



高分辨率遥感影像建筑物提取在数字城市建设、地表动态变化监测及土地利用变更调查等应用中都具有重要的意义。但是高分辨率遥感影像细节丰富的特点也使得建筑物的尺度多变、结构复杂、外观各异,如何准确地从高分辨率遥感影像中提取建筑物目前仍是遥感影像处理与应用领域研究的热点和难点。
传统建筑物提取的方法主要根据建筑物特有的光谱、纹理、几何和阴影等特性,人工设计合适的特征去区分建筑物和非建筑物区域[1-3]。文献[4]通过窗口Hough变换提取矩形建筑物的角点特征,实现矩形屋顶的提取,但当建筑物角点被遮挡时,无法精确地提取建筑物。文献[5]利用了遥感影像中建筑物受光照影响产生的阴影信息对建筑物自动定位,然而排列整齐的树木阴影可能会对其造成干扰。此外,DSM数据、LiDAR和SAR数据等多源数据可以提供建筑物的高程信息,融合多源数据可以有效提高建筑物提取的精度[6], 但获得满足精度条件的多源数据需要较高的成本,具有一定的局限性。总体而言,这些人工设计的特征会随着传感器质量、光照条件、建筑物风格产生较为明显的变化,只能处理特定的数据[7]。
近年来,卷积神经网络良好的特征表示能力,使其受到了广泛的关注,在自然语言处理、图像分割、目标检测等领域都有广泛应用[8-11]。建筑物提取方法也由人工设计特征的传统方法转向学习特征的卷积神经网络方法。
文献[12]提出的全卷积神经网络(fully convolutional network,FCN)将传统卷积神经网络中的全连接层转化为卷积层,首次实现端到端训练的语义分割网络。文献[13]以FCN为基础,提出UNet,利用跳跃连接来融合深层特征和浅层特征,使得分割边缘得到提升。FCN是许多语义分割方法的基本框架,基于FCN的方法主要分为两种改进方向:①从特征图出发,扩大卷积神经网络的感受野,获取多尺度特征。文献[14]提出金字塔空间池化模块,融合不同尺度的池化后的特征图以获取全局依赖。文献[15]从原始影像中提取不同尺度的特征,之后在恢复尺度的阶段逐步融合粗糙的浅层特征及细粒度的深层特征,从而使得分割精度提升。②从原始影像出发,利用多尺度的原始影像作为输入,获取全局信息。文献[16]提出一种基于多尺度影像的全卷积神经网络,将原始影像进行不同尺度的下采样,之后分层地对其进行特征提取和融合。注意力机制[17-18]是近几年来提出的一种在空间或通道上捕获远程依赖的方法,能够有效地提高分割性能。文献[19]提出位置注意力模块和通道注意力模块去学习特征之间的空间依赖性以及通道间的相关性。位置注意力模块是对所有位置的特征加权求和,选择性地聚合各个位置的特征,使得远距离特征也可以得到关联。通道注意力模块整合所有通道之间的相关特征图,选择性地强调存在相互依赖的通道图。将两个注意力模块的结果融合可以获得更精确的分割结果。文献[20]通过输入不同尺度的影像,利用分层多尺度注意力机制,学习不同尺寸的物体在相应尺度上的权重,让网络自适应地选择最合适的分辨率来预测物体,但该方法网络结构较为复杂对硬件要求较高。
与基于FCN的主流语义分割框架不同,文献[21]提出了一种高分辨率神经网络(high-resolution network,HRNet), 该方法可使特征图保持高分辨率,在高分辨率特征图中融入低分辨率特征图使其包含多尺度信息,为网络结构设计提供了新的思路。文献[22]设计了一种双层嵌套UNet的网络结构U2Net,能够捕获更多的上下文信息,在显著性检测任务中表现突出,但其参数量较多,训练效率较低。
以往研究中,基于全卷积神经网络的建筑物提取方法基本框架以编码器-解码器结构为主[23-24]。但是该框架在编码器阶段的多次池化易丢失空间信息,使得小型建筑物难以检测;同时在解码器阶段,通过跳跃连接融合浅层特征恢复细节的效果有限,还会从浅层引入一些粗糙特征,最终进一步加剧建筑物边界的不准确[25]。除此之外,卷积神经网络提取的特征往往是局部的,基于FCN的方法缺乏对全局特征的有效利用,导致提取大型建筑物时存在不连续和空洞等情况,如图 1所示。而过于关注全局特征,忽略局部特征,会导致边缘信息的缺失。如何高效利用全局特征和局部特征,是优化建筑物提取结果的关键。因此,受HRNet和U2Net启发,本文提出一种基于RSU模块的高分辨率遥感影像建筑物提取方法:MPRSU-Net,能够在保持高分辨率语义信息的同时,融入全局特征,从而改善大型建筑物存在空洞、边缘分割不完整的问题。MPRSU-Net通过并行和级联RSU模块融合多尺度特征,之后将多个尺度的预测结果融合得到最终提取结果。在WHU和Inria建筑物数据集上的试验结果表明,本文方法提取建筑物精度高、边缘清晰、结构完整,相较其他主流方法泛化能力更强,参数较少。

|
| 图 1 建筑物提取结果示例 Fig. 1 The example results of building extraction |
1 方法与原理
本节首先介绍RSU模块的结构,然后对本文提出的MPRSU-Net进行详细说明,最后阐述了本文方法训练过程中使用的损失函数。
1.1 RSU模块RSU模块是本文网络的主要构成部分,由简化的UNet结构和ResNet的残差结构[26]组成,能够捕捉输入特征图的多尺度特征和局部特征。RSU模块的超参数有L、Cin、Cout和Cmid,分别代表编码器阶段的卷积层数、输入特征图的通道数、输出特征图的通道数和中间层的通道数。本文使用RSU-L(Cin, Cmid, Cout)表示单个RSU模块,结构如图 2所示。RSU模块的输入为通道数Cin的特征图,首先通过一个3×3的卷积,将输入映射为通道数为Cout的特征图,并同时从输入特征图中提取局部特征;然后通道数为Cout的特征图经过一个简化的编码器-解码器结构,其中编码器提取出多尺度特征,编码器阶段的池化次数为L-2,L越大池化次数越多,感受野范围越大,多尺度特征便越丰富,解码器将多尺度特征编码成高分辨率的多尺度特征图;最后将第一步获得的通道数为Cout的特征图和高分辨率的多尺度特征图相加得到输出,使得局部特征和多尺度特征融合,保证特征图中的细节信息不被丢失。

|
| 图 2 RSU结构 Fig. 2 RSU architecture |
1.2 MPRSU-Net
MPRSU-Net的网络结构如图 3所示,主要包括两个部分:多路径特征提取模块和多尺度特征融合模块。

|
| 图 3 MPRSU-Net结构 Fig. 3 MPRSU-Net architecture |
1.2.1 多路径特征提取
基于编码器-解码器结构的卷积神经网络一般过程为:由高分辨率到低分辨率获取深层特征,再从低到高恢复分辨率得到输出结果,此过程中极易丢失细节信息。而HRNet的多路径结构能够有效地解决此问题,较好地保持特征图中的细节信息;其使用多个并行的子网络提取不同尺度的特征,然后将多尺度特征在子网络之间反复交换以充分融合多尺度特征。
基于多路径结构与RSU模块,本文提出多路径特征提取模块,详细架构如图 3所示,不仅能提取多尺度特征,还能减少细节丢失。RSU模块是多路径特征提取模块的主要组成部分,其利用编码器-解码器结构从特征图中提取多尺度特征,再将多尺度特征编码成高分辨率的特征图。多路径结构通过串联RSU模块,能够保持高分辨率的特征表示,减少编码器下采样带来的细节丢失,保持高层语义信息和精确的空间定位信息,改善建筑物边界提取模糊及空洞现象。
MPRSU-Net的多路径特征提取模块由3条并行路径组成,特征图的空间分辨率分别为原始影像的1、1/4、和1/16。对于相邻路径之间的上、下采样,本文使用图 4(c)、(f)所示的方法:上采样先对影像进行双线性上采样,再将低分辨率的特征图的通道压缩,去除冗余信息;下采样时首先扩大一倍通道数,以保存高分辨率的信息,再进行池化。除此之外,常用的上、下采样还有图 4(a)、(d)对应的直接采样方法,但是这种方式很容易造成信息冗余和细节信息丢失。图 4(b)、(e)对应的是没进行通道压缩和扩增的上、下采样,但存在一定程度的信息冗余和丢失。

|
| 图 4 下采样和上采样方法 Fig. 4 The methods of downsample and upsample |
1.2.2 多尺度特征融合
多尺度特征融合模块如图 3所示,首先,利用1×1卷积和sigmoid函数对多路径特征提取模块输出的多尺度特征进行预测,得到每个尺度的分类结果;然后,将各个尺度上的分类结果上采样到输入尺寸后进行拼接;最后,将不同尺度的预测结果融合得到建筑物的最终预测结果。最终的预测结果汇聚了多个尺度的信息,使得反向传播和权重更新能够利用多尺度信息。
1.3 损失函数本文使用二分类交叉熵损失函数[27]来指导网络学习,如式(1)所示
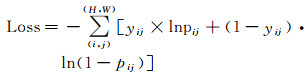 (1)
(1)
式中,(x, y)为样本点坐标;(H, W)为影像尺寸;yij表示样本点的真值;建筑物像素为1;非建筑物像素为0;pij表示模型预测样本点是建筑物像素的概率。
2 试验与分析本节首先介绍试验所采用的数据集、结果评价指标及试验相关设置,之后阐述试验设计目的、结果及分析。
2.1 数据集介绍为证明本文方法的有效性,选取WHU建筑物数据集[7]和Inria建筑物数据集[28]两个数据集进行综合性的试验,数据集的相关描述如下:
(1) WHU建筑物数据集包括航空和卫星影像数据集,以及相应的矢量文件和栅格影像,本文选取航空影像数据集进行试验。航空影像数据集中包含不同尺度、不同风格和颜色的建筑物,如图 5所示,影像空间分辨率为0.3 m,每幅影像的大小为512×512像素,共计8188张,其中训练集、验证集、测试集分别为4736、1036和2416张。

|
| 图 5 WHU数据集样例 Fig. 5 WHU dataset examples |
(2) Inria建筑物数据集包含5个地区(奥斯汀、芝加哥、基特萨普、蒂罗尔西部、维也纳)的航空正射彩色影像,每个地区分别有36张尺寸为5000×5000像素的影像,空间分辨率为0.3 m,数据集示例如图 6所示。数据集中5个地区的影像季节不同,照明条件不同,有建筑物密集的城市中心,也有建筑物稀疏的山区,可用于评估模型的泛化能力。试验前,将每幅影像裁剪为500×500像素的大小,最终获取18 000张影像,其中随机抽取10 832张作为训练集,1805张作为验证集,5363张作为测试集。

|
| 图 6 Inria数据集样例 Fig. 6 Inria dataset examples |
2.2 评价指标
本文采用精度(Precision)、召回率(Recall)、F1分数、交并比(IoU)4个指标来评价建筑物提取的准确性。精度指预测正确的建筑物像素数量占预测的建筑物像素数量的比例。召回率指预测正确的建筑物像素数量占真实的建筑物像素数量的比例。F1分数综合考虑了精度和召回率的结果。IoU是目标检测和语义分割中的常用指标,指预测的建筑物像素数量与真实的建筑物像素的交集和并集的比值。4种指标的计算公式如下
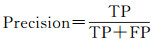 (2)
(2)
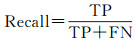 (3)
(3)
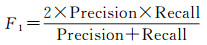 (4)
(4)
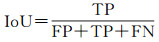 (5)
(5)
式中, TP指真实建筑物像素的预测为建筑物像素的数量;TN指背景像素预测为背景像素的数量;FP指背景像素预测为建筑物像素的数量;FN指真实建筑物像素预测为背景像素的数量。
2.3 试验设置本文试验的硬件环境为Intel(R) Core(TM) i7-7700 CPU,64 GB RAM,GPU Nvidia Titan Xp(显存12 GB),操作系统为Windows10,编程环境为Python3.6,Pytorch1.2.0。
为保证试验结果的客观性,所有试验网络均采用小批量梯度下降算法训练,使用Adam算法进行优化,初始学习率设置为0.001,批处理数量为4。训练过程中,所有试验网络从零开始对数据集迭代100次,并对影像进行随机水平翻转。
2.4 试验及结果分析本节首先分析不同上、下采样方法对本文方法在WHU数据集上性能的影响;使用WHU和Inria数据集进行对比试验,比较本文方法和UNet[13]、DANet[19]、HRNetv2[21]、U2Net[22]4种方法提取建筑物的性能,对比方法中,DANet基本框架设置为101层的ResNet,HRNet多路径通道数设置为48、96、192、384。最后,为验证本文方法在性能和复杂度上面的平衡,对不同方法的复杂度进行分析。
2.4.1 上下采样方法对比试验为探讨不同上、下采样方法对本文方法在WHU数据集上性能的影响,在MPRSU-Net结构基础上使用1.2.1节中3种上、下采样方法进行试验,结果见表 1。表 1中结果显示,间接上、下采样方法与直接采样方法相比,精度和IoU有一定提升,说明连续采样之间添加卷积层可以减少信息损失。本文的上、下采样方法较间接上、下采样方法各项指标均有提升,表明了上采样缩减通道数可以去除冗余信息,下采样扩大通道数可以保存一定的细节信息,验证了本文上、下采样方法的有效性。
| 方法 | IoU | 精度 | 召回率 | F1分数 |
| 直接上、下采样 | 90.36 | 94.96 | 94.91 | 94.94 |
| 间接上、下采样 | 90.67 | 95.36 | 94.85 | 95.11 |
| 本文上、下采样 | 91.17 | 95.65 | 95.11 | 95.38 |
2.4.2 WHU数据集试验结果分析
选取UNet、DANet、HRNet、U2Net 4种方法与本文方法进行对比,在WHU建筑物数据集上的可视化试验结果如图 7所示。卷积神经网络依靠卷积核提取特征,获取感受野范围有限,故提取大型建筑物时,易产生空洞现象。针对该现象,本文方法使用RSU模块融合局部特征和全局特征,扩大感受野,并在不同尺度的RSU模块之间增加信息交互,进一步提升特征聚集率。由图 7中可以看出,第1、第5个样例的影像中,存在颜色相似的地面和建筑物,一些对比方法不能正确地区分两者,导致出现将地面错误识别成建筑物的现象,而本文方法能够较为精确地区分颜色相近的地面及建筑物。此外,对于第1、第4个样例影像中颜色不一致的建筑物,本文方法可以准确提取,而对比方法错误地将其识别为背景,表明本文方法相较于其他方法能够更加充分地获取上下文信息。综上,根据目视评价,可以看出本文方法能够良好地适应不同场景的建筑物提取,在一定程度上可以改善建筑物边界不清晰、出现空洞的现象,且对于“同物异谱,异物同谱”现象可以进行较为正确地识别,结果优于其他几种对比方法。

|
| 图 7 WHU数据集上各种方法的建筑物提取结果 Fig. 7 Building extraction results of various methods on WHU dataset |
对WHU建筑物数据集的提取结果进行定量评价见表 2。由表 2可以看出,在WHU建筑物数据集上,与其他方法相比较,本文方法在各项指标上均达到最优,IoU达91.17%,精度达95.65%,F1分数达到了95.38%,与UNet、DANet、HRNet、U2Net相比IoU分别提高了2.30%、1.96%、1.40%、0.83%,精度分别提高了2.18%、1.44%、0.73%、0.62%。
| 方法 | IoU | 精度 | 召回率 | F1分数 |
| UNet | 88.87 | 93.47 | 94.75 | 94.10 |
| DANet | 89.21 | 94.21 | 94.40 | 94.30 |
| HRNet | 89.77 | 94.92 | 94.30 | 94.61 |
| U2Net | 90.34 | 95.03 | 94.82 | 94.93 |
| MPRSU-Net | 91.17 | 95.65 | 95.11 | 95.38 |
WHU数据集上的试验结果从目视和定量评价上均验证了本文方法的优越性,表明了多路径结构结合编码器-解码器结构使得建筑物的局部特征和全局特征更好地聚合,能够更好地提取建筑物细节信息和全局特征。
2.4.3 Inria数据集试验结果分析Inria数据集包含5个地区的建筑物影像,分别取其典型区域,提取结果可视化如图 8所示,从上到下依次是奥斯汀、芝加哥、基特萨普、蒂罗尔西部和维也纳典型建筑物的提取结果。5个地区的建筑物风格不同,且由于成像时间不同,不同地区的建筑物光谱、阴影特征并不一致。由于树木遮挡、建筑物结构复杂等情况,Inria数据集的建筑物边界不易提取。本文方法通过串联RSU模块,保持高分辨率的语义表示,减少RSU模块中编码器下采样带来的细节丢失,增加高层语义信息和精确的空间定位信息,改善建筑物边界提取模糊及空洞现象。由图 8可以看出,本文方法对不同场景下的大型建筑物的空洞现象都有所改进,提取的建筑物边缘较其他方法更为清晰,且能够更加准确地识别细长型建筑物。对于环绕型、内部存在不规则背景的建筑物,本文方法能够较好地识别被建筑物环绕的背景。综合不同地区的建筑物提取的目视效果上看,本文方法能够较为良好地适应不同场景的大型建筑物提取,边缘较为完整,能够减少建筑物漏检结果,综合表现较优,表明使用多路径结构保持高分辨率的语义信息的可行性。

|
| 图 8 Inria数据集上各种方法的建筑物提取结果 Fig. 8 Building extraction results of various methods on Inria dataset |
对Inria建筑物数据集的提取结果进行定量评价见表 3。虽然该数据集较多建筑物被植被遮挡不易识别,但本文方法仍在各项指标上表现较好,IoU达79.31%,召回率达88.29%,F1分数达88.46%,与UNet、DANet、HRNet、U2Net相比IoU分别提高了1.34%、0.93%、0.53%、2.95%,召回率分别提高了1.85%、2.20%、1.06%、1.59%,证明了本文方法的稳定性和优越性。在该数据集上,本文方法的提取精度稍低,本文分析是由于该数据集小型建筑物较密集,影像尺寸裁剪为500×500像素,本文方法中存在较多的下采样操作,不能整除,导致部分细节信息丢失,精度较低,然而本文方法的精度较同样有多次下采样操作的U2Net方法提升了2.13%,说明了多路径特征提取的有效性。可以进一步探索RSU模块合适的下采样次数,以使提取结果进一步提升。
| 方法 | IoU | 精度 | 召回率 | F1分数 |
| UNet | 77.97 | 88.83 | 86.44 | 87.62 |
| DANet | 78.38 | 89.75 | 86.09 | 87.89 |
| HRNet | 78.78 | 89.04 | 87.23 | 88.13 |
| U2Net | 76.36 | 86.50 | 86.70 | 86.60 |
| MPRSU-Net | 79.31 | 88.63 | 88.29 | 88.46 |
2.4.4 网络复杂度分析
本文对5种方法的模型复杂度及效率进行了比较,结果见表 4。模型的计算量和参数量使用thop工具包进行统计,模型计算量与输入尺寸有关,此处输入尺寸均设置为1×512×512×3。训练时间为迭代一次WHU训练数据集所需要的时间,推理时间为在WHU测试数据集上推理所需要的总时间。由表 4可以看出,本文方法计算量较少,仅是U2Net的1/3,同时本文方法训练效率较高,仅需要U2Net的一半训练时间。综合不同方法在WHU数据集和Inria数据集上的试验结果来看,本文方法在精度和效率方面取得了较好的平衡,有较高的应用价值。
| 方法 | 计算量(GFLOPs) | 参数/M | 训练时间/(min/epoch) | 推理时间/s |
| UNet | 160.6 | 17.3 | 10 | 94 |
| DANet | 282.8 | 66.6 | 107 | 1420 |
| HRNet | 40.7 | 22.4 | 6 | 113 |
| U2Net | 150.5 | 44.0 | 24 | 266 |
| MPRSU-Net | 81.6 | 13.8 | 12 | 116 |
3 结论
本文提出了MPRSU-Net用于改善高分辨率遥感影像建筑物提取中边界不准确、大型建筑物提取结果存在空洞等问题。本文方法通过并行和级联RSU模块,能够从浅层和深层交叉学习到更丰富的全局特征和局部特征。在WHU和Inria数据集上的试验结果表明,本文方法相对其他方法具有更高的IoU和召回率,并在性能和效率上取得了良好的平衡,能够更好地提取边界信息,且对于不同场景的建筑物都能得到良好的分割结果,有较强的泛化能力。本文方法是基于像素级别的建筑物提取,结果会存在一些非建筑物斑块,如何将建筑物实体作为提取对象将是下一步研究方向。
| [1] |
PESARESI M, GERHARDINGER A, KAYITAKIRE F. A robust built-up area presence index by anisotropic rotation-invariant textural measure[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2008, 1(3): 180-192. DOI:10.1109/JSTARS.2008.2002869 |
| [2] |
JIN Xiaoying, DAVIS C H. Automated building extraction from high-resolution satellite imagery in urban areas using structural, contextual, and spectral information[J]. EURASIP Journal on Advances in Signal Processing, 2005, 2005(14): 2196-2206. |
| [3] |
HUANG Xin, ZHANG Liangpei. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2012, 5(1): 161-172. DOI:10.1109/JSTARS.2011.2168195 |
| [4] |
JUNG C, SCHRAMM R. Rectangle detection based on a windowed hough transform[J]. Brazilian Symposium of Computer Graphic and Image Processing, 2004, 2004(4): 113-120. |
| [5] |
OK A O, SENARAS C, YUKSEL B. Automated detection of arbitrarily shaped buildings in complex environments from monocular VHR optical satellite imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 51(3): 1701-1717. DOI:10.1109/TGRS.2012.2207123 |
| [6] |
张亚一, 费鲜芸, 王健, 等. 基于高分辨率遥感影像的建筑物提取方法综述[J]. 测绘与空间地理信息, 2020, 43(4): 76-79. ZHANG Yayi, FEI Xianyun, WANG Jian, et al. Survey of building extraction methods based on high resolution remote sensing images[J]. Geomatics & Spatial Information Technology, 2020, 43(4): 76-79. DOI:10.3969/j.issn.1672-5867.2020.04.020 |
| [7] |
季顺平, 魏世清. 遥感影像建筑物提取的卷积神经元网络与开源数据集方法[J]. 测绘学报, 2019, 48(4): 448-459. JI Shunping, WEI Shiqing. Building extraction via convolutional neural network from an open remote sensing building dataset[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(4): 448-459. DOI:10.11947/j.AGCS.2019.20180206 |
| [8] |
GONG Jianya, JI Shunping. Photogrammetry and deep learning[J]. Journal of Geodesy and Geoinformation Science, 2018, 1(1): 1-15. |
| [9] |
DAI Yuchao, ZHANG Jing, HE Mingyi, et al. Salient object detection from multi-spectral remote sensing images with deep residual network[J]. Journal of Geodesy and Geoinformation Science, 2019, 2(2): 101-110. |
| [10] |
SUN Long, WU Tao, SUN Guangcai, et al. Object detection research of SAR image using improved faster region-based convolutional neural network[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 18-28. |
| [11] |
HE Hao, WANG Shuyang, WANG Shicheng, et al. A road extraction method for remote sensing image based on encoder-decoder network[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(2): 16-25. |
| [12] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(4): 640-651. |
| [13] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]// Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer, 2015: 234-241.
|
| [14] |
ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 6230-6239.
|
| [15] |
LIN Guosheng, MILAN A, SHEN Chunhua, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 5168-5177.
|
| [16] |
崔卫红, 熊宝玉, 张丽瑶. 多尺度全卷积神经网络建筑物提取[J]. 测绘学报, 2019, 48(5): 597-608. CUI Weihong, XIONG Baoyu, ZHANG Liyao. Multi-scale fully convolutional neural network for building extraction[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(5): 597-608. DOI:10.11947/j.AGCS.2019.20180062 |
| [17] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of 2017 IEEE Conference on Neural Information Processing Systems. [S. l. ]: IEEE, 2017.
|
| [18] |
WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7794-7803.
|
| [19] |
FU Jun, LIU Jing, TIAN Haijie, et al. Dual attention network for scene segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019: 3141-3149.
|
| [20] |
TAO A, SAPRA K, CATANZARO B. Hierarchical multi- scale attention for semantic segmentation[C]//Proceedings of 2020 IEEE Conference on Computer Vision and Pattern Recognition. [S. l. ]: IEEE, 2020.
|
| [21] |
SUN Ke, XIAO Bin, LIU Dong, et al. Deep high-resolution representation learning for human pose estimation[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019: 5686-5696.
|
| [22] |
QIN Xuebin, ZHANG Zichen, HUANG Chenyang, et al. U2-Net: Going deeper with nested U-structure for salient object detection[J]. Pattern Recognition, 2020, 106: 107404. DOI:10.1016/j.patcog.2020.107404 |
| [23] |
LIU Penghua, LIU Xiaoping, LIU Mengxi, et al. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network[J]. Remote Sensing, 2019, 11(7): 830. DOI:10.3390/rs11070830 |
| [24] |
FENG Wenqing, SUI Haigang, HUA Li, et al. Building extraction from VHR remote sensing imagery by combining an improved deep convolutional encoder-decoder architecture and historical land use vector map[J]. International Journal of Remote Sensing, 2020, 41(17): 6595-6617. DOI:10.1080/01431161.2020.1742944 |
| [25] |
ZHU Qing, LIAO Cheng, HU Han, et al. MAP-net: multiple attending path neural network for building footprint extraction from remote sensed imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(7): 6169-6181. DOI:10.1109/TGRS.2020.3026051 |
| [26] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 770-778.
|
| [27] |
BISHOP C M, HINTON G. Neural networks for pattern recognition[M]. Oxford: Oxford University Press, 1995.
|
| [28] |
MAGGIORI E, TARABALKA Y, CHARPIAT G, et al. Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark[C]//Proceedings of 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Fort Worth, TX, USA: IEEE, 2017: 3226-3229.
|