



2. 中山大学地理科学与规划学院, 广东 广州 510275;
3. 广东省城市安全智能监测与智慧城市规划企业重点实验室, 广东 广州 510290
2. School of Geography and Planning, Sun Yat-Sen University, Guangzhou 510275, China;
3. Guangdong Provincial Key Laboratory of Urban Security Intelligent Monitoring and Smart City Planning, Guangzhou 510290, China
遥感影像变化检测任务是利用覆盖同一地表不同时期的影像,结合相应特征和成像机理,分析该区域内地物位置、状态和特征的变化,识别多时相遥感影像之间的差异[1]。变化检测任务关键在于如何克服噪声干扰因素,检测出语义信息变化区域[2]。随着遥感空天观测技术的快速发展与成像传感器的改进与应用,大量拥有更高的空间分辨率和光谱分辨率的遥感影像可供使用[3],利用遥感影像进行地表覆盖变化检测是目前的主流方向[4]。
传统的变化检测方法根据研究对象可分为两大类:基于像素与基于对象的方法[5]。常见的方法包括主成分分析[6]、聚类算法[7]、变化向量分析[8]等。基于像素的变化检测方法实现较为简单,但它们的稳健性较差,并在处理过程中容易产生椒盐噪声,使用此方法往往难以达到理想的结果。基于对象的变化检测方法是将遥感影像按照一定的规则分割成不相交的同质对象,基于同质对象特征信息分析影像间的差异[9]。与基于像素的方法相比,基于对象的方法利用了遥感影像的空间上下文信息,但人工设计特征过程复杂且难度较大,在包含复杂的光谱和纹理特征的遥感影像中应用效果不理想。
随着深度学习模型在计算机视觉任务中的不断发展,深度学习模型也被应用于处理高分辨率遥感影像解译任务,例如场景分类[10]、语义分割[11]和变化检测[12]。与传统方法相比,深度学习不依赖先验知识,可以从输入图像中自动学习丰富的上下文特征和高级语义特征,高分辨率遥感影像变化检测领域也开始关注基于深度学习方法的研究[13]。常见的深度学习变化检测方法大致可分为后分类和直接分类。后分类[14]的方法一般分别先对双时相影像进行地物分类,然后通过比较分类结果得到差分结果。这种方法只有在变化标签和双时相语义标签都可用的情况下才可行,往往存在分类误差积累的缺点。直接分类的方法则通过双时相影像直接得到影像变化图,根据影像输入融合策略,常见的直接分类方法大致可分为早期融合和晚期融合。早期融合通常是以双时相影像的拼接或差分影像作为网络输入,网络结构与传统的语义分割网络结构类似[15]。晚期融合通常采用孪生网络[16]结构,由两个权重共享的特征提取网络组成,可以直接把双时相影像作为输入,采用孪生结构和权重共享策略使得网络参数更少,收敛速度更快。常见晚期融合孪生变化检测网络[17-19]的主体结构主要基于UNet[20]与UNet++[21],其中UNet采用编码器与解码器相同尺寸的单一支路跳跃连接方式,UNet++采用不同深度网络的编码器与解码器相同尺寸的密集跳跃连接方式。这些方法虽能一定程度上解决细节信息丢失问题,有效改善了网络检测效果,但局限于没有考虑从全尺度上进行特征融合,忽略了不同尺度特征图之间的相互作用,导致变化区域边界模糊,小目标丢失等问题。此外,缺少监督和细化的高级特征与较低级别特征融合方式容易导致信息冗余,不利于模型拟合,导致变化检测效果不佳。
基于以上分析,本文提出一种结合孪生网络的全尺度特征聚合高分辨率遥感影像变化检测网络(full-scale aggregation network,FSANet)。为了解决传统基于深度学习变化检测方法中单一尺度特征融合方式导致信息融合不充分的问题,本文利用全尺度特征融合方式加强各个尺度特征之间的联系,减少信息损失对模型性能的影响。具体而言,首先使用孪生网络提取影像对的多层特征;然后,利用全尺度特征融合结构(full-scale connection,FSC)聚合全尺度特征中的低层细节信息和高层次语义信息,同时使用特征细化模块(feature refinement module,FRM)将每一层的融合特征信息细化;最后,在模型训练阶段,使用多尺度监督(multiscale supervision,MS)方式优化网络输出。试验结果表明,与其他方法相比,FSANet在定量指标和可视化方面都表现出色,特别是在小目标和狭长目标的变化检测方面。
1 模型结构与方法 1.1 网络总体结构本文所提出的FSANet由编码器网络和解码器网络组成,是一个端到端的遥感影像变化检测网络,整体结构如图 1所示。编码器采用孪生结构,使用孪生网络提取输入的两期影像特征,在提取特征过程中保证了两期影像之间的独立性,权重共享可减少模型参数量,效果更好。编码器网络由5个残差模块组成,可产生5种不同尺寸的特征图,特征图的通道数分别为32、64、128、256、512。两期影像输入到编码器中,分别得到4层和5层特征,编码器结构类似FC-Siam-Conc[17],采用拼接方式融合两期影像特征。与编码器相对应,解码器网络有4个上采样层,为了更好地利用低级与高级语义特征,使用全尺度跳跃连接方式进行特征融合,目的是减少信息丢失,充分聚合各个尺度上的特征,提高变化检测精度。特征拼接后,使用卷积核大小为1×1卷积聚合全尺度特征信息,接着进行下一步的上采样操作。此外,由于网络聚合了多个尺度上的低级和高级特征,特征信息比较丰富但易导致冗余,使用特征细化模块进行特征细化,将细化的特征通过卷积核大小为3×3卷积得到该尺度的预测图。最后,将各个尺度的预测图上采样到与输入影像的标签相同的尺寸,利用多尺度监督策略对解码器各个阶段的预测图进行监督并计算损失值,网络的总体损失值为多阶段损失值的总和。

|
| 图 1 FSANet整体结构 Fig. 1 Overview of the proposed FSANet |
1.2 编码器残差模块
编码器的残差模块结构如图 2所示,首先将输入的特征通过一个卷积层(convolutional layer,Conv),然后是归一化层(batch normalization,BN),接着是一个修正线性单元层(rectified linear unit,ReLU)。然后,添加另一个Conv和BN层。最后,将通过将第二个BN层和第一个Conv层的输出相加得到输出,采用另一个ReLU层来选择性激活特征值,卷积层的卷积核大小均为3×3。使用残差连接结构与激活函数层,目的是使网络学习更快,避免了梯度消失等问题。

|
| 图 2 残差模块 Fig. 2 Residual module |
1.3 特征细化模块
进行多尺度特征融合时,由于不同尺度的特征存在不可忽略的语义差异,直接融合会带来大量的冗余信息,降低多尺度融合特征表达的能力。特征细化模块是结合注意力机制[22]思想,通过对融合特征在通道和空间维度上分配权重,用于筛选特征信息,过滤掉冗余和不相关的特征,达到特征细化的效果,有利于提取目标的有效特征。如图 3所示,H、W、C分别代表输入特征的高、宽与通道数,r代表通道维度的缩减系数。特征细化模块由两个分支组成:通道注意力分支和空间注意力分支。通道注意力分支首先对输入特征在空间维度上进行最大与平均池化以聚合全局信息,将这两种全局信息拼接后使用1×1卷积进行通道降维,接着通过ReLU层。空间注意力分支首先采用1×1卷积进行通道降维,得到特征的局部信息,通过ReLU层后与通道注意力分支的特征进行拼接,以此来获取全局信息,使得局部和全局信息得以融合。然后,通道与空间分支分别通过1×1卷积与7×7卷积,利用Sigmoid激活函数获得两个维度的注意力特征图。分别将输入特征与得到的通道、空间维度注意力特征图相乘得到通道、空间维度细化后的特征,同时将两个维度细化后的特征相加,融合两个维度的细化特征。最后使用1×1卷积与BN层进一步融合特征,采用残差连接结构连接细化前的特征,使其包含原有特征,最后采用ReLU层选择性激活融合特征,得到最终的特征。

|
| 图 3 特征细化模块 Fig. 3 Feature refinement module |
1.4 全尺度特征聚合模块
本文提出的FSANet采用全尺度跳跃连接结构,全尺度跳跃连接在传统网络的特征连接方式基础上进行改进,实现了编码器和解码器之间的互连及解码器网络之间的内部连接,可以在全尺度上捕获细粒度的细节和粗粒度的语义。以特征DAB3为例,如图 4所示,具体介绍全尺度跳跃连接结构。双时相影像经过孪生结构的编码器得到不同尺寸的特征,相较于特征DAB3的尺寸,双时相影像尺寸大的特征连接后经过最大值池化操作得到与特征DAB3的相同尺寸的特征,接着使用卷积核大小为1×1卷积将通道数减少。与特征DAB3相同尺寸的双时相影像特征连接后使用1×1卷积减少通道数,而尺寸较小的特征EB5与DAB4则采用先将通道数减少,再上采样的操作。将这5个处理好的特征拼接,使用卷积核大小为1×1卷积操作得到具有全尺度特征信息的特征,接着通过特征细化模块将融合特征进一步细化,防止信息冗余,得到最终的特征DAB3。解码器中其他尺寸的特征采用与DAB3相同的全尺度跳跃连接结构,这里使用卷积核大小为1×1卷积减少特征通道数,通道数变为原来通道数的1/4,目的是减少参数量,提升模型训练的效率。

|
| 图 4 全尺度特征聚合模块 Fig. 4 Full-scale feature aggregation module |
1.5 多尺度监督与损失函数
传统深度学习方法计算网络损失值时,一般使用最终的预测结果与标签之间计算损失,然后进行反向传播更新参数,本文结合深度监督[23]思想,在网络中间加入损失约束,优化模型训练。由于变化检测任务目的是寻找双时相影像中变化与未变的区域,是一个二分类问题,而影像中普遍存在样本不平衡问题,变化区域像素数通常少于未变化区域像素数,常采用混合损失的方法来缓解样本不平衡对精度的影响[18, 24]。本文采用包括二元交叉熵(BCE)损失与Dice损失的混合损失函数作为最终的损失函数,分别定义为
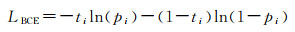 (1)
(1)
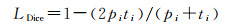 (2)
(2)
式中,ti代表像素i真实标签;pi表示像素i属于变化类的预测概率。混合损失函数公式为
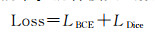 (3)
(3)
由于网络结构含有多个输出结果,最终的损失函数值是多个输出损失的总和,计算公式为
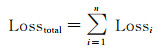 (4)
(4)
式中,Losstotal表示总损失值;Lossi表示输出i的损失值;n表示网络输出结果的个数。
2 数据集与试验流程 2.1 数据集简介本文采用LEVIR-CD[25]和SVCD[26]数据集来评估模型,部分样本如图 5所示。LEVIR-CD是一个建筑物变化数据集,包括637对多光谱(R、G、B)影像,分辨率为0.5 m,尺寸为1024×1024像素。该数据集被分为3组:训练集、验证集和测试集。受计算机GPU内存的限制,将影像滑动裁剪成像素大小为256×256像素且没有重叠的影像。按照原始的数据集划分规则,经过裁剪后的训练集、验证集、测试集分别包含7120、1024、2048对影像。

|
| 图 5 LEVIR-CD和SVCD数据集的双时相影像和标签 Fig. 5 Examples of bi-temporal images and labels from LEVIR-CD and SVCD datasets |
SVCD数据集中包括7对4725×2200像素的季节变化影像和4对1900×1000像素的多光谱(R、G、B)影像,分辨率为0.03~1 m,该数据集含有不同大小的物体和自然物体的季节变化等变化类型。文献[26]将影像数据进行处理,生成16 000对尺寸为256×256像素的影像,其中分别包括训练集10 000对,验证集3000对,测试集3000对影像,本文保持此划分规则用于模型训练。
2.2 试验流程本文试验采用PyTorch深度学习框架,在NVIDIA RTX6000 GPU,内置24 GB显存的环境下运行。考虑到有限的计算资源,批处理大小设置为8,试验采用AdamW作为优化器,对应的超参数β1、β2分别设置为0.9、0.999,学习速率初始设置为0.000 5,每5个迭代次数衰减0.8,总迭代次数为100。
2.3 评价指标本文使用精确度(precision,P)、召回率(recall,R)、F1分数(F1-score,F1)、交并比(intersection over union,IoU)、平均交并比(mean intersection over union,mIoU)、总体精度(overall accuracy,OA)作为衡量模型性能的评价指标。在评价指标中,精确度值越高,说明检测到的变化像素越准确,召回率越高表示模型发现错误变化像素的现象越少。F1分数同时考虑了分类模型的精确度和召回率,可以比较均衡地评价模型的精度。IoU用于测量真实和预测之间的相关度,mIoU是各类IoU的平均值,OA是预测结果的总体精度。这些指标的值越大,预测结果越好,范围是0~1。相关公式定义为
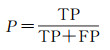 (5)
(5)
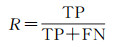 (6)
(6)
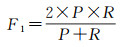 (7)
(7)
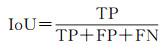 (8)
(8)
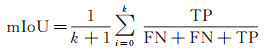 (9)
(9)
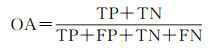 (10)
(10)
式中,TP(true positive)为真正类;FP(false positive)为假正类;FN(false negative)为假反类;TN(true negative)为真反类;k代表类别0、1,0代表未变化,1代表变化。
2.4 模型比较为了验证提出的FSANet有效性,本文采用8种变化检测方法与FSANet进行对比,包括FC-EF[17]、FC-Siam-Conc[17]、FC-Siam-Diff[17]、UNet++_MSOF[15]、STANet[25]、IFN[24]、SNUNet-CD[18]、BIT[27],网络训练、测试均在相同条件下进行。
(1) FC-EF、FC-Siam-Conc、FC-Siam-Diff:3个基础的全卷积变化检测网络,FC-EF使用早期融合策略,FC-Siam-Conc和FC-Siam-Diff使用后期融合策略;FC-Siam-Conc和FC-Siam-Diff的区别在于特征融合方法,一个使用拼接法,另一个使用差分法。
(2) UNet++_MSOF:一个基于UNet++的早期融合变化检测网络,同时采用多侧边输出融合策略,获得最终预测结果。
(3) STANet:通过引入自注意力机制,以获得更多的鉴别特征。
(4) IFN:在解码阶段应用注意力机制来细化特征,使用深度监督的方法来训练网络。
(5) SNUNet-CD:利用UNet++的密集连接结构来融合不同的深度网络特征,使用集成通道注意力来加强对不同语义层次特征的识别。
(6) BIT:一个基于Transformer的变化检测方法,使用孪生CNN作为主干网络提取特征,同时利用Transformer来建模上下文信息并增强特征表达。
3 试验结果与分析 3.1 试验结果定量比较在本文试验条件下,各个变化检测方法在LEVIR-CD数据集的精度结果见表 1。由表 1可以看出,FSANet取得良好的精度,除了准确率与召回率略低于其他方法外,其他指标均取得最优值。IFN与BIT的准确率高于FSANet,但两种方法的召回率较低,导致总体精度不高。FSANet的召回率略低于SNUNet-CD,但FSANet综合考虑了准确率与召回率,取得最佳的F1,说明FSANet更能适应变化检测任务。从总体来看,对比方法中,SNUNet-CD综合评价精度最好,FC-EF表现最差。相较于其他对比方法,IFN在指标准确率上取得次优值,但在其他指标上表现较差。基于Transformer的模型BIT,取得了最高的准确率,但总体精度不高。3个基础模型(FC-EF、FC-Siam-Conc、FC-Siam-Diff)中对比,FC-Siam-Conc表现最优。
| 方法 | P | R | F1 | IoU | mIoU | OA |
| FC-EF | 86.91 | 87.70 | 87.30 | 77.47 | 88.05 | 98.70 |
| FC-Siam-Conc | 90.68 | 88.38 | 89.52 | 81.02 | 89.96 | 98.95 |
| FC-Siam-Diff | 89.86 | 88.50 | 89.17 | 80.46 | 89.66 | 98.91 |
| UNet++_MSOF | 90.48 | 89.70 | 90.09 | 81.96 | 90.46 | 98.99 |
| STANet | 90.46 | 88.76 | 89.60 | 81.16 | 90.03 | 98.95 |
| IFN | 91.27 | 88.12 | 89.66 | 81.23 | 90.17 | 98.97 |
| SNUNet-CD | 90.16 | 90.77 | 90.46 | 82.58 | 90.78 | 99.02 |
| BIT | 92.09 | 88.07 | 90.03 | 81.87 | 90.42 | 99.00 |
| FSANet | 90.89 | 90.42 | 90.65 | 82.91 | 90.96 | 99.05 |
| 注:加粗字体表示每列最优值;下划线表示每列次优值。 | ||||||
各个变化检测方法在SVCD数据集的精度结果见表 2。由表 2可以看出,FSANet在各个精度评价指标均达到最优值,说明在SVCD数据集中,FSANet相较于其他变化检测方法,更能适应变化检测任务。其他对比方法中,SNUNet-CD凭借UNet++密集连接结构取得仅次于FSANet的效果,效果优于同样使用UNet++结构的UNet++_MSOF,主要原因是SNUNet-CD采用了孪生结构,同时应用注意力机制对特征进行有效的筛选。FC-EF、FC-Siam-conc和FC-Siam-diff 3个基础模型中,晚期融合网络明显优于早期融合网络,晚期融合网络中,对特征进行差分的效果比拼接效果好。
| 方法 | P | R | F1 | IoU | mIoU | OA |
| FC-EF | 86.13 | 74.12 | 79.67 | 66.22 | 80.54 | 95.33 |
| FC-Siam-Conc | 89.37 | 81.25 | 85.12 | 74.09 | 85.10 | 96.49 |
| FC-Siam-Diff | 92.79 | 85.75 | 89.13 | 80.39 | 88.75 | 97.42 |
| UNet++_MSOF | 94.76 | 87.05 | 90.74 | 83.05 | 90.30 | 97.81 |
| STANet | 93.57 | 87.51 | 90.44 | 82.55 | 89.99 | 97.72 |
| IFN | 95.19 | 90.04 | 92.54 | 86.12 | 92.05 | 98.21 |
| SNUNet-CD | 97.53 | 90.70 | 93.99 | 88.67 | 93.53 | 98.57 |
| BIT | 96.56 | 89.88 | 93.10 | 87.09 | 92.62 | 98.36 |
| FSANet | 97.68 | 92.93 | 95.25 | 90.93 | 94.82 | 98.86 |
| 注:加粗字体表示每列最优值;下划线表示每列次优值。 | ||||||
总之,从两个数据集的试验结果来看,FSANet均取得最佳的效果。相较于其他采用UNet或UNet++结构的方法,FSANet通过采用全尺度特征连接结构,加强了不同尺度特征之间的联系,缓解了信息损失对精度的影响。另外,结合注意力机制和多尺度监督思想,可有效缓解信息冗余,加快模型训练,比同样采用此类策略的方法精度高。两个数据集的提取难度不同,LEVIR-CD是建筑物变化数据集,提取较为简单,而SVCD则包含多种变化类型,提取难度较大。而从FSANet在两个数据集的表现来看,FSANet在SVCD的表现比LEVIR-CD更能显示出竞争力,说明FSANet可适应不同场景下的变化检测,在复杂场景下同样展现出较好的检测效果。
3.2 可视化结果与分析为了更加形象地表示各个方法的检测效果,将2个数据集中的检测结果进行可视化,如图 6、图 7所示,包括4个场景。图 6展示的是建筑物变化场景,从可视化结果中可以看出FSANet提取的房屋边界更加清晰,漏提取的区域较少。其他模型出现的漏提取的现象比较严重,如图 6中第2个场景,均未能完整地将建筑物轮廓提取出来,而FSANet可以较为完整地将建筑物轮廓提取出来。图 7展示了2个SVCD数据集的测试区域,包含了多种典型地物变化。通过视觉比较,本文提出的FSANet在SVCD数据集上实现了最佳的变化检测性能,由图 7可以看出更精确的边界轮廓,漏检和误检的现象较少。FSANet能够清晰地检测出小物体的变化,比如场景1中汽车变化的检测,其他方法对小物体变化的漏检误检现象比较严重,比如FC-EF、FC-Siam-Conc、FC-Siam-Diff未检测出汽车的变化,而其他模型不同程度上也出现了漏检误检现象。此外,FSANet对变化区域的边界细节信息提取地更加精细。由第2个场景中可以看出,FSANet对狭长地物的变化具有更好的检测性能,能够保持道路的连续性和精确的边界细节,FC-EF、FC-Siam-Conc、STANet、IFN未能完整的检测道路的变化,其他的对比模型检测的边界细节比较粗糙。由以上分析可以看出,FSANet在两个数据集上取得最佳的视觉效果,总体上可以准确地预测出遥感影像变化的区域,对小物体和地物边界细节的检测更加精准,对地物变化信息的检测出现误检和漏检的现象较少,总体上检测的结果与真实标签相近。

|
| 图 6 不同方法在LEVIR-CD测试集的可视化结果 Fig. 6 Visualization results of different methods on the LEVIR-CD dataset test set |

|
| 图 7 不同方法在SVCD测试集的可视化结果 Fig. 7 Visualization results of different methods on the SVCD dataset test set |
3.3 消融试验
为了更好地探究各个模块对FSANet方法的影响,本文进行了相关消融试验,将删除FSC、FRM、MS模块的网络作为基线网络(Baseline),对比基线网络与去除相关模块后的网络精度,其中Baseline与FSANet_noFSC未采用全尺度连接结构,而是采用UNet跳跃连接结构,消融试验在SVCD数据集进行,试验结果见表 3。由表 3可以看到,FSANet_noFSC、FSANet_noFRM、FSANet_noMS的精度均低于FSANet,表明本文使用的FSC、FRM、MS模块均可以有效提高FSANet的性能。在所有方法中,未添加3种模块的模型(Baseline)的精度最低,表明添加3种模块可提高模型精度,而3种消融模型中,FSANet_noFSC精度最低,这表明FSC模块是改进模型的关键模块,该结构充分整合了不同尺度上的信息,可有效提高变化检测的效果。FSANet_noMS未使用多尺度监督策略,仅在网络末端输出一个结果,试验结果显示,FSANet_noMS在各项评价指标中均取得次优值,其中F1/IoU比FSANet少0.43%/0.86%,mIoU/OA比FSANet少0.44%/0.07%,说明添加MS模块在一定程度上可以提升模型的性能。
| 方法 | P | R | F1 | IoU | mIoU | OA |
| Baseline | 95.87 | 90.78 | 93.26 | 87.36 | 92.71 | 98.29 |
| FSANet_noFSC | 97.02 | 91.66 | 94.26 | 89.15 | 93.80 | 98.62 |
| FSANet_noFRM | 97.27 | 92.11 | 94.62 | 89.79 | 94.17 | 98.71 |
| FSANet_noMS | 97.41 | 92.37 | 94.82 | 90.07 | 94.38 | 98.79 |
| FSANet | 97.69 | 92.93 | 95.25 | 90.93 | 94.82 | 98.86 |
| 注:加粗字体表示每列最优值;下划线表示每列次优值;“_no”代表去除此模块。 | ||||||
FRM模块根据注意力机制原理搭建,通过通道和空间维度两个维度产生注意力特征图,然后两种注意力特征图在与原输入特征进行相乘进行自适应特征细化,生成最后的特征。为了分析FRM模块对网络的影响,本文可视化了使用FRM模块前后网络的提取结果,同时将Sigmoid操作之前的特征热力图可视化,在特征热力图中,红色代表较高的像素值,说明该区域响应效果较强,蓝色代表较低的像素值,说明该区域响应较弱,可视化结果如图 8所示。由图 8可以看出,在加入FRM模块后,网络可以更好地关注变化区域,并抑制未变区域的影响。如图 8(f)、(g)所示,在加入FRM模块后,网络在变化区域有强烈的响应,而其他区域的响应不明显,说明FRM模块可以增强相关区域的特征表达,使网络更加关注影像中变化的区域,提高变化检测精度。

|
| 图 8 FRM模块的效果可视化 Fig. 8 Visualization of the effects of the FRM module |
3.4 复杂度分析
为了更加全面地评估提出的变化检测方法,本文将模型的输入图像的尺寸设置为256×256×3,统计出模型的参数量(parameters,Params)、计算量(floating-point operations,FLOPs)与推理时间(inference time,Infer-time),进行模型的复杂度分析,其中参数量的单位为106(M),计算量的单位为109(G),推理时间的单位为毫秒(ms)。图 9展示了不同方法的综合性能,F1是SVCD数据集上的精度,由图 9看出,通过对比不同方法,所提出的FSANet获得了最高的F1和相对较低的参数量和计算量,同时推理时间花费较少。结构简单的3个基础模型(FC-EF、FC-Siam-Conc和FC-Siam-Diff)具有较低的参数量和计算量,推理时间指标上也有显著优势。然而,由于它们的特征提取能力较弱,此类方法的精度较差。BIT的参数量和计算量较低,但由于此方法缺乏对低级细节特征的融合,虽结构比较轻便,但精度较低。与FSANet精度接近的方法是SNUNet-CD,SNUNet-CD采用UNet++的结构,结构比较复杂,而FSANet采用全尺度特征连接结构,弥补了UNet++在多尺度特征融合方面的缺陷,同时在解码器阶段主要采用1×1卷积,进一步降低了模型复杂度。表 4列出了相关指标的具体值。综合以上分析,说明了FSANet在复杂度和准确性之间有更好的平衡。

|
| 图 9 模型复杂度对比 Fig. 9 Comparison of the model complexity |
| 方法 | Params/M | FLOPs/G | Infer-time/ms | LEVIR-CD-F1/(%) | SVCD-F1/(%) |
| FC-EF | 1.35 | 1.78 | 11.72 | 87.30 | 79.67 |
| FC-Siam-Conc | 1.54 | 2.66 | 13.53 | 89.52 | 85.12 |
| FC-Siam-Diff | 1.35 | 2.36 | 13.43 | 89.17 | 89.13 |
| UNet++_MSOF | 9.16 | 17.36 | 17.94 | 90.09 | 90.74 |
| STANet | 12.21 | 6.35 | 37.47 | 89.60 | 90.44 |
| IFN | 35.99 | 41.18 | 29.49 | 89.66 | 92.54 |
| SNUNet-CD | 12.03 | 27.44 | 24.44 | 90.46 | 93.99 |
| BIT | 3.01 | 4.24 | 20.45 | 90.03 | 93.10 |
| FSANet | 5.98 | 11.68 | 21.76 | 90.65 | 95.25 |
| 注:加粗字体表示每列最优值;下划线表示每列次优值。 | |||||
4 总结
本文根据深度神经网络的特点,结合特征聚合与注意力机制等思想,提出了一种端到端的遥感影像变化检测方法FSANet。使用孪生结构提取双时相影像特征,采用全尺度特征聚合结构融合多个尺度上的特征,利用注意力机制将特征进一步细化,同时结合多尺度监督优化模型训练,使模型适应不同尺寸区域变化的检测。在两个公开的数据集上的试验结果表明,相较于其他模型,FSANet取得了最高的F1和IoU分数,分别达到90.65%、82.91%,95.56%、91.50%。同时,本文方法可以更精确地检测变化区域边缘细节信息,对小区域和狭长区域也能保持良好的检测性能,模型精度和复杂度有着较好的平衡。
本文方法也有局限性,由于是一种全监督变化检测模型,只能在数据标签充足的情况下适用,未能解决标签不足的问题,未来可以向半监督学习或弱监督学习领域进行研究。此外,本文方法只适用于两期影像之间的变化检测,缺乏对多期影像进行时序分析。未来的工作会考虑将时序数据与时序方法融合,解决多期遥感影像变化检测时序分析问题。
| [1] |
SINGH A. Review article digital change detection techniques using remotely-sensed data[J]. International Journal of Remote Sensing, 1989, 10(6): 989-1003. DOI:10.1080/01431168908903939 |
| [2] |
眭海刚, 冯文卿, 李文卓, 等. 多时相遥感影像变化检测方法综述[J]. 武汉大学学报(信息科学版), 2018, 43(12): 1885-1898. SUI Haigang, FENG Wenqing, LI Wenzhuo, et al. Review of change detection methods for multi-temporal remote sensing imagery[J]. Geomatics and Information Science of Wuhan University, 2018, 43(12): 1885-1898. |
| [3] |
龚健雅, 许越, 胡翔云, 等. 遥感影像智能解译样本库现状与研究[J]. 测绘学报, 2021, 50(8): 1013-1022. GONG Jianya, XU Yue, HU Xiangyun, et al. Status analysis and research of sample database for intelligent interpretation of remote sensing image[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8): 1013-1022. DOI:10.11947/j.AGCS.2021.20210085 |
| [4] |
张祖勋, 姜慧伟, 庞世燕, 等. 多时相遥感影像的变化检测研究现状与展望[J]. 测绘学报, 2022, 51(7): 1091-1107. ZHANG Zuxun, JIANG Huiwei, PANG Shiyan, et al. Review and prospect in change detection of multi-temporal remote sensing images[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7): 1091-1107. DOI:10.11947/j.AGCS.2022.20220070 |
| [5] |
HUSSAIN M, CHEN D, CHENG A, et al. Change detection from remotely sensed images: from pixel-based to object-based approaches[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2013, 80: 91-106. DOI:10.1016/j.isprsjprs.2013.03.006 |
| [6] |
RICHARDS J A. Thematic mapping from multitemporal image data using the principal components transformation[J]. Remote Sensing of Environment, 1984, 16(1): 35-46. DOI:10.1016/0034-4257(84)90025-7 |
| [7] |
LIU Junfu, CHEN Keming, XU Guangluan, et al. Convolutional neural network-based transfer learning for optical aerial images change detection[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 17(1): 127-131. DOI:10.1109/LGRS.2019.2916601 |
| [8] |
LIU S, BRUZZONE L, BOVOLO F, et al. Sequential spectral change vector analysis for iteratively discovering and detecting multiple changes in hyperspectral images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(8): 4363-4378. DOI:10.1109/TGRS.2015.2396686 |
| [9] |
CHEN G, HAY G J, CARVALHO L M T, et al. Object-based change detection[J]. International Journal of Remote Sensing, 2012, 33(14): 4434-4457. DOI:10.1080/01431161.2011.648285 |
| [10] |
CHEN Jie, HUANG Haozhe, PENG Jian, et al. Contextual information-preserved architecture learning for remote-sensing scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-14. |
| [11] |
WANG L, LI R, ZHANG C, et al. UNetFormer: a UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 196-214. DOI:10.1016/j.isprsjprs.2022.06.008 |
| [12] |
ZHU Q, GUO X, DENG W, et al. Land-use/Land-cover change detection based on a siamese global learning framework for high spatial resolution remote sensing imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 184: 63-78. DOI:10.1016/j.isprsjprs.2021.12.005 |
| [13] |
SHAFIQUE A, CAO Guo, KHAN Z, et al. Deep learning-based change detection in remote sensing images: a review[J]. Remote Sensing, 2022, 14(4): 871. DOI:10.3390/rs14040871 |
| [14] |
JI Shunping, SHEN Yanyun, LU Meng, et al. Building instance change detection from large-scale aerial images using convolutional neural networks and simulated samples[J]. Remote Sensing, 2019, 11(11): 1343. DOI:10.3390/rs11111343 |
| [15] |
PENG Daifeng, ZHANG Yongjun, GUAN Haiyan. End-to-end change detection for high resolution satellite images using improved UNet++[J]. Remote Sensing, 2019, 11(11): 1382. DOI:10.3390/rs11111382 |
| [16] |
BROMLEY J, BENTZ J W, BOTTOU L, et al. Signature verification using a "siamese" time delay neural network[J]. International Journal of Pattern Recognition and Artificial Intelligence, 1993, 7(4): 669-688. DOI:10.1142/S0218001493000339 |
| [17] |
CAYE D R, LE S B, BOULCH A. Fully convolutional siamese networks for change detection[C]//Proceedings of the 25 th IEEE International Conference on Image Processing (ICIP). Athens: IEEE, 2018: 4063-4067.
|
| [18] |
FANG Sheng, LI Kaiyu, SHAO Jinyuan, et al. SNUNet-CD: a densely connected siamese network for change detection of VHR images[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 1-5. |
| [19] |
CHEN P, ZHANG B, HONG D, et al. FCCDN: feature constraint network for VHR image change detection[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 187: 101-119. DOI:10.1016/j.isprsjprs.2022.02.021 |
| [20] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of the 18 th Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234-241.
|
| [21] |
ZHOU Zongwei, SIDDIQUEE M M R, TAJBAKHSH N, et al. UNet: redesigning skip connections to exploit multiscale features in image segmentation[J]. IEEE Transactions on Medical Imaging, 2020, 39(6): 1856-1867. DOI:10.1109/TMI.2019.2959609 |
| [22] |
GUO Menghao, XU Tianxing, LIU Jiangjiang, et al. Attention mechanisms in computer vision: a survey[J]. Computational Visual Media, 2022, 8(3): 331-368. |
| [23] |
LEE C Y, XIE S, GALLAGHER P, et al. Deeply-supervised nets[C]//Proceedings of the 8 th International Conference on Artificial Intelligence and Statistics. San Diego: PMLR, 2015: 562-570.
|
| [24] |
ZHANG C, YUE P, TAPETE D, et al. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 166: 183-200. DOI:10.1016/j.isprsjprs.2020.06.003 |
| [25] |
CHEN Hao, SHI Zhenwei. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection[J]. Remote Sensing, 2020, 12(10): 1662. |
| [26] |
LEBEDEV M A, VIZILTER Y V, VYGOLOV O V, et al. Change detection in remote sensing images using conditional adversarial networks[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2018, XLII-2: 565-571. |
| [27] |
CHEN Hao, QI Zipeng, SHI Zhenwei. Remote sensing image change detection with transformers[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-14. |