



2. 中国地质大学(武汉)地质探测与评估教育部重点实验室,湖北 武汉 430074;
3. 自然资源部城市国土资源监测与仿真重点实验室,广东 深圳 518034;
4. 西安测绘研究所,陕西 西安 710054;
5. 地理信息工程国家重点实验室,陕西 西安 710054;
6. 中国地质大学(武汉)计算机学院,湖北 武汉 430078;
7. 中南电力设计院有限公司,湖北 武汉 430071
2. Key Laboratory of Geological Survey and Evaluation of Ministry of Education, China University of Geosciences, Wuhan 430074, China;
3. Key Laboratory of Urban Land Resource Monitoring and Simulation, Ministry of Natural Resource, Shenzhen 518034, China;
4. Xi'an Research Institute of Surveying and Mapping, Xi'an 710054, China;
5. State Key Laboratory of Geo-Information Engineering, Xi'an 710054, China;
6. School of Computer Science, China University of Geoscience, Wuhan 430078, China;
7. Central Southern China Electric Power Design Institute Co., Ltd., Wuhan 430071, ChinaAbstract
遥感影像具备监测范围大、信息传输快、全天候工作的特点,使政府在智能化监测与评估的工作中节约了大量的人力、物力及财力的运作成本,为国土的规划、资源调配及可持续发展提供了更为高效、可靠的手段。当前,在机器视觉技术的协助下通过遥感影像提取地面目标信息是重要的研究课题之一[1-3]。特别是在城建区域内,基于机器视觉的建筑物检测方法在城市规划、灾情评估、国土资源、城市地理信息系统平台建设、地图更新、违章建筑物检测、智慧城市建设、军事侦察等方面均获得了广泛的应用[4-9]。
传统的建筑物目标检测算法侧重于描述建筑物的底层视觉特征,例如建筑物颜色、形状、纹理、阴影等单一特征检测建筑物[10-13]或是几种特征的简单组合[14-15],并且加入了激光雷达、DEM等其他数据源的建筑物检测算法[16-17]。然而,这类方法往往受到与建筑物具有相似特征的地物干扰,使得检测结果不够准确。此外,特征提取很多情况下需要人工干预来完成,这很难完整地表达建筑物目标特征,在面对海量数据时缺乏泛化能力且费时费力,同时也不易通过图像特征训练出一个较好的分类器。
近年来,基于深度学习的模型往往能够凭借强大的深度神经网络对大量数据进行学习,不仅能够提取目标的浅层信息,还能够挖掘出目标潜藏的深层语义信息来解决复杂的遥感图像检测问题;在特征提取方面也有着巨大的优势,泛化能力强、稳健性好,解决了传统建筑物目标检测的不足[18-20]。目前,应用于建筑物检测的深度学习模型主要有两类:一类是基于候选区域的双阶段方法。首先通过区域推荐网络(region proposal network,RPN)生成候选区域,然后利用卷积神经网络进行分类和边框修正,该方法检测精度较高,但检测速度较慢,如Fast R-CNN[21]、Faster R-CNN[22]、Mask R-CNN[23]等。另一类是基于回归的单阶段方法,将目标检测框的定位问题转化为回归问题来处理,不用产生候选框,直接使用单一的卷积神经网络对目标类别和位置进行预测。该类算法检测速度快[24],例如YOLO[25]和SSD[26]等。由于在工程项目中需要考虑时间成本的原因,单阶段方法要比双阶段方法更为常用。
具体地,文献[27—28]通过优化特征图分辨率、调整先验框维度以得到一种适合遥感图像中小型建筑物检测的网络模型。文献[29]以提升建筑物检测速度为目的进行模型设计。然而,以上方法没有顾及密集型建筑物的检测。此外,文献[30—31]提出的模型在密集型建筑物检测中有良好的性能,但是所用的建筑物数据较为规则,数据集中不包含检测框重叠比高的样本。基于此,本文首先通过构建形状多样的密集型建筑物数据集,然后提出一种Correg-YOLOv3方法,该方法以YOLOv3模型为基础,通过嵌入角点回归机制,增设一个关于顶点相对于边界框中心点的偏移量的额外损失项,使其可同时输出矩形检测框及建筑物角点,实现了检测框重叠比高的建筑物的精准定位。
1 Correg-YOLOv3目标检测方法 1.1 设计思路本文以YOLOv3模型为基础进行算法设计,该算法引入特征金字塔网络,能够降低小目标的漏检率,由于其显著的速度和识别优势,已成为深度学习目标检测领域最受关注的网络模型,相对于YOLOv4、YOLOv5模型,YOLOv3训练模型较小,能大大提高模型的训练效率,提高计算资源的利用率[32]。
本文方法流程如图 1所示。主要分为模型训练和模型测试两个阶段。首先获取高分辨率遥感影像数据并制作样本集,然后利用本文方法进行网络训练并调整参数,多次迭代训练网络模型,利用训练好的网络对测试样本进行检测,判断测试结果是否符合试验要求,如果不符合试验要求,则重新调整预训练参数进行训练,直到测试结果符合试验要求为止,最后得到优化的建筑物检测模型。

|
| 图 1 目标检测方法 Fig. 1 The object detection method flowchart |
1.2 网络模型
本文充分地利用YOLOv3在目标检测中的优势,对其进行改进使其适应密集建筑物的精准检测,提出一种Correg-YOLOv3方法。该方法的网络结构如图 2所示,Darknet53卷积网络是特征提取器,如图 2紫色虚线框所示。Darknet53主要由一系列1×1和3×3的卷积层组成,共53层。每个卷积层后面都有一个批量归一化(BN)[33]层和Leakyrelu层。Darknet53中引入了许多残差网络模块,它是从ResNet[34]中派生出来的。添加残差层的目的是解决网络中梯度消失或梯度爆炸的问题,这样就可以更容易地控制梯度的传播并进行网络训练。此外,还采用了多尺度预测、特征融合、边界框回归和角点回归等多种策略。

|
| 图 2 Correg-YOLOv3网络结构 Fig. 2 Correg-YOLOv3 network structure |
(1) 多尺度预测:采用多尺度预测方法,最终输出3个不同尺度的特征图,每个特征图分配3组不同大小的锚框,以适应不同尺寸目标的检测,如图 2红色虚线部分,由于输出网格的感受野不同,锚框的尺寸也需要做出调整,实现不同尺度上的目标检测。锚框大小可以通过K-means算法聚类得到,以提升算法的检测能力。
(2) 特征融合:采用类似特征金字塔结构实现深层特征与浅层特征融合,如图 2中Concat部分,将深层网络提取的细粒度特征经过上采样后与浅层网络提取的粗粒度特征进行融合,在保留了位置信息的同时提升细节感知能力,融合浅层特征与深层特征能进一步提升对纹理、颜色和边缘信息相对较少的目标的检测精度。
(3) 边界框回归:采用边界框回归的方式预测相对于特征图网格单元的偏移,用以确定中心点坐标,同时预测相对于锚框宽高的比例系数,用以确定目标大小。目标框与锚框的关系图如图 3所示。

|
| 图 3 目标框与锚框之间的关系 Fig. 3 Relationship between target box and anchor box |
回归公式为
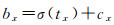 (1)
(1)
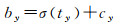 (2)
(2)
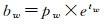 (3)
(3)
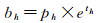 (4)
(4)
式中,(bx, by, bw, bh)为目标边界框的中心点坐标及宽和高;(tx, ty, tw, th)为网格预测的边界框中心点偏移量和宽高偏移量;(cx, cy)为目标中心点所在的网格单元左上角在特征图上的位置偏移;(pw, ph)为与目标边界框最匹配的锚框的宽和高;σ为Sigmoid函数。
(4) 角点回归:本文方法增设一种角点回归预测的方法,如图 3所示,4个角点1、2、3、4到中心点坐标的水平与垂直偏移量分别为(x1, y1)、(x2, y2)、(x3, y3)、(x4, y4),从而使用边界框回归和角点回归共同预测建筑物的位置。
角点的偏移和边界框宽高的预测方式相同,计算公式如下
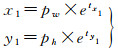 (5)
(5)
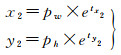 (6)
(6)
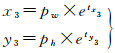 (7)
(7)
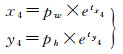 (8)
(8)
式中,(x1, y1)、(x2, y2)、(x3, y3)、(x4, y4)分别为左上、右上、右下、和左下4个顶点的水平与垂直偏移量;(tx1, ty1)、(tx2, ty2)、(tx3, ty3)、(tx4, ty4)分别为预测4个顶点的偏移量;(pw, ph)为与目标边界框最匹配的锚框的宽和高。
1.3 损失函数本文方法的损失函数包括中心点坐标损失、宽高损失、置信度损失、类别概率损失和角点偏移损失。具体使用的损失函数分别为:①中心点x、y的调整参数使用BCELoss;②anchor的宽高w、h的调整参数使用MSELoss;③置信度confidence使用BCELoss;④类别预测class使用BCELoss;⑤角点偏移参数调整使用smooth L1计算,计算公式为
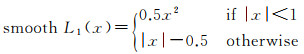 (9)
(9)
本方法损失函数L的计算公式如式(10)所示
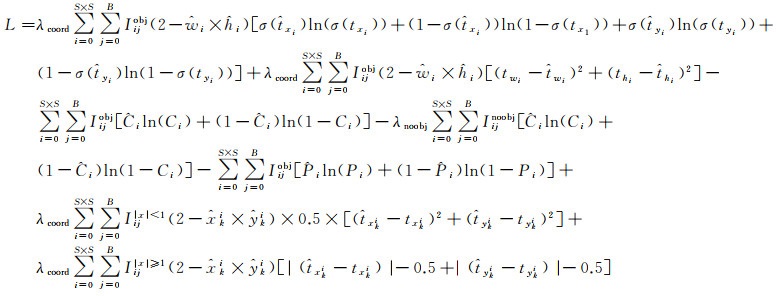 (10)
(10)
式中,λcoord为坐标损失权重,是一个动态变化的值,当检测目标尺寸较大时,λcoord较小,相反则较大;λnoobj表示不负责预测目标的网格单元的损失权重,由于负责预测目标的网格单元的数量远远小于不负责预测目标的网格单元数量,则λnoobj一般较小;对于第i个网格的第j个锚框,如果它负责检测某个目标,则Iijobj=1,Iijnoobj=0,反之Iijobj=0,Iijnoobj=1;S×S为输出层特征图的尺寸;B为特征图中每个网格单元产生的边界框数量;(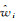
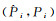
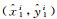
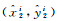
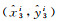
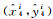
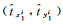
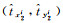
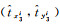
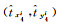
为了定量评估所选模型的性能,本文采用准确率(p)、召回率(r)、平均检测精度(AP)、F1作为检测评价指标。
精确率和召回率的计算公式分别为
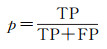 (11)
(11)
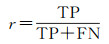 (12)
(12)
式中,TP表示被预测为建筑物,实际为建筑物;FP表示被预测为建筑物,实际为非建筑物;FN表示被预测为非建筑物,实际为非建筑物。
通常定义的平均精度(average precision)是指召回率在0~1之间的平均精度值,也是精度召回曲线下的区域。一般地,平均精度越高,模型性能越好。每个类别都可以根据准确率(precision)和召回率(recall)绘制一条曲线,具体可表示为
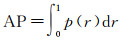 (13)
(13)
F1用于评估模型的综合性能,计算公式为
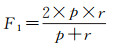 (14)
(14)
本文高分辨率遥感影像数据空间分辨率为0.6 m,图像覆盖了中国的不同城市住区,包括北京、石家庄、郑州、西安、太原等,影像裁剪为416×416像素。该影像数据集部分数据如图 4所示,建筑物种类丰富、形状各异、大小不一、色彩鲜明、地物清晰、质量很高,可以满足试验要求。

|
| 图 4 遥感影像建筑物数据(部分) Fig. 4 Building data from remote sensing images (part) |
2.1.2 数据集制作
通过人工筛选及手动标注,采用了LabelImg标注工具,该标注工具可以框出目标物体,并通过所选定的目标类型进行标签文件生成。当前,YOLOv3、SSD、Faster-RCNN等目标检测所需要的数据集,均需借助此工具标定图像中的目标,所生成的XML文件遵循PASCAL VOC数据的格式。标签文件记录了目标位置和目标类别,位置信息是由左上角和右下角坐标表示。共标注建筑物样本1757张,其中训练集1405张,测试集352张。
2.1.3 训练样本增强数据增强是深度学习模型训练的关键组成部分。作为本文主要的检测目标,建筑物在不同区域的影像中的分布规律多样,形状大小多变(多为不规则的多边形),房屋的排列方向也不同。为了防止模型在训练过程中出现过拟合现象,本文采用的数据增强方式有图像旋转、翻转、HSV、高斯噪声、亮度、HSV+亮度、HSV+亮度+高斯噪声。数据增强结果如图 5所示,其中旋转是在原始影像上旋转90°、180°和270°,翻转是在旋转的基础上进行了翻转;HSV变化用来调节图像色调、饱和度、明度。除此之外,还有添加高斯噪声、调整亮度及HSV+亮度、HSV+亮度+高斯噪声等数据增强方式。

|
| 图 5 数据增强处理结果 Fig. 5 Data enhancement processing results |
2.2 试验环境与参数设置
本文的模型均搭建在PyTorch深度学习框架下,操作系统环境为Ubuntu18.04,配置2路12 GB显存的Nvidia 3080GPU,并使用Cuda11.1和cudnn-8.0.5进行GPU加速计算,深度学习算法代码和训练得到的模型都被保存在Ubuntu系统环境下,方便保存和维护。对于模型软件环境,本文试验所有网络模型都是由Pytorch实现的,初始学习率设定为0.000 1,批处理大小为8,epoch为200。
2.3 结果与分析为了验证本文方法的有效性,以自建高分辨率遥感影像数据集为基础,训练集共有1405张,测试集352张,通过样本数据增强使得训练集为18 265张,训练过程中随机抽出10%作为验证集,通过调整网络参数,如学习率、训练次数和锚框大小等,并将准备好的数据放入网络中训练,最后分别利用改进前后训练好的模型进行测试。
由于建筑物大小不一、形状各异,锚框尺寸也需要做出调整。针对建筑物数据集,采用K-means算法聚类计算出9个锚框的大小,并将其均分到3个尺度的特征图,以此来获得更多的目标边缘信息,锚框大小分别为:(128,64)、(140,64)、(165,50)、(64,64)、(92,32)、(112,40)、(32,32)、(48,48)、(64,48)。分辨率较小的13×13的特征图有较大的感受野,故采用较大的锚框(128,64)、(140,64)、(165,50);分辨率为26×26的特征图对于检测中等大小的目标有利,故采用中等的锚框(64,64)、(92,32)、(112,40);分辨率较大的52×52的特征图有较小的感受野,故采用较小的锚框(32,32)、(48,48)、(64,48)。
本文分别对YOLOv3和Correg-YOLOv3方法在先验框聚类前后进行了试验对比分析(表 1)。由表 1可知,不管是YOLOv3还是Correg-YOLOv3方法,采用K-means调整先验框维度后的结果都相较于原始先验框检测结果都好,精度、召回率和平均精度都有所提升。本文方法检测精度、召回率和平均精度分别达到了96.45%、95.75%和98.05%,较原算法YOLOv3分别提高了2.73%、5.4%和4.73%。
| 方法 | p | r | F1 | AP |
| YOLOv3 | 93.72 | 90.35 | 92.00 | 93.32 |
| YOLOv3+kmeans | 94.07 | 90.80 | 92.41 | 93.63 |
| Correg-YOLOv3 | 94.68 | 95.53 | 95.10 | 97.63 |
| Correg-YOLOv3+kmeans | 96.45 | 95.75 | 96.10 | 98.05 |
此外,本文对比了YOLOv3和Correg-YOLOv3方法调整先验框前后训练时损失的变化情况(图 6),可以看出不管是否加入K-means算法调整先验框维度,本文方法的损失收敛较快,如图 6黄色线和蓝色线所示,在epoch大约为15时趋向于平稳,而原始YOLOv3方法收敛较缓慢,如图 6绿色线和红色线所示,在epoch大约为30时才趋向于平稳。此外,再经过多次迭代训练,可以看出4种方法的损失值相差较小,但调整先验框维度后的Correg-YOLOv3方法的损失在epoch为160时,开始始终低于其他3种方法的损失,这也体现了本文方法的优越性。

|
| 图 6 YOLOv3和Correg-YOLOv3方法调整先验框前后损失变化 Fig. 6 YOLOv3 and Correg-YOLOv3 were used to adjust the loss changes before and after the prior frame |
为了验证本文方法的可行性,本文又对原始YOLOv3方法和本文方法的检测效果图及流行的目标检测方法SSD和Faster R-CNN进行对比分析,如图 7、图 8所示。通过对比发现,本文方法对密集型建筑物检测效果较好,漏检明显减少。

|
| 图 7 密集建筑物检测效果对比 Fig. 7 Comparison of detection results of dense buildings |

|
| 图 8 非水平排列密集建筑物检测效果对比 Fig. 8 Comparison of detection results of non-horizontal arrangement of dense buildings |
图 7展示了4种网络模型对于密集建筑物场景下的检测效果,第1行检测结果对比可以看出,SSD和Faster R-CNN方法检测的建筑物定位不准确,漏检较多,YOLOv3方法大部分检测结果还可以,仅仅对难以区分边界的建筑物(图 7黄色箭头所指向区域)检测结果较差,本文方法能够有较好的检测结果(图 7蓝色箭头所指向区域);第2行检测结果对比可以发现,YOLOv3和SSD方法对图 7黄色框内建筑物误认为是一个建筑物,Faster R-CNN方法比YOLOv3和SSD检测结果相比检测较好,但存在检测框定位不准确的问题,而本文方法能够有较好的检测结果(图 7蓝色箭头所指向区域)。图 8展示了对于非水平排列的建筑物中4种网络模型检测效果的对比,第1行检测结果对比可以看出,虽然SSD和Faster R-CNN方法对于黄色框区域内建筑物检测效果较好,但是这两种方法存在漏检、错检较多,以至于影响建筑物整体检测结果,本文方法不仅能够改善非水平排列密集型建筑物检测效果,而且整体上也检测较好;第2行检测结果对比也可以发现,SSD和Faster R-CNN方法错检、漏检较多,本文方法整体上检测效果较好。
为了验证改进算法的可行性,本文又与当前目标检测比较流行的Faster R-CNN、SSD进行了定量对比,分别采用相同阈值IoU=0.5时进行测试,不同模型的评价指标结果见表 2。
| 模型 | p | r | F1 | AP |
| Faster R-CNN | 57.25 | 87.53 | 69.22 | 81.86 |
| SSD | 91.42 | 87.98 | 89.67 | 93.84 |
| YOLOv3 | 93.72 | 90.35 | 92.00 | 93.32 |
| 本文方法 | 96.45 | 95.75 | 96.10 | 98.05 |
由表 2可以看出,当前流行的Faster R-CNN、SSD、YOLOv3方法中YOLOv3有较大的优势,主要是因为YOLOv3采用类似特征金字塔结构,对大小不一的目标检测相对于其他两种网路比较友好,这也是本文选择在YOLOv3上做进一步改进的原因。以上3种流行的方法都是利用边界框回归的方式进行预测的,而本文方法是通过嵌入角点回归机制,增设建筑物角点损失,扩展其输出维度,使其可同时输出矩形检测框及建筑物角点,利用边界框回归和角点回归共同预测,对密集排列的建筑物起到了较好的检测效果,充分说明了本文方法在密集建筑物检测领域的先进性。
为了进一步验证本文方法的性能,本文模型对不同IoU阈值下的各评价指标进行了统计,见表 3。
| IoU | p | r | F1 | AP |
| 0.6 | 96.2 | 95.76 | 96.00 | 98.11 |
| 0.65 | 95.52 | 95.76 | 95.64 | 98.01 |
| 0.7 | 89.69 | 95.78 | 92.64 | 97.52 |
| 0.75 | 64.54 | 95.80 | 77.12 | 95.83 |
| 0.8 | 41.97 | 95.78 | 58.36 | 91.66 |
将表 3中的结果与表 2中阈值设置为0.5的其他模型相比,可以看出,本文方法在阈值为0.65时,各评价指标仍然具有明显的优势。随着阈值的增大,准确率开始下降,是因为阈值增大后,FP增多所致,另外AP在阈值为0.75时,仍然保持较高的平均精度,充分证明了本文方法的优越性。
3 总结本文针对现有的以先验框回归方式输出的目标检测算法在密集型建筑物检测中存在检测框重叠比高的问题,提出了一种基于YOLOv3的高分辨率遥感影像中密集建筑物检测方法Correg-YOLOv3。该方法是以YOLOv3为基础,通过嵌入角点回归机制,增设一个关于顶点相对于边界框中心点的偏移量的额外损失项,使其可同时输出矩形检测框及建筑物角点。同Faster R-CNN、SSD、YOLOv3方法相比,本文方法在准确率、召回率、平均检测精度、F1等方面都有较为显著的提升,有效解决了高分影像中密集型建筑物的检测问题。
本文方法虽然在一定程度上提升了建筑物检测的精度,但仍然还有提升的空间,如图像中建筑物背景模糊、树木遮挡、高建筑物遮挡,以及城中村建筑物小且密集难以区分边界等情况,因此会导致对此类建筑物难以检测出来。在接下来的工作中,可以通过融合纹理特征、优化网络结构、扩充建筑物数据种类等措施,提升模型在上述难以检测的环境下的建筑物检测精度。
| [1] |
CHENG Gong, HAN Junwei. A survey on object detection in optical remote sensing images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 117: 11-28. DOI:10.1016/j.isprsjprs.2016.03.014 |
| [2] |
邓睿哲, 陈启浩, 陈奇, 等. 遥感影像船舶检测的特征金字塔网络建模方法[J]. 测绘学报, 2020, 49(6): 787-797. DENG Ruizhe, CHEN Qihao, CHEN Qi, et al. A deformable feature pyramid network for ship detection from remote sensing images[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(6): 787-797. DOI:10.11947/j.AGCS.2020.20190117 |
| [3] |
张涛, 丁乐乐, 史芙蓉. 高分辨率遥感影像城中村提取的景观语义指数方法[J]. 测绘学报, 2021, 50(1): 97-104. ZHANG Tao, DING Lele, SHI Furong. Urban villages extraction from high-resolution remote sensing imagery based on landscape semantic metrics[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(1): 97-104. DOI:10.11947/j.AGCS.2021.20190463 |
| [4] |
张勇. 遥感与GIS在厦门市违章建筑监测与管理中的应用[J]. 测绘与空间地理信息, 2016, 39(2): 75-77. ZHANG Yong. Application of remote sensing and GIS in monitoring and management of illegal construction Xiamen city[J]. Geomatics & Spatial Information Technology, 2016, 39(2): 75-77. DOI:10.3969/j.issn.1672-5867.2016.02.022 |
| [5] |
孙长奎, 刘善磊, 王圣尧, 等. 浅谈无人机遥感技术在智慧城市建设中的应用[J]. 国土资源遥感, 2018, 30(4): 8-12. SUN Changkui, LIU Shanlei, WANG Shengyao, et al. Application of UAV in construction of smart city[J]. Remote Sensing for Land & Resources, 2018, 30(4): 8-12. |
| [6] |
刘扬, 付征叶, 郑逢斌. 高分辨率遥感影像目标分类与识别研究进展[J]. 地球信息科学学报, 2015, 17(9): 1080-1091. LIU Yang, FU Zhengye, ZHENG Fengbin. Review on high-resolution remote sensing image classification and recognition[J]. Journal of Geo-Information Science, 2015, 17(9): 1080-1091. |
| [7] |
LIN Jingbo, JING Weipeng, SONG Houbing, et al. ESFNet: efficient network for building extraction from high-resolution aerial images[J]. IEEE Access, 2019(7): 54285-54294. |
| [8] |
ZOU Weitao, JING Weipeng, CHEN Guangsheng, et al. A survey of big data analytics for smart forestry[J]. IEEE Access, 2019, 7: 46621-46636. DOI:10.1109/ACCESS.2019.2907999 |
| [9] |
冯丽英. 基于深度学习技术的高分辨率遥感影像建设用地信息提取研究[D]. 杭州: 浙江大学, 2017. FENG Liying. Research on construction land information extraction from high resolution images with deep learning technology[D]. Hangzhou: Zhejiang University, 2017. |
| [10] |
马长辉, 黄登山. 纹理与几何特征信息在高空间分辨率遥感影像分类中的应用[J]. 测绘地理信息, 2019, 44(6): 66-70, 92. MA Changhui, HUANG Dengshan. Application of texture features and geometric feature information in high spatial resolution remote sensing image classification[J]. Journal of Geomatics, 2019, 44(6): 66-70, 92. |
| [11] |
HU Lei, ZHENG Jin, GAO Feng. A building extraction method using shadow in high-resolution multispectral images[C]//Proceedings of 2011 IEEE International Geoscience and Remote Sensing Symposium. Las Vegas, NV, USA: IEEE, 2011: 1862-1865.
|
| [12] |
施文灶, 毛政元. 基于图割与阴影邻接关系的高分辨率遥感影像建筑物提取方法[J]. 电子学报, 2016, 44(12): 2849-2854. SHI Wenzao, MAO Zhengyuan. Building extraction from high-resolution remotely sensed imagery based on shadows and graph-cut segmentation[J]. Acta ElectronicaSinica, 2016, 44(12): 2849-2854. DOI:10.3969/j.issn.0372-2112.2016.12.006 |
| [13] |
KONSTANTINIDIS D, STATHAKI T, ARGYRIOU V, et al. Building detection using enhanced HOG-LBP features and region refinement processes[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2016, 10(3): 888-905. |
| [14] |
吕凤华, 舒宁, 龚龑, 等. 利用多特征进行航空影像建筑物提取[J]. 武汉大学学报(信息科学版), 2017, 42(5): 656-660. LV Fenghua, SHU Ning, GONG Cun, et al. Regular building extraction from high-resolution image based on multilevel-features[J]. Geomatics and Information Science of Wuhan University, 2017, 42(5): 656-660. |
| [15] |
CHAUDHURI D, KUSHWAHA N K, SAMAL A, et al. Automatic building detection from high-resolution satellite images based on morphology and internal gray variance[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 9(5): 1767-1779. |
| [16] |
AWRANGJEB M, ZHANG Chunsun, FRASER C S. Improved building detection using texture information[J]. International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2011, 38: 143-148. |
| [17] |
赵传, 张保明, 陈小卫, 等. 一种基于LiDAR点云的建筑物提取方法[J]. 测绘通报, 2017(2): 35-39. ZHAO Chuan, ZHANG Baoming, CHEN Xiaowei, et al. A method of extracting building based on LiDAR point clouds[J]. Bulletin of Surveying and Mapping, 2017(2): 35-39. |
| [18] |
GUO Haonan, SHI Qian, DU Bo, et al. Scene-driven multitask parallel attention network for building extraction in high-resolution remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(5): 4287-4306. |
| [19] |
LI Zhenshi, ZHANG Xueliang, XIAO Pengfeng, et al. On the effectiveness of weakly supervised semantic segmentation for building extraction from high-resolution remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 3266-3281. |
| [20] |
胡舒, 王树根, 王越, 等. 基于Mask R-CNN的高分遥感影像建筑物目标检测研究[J/OL]. 测绘地理信息. [2021-04-01]. https://doi.org/10.14188/j.2095-6045.2020416. HU Shu, WANG Shugen, WANG Yue, et al. Building object detection in high-resolution remote sensing image based on mask R-CNN[J/OL]. Journal of Geomatics. [2021-04-01]. https://doi.org/10.14188/j.2095-6045.2020416. |
| [21] |
GIRSHICK R. Fast R-CNN[C]//Proceedings of 2015 IEEE International Conference on Computer Vision. New York, USA: IEEE, 2015: 1440-1448.
|
| [22] |
REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 39(6): 1137-1149. |
| [23] |
HE Kaiming, GKIOXARI G, DOLLAR P, et al. Mask r-cnn[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. New York, USA: IEEE, 2017: 2961-2969.
|
| [24] |
史文旭, 鲍佳慧, 姚宇. 基于深度学习的遥感图像目标检测与识别[J]. 计算机应用, 2020, 40(12): 3558-3562. SHI Wenxu, BAO Jiahui, YAO Yu. Remote sensing image target detection and identification based on deep learning[J]. Journal of Computer Applications, 2020, 40(12): 3558-3562. |
| [25] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2016: 779-788.
|
| [26] |
LIU Wei, ANGUELOY D, ERHAN D, et al. Ssd: single shot multibox detector[C]//Proceedings of 2016 European Conference on Computer Vision. Cham, Switzerland: Springer, 2016: 21-37.
|
| [27] |
董彪, 熊风光, 韩燮, 等. 基于改进Yolo v3算法的遥感建筑物检测研究[J]. 计算机工程与应用, 2020, 56(18): 209-213. DONG Biao, XIONG Fengguang, HAN Xie, et al. Research on remote sensing building detection based on improved Yolo v3 algorithm[J]. Computer Engineering and Applications, 2020, 56(18): 209-213. |
| [28] |
李响, 苏娟, 杨龙. 基于改进YOLOv3的合成孔径雷达图像中建筑物检测算法[J]. 兵工学报, 2020, 41(7): 1347-1359. LI Xiang, SU Juan, YANG Long. A SAR image building detection algorithm based on improved YOLOv3[J]. Acta Armamentarii, 2020, 41(7): 1347-1359. |
| [29] |
MA Haojie, LIU Yalan, REN Yuhuan, et al. Detection of collapsed buildings in post-earthquake remote sensing images based on the improved YOLOv3[J]. Remote Sensing, 2020, 12(1): 44. |
| [30] |
LI Qingpeng, WANG Yunhong, LIU Qingjie, et al. Hough transform guided deep feature extraction for dense building detection in remote sensing images[C]//Proceedings of 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York, USA: IEEE, 2018: 1872-1876.
|
| [31] |
JIANG Kaiyu, LI Qingpeng. TQR-Net: Tighter quadrangle-based convolutional neural network for dense building instance localization in remote sensing imagery[C]//Proceedings of 2019 International Conference on Image and Graphics. Cham, Switzerland: Springer, 2019: 281-291.
|
| [32] |
WANG Kun, LIU Maozhen, YE Zhaojun. An advanced YOLOv3 method for small-scale road object detection[J]. Applied Soft Computing, 2021, 107846. |
| [33] |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proceedings of 2015 International conference on machine learning. Calgary Canada: PMLR, 2015: 448-456.
|
| [34] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE conference on computer vision and pattern recognition. Las Vegas, NV, USA: IEEE, 2016: 770-778.
|