



2. 山东浪潮新基建科技有限公司, 山东 济南 250101;
3. 中国地质大学(武汉)地质探测与评估教育部重点实验室, 湖北 武汉 430074;
4. 中国地质大学(武汉)计算机学院, 湖北 武汉 430074
2. Shandong Inspur New Infrastructure Technology Co., Ltd., Jinan 250101, China;
3. Key Laboratory of Geological Survey and Evaluation of Ministry of Education, China University of Geosciences, Wuhan 430074, China;
4. School of Computer Science, China University of Geosciences, Wuhan 430074, China
空间关系与人们的日常生活息息相关,如地理文本资料中对某一研究区的区域位置、城市功能区区域范围的叙述等,都离不开空间关系的描述。然而,大量的空间关系等信息是以非结构化的文本形式存在,计算机无法直接识别出空间关系。由于缺乏大规模的空间关系标注数据用于深度学习模型训练[1],而且现有的语料库包含的空间类别也较为单一,本文拟通过总结空间关系类别,对获取的空间文本数据进行标注,构建地理空间关系语料库。
空间关系抽取作为地理信息抽取的一部分,具有其独特性,从现有的地理空间文本中抽取空间关系存在空间关系一义多词、过于专业性的特点。例如“南部”暗含“南边”和“包含”方位和拓扑两种空间关系。同时,句中地理实体之间的空间关系通常不是唯一的,句中的某一个地理实体可能与多个地理实体之间存在联系,形成一对多的关系,例如:“肇庆市位于广东省中部偏西,深圳市之南,距广州市约130千米”。上述例句中,存在肇庆市、深圳市、广州市3个地理实体,同时也存在着多种空间关系,包括方位关系(偏西、之南)。距离关系(130千米)。这几种关系对应的地理实体是不同的,如例句中“肇庆市”就同时存在﹤肇庆市,中部偏西,广东省﹥、﹤肇庆市,南,深圳市﹥、﹤肇庆市,130千米,广州市﹥3条空间关系记录。一对多地理实体关系存在于自然语言中,描述形式多种多样,在句法、描述对象上存在较大差别,也存在某种特定的格式、句式。这种一个实体与其他不同实体之间存在着多种关系,或者一个实体与另一个实体之间存在多种关系即是重叠关系。如果能通过模型学习获取其中的规律,从地理文本或网络文本数据中识别和抽取蕴含的空间关系,并快速地将非结构化文本中有价值的空间信息进行结构化处理,对于自动化、智能化理解空间语义关系具有重要意义。
本文在构建地理空间关系语料库的基础上,改进CasRel模型,构建地理实体与空间关系联合抽取模型,提升对文本中地理实体与重叠空间关系联合抽取的效果。
1 相关工作关系抽取通常区分为管道式(pipeline)和联合(joint)抽取两种方式。管道式抽取是将实体识别和关系分类两个子任务分开训练,得到两个模型,利用两个模型分别提取实体和关系。管道式抽取方式存在明显的局限性:首先,管道式抽取方式会产生误差传播,影响抽取结果。其次,两个子任务的有用信息不能被充分利用,忽略了实体识别和关系分类之间的内在联系与相互依赖[2]。最后,实体之间可能不存在关系,这些实体传递至关系抽取子任务中时,会产生冗余信息。鉴于此,近年来开始关注实体与关系联合抽取研究。
联合抽取是对实体识别与关系抽取任务进行联合建模,利用实体和关系间的交互信息同时提取实体和关系,解决管道式提取存在的误差传播和子任务依赖问题。联合抽取方法可分为两类:基于共享参数的方法和基于联合解码的方法。文献[3—4]通过共享参数实现实体和关系的联合学习。文献[5]采用端到端的神经网络结构,使用基于LSTM的模型提取词序列和依赖树结构上实体之间的关系。基于共享参数的方法容易实现联合抽取,但是容易产生信息冗余,且难以解决关系重叠的问题。文献[6]提出了一种统一标记方案来实现联合解码,将关系提取的任务转化为不需要命名实体识别或关系抽取的端到端序列标记问题。文献[7]提出了一种带有双指针模块的端到端模型,可以联合抽取句子中的实体和关系。双指针模块与多个解码器相结合,以预测输入句子中实体的开始和结束位置。上述方法能够降低误差传播的影响,提高关系抽取的性能,但是不能解决关系重叠和实体嵌套的问题。
对于重叠关系,文献[8]首次提出了这个概念,并提出了具有复制机制的序列到序列(Seq2Seq)模型来解决该问题。文献[9]使用多头选择(multi-head selection)结构来解决实体关系联合抽取中的关系重叠问题,实体信息和关系信息被集成到一个统一的标记方案中,实体与关系可以作为一个整体学习训练,得到的模型可用于抽取关系三元组。文献[10]提出了一种关系元组表示方案,使得在每个时间步长提取一个单词的编码器-解码器模型仍然可以从句子中找到具有重叠实体的多个元组和具有多标记实体的元组。虽然联合抽取模型在解决误差传递和关系提取方面取得了良好的效果,但上述方法无法解决重叠关系三元组的提取问题。为了提取出实体之间的重叠关系,文献[11]针对实体对之间关系类别分布不均衡及多三元组重叠问题,提出一种级联二进制标注框架CasRel模型,将关系建模为一个从头实体映射到尾实体的函数,可以不受重叠三元组问题影响,同时提取出句子中的多个关系三元组。
针对包含空间信息文本的地理实体关系抽取,主要通过句法模式或机器学习算法实现。文献[12]将空间关系概括为“[前缀]+空间词汇+[后缀]”的描述模式,降低了空间关系查询请求难度,提高关系抽取效率。文献[13]提出了一种融合词法、句法的树形结构抽取模式,这种模式学习过程无须人工干预,通过融入句法依存关系消除匹配歧义,提高识别准确率。文献[14]通过对句法、语法规则的自然语言位置描述的特征,归纳出其结构化的表达形式,提出了一种规则化文本的自然语言位置估算方法。文献[15]提出一种融合语义文法的地理实体空间关系抽取方法,可以从非结构化文本中提取多个地理实体之间的空间位置关系。文献[16]分析互联网新闻非结构化文本中时间信息的描述特点,并构建时间词汇词典,结合触发词汇和规则模型实现时间信息抽取。文献[17]利用序列对比方法构建空间关系相似度矩阵,泛化得到空间关系描述的句法模式,克服了人工构建关系词典和规则集适用情况受限的缺点。虽然基于句法模式的方法在一定程度上具有提高识别准确率等优点,但这种方法严重依赖关系词典和规则集,难以满足大规模地理实体关系抽取的需要。在大规模地理空间关系语料数据的基础上,采用机器学习方法逐渐获得关注。文献[18—19]使用bootstrapping技术和无监督的方法,先通过统计词性、位置等计算词语权值,寻找描述地理实体关系的关键词,再通过机器学习方法抽取地理实体及关系。
基于机器学习的方法也存在不足,该方法十分依赖特征工程的准确性,需要花费大量人力和时间对语料文本特征做处理。目前,国内基于深度学习方法开展面向空间信息文本的地理实体关系抽取的研究较少,且精度不足。鉴于此,本文设计改进的CasRel模型并应用于地理实体与重叠空间关系的联合抽取,取得了良好的效果。
2 重叠空间关系联合抽取方法空间关系抽取是将非结构化文本中的地理实体以及实体间的空间关系以结构化的方式识别出来,其实现过程一般包括语料标注、数据预处理和模型训练。以下将着重阐述空间关系语料构建和基于ERNIE[20]预训练模型构建联合抽取模型,实现流程如图 1所示。

|
| 图 1 空间关系抽取流程 Fig. 1 Spatial relationship extraction process |
2.1 空间关系及地理空间关系语料库构建
地理空间信息是对地理实体位置及相互关系的描述。如图 2所示,通常地理空间信息有两种表述方式。图 2(a)中,电子地图通过数字化点线面符号的方式将地理实体信息位置表达出来,通过函数关系计算得到地理实体间的距离、拓扑、方位等关系。图 2(b)通过非结构化文本的方式描述地理实体及相互关系。相比于图形结构的表达方式,自然语言的表述方式存在空间关系描述形式多样且涵义模糊不清等问题。

|
| 图 2 空间信息表述形式 Fig. 2 Representation form of spatial information |
地理空间数据是空间信息的载体,主要用于描述地理实体的空间特征,其特征主要包括位置形状及空间关系[21],空间关系可以反映两个或多个地理实体之间的位置或属性之间的联系,主要包含方位关系、距离关系、拓扑关系等。其中,方位关系是指两个地物之间方向与位置的相对关系,用来描述边界并不相互接触的两个对象,通常包含东(E)、西(W)、南(S)、北(N)、东南(SE)、东北(NE)、西南(SW)、西北(NW)等方位。距离关系是指地理实体之间的远近距离,可以通过远、近等模糊描述或者通过具体数值来表达,比如“中国地质大学距离光谷广场比较近”和“中国地质大学距离光谷广场2千米”。本文参照文献[22—23]将定性的距离关系尺度分为“非常近”“近”“中等”“远”和“非常远”。拓扑关系是指两个或多个地理实体之间的关联程度,比如有包含、重叠、邻接、相交等。
针对空间信息领域的特殊性,本文在实体关系的基础上,将空间拓扑关系、空间方位关系和空间距离关系3大类加入空间关系抽取模型的关系库。根据空间关系的描述方式,首先通过人工归纳、总结出中国大百科全书[24]中13种空间关系类别。将预处理后的数据进行数据标注,标注示例如图 3所示。

|
| 图 3 空间关系语料标注示例 Fig. 3 Examples of spatial relational corpus annotation |
通过手工方式对语料数据进行空间信息标注,将其存储为JSON数据格式,建立地理空间关系语料库。标注是以自然语言的句子为单位,对句子中词语单元进行标注。标注完成后,按照与DuIE数据集相同的比例划分训练集、验证集和测试集,具体划分见表 1。
| 数据集 | 数量 | 关系数 | 句子中最大关系数N |
| 关系类型 | 13 | - | - |
| 训练集 | 75 625 | 158 841 | 6 |
| 验证集 | 10 609 | 20 078 | 4 |
| 测试集 | 20 136 | 41 064 | 4 |
2.2 模型结构
实体和关系联合提取任务的目标是识别句子中所有可能的三元组(主体s、关系r、客体o)。如图 4所示,本文根据式(1)的原理提出一种改进CasRel的联合抽取模型

|
| 图 4 本文提出的用于联合实体和关系提取任务的模型架构 Fig. 4 Architecture of the proposed model for joint entity and relation extraction task |
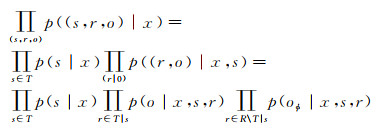 (1)
(1)
式中,s∈T代表重叠关系中的主体;T|s是T中以s为主体的三元组;(r, o)∈T|s是T|s中的(r, o)关系对;r是训练集中所有关系的集合;R\T|s代表除T中作为主体的s之外的所有关系;oϕ是“null”对象,表示除了包含在三元组T|s中的那些关系之外,所有其他关系在句子s中都没有对应的对象。
在文献[11]基础上通过增加BAB(BiLSTM+ self-attention mechanism+BiLSTM)模块提升重叠关系抽取效果。
本文经改进后的模型由两部分组成。
(1) 句子编码部分:ERNIE的Embedding层和双向Transformer层得到每一个字符的特征向量表示,作为主体识别和主客体关系识别模块的输入。
(2) 级联解码部分:首先通过主体识别模块抽取句子中的主体信息,其次通过主客体关系识别模块将与关系对应的客体关联。
(1) ERNIE词嵌入层。首先把训练中的句子利用ERNIE预训练模型进行切分得到相应的编码,通过式(2)获取每个词的输出向量hi用于后续模型结构的句子编码
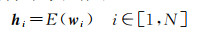 (2)
(2)
式中,N为句子长度;E是预训练模型ERNIE;wi是字在句子中的独热(one-hot)向量。
(2) BAB模块。BiLSTM抽取的特征可以兼顾上下文的联系,在分类中应用广泛。第一个BiLSTM层是将ERNIE输出的编码向量作为输入,结果由式(3)得到
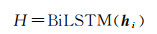 (3)
(3)
因为文本中的空间关系信息可能出现在句子中不同位置,BiLSTM虽可以获取句子的局部特征,但仍无法确定哪些词语对关系分类比较重要。而Self-Attention的特点[25]是可以不受词之间距离的限制计算依赖关系,能够学习得到句子的内部结构。所以增加Self-Attention层,利用式(4)对每个词分配不同的权重
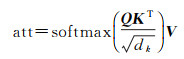 (4)
(4)
式中,Q、K和V 3个矩阵是将BiLSTM输出的结果H分别通过线性变换处理得到;att是通过softmax得到自注意力计算结果;dk表示矩阵K的维度。将式(2)与式(4)结果融合输入到第二个BiLSTM层提取局部信息。再通过式(5)将结果hN输入主体抽取部分
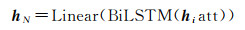 (5)
(5)
(3) 主体(subject)抽取[11]。主体抽取部分的主要作用是对BAB层获取到的词的隐层表示解码,构建两个二分类分类器,由式(6)和式(7)分别预测主体(subject)的开始(start)和结束(end)索引位置,对每一个词计算其作为start和end的一个概率,并根据设定的阈值,大于阈值则标记为1,否则标记为0。式(6)、式(7)如下
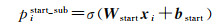 (6)
(6)
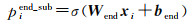 (7)
(7)
式中,xi为输入向量中第i个字词的编码表示,即xi= hN[i];W (·)为训练权值;b (·)为偏差;σ为sigmoid激活函数;pistart_sub是输入向量中第i个字词(token)为主体开始位置的概率;piend_sub是结束位置的概率。如果pistart_sub和piend_sub的概率超过了模型参数中设定的阈值,则pistart_sub、piend_sub的标记将被赋值1,否则赋值0。通过式(8)确定主体(subject)在x中的位置
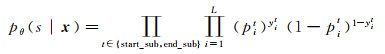 (8)
(8)
式中,L是句子的长度;yistart_sub是x中第i个标记的主体开始位置的标记,如果是则yistart_sub取1,否则取0;yiend_sub表示主体结束位置,取值同理;参数θ={ Wstart, bstart, Wend, bend}。
(4) 主体特征融合。为防止特征的表达能力下降,且在客体抽取时融入主体的特征信息。加之层归一化(layer normalization,LN)可以加速模型收敛,防止梯度爆炸。本文把主体特征(vsubk)与经过LSTM层的hN相加的结果X,采用LN方法进行更有效的融合,如式(9)所示
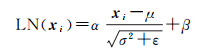 (9)
(9)
式中,xi为输入向量X中对应第i个位置的向量;μ为均值;σ为标准差;ε是接近0的正数;α与β是模型训练参数。
(5) 客体标注层[11]。客体标注由式(10)、式(11)建立每个关系的0/1标注
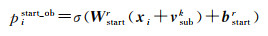 (10)
(10)
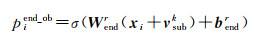 (11)
(11)
式中,pistart_ob和piend_ob表示将输入向量中的第i个字词分别识别为客体的开始和结束位置的概率;vsubk表示在主体抽取(sub)模块中检测到的第k个对象的编码表示向量。由式(12)在特定关系下从融合了主体特征信息的句子向量中抽取客体的概率
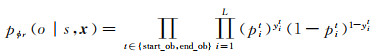 (12)
(12)
式中,L是句子的长度;yistart_ob是x中第i个标记的客体开始位置的标记,如果是则取1,否则为0;yiend_ob表示客体结束位置。参数θ={ Wstartr, bstartr, Wendr, bendr}。
(6) 损失函数。模型的整体损失值为主体抽取任务和关系条件下客体抽取任务两部分任务的损失值之和。损失函数如式(13)所示
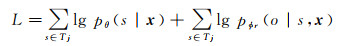 (13)
(13)
式中,Tj={(s, r, o)}是句子中的潜在三元组。
3 试验 3.1 试验环境及参数设置本文模型在硬件参数为RTX2080 Ti GPU,64 GB内存,系统软件为Windows 10,Python 3.9和Pytorch 1.8.0的服务器上训练。
ERNIE预训练模型的参数见表 2。
| 类别 | 数值 |
| Encoder layer | 12 |
| hidden | 768 |
| heads | 12 |
| parameters/M | 108 |
基于Pytorch深度学习框架构建基于预训练模型的地理实体-空间关系联合抽取模型,模型参数见表 3。
| 类别 | 数值 |
| learning_rate | 2×10-5 |
| epochs | 5 |
| batch_size | 32 |
| Dropout | 0.1 |
| Thresholds | 0.6 |
对于重叠关系提取,本文在PyTorch中实现的预训练ERNIE模型基础上改进了CasRel模型,并采用其默认的超参数设置。训练过程使用AdamW优化器优化改进的模型。为了防止模型过度拟合,当验证集的性能在至少连续5个epoch内没有得到任何改善时,停止训练过程,并将此时趋于稳定的试验结果的参数作为最终模型参数。试验将输入句子中的最大字数设置为128,将初始阈值设置为0.5,以确定单词在训练阶段的开始和结束标记,表 3中所有超参数都是在验证集上确定的。
3.2 数据集和评估指标(1) 数据集。试验采用2019年百度信息抽取竞赛中开源的数据集DuIE[26]和本文创建的地理空间关系语料库评估改进的模型。其中DuIE数据集由50个关系组成,因为DuIE暂未提供测试集数据,试验将按照7∶1∶2将训练集拆分一部分作为测试集,划分后包括132 217个训练句子、21 626个验证句子和40 766个测试句子。创建的地理空间关系语料库包括75 624个训练句子、10 608个验证句子和20 136个测试句子。根据三元组的重叠类型,将句子分为3类:正常(Normal)、实体重叠(entity pair overlap, EPO)和单一实体重叠(single entity overlap, SEO)。其中Normal表示三元组之间没有重叠关系,EPO表示多个三元组之间实体对是相同的,SEO是指多个三元组之间只有某一个实体是相同的,本文将在后面详细的试验中讨论这个结果。
(2) 评价指标。使用精度(P),召回率(R),F1值作为评估指标,其中F1为主要的评价指标。计算方式为
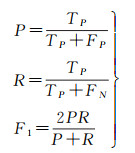 (14)
(14)
式中,TP表示正类判定为正类的个数;FP表示负类判定为正类的个数;FN表示正类判定为负类的个数。在本文试验中,预测正确与错误是针对三元组而言的,即当三元组中的主体s、关系r、客体o全部预测正确时,才认定该三元组的结果是正确的。
3.3 对比试验与结果分析 3.3.1 对比试验对于重叠关系提取任务,将改进模型与NovelTaggingBERT、NovelTaggingERNIE和CasRel模型进行比较。其中NovelTaggingBERT与NovelTaggingERNIE是多标签分类的序列标注模型,是基于NovelTagging在编码层分别使用BERT和ERNIR预训练模型设计多标签分类解决重叠关系抽取。CasRel是根据开源模型在PyTorch上复现。表 4是在DuIE数据集和本文构建的地理空间关系语料库上联合实体和关系抽取针对不同方法得到的试验结果。结果表明,改进的CasRel的模型优于上述其他方法,并在两个数据集上获得了较好的效果。与CasRel模型的比较表明本文模型可以显著地增强模型提取三元组的能力。对于DuIE数据集,本文的模型F1值比CasRel模型提高了4.81%,精确度和召回率分别提高3.96%和5.61%。对于构建的地理空间关系语料库,模型在F1值方面比CasRel方法提高了1.9%。因为DuIE数据集拥有更多的关系类别和更高比例的重叠三元组,所以在DuIE数据集上F1值要低于本文构建的地理空间关系语料库。
| 方法 | DuIE | 本文构建的数据集 | |||||
| P | R | F1 | P | R | F1 | ||
| NovelTaggingBERT | 75.62 | 64.93 | 69.87 | 89.47 | 79.28 | 84.07 | |
| NovelTaggingBERNIE | 74.73 | 66.02 | 70.11 | 89.86 | 80.87 | 85.13 | |
| CasRel | 78.97 | 75.37 | 77.13 | 88.42 | 84.67 | 86.5 | |
| 本文方法 | 82.93 | 80.98 | 81.94 | 86.77 | 90.23 | 88.47 | |
综上情况分析,本文方法可以提高召回率并保持较高的准确率,证明本文方法可以有效地处理重叠问题。
3.3.2 分析和讨论(1) 阈值(Thresholds)分析。本文还探讨了不同标记阈值的影响,其中为主体标记和客体标记设置了相同的阈值。图 5显示了本文方法和目前较好的CasRel方法在不同标签阈值设置下的结果。随着阈值的增加,所有模型的精度如图 5(a)逐渐增加,而召回率如图 5(b)逐渐降低,F1值如图 5(c)则是先升后降。本文方法的F1值无论在DuIE数据集还是构建的地理空间关系语料库上,每个阈值条件下均优于CasRel方法。总体结果表明,阈值会影响提取文本中的三元组数量。随着阈值的增加,提取的三元组数量也会增加,但整体的F1值会降低。当阈值分别为0.6或0.7时,模型的效果可以达到最优。总体来说,改进的模型对重叠关系抽取有很高的可信度。即使阈值为0.1,在DuIE上本文方法比CasRel的F1值也超过4%。

|
| 图 5 不同标签阈值结果 Fig. 5 Results on different tag thresholds |
(2) 消融试验。选取在本文构建的地理空间关系语料库上F1值最好的模型参数构建模型,检查实体关系联合抽取层中不同模块组件层的影响程度。首先去除自注意力层,其次去除第二个BiLSTM层,分别试验对F1值的影响。表 5结果表明,这两个模型组件层有助于本文模型更好地抽取三元组,且Self-Attention在改进的模型中发挥了更重要的作用。如果删除该层,F1的值下降了0.65%,表明融合关系表示和单词表示的重要性。此外,去除第二个BiLSTM层指标也有所降低,也表明了它的作用和有效性。
| 方法 | P | R | F1 |
| 本文方法 | 86.77 | 90.23 | 88.47 |
| -2ndBiLSTM | 87.89 | 88.46 | 88.17 |
| -SelfAttention | 86.11 | 89.61 | 87.82 |
| 注:-代表去除的模块组件层。 | |||
(3) 不同类型句子抽取结果分析。为了进一步分析改进CasRel模型提取重叠三元组的能力,本文对不同类型的句子进行了扩展试验,并将其性能与之前的工作进行了比较。首先,本文根据不同的重叠类型将DuIE中(因为地理空间关系语料库多为SEO形式,本部分结果不具有参考价值)的测试句子分为3类:Normal、重叠(entity pair overlap,EPO)和单实体重叠(single entity overlap,SEO),划分结果如表 6所示,然后测试每一类数据的评估效果。结果如图 6所示,从中可以看到,在不同的重叠类型下,本文模型优于目前较好的CasRel方法5%左右。
| 类别 | Train | Dev | Test |
| Normal | 61 986 | 10 003 | 18 798 |
| EPO | 9006 | 1435 | 2837 |
| SEO | 61 225 | 10 188 | 19 131 |
| 总计 | 132 217 | 21 626 | 40 766 |

|
| 图 6 模型抽取不同重叠类型三元组的F1值 Fig. 6 F1 score of extracting triples from sentences with different overlapping type |
试验表明,在SEO这类数据集下,本文方法F1达到86.37%,说明可以有效地提取文本中一对多的三元组。
(4) 不同三元组数量句子抽取结果。本文还验证了改进的模型从单个句子中提取多个三元组的能力。将DuIE测试句子分为5类,这表明它的三元组数是1、2、3、4、5,地理空间关系语料库分为4类。表 7显示了结果,与CasRel模型相比,可以看到本文模型在所有类别设置下都高于前者的效果,这表明本文方法可以有效地处理文本中关系复杂的情况。在DuIE上5个测试小组的F1值随着句子所包含的三元组数量的增加,模型性能也比CasRel表现稳定。
| 方法 | DuIE | 本文的数据集 | |||||||||
| N=1 | N=2 | N=3 | N=4 | N≥5 | N=1 | N=2 | N=3 | N≥4 | |||
| CasRel | 69.41 | 77.76 | 79.33 | 79.57 | 81.52 | 86.72 | 86.19 | 86.28 | 95.71 | ||
| 本文方法 | 74.76 | 84.07 | 82.6 | 84.3 | 84.76 | 85.34 | 87.9 | 90.87 | 96.31 | ||
(5) 实例分析。通过上述对模型精度结果的分析,本文模型在空间文本关系抽取上有较好的精度,整体表现较优。通过选取单个关系和多种空间关系类别组成的空间文本数据做测试,来进一步观察模型的抽取效果(表 8)。
| 序号 | 示例文本 | 抽取结果 |
| 1 | [咸宁市]位于[武汉市][南部]。 | (咸宁市) |
| 2 | [咸宁市]位于[湖北省][东南部],[武汉市]之[南]。 | (咸宁市,南,武汉市) (咸宁市,东南,湖北省) (咸宁市,在之内,湖北省) |
| 3 | [学一食堂]位于[研八楼][南边],和[超市][相邻]。 | (学一食堂,南,研八楼) (学一食堂,相邻,超市) |
| 4 | [地大]位于[洪山区][中部],距离[光谷广场]约[2千米]。 | (地大,在之内,洪山区) (地大,2千米,光谷广场) |
| 5 | [百泉]位于[辉县城][西北][2.5千米]。 | (百泉,西北,辉县) |
| 注:蓝色文字为地理实体;绿色文字为空间关系;红色文字为未识别文本。 | ||
对于Normal类别如示例1代表的文本,本文模型可以正确地识别出地理实体与地理实体之间的空间关系。示例2—5对应的是SEO关系类别文本,其中示例2代表抽取同一地理实体对应多个地理实体之间的方位关系,如正确抽取了咸宁市、湖北省、武汉市3个地理实体以及东南、南两个方位关系,且在结果中正确表达这两个三元组之间的关系。示例3代表抽取同一地理实体对应多个地理实体之间的方位和拓扑关系,如正确抽取了学一食堂、研八楼和超市3个地理实体,且正确抽出方位关系南和拓扑关系邻接。示例4代表抽取同一地理实体对应多个地理实体之间的方位和距离关系,如正确抽取了地大、洪山区、光谷广场3个地理实体,且正确抽取了方位关系中部和距离关系2千米。示例5是属于同一句中关系重叠问题,正确抽取结果为﹤百泉,西北,辉县城﹥、﹤百泉,2.5千米,辉县城﹥,然而在本文的模型中,无法正确抽取﹤百泉,2.5千米,辉县城﹥这一关系,针对这一情况,初步考虑因为训练语料中相关描述方式较少,需要在后续的研究中补充此类数据,来进一步提升模型的精度。
3.4 应用示例利用本文的空间关系抽取模型,从中国大百科全书、百度百科等数据集中抽取出地理实体与空间关系三元组,依照知识图谱的结构依次存入图数据库。图 7展示了部分地理实体空间关系图谱,地理空间关系知识图谱的构建不仅可以直观地显示实体之间的空间关系,在实际应用中还可据此从文本中获取地理实体的空间位置,为相关学者提供数据支撑,为传统的信息检索提供了思路。

|
| 图 7 地理空间知识图谱部分示例 Fig. 7 Examples of part of geospatial knowledge Graph |
4 总结
本文通过融合ERNIE预训练模型和BAB模块的方式改进CasRel联合抽取方法,模型在DuIE数据集和本文构建的地理空间关系语料库的F1值分别达到81.94%和88.47%。并通过大量试验结果表明,本文改进的CasRel模型可以提升联合抽取模型的评价指标,且可以有效提取关系重叠三元组。
该模型虽然取得了一定的效果,但是仍存在很多问题:如表 8中示例5同一句子关系重叠语境下,句子间隐含的空间实体关系的抽取问题;在训练语料中,部分关系和实体对出现的频率过少的问题;地理实体中包含着空间关系词如“南望山”中的“南”,“东湖”中的“东”,可能对模型的关系抽取上有所影响,这些都影响着本模型实体关系抽取的准确性,需要后续进一步研究。
| [1] |
张雪英, 张春菊, 朱少楠. 中文文本的地理空间关系标注[J]. 测绘学报, 2012, 41(3): 468-474. ZHANG Xueying, ZHANG Chunju, ZHU Shaonan. Annotation for geographical spatial relations in Chinese text[J]. Acta Geodaetica et Cartographica Sinica, 2012, 41(3): 468-474. |
| [2] |
BEKOULIS G, DELEU J, DEMEESTER T, et al. Joint entity recognition and relation extraction as a multi-head selection problem[J]. Expert Systems with Applications, 2018, 114: 34-45. DOI:10.1016/j.eswa.2018.07.032 |
| [3] |
MIWA M, SASAKI Y. Modeling joint entity and relation extraction with table representation[C]//Proceedings of 2014 Conference on Empirical Methods in Natural Language Processing. Doha: Association for Computational Linguistics, 2014.
|
| [4] |
KATIYAR A, CARDIE C. Going out on a limb: joint extraction of entity mentions and relations without dependency trees[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vancouver: Association for Computational Linguistics, 2017.
|
| [5] |
MIWA M, BANSAL M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Berlin: Association for Computational Linguistics, 2016.
|
| [6] |
ZHENG Suncong, WANG Feng, BAO Hongyun, et al. Joint extraction of entities and relations based on a novel tagging scheme[EB/OL]. [2022-12-30]. https://arxiv.org/abs/1706.05075.
|
| [7] |
BAI C, PAN L, LUO S, et al. Joint extraction of entities and relations by a novel end-to-end model with a double-pointer module[J]. Neurocomputing, 2020, 377: 325-333. DOI:10.1016/j.neucom.2019.09.097 |
| [8] |
ZENG Xiangrong, ZENG Daojian, HE Shizhu, et al. Extracting relational facts by an end-to-end neural model with copy mechanism[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne: Association for Computational Linguistics, 2018.
|
| [9] |
BEKOULIS G, DELEU J, DEMEESTER T, et al. Joint entity recognition and relation extraction as a multi-head selection problem[J]. Expert Systems with Applications, 2018, 114: 34-45. DOI:10.1016/j.eswa.2018.07.032 |
| [10] |
NAYAK T, NG H T. Effective modeling of encoder-decoder architecture for joint entity and relation extraction[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 8528-8535. DOI:10.1609/aaai.v34i05.6374 |
| [11] |
WEI Zhepei, SU Jianlin, WANG Yue, et al. A novel cascade binary tagging framework for relational triple extraction[EB/OL]. [2022-12-30]. https://arxiv.org/abs/1909.03227.
|
| [12] |
张雪英, 闾国年. 自然语言空间关系及其在GIS中的应用研究[J]. 地球信息科学, 2007, 9(6): 77-81. ZHANG Xueying, LV Guonian. Natural-language spatial relations and their applications in GIS[J]. Geo-Information Science, 2007, 9(6): 77-81. |
| [13] |
袁烨城, 刘海江, 裴韬, 等. 基于语义知识的空间关系识别研究[J]. 地球信息科学学报, 2014, 16(5): 681-690. YUAN Yecheng, LIU Haijiang, PEI Tao, et al. Spatial relation extraction from Chinese characterized documents based on semantic knowledge[J]. Journal of Geo-Information Science, 2014, 16(5): 681-690. |
| [14] |
陈功, 李霖, 邢小雨, 等. 一种规则化自然语言位置估算方法[J]. 测绘地理信息, 2015, 40(3): 39-42. CHEN Gong, LI Lin, XING Xiaoyu, et al. A method of rule-based natural language position estimation[J]. Journal of Geomatics, 2015, 40(3): 39-42. |
| [15] |
周琦, 陆叶, 李婷玉, 等. 基于语义文法的地理实体位置关系的获取[J]. 计算机科学, 2016, 43(7): 208-216. ZHOU Qi, LU Ye, LI Tingyu, et al. Acquiring relationships between geographical entities based on semantic grammar[J]. Computer Science, 2016, 43(7): 208-216. |
| [16] |
张春菊, 张雪英, 王曙, 等. 中文文本的事件时空信息标注[J]. 中文信息学报, 2016, 30(3): 213-222. ZHANG Chunju, ZHANG Xueying, WANG Shu, et al. Annotation of spatial-temporal information of event in Chinese text[J]. Journal of Chinese Information Processing, 2016, 30(3): 213-222. |
| [17] |
ZHU Shaonan, ZHANG Xueying, ZHANG Chunju. Syntactic pattern recognition of geospatial relation description [C]//Proceedings of 2011 International Conference on Software Engineering and Multimedia Communication(SEMC 2011 Ⅴ1). Qingdao: Information Engineering Research Institute, 2011: 366-369.
|
| [18] |
余丽, 陆锋, 刘希亮. 开放式地理实体关系抽取的Bootstrapping方法[J]. 测绘学报, 2016, 45(5): 616-622. YU Li, LU Feng, LIU Xiliang. A Bootstrapping based approach for open geo-entity relation extraction[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(5): 616-622. |
| [19] |
相颖, 冯钧, 夏珮珮, 等. 基于Bootstrapping的水利空间关系词提取[J]. 计算机科学, 2020, 47(12): 131-138. XIANG Ying, FENG Jun, XIA Peipei, et al. Extraction of water conservancy spatial relationship words based on bootstrapping[J]. Computer Science, 2020, 47(12): 131-138. |
| [20] |
SUN Yu, WANG Shuohuan, LI Yukun, et al. ERNIE: enhanced representation through knowledge integration[EB/OL]. [2022-11-01]. https://arxiv.org/abs/1904.09223.
|
| [21] |
刘俊楠, 刘海砚, 陈晓慧, 等. 基于地理空间数据的知识图谱构建技术研究[J]. 中文信息学报, 2020, 34(11): 29-36. LIU Junnan, LIU Haiyan, CHEN Xiaohui, et al. Construction of knowledge graph based on geo-spatial data[J]. Journal of Chinese Information Processing, 2020, 34(11): 29-36. |
| [22] |
王东旭, 诸云强, 潘鹏, 等. 地理数据空间本体构建及其在数据检索中的应用[J]. 地球信息科学学报, 2016, 18(4): 443-452. WANG Dongxu, ZHU Yunqiang, PAN Peng, et al. Construction of geodata spatial ontology and its application in data retrieval[J]. Journal of Geo-Information Science, 2016, 18(4): 443-452. |
| [23] |
刘俊楠, 刘海砚, 陈晓慧, 等. 面向多源地理空间数据的知识图谱构建[J]. 地球信息科学学报, 2020, 22(7): 1476-1486. LIU Junnan, LIU Haiyan, CHEN Xiaohui, et al. The construction of knowledge graph towards multi-source geospatial data[J]. Journal of Geo-Information Science, 2020, 22(7): 1476-1486. |
| [24] |
中国大百科全书总编辑委员会. 中国大百科全书: 中国地理[M]. 北京: 中国大百科全书出版社, 1998. General Editorial Committee of Encyclopedia of China. Encyclopedia of China: geography of China[M]. Beijing: Encyclopedia of China Press, 1998. |
| [25] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: ACM Press, 2017: 6000-6010.
|
| [26] |
LI Shuangjie, HE Wei, SHI Yabing, et al. DuIE: a large-scale Chinese dataset for information extraction[M]//Natural Language Processing and Chinese Computing. Cham: Springer International Publishing, 2019: 791-800.
|