



2. 中国地质大学(武汉)地质探测与评估教育部重点实验室, 湖北 武汉 430074;
3. 中国地质大学(武汉)地理与信息工程学院, 湖北 武汉 430078
2. Key Laboratory of Geological Survey and Evaluation of Ministry of Education, China University of Geosciences, Wuhan 430074, China;
3. School of Geography and Information Engineering, China University of Geosciences, Wuhan 430078, China
随着遥感技术的迅速发展,国内外遥感卫星的陆续发射,越来越多的高质量遥感数据资源用于生产研究中。如何自动提取高分辨率遥感图像中的关键信息,一直都是遥感图像处理中的一个重要研究方向。遥感图像语义分割是遥感智能解译中的重要一环,在地球观测、土地数据更新、农作物估产及变化检测等领域发挥着十分重要的作用。遥感影像语义分割,也称作地物分类,是对影像中每一个像素分配一个确定的地物类别[1]。传统的地物分类方法主要包括两方面内容,人工设计特征和分类算法,因此选择优良的表达特征及更加稳健的分类器是影响影像分类精度最重要的因素。但是借鉴大量先验知识的人工设计特征往往具有单一性,无法表征目标中复杂的高层语义信息,缺乏对不同数据的泛化能力,给地物分类精度带来很大影响。
近年来,随着深度学习和计算机硬件的迅速发展,卷积神经网络[2]因其局部连接、权值共享等特点,在图像数据处理上具有独特的优势。神经网络通过学习得到的深层次特征在表达方面超过了传统的人工经验设计特征,在图像分类、目标检测及语义分割等任务中取得了一系列突破,在地物识别精度和速度上均得到了明显的提升。端到端的学习范式将特征提取和分类算法等步骤整合到一个神经网络中,进一步降低了地物分类过程的复杂性。
对于语义分割,编码解码结构已经成为一种通用的方案。编码器通过特征提取和语义浓缩,得到低分辨率的高级语义特征;解码器进行上采样恢复输入尺寸和图像细节。文献[3]开创性地将全卷积网络(fully convolutional network,FCN)引入语义分割任务中,提出跳跃连接(skip connection),将粗糙的高层语义信息和精细的浅层边缘信息进行融合,弥补空间细节丢失,得到更加准确的分割结果。文献[4]采用FCN框架并对其改进,提高了遥感图像中小目标物体(建筑物、汽车等)的分割效果。文献[5]基于FCN的编解码结构,提出了更加复杂高效的分割模型U-Net,该模型采用对称的U形结构,分为收缩路径和扩张路径两部分,收缩路径对原始输入进行卷积和下采样,扩张路径结合上下文信息进行上采样并实现精确定位,相同分辨率部分通过跳跃连接进行特征融合,改善了物体边界语义细节的分类效果。在遥感语义分割中,U-Net及其变体得到了广泛应用[6-8]。文献[9]在U-Net的基础上,重新设计跳跃连接,相同分辨率的特征层之间进行密集连接,缩小了编码器和解码器的语义差距。U-Net也存在很多缺点,如未能充分融合不同阶段的信息;重复堆叠的卷积和池化使得空间细节丢失,很难对形变较大的小对象进行分类;缺乏适当的策略来利用全局上下文信息处理复杂场景。
注意力机制(attention mechanism,AM)[10]是对人类视觉方式的模拟,为网络分配更多的权重关注特征图中的有用信息。在语义分割框架的基础上,引入注意力机制,通过网络学习为特征图的不同空间位置或通道分配不同的权重,能够获取更具分辨性的特征表示。SE-Net(squeeze-and-excitation networks)[11]对通道维度进行挤压,获取通道级的全局特征,然后对全局特征进行激励操作,学习不同通道之间的依赖关系,提升网络的特征表达能力。文献[12]在SE-Net的基础上,增加对空间维特征的重新校准,并将通道维度和空间维度重校准结果进行融合。文献[13]在U-Net每个跳跃连接的末端,使用注意力门控机制(attention gates)学习一组注意力系数矩阵,与原始特征图相乘,强化了有效信息之间的传递,减少不重要空间点带来的负面影响。
空间金字塔池化[14]最初用于目标检测中,将不同大小的图像固定成指定长度的图像表示来适应不同尺度目标的识别。文献[15]对其进行改进,并引入到语义分割网络中,提出了金字塔池化(pyramid pooling module,PPM),通过不同步长的池化聚合不同大小区域的上下文信息达到获取全局上下文的目的。后来研究者将空洞卷积[16]、批标准化[17]引入空间金字塔池化中,提出了DeepLab系列[18-21]分割网络,并在自然影像数据集中取得了很好的效果。
相比于自然图像分割,遥感图像语义分割更具挑战性,造成分割困难的原因有:①多尺度目标,同一类别的物体在不同影像中尺度差异巨大;②背景复杂,与当前任务无关的土地覆盖类别过多;③不同类别目标在外观上相似,如植被稀少的林地与裸地、建筑屋顶与道路等。针对上述问题,本文从U-Net模型出发,采用多尺度跳跃连接(multi-scale skip connection,MSC)融合不同层次的特征,提升模型对不同尺度物体的学习能力;结合注意力机制对输入特征的通道和空间维进行重标定,抑制背景中无关类别与形状变化的干扰;引入金字塔池化构造全局先验信息,应对复杂场景下不同类别相似物体的分割,提出一种改进U-Net的遥感语义分割方法。与U-Net、U-Net++、Attention U-Net及DeepLab V3+等主流分割模型对比,在WHDLD和LandCover.ai数据集上取得了更好的分割性能。
1 理论背景与方法 1.1 网络整体结构本文以U-Net模型为基础,结合金字塔池化、多尺度跳跃连接与注意力模块,构建了一种语义分割模型,网络结构如图 1所示。编码器部分应用VGG16[22]网络作为模型的主干,用于提取特征,获得5个不同层次、不同尺度的特征图。在主干网络的末端进行金字塔池化,捕获区分力强且多尺度信息丰富的特征以应对复杂场景下相似物体的分割。最后附加一个注意力模块,学习不同空间位置和通道特征的重要程度,实现特征重标定。解码器部分通过上采样恢复图像尺寸,每一个层级的特征图,通过注意力模块进行依赖关系调整,抑制与当前分类无关的特征,提取特征图中关注对象的有用信息。对不同层次的特征,采用多尺度跳跃连接将深层特征和浅层特征进行融合。针对训练数据中的类别不平衡和小物体等问题,选择使用Focal Loss与Dice Loss结合的损失函数替代语义分割中常用的交叉熵损失函数,能够有效避免训练中的过拟合现象。

|
| 图 1 本文网络整体结构 Fig. 1 Overall network structure of our method |
1.2 多尺度跳跃连接
遥感影像地物信息复杂,不同地物之间尺度各异,多尺度物体的存在往往导致分割结果不准确。在U-Net结构中,如图 2(a),跳跃连接只是简单地将编码器和解码器分辨率相同的特征映射进行拼接融合,未能利用不同抽象层级之间的多尺度信息,对于全局多尺度问题建模具有挑战性。U-Net++是针对U-Net的改进,如图 2(b)所示,它在网络中嵌入不同深度的U形结构,同时设计了一种灵活的特征融合方案,在解码器子网部分,聚合不同语义尺度的特征。以解码器部分的X1, 3为例,除了接收编码器X1, 0中的信息,还会融合不同深度U形结构中特征X1, 1和X1, 2。试验证明,这种特征融合方式在恢复细粒度特征方面是有效的。但是网络参数的增加是巨大的,而且这种连接方式在网络上层结构中存在大量的信息冗余。

|
| 图 2 U-Net与U-Net++网络结构 Fig. 2 U-Net and U-Net++ network architecture |
本文对存在的特征融合方案进行简化,提出了一种简单的多尺度跳跃连接来捕获不同层级的多尺度信息。如图 1所示,以X2, 1为例,编码器中分辨率较低的X3, 0通过上采样增加分辨率,在经过1×1卷积整合信息的同时减少通道维度。对解码器X3, 2上采样,相同分辨率的特征X2, 0、X3, 0、X3, 2进行维度拼接,实现特征融合与复用。上采样的方式可选择转置卷积与双线性插值,本文为避免较大的参数量,选择插值的方法恢复图像尺寸。该特征融合方法将不同分辨率的特征进行融合,低分辨率的特征对于语义信息表征能力强,高分辨率的特征对于细粒度的几何细节信息表征能力强,不同层次特征进行融合有助于分割出遥感图像中不同尺度的物体。
1.3 金字塔池化深层网络中,感受野的大小表明了使用上下文信息的程度,全局上下文信息有助于复杂场景理解,局部信息又有利于细节部分的恢复。文献[15]提出了金字塔池化来扩大感受野,融合全局图像级特征与局部特征,增加正确分类的可能性。PPM的结构如图 3所示,将主干网络提取到的特征图传入金字塔池化中,在不同池化步长下,输出不同大小的特征图。图 3中红色特征图为输入特征经过步长为8的平均池化层得到的输出结果,包含了全局图像特征;其余特征图是输入特征分别经过步长为1、2、4的平均池化层得到的输出结果,包含了图像中不同大小区域的图像特征。为了保持全局特征的权重,首先在每一个金字塔层后使用1×1卷积,并将通道维数减至128;然后通过双线性插值上采样到输入特征图尺寸;最后将不同级别的特征图与输入特征图在通道上拼接,实现特征融合及全局上下文信息的捕获,并传入后面的卷积网络中。

|
| 图 3 金字塔池化模块 Fig. 3 Pyramid pooling module |
1.4 注意力模块
在卷积网络中,卷积计算是核心部分,通过卷积计算聚合局部感受野中的空间位置信息和通道信息,构建特征表达。堆叠池化和非线性激活函数,理论上可以获取全局感受野的图像描述。但文献[23]表明,CNN的实际感受野比理论上的感受野小得多。为了寻求更强大的特征表示方法,研究者们将学习机制集成到网络模型中,通过网络自适应地学习特征之间的相关性。特征之间的相关性可分为空间相关性和通道相关性。
通道注意力机制,对通道间的依赖关系进行建模,自适应地学习和调整不同通道的特征响应[11],其中最典型的代表是SE-Net。本文在SE-Net的基础上,对其网络结构进行扩展,增加对空间依赖关系建模,让模型学习每个空间像素点上的关系,注意力模块网络结构如图 4所示。该模块由两部分组成,左边是SE Block,实现通道特征重标定;右边是空间信息捕获模块(spatial attention block),为特征图中不同位置分配不同的权重。

|
| 图 4 注意力模块 Fig. 4 Attention module |
SE Block包括挤压、激励和加权3部分。挤压是对输入的特征图X1使用全局平均池化,在空间维度进行压缩,即将整张特征图压缩为1×1大小。激励是通过两个全连接层学习各特征通道之间的重要性,第1个全连接层通过缩放参数r来控制通道维数,降低计算量,使用ReLU激活函数增加非线性;第2个全连接层恢复通道数,使用Sigmoid激活函数将各通道权重限制在0~1之间。加权即将学习到的各通道权重与输入特征图进行点积。
空间信息获取模块与SE Block采用相同的思路,但是实现更加简单。通过一个1×1大小的卷积核对特征图X2通道维度进行压缩,使用Sigmoid激活函数将卷积权重归一化。最后实现加权操作,实现空间特征重标定。
1.5 Focal Loss与Dice Loss结合的损失函数在语义分割中,交叉熵损失函数(cross entropy,CE)是最常用的一种损失函数,但是当数据中存在严重的类别不平衡现象时,会导致模型偏向预测占比较大的类别,对占比较小的物体而言,很难学到其特征。为解决数据中存在的不平衡与小物体预测不准确等现象,本文采用一种结合Focal Loss与Dice Loss的损失函数作为语义分割试验的总损失。
语义分割中使用IoU作为评价指标,直接把分割评价指标作为损失值去监督网络,比起使用代理损失函数是一种更好的选择。Dice系数是一种集合相似度度量函数,用于计算两个样本集的相似度,是评估分割效果的一种常用指标。对于类别c,二分类Dice系数的定义如式(1)
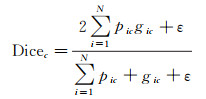 (1)
(1)
DiceLoss为预测值和真实值相似度的最小化,定义如式(2)
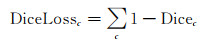 (2)
(2)
式中,pic、gic分别代表类别c的预测值和真实值, pic取值为[0, 1], gic取值为0或1;N为图像中的像素数;ε提供数值稳定性,防止分母为0。
Focal Loss[24]是在交叉熵损失基础上改进得到的,用于解决类别占比严重不均衡、难易样本不均衡问题。Focal Loss的定义为
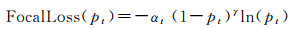 (3)
(3)
式中,pt为对应标签的预测概率;αt是样本数量平衡因子,调节不平衡样本占总损失的比重;聚焦参数γ用来控制难分样本对损失函数的贡献;当γ>1时,pt越大,权重(1-pt)γ就越小,从而降低了易分样本的损失贡献。Focal Loss通过调节αt和γ来控制类别不平衡和难易样本分类问题,使得模型在训练时更专注于占比较小和难分类的样本。
模型总损失可表示为
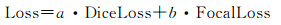 (4)
(4)
式中,a、b为超参数,调整Dice Loss和Focal Loss处于同一数量级。
2 试验与分析 2.1 试验数据本文所使用的遥感试验数据为WHDLD(Wuhan dense labeling dataset)[25-26]和LandCover.ai[27]数据集。WHDLD数据集包括4940张高分辨率遥感影像,包含6种土地覆盖类型,影像尺寸均被裁剪至256×256像素。由于数据集中图片较少,对遥感影像中的数据进行随机旋转、翻转、模糊及添加噪声点等操作将数据集扩充至24 700张影像,并按照3∶1∶1的比例随机划分为训练集、验证集和测试集。LandCover.ai数据集包括41幅大分辨率遥感影像,包含5种土地覆盖类型,试验中将数据集裁剪为512×512像素,得到10 674张影像,并采用在线数据增强的方式进行训练,增强方式包括垂直翻转、水平翻转、随机旋转90°及随机缩放,数据集基本信息见表 1。
| 数据集 | 尺寸大小 | 地物类别 | 划分比例 | 图像数量 | 空间分辨率/m |
| WHDLD | 256×256×3 | 建筑物、道路、人行道、植被、裸地、水域 | 3∶1∶1 | 24 700 | 2 |
| LandCover.ai | 512×512×3 | 建筑物、林地、道路、水域、背景 | 7∶1.5∶1.5 | 10 674 | 25/50 |
2.2 试验设置 2.2.1 损失函数
在语义分割任务中,常使用交叉熵损失函数来评价模型预测值和真实值之间的差异。本文试验数据集存在严重的数据不平衡现象,地物各类别占比见表 2。WHDLD数据集中植被和水域占比之和高达70%,而道路和裸地的占比不足5%;LandCover.ai数据集中背景占比超过50%,建筑与道路占比均不足2%。数据集中类别占比不均衡,以及多类别交叉熵损失函数偏向于预测占比较大类别的特性会导致分割效果不佳,并且在网络的训练过程中,出现过拟合现象。如图 5所示,在相同的网络模型和试验配置下,使用多类别交叉熵损失函数时,随着迭代的进行,验证集损失存在严重的上下震荡情况,且无法收敛。使用本文引入的Focal Loss与Dice Loss相结合的损失函数,仅使用ImageNet预训练权重,不进行深度调参的情况下,就能有效解决该问题(平衡参数αt=0.25,聚焦参数γ=2,超参数a、b均设置为0.5)。
| 数据集 | 裸地 | 建筑 | 人行道 | 植被 | 水域 | 道路 |
| WHDLD | 4.35 | 11.05 | 11.48 | 44.59 | 24.24 | 4.29 |
| LandCover.ai | 57.93 | 0.86 | 33.13 | 6.46 | 1.62 | - |

|
| 图 5 不同损失函数曲线 Fig. 5 Curves of different loss functions |
2.2.2 评价指标与试验平台
评价指标:为定量描述模型对遥感影像的分割效果,本文使用总体分类精度(overall accuracy,OA)、F1 score均值(mean F1)、平均交并比(mean intersection-over-union,mIoU)及Kappa系数作为评价分割性能的指标。对于给定的预测结果图和真实标签,IoU表示真实值和预测值两个集合的交集与并集之比,mIoU为所有类别IoU的均值,是试验中最主要的评价指标,计算公式为
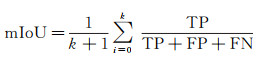 (5)
(5)
式中,(k+1)为所有类别数(包括背景);TP、FP、FN分别表示正确分类为正类的像素个数、错误分类为正类的像素个数、错误分类为负类的像素个数。
试验平台:硬件设备采用Intel(R)Xeon(R)CPU E5-2680 v3 @ 2.50 GHz处理器,搭载单张NVIDIA GeForce RTX 2080 Ti 11 GB显存的显卡。在软件环境方面,试验采用Windows10 64位操作系统,Python 3.6版本,模型搭建框架为Keras 2.3.1, TensorFlow 1.14.0。所有模型都使用Keras深度学习框架实现,优化器选择Adam,训练代数设置为60代,初始学习率设置为0.000 3,加载ImageNet预训练权重进行初始化。设置学习率衰减策略为:每训练6轮若验证集损失不下降,学习率减半。
2.3 试验结果 2.3.1 试验结果定量分析为了对比本文模型的有效性,将其与U-Net、Attention-UNet、U-Net++及DeepLab v3+进行对比,其中Attention-UNet和U-Net++的主干特征提取网络与本文方法一致,并使用VGG16在ImageNet数据集上的预训练模型,DeepLab v3+的主干特征提取网络为Xception[28]。
不同模型在WHDLD与LandCover.ai数据集上的定量评价结果见表 3。由表 3可以看出,本文方法在所有指标中均高于对比模型。在WHDLD数据集中,mIoU相比U-Net模型增加了7.37%,OA提高了1.38%,F1均值和Kappa系数分别提高了5.44%和4.22%。在LandCover.ai数据集中,mIoU和OA分别提升了2.33%和0.53%,F1均值和Kappa系数分别提高了1.87%和0.77%。U-Net的改进模型Attention U-Net和U-Net++在mIoU上也明显高于U-Net,说明了Attention U-Net中的注意力门控机制与U-Net++中重新设计的多尺度跳跃连接对于提升模型整体性能有一定的帮助。
| 方法 | WHDLD | LandCover.ai | |||||||
| OA | Kappa系数 | F1均值 | mIoU | OA | Kappa系数 | F1均值 | mIoU | ||
| U-Net | 86.09 | 80.28 | 79.03 | 66.91 | 93.60 | 88.42 | 87.89 | 79.71 | |
| Att U-Net | 86.34 | 80.80 | 79.98 | 68.12 | 93.97 | 89.08 | 88.64 | 80.77 | |
| U-Net++ | 86.95 | 81.65 | 81.16 | 69.61 | 93.74 | 88.45 | 89.41 | 81.43 | |
| DeepLab v3+ | 87.47 | 82.35 | 82.41 | 71.16 | 93.99 | 89.12 | 88.93 | 80.83 | |
| 本文方法 | 88.98 | 84.50 | 84.47 | 74.28 | 94.13 | 89.19 | 89.76 | 82.04 | |
水域、植被、背景等类别的分割效果远高于其他类别,造成这种现象的原因主要是数据集中像素占比较大,且水域和植被在遥感图像中呈现大块的聚集区域,相比于人行道和建筑物等细长及散乱分布的类型,识别更加容易(表 4、表 5)。在损失函数中,αt样本数量平衡因子和聚焦参数γ的设置,对占比较少的类别能够有效提高分割精度。在LandCover.ai数据集中,建筑物和道路的IoU提高了5%以上;在WHDLD数据集中,裸地、人行道和道路3种类别的IoU相比于U-Net提高了10%以上,并高于其他模型。
| 方法 | IoU | mIoU | |||||
| 裸地 | 建筑 | 人行道 | 道路 | 植被 | 水域 | ||
| U-Net | 51.27 | 61.34 | 47.91 | 64.08 | 82.31 | 94.53 | 66.91 |
| Att U-Net | 53.14 | 61.88 | 49.19 | 66.94 | 82.67 | 94.91 | 68.12 |
| U-Net++ | 55.83 | 63.33 | 51.28 | 69.27 | 82.91 | 95.05 | 69.61 |
| DeepLab v3+ | 59.17 | 63.92 | 54.64 | 72.05 | 82.77 | 94.44 | 71.16 |
| 本文方法 | 65.52 | 67.83 | 58.50 | 74.69 | 84.48 | 95.65 | 74.28 |
| 方法 | IoU | mIoU | ||||
| 建筑 | 林地 | 水域 | 道路 | 背景 | ||
| U-Net | 71.86 | 89.07 | 92.10 | 54.12 | 91.36 | 79.71 |
| Att U-Net | 73.07 | 89.43 | 93.03 | 56.58 | 91.77 | 80.77 |
| U-Net++ | 76.72 | 86.23 | 90.08 | 63.96 | 90.15 | 81.43 |
| DeepLab v3+ | 75.88 | 87.31 | 89.73 | 60.58 | 90.68 | 80.83 |
| 本文方法 | 77.19 | 87.11 | 91.35 | 63.86 | 90.71 | 82.04 |
表 6列出了各模型的参数量以及两个数据集上的每轮平均训练时长。可以看出,U-Net模型的参数量最少,轻量化水平最高,同时每轮平均训练时间也最短。Att U-Net在编码器和解码器每个阶段之间进行Attention Gate,不仅带来大量参数,矩阵乘法使运算量增加;U-Net++嵌入不同深度的U形结构不仅增加了参数量,也带来计算量的提升;本文提出的金字塔池化与注意力模块属于轻量型结构,参数量上不会带来巨大增加,但是模块中增加的卷积计算会带来时间上的消耗。
| 方法 | 训练时长/(Min) | 参数量/m | |
| WHDLD数据集 | LandCover.ai数据集 | ||
| U-Net | 5.9 | 16.5 | 24.8×106 |
| Att U-Net | 14.9 | 24.6 | 35.6×106 |
| U-Net++ | 13.3 | 26.8 | 34.1×106 |
| Deep Labv3+ | 8.2 | 13.7 | 41.3×106 |
| 本文方法 | 11.2 | 17.2 | 29.7×106 |
2.3.2 分割结果可视化
图 6为4种模型在两组数据测试集中选取的预测结果,整体来看,4种方法对于水体、植被(林地)和背景的分割效果较好,但是在其他类别的预测上存在较大差异。以WHDLD预测结果为例,从第1行圈中部分可以看出,对比的3种模型在裸地预测上存在漏分,U-Net和U-Net++将道路错分成人行道。这是由于植被稀少的林地和裸地、道路和人行道在外观上十分相似,本文方法中的金字塔池化能够提供额外的上下文信息,有利于复杂场景下的类别判定,提升相似物体的分割识别效果。第2行圈中的人行道分布散乱且细长,存在很大的挑战性,U-Net、U-Net++和DeepLab v3+都未能将其识别出来,说明本文使用的注意力模块能够关注细小物体,减少背景干扰,提高类别分割的稳健性。从第3行框中的建筑物和人行道来看,U-Net简单地将编码器和解码器分辨率相同的特征映射进行拼接融合,对细节部分处理效果很差,建筑物轮廓中存在明显的破碎斑块,U-Net++和DeepLab v3+在左下角不同建筑间存在粘连现象,右下角的建筑出现缺块,本文提出的多尺度跳跃连接能够有效缓解这种现象。LandCover.ai数据集的预测结果也能说明本文方法在正确分类和恢复物体细节方面优于其他对比方法。本文方法也存在不足:裸地、人行道的分割精度有待提高,存在错分和漏分;人行道和道路在外观和形态上极为相似,如何正确对其分类仍然存在很大的挑战性;建筑物轮廓部分细节恢复不足,存在破碎情况;弯曲细长的道路存在截断现象等。

|
| 图 6 测试集预测结果可视化 Fig. 6 Visualization of test set prediction results |
2.3.3 消融试验
为了分别验证金字塔池化、多尺度跳跃连接、注意力模块的有效性,本文在WHDLD数据集上设计了消融试验,见表 7,MSC表示多尺度跳跃连接,PPM表示金字塔池化,SE_R表示在解码器的4个阶段添加SE block,AM_B、AM_R表示在编码器末端和解码器的4个阶段添加本文提出的注意力模块。在原始U-Net的基础上增加本文设计的多尺度跳跃连接,在mIoU和Kappa系数上分别带来3.4%和2.45%的性能提升;添加金字塔池化分别带来1.09%和0.54%的提升;解码器不同阶段使用本文的注意力模块相比SE block在指标上分别增加0.45%和0.30%。经过上述分析可知,本文引入的各个模块都能在一定程度上带来分割性能的提升,使地物分类结果更加精细。
| MSC | PPM | SE_R | AM_B | AM_R | mIoU | Kappa系数 |
| 66.91 | 80.28 | |||||
| √ | 70.31 | 82.73 | ||||
| √ | √ | √ | 72.74 | 83.66 | ||
| √ | √ | √ | √ | 73.83 | 84.20 | |
| √ | √ | √ | √ | 74.28 | 84.50 |
3 结论与展望
针对U-Net在遥感语义分割中存在的空间细节丢失、复杂场景下分割精度低等问题,本文设计了一种多尺度跳跃连接方案来融合图像的高低维特征,恢复小目标的空间细节;引入注意力机制和金字塔池化模块专注于复杂场景下的地物分类,金字塔池化模块能够处理复杂场景下的不同尺度地物分割,注意力机制自适应地增强有用信息,实现通道和空间权重的重标定,进一步优化分割结果。在公开的语义分割数据集WHDLD和LandCover.ai上进行比较试验,证实了本文提出的改进模型在分割性能上显著优于U-Net模型,与其他分割模型相比也存在明显优势。
本文方法仍存在需要改进的地方,如模型对于外观与形状十分相似的人行道和道路存在错分现象,房屋建筑物的边界信息还需要进一步提升精度,后续研究将针对性地提高模型对此类地物的判别能力。另外,本文并未考虑主干网络对模型分割性能的影响,选择合适的主干特征提取网络(如残差网络、视觉transformer等),会给模型带来很大的提升。遥感语义分割任务需要大量人工标记数据,数据标注十分困难且成本高昂,标注样本的准确性也是影响语义分割的一个重要因素。结合半监督学习,利用有限的标注数据和大量的无标签数据训练语义分割模型也是一种有效的解决方案。
| [1] |
李道纪, 郭海涛, 卢俊, 等. 遥感影像地物分类多注意力融和U型网络法[J]. 测绘学报, 2020, 49(8): 1051-1064. LI Daoji, GUO Haitao, LU Jun, et al. A remote sensing image classfication procedure based on multilevel attention fusion U-Net[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(8): 1051-1064. DOI:10.11947/j.AGCS.2020.20190407 |
| [2] |
LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. DOI:10.1109/5.726791 |
| [3] |
SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651. DOI:10.1109/TPAMI.2016.2572683 |
| [4] |
KAMPFFMEYER M, SALBERG A B, JENSSEN R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Las Vegas: IEEE, 2016: 680-688.
|
| [5] |
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]//Proceedings of 2015 International Conference on Medical Image Computing and Computer-assisted Intervention. [S. l. ]: Springer, 2015.
|
| [6] |
PAN Xuran, YANG Fan, GAO Lianru, et al. Building extraction from high-resolution aerial imagery using a generative adversarial network with spatial and channel attention mechanisms[J]. Remote Sensing, 2019, 11(8): 917. DOI:10.3390/rs11080917 |
| [7] |
张玉鑫, 颜青松, 邓非. 高分辨率遥感影像建筑物提取多路径RSU网络法[J]. 测绘学报, 2022, 51(1): 135-144. ZAHNG Yuxin, YAN Qingsong, DENG Fei. Multi-path RSU network method for high-resolution remote sensing image building extraction[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(1): 135-144. DOI:10.11947/j.AGCS.2021.20200508 |
| [8] |
HE Hao, WANG Wang, WANG Wang, et al. A road extraction method for remote sensing image based on encoder-de-coder network[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(2): 415-426. |
| [9] |
ZHOU Z, SIDDIQUEE M M R, TAJBAKHSH N, et al. UNet: redesigning skip connections to exploit multiscale features in image segmentation[J]. IEEE Transactions on Medical Imaging, 2020, 39(6): 1856-1867. DOI:10.1109/TMI.2019.2959609 |
| [10] |
MNIH V, HEESS N, GRAVES A. Recurrent models of visual attention: advances in neural information processing systems[EB/OL]. [2022-11-20]. https://arxiv.org/abs/1406.6247.
|
| [11] |
HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141.
|
| [12] |
ROY A G, NAVAB N, WACHINGER C. Concurrent spatial and channel 'squeeze & excitation' in fully convolutional networks[C]//Proceedings of 2018 Medical Image Computing and Computer Assisted Intervention. Cham: Springer, 2018: 421-429.
|
| [13] |
OKTAY O, SCHLEMPER J, FOLGOC L L, et al. Attention U-net: learning where to look for the pancreas[EB/OL]. [2022-11-24]. https://arxiv.org/abs/1804.03999.
|
| [14] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. DOI:10.1109/TPAMI.2015.2389824 |
| [15] |
ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 6230-6239.
|
| [16] |
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. [2022-12-04]. https://arxiv.org/abs/1511.07122.
|
| [17] |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proceedings of the 32nd International Conference on International Conference on Machine Learning. New York: ACM, 2015: 448-456.
|
| [18] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[EB/OL]. [2023-01-04]. https://arxiv.org/abs/1412.7062.
|
| [19] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. DOI:10.1109/TPAMI.2017.2699184 |
| [20] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. [2023-03-24]. https://arxiv.org/abs/1706.05587.
|
| [21] |
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of 15th European Conference of Computer Vision. Munich: ACM, 2018: 833-851.
|
| [22] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014, 10(1409): 1556. |
| [23] |
ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs[C]//Proceedings of 2015 International Conference on Learning Representations. San Diego: ICLR, 2015.
|
| [24] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 2999-3007.
|
| [25] |
SHAO Zhenfeng, YANG Ke, ZHOU Weixun. Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset[J]. Remote Sensing, 2018, 10(6): 964. DOI:10.3390/rs10060964 |
| [26] |
SHAO Zhenfeng, ZHOU Weixun, DENG Xueqing, et al. Multilabel remote sensing image retrieval based on fully convolutional network[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 318-328. DOI:10.1109/JSTARS.2019.2961634 |
| [27] |
BOGUSZEWSKI A, BATORSKI D, ZIEMBA-JANKOWSKA N, et al. LandCover.ai: dataset for automatic mapping of buildings, woodlands and water from aerial imagery[J]. Journal of the Indian Society of Remote Sensing, 2018, 46: 2057-2068. DOI:10.1007/s12524-018-0871-2 |
| [28] |
CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 1800-1807.
|