 0.008 |
| fp3 | 165 000 | 0.014 |
| fp2 | 115 000 | 0.045 |
| fp1 | 50 000 | 0.181 |
| Fc | 19 000 | 0.001 |
| 总和 | 3.7 M | 1.424 |
3 结论
本文构造了一种城市大规模点云语义标识的端到端深度学习网络,为目标的识别和信息的提取提供了关键支撑。该深度学习网络直接对大规模三维点云进行特征学习,通过卷积操作模拟人眼扩大视觉感受野,兼顾了单个点的上下文特征,有力提高了不同尺度目标特征准确刻画和表达的能力,为目标的提取和类别的区分提供了有益的知识。实际的测试表明:该深度学习网络在高效的采样策略、多层的特征聚合与传播,以及兼顾样本不平衡的代价损失函数具有较好的性能,可高效地对大规模的室外场景点云进行近20类目标的正确语义标识,且性能优于现有的几个主流网络(如:PointNet等),为三维地理信息的快速有效提取提供了有力支撑。当前,本文构造的点云深度学习网络测试的目标多为人工地物,在自然地物的语义类别的自动识别方面还需要进一步测试。其次,本文当前的研究尚未开展实体对象的识别工作,下一步将在语义类别的基础上开展实体对象的提取研究。
| [1] |
杨必胜, 梁福逊, 黄荣刚. 三维激光扫描点云数据处理研究进展、挑战与趋势[J]. 测绘学报, 2017, 46(10): 1509-1516. YANG Bisheng, LIANG Fuxun, HUANG Ronggang. Progress, challenges and perspectives of 3D LiDAR point cloud processing[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(10): 1509-1516. DOI:10.11947/j.AGCS.2017.20170351 |
| [2] |
廖小罕. 中国对地观测20年科技进步和发展[J]. 遥感学报, 2021, 25(1): 267-275. LIAO Xiaohan. Scientific and technological progress and development prospect of the earth observation in China in the past 20 years[J]. National Remote Sensing Bulletin, 2021, 25(1): 267-275. |
| [3] |
杨必胜, 董震. 点云智能研究进展与趋势[J]. 测绘学报, 2019, 48(12): 1575-1585. YANG Bisheng, DONG Zhen. Progress and perspective of point cloud intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(12): 1575-1585. DOI:10.11947/j.AGCS.2019.20190465 |
| [4] |
杨必胜, 董震. 点云智能处理[M]. 北京: 科学出版社, 2020. YANG Bisheng, DONG Zhen. Intelligent processing of point cloud[M]. Beijing: Science Press, 2020. |
| [5] |
MA J W, CZERNIAWSKI T, LEITE F. Semantic segmentation of point clouds of building interiors with deep learning: Augmenting training datasets with synthetic BIM-based point clouds[J]. Automation in Construction, 2020, 113: 103144. DOI:10.1016/j.autcon.2020.103144 |
| [6] |
DONG Zhen, YANG Bisheng, HU Pingbo, et al. An efficient global energy optimization approach for robust 3D plane segmentation of point clouds[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 137: 112-133. DOI:10.1016/j.isprsjprs.2018.01.013 |
| [7] |
YI Li, SU Hao, GUO Xingwen, et al. SyncSpecCNN: synchronized spectral CNN for 3D shape segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 6584-6592.
|
| [8] |
WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D ShapeNets: a deep representation for volumetric shapes[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 1912-1920.
|
| [9] |
DAI A, CHANG A X, SAVVA M, et al. ScanNet: richly-annotated 3D reconstructions of indoor scenes[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 2432-2443.
|
| [10] |
HACKEL T, SAVINOV N, LADICKY L, et al. Semantic3d.net: a new large-scale point cloud classification benchmark[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2017, IV-1/W1: 91-98. |
| [11] |
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012: 3354-3361.
|
| [12] |
DONG Zhen, LIANG Fuxun, YANG Bisheng, et al. Registration of large-scale terrestrial laser scanner point clouds: a review and benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 163: 327-342. DOI:10.1016/j.isprsjprs.2020.03.013 |
| [13] |
杨必胜, 韩旭, 董震. 点云深度学习基准数据集[J]. 遥感学报, 2021, 25(1): 231-240. YANG Bisheng, HAN Xu, DONG Zhen. Point Cloud Benchmark Dataset WHU-TLS and WHU-MLS for Deep Learning[J]. Journal of Remote Sensing, 2021, 25(1): 231-240. |
| [14] |
FANG Hao, LAFARGE F. Pyramid scene parsing network in 3D: Improving semantic segmentation of point clouds with multi-scale contextual information[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 154: 246-258. DOI:10.1016/j.isprsjprs.2019.06.010 |
| [15] |
HU Qingyong, YANG Bo, XIE Linhai, et al. RandLA-net: efficient semantic segmentation of large-scale point clouds[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020: 11105-11114.
|
| [16] |
CHEN Xiaozhi, MA Huimin, WAN Ji, et al. Multi-view 3D object detection network for autonomous driving[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 6526-6534.
|
| [17] |
YANG Bin, LUO Wenjie, URTASUN R. PIXOR: real-time 3D object detection from point clouds[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7652-7660.
|
| [18] |
LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019: 12689-12697.
|
| [19] |
GRAHAM B, ENGELCKE M, MAATEN L V D. 3D semantic segmentation with submanifold sparse convolutional networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 9224-9232.
|
| [20] |
MENG H Y, GAO Lin, LAI Yukun, et al. VV-net: voxel VAE net with group convolutions for point cloud segmentation[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019: 8499-8507.
|
| [21] |
CHARLES R, SU H, KAICHUN M, et al. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation[C/OL]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017.
|
| [22] |
QI C R, YI Li, SU Hao, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2017: 5105-5114.
|
| [23] |
WANG Yue, SUN Yongbin, LIU Ziwei, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 1-12. |
| [24] |
JIANG Li, ZHAO Hengshuang, LIU Shu, et al. Hierar chical point-edge interaction network for point cloud semantic segmentation[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019: 10432-10440. DOI: 10.1109/ICCV.2019.01053.
|
| [25] |
HERMOSILLA P, RITSCHEL T, VÁZQUEZ P P, et al. Monte Carlo convolution for learning on non-uniformly sampled point clouds[J]. ACM Transactions on Graphics, 2019, 37(6): 1-12. |
| [26] |
XU Yifan, FAN Tianqi, XU Mingye, et al. SpiderCNN: deep learning on point sets with parameterized convolutional filters[M]//FERRARI V, HEBERT M, SMINCHISESCU C, et al. Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 90-105. DOI: 10.1007/978-3-030-01237-3_6.
|
| [27] |
WU Wenxuan, QI Z, FUXIN Li. PointConv: deep convolutional networks on 3D point clouds[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019: 9613-9622.
|
| [28] |
ZHANG Rui, LI Guangyun, LI Minglei, et al. Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 143: 85-96. DOI:10.1016/j.isprsjprs.2018.04.022 |
| [29] |
LUO Zhipeng, LIU Di, LI J, et al. Learning sequential slice representation with an attention-embedding network for 3D shape recognition and retrieval in MLS point clouds[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 161: 147-163. |