



2. 中南大学有色金属成矿预测与地质环境监测教育部重点实验室, 湖南 长沙 410083;
3. 西南交通大学地球科学与环境工程学院, 四川 成都 611756
2. Key Laboratory of Metallogenic Prediction of Nonferrous Metals and Geological Environment Monitoring(Central South University), Ministry of Education, Changsha 410083, China;
3. Faculty of Geosciences and Environmental Engineering, Southwest Jiaotong University, Chengdu 611756, China
近20年来,随着大量遥感卫星相继成功发射,标志着地球空间数据获取新纪元的来临。目前,我国已实现60~70颗遥感卫星同时在轨工作,每天获取的数据量达到数百个TB,数据总规模已接近100 PB[1],这些都表明遥感大数据时代已然来临[2-5]。然而,与遥感影像数据获取能力形成鲜明对比的是,当前遥感信息自动化处理能力依然十分低下,其现状可描述为:"data-rich but analysis-poor"[6],即"大数据,小知识"。因此,如何有效利用遥感大数据准确获取所需要的信息,实现从数据到地学知识的智能转化是目前亟待解决的问题,其背后关键技术与理论瓶颈"遥感影像智能解译"依然是国内外遥感领域共同面临的开放科学问题。
针对该问题,目前国内外相关领域研究学者开展了大量的研究工作,结合当前研究进展和状况,主要体现以下两个发展特征:
(1) 在解译对象方面,早期遥感影像智能解译主要关注像素[7]和目标[8]这两类对象。但随着影像空间分辨率的不断提高,由于像素或目标只包含较低层次的局部地物信息,通过该类解译手段无法获得与人类认知更为吻合的场景级语义信息(如工业区、商业区、学校等)。为满足更高层次的遥感地物解译需求,跨越从低层次图像特征到高层次场景语义特征之间的"语义鸿沟",结合更大解译单元内的上下文信息进行场景级影像分类已成为当前热点研究问题[9]。
(2) 在模型算法方面,由于传统手工特征结合监督分类的解译方式存在依赖启发性专业知识、泛化能力较弱等问题,以深度学习为代表的数据驱动方法[10]凭借其强大的特征学习和多层次表达能力,在遥感影像智能解译领域已得到广泛关注,并取得了令人印象深刻的结果[11-13]。但深度学习方法依赖海量的标注数据,而数据集的收集和人工标注需要耗费大量的人力成本,这一矛盾也使得该类方法在大区域、复杂场景下的遥感影像解译任务中(如全球制图[14])仍然面临诸多挑战。
机器学习范式-自监督学习已在机器学习领域渐受关注[15],目前已在自然语言处理[16]、自然图像分析[17]等领域崭露头角,甚至在某些细分任务中的表现性能已超越监督学习方法[18-19]。其主要思想是通过人工设计的自监督学习信号从海量无标注数据中挖掘自身的监督信息构成伪标签,从而替代传统人工标注数据来驱动模型进行全局特征学习,然后再通过特征迁移或域适配的方式完成具体的目标任务。这种"全局通用特征学习-局部特定任务迁移"的学习机制,可以大大降低对标注数据的依赖,具有解决大尺度遥感应用(如全球地表覆盖,全球环境监测)中由于标注样本贫乏导致的解译瓶颈问题的潜力。鉴于此,本文概述了以深度学习为代表的监督学习方法在遥感影像智能解译领域的主要研究进展,并对该类方法存在的问题和背后原因进行了深层次剖析。在此基础上,介绍了自监督学习范式的定义和常用方法,并分析了自监督学习范式相对传统监督学习范式在遥感影像智能解译任务中的优势和应用潜力,最后归纳了建立自监督学习驱动的遥感影像智能解译框架涉及的主要研究问题,以期推动自监督学习技术在遥感影像智能解译领域的发展与应用。
1 有监督的遥感影像智能解译研究进展 1.1 面向遥感影像智能解译的监督学习范式定义对应于人类认知遥感影像时思考"影像中存在哪些地物目标?""这些地物目标在哪里?""这些地物目标联合起来展现什么样的场景?"层层递进的理解方式,也对应于从单一到全面的理解内容,遥感影像智能解译可分为像素级理解、目标级理解和场景级理解3个层次,如图 1所示。

|
| 图 1 遥感影像智能解译涉及的主要任务 Fig. 1 The main tasks involved in RSI intelligent interpretation |
尽管这3种方式可认为是从不同层次、不同角度来理解遥感影像,但从信息提取的角度来看,它们本质上都属于一个模式识别与分类问题,采用监督学习方式是目前解决该问题最主流也最具代表性的研究方向[20]。在监督学习过程中,这3种理解方式分别以像素、目标和场景作为最小的学习单元,然后通过大量的标注样本来进行特征表示和分类器训练,以此建立从输入影像数据x到其对应标签y之间的函数映射关系f(x)用于后续未知样本的分类与预测, 具体流程可抽象为数据集标注、监督模型构建、损失函数定义和最优化学习4部分,其形式化数学描述表述如下
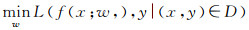 (1)
(1)
式中,f(x; w)表示监督学习模型;w表示模型的参数;f(x; w)本质上用于描述本文将采用什么样的特征和模型来表示并拟合数据,以建立数据到真实标签的函数映射关系;L表示损失函数,本质上描述监督学习模型f(x; w)在什么度量标准下以什么形式逼近真实标签y,主要解决模型预测值与真实标签之间差异度量的问题;min表示最优化求解器,主要解决在损失函数L的意义下如何通过调节模型参数w以缩小模型预测值与真实标签差异的问题,它可以是随机梯度法、进化算法等;D={(xi, yi)|i=1,2,…,N}表示人工标注数据集,其作用是给模型提供可学习的样本和可验证的真实标签。在监督学习过程中,真实标签至关重要,它为模型学习提供了逼近的标准。
1.2 人工构筑特征阶段在深度学习方法出现之前,常用的监督学习范式将监督模型学习分解为遥感地物目标特征描述和分类器学习两个独立的模块,然后分别进行优化,如图 2所示。在特征描述方面,该阶段常用的特征多为手工特征,包括底层特征和中层特征两大类。底层特征可进一步细分为光谱特征、纹理特征、形状特征及局部不变特征4类,代表性方法包括归一化植被指数[21]、Gabor纹理[22]、形态学剖面[23]、形态学房屋指数[24]、Harris角点[25]、SIFT特征[26]等。为缩小视觉上的"语义鸿沟",中层特征表达方法也在遥感影像智能解译领域得到了快速发展,其主要思想为,通过对底层特征进行特征编码以获得对尺度、旋转、光照等影像变化更为稳健的特征表达。常用的中层特征编码方法包括视觉词袋模型[27]、狄利克雷多主题模型[28]、概率潜在语义模型[29]、层次贝叶斯模型[30]等。在分类器方面,遥感领域研究学者对此研究并不多,一般直接使用机器学习领域较为成熟的分类器,包括支持向量机[31]、随机森林[32]、概率图模型[33]等。

|
| 图 2 手工特征阶段的监督学习范式 Fig. 2 Supervised learning paradigm driven by hand-crafted feature |
这一阶段采用手工特征结合监督分类进行机器解译很大程度上缓解了人工目视解译的压力,但是仍然存在两点不足:
(1) 从特征描述的角度来看,手工设计特征费时费力,需要启发式专业知识,且特征可分性依赖于经验上的参数设置,受主观因素影响大。
(2) 从模型优化的角度来看,该阶段将遥感地物目标特征提取和分类器学习视为两个独立的模块,然后分别进行优化,容易收敛到局部最优解。
1.3 数据驱动的特征学习阶段近年来,随着大规模标注数据的发布和高性能计算的普及,以深度学习为代表的数据驱动方法凭借其强大的特征学习和多层次表达能力,在遥感影像智能解译领域已得到广泛关注,并取得了令人印象深刻的结果。深度学习以数据驱动的形式来学习特征,并通过"端对端"的方式将特征学习与分类器优化嵌入同一个框架下进行联合优化,是其在遥感影像解译任务上较传统方法表现更优的关键原因,如图 3所示。下面分别从场景分类、语义分割、目标识别3个方面介绍深度学习方法在遥感影像智能解译领域的主要工作进展。

|
| 图 3 特征学习阶段的监督学习范式 Fig. 3 Supervised learning paradigm driven by feature learning |
1.3.1 场景分类
遥感影像场景分类侧重于影像内容的整体理解,即可理解为一个图像级分类问题。早期基于深度学习遥感影像场景分类工作的主要思路为:直接使用在大规模自然图像数据集(如ImageNet[34])预训练的卷积神经网络(convolutional neural networks,CNN)作为特征提取器,然后对网络进行微调以一种迁移学习的思想完成遥感场景分类。这种"拿来主义"思想虽然在一些同样只包含RGB 3个波段的航空遥感场景分类数据集上(如UC Merced、AID等)表现出较好的分类效果[35-36],但因微调过程中存在的数据通道数与网络结构固化等问题,导致无法充分利用遥感数据丰富的光谱特征,也无法根据遥感场景分类任务特点优化网络结构。针对这一问题,许多研究学者选择结合遥感影像及场景分类特点对网络结构或目标函数进行再设计,然后从头训练整个网络。如文献[37]针对遥感影像场景分类中各类地物尺度差异大的问题,提出了一个包含固定规模网络和可变规模网络的双重分支结构,从而实现在多尺度上对遥感场景进行训练和学习。针对影像场景中多类地物目标共存的问题,文献[38]将注意力递归卷积网络用于场景分类,这种循环注意结构可以自适应地选择并关注关键区域的信息并丢弃非关键信息,进一步提升了分类性能。文献[39]研究发现对于包含丰富光谱信息的哨兵影像,使用所有光谱信息从头训练改进的ResNet网络模型比预训练模型表现更优。另外,为改善遥感场景类内差异大和类间差异小带来的细粒度场景分类精度低的问题,文献[40]通过引入深度度量学习方法建立新的特征空间,目标是在新的特征空间中聚集同类场景并拉远不同类场景之间的距离以提升分类精度。
1.3.2 语义分割遥感影像语义分割旨在为影像中每一个像素分配一个土地覆盖标签,即可理解为一个像素级分类问题。文献[41]提出全卷积神经网络(fully convolutional networks,FCN)突破了卷积神经网络应用到语义分割领域的限制。全卷积神经网络一般采用编码器-解码器的框架结构,其中编码器一般定义为一个下采样网络,主要用于学习多层次的语义特征。而解码器一般定义为一个上采样网络,主要用于将编码器学习到的语义特征映射到原始分辨率的像素空间用于像素级分类。目前在遥感领域,研究学者结合遥感影像特点对FCN进行了大量改进,如针对遥感地物类别丰富多样、边界复杂这一特点,文献[42]通过设计反卷积和跳跃连接来改进解码器以改善遥感地物边缘细节提取效果;文献[43]通过减小空洞卷积的扩展因子以聚合局部特征以解决FCN方法提取的地物边缘细节模糊的问题。针对复杂遥感场景中地物多尺度问题,文献[44]提出利用门控卷积结构(gated convolutional neural network,GCNN)完成不同层次特征图之间的信息传播以实现多尺度特征融合;文献[45]基于分组卷积的设计思想提出一种高效带空洞的空间金字塔网络完成遥感地物要素多尺度信息提取;文献[46]则结合空洞卷积和通道注意力机制实现自适应多尺度的语义分割。另外针对FCN由于固定感受野而无法自适应捕捉不同地物间长远程依赖关系的问题,研究学者们利用递归神经网络、自注意力机制等方法对遥感地物长远程上下文关系进行建模以进一步改善语义分割精度[47-49]
1.3.3 目标识别遥感影像目标识别侧重于分析和描述影像中地物目标的类别和其所处的位置,即可理解为一个对象级分类问题。目前基于深度学习的遥感影像自动地物识别方法主要可分为两大类:
(1) 以R-CNN[50]、Fast-RCNN[51]、Faster-RCNN[52]等为代表的基于建议区域的目标识别方法。该类方法首先通过选择性搜索算法或区域建议网络(region proposal network,RPN)提取一组建议区域,然后在建议区域内通过深度神经网络提取目标候选区域的特征,最后利用这些特征进行目标识别以及目标真实边界的回归。由于遥感影像背景复杂,算法给出的建议区域可能存在大量的噪声,而过多的噪声将会混淆物体信息、模糊目标的边界细节,进而导致漏检并增加虚景。针对该问题,大量研究[53-54]发现在Faster-RCNN框架中引入空间注意力和通道注意力模块能更好地捕捉复杂背景下的物体特征,提高目标识别算法的稳健性。
(2) 以文献[55—56]为代表的基于冋归的目标识别方法。该类方法丢弃第一类方法中建议区域生成的思想,而直接通过构造一个回归网络来完成目标识别和定位,因此,较第一类方法在速度上有了较大的提升。另外,针对遥感影像目标具有任意角度的特点,文献[57]提出在回归预测目标位置的同时,也对目标的角度信息进行估计,可提供更准确的目标位置定位。针对密集小目标检测问题,文献[58]通过对YOLO网络架构进行改进,加密了最后预测输出的栅格数量,以改善小目标和密集目标群的检测。
1.4 监督学习范式在遥感影像解译应用中的局限性和解决思路尽管监督学习是目前解决遥感影像解译问题最为主流的方法,但如何利用遥感影像数据完成大区域、复杂场景下影像智能解译任务仍然是一个世界性、开放性难题,要想从实质上推进遥感智能解译的发展,必须要认识到监督学习范式存在的不足和局限性,如图 4所示。

|
| 图 4 监督学习范式在遥感解译中存在的瓶颈问题 Fig. 4 The bottleneck problem of supervised learning paradigm in remote sensing interpretation |
(1) 从数据层面上来看,深度神经网络的成功在于它在拟合大规模样本的同时不会大幅牺牲泛化能力,但在遥感影像解译领域,构建一个大规模、高质量、完备的遥感场景分类数据集面临着诸多挑战:首先从时间上来看,一个训练样本只能代表一个时间截面的采样,而遥感影像解译对象是全球性、高度动态变化的,其特征随气象,气候,光照,季节,卫星成像条件等变化而变化, 这种时间异质性对样本标注的质量、规模和完备性提出了更高的要求。其次从空间上来看,由于气候光照条件的差异,不同区域的地物类别分布存在天然的异质性(如湖南地区多耕地而宁夏地区多草地)。这种空间异质性导致在监督学习过程中,无论在训练集内部还是训练集和测试集之间都极易出现样本类别不平衡现象[59-60], 进而引发"过学习"或"欠学习"问题,最终导致在应用上的失效。
(2) 从学习机制上来看,目前以监督学习为主流的深度学习方法在有限样本上进行训练学习,由于样本的封闭性和样本特征的动态变化性很容易导致方法性能的崩塌。虽然通过加大标注样本的数目可以缓解这一问题,但由于获取高质量数据标注成本极高,且难以满足样本的时间动态性,因此,这一矛盾从原理上决定了监督学习范式的先天不足。其次,监督学习主要依靠人工标注提供的语义支持作为唯一的学习信号进行模型学习,如果将人类的标注作为一种知识先验,那么在标注的过程中实际上已经给机器做了知识的限定。但对于海量遥感数据而言,其内蕴信息理论上应该比稀疏标签所提供的语义信息丰富得多,因此过分依赖于人工标注,将使得学习得到的模型存在"归纳偏置"的风险。
要有效解决上述问题,需要引入一种新的机器学习范式:这种新范式可以高效灵活地利用海量无标签遥感影像进行自主学习,由于无须引入样本标签,使得无限制、全球性、多时态遥感影像的学习成为可能,也可避免监督学习中常见的数据类别不平衡问题。同时也希望这种新范式的学习能力能够优于传统的无监督学习,它能够建立并利用有效的学习信号驱动模型学习,以保证学习得到的特征和目标任务有很好的关联。此外也希望这种新的学习机制能够利用多样化的特征学习信号进行学习,从而起到比监督学习仅利用真实标签提供的语义支持作为唯一的学习信号更好的特征学习效果。
2 自监督的遥感影像智能解译发展展望 2.1 自监督学习自监督学习是近年来兴起的一种新的机器学习范式[61],它与监督学习方法的核心差异在于自监督学习通过人工设计的自监督学习信号从海量无标注数据中挖掘自身的监督信息构成伪标签,从而替代传统人工标注数据来驱动模型进行特征学习。目前常用的自监督学习方法可分为生成型和对比型两大类。
2.1.1 生成型自监督学习方法生成型自监督学习方法的基本思想为通过还原人为破坏后的图像来达到特征学习的目的,其背后的动机为一旦模型能够完全还原原始图像,则说明模型已学习到能够刻画原始图像的关键特征。基于该思想的自监督学习信号构建方法包括图像修复、图像上色等。
图像修复自监督学习信号[62-63]构建流程为首先在原始图像中随机剔除一部分内容,然后利用剩余部分对剔除部分进行预测来补全图像(如图 5所示),其背后的动机为只有模型真正读懂了这张图所代表的含义,才能有效地进行缺失信息补全。具体来说,该方法通常将一张残缺图像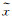
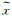
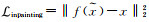

|
| 图 5 图像修复自监督学习信号构建 Fig. 5 Image inpainting pretext task |
图像上色自监督学习信号构建[64-65]的设计动机为不同物体的语义与其颜色间可能有较强的关联性,比如天空是蓝色,草地是绿色,斑马是黑白相间的,因此只有模型可以理解图像中的语义信息才有可能给图像中的不同区域上正确的颜色。其一般流程如图 6所示,用输入灰度图像对应的彩色图像作为学习的标签,通过最小化灰度图像和对应彩色图像间的色彩重建损失迫使模型学习建立从"是什么"到"上什么颜色"之间的映射关系。

|
| 图 6 图像上色自监督学习信号构建示意图 Fig. 6 Image colorization pretext task |
2.1.2 对比型自监督学习方法
对比型自监督学习方法的核心思想为将同一图像不同视图表示(正样本对)拉近并将不同图像的视图表示(负样本对)拉远,从而达到学习兼具不变性和可区分性特征表达的目的,其实现流程主要包含两个步骤,如图 7所示。

|
| 图 7 对比型自监督学习方法主要流程 Fig. 7 The main process of contrastive self-supervised learning method |
(1) 对于每一个无标签数据x, 引入数据增强技术构建正样本对(x, x+),其中x+=T(x)通过对数据x施加随机数据变换T(·)得到(如随机裁剪、缩放、翻转、旋转、随机噪声、随机颜色失真等)。
(2) 构建如式(2)定义的对比损失函数,并通过最小化该损失函数,达到拉近正样本间的距离同时拉远负样本间的距离的目的,以此来强化学习得到特征的不变性和可区分性。
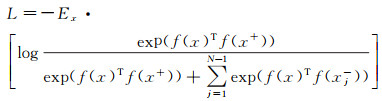 (2)
(2)
式中,xj-表示与x不同的数据样本;f(·)表示卷积神经网络提取的特征表达。
目前大量研究表明,在对比自监督学习过程中构建合理的正样本对并包含足够多、足够难的负样本对是提升对比学习性能的关键。对此,文献[66]通过维持一个大的负样本队列并采用动量对比学习的机制来更新负样本编码器,巧妙地将一个学习批次能够容纳的负样本数量和模型batch size大小进行解耦。文献[67]则认为,在对比学习过程仅仅通过增加负样本对数目并不能保证性能稳定上升,提出通过在特征空间进行特征混合的形式,产生更难的分类样本来提升对比学习能力。另外,文献[68]发现,采用多种数据变换组合的形式构建正样本对比实用单一数据变换更有益于提升对比学习性能。
2.2 主要研究问题和研究展望自监督学习技术已在自然图像分析任务中取得了阶段性成果,甚至在某些细分任务中(如图片分类,医学图像分割、目标跟踪)的表现性能已经接近甚至超过监督学习方法,但目前在遥感领域却鲜有研究。自监督学习技术对遥感影像智能解译研究有独到意义:从数据层面来看,由于最近全球对地观测系统的快速发展,多时相、全球覆盖的遥感影像变得唾手可得,这为在遥感领域开展自监督学习研究提供了强大的数据支撑。从理论与方法层面来看,相对于传统的监督学习范式,自监督学习既能够低成本地利用海量无标注遥感数据驱动模型学习,也能够灵活地利用多样化的特征学习信号充分挖掘海量遥感数据的内蕴信息,因此具备解决当前有监督的遥感影像解译方法面临的瓶颈问题的潜力。但要想真正实现自监督学习驱动的遥感影像智能解译框架,并突破当前监督学习范式在遥感解译过程中面临的瓶颈问题,本文认为应围绕以下3个关键问题开展研究工作,如图 8所示。

|
| 图 8 自监督学习驱动的遥感影像智能解译主要研究内容 Fig. 8 The main research content of remote sensing image interpretation driven by self-supervised learning |
2.2.1 面向自监督学习的超大规模遥感样本数据集高效构建问题
与监督学习相比,自监督学习的核心优势在于能够低成本地利用海量无标注数据驱动模型学习,但文献[69]表明自监督学习方法能否学习到有价值的图像表征与自监督学习数据集包含样本类别的丰富性和多样性有密切关系。因此,期望用于自监督学习的遥感数据集具有:在内容上能够涵盖类别丰富、类内多样的遥感场景要素;在时空上能够涵盖多季节、多气候以及多尺度; 在波谱上能够涵盖多个遥感成像传感器。理论上来讲,当数据集达到千万甚至更大规模的时候,上述特性应该都能够得到较好的满足,但背后存在的关键问题在于如何自动采集大规模、高质量的遥感样本。尽管传统格网采样的办法简单直接,但由于遥感地物通常不可能完全按照规则格网划分,导致该方法通常会存在采集的样本没有包含明显或完整的地物语义内容、甚至多种地物语义混杂等问题。如果在格网采样的基础上进行人工过滤无疑又违背了自监督学习无须过多人工干预的初衷。因此采用何种策略才能实现高质量样本自动采集和冗余样本快速清洗,是保证面向遥感智能解译的自监督学习理论与方法研究有效开展的基础问题。
针对上述问题,本文认为可综合以下3个途径完成超大规模遥感样本数据集高效构建工作:①充分利用已有丰富的地理国情监测、三调等重大工程积累的样本数据和成果进行引导式采样。以文献[70]发布的全球地表覆盖制图为例,其空间分辨率10 m,共包含10个一级类,可用于直接指导林地、草地、河流湖泊、山体等变化较为缓慢的地物样本采集。②借助OpenStreetMap(OSM) 等众源地理数据进行引导采样。近年来众源地理数据发展迅速,其数据量大、信息丰富、成本低廉以及现势性强的特点使其相比于传统地理数据有很大的优势,其所提供的路网、建筑物等丰富地物属性与标记可为自动化采样提供位置与语义信息,从而可极大程度上提高采样效率[71]。③利用现有人工标注数据集训练自动采样模型。尽管当前基于深度学习的目标识别算法还不能做到全目标精准识别,但对于如机场、港口、停车场等人工构筑物已能达到较高的目标检测识别精度[72],因此可考虑采用机器模型完成上述类别的地物自动采样。另外,需要注意的是自监督学习研究并不需要样本标签,其采样的主要目标是希望采集的样本能够包含明显的地物语义信息,因此采样过程中存在一些类别错误也是可以容忍的。
2.2.2 自监督学习信号与遥感特征表示能力的内在关系问题自监督学习和监督学习的核心差异在于,其通过人工设计的自监督学习信号从海量无标注数据中挖掘关联信息构成伪标签,从而替代人工标注来驱动模型进行特征学习。因此,一个很自然的问题是,在遥感影像解译目标任务已知的情况下,什么样的学习信号提供的伪标签才能起到替代真实标签效果。此外,相对于监督学习仅利用真实标签提供的语义支持作为唯一的特征学习信号,自监督学习可以通过设计多样化的学习信号进行特征学习是其优势。但学习信号与特征表示能力的内在关系目前并不清楚:设计与遥感解译目标任务相关的自监督学习信号是否对提升特征可分性有帮助?什么样的自监督信号在什么条件下有助于捕捉高维遥感数据内在不变特征?为回答上述问题,摸清自监督学习信号与遥感特征表示能力的内在关系,是建立有效自监督遥感解译框架的核心研究问题。
针对上述问题,本文认为可从特征"可分性"和"不变性"这两个基本原则入手,结合先验知识和遥感数据自身特点,开展契合遥感影像解译任务的自监督学习信号构建方法研究,探索自监督学习信号在特征"可分性"和"不变性"两方面对特征学习性能的影响。在特征可分性方面,尽管当前主流的自监督对比学习方法特征已经能够提供一个较好的可分性特征学习框架[73-74],但将其应用于遥感领域时还应充分考虑遥感数据自身特点,才能充分发挥海量遥感数据驱动和自监督学习技术的双重优势。比如,遥感时间序列间隐含了很强的时空自相似性,利用这一特点,可以假设相隔距离和时相接近的地物特征应该是相似的,而相隔距离和时相较远的地物特征是不相似的,然后以此作为依据构建正负样本对进行自监督对比学习。另外,对于同一区域可以获取不同视角、不同波谱、不同模态的数据,尽管在视觉上这些数据间存在很大差异,但从语义角度来看它们都属于同一地物对象不同视图表达[75],其背后隐含的"语义一致性和关联性"约束也可从特征不变性角度启发相应的自监督学习信号设计。此外,对于海量遥感数据而言,其内蕴信息理论上应该比稀疏标签所提供的语义信息丰富得多,那么是否可以通过设计多个自监督学习信号从不同角度挖掘数据内蕴特征,从而起到比监督学习仅利用真实标签作为唯一学习信号更好的特征学习效果,也是值得重点关注的研究问题。
2.2.3 自监督学习特征有效迁移问题通过使用超大规模的无标注数据集并设计有效的自监督学习信号,自监督学习理论上可以学习得到一种全局的知识表征,但如何保证这种知识表征能够有效地迁移到目标任务目前尚不清楚。具体而言,由于不同的自监督学习信号设计的出发点不一样,导致学习得到的特征与遥感解译目标任务关联度也会不一样。如果将特征看成一种知识,有的可能与目标任务直接相关,有的可能只是间接相关,这就意味着他们对于指导遥感解译模型学习的效果也是不一样的,如果采用统一的特征迁移策略可能会造成无效迁移甚至是负迁移进而损害模型的泛化性能。因此,对于不同类型的特征,采用何种迁移策略才能发挥其最佳效果,是建立有效自监督遥感解译框架的另一个核心研究问题。
对于与遥感解译目标任务强相关的自监督学习特征,理论上来讲可直接采用传统微调的方式实现自监督学习特征到目标任务的迁移。但存在的问题是:由于遥感影像解译是一个开放性任务,自监督学习训练集和目标任务数据集可能来自于不同传感器,但传统微调迁移方法是建立在同构网络框架下的,因此无法根据数据集的变化灵活调整网络结构,这将导致丰富的光谱特征没有被充分利用(从RGB航空遥感影像迁移到多光谱遥感影像)或反之信息丢失(如从多光谱遥感影像迁移到RGB航空遥感影像)的问题。针对该问题,本文认为可借鉴机器学习中知识蒸馏技术[76]方法,实现强关联的自监督特征有效迁移,其基本思路为,将已学习得到的自监督学习网络作为老师网络,然后通过老师网络提供高置信度的伪标签来指导学生网络学习(与目标任务数据集适配的网络结构),从而达到在不同传感器条件下自监督学习特征有效迁移的目的。但由于自监督学习信号的多样性,某些学习得到的特征可能仅具有一定的"不变性"而不具备很好的"可分性",这意味着如果仍采用上述迁移方法,可能会由于该类型特征无法提供高质量的伪标签,进而导致无效迁移甚至是负迁移。针对该问题,本文认为可采用特征图相似性保持的弱关联特征迁移方法[77],其设计动机为:如果自监督学习得到的特征具有较强的不变性,那么两个相关数据在已训练的自监督学习网络中应该有高度相似的激活特征图。因此为保证该类型特征能够有效迁移,特征迁移的目标可定义为引导目标网络趋向于对这两个输入也同样产生高度相似的激活特征图。此外,对于两种不同类型的自监督学习特征,如何充分发挥各自的互补优势,以实现多类型自监督学习特征从已训练自监督学习模型到遥感影像解译模型的集成迁移也是一个非常值得研究的问题。
3 结论虽然近年来遥感对地观测数据呈现爆炸式增长,但这些遥感数据大部分都是未经标注的,因此无法直接利用这些数据以监督学习范式来训练一个高精度的遥感影像解译模型。虽然本领域已公开发布了很多带标注的遥感影像数据集[78-80],但由于遥感数据自身时空异质性的原因,导致无论从体量还是质量上来看,现有公开数据集都无法支撑学习得到一个具有良好迁移泛化性能的遥感解译模型。
在这一背景下,本文分别从数据需求和学习机制两个层面,深入分析了当前监督学习范式在遥感影像解译任务上存在的不足和局限性,并指出相对于传统的监督学习范式,自监督学习既能够低成本地利用海量无标注遥感数据驱动模型学习,也能够充分利用多样化的特征学习信号挖掘遥感数据丰富的内蕴信息,因此在遥感影像智能解译任务上具有更好的应用潜力。在此基础上,分别从面向自监督学习的超大规模遥感数据集高效构建、自监督学习信号与遥感影像表征的内在关系、自监督学习特征有效迁移机制3个方面,归纳梳理了建立自监督的遥感影像智能解译框架涉及的3个关键研究问题,并给出相应的解决思路和方案,以期为数据源极大丰富条件下开展遥感影像智能解译研究提供新的视角。
| [1] |
国家对地观测科学数据中心. 中国对地观测数据资源发展报告2019[R]. 北京: 中国科学院空天信息创新研究院, 2020: 1-34. National Earth Observation Data Center. Executive summary of the report on earth observation data resources of China (2019)[R]. Beijing: Aerospace Information Research Institute, Chinese Academy of Sciences, 2020: 1-34. |
| [2] |
何国金, 王力哲, 马艳, 等. 对地观测大数据处理: 挑战与思考[J]. 科学通报, 2015, 60(Z1): 470-478. HE Guojin, WANG Lizhe, MA Yan, et al. Processing of earth observation big data: challenges and countermeasures[J]. Chinese Science Bulletin, 2015, 60(Z1): 470-478. |
| [3] |
李德仁, 王密, 沈欣, 等. 从对地观测卫星到对地观测脑[J]. 武汉大学学报(信息科学版), 2017, 42(2): 143-149. LI Deren, WANG Mi, SHEN Xin, et al. From earth observation satellite to earth observation brain[J]. Geomatics and Information Science of Wuhan University, 2017, 42(2): 143-149. |
| [4] |
李德仁, 张良培, 夏桂松. 遥感大数据自动分析与数据挖掘[J]. 测绘学报, 2014, 43(12): 1211-1216. LI Deren, ZHANG Liangpei, XIA Guisong. Automatic analysis and mining of remote sensing big data[J]. Acta Geodaetica et Cartographica Sinica, 2014, 43(12): 1211-1216. |
| [5] |
张兵. 遥感大数据时代与智能信息提取[J]. 武汉大学学报(信息科学版), 2018, 43(12): 1861-1871. ZHANG Bing. Remotely sensed big data era and intelligent information extraction[J]. Geomatics and Information Science of Wuhan University, 2018, 43(12): 1861-1871. |
| [6] |
CLERY D, VOSS D. All for one and one for all[J]. Science, 2005, 308(5723): 809-810. DOI:10.1126/science.308.5723.809 |
| [7] |
杜培军, 夏俊士, 薛朝辉, 等. 高光谱遥感影像分类研究进展[J]. 遥感学报, 2016, 20(2): 236-256. DU Peijun, XIA Junshi, XUE Zhaohui, et al. Review of hyperspectral remote sensing image classification[J]. Journal of Remote Sensing, 2016, 20(2): 236-256. |
| [8] |
CHENG Gong, HAN Junwei. A survey on object detection in optical remote sensing images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 117: 11-28. DOI:10.1016/j.isprsjprs.2016.03.014 |
| [9] |
CHENG Gong, HAN Junwei, LU Xiaoqiang. Remote sensing image scene classification: benchmark and state of the art[J]. Proceedings of the IEEE, 2017, 105(10): 1865-1883. DOI:10.1109/JPROC.2017.2675998 |
| [10] |
HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507. DOI:10.1126/science.1127647 |
| [11] |
ZHU Xiaoxiang, TUIA D, MOU Lichao, et al. Deep learning in remote sensing: a comprehensive review and list of resources[J]. IEEE Geoscience and Remote Sensing Magazine, 2017, 5(4): 8-36. DOI:10.1109/MGRS.2017.2762307 |
| [12] |
MA Lei, LIU Yu, ZHANG Xueliang, et al. Deep learning in remote sensing applications: a meta-analysis and review[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 152: 166-177. DOI:10.1016/j.isprsjprs.2019.04.015 |
| [13] |
CHENG Gong, XIE Xingxing, HAN Junwei, et al. Remote sensing image scene classification meets deep learning: challenges, methods, benchmarks, and opportunities[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 3735-3756. DOI:10.1109/JSTARS.2020.3005403 |
| [14] |
陈军, 陈晋. GlobeLand30遥感制图创新与大数据分析[J]. 中国科学: 地球科学, 2018, 48: 1391-1392. CHEN Jun, CHEN Jin. 2018. GlobeLand30:Operational global land cover mapping and big-data analysis[J]. Science China Earth Sciences, 2018, 48: 1391-1392. |
| [15] |
JING Longlong, TIAN Yingli. Self-supervised visual feature learning with deep neural networks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2393, PP(99): 1. |
| [16] |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota: NAACL, 2019: 4171-4186.
|
| [17] |
CARON M, MISRA I, MAIRAL J, et al. Unsupervised learning of visual features by contrasting cluster assignments[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Curran Associates, Inc, 2020: 9912-9924.
|
| [18] |
LAI Zihang, LU E, XIE Weidi. MAST: a memory-augmented self-supervised tracker[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 13-19, 2020, Seattle, WA, USA. IEEE, 2020: 6478-6487.
|
| [19] |
HAGHIGHI F, TAHER M R H, ZHOU Z, et al. Learning semantics-enriched representation via self-discovery, self-classification, and self-restoration[C]//Proceedings of 2020 International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2020: 137-147.
|
| [20] |
周培诚, 程塨, 姚西文, 等. 高分辨率遥感影像解译中的机器学习范式[J]. 遥感学报, 2021, 25(1): 182-197. ZHOU Peicheng, CHENG Gong, YAO Xiwen, et al. Machine learning paradigms in high-resolution remote sensing image interpretation[J]. Journal of Remote Sensing, 2021, 25(1): 182-197. |
| [21] |
ROUSE J W, HAAS R H, SCHELL J A, et al. Monitoring vegetation systems in the Great Plains with ERTS[J]. NASA special publication, 1974, 351(1974): 309-317. |
| [22] |
MANJUNATH B S, MA W Y. Texture features for browsing and retrieval of image data[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(8): 837-842. DOI:10.1109/34.531803 |
| [23] |
PESARESI M, BENEDIKTSSON J A. A new approach for the morphological segmentation of high-resolution satellite imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2001, 39(2): 309-320. DOI:10.1109/36.905239 |
| [24] |
HUANG Xin, ZHANG Liangpei. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2012, 5(1): 161-172. DOI:10.1109/JSTARS.2011.2168195 |
| [25] |
HARRIS C, STEPHENS M. A combined corner and edge detector[C]//Procedings of 1988 Alvey Vision Conference 1988. Manchester. Alvey Vision Club, 1988: 10-5244.
|
| [26] |
LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. DOI:10.1023/B:VISI.0000029664.99615.94 |
| [27] |
YANG Y, NEWSAM S. Spatial pyramid co-occurrence for image classification[C]//Proceedings of 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011: 1465-1472.
|
| [28] |
ZHAO Bei, ZHONG Yanfei, XIA Guisong, et al. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(4): 2108-2123. DOI:10.1109/TGRS.2015.2496185 |
| [29] |
ZHAO Bei, ZHONG Yanfei, ZHANG Liangpei. Scene classification via latent Dirichlet allocation using a hybrid generative/discriminative strategy for high spatial resolution remote sensing imagery[J]. Remote Sensing Letters, 2013, 4(12): 1204-1213. DOI:10.1080/2150704X.2013.858843 |
| [30] |
ZHANG Xiuyuan, DU Shihong, WANG Qiao. Integrating bottom-up classification and top-down feedback for improving urban land-cover and functional-zone mapping[J]. Remote Sensing of Environment, 2018, 212: 231-248. DOI:10.1016/j.rse.2018.05.006 |
| [31] |
MOUNTRAKIS G, IM J, OGOLE C. Support vector machines in remote sensing: a review[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2011, 66(3): 247-259. DOI:10.1016/j.isprsjprs.2010.11.001 |
| [32] |
PAL M. Random forest classifier for remote sensing classification[J]. International Journal of Remote Sensing, 2005, 26(1): 217-222. DOI:10.1080/01431160412331269698 |
| [33] |
ZHENG Chen, ZHANG Yun, WANG Leiguang. Semantic segmentation of remote sensing imagery using an object-based Markov random field model with auxiliary label fields[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(5): 3015-3028. DOI:10.1109/TGRS.2017.2658731 |
| [34] |
DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248-255.
|
| [35] |
PENATTI O A B, NOGUEIRA K, DOS SANTOS J A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains?[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitionworkshops. Boston, MA: IEEE, 2015: 44-51.
|
| [36] |
MARMANIS D, DATCU M, ESCH T, et al. Deep learning earth observation classification using ImageNet pretrained networks[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(1): 105-109. DOI:10.1109/LGRS.2015.2499239 |
| [37] |
LIU Yanfei, ZHONG Yanfei, QIN Qianqing. Scene classification based on multiscale convolutional neural network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(12): 7109-7121. DOI:10.1109/TGRS.2018.2848473 |
| [38] |
WANG Q, LIU S, CHANUSSOT J, et al. Scene classification with recurrent attention of VHR remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 57(2): 1155-1167. |
| [39] |
WANG Qi, LIU Shaoteng, CHANUSSOT J, et al. Scene classification with recurrent attention of VHR remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(2): 1155-1167. DOI:10.1109/TGRS.2018.2864987 |
| [40] |
HELBER P, BISCHKE B, DENGEL A, et al. EuroSAT: a novel dataset and deep learning benchmark for land use and land cover classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019, 12(7): 2217-2226. DOI:10.1109/JSTARS.2019.2918242 |
| [41] |
叶利华, 王磊, 张文文, 等. 高分辨率光学遥感场景分类的深度度量学习方法[J]. 测绘学报, 2019, 48(6): 698-707. YE Lihua, WANG Lei, ZHANG Wenwen, et al. Deep metric learning method for high resolution remote sensing image scene classification[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(6): 698-707. |
| [42] |
LONG J, SHELHAMERE, DARRELL T. Fullyconvolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 3431-3440.
|
| [43] |
LIU Yu, MINH NGUYEN D, DELIGIANNIS N, et al. Hourglass-shapenetwork based semantic segmentation for high resolution aerial imagery[J]. Remote Sensing, 2017, 9(6): 522. DOI:10.3390/rs9060522 |
| [44] |
HAMAGUCHI R, FUJITA A, NEMOTO K, et al. Effective Use of Dilated Convolutions for Segmenting Small Object Instances in Remote Sensing Imagery[C]//Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, Nevada: IEEE, 2018: 1442-1450.
|
| [45] |
WANG Hongzhen, WANG Ying, ZHANG Qian, et al. Gated convolutional neural network for semantic segmentation in high-resolution images[J]. Remote Sensing, 2017, 9(5): 446. DOI:10.3390/rs9050446 |
| [46] |
VALADA A, MOHAN R, BURGARD W. Self-supervised model adaptation for multimodal semantic segmentation[J]. International Journal of Computer Vision, 2020, 128(5): 1239-1285. DOI:10.1007/s11263-019-01188-y |
| [47] |
SHANG Ronghua, ZHANG Jiyu, JIAO Licheng, et al. Multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images[J]. Remote Sensing, 2020, 12(5): 872. DOI:10.3390/rs12050872 |
| [48] |
SHUAI Bing, ZUO Zhen, WANG Bing, et al. Scene segmentation with DAG-recurrent neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1480-1493. DOI:10.1109/TPAMI.2017.2712691 |
| [49] |
李道纪, 郭海涛, 卢俊, 等. 遥感影像地物分类多注意力融和U型网络法[J]. 测绘学报, 2020, 49(8): 1051-1064. LI Daoji, GUO Haitao, LU Jun, et al. A remote sensing image classification procedure based on multilevel attention fusion U-Net[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(8): 1051-1064. |
| [50] |
TAO Chao, QI Ji, LI Yansheng, et al. Spatial information inference net: Road extraction using road-specific contextual information[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 158: 155-166. DOI:10.1016/j.isprsjprs.2019.10.001 |
| [51] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio: IEEE, 2014: 580-587.
|
| [52] |
GIRSHICK R. Fast R-CNN[C]//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1440-1448.
|
| [53] |
REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI:10.1109/TPAMI.2016.2577031 |
| [54] |
YANG Xue, YANG Jirui, YAN Junchi, et al. SCRDet: towards more robust detection for small, cluttered and rotated objects[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019: 8231-8240.
|
| [55] |
LI Ke, CHENG Gong, BU Shuhui, et al. Rotation-insensitive and context-augmented object detection in remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2337-2348. DOI:10.1109/TGRS.2017.2778300 |
| [56] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 779-788.
|
| [57] |
XIANG W, ZHANG D Q, YU H, et al. Context-aware single-shot detector[C]//Proceedings of 2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe, Nevada: IEEE, 2018: 1784-1793.
|
| [58] |
YU Yongtao, GUAN Haiyan, LI Dilong, et al. Orientation guided anchoring for geospatial object detection from remote sensing imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 160: 67-82. DOI:10.1016/j.isprsjprs.2019.12.001 |
| [59] |
VAN E A. Satellite imagery multiscale rapid detection with windowed networks[C]//Proceedings of 2019 IEEE Winter Conference on Applications of Computer Vision. Hilton Waikoloa Village, Hawaii: IEEE, 2019: 735-743.
|
| [60] |
H E, H. AND GARCIA, E. A.. Learning from imbalanced data[J]. IEEE Transactions on Knowledge And and Data Engineering, 2009, 21(9): 1263-1284. DOI:10.1109/TKDE.2008.239 |
| [61] |
JOHNSON J M, KHOSHGOFTAAR T M. Survey on deep learning with class imbalance[J]. Journal of Big Data, 2019, 6(1): 1-54. DOI:10.1186/s40537-018-0162-3 |
| [62] |
JAISWAL A, BABU A R, ZADEH M Z, et al. A survey on contrastive self-supervised learning[J]. Technologies, 2021, 9(1): 2. |
| [63] |
IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 1-14. |
| [64] |
PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 2536-2544.
|
| [65] |
ZHANG R, ISOLA P, EFROS A A. Colorful image colorization[C]//Proceedings of 2016 European Conference on Computer Vision (ECCV). Amsterdam, the Netherlands: Springer, 2016: 649-666.
|
| [66] |
LARSSON G, MAIRE M, SHAKHNAROVICH G. Colorization as a proxy task for visual understanding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 840-849.
|
| [67] |
HE Kaiming, FAN Haoqi, WU Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA: IEEE, 2020: 9726-9735.
|
| [68] |
KALANTIDIS Y, SARIYILDIZ M B, PION N, et al. Hard negative mixing for contrastive learning[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. Curran Associates, Inc, 2020: 21798-21809.
|
| [69] |
CHEN TING, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]//Proceedings of the 37th International Conference on Machine Learning. [S. l. ]: PMLR, 2020: 1597-1607. Virtual Event.
|
| [70] |
YANG Xingyi, HE Xuehai, LIANG Yuxiao, et al. Transfer learning or self-supervised learning? A tale of two pretraining paradigms[EB/OL]. [2020-12-16]. . https://arxiv.org/abs/2007.04234.
|
| [71] |
GONG Peng, LIU Han, ZHANG Meinan, et al. Stable classification with limited sample: transferring a 30m resolution sample set collected in 2015 to mapping 10m resolution global land cover in 2017[J]. Science Bulletin, 2019, 64(6): 370-373. DOI:10.1016/j.scib.2019.03.002 |
| [72] |
LONG Yang, XIA Guisong, LI Shengyang, et al. DiRS: On creating benchmark datasets for remote sensing image interpretation[EB/OL]. [2019-11-06]. https://arxiv.org/abs/2006.12485v1.
|
| [73] |
XIA Guisong, BAI Xiang, DING Jian, et al. DOTA: a large-scale dataset for object detection in aerial images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, 2018: 3974-3983.
|
| [74] |
TAO Chao, QI Ji, LU Weipeng, et al. Remote sensing image scene classificationwith self-supervised paradigm under limited labeled samples[J]. IEEE Geoscience and Remote Sensing Letters, 2020(99): 1-5. |
| [75] |
XIE E, DING J, WANG W, et al. Detco: unsupervised contrastive learning for object detection[C]//Proceedings of 2021 IEEE International Conference on Computer Vision. [S. l. ]: IEEE, 2021.
|
| [76] |
ZHU Linchao, YANG Yi. ActBERT: learning global-local video-text representations[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020: 8743-8752.
|
| [77] |
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[C]//Proceedings of 2014 International Conference on Neural Information Processing SystemsDeep Learning workshop. Montreal, Quebec: MIT Press. 2014.
|
| [78] |
TUNG F, MORI G. Similarity-preserving knowledge distillation[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019: 1365-1374.
|
| [79] |
JIN Pu, XIA Guisong, HU Fan, et al. Aid++: an updated version of aid on scene classification[C]//Proceedings of IEEE 2018 International Geoscience and Remote Sensing Symposium. Valencia, Spain: IEEE, 2018: 4721-4724.
|
| [80] |
LI Ke, WAN Gang, CHENG Gong, et al. Object detection in optical remote sensing images: a survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296-307. DOI:10.1016/j.isprsjprs.2019.11.023 |
| [81] |
SUMBUL G, CHARFUELAN M, DEMIR B, et al. Bigearthnet: a large-scale benchmark archive for remote sensing image understanding[C]//Proceedings of 2019 IEEE International Geoscience and Remote Sensing Symposium. Yokohama, Japan: IEEE, 2019: 5901-5904.
|