



2. 广西空间信息与测绘重点实验室, 广西 桂林 541004;
3. 广西壮族自治区森林资源与生态环境监测中心, 广西 南宁 530000
2. Guangxi Key Laboratory of Spatial Information and Mapping, Guilin 541004, China;
3. Guangxi Zhuang Autonomous Region Forest Resources and Ecological Environment Monitoring Center, Nanning 530000, China
近年来,随着视频监控系统在安防、国防和军事领域中的广泛应用,监控视频中动态目标的跟踪和识别已经成为研究热点。单纯的视频目标跟踪无法完成实际地理位置和目标的动态方位、速度、运动轨迹等信息的提取,须将地理空间信息与视频融合才能有效解决这一问题[1]。传统视频动态目标检测与跟踪技术按照算法原理大致分为生成式模型、判别式模型和深度学习的方法[2-5]。生成式模型提取目标特征构建表观模型,在图像中搜索与模型最匹配的区域作为跟踪结果[6-8]。生成式模型不论采用全局特征还是局部特征,其本质是在目标表示的高维空间中检测出候选目标,对目标区域进行特征描述后找出重构误差最小的候选目标作为当前估计[9],生成式模型只关注目标信息,而忽略了背景信息。判别式模型与生成式模型不同,既考虑了目标信息,也没有忽略背景信息。判别式模型的目的是寻找一个判别函数,将跟踪问题看作分类或者回归问题,利用一个在线分类器将目标与背景分离, 从而实现对目标的跟踪[10-11]。基于深度学习的目标跟踪方法主要是利用深度特征强大的表征能力来实现跟踪。HCF(hierarchical convolutional features for visual tracking)利用VGG(visual geometry group)网络的深层特征与浅层特征,融入相关滤波器获得了很好的跟踪性能[12],但该算法并没有对尺度进行处理,在整个跟踪序列中都假定目标尺度不变,因此对尺度变化较大的跟踪目标并不稳健。目前,许多定位方法都会选择计算目标的质心来进行定位,目前常用的质心提取方法有传统质心法、平方加权质心法及高斯曲面拟合法[13-14]。传统质心法与平方加权质心法都基于特征点像素的灰度值进行相关运算, 不同点是平方加权质心法采用灰度值的平方来代替灰度值进行相关运算, 进而加大了图像中灰度值像素在质心求取中的权重。高斯曲面拟合法则是依据特征点图像灰度分布的高斯特性和各个像素点灰度值与高度之间的相关性, 并不仅仅依赖特征点像素的灰度值。文献[13]提出基于成像角度的特征点质心提取方法,针对特征点所在平面与相机平面不平行情况, 结合这3种质心提取方法, 引入重复性标准差作为特征点质心提取精度的评价标准进行试验验证。关于使用多摄像头协同跟踪的算法,国内外已经做了一些研究。文献[15]描述了一种基于多视角通道融合网络的无人车夜间三维目标检测方法,通过鸟瞰图、前视图与红外图像组成多视角通道融合互补形式,提高物体识别能力。文献[16]利用基于SIFT算法的单应性矩阵变换完成多个摄像头跟踪目标的数据融合, 从而提高目标跟踪的稳健性、准确性和实时性。
以上算法主要集中在图像本身的颜色、几何特征提取以及视觉特征跟踪等方面,多采用训练或概率等方法开展研究,忽略了监控视频中动态目标与在地理坐标系精准匹配问题,从而难以满足智能监控在复杂的地理场景中全方位时空信息感知。为解决这一问题,本文提出了一种多视角监控视频中动态目标的时空信息提取方法,将多角度获取的同一动态目标匹配于统一地理坐标系中,通过背景减法与Canny算子融合提取目标轮廓,运用质点偏移算法来测量动态目标每一时刻的地理位置,从而实现统一地理坐标系中动态目标的空间位置、轮廓特征及连续轨迹等时空信息的提取,以提升监控视频中动态目标的快速提取和实时跟踪能力。
1 视频监控图像与地理空间数据互映射模型构建监控视频信息是把真实的地理空间实体信息投影到二维图像平面上,因为成像是二维的,所以丢失了真实地理空间实体所蕴含的三维时空信息。建立视频监控图像与地理空间坐标互映射模型,可以实现三维地理空间坐标与二维图像像素坐标的互转换以及图像像素的地理时空分析。因摄像机是固定的,会长时间拍摄同一个地理场景,即监控场景的背景是不变的,变化的只是动态的前景目标,因此,把不变的背景与地理空间数据映射,找出图像上背景的每一个像素点与地理空间坐标相对应的地理坐标,在此基础上提取单帧图像动态目标的位置信息和连续视频序列的动态目标的运动(方向、速度、轨迹)信息。
若是每个相机都以各自的成像中心建立坐标系,那么每一个坐标系统的原点和坐标轴都不一样,无法将地理场景置于同一尺度下去分析,因此需要将所有的相机置于一个稳定不变的坐标系统。假设地理实体P在世界坐标系下的坐标为PW,在相机坐标系下的坐标为PC,地理实体P在两个坐标系的旋转和平移可以用两个矩阵R和t来表示[17-18]
 (1)
(1)
P点在相机坐标系和图像坐标系下的关系公式为
 (2)
(2)
式(2)就是计算机视觉中常用的坐标转换方程,其中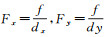
通过上面4个坐标系的转换就可以得到P点从图像坐标系转换到像素坐标系的关系公式为
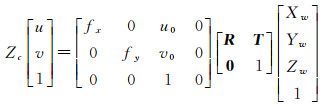 (3)
(3)
式中,fx、fy与相机的焦距和成像过程中的空间实体的缩放有关,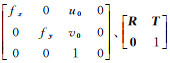
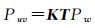 (4)
(4)
式中,Puv、Pw分别代表点在像素坐标系下的坐标及其对应点在世界坐标系下的坐标;K、T分别为相机的内参数矩阵和外参数矩阵,且T=[R t]。
随着世界坐标系的点坐标和对应点的像素坐标系坐标不断发生变化,相机深度s也会不断变化,若求得相机深度s,即可实现世界坐标系与像素坐标系的映射。将矩阵进行变换,可得到像素坐标系与世界坐标系的映射,即
 (5)
(5)
在理想状态下,相机与地理约束平面平行,则相机深度可用相机位姿平移矩阵的t3进行表示,即s=t3,但是,在实际情形中,相机会与地理约束平面产生绕X轴或Y轴的旋转,不会与地理约束平面平行,因此,相机深度计算会发生变化,即
 (6)
(6)
相机深度s会根据地理约束平面的点坐标变化而变化,可采用拟合多个相机深度值来确定相机深度s,本文采用利用相机外参矩阵来计算不同位置的深度,该方法可以提高像素坐标系到世界坐标系的映射精度。公式可以简化为
 (7)
(7)
式中,ZC为像素点对应世界坐标系Z方向的值。由于相机位置固定,且地理约束平面处于水平位置,因此,本文设置ZC的值为0,可获取像素点到地理约束平面的二维坐标。通过参考控制点获取到相机深度s后,即可实现像素坐标到地理空间坐标的互映射,求得像素坐标系下点到对应地理空间坐标系下点的坐标。
2 目标的时空信息提取 2.1 Canny算子与背景减法融合的目标轮廓提取目标轮廓识别是指剔除图像复杂背景、各种文理以及噪声的影响来对图像中目标的轮廓进行精确提取的方法和过程,是目标检测、跟踪、识别的基础[22-23]。当前较为广泛的轮廓识别方法是混合高斯模型背景减法,但该方法在提取动态目标的过程中,往往会遇到动态目标的灰度值与背景相近这种情况,导致提取的轮廓缺失[24]。例如,当监控场景的背景为白色和移动目标的边界轮廓也为白色时,移动目标的轮廓提取就会产生错误,这是因为动态目标与背景的灰度值接近或相同,在做差分运算得到的灰度绝对值没有达到提取设定的阈值造成的,因此本文设计了一种Canny边缘检测与背景减法融合模块来获取动态目标边缘轮廓。Canny算子受到噪音的干扰较小,能够容易检测到弱边缘[25],与背景减法融合可以削弱图像的相似部分,突出显示图像的变化部分,提取出来的边缘位置和图像的真正边缘的中心位置充分接近。融合算法的流程如图 1所示。

|
| 图 1 背景减法与Canny算子的融合提取算法流程 Fig. 1 Fusion algorithm of background subtraction and Canny |
(1) 对原始视频做直方图均衡化处理,把原始图像的直方图变换为均匀分布的形式,增加灰度值的动态范围,从而达到增强图像整体对比度的效果。计算图像f(x, y)的各灰度级中像素出现的概率p(i),将灰度级个数设为L,则该函数为
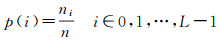 (8)
(8)
计算p的累计概率函数c(i),将c(i)缩放至0~255范围内,c为图像的累计归一化直方图
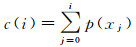 (9)
(9)
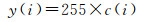 (10)
(10)
(2) 分别对图像进行预处理,先利用Canny算子检测无动态目标存在的图像,其检测出来的结果仅包含着背景图像的边缘。然后,再对有动态目标存在的图像进行边缘检测。利用高斯滤波平滑图像,消除噪声,将高斯滤波器的参数设为σ,则该函数为
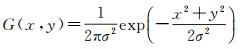 (11)
(11)
统计图像中每个像素的灰度值,并计算出每个点灰度变化的方向和梯度,灰度沿着垂直、水平方向的导数Gx和Gy,这样就可以如下计算梯度模和方向
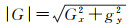 (12)
(12)
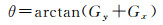 (13)
(13)
仅仅对图像进行梯度值提取边缘仍然很模糊,必须要采取非极大值抑制,消除噪声杂散响应,细化图像边缘信息;之后再进行双阈值处理,设定高低阈值将图像进行分割,检测和连接真实的边缘;剔除检测结果中孤立的弱边缘。
(3) 将边缘检测结果与背景边缘做背景差分运算。通过灰度图像序列中每一帧的图像与背景图像进行差处理,得到只含有运动目标的差分图像
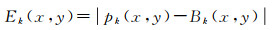 (14)
(14)
对差分图像的像素值与预先设定的阈值T进行二值化处理,1代表运动目标区域,0代表背景区域
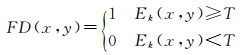 (15)
(15)
(4) 将检测的目标轮廓信息与背景减法的结果进行逻辑“与”运算从而得到最终的目标提取结果。与代数运算不同,图像的逻辑运算主要针对二值图像,既关注图像像素点的数值变化,又重视位变换的情况,以像素对像素为基础进行的两幅或多幅图像间的操作。实现步骤为:首先对原图、背景二值化,设定阈值,将灰度图像的像素分成大于阈值的像素群(置为1)和小于阈值(置为0)的像素群两部分,把二值图像转化为0、1值后循环两幅图像的像素点,再把0、1值转化为二值图像数据,为0的像素置0,为1的像素置255。当两个图像对应的像素同时为真时,结果为真。“与”运算主要用于求两幅二值图像的相交部分,对图像进行二值化的同时不仅去除了不同的部分,也保留了原图和背景中相同的部分。
2.2 多摄像头协同下目标位置信息提取过程Canny算子与背景减法融合提取的是动态目标的轮廓,而位置信息是点在坐标系上三维信息的表达,不能直接提取出来,需要对视频监控图像的动态目标进行地理空间数据的映射,即需要进行图像像素点与其对应到地理空间的点所在的两个参考坐标系之间的转换。当前,视频监控系统中每一个摄像机都可以实现对动态目标的跟踪。但是,同一场景内的各个摄像机的监控视频的动态目标提取数据仍然是独立的,目标的图像数据、空间数据并未融合,各个摄像机也无法协同工作。因为各个摄像头放置的位置、姿态角度和投影过程中的误差不同,拍摄图像的空间分辨率也不一致,从而导致监控图像与地理空间数据的映射的精度、目标定位的精度存在偏差,那么相同目标在不同摄像头下的定位和连续轨迹就无法完全重合。因此,本文在基于地理约束下的监控视频与地理空间数据的交点映射算法的基础上,提出了一种多摄像机协同下的动态目标时空特征匹配与识别模式。该模式在传统图像处理的基础上,融合动态目标的时空信息,运用时空特征匹配与空间分析方法,来实现多摄像头协作下对单目标、多目标的识别与匹配。该方法具体可分多摄像头下提取判别目标轮廓、目标位置信息提取、多摄像头下多目标轨迹融合等3个部分,具体流程如图 2所示。

|
| 图 2 基于多摄像头下的多目标匹配与识别模式 Fig. 2 Multi-target matching and recognition pattern based on multi-camera |
2.2.1 多摄像头下提取判别目标轮廓
首先将多摄像头的映射关系转换到同一坐标系下,并匹配相同的坐标,建立公共区域。多摄像头协同下对目标进行识别与匹配的前提条件是:该目标置于多个约束平面的重叠区域。只有把多个摄像头的映射关系置于同一坐标系下,寻找其对应的公共坐标,判断公共区域的范围才能够实现多摄像头下的协同工作;在地理坐标系下建立公共区域以后,还要通过互映射模型计算各个摄像机拍摄的图像中的重叠区域坐标,构建各个图像场景内的公共区域;最后根据基于Canny算子与背景减法融合的动态目标提取公共区域内目标的轮廓,并判断轮廓数量。当目标检测算法监测到动态目标经过图像上的公共区域时,需要对目标的轮廓个数进行判断:若公共区域内的目标轮廓数量为1,那么多摄像头拍摄的一定为同一个目标,无须进行多摄像机的目标融合与匹配就可以确定目标,对于不重合的轨迹可以融合成一个公共轨迹;若公共区域内的目标轮廓数量大于1,则进入到多目标的判断步骤。
2.2.2 目标位置信息提取为了便于研究动态目标的位置变化信息,通常将动态目标的轮廓抽象为点,用目标的质心来表达。质心被认为一个几何物体质量集中的假想点,对于质量均匀分布的物体,质心一般在物体的几何中心。本文中摄像机的位置与其映射模型是基于约束平面下的2D映射,且摄像头与地面的角度是45°,若动态目标出现在约束平面上,它的质心位置必定不会是目标在约束平面上的真实位置。如果直接运用图像上目标的质心当作定位点,那么会造成较大的偏差。为了解决上述问题,本文设定了一种质心偏移法来确定目标的在图像中的定位点,从而提高其定位精度。质心偏移计算过程如下。
(1) 设定提取的动态目标所在区域内密度均匀,其图像的分辨率为m×n,动态目标在整幅图像中的像素坐标为(xi, yi), i、j表示该目标的在区域内的像素点的总个数,通过计算质心的计算公式计算质心,其计算公式为
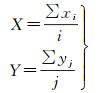 (16)
(16)
式中,0 < i < m;0 < j < n。
(2) 根据提取到的前景目标图像中的动态目标轮廓,计算它的最小外接矩形,获取矩形中心点坐标(x,y)及4个角点的x坐标矩阵rectx及y坐标矩阵recty。其中,rectx=[x1 x2 x3 x4],recty=[y1 y2 y3 y4]。
(3) 质心垂直向下位移,一直位移到目标的轮廓边缘,设定该点为质心偏移点。设置质心向下偏移的比率rate,即质心距质心偏移点的距离与质心距离最小外接矩形底边中点的距离的比例。本文摄像头与地面呈45°角,拍摄出来的照片目标质心偏移比例为0.9∶1。
(4) 质心偏移点(xp, yp)计算
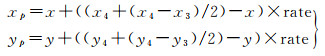 (17)
(17)
(5) 利用视频监控图像与地理空间数据互映射式(7)求得质心偏移点在地理空间坐标中的位置(XP, YP)。
将动态目标的轨迹转换空间直角坐标系上,不仅可以还原目标在该场景的实际位置,计算目标的运动方向和速度等其他时空信息,为多角度下目标的识别与检测提供数据支撑。目标轨迹是由一系列连续的位置信息组成,假设在t时刻目标的地理位置为P(xt, yt),在下一时刻t+1(连续视频由很多相邻帧的图像组成,这里表示下一帧图像)的地理位置为P(xt+1, yt+1),那么在t时刻目标的行动方位可以定义为
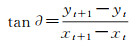 (18)
(18)
在摄像机侧视的情况下,质心和指定偏移点在约束平面上的位置是不同的,质心所在的位置并不是动态目标的实际位置,经过计算,质心点偏移点和质心映射后的坐标两者相比,质心偏移点的计算结果比直接用质心计算得出的结果与实际位置更加接近,更适用于视频监控中动态目标的定位。因此本文采用质心偏移点的计算结果作为动态目标的质心。动态目标时空信息方法流程如图 3所示。

|
| 图 3 目标时空信息提取方法流程 Fig. 3 Target space-time information extraction |
基于连续视频序列的动态目标时空信息提取模式根据设定的时间间隔把视频序列分为若干幅连续的监控图像,再运用质心找到图像上目标的定位坐标P将图像坐标转换为空间直角坐标系上,进行定位点纠正,通过质心偏移的比率计算质心偏移点,利用视频监控图像与地理空间数据互映射方法求得质心偏移点在地理空间坐标中的位置(XP,XP),从而还原目标在该场景的实际位置。
2.2.3 多摄像头下多目标轨迹融合多摄像头协同下的目标匹配与识别分为两种场景:单一目标的场景和多个目标同时存在的场景。其中,多个目标同时存在的场景由又可以分为两种情况:多个目标的混乱轨迹多目标并行的相似轨迹。针对不同的场景,本文设计了不同的目标识别与跟踪方法。若是多人无序的场景,各个目标在同一时刻的空间位置、运动角度差别很大,可以通过动态目标的时空特征匹配来进行判别;若是多人并行的场景,多个目标的位置、行动角度和运动速度都接近,无法用时空特征进行判断,需要建立场景内目标的顺序空间关系,通过空间分析方法进行判别。具体步骤如下。
(1) 假设在一段时间中,有i个摄像头Pi在同一个公共区域内拍摄到n个目标On,那么任意一个目标可以表示为PiOn。选定需要进行判别的目标P1O1,计算在初始时刻t目标的位置D1和行动角度A1。
(2) 计算摄像头P2所有目标的位置和行动角度集合{P2Oi},设定位置阈值∂,剔除集合{P2Oi}不在∂内的目标,然后更新{P2Oi}。
(3) 计算下一时刻t+Δt目标P1O1和集合{P2Oi}内目标位置和行动角度,然后根据∂继续更新集合{P2Oi},重复上述步骤,直到目标离开公共区域。
(4) 查询集合{P2Oi},若该集合只剩下一个目标,就完成了目标P1O1在摄像头P2下的匹配;若在该集合内的目标大于1,则表示该目标是与其他目标并行,在同一时刻内他们在空间内的位置、行动方向都相似,而由于摄像机的空间分辨率存在着误差,所以很难通过位置和行动方向进行判别。面对多人并行的场景,本文运用顺序空间位置关系去判断:计算摄像头P1内多人并行场景在公共区域内每一个时刻的位置P1Di,按照顺序连接目标的位置构建时空轨迹图,建立每一个目标的顺序空间关系;计算其他摄像头在公共区域内相应时刻位置PiDi,按照顺序连接各个目标的时空轨迹图,并根据建立的顺序空间关系判断相应目标,完成多人并行的场景在多摄像头下协同匹配与接力。
3 试验验证 3.1 监控图像与地理空间的坐标映射试验本文试验使用的图像传感器为锐刻智能安防摄像头,具体参数见表 1,数据处理使用是Matlab软件。
| 参数 | 参数值 |
| 摄像头型号 | 锐刻智能安防摄像头 |
| 云台角度 | 水平355°, 垂直140° |
| 日夜转换模式 | ICR红外滤片 |
| 视频压缩标准 | H.264 |
| 图片像素 | 1080×1920 |
| 固定焦距 | 3.5 mm |
| 镜头 | 3.5 mm@f2.3, 对角视角:140° |
| 镜头接口类型 | M12 |
| 降噪 | 3D数字降噪 |
| 视频压缩码率 | Main rofile |
| 径向畸变(3阶) | [-0.315 6 0.210 2 -0.064 6] |
| 内参(标定) |  |
图 4为摄像头拍摄的场景,选取地面为地理约束平面,在地理约束平面上选取5个控制点为3D参考控制点,为提高选取精度,本文试验选取各地板之间缝隙连接成的交点作为其参考控制点。设置点1所在位置为地理空间坐标系原点,即5个参考控制点的地理空间坐标和对应的图像像素坐标见表 2。该地理场景中,地理约束平面内的每块地板均为60 cm×60 cm的正方形地板,该约束平面内选取的5个参考控制点的地理空间坐标分别为(0, 0)、(0, 180)、(180, 0)、(240, 240)、(-60, 120),其对应的图像像素坐标分别为(306, 686)、(800, 546)、(247, 432)、(686, 271)、(715, 698)。经过相机位姿估计,可以获得相机的外参数矩阵T为


|
| 图 4 参考控制点及世界坐标系确定 Fig. 4 Determination of reference control points and world coordinate system |
| 图像像素坐标/像素 | 真实地理坐标/cm | 映射地理坐标/cm | 误差/cm | |||||||
| xo | yo | x1 | y1 | X' | Y' | Δx | Δy | |||
| 529 | 756 | -60 | 60 | -56.724 0 | 54.568 8 | -3.276 | 5.431 2 | |||
| 433 | 543 | 60 | 60 | 68.147 5 | 58.076 6 | -8.147 5 | 1.923 4 | |||
| 991 | 758 | -120 | 180 | -127.716 2 | 184.591 1 | 7.716 2 | -4.591 1 | |||
| 943 | 506 | 0 | 240 | 1.617 2 | 244.040 6 | -1.617 2 | -4.040 6 | |||
| 1387 | 588 | -120 | 360 | -124.048 4 | 371.126 9 | 4.048 4 | -11.126 9 | |||
| 370 | 400 | 180 | 60 | 181.976 6 | 61.824 1 | -1.976 6 | -1.824 1 | |||
| 793 | 252 | 240 | 300 | 239.764 6 | 293.216 9 | 0.235 4 | 6.783 1 | |||
| 1505 | 676 | -180 | 360 | -182.053 5 | 372.344 7 | 2.053 5 | -12.344 7 | |||
| 1037 | 593 | -60 | 240 | -63.183 7 | 246.645 4 | 3.183 7 | -6.645 4 | |||
| 838 | 200 | 300 | 360 | 291.130 8 | 347.239 2 | 8.869 2 | 12.760 8 | |||
图像坐标与地理空间坐标互映射模型参数确定后,选取地理约束平面内的10个不同位置的空间平面测试点对进行映射模型的精度评定,如图 5所示,与真实地理空间坐标相比较,确定像素坐标映射到地理空间坐标系的误差,其计算结果见表 2。

|
| 图 5 空间点位选取 Fig. 5 A schematic diagram of spatial point location selection |
通过图 4和表 2的10个测试点的像素坐标所对应的真实地理坐标与映射的地理坐标计算结果分析可知,上半部分区域点位位置离摄像头较近,空间分辨率变化不大,几何映射结果在X和Y方向的误差都在10 cm以内,得到的结果与真实地理坐标接近。而点位5、8、10距离摄像机较远,与其他较近的点位相比误差较大,在20 cm左右。误差最大点为距离摄像头最远处的测试点10,映射的地理坐标与其对应的真实地理x坐标的为最大误差8.869 2 cm,y坐标误差为12.760 8 cm,也是测试点中的最大误差,可以通过连续跟踪观测解决较远目标点的误差问题。
3.2 动态目标轮廓提取算法改进前后对比为验证融合算法的检测效果以及有效性,试验选取原始背景减法与改进的融合检测算法进行对比。本文利用固定的监控摄像头对空间区域行走视频文件进行模拟试验,针对该地理场景的大小和试验需求,定义的时间采样间隔为0.5 s。试验为行人在地理约束空间内行走,拍摄时长17 s,摄像头拍摄帧率为11.88帧/s,视频帧图像分辨率为1920×1080,每隔10帧对视频进行采样提取,采样间隔为1 s。本文试验的约束平面由相同的地板组成,地板的尺寸为60 cm。以拍摄场景的左上角地板的角点为顶点坐标,在Y方向上共计9块地板,X方向上共计29块地板,以此构建的坐标网格。采用图像坐标与地理空间坐标互映射模型根据试验中坐标系的位置建立视频监控图像与地理空间之间的互映射关联。
本文研究在Matlab平台上实现了背景减法与Canny算子和背景减法融合算法并进行了对比试验,如图 6所示,该拍摄区域主要由地面、墙壁栏杆和行人组成,场景内的约束平面是占图像80%左右的地面,阈值设置为80。目标轮廓信息提取结果如图所示:图 6(c)是该图像经过背景减法后提取的目标轮廓,对比原始图像,可以发现目标轮廓并不完整,其所携带的书被过滤掉;图 6(d)是背景减法与Canny边缘检测后合成的图像,是融合算法最终的结果图像。对比图 6(c)和图 6(d)可以发现图 6(d)的轮廓更为完整和清晰,这表明在该场景下本文提出的融合算法在提取动态目标的效果更好。

|
| 图 6 本文算法与传统背景减法比较 Fig. 6 Comparison between the proposed algorithm and traditional background subtraction |
3.3 动态目标跟踪轨迹对比试验
为验证质心偏移法算法的有效性,本文分别使用原始质心算法和改进的质心偏移法算法进行跟踪测试,所求质心点为最小外接矩形中心点,质心偏移点是通过将质心点进行偏移,移动到行人目标的双脚处,质心距质心偏移点的距离与质心距离最小外接矩形底边中点的距离的比例为0.9∶1,如图 7所示。选取第13帧和第133帧图像为例,首先在视频第1帧手动确定移动目标区域,然后对该区域进行跟踪,其中红色点为质心点,绿色点为质心偏移点,左上角为图像所在帧数。

|
| 图 7 质心及质心偏移点提取 Fig. 7 Extraction of centroid and centroid offset points |
试验中共选取了均匀分布的11个点作为图像空间与地理空间的对应点,并计算其误差,见表 3,其中质心跟踪算法与真实地理坐标最大误差为36.589 6 cm,最小误差为1.186 6 cm;质心偏移算法于真实地理坐标最大误差为-25.406 9 cm,最小误差为0.696 5 cm。质心偏移算法的映射结果的误差都在20 cm以内,而质心跟踪算法误差较大,在30 cm左右。由此看来质心跟踪算法相较于质心偏移算法与实际运动轨迹相比波动较大;质心偏移点的计算结果与实际位置更加接近。
| 序号 | 像素坐标/像素 | 实际坐标/cm | 质心跟踪算法/cm | 质心偏移算法/cm |
| 1 | (506.063 5, 154.416 6) | (-180,360) | (-161.897 2,323.410 4) | (-184.189,375.534 3) |
| 2 | (403.688 6,86.628 4) | (-60,340) | (-58.813 4,308.271 6) | (-42.814 2,357.571 1) |
| 3 | (420.553 5,118.975 7) | (60,360) | (53.692,325.044 1) | (53.127 6,385.406 9) |
| 4 | (395.329 1,101.032 4) | (180,330) | (161.565 7,296.217) | (172.454 4,337.157 3) |
| 5 | (384.067 3,107.446 2) | (300,360) | (270.238 1,328.333 2) | (299.303 5,373.993 6) |
| 6 | (435.916 0,126.944 8) | (360,240) | (323.287,214.877 7) | (357.760 7,247.547 8) |
| 7 | (293.860 0,146.605 4) | (300,60) | (271.492 9,54.557 4) | (288.444 8,64.304 5) |
| 8 | (271.724 5,162.949 9) | (120,100) | (101.820 6,105.440 4) | (112.982 7,108.980 4) |
| 9 | (291.897 9,145.191 9) | (0,120) | (3.894 1,107.438 8) | (-9.953 1,123.410 5) |
| 10 | (333.334 5,121.377 6) | (-60,200) | (-73.466 2,178.680 9) | (-45.416 1,201.762 5) |
| 11 | (492.264 2,187.844 0) | (-180,300) | (-162.195 7,269.426 7) | (-183.106 1,313.842 2) |
把单帧视频提取的目标位置信息融合成连续的轨迹,如图 8所示,绿色虚线为实际运动轨迹,红色实线为所提出质心偏移法算法的跟踪结果,蓝色虚线为质心算法跟踪结果。

|
| 图 8 动态目标运动轨迹对比 Fig. 8 Dynamic target trajectory comparison diagram geographic coordinates |
从局部区域分析,右下角区域红色实线和蓝色虚线与绿色虚线的距离相较于左上角区域更为接近,也就是说,两种算法在右下角区域误差相对较小,这是因为右下角区域离摄像头比较近,约束平面上的交点比较清晰,所以交点映射的误差较低;而离摄像机较远的位置,因为图像较为模糊,无法提取约束平面上的线状信息,所以两种方法误差接近,误差也较大。从整体来看,红色实线与绿色虚线的距离始终比蓝色虚线与绿色虚线的距离更小,说明质心偏移算法与实际运动轨迹重合度更高,算法更加精准。这是因为移动目标刚开始移动的时候,遭到障碍物遮挡,质心算法受到干扰导致了跟踪漂移;期间又因为移动目标进行转弯移动,质心算法和质心算法都失去了目标,但是质心偏移法算法能够迅速通过重检测找回目标,继续跟踪。根据以上分析,可以得出质心算法定位容易受到干扰,虽然能够跟踪到目标,但跟踪会出现稍许的偏差,而质心偏移法算法能够有效地应对遮挡、形变等问题,与实际运动轨迹重合度更高,误差更小。
3.4 多摄像头下目标的匹配与识别试验本文试验选择两组摄像头进行拍摄,位置地理坐标系下的坐标为(60, 480)和(240, 0),两组摄像头拍摄2栋教学楼的休息区域,将监控视频序列分解成监控图像,采样的时间间隔为1 s。
针对单目标在公共区域的情况,如图 9(a)、(d)所示,两个摄像机从不同角度拍摄同一区域。动态目标在该区域内停留的时间为10 s,时间间隔定为1 s。图 9(b)、(e)是两个摄像机拍摄的多目标混乱无序的场景,该区域内共有两个目标,摄像机1拍摄左侧为P1O1,另外一个为P1O2,同理可得摄像机2的两个目标为P2O1和P2O2。多人混乱无序的场景下可以通过位置和行动角度去判断目标,他们在该区域停留的时间为7 s,采样间隔为1 s。图 9(c)、(f)是拍摄的是多人并行场景,该区域内共有两个目标,摄像机1拍摄左侧目标为P1O1,另一个目标为P1O2。两个目标在场景内停留的时间为10 s,设定采样间隔为1 s。

|
| 图 9 双摄像头协同跟踪试验 Fig. 9 Dual-camera collaborative tracking experiment |
针对以上3种目标在移动情况,本文通过多摄像头协同下目标检测与识别方法实现对目标的连续跟踪。图 10(a)、(d)是图 9(a)、(d)多摄像头协同下单目标轨迹融合后的图像。表 4是图 9(b)、(e)多目标混乱无序情况下同一时刻在两个摄像头位置和行动角度,行动轨迹图和匹配成功后的轨迹融合如图 10(b)、(e)所示。图 10(c)、(f)是图 9(c)、(f)多目标并行行动轨迹和目标轨迹融合图,通过计算不同摄像头下的两个目标在对应时刻的空间位置和行动方向见表 5。

|
| 图 10 目标行动轨迹和目标轨迹融合 Fig. 10 Target trajectory and target trajectory fusion diagram |
| 帧数 | 位置坐标 | 行动角度 | |||||||
| P1O1 | P1O2 | P2O1 | P2O2 | P1O1 | P1O2 | P2O1 | P2O2 | ||
| 1 | (649.47, 257.43) | (673.55, 340.57) | (659.74, 262.88) | (632.57, 330.60) | 114.93° | -70.92° | 163.30° | 53.31° | |
| 2 | (664.40, 250.49) | (670.63, 341.58) | (666.65, 239.85) | (643.12, 338.46) | -136.43° | 22.51° | -116.10° | 6.10° | |
| 3 | (609.12, 192.38) | (673.83, 349.30) | (594.93, 204.71) | (644.19, 348.48) | 109.91° | -63.78° | -118.57° | -59.97° | |
| 4 | (543.23, 168.52) | (561.87, 404.42) | (498.08, 151.97) | (522.96, 418.56) | -111.34° | -79.23° | -114.56° | -84.53° | |
| 5 | (440.85, 128.53) | (454.81, 424.79) | (448.72, 129.41) | (443.44, 426.17) | -97.43° | -90.94° | -101.43° | -87.62° | |
| 6 | (285.40, 108.28) | (318.72, 422.55) | (238.68, 96.03) | (287.84, 432.65) | -86.12° | -96.09° | -88.58° | -94.76° | |
| 7 | (156.29, 117.04) | (170.23, 406.71) | (118.63, 100.12) | (140.95, 420.41) | -86.12° | -96.09° | -88.58° | -94.76° | |
| 帧数 | 位置坐标 | 行动角度 | |||||||
| P1O1 | P1O2 | P2O1 | P2O2 | P1O1 | P1O2 | P2O1 | P2O2 | ||
| 1 | (343.37, 421.52) | (372.03, 466.16) | (328.50, 429.16) | (339.58, 487.20) | 98.68° | 86.90° | 94.79° | 90.57° | |
| 2 | (461.95, 403.41) | (478.52, 471.92) | (453.82, 418.65) | (455.12, 486.06) | 89.27° | 96.11° | 101.72° | 102.13° | |
| 3 | (541.57, 404.42) | (577.51, 461.32) | (575.05, 393.49) | (580.59, 459.09) | 131.68° | 119.76° | 141.35° | 133.85° | |
| 4 | (623.68, 331.31) | (707.87, 386.76) | (635.20, 318.34) | (688.25, 355.68) | 146.22° | 153.26° | -178.58° | 172.35° | |
| 5 | (663.63, 271.59) | (758.51, 286.25) | (632.79, 221.32) | (708.03, 208.32) | -133.30° | -152.00° | -134.64° | -148.18° | |
| 6 | (544.91, 159.71) | (664.34, 109.14) | (578.35, 167.56) | (654.63, 122.27) | -91.94° | -102.18° | -92.54° | -108.19° | |
| 7 | (445.78, 156.35) | (471.04, 67.41) | (476.50, 163.04) | (520.84, 78.31) | -93.51° | -87.82° | -93.45° | -89.53° | |
| 8 | (346.51, 150.27) | (346.84, 72.14) | (344.62, 155.01) | (367.05, 79.57) | -87.00° | -86.92° | -83.34° | -87.36° | |
| 9 | (217.58, 157.02) | (215.78, 79.20) | (218.93, 169.68) | (194.09, 87.54) | -90.19° | -79.01° | -86.12° | -76.22° | |
| 10 | (82.85, 156.58) | (76.39, 106.29) | (70.86, 179.72) | (59.11, 120.64) | -90.19° | -79.01° | -86.12° | -76.22° | |
图 10(b)、(e)中,在多目标混乱无序的情况下,在1—3帧的视频中,摄像头的两个目标的位置接近,但是从第4帧开始P1O1的与P2O2的距离逐渐增加,到最后一帧图像中两个目标的在Y方向的位置距离相差3 m。P1O1与P2O1的空间位置相近,并且行动角度也相近,因此可以判断P1O1与P2O1匹配,P1O2与P2O2相匹配。通过分析表 5可知,虽然P1O1与P2O1的空间位置与行动角度更加进阶,但是与P2O2比较也在阈值范围内,所以无法对P1O1进行匹配。根据多摄像头协同下多目标的识别与匹配方法,需要通过顺序空间关系来判别。图 10(c)、(f)是两个目标在地理空间内的行动轨迹,蓝色表示第1个摄像头,红色代表第2个摄像头。通过观察,P1O1的行动轨迹靠内侧,第2个摄像头轨迹靠内侧的目标为P2O1,它们的顺序空间关系相同,P1O1与P2O1相匹配。
4 结论监控视频中动态目标的时空信息提取是活动场景中动态目标智能检测与准确地定位跟踪的基础,本文建立一种监控图像与地理空间坐标互映射模型,提出Canny算子与背景减法的融合算法,实现视频监控图像信息与地理时空信息的相互融合以及动态目标轮廓的提取,针对单目标、多目标在公共区域内的不同场景,综合动态目标的空间位置、运动方向和速度,并融合地理信息空间分析算法,设计了一种多角度下目标识别与检测模式。加强监控视频动态前景目标在真实地理空间中的表达,解决传统目标跟踪仅仅处于图像空间中,无法实现真实地理空间中可量测、可定位的问题,提高了地理场景的时空理解力和分析力,为视频监控的行业应用提供了新的思路。结合试验分析可以得出以下结论。
(1) 视频监控图像与地理空间坐标互映射模型计算得出的动态目标运动轨迹,与实际运动轨迹相比误差较小,模型降低了由于图像的空间分辨率不同而导致几何映射出现的较大误差,提高了映射模型算法的几何映射精度,满足了对动态目标的实时准确定位要求。
(2) Canny算子与背景减法的融合,能够很好地消除前景目标中误检的窗户处区域及墙体、出现在地理约束屏幕上的倒影,获得相对准确的前景模型。但是由于外部环境光照射产生的动态目标阴影被误检为动态目标的问题仍然存在。
(3) 基于时空特征匹配的多摄像头协同下单目标、多目标的识别与匹配模式,主要通过公共区域内目标的空间位置、行动角度和空间顺序关系3个方面进行识别与匹配。可以实现多摄像头协同下的动态目标识别与匹配,完成多摄像头对目标的连续跟踪。
| [1] |
张旭, 郝向阳, 李建胜, 等. 监控视频中动态目标与地理空间信息的融合与可视化方法[J]. 测绘学报, 2019, 48(11): 1415-1423. ZHANG Xu, HAO Xiangyang, LI Jiansheng, et al. Fusion and visualization method of dynamic targets in surveillance video with geospatial information[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(11): 1415-1423. DOI:10.11947/j.AGCS.2019.20180572 |
| [2] |
管皓, 薛向阳, 安志勇. 深度学习在视频目标跟踪中的应用进展与展望[J]. 自动化学报, 2016, 42(6): 834-847. GUAN Hao, XUE Xiangyang, AN Zhiyong. Advances on application of deep learning for video object tracking[J]. Acta Automatica Sinica, 2016, 42(6): 834-847. |
| [3] |
李志欣, 施智平, 张灿龙, 等. 混合生成式和判别式模型的图像自动标注[J]. 中国图象图形学报, 2015, 20(5): 687-699. LI Zhixin, SHI Zhiping, ZHANG Canlong, et al. Hybrid generative/discriminative model for automatic image annotation[J]. Journal of Image and Graphics, 2015, 20(5): 687-699. |
| [4] |
朱文青, 刘艳, 卞乐, 等. 基于生成式模型的目标跟踪方法综述[J]. 微处理机, 2017, 38(1): 41-47. ZHU Wenqing, LIU Yan, BIAN Le, et al. Survey on object tracking method base on generative model[J]. Microprocessors, 2017, 38(1): 41-47. DOI:10.3969/j.issn.1002-2279.2017.01.011 |
| [5] |
陈旭, 孟朝晖. 基于深度学习的目标视频跟踪算法综述[J]. 计算机系统应用, 2019, 28(1): 1-9. CHEN Xu, MENG Zhaohui. Survey on video object tracking algorithms based on deep learning[J]. Computer Systems & Applications, 2019, 28(1): 1-9. |
| [6] |
HORN B K P, SCHUNCK B G. Determining optical flow[J]. Artificial Intelligence, 1981, 17(1-3): 185-203. DOI:10.1016/0004-3702(81)90024-2 |
| [7] |
MEI Xue, LING Haibin. Robust visual tracking and vehicle classification via sparse representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(11): 2259-2272. DOI:10.1109/TPAMI.2011.66 |
| [8] |
CRUZ-MOTA J, BOGDANOVA I, PAQUIER B, et al. Scale invariant feature transform on the sphere: theory and applications[J]. International Journal of Computer Vision, 2012, 98(2): 217-241. DOI:10.1007/s11263-011-0505-4 |
| [9] |
李玺, 查宇飞, 张天柱, 等. 深度学习的目标跟踪算法综述[J]. 中国图象图形学报, 2019, 24(12): 2057-2080. LI Xi, ZHA Yufei, ZHANG Tianzhu, et al. Survey of visual object tracking algorithms based on deep learning[J]. Journal of Image and Graphics, 2019, 24(12): 2057-2080. DOI:10.11834/jig.190372 |
| [10] |
欧阳谷, 钟必能, 白冰, 等. 深度神经网络在目标跟踪算法中的应用与最新研究进展[J]. 小型微型计算机系统, 2018, 39(2): 315-323. OUYANG Gu, ZHONG Bineng, BAI Bing, et al. Recent research advances and application of object tacking algorithm based on deep neural network[J]. Journal of Chinese Computer Systems, 2018, 39(2): 315-323. DOI:10.3969/j.issn.1000-1220.2018.02.024 |
| [11] |
HARE S, GOLODETZ S, SAFFARI A, et al. Struck: structured output tracking with kernels[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2096-2109. DOI:10.1109/TPAMI.2015.2509974 |
| [12] |
MA Chao, HUANG Jiabin, YANG Xiaokang, et al. Hierarchical convolutional features for visual tracking[C]//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago. Chile: IEEE, 2015: 3074-3082.
|
| [13] |
王志军, 马凯. 基于成像角度的特征点质心提取精度研究[J]. 激光杂志, 2018, 39(4): 90-93. WANG Zhijun, MA Kai. Study on the precision of feature point centroid extraction based on imaging angle[J]. Laser Journal, 2018, 39(4): 90-93. |
| [14] |
王敏, 赵金宇, 陈涛. 基于各向异性高斯曲面拟合的星点质心提取算法[J]. 光学学报, 2017, 37(5): 226-235. WANG Min, ZHAO Jinyu, CHEN Tao. Center extraction method for star-map targets based on anisotropic Gaussian surface fitting[J]. Acta Optica Sinica, 2017, 37(5): 226-235. |
| [15] |
王宇岚, 孙韶媛, 刘致驿, 等. 基于多视角融合的夜间无人车三维目标检测[J]. 应用光学, 2020, 41(2): 296-301. WANG Yulan, SUN Shaoyuan, LIU Zhiyi, et al. Nighttime three-dimensional target detection of driverless vehicles based on multi-view channel fusion network[J]. Journal of Applied Optics, 2020, 41(2): 296-301. |
| [16] |
胡玉兰, 石心蕊. 基于多摄像头协同的目标融合[J]. 电子世界, 2019(13): 58-59. HU Yulan, SHI Xinrui. Object fusion based on multi-camera collaboration[J]. Electronics World, 2019(13): 58-59. |
| [17] |
张兴国. 地理场景协同的多摄像机目标跟踪研究[D]. 南京: 南京师范大学, 2014. ZHANG Xingguo. Object tracking methods based on geographic scene and multi-camera[D]. Nanjing: Nanjing Normal University, 2014. |
| [18] |
刘垒. 基于地理约束场景的动态目标检测及行为识别方法研究[D]. 桂林: 桂林理工大学, 2020. LIU Lei. Research of dynamic target detection and behavior recognition method based on geographic constraint scene[D]. Guilin: Guilin University of Technology, 2020. |
| [19] |
ZHANG Z. A flexible new technique for camera calibration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1330-1334. DOI:10.1109/34.888718 |
| [20] |
李莉. OpenCV耦合改进张正友算法的相机标定算法[J]. 轻工机械, 2015, 33(4): 60-63, 68. LI Li. Camera calibration algorithm based on OpenCV and improved Zhang zhengyou algorithm[J]. Light Industry Machinery, 2015, 33(4): 60-63, 68. |
| [21] |
刘艳, 李腾飞. 对张正友相机标定法的改进研究[J]. 光学技术, 2014, 40(6): 565-570. LIU Yan, LI Tengfei. Reaserch of the improvement of Zhang zhengyou camera calibration method[J]. Optical Technique, 2014, 40(6): 565-570. |
| [22] |
李云功. 基于轮廓特征描述的目标识别算法研究[D]. 沈阳: 沈阳理工大学, 2019. LI Yungong. Research on object recognition algorithm based on contour feature description[D]. Shenyang: Shenyang Ligong University, 2019. |
| [23] |
WANG Shengchun, WANG Hao, ZHOU Yunlai, et al. Automatic laser profile recognition and fast tracking for structured light measurement using deep learning and template matching[J]. Measurement, 2021, 169: 108362. DOI:10.1016/j.measurement.2020.108362 |
| [24] |
华媛蕾, 刘万军. 改进混合高斯模型的运动目标检测算法[J]. 计算机应用, 2014, 34(2): 580-584. HUA Yuanlei, LIU Wanjun. Moving object detection algorithm of improved Gaussian mixture model[J]. Journal of Computer Applications, 2014, 34(2): 580-584. |
| [25] |
徐亮, 魏锐. 基于Canny算子的图像边缘检测优化算法[J]. 科技通报, 2013, 29(7): 127-131, 150. XU Liang, WEI Rui. An optimal algorithm of image edge detection based on canny[J]. Bulletin of Science and Technology, 2013, 29(7): 127-131, 150. |