



2. 31682部队, 甘肃 兰州 730020;
3. 中国地质调查局西宁自然资源综合调查中心, 青海 西宁 810000
2. Troops 31682, Lanzhou 730020, China;
3. Xining Center of Natural Resources Comprehensive Survey, China Geological Survey, Xining 810000, China
大视角差影像序列匹配是利用倾斜摄影平台在不同时间、不同方位对目标区域依次获取多幅视角变化较大的影像,然后通过寻找不同影像之间的同名像点,得到像素级对应关系的方法,在三维重建、灾害应急、纹理映射等应用发挥着重要作用[1],服务于地理空间感知智能的发展[2]。不同于常规的航空或卫星影像,无人机通过搭载非量测型相机拍摄大视角差影像序列,包含了更丰富的侧面信息,能够更加客观真实地反映目标区域的实际情况[3]。随着影像在质与量方面的升级,实际应用中对大视角差影像匹配算法的正确率、匹配点数量、匹配精度、匹配耗时等提出了更高的要求。但由于大视角差图像序列中存在仿射变形大、遮挡严重、视角差异显著等问题,使得被摄物体的几何特征、纹理特征等信息缺失,出现了同名点匹配存在多解和误匹配等现象,流失了大量有用的特征点信息,导致了最终确定的匹配点分布不均、稳健性低下等问题,在此基础上计算的图像之间变换矩阵无法充分体现被摄物体复杂的变换关系,严重影响了后续的工程应用[4]。
针对上述问题提出的解决大视角差影像匹配方法可划分为两大类,一是基于手工设计型的特征匹配方法,二是基于深度学习型的特征匹配方法。基于手工设计的影像视角变化较大的匹配方法归纳起来主要有4种[5]:①由粗到精的特征匹配。文献[6]利用SIFT算法获取特征点,NCC算法优选匹配点对,LSM算法精确定位匹配点同名点对,实现了倾斜影像的高精度匹配。②基于仿射不变特征的倾斜影像匹配。文献[7]基于Gabor滤波分解及相位一致性提取归一化区域内的特征点,利用高斯混合模型确定同名点及影像间的变换矩阵来解决仿射不变区域特征点位精度低的问题。③基于几何纠正的倾斜影像匹配。文献[8]提出一种具有仿射不变性倾斜影像匹配方法,通过估算影像的相机轴定向参数计算初始仿射矩阵,再逆仿射变换得到纠正影像,对纠正影像进行SIFT匹配实现倾斜影像的匹配[9]。文献[10]利用机载POS数据对倾斜影像进行全局几何纠正,然后利用SIFT算法实现影像特征提取和匹配,但这种方法需获取相机外方位元素,对摄影系统提出了较高的要求。④基于模拟畸变的倾斜影像匹配。文献[11]通过分析SIFT在仿射变化条件下的效率,提出了以图像变换集为基础的仿射尺度不变特征变换算法,对图像平移、旋转、尺度缩放、光照变化表现出了较好性能。可知,上述基于手工设计的方法多数是以SIFT算法为基础进行改进,但由于SIFT算法仅适应较小仿射变换的约束,使得在视角差异较大时会出现计算复杂度高,算法稳健性低,实际应用性能不佳等问题。
近年来随着人工智能技术的发展,深度卷积神经网络CNN作为一种高层特征提取器被引入到图像匹配领域,借助其强大的特征学习能力和视觉推理能力,在影像匹配领域取得较好效果[12],有望在应对大视角差影像序列匹配存在的困难中取得突破。文献[13]首先使用卷积神经网络MC-CNN计算序列影像匹配,证明了通过卷积神经网络提取的图像特征比手工设计的特征算子更加准确。受此启发,大量影像匹配工作利用卷积神经网络来计算匹配代价,并取得较好的匹配结果。如利用孪生网络提取特征和计算描述符相似度的MatchNet网络[14],采用三元组损失函数的HardNet网络[15],同时提取特征点和描述符的SuperPoint[16]、D2-Net[17]、R2D2[18]等网络,这些网络模型在标准数据集上取得了较好的效果,但直接应用于大倾斜无人机影像的匹配表现不佳[19]。文献[20]采用多分支卷积网络的倾斜立体影像仿射不变特征匹配,验证了这种方法对于低空无人机倾斜立体影像匹配的有效性,然而其匹配精度和匹配效率都受到了限制。
由此可见,从经典的特征匹配方法、仿射不变特征匹配、几何纠正的方法、影像畸变模拟方法再到深度学习匹配方法都取得了长足的发展。但随着应用领域的深入,对视角变化较大的影像匹配提出了更高的要求,依然面临较大挑战,主要表现为:①视角变化大的影像仿射变形大,高分辨率影像潜在同名匹配特征点分布区域的精确位置难以获取;②显著的视角差异使得被摄区域存在严重遮挡和剧烈光照变化,会造成影像特征提取不完备、匹配效率低等问题,特别是密集建筑物地区表现更为突出;③弱光照或夜晚条件下拍摄的图像往往分辨率低、有较多噪点,缺少足够的纹理特征,给大视角差图像匹配任务带来了困难。
针对以上高分辨率大视角差影像匹配存在的相似特征干扰下匹配正确率低、计算规模大、同名特征点对稀少等挑战,应当设计一个具备匹配点精度高、耗时少、稳健性强等特点的学习型特征匹配模型。在已有的卷积神经网络模型中,D2-Net是一种能够高效提取深层次特征的网络,通过深层网络的学习,提取不同影像间的同名特征,具备了高效抵抗影像间非线性辐射畸变和几何畸变的性能。基于此,本文将通过对D2-Net网络进行适应性改进,使其能够有效地提取具有旋转不变性的学习型特征描述符,来弥补影像特征匹配算法对视角变化敏感的缺陷,然后采用由粗到精的特征提纯策略,实现稳健匹配同名点对的同时降低匹配时间成本,完成大视角差图像序列高精度匹配。
1 旋转不变局部学习型特征匹配方法 1.1 本文方法基本思想与流程大视角差影像序列的稳健匹配,核心问题在于如何减小影像视角变化带来的影响,找到具有旋转不变性的特征表示方法[21]。为实现这一目的,本文提出的大视角差影像序列匹配方法着重考虑以下3个方面:①构建一种适合大视角差影像序列旋转不变特征提取和描述的CNN网络;②利用已经配对好的光照和拍摄角度都存在较大差异的数据训练CNN网络,让CNN特征提取器能够学习到具有视角、尺度、纹理、几何等变化的影像不变性特征;③设计一种对低内点率有较强稳健性能的误匹配剔除算法,以适应影像的旋转、尺度等变化。因此,匹配方法主要包括3个步骤:①网络模型设计,网络设计思想主要来源于D2-Net网络,对其增加随机旋转单应矩阵创建训练图像对,形成双头通信的D2-Net网络结构;②旋转不变学习型特征提取与描述,利用构造的网络模型作为特征提取器,在大视角差影像序列上提取学习型特征及其描述符;③特征匹配与误匹配剔除,特征匹配方法采用特征描述符最近邻和次近邻动态最优距离之比得到粗匹配同名点,结合RANSAC算法完成误匹配点对剔除,并通过重新验证相似性特征点的几何一致性,完成特征精匹配。本文方法流程如图 1所示。

|
| 图 1 本文方法基本流程 Fig. 1 The basic flowchart of the proposed algorithm |
1.2 网络模型设计 1.2.1 网络模型结构
由于卷积神经网络模型单次输入影像边长的最大尺寸受到约束,因此,在处理大幅面影像时,设计对输入影像自适应降采样策略,能够满足合适的输入尺寸到网络模型进行提取特征。另外,卷积神经网络端到端的匹配方式,会由于缺少几何约束,存在过拟合等问题,通常无法达到手工设计方法的精度,通过引入大型数据集上预训练模型到特征提取器中,往往可以达到更好的匹配效果。本文基于D2-Net网络模型构建的大视角差影像序列旋转不变特征匹配模型,相比于原始网络,显著性体现在如下两方面。
第一,通过迁移学习微调原始模型的骨干网络VGG16,使构建的网络模型能够适应于视角差异显著的图像匹配。具体做法是通过迁移学习冻结浅层权重的同时微调最后一层,微调后网络结构如图 2所示。微调VGG16骨干网络能够有效提取显著性特征,在筛选特征明显的关键点时,降低了在另一幅图像中搜索同名特征点描述符的耗时,从而提高影像匹配效率和算法模型性能。为了在Rw×h×c特征空间筛选出较为显著的特征点,采用了在高维特征图的通道方向和局部平面内同时最大的筛选策略[17],选取VGG16的Conv4_3层的特征描述输出作为特征图,为提升匹配效率,特征匹配时采用前256维向量;另外,为能够扩大卷积计算的感受野,增加网络对全局特征的提取能力,避免空间分辨率的下降和模型参数量的提升,本文对Conv4_3所在的卷积模块全部采用空洞率为2的空洞卷积,提升特征多尺度表征能力[17]。

|
| 图 2 特征提取网络结构 Fig. 2 Feature extraction network structure |
第二,通过共享骨干网络VGG16的方法增加分支网络,形成双头通信的网络结构。不同于D2-Net网络的是,设计网络的输入是随机裁剪成400×400×3大小的图像区域,随机旋转单应矩阵HR(θ)用于在平面内将图像旋转θ度,创建训练图像对。本文采用的训练方式、特征提取和特征描述方法遵循文献[17]中的定义,主要区别在于本文使用的训练数据是基于在平面内旋转后的图像对。由于传感器获取影像的视角差异,不同视角影像中同名点特征描述符存在差异,训练影像除了具备一系列旋转变化,还结合透视变换、尺度变换、光照变换等进一步模拟真实的视角变化,文献[22]提出的PhotoTourism数据集不仅具有同名点像素级标注的图像对,且能够满足上述特性,因此,本文还选用了该数据集进行模型训练。
上述过程对影像在视角变化较大时,局部特征匹配性能提升明显。但在视角变化不大时,则可能出现特征匹配不上的情况[23]。为此,设计了双头通信的D2-Net网络结构方法,即第1个头部是按照文献[17]训练MegaDepth数据集,通过训练结果模型来获取特征点和描述符;第2个头部对应于本文所使用的平面内旋转数据和PhotoTourism训练结果。由于网络结构的双头模型共享同一个骨干网络,且仅微调了网络输出的最后一层,因此这种双头通信方法能够提升模型的效率。在双头模型框架下,一旦获得了特征关键点和描述符,就可以独立地为每个头部在图像对之间获得特征最近邻的对应关系。
1.2.2 特征多尺度检测模型尽管训练CNN模型使用了具有尺度差异的训练样本,学习到的特征描述符可以一定程度上抵抗尺度变化,但对于大尺度差异表现并不理想[21]。因此,为了获得特征多尺度描述符,本文对输入图像进行上下采样操作来构建图像多尺度金字塔模型。对于输入图像,通过构建5层金字塔来适应影像尺度的剧烈变化,系数σ取值分别为0.25、0.5、1.0、2.0、4.0,中间第3层表示σ=1.0的原始输入图像,更高层是中间层的收缩层,更低层是中间层的扩张层。上述5个层用于提取每个层级分辨率的特征图Fl,并应用式(1)来累积特征融合结果。最终从融合后的特征图中提取特征描述符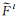
 (1)
(1)
由于图像多尺度金字塔不同层级的分辨率不同,在特征累积融合之前,需要对齐低分辨率特征图和高分辨率特征图。对于在不同层级可能检测到的重复特征,从最粗的尺度开始标记检测特征位置,这些位置被上采样到更高层级的特征图作为模板。如果从高一层级分辨率特征图中提取的特征关键点落入模板中,它们将被丢弃[21]。
1.3 旋转不变学习型特征匹配对于参考图像I1第k1个特征点对应的256维学习型特征向量可表示为[4]
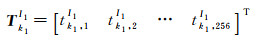 (2)
(2)
式(2)与图像I2第k2个特征点对应的特征向量归一化内积可用向量夹角θ的余弦值表示[4]
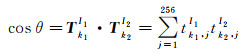 (3)
(3)
利用式(3)可解算最近邻与次近邻夹角余弦值的比值,以此来判定是否选择最近邻夹角对应向量作为匹配的特征向量[4]。记φi1为最近邻特征向量余弦值,φi2为次近邻特征向量余弦值,如式(4)所示,阈值ratio越小,所得匹配点显著性越高,对于大视角差无人机影像序列,存在大量潜在同名相似性特征的情况,小ratio值能够得到更高匹配精度的同名点对
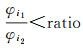 (4)
(4)
对于特征点数量丰富的高分辨率无人机影像而言,可通过尺度降采样的方式,获取更能表征图像整体结构的特征点,避免因影像分辨率较高使得特征点位置包含粗差带来的错误匹配,以实现影像的快速高精度初始匹配。根据文献[4],为在确保匹配正确率的基础上保留更多匹配点对,匹配过程中ratio取值为0.4时最优。
1.4 特征误匹配剔除当影像间存在显著的几何变换时,在同名点匹配搜索过程中,理论上的唯一匹配点将受到更多潜在可行解的干扰[4]。RANSAC算法常被用来探测最近邻特征点集的内点和外点,但最近邻特征点集以外的正确匹配点难以检测,因此可尝试在RANSAC的基础上,增加K近邻特征点集的几何一致性验证策略,提高正确匹配点数量和匹配正确率。为此,本文采用了一种由粗到精的提纯策略,试图在提高计算效率的同时,进一步增加正确匹配点对数。具体步骤如下。
(1) 基于动态自适应阈值的粗提纯。为提高RANSAC的计算效率和正确匹配点对的识别精度,本文采用文献[21]的动态自适应阈值算法,它是在近邻距离比基础上进行的改进,首先根据描述符的相似性,搜索参考影像上的每个特征在待匹配影像上两个最相似的特征点,即最近邻特征和次近邻特征,并将所有最近邻特征与次近邻特征在描述符空间的距离差均值作为正确匹配的依据,计算公式为[21]
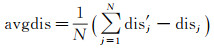 (5)
(5)
式中,dis和dis′分别为最近邻距离和次近邻距离;N为参考图像上的特征点数;avgdis为距离差均值。当dis和dis′距离差满足式(6)时,将最近邻特征作为候选匹配点保留,否则,将该初始匹配点对剔除[21]
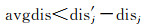 (6)
(6)
(2) RANSAC算法精提纯。经过动态自适应阈值粗提纯后,能够剔除大量误匹配点,显著提升内点率,但大视角差影像序列之间仿射变形、遮挡、视角差异等问题显著,仍含有部分错误匹配点,为此采用RANSAC算法进一步精提纯,利用影像间单应性矩阵作为估计模型,置信度设置为0.999,将满足几何一致性约束的点作为正确匹配点保留。由于粗提纯后的匹配点对中误匹配点显著减少,因此可有效提升RANSAC随机采样和几何一致性验证的计算效率,并提高匹配结果的稳健性。
(3) K近邻特征点的几何一致性检验。以上粗提纯和精提纯过程可能会错误剔除正确匹配点,且RANSAC几何一致性验证过程仅在最近邻特征点集进行,导致次近邻特征点集的正确匹配点被忽略[24],因此本文利用第(2)步计算的几何变换矩阵对基准影像特征点的k(k=2)近邻特征再次执行几何一致性检验,以识别出更多的正确匹配点,计算公式为[24]
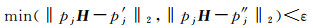 (7)
(7)
式中,pj为基准影像上特征点j的坐标;p′j和p″j为j点的K近邻特征点在待匹配影像上的坐标;H为影像对间的变换矩阵;||·||2为L2范数运算符;ε为投影误差阈值,本文设置为3。对于参考影像上的特征点,当其最近邻和次近邻特征中至少有一个在预测同名点pjH的ε范围内时,即可将投影误差最小的特征添加到内点集当中,依次遍历基准影像上的所有特征点,最终得到影像间的正确匹配点对。
2 试验结果与分析本节首先介绍大视角差影像序列匹配的试验数据情况;然后基于HPatches数据集对比分析适应于大视角差影像匹配的基于手工设计的ASIFT[11]算法和基于深度学习的D2-Net[17]、ASLFeat[25]、R2D2[18]和CMM-Net[21]算法计算的匹配结果;最后利用无人机实际飞行数据进一步对比试验分析。试验过程中,上述算法模型试验平台为联想LEGION笔记本,CPUi7-9750H,显卡GeForce GTX 1660Ti(6 GB显存),内存32 GB,编程语言Python,操作系统Ubuntu16.04。
2.1 试验数据数据包括HPatches标准数据集和实地采集影像两种类型。HPatches数据集包含多组剧烈视角变化的图像序列,每组图像序列由1幅参考图像、5幅不同视角的目标图像以及参考图像到目标图像的单应变换矩阵文件组成,能够较好地适用于算法性能测试。针对大视角差影像仿射变形大、视角差异显著、弱光照或夜晚条件等实际应用中的问题,按照无人机序列影像关键帧模式在维度上定向抽帧方法[26],实地采集了2组可见光和3组热红外大视角差图像序列,共20幅影像,其中可见光图像尺寸为2000×1125像素,热红外图像尺寸为640×512像素,此外两种不同模态影像之间还存在灰度、分辨率、信噪比、纹理特征等方面的差异,每种场景大视角差图像序列之间存在尺度、旋转、地物类型、飞行模式(绕飞、直飞、俯冲)等多方面差异,对测试算法适应性具有较好的代表性。基本情况如图 3所示。

|
| 图 3 大视角差影像序列试验数据 Fig. 3 The test data of image sequences with significantly different viewpoints |
由图 3展示的测试数据可知,场景1和场景2为尺度近似,视角差异较大的可见光大视角差图像序列,与基准图像视角差异分别约25°、50°、75°,主要差异体现在地物类型。场景3为噪声明显、纹理稀疏、尺度差异显著的夜间热红外大视角差图像序列。场景4为地面建筑密集、尺度近似、视角不同、纹理相对丰富的绕飞热红外图像序列。场景5为地面建筑密集、尺度差异显著、视角近似、纹理相对丰富的平飞热红外图像序列。
2.2 评价指标 2.2.1 特征重复率特征重复率衡量了特征检测器在不同视点、不同尺度、不同光照等条件下识别相同特征的能力,特征检测器的重复率越高,找到匹配项的可能性就越高。假设图像对重叠区域特征点检测的数量为N1和N2,对于第1幅图像中的每个特征点,检测其在第2幅图像中同名像点是否存在,则同名点特征重复率计算为
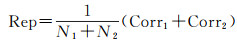 (8)
(8)
式中
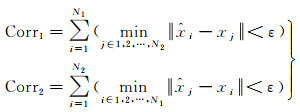
式中,xi是从第1幅图像检测的特征点;xj是从第2幅图像检测的特征点;
基于单应性矩阵将待匹配图像的特征点映射到参考图像上,可计算得出重投影误差矩阵DN1×N2,该矩阵元素表达成
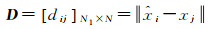 (9)
(9)
当相应的限差小于设定的阈值dij < d时,认为是正确匹配点对。特征匹配率则是基于该公式得到的正确匹配点对数量占所有匹配点对数量的百分比。
2.2.3 最近邻重投影误差完好的最近邻特征描述符匹配具有低值的重投影误差。当单应性矩阵完美地描述了两幅图像之间变换关系时,特征重投影误差趋于0。对于理想的特征匹配,重投影误差仅在0处得到峰值。假设两幅图像的同名点满足xit=Hxi,H是平面单应矩阵,xit和xi分别是图像中对应的同名点,重投影误差表述为
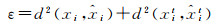 (10)
(10)
式中,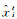
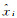
匹配精度的优劣可通过同名点的均方根误差(RMSE)刻画,描述为
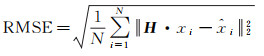 (11)
(11)
式中,xi和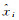
为验证本文方法的稳健性,基于HPatches数据集分别从算法本身改进对比、其他方法对比和定量检测描述3个方面进行验证。
首先,由于本文方法是在D2-Net方法基础上改进的,因此算法本身改进对比是与D2-Net算法在特征点检测和特征描述符进行对比评价,特征点检测的评价从特征重复性方面衡量,特征描述符的评价指标主要体现在单应矩阵的变换精度和特征匹配率。此外,利用尺度上有差异的数据集训练结果,其特征描述符能够一定程度上抵抗尺度变化,但对于尺度差异较大的情况难以适应,因此还需要构造多尺度特征检测器以增加匹配的稳健性。
由图 4可知,构建多尺度特征检测器对特征检测具有非极大值抑制作用,得到更稳健的特征点,本文的多尺度方法相比D2-Net多尺度方法,虽匹配点数量略低,但具有更高的特征重复率和正确匹配率,且当匹配阈值ε=3像素时具有最优的匹配性能,为真实场景中大视角差图像序列匹配明确了阈值设置。

|
| 图 4 模型改进前后特征提取重复率、匹配数量、匹配率对比 Fig. 4 Comparison of feature repetition rate, matching number, and matching rate |
然后,选取了HPatches数据集中视点变化显著的55组图像对,对比本文方法、D2-Net方法[17]、适应异源遥感影像匹配的D2-Net改进方法CMM-Net[21]、为获取高精度的像素级特征匹配对D2-Net改进的ASLFeat[25]、R2D2和ASIFT方法。为公平比较,对比方法的参数配置为:ASIFT参数为倾斜度采样间隔Δt= 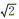

|
| 图 5 HPatches数据集55组影像对匹配 Fig. 5 Fifty-five image pairs matching in HPatches dataset |
2.3.2 实际数据匹配测试
为进一步验证本文方法的稳健性,采用了5种不同的实际场景下大视角差图像序列数据进行试验,参数设置与标准数据集一致,具体匹配结果如图 6所示。

|
| 图 6 不同方法在5种场景测试数据集的匹配结果 Fig. 6 The matching results of the six comparison methods in five scenarios test data |
图 6展示了6种方法在5种不同场景的匹配,其中本文方法能够对所有场景的影像序列给出一定数量的正确匹配点对。基于手工设计的ASIFT方法对视角差异显著的影像序列具有较好的适应性,但当视角差异约50°或者更大时,存在较多误匹配(图 6(b),场景2),甚至失败的情况(图 6(d),场景4),基于深度学习的D2-Net、R2D2、CMM-Net和ASLFeat方法对视角差异较大的图像对较为敏感,匹配点对稀少或者匹配失败,但在尺度差异大的影像序列上,均取得了较好的匹配效果。可知,对比方法能够适应一定视角差异的影像匹配,但当视角差异超过50°时,匹配效果急剧下降,出现匹配失败情况,视角差异较大的影像序列匹配稳健性较弱。而本文方法在5种场景的所有图像序列中均得到数量丰富的正确匹配点,对于角差异超过50°的影像和尺度差异大的影像匹配,识别到的同名点均较为充足且分布均匀,说明本文方法在不同视点的倾角变化较大的影像匹配中有着较好的稳健性。
图 7统计了6种对比方法在5种场景中的精提纯后匹配点数量和匹配耗时两个指标。从匹配点数量来看,本文方法在以视角差异显著的场景1、场景2和场景4影像序列中具有较为明显的优势,其他方法均出现匹配数量稀少甚至匹配不上的情况,在尺度差异明显的场景3和场景5中对比方法有着丰富的匹配点对数量,其中D2-Net、ASIFT、CMM-Net和R2D2匹配点数量均有超过本文方法的情况,说明了在极端视角差异情况下,剧烈的仿射变换会严重影响匹配算法性能,而尺度差异对算法性能影响不大。匹配耗时方面,D2-Net方法对于视角差异显著的场景1和场景2,匹配耗时严重,远高于其他方法,基于手工设计的ASIFT方法同样耗时较长,其他几种深度学习方法匹配耗时小于手工设计方法,且每种场景的影像序列匹配耗时相当,本文方法耗时在5种不同场景均用时相对较少。由此说明,对于大视角差图像序列匹配,通过构建双头通信机制的本文方法在保证识别出丰富的同名匹配点对的同时,降低了匹配时间成本,表现出较佳的匹配效果。

|
| 图 7 不同场景匹配结果对比 Fig. 7 Comparison of matching results in different scenarios |
表 1重点从匹配精度方面统计了精提纯后特征点数量占粗匹配特征点数量的比率(MR)和匹配点对的均方根误差(RMSE)。分析表 1数据可知,以成像视角差异为主的场景1、场景2和场景4中,本文方法相较于其他方法具有较高的MR,且能够得到较为可靠的RMSE,而其他方法在这3个场景中均出现匹配率低下,RMSE结果值较大等情形。以尺度差异为主的场景3和场景5中,本文方法和其他方法的MR和RMSE均具有较好的结果。表明本文方法相对于其他方法能够很好地适应视角差异较大的大倾角影像序列匹配,对于尺度差异显著的影像序列,本文方法和其他方法表现相当。
| 场景 | 影像对 | 指标 | 本文方法 | D2-Net | ASIFT | R2D2 | CMM-Net | ASLFeat |
| 场景1 | 序列1 | MR/(%) | 22.27 | 20.58 | 2.57 | 11.34 | 5.0 | 20.74 |
| RMSE | 2.71 | 3.11 | 3.51 | 3.37 | 3.58 | 3.16 | ||
| 序列2 | MR/(%) | 4.44 | 2.5 | 0.63 | 2.31 | 1.1 | fail | |
| RMSE | 6.55 | - | 7.70 | - | - | - | ||
| 序列3 | MR/(%) | 3.27 | 2.11 | 0.39 | fail | 1.7 | fail | |
| RMSE | 7.34 | - | - | - | - | - | ||
| 场景2 | 序列1 | MR/(%) | 34.36 | 31.44 | 0.56 | 30.33 | 6.22 | 13.28 |
| RMSE | 2.98 | 3.75 | 2.93 | 7.29 | 5.19 | 4.22 | ||
| 序列2 | MR/(%) | 7.46 | 4.24 | 2.07 | 7.43 | 6.7 | 1.44 | |
| RMSE | 4.08 | - | 5.76 | - | - | - | ||
| 序列3 | MR/(%) | 12.0 | 1.22 | 1.14 | 4.51 | fail | 0.26 | |
| RMSE | 6.62 | - | 6.98 | - | - | - | ||
| 场景3 | 序列1 | MR/(%) | 60.07 | 47.3 | 3.67 | 64.31 | 31.8 | 10.96 |
| RMSE | 1.34 | 1.53 | 1.86 | 1.51 | 2.14 | 1.48 | ||
| 序列2 | MR/(%) | 33.71 | 36.33 | 2.69 | 54.01 | 18.67 | 30.22 | |
| RMSE | 1.95 | 2.16 | 2.13 | 2.44 | 3.65 | 2.13 | ||
| 序列3 | MR/(%) | 37.0 | 50.25 | 3.41 | 85.73 | 19.93 | 7.78 | |
| RMSE | 1.11 | 0.959 | 1.62 | 0.77 | 1.78 | 1.01 | ||
| 场景4 | 序列1 | MR/(%) | 50.26 | 45.02 | 1.15 | 39.23 | 23.07 | 6.14 |
| RMSE | 3.61 | 3.88 | 3.63 | 4.31 | 3.92 | 3.74 | ||
| 序列2 | MR/(%) | 16.80 | 12.76 | 1.80 | 11.5 | 9.56 | 8.0 | |
| RMSE | 5.96 | 5.48 | 6.69 | - | 8.09 | 9.66 | ||
| 序列3 | MR/(%) | 8.25 | 4.97 | 0.52 | 7.17 | 3.87 | 0.26 | |
| RMSE | 6.52 | - | - | - | 8.61 | - | ||
| 场景5 | 序列1 | MR/(%) | 82.67 | 82.5 | 52.6 | 91.24 | 41.13 | 20.24 |
| RMSE | 0.90 | 0.94 | 0.84 | 1.08 | 0.87 | 0.84 | ||
| 序列2 | MR/(%) | 58.77 | 71.56 | 2.35 | 86.42 | 20.78 | 9.94 | |
| RMSE | 0.91 | 0.79 | 0.82 | 0.83 | 0.79 | 0.86 | ||
| 序列3 | MR/(%) | 34.29 | 41.82 | 1.31 | 68.32 | 17.52 | 5.42 | |
| RMSE | 2.06 | 2.41 | 2.18 | 1.87 | 2.31 | 2.11 | ||
| 注:“-”表示RMSE结果值大于10,得到的匹配精度不可靠。 | ||||||||
3 结论与展望
大视角差影像序列之间由于存在仿射变换、遮挡、视角、纹理等差异,使得同名点匹配存在多解和误匹配现象,导致了最终识别的匹配点分布不均、稳健性低下等问题。本文提出了一种适用于大视角差影像稳健匹配的方法,该方法通过构建一种适用于大视角差影像旋转不变学习型特征提取和描述的CNN网络,设计了一种对低内点率有较强稳健性能的误匹配剔除算法,引进已经配对好的光照和拍摄角度都存在较大差异的训练数据,实现了在稳健匹配同名点对的同时大幅降低匹配开销成本。在HPatches标准数据集和5种典型实地场景进行了大视角差影像序列匹配,并与适用于大视角差影像匹配的具有代表性的6种匹配方法进行了性能对比,验证了提出方法在正确匹配点数、匹配点正确率、匹配点均方根误差和匹配时间开销方面的优势。
本文方法仅使用局部学习型特征和由粗到精的误匹配约束策略来探索大视角差影像不变特征匹配。然而,在视角差异巨大时,两幅图像不再满足单一的仿射变换,如果要获得具有很强特征表示能力的卷积神经网络模型,往往需要大量的训练数据,而深度学习特征识别和检测的准确性高度依赖于训练数据集的质量和多样性。因此,在进一步的研究中可以利用迁移学习的思想,找到一个在大型数据集上预训练的网络模型和一些接近目标数据集的标记数据,利用这些模型和数据构建模型,增加目标数据的标记,更好地实现大视角差小样本图像匹配和大倾角图像的亚像素级精确匹配,以更好地服务于实际工程应用。
| [1] |
李德仁, 肖雄武, 郭丙轩, 等. 倾斜影像自动空三及其在城市真三维模型重建中的应用[J]. 武汉大学学报(信息科学版), 2016, 41(6): 711-721. LI Deren, XIAO Xiongwu, GUO Bingxuan, et al. Oblique image based automatic aerotriangulation and its application in 3D city model reconstruction[J]. Geomatics and Information Science of Wuhan University, 2016, 41(6): 711-721. |
| [2] |
张永生, 张振超, 童晓冲, 等. 地理空间智能研究进展和面临的若干挑战[J]. 测绘学报, 2021, 50(9): 1137-1146. ZHANG Yongsheng, ZHANG Zhenchao, TONG Xiaochong, et al. Progress and challenges of geospatial artificial intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(9): 1137-1146. DOI:10.11947/j.AGCS.2021.20200420 |
| [3] |
张卡, 宿东, 王蓬勃, 等. 深度学习技术在影像密集匹配方面的进展与应用[J]. 科学技术与工程, 2020, 20(30): 12268-12278. ZHANG Ka, SU Dong, WANG Pengbo, et al. Progress and application of deep learning in image dense matching[J]. Science Technology and Engineering, 2020, 20(30): 12268-12278. DOI:10.3969/j.issn.1671-1815.2020.30.003 |
| [4] |
赵红蕊, 陆胜寒. 基于特征尺度分布与对极几何约束的高清影像快速密集匹配方法[J]. 测绘学报, 2018, 47(6): 790-798. ZHAO Hongrui, LU Shenghan. Dense high-definition image matching strategy based on scale distribution of feature and geometric constraint[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 790-798. DOI:10.11947/j.AGCS.2018.20170630 |
| [5] |
余美. 倾斜立体影像匹配若干问题研究[D]. 徐州: 中国矿业大学, 2018. YU Mei. Research on several issues of oblique stereo image matching[D]. Xuzhou: China University of Mining and Technology, 2018. |
| [6] |
YANG Huachao, ZHANG Shubi, WANG Yongbo. Robust and precise registration of oblique images based on scale-invariant feature transformation algorithm[J]. IEEE Geoscience and Remote Sensing Letters, 2012, 9(4): 783-787. DOI:10.1109/LGRS.2011.2181485 |
| [7] |
ZHANG Qiang, WANG Yabin, WANG Long. Registration of images with affine geometric distortion based on maximally stable extremal regions and phase congruency[J]. Image and Vision Computing, 2015, 36: 23-39. DOI:10.1016/j.imavis.2015.01.008 |
| [8] |
肖雄武, 郭丙轩, 李德仁, 等. 一种具有仿射不变性的倾斜影像快速匹配方法[J]. 测绘学报, 2015, 44(4): 414-421. XIAO Xiongwu, GUO Bingxuan, LI Deren, et al. A quick and affine invariance matching method for oblique images[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(4): 414-421. DOI:10.11947/j.AGCS.2015.20140048 |
| [9] |
肖雄武, 李德仁, 郭丙轩, 等. 一种具有视点不变性的倾斜影像快速匹配方法[J]. 武汉大学学报(信息科学版), 2016, 41(9): 1151-1159. XIAO Xiongwu, LI Deren, GUO Bingxuan, et al. A robust and rapid viewpoint-invariant matching method for oblique images[J]. Geomatics and Information Science of Wuhan University, 2016, 41(9): 1151-1159. |
| [10] |
姜三, 许志海, 张峰, 等. 面向无人机倾斜影像的高效SfM重建方案[J]. 武汉大学学报(信息科学版), 2019, 44(8): 1153-1161. JIANG San, XU Zhihai, ZHANG Feng, et al. Solution for efficient SfM reconstruction of oblique UAV images[J]. Geomatics and Information Science of Wuhan University, 2019, 44(8): 1153-1161. |
| [11] |
MOREL J M, YU Guoshen. ASIFT: a new framework for fully affine invariant image comparison[J]. SIAM Journal on Imaging Sciences, 2009, 2(2): 438-469. DOI:10.1137/080732730 |
| [12] |
FAN Dazhao, DONG Yang, ZHANG Yongsheng. Satellite image matching method based on deep convolutional neural network[J]. Journal of Geodesy and Geoinformation Science, 2019, 2(2): 90-100. |
| [13] |
ŽBONTAR J, LECUN Y. Computing the stereo matching cost with a convolutional neural network[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 1592-1599.
|
| [14] |
HAN Xufeng, LEUNG T, JIA Yangqing, et al. MatchNet: unifying feature and metric learning for patch-based matching[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 3279-3286.
|
| [15] |
MISHCHUK A, MISHKIN D, RADENOVIC F, et al. Working hard to know your neighbor's margins: local descriptor learning loss[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York, NY, USA: ACM, 2017: 4829-4840.
|
| [16] |
DETONE D, MALISIEWICZ T, RABINOVICH A. SuperPoint: self-supervised interest point detection and description[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, UT, USA: IEEE, 2018: 337-33712.
|
| [17] |
DUSMANU M, ROCCO I, PAJDLA T, et al. D2-net: a trainable CNN for joint description and detection of local features[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2020: 8084-8093.
|
| [18] |
REVAUD J, WEINZAEPFEL P, SOUZA C D, et al. R2D2: repeatable and reliable detector and descriptor[C]//Proceedings of 2019 IEEE Conference on Computer Vision and Pattern Recognition workshop. [S. l. ]: IEEE, 2019.
|
| [19] |
JIANG San, JIANG Wanshou, GUO Bingxuan, et al. Learned local features for structure from motion of UAV images: a comparative evaluation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 10583-10597. DOI:10.1109/JSTARS.2021.3119990 |
| [20] |
张传辉, 姚国标, 张力, 等. 多分支网络联合的倾斜影像仿射不变特征匹配[J]. 测绘学报, 2021, 50(5): 641-651. ZHANG Chuanhui, YAO Guobiao, ZHANG Li, et al. Affine invariant feature matching of oblique images based on multi-branch network[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(5): 641-651. DOI:10.11947/j.AGCS.2021.20200506 |
| [21] |
蓝朝桢, 卢万杰, 于君明, 等. 异源遥感影像特征匹配的深度学习算法[J]. 测绘学报, 2021, 50(2): 189-202. LAN Chaozhen, LU Wanjie, YU Junming, et al. Deep learning algorithm for feature matching of cross modality remote sensing images[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(2): 189-202. DOI:10.11947/j.AGCS.2021.20200048 |
| [22] |
SNAVELY N, SEITZ S M, SZELISKI R. Photo tourism: exploring photo collections in 3D[J]. ACM Transactions on Graphics, 2006, 25(3): 835-846. |
| [23] |
SINGH PARIHAR U, GUJARATHI A, MEHTA K, et al. RoRD: rotation-robust descriptors and orthographic views for local feature matching[C]//Proceedings of 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Prague, Czech Republic: IEEE, 2021: 1593-1600.
|
| [24] |
蓝朝桢, 阎晓东, 崔志祥, 等. 用于无人机自主绝对定位的实时特征匹配方法[J]. 测绘科学技术学报, 2020, 37(3): 264-268, 274. LAN Chaozhen, YAN Xiaodong, CUI Zhixiang, et al. Real-time feature matching method for the autonomous absolute location of UAV[J]. Journal of Geomatics Science and Technology, 2020, 37(3): 264-268, 274. |
| [25] |
LUO Zixin, ZHOU Lei, BAI Xuyang, et al. ASLFeat: learning local features of accurate shape and localization[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020: 6588-6597.
|
| [26] |
张永生, 于英, 薛武. 无人机地理影像直播技术[M]. 北京: 科学出版社, 2020. ZHANG Yongsheng, YU Ying, XUE Wu. UAV geographic image live broadcast technology[M]. Beijing: Science Press, 2020. |