



2. 北京吉威空间信息股份有限公司, 北京 100040
2. Beijing Geoway Spatial Information Co., Ltd., Beijing 100040, China
使用卫星影像生成高质量的大场景数字表面模型(DSM)是摄影测量与遥感的基本任务之一,核心在于对影像进行准确的立体匹配以获取高精度的视差图,其关键是寻找左右核线影像上同名点的像素对应关系[1]。立体匹配一般分为4个步骤[2]:匹配代价计算、代价聚合、视差计算和视差优化。传统算法可分为局部匹配、全局匹配和半全局匹配(semi-global matching, SGM)3类[3],其中半全局匹配在近景、航空、卫星等多种影像的立体匹配中得到了广泛的应用[4-7]。然而,传统算法在各个阶段都或多或少地采用了经验性的方法[8],例如,按照给定的相似性测度计算匹配代价,通过对匹配点邻域内的所有匹配代价加权求和执行代价聚合,根据“赢家通吃(winner takes all, WTA)”的规则计算视差,采用后处理如噪声剔除、子像素增强等技术优化视差。手工设计的策略使得传统方法易受弱(无)纹理、遮挡及视差不连续的影响,对光照、噪声等外界环境也比较敏感,这些缺点使其在匹配大场景复杂的卫星影像时容易产生大量误匹配和无效值。
最近的研究表明,深度学习技术,尤其是卷积神经网络(convolutional neural network, CNN),在立体匹配中表现出超越传统方法的性能[9]。最初的基于深度学习的立体匹配方法通过使用CNN代替4个标准步骤中的某些部分来改善匹配效果,如MC-CNN(matching cost)[10]使用CNN自适应地学习匹配代价,SGM-Net[11]在传统SGM中引入CNN学习惩罚项以解决惩罚参数难以调整的问题,GDN(global disparity network)[12]使用CNN学习匹配代价并在视差优化阶段对视差图做异常值探测。文献[13]提出了首个端到端的立体匹配神经网络DispNet,随后,大量端到端的模型被提出并逐渐成为主流的深度学习方法。这类方法将4个标准步骤整合在同一个网络模型中,通常的做法是,首先使用一个共享参数的孪生网络(siamese network)[14]提取左右核线影像的深度特征并构建一个匹配代价量(cost volume);然后使用卷积网络对其进行聚合,接着将聚合后的代价量转换成概率分布,通过对所有可能的视差值加权求和得到初步的视差图;最后通过一定的优化策略得到最终的视差。例如,GC-Net(geometry and context)[15]采用共享权重的2D卷积层提取影像下采样后的特征图,再将左右特征图在视差方向上错位拼接得到代价体,利用3D卷积层对其进行聚合并上采样至输入影像大小,最后使用soft argmin将匹配代价转换成视差图。PSM-Net(pyramidal stereo matching)[16]引入SPP(spatial pyramid pooling)模块[17]用于提取不同尺度的特征来构建代价体,在代价聚合阶段采用堆叠漏斗结构的3D卷积层,并计算3个阶段的视差图,在测试时以最后一个视差图作为优化后的视差。由于完全避免了手工的特征设计,端到端的方法取得了更高的匹配精度,在多个开源数据集上,如KITTI[18-19]、Middlebury[20]和SceneFlow[13, 21]等,处于领先地位。
在摄影测量与遥感领域,也有一些深度学习模型被用于遥感影像的立体匹配。例如,文献[22]在PSM-Net的基础上改进得到Bidir-EPNet(bidirectional pyramid stereo matching network),提升了对遮挡区域视差的估计;文献[23]提出了HMSM-Net(hierarchical multi-scale matching network),通过构建多尺度的代价量来学习不同尺度地物的匹配;文献[24]提出了一个多任务模型BGA-Net(bidirectional guided attention network),可同时对遥感影像进行立体匹配和语义分割。这些模型在公开数据集上取得了好于传统方法的结果,但是它们的性能仅在小尺寸遥感影像(如1024×1024)上得到了验证,很少有研究人员将深度学习模型用于大场景卫星遥感影像的视差图生成。尽管基于深度学习的立体匹配算法表现出良好的前景,但是现阶段将其应用于卫星立体影像的匹配中仍存在一些困难,原因主要是目前主流的立体匹配模型严重依赖训练数据,而基于卫星影像的立体匹配数据集较少;卫星影像幅宽大,覆盖范围广,在地形起伏大或有高层建筑物的地区视差很大,而一般深度学习模型每次只能匹配一小块影像,且能够预测的视差范围固定有限(如Bidir-EPNet设置的范围为[-64, 64]),这些限制了它们在大场景卫星立体影像处理中的实际应用能力。近年来,高分系列卫星的发射极大地提高了我国对地观测的能力,以高分七号为例,它搭载的两线阵立体相机可获取20 km幅宽、分辨率优于0.8 m的前后视全色立体影像,是立体测绘的重要数据来源。然而由于场景十分复杂,传统方法在高分七号影像立体匹配中表现不佳,因此如何将深度学习有效地应用于这类卫星影像是值得探索的。
针对上述问题,本文提出一种能够使深度学习模型适应大场景卫星影像立体匹配的策略,同时提出一套卫星影像立体匹配训练样本的制作方案,构建一个高分七号立体匹配数据集,并首次以高分七号卫星立体影像为试验对象,使用两个典型的立体匹配神经网络模型预测整景视差图并制作DSM,通过与传统方法的对比论证了本文方法的可行性和制作的数据集的应用价值。
1 立体匹配神经网络模型目前,大多数端到端的立体匹配神经网络模型都采用GC-Net[15]模式计算匹配代价和执行代价聚合,即生成大小为H×W×D×C的4维代价量,其中H、W为影像的高、宽,D为视差范围,C为特征通道数,再用3D卷积处理这个代价量。这种方式可以获得比较高的精度,然而由于代价量和3D卷积的维度较高,运算量较大。本文选取两个具有代表性的,可以实现快速立体匹配的轻量卷积神经网络模型,分别是Stereo-Net[25]和DSM-Net[26],用于高分七号影像的立体匹配。其中Stereo-Net是计算机视觉领域的经典模型,DSM-Net是专门针对遥感影像设计的模型。
1.1 Stereo-NetStereo-Net[25]是首个端到端的可以进行实时立体匹配的深度神经网络模型,其主要思想是构建一个低分辨率的代价量以减少运算量,对其进行聚合后计算一个低分辨率的视差图,然后利用原始影像逐步引导其恢复至原图分辨率,网络结构如图 1所示[25]。

首先连续使用K(K=3或4)个尺寸为5×5、步长为2的卷积操作从原始影像中提取特征并降低分辨率,再使用6个残差块(residual block)[27]和1个3×3卷积提取更深的特征,得到通道数为32的特征图。然后以左右特征图在视差方向上错位相减得到代价体,使用4个3×3×3的3D卷积执行代价聚合,再用1个3D卷积将聚合后的代价体的通道调整为1,得到形状为H/2K×W/2K×D/2K的代价体。最后,采用soft argmin[15]将代价体转化成大小为H/2K×W/2K的视差图。为了将低分辨率的视差图恢复至原始影像分辨率并重建下采样中丢失的部分细节信息,网络采用了分层优化的方法,每次将上一级的视差图上采样两倍,并将其与调整大小后的原始影像拼接,经过若干2D卷积和残差块,得到视差残差并与上一级视差相加得到当前层级的视差图,重复这样的操作直到获得与原始图像大小一致的视差图。训练时,同时学习左右视差图(缺少右图视差标签时也可以只学习左图视差),对每级视差图都计算损失,以它们的和作为总的训练损失。测试阶段,以左视的最后一级视差图作为最终的预测结果。
1.2 DSM-NetDSM-Net[26]是一个用于高分辨率卫星影像立体匹配的端到端模型,其主要思想是通过构建两个尺度的代价量来学习不同尺度地物的匹配,从而提高匹配的成功率,网络结构如图 2所示。

首先,使用由若干层2D卷积和残差块构成的特征提取器提取两个尺度(输入图像1/4和1/8分辨率)的深度特征;然后,采用与Stereo-Net相同的方式分别构建两个尺度的代价体。由于遥感影像的视差可能同时存在正负值,因此DSM-Net构建了从负视差到正视差范围的代价体。在代价聚合阶段,首先使用一个代价聚合模块处理低尺度的代价量并计算相应尺度的视差图,然后将聚合后的低尺度代价量上采样并与初始的高尺度代价量融合,经过另一个代价聚合模块后计算该尺度的视差图。为了降低网络的计算量,代价聚合模块被设计成编码器-解码器的结构,并且使用分解的3D卷积代替普通的3D卷积。在视差优化阶段,先将高尺度的视差图上采样至原始影像的1/2分辨率,并与从左核线影像提取出来的浅层特征拼接,然后采用与Stereo-Net相似的方式学习一个视差残差,相加得到优化后的视差。训练时,对3个视差图都计算损失值,以它们的加权和为最终损失。预测时,使用双线性插值将优化后的视差直接上采样输入影像分辨率作为最终的预测结果。
2 大幅宽影像匹配策略与数据集 2.1 分层动态匹配策略由于卫星影像往往具有很大的尺寸,无法直接使用深度学习模型对整幅核线影像进行匹配,因此需要分块处理,再将小块的视差图拼接成整体视差图。然而,卫星影像成像视角差异大,有些地区地形起伏大或者存在高层建筑,直接对立体像对进行一一对应分块可能导致得到的小像对上视差过大或者重叠度较低(如图 3绿色分块),加上网络模型本身能够回归的视差范围固定且有限,难以匹配成功。因此,需要将其中一个分块窗口做一定量的平移,使得到的分块核线影像有较大的重叠度,缩小像对的视差。

|
| 图 3 核线影像分块方法 Fig. 3 Blocking method for epipolar image |
整幅核线影像上不同区域的视差不一样,无法通过移动整幅左核线或右核线影像使所有区域视差都被调整到合适的范围。本文提出一种简单有效的分层动态匹配策略,采用局部动态调整核线影像切块位置的方式解决该问题。首先构建原始核线影像的金字塔影像(如分别缩小16、8、4、2倍),不同层级的金字塔核线影像上,视差也被缩小相应的倍数。对于最小的核线影像(金字塔顶端),由于视差较小,一一对应分块也可以获得高重叠度的核线影像块,采用这种方式分块预测小块视差图,最后拼接成最小核线影像的整幅视差图。从金字塔的次顶层开始,采用前一级的视差图作为参考,将前一级的视差图放大一倍到当前层级的大小,计算左核线影像块对应区域(图 3红色框区域)的视差的平均值,然后以该平均值为平移量将右核线影像上分块窗口平移,取平移后窗口的右核线影像块与左核线影像块匹配,如图 3所示,绿色框是按照一一对应关系获取的核线影像块,蓝色框是根据视差平均值平移后获取的右核线影像块,平移后的右核线影像块与左核线影像块的重叠度明显比平移前更大。
假设左核线影像分块区域范围为[i: i+h, j: j+w],平移量为a,则右核线影像分块区域为[i: i+h, j-a: j-a+w],核线块上的视差换算到整幅核线影像上为D=d+a(d表示分块核线影像对上匹配得到的视差)。为了使由小块视差图拼接成的整幅视差图不出现明显的接缝线,在对大核线影像分块时,以分块窗口的宽、高的一半为步长分别在水平和垂直方向上滑动切割窗口,每次取窗口的中间部分的视差值作为整幅视差图对应区域的视差。
2.2 数据集数据集是推动和影响深度学习模型发展和性能的关键因素之一。目前有不少基于街景影像、虚拟影像或者航空影像制作的数据集,如KITTI[18-19]、Middlebury[20]、SceneFlow[13, 21]、ISPRS[28]等。然而与卫星影像相比,它们在成像方式、交会视角、影像波段、覆盖范围等方面都有着显著的差异,基于这些数据集训练的模型难以直接迁移到卫星影像的处理中。现有公开的卫星影像立体匹配数据集较少,US3D(urban semantic 3D)[29]和SatStereo[30]各提供了一个基于WorldView卫星影像的立体匹配数据集。对于国产高分系列卫星,目前已知的仅有WHU-Stereo[31]提供了一个基于高分七号立体影像的数据集,但WHU-Stereo主要面向城市及其周边区域,所代表的地面覆盖类型有限。本文基于高分七号卫星影像制作了一个数据集,弥补了WHU-Stereo缺乏地形起伏大、视差大的样本的不足。
WHU-Stereo数据集的视差真值由机载LiDAR制作得到,然而点云的获取成本高,点云与影像之间的时间不一致容易给计算变化地物(如植物)的视差真值带来误差。本文提出了一个不依赖LiDAR点云的视差标签制作方案,如图 4所示。给定1景高分七号立体影像,首先使用商业软件生成整景核线影像和视差图,如果视差图质量满足要求,则对核线影像和视差图进行切片得到样本;如果不满足要求,则生成相应的DSM,并使用立体测图软件对其进行人工编辑,得到目视精度较高的DSM,再由DSM反算得到视差图,连同核线影像进行切片获取样本。一般情况下,对于山区等人工地物不多的影像,使用商业软件生成的视差图可以满足神经网络的训练;对于城区等,则需要适当的人工编辑。

|
| 图 4 高分七号立体匹配样本制作方案 Fig. 4 Production scheme of GF-7 stereo matching samples |
依照该方案,本文使用山东省崂山地区的高分七号影像,采用国产商业软件生成了若干样本(以山区为主,如图 5(a))。此外,本文收集了若干LiDAR点云(广东省梅州市)及成像时间与点云相近的该地区高分七号影像,采用与WHU-Stereo相同的方式生成了一批覆盖城市建筑物的样本(图 5(c))。

|
| 图 5 高分七号立体匹配样本示例(仅展示左核线影像和视差图) Fig. 5 Samples of GF-7 stereo matching dataset (only left epipolar images and disparity maps are displayed) |
3 试验与分析
整体的试验方案流程如图 6所示。试验中将WHU-Stereo[31]数据集与本文提供的数据集混合,使用Stereo-Net[25]和DSM-Net[26]公开的代码训练两个立体匹配神经网络模型,根据训练样本的视差分布及GPU显存的大小,将网络模型回归的视差范围设定为[-192, 128]。模型训练时,采用提前结束的措施,即当损失函数连续若干个训练回合下降不超过一定的阈值时就停止训练,这样可以一定程度上避免过拟合。本文制作的数据集、使用的代码及训练好的模型权重文件均已公布至https://github.com/Sheng029/GF-7_Stereo_Matching。测试的数据为3景高分七号前后视全色立体影像,它们均没有在训练样本中出现过,其部分信息见表 1,3景影像均有极大的幅宽。试验中,后视影像作为参考影像,前视影像作为目标影像。

|
| 图 6 试验方案流程 Fig. 6 Flowchart of experiment |
| 影像覆盖区域 | 获取时间 | 原始影像大小 | 核线影像大小 | |
| 后视 | 前视 | |||
| 北京市 | 2021年10月 | 35 864×40 001 | 31 268×31 001 | 35 072×39 936 |
| 广州市 | 2021年1月 | 35 863×40 004 | 31 267×30 997 | 34 816×39 936 |
| 中山市 | 2021年1月 | 35 863×40 004 | 31 267×30 997 | 34 816×39 936 |
3.1 匹配策略的有效性分析
为验证本文分层动态匹配策略在大幅宽卫星影像立体匹配中的有效性,设计了一组对比试验,即对同1景高分七号核线影像,分别使用一一对应分块匹配和分层动态匹配两种方式预测视差大图。以Stereo-Net和北京市影像为例,将原始核线影像分别缩小8、4、2倍构建金字塔,使用两种方法预测的结果如图 7所示。由北京市影像整景匹配结果(图 7第1行)可以看出,在地形较为平坦的地区,两种方法均可以预测出比较好的视差。然而在地形高差较大的山区(左下区域),一一对应分块获得的小块核线影像对重叠度较小、视差较大,超出了模型所能回归的范围,因此预测出来的视差有明显的错误。而采用分层动态匹配策略,可以根据上一级的视差动态调整本级右核线影像的分块位置,使得每次分块得到的核线影像块之间有较大的重叠度,进而将视差偏移到相对较小、模型能够回归的范围。该策略使得深度学习模型能够突破自身预测视差范围的限制,从而适用于视差范围较大的大幅宽卫星影像,由图 7中可以看出,一一对应分块预测出的视差没有超过预设的[-192, 128],而分层动态匹配策略能够预测的视差远大于预设范围。由于GF-7搭载的立体相机前后两个视角差异大,高层建筑物区域难以匹配,由图 7第2行可以看出,SGM几乎无法匹配高层建筑物,深度学习方法显著优于SGM。进一步对比两种匹配策略的结果,不难发现分层动态匹配的成功率高于一一对应分块匹配,进一步证明了本文提出的匹配策略的有效性。

|
| 图 7 两种策略视差预测结果对比 Fig. 7 Comparison of disparity maps predicted by two strategies |
3.2 视差图质量评价
为统计预测视差图的精度,利用SIFT算子提取核线影像上的同名像点,计算这些特征点的x视差作为视差真值,通过比较这些特征点的预测视差值与真值来评价精度。采用平均视差绝对误差(average endpoint error, EPE)和错误视差像素比例(D1)[26, 29]作为衡量指标,前者表示所有参与统计的视差误差的绝对值的平均数,后者表示视差错误的像素在所有参与统计的像素中占有的比例,两个指标均是越小代表视差精度越高,计算公式为
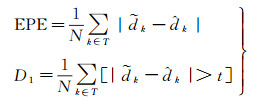 (1)
(1)
式中,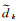
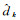
对于所有影像,以分层动态匹配的方式,分别使用Stereo-Net和DSM-Net对核线影像进行视差图预测,并将结果与传统SGM算法匹配的结果对比。表 2统计了这3种方法的定量精度比较,可以看出,深度学习方法的EPE整体在1个像素左右,稍差于SGM,而D1要优于SGM,说明深度学习方法预测的视差异常值要少于SGM算法。需要说明的是,SGM算法匹配的视差图中有很多无效值,因此SGM生成的视差图中参与统计的点数少于深度学习生成的视差图,如果考虑无效值,则SGM的EPE和D1都要差于深度学习方法。
| 影像 | 统计点数 | EPE/像素 | D1/(%) | |||||||
| SGM | 深度学习 | SGM | Stereo-Net | DSM-Net | SGM | Stereo-Net | DSM-Net | |||
| 北京市 | 13 157 | 14 083 | 0.853 | 1.052 | 1.012 | 3.952 | 3.536 | 3.721 | ||
| 广州市 | 42 284 | 44 676 | 0.815 | 0.923 | 0.834 | 3.55 | 3.02 | 3.021 | ||
| 中山市 | 48 377 | 51 449 | 0.819 | 0.941 | 0.887 | 3.303 | 2.869 | 3.122 | ||
图 8是3种方法生成的广州市影像的整景视差图及局部细节。可以看出,SGM生成的视差图存在大量的无效值(局部细节图中黑色空洞),而深度学习模型可以为每个像素都预测出有效的视差值。对于建筑物,深度学习模型可以更好地还原建筑物的整体轮廓,对建筑物的细部结构也保持得较好。对于平地,SGM视差图中存在较多的表现为“突刺”的噪声,平滑性明显不如深度学习方法。对比Stereo-Net和DSM-Net,前者在平坦地面的表现稍好于后者,而后者对建筑物的视差预测更有优势。总体而言,两个深度学习模型的匹配效果均超过了SGM算法。

|
| 图 8 3种方法生成的视差图对比 Fig. 8 Comparison of disparity maps generated by three methods |
3.3 DSM质量评价
获取视差图后,利用核线影像与原始影像之间的对应关系,逐像素地把通过视差计算得到的同名点推算至原始影像,再基于前方交会原理即可获取物方密集点云[32-33]。本文将Stereo-Net和DSM-Net生成的点云栅格化为1 m分辨率的DSM,并与用基于SGM算法的商业软件PCI Geomatica制作的DSM进行对比分析,图 9为3种方法生成的中山市影像整景DSM。需要说明的是,由于区域网平差中缺少实测地面控制点或高精度参考地形等数据,本文方法生成的DSM均为相对高程,因此只做定性评价。总体上看,几种DSM均能大致反映该地区的地表形态,两种深度学习方法的结果好于PCI,例如PCI在河流等水域生成的结果明显不如两个深度学习模型的结果。为进一步分析遮挡、视差不连续及弱纹理地区的匹配质量,选取建筑物和平坦地面两类具有代表性的地物进行详细比较。

|
| 图 9 3种方法制作的DSM对比 Fig. 9 Comparison of DSMs produced by three methods |
图 10为城区某区域3种方法的效果对比。可以看出,在建筑物分布密集的区域,PCI生成的DSM建筑物容易连成一片。在含有高层建筑物的区域,由于遮挡严重,这种现象尤为明显(如左上角部分),而两种深度学习方法对建筑物群的区分明显更好,其中DSM-Net对高层建筑物的匹配效果最好。此外,深度学习方法能够更好地保持建筑物的边缘信息。猜测可能是神经网络模型不仅能够有效学习像素之间的相关性,还可以充分利用上下文语意信息对不同的地物类型加以区分,并对遮挡部分的视差进行合理的推测。

|
| 图 10 3种方法生成的建筑物密集区域DSM对比 Fig. 10 Comparison of DSMs generated by three methods in a built-up area |
进一步评价建筑物的匹配质量,选取房屋的断面对3种方法生成的DSM进行比较。如图 11所示,沿着图中红色线段采集高程,可通过高程变化来反映DSM的垂直精度。从整体断面曲线可以看出,PCI将第3和第4个屋顶之间的狭小地面误匹配成了屋顶,而Stereo-Net和DSM-Net能正确地区分出所有屋顶及夹在其中的地面。由屋顶部分的曲线可以看出,PCI的DSM平滑性不佳,有较大的粗差,Stereo-Net和DSM-Net也存在同样的问题,但屋顶整体上还是更加平整。由屋顶和地面交界处的曲线可以看出,两种深度学习方法的DSM高程变化较为剧烈,更加符合这些地方高程不连续的特点。综合表明,深度学习方法在保持建筑物的整体轮廓、屋顶形态及处理视差不连续和遮挡等方面比基于SGM的传统方法更具优势。

|
| 图 11 3种方法获取的房屋断面高程变化曲线 Fig. 11 Elevation change curves of house section acquired from three methods |
弱纹理区域对于SGM算法是一个难点,为了验证深度学习方法在匹配卫星影像弱纹理区域是否更加有效,选取了3种方法在平坦地区的结果进行对比(图 12)。不难看出,PCI生成的DSM有明显的错误。采集左影像红色线段上的高程绘制成平地断面高程变化曲线,可以看出,Stereo-Net和DSM-Net反映出的高程变化较小,符合平地起伏不大的特点,而PCI的曲线存在一个显著的阶跃,说明SGM算法在匹配该区域时出现严重误匹配。深度学习模型能够更好地保持地表形态,对于弱纹理的处理也更加有效,推测可能的原因是深度学习方法可以自适应地学习匹配代价,对于弱纹理区的像素能够得到比传统方法定义的更合适的相似性测度。

|
| 图 12 3种方法生成的弱纹理平地DSM对比 Fig. 12 Comparison of DSMs in a texture-less plain ground generated by three methods |
3.4 本文数据集的作用分析
为验证本文制作的高分七号立体匹配数据集的应用价值,设计了一组消融试验:对于DSM-Net,仅使用WHU-Stereo[31]数据集训练(视差范围设置为[-128, 64],与文献[31]一致)和混合两个数据集训练(视差范围设置为[-192, 128]),结合分层动态匹配策略分别在广州市影像上进行立体匹配测试,结果如图 13所示。当模型仅用WHU-Stereo数据集训练时,对于地形起伏较大的山区错误匹配较多(视差图左边部分),而引入本文数据集后,效果有明显改善,原因在于本文数据集中含有较多视差范围较大的山区样本,弥补了WHU-Stereo缺乏这类样本的不足,使训练出来的模型具有更大的视差回归范围和更强的预测能力。

|
| 图 13 使用和不使用本文数据集训练的模型预测结果对比 Fig. 13 Comparison of predictions of models trained with and without the dataset in this paper |
4 结语
针对深度学习模型直接用于大场景卫星影像的立体匹配遇到的困难,本文提出了相应的解决方案。通过分层动态匹配策略,神经网络模型可以突破自身视差回归范围不足的限制,适用于视差跨度较大的大幅宽卫星影像;提出了一套制作卫星影像立体匹配样本的方案并制作了一个高分七号影像数据集,对现有的数据库是一个很好的补充。基于此,本文实现了结合深度学习技术的高分七号影像大场景DSM生成。在3个城市的高分七号影像上的试验表明,使用本文方法和数据,深度学习模型可以生成高质量的视差图,在遮挡、视差不连续和弱纹理等传统SGM算法难以匹配的区域,效果有显著的提升,基于深度学习方法生成的视差图制作的DSM,无论在高程精度还是典型地物的形态特征保留上,都优于传统方法。
| [1] |
季顺平, 罗冲, 刘瑾. 基于深度学习的立体影像密集匹配方法综述[J]. 武汉大学学报(信息科学版), 2021, 46(2): 193-202. JI Shunping, LUO Chong, LIU Jin. A review of dense stereo image matching methods based on deep learning[J]. Geomatics and Information Science of Wuhan University, 2021, 46(2): 193-202. |
| [2] |
SCHARSTEIN D, SZELISKI R, ZABIH R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International Journal of Computer Vision, 2002, 47(1): 7-42. |
| [3] |
岳庆兴, 高小明, 唐新明. 基于半全局优化的资源三号卫星影像DSM提取方法[J]. 武汉大学学报(信息科学版), 2016, 41(10): 1279-1285. YUE Qingxing, GAO Xiaoming, TANG Xinming. ZY-3 DSM generation method based on semi-global optimization[J]. Geomatics and Information Science of Wuhan University, 2016, 41(10): 1279-1285. |
| [4] |
HIRSCHMVLLER H. Stereo processing by semiglobal matching and mutual information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(2): 328-341. DOI:10.1109/TPAMI.2007.1166 |
| [5] |
GEHRKE S, MORIN K, DOWNEY M, et al. Semi-global matching: an alternative to LiDAR for DSM generation?[EB/OL]. [2022-10-04]. https://www.isprs.org/proceedings/XXXVIII/part1/11/11_01_Paper_121.pdf.
|
| [6] |
D'ANGELO P, REINARTZ P. Semiglobal matching results on the ISPRS stereo matching benchmark[EB/OL]. [2022-10-04]. https://pdfs.semanticscholar.org/63a1/166a69bb236bf0c07c4d0c421aa8ecad3e81.pdf.
|
| [7] |
张力, 张继贤. 基于多基线影像匹配的高分辨率遥感影像DEM的自动生成[J]. 武汉大学学报(信息科学版), 2008, 33(9): 943-946. ZHANG Li, ZHANG Jixian. Automatic DEM generation from high-resolution satellite imagery based on multiple-baseline image matching[J]. Geomatics and Information Science of Wuhan University, 2008, 33(9): 943-946. |
| [8] |
刘瑾, 季顺平. 基于深度学习的航空遥感影像密集匹配[J]. 测绘学报, 2019, 48(9): 1141-1150. LIU Jin, JI Shunping. Deep learning based dense matching for aerial remote sensing images[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(9): 1141-1150. DOI:10.11947/j.AGCS.2019.20180247 |
| [9] |
POGGI M, TOSI F, BATSOS K, et al. On the synergies between machine learning and binocular stereo for depth estimation from images: a survey[EB/OL]. [2022-10-04]. https://arxiv.org/abs/2004.08566.
|
| [10] |
ZBONTAR J, LECUN Y. Computing the stereo matching cost with a convolutional neural network[EB/OL]. [2022-10-04]. https://arxiv.org/pdf/1409.4326.pdf.
|
| [11] |
SEKI A, POLLEFEYS M. SGM-nets: semi-global matching with neural networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6640-6649.
|
| [12] |
SHAKED A, WOLF L. Improved stereo matching with constant highway networks and reflective confidence learning[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6901-6910.
|
| [13] |
MAYER N, ILG E, HAUSSER P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 4040-4048.
|
| [14] |
CHOPRA S, HADSELL R, LECUN Y. Learning a similarity metric discriminatively, with application to face verification[C]//Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005: 539-546.
|
| [15] |
KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 66-75.
|
| [16] |
CHANG Jiaren, CHEN Yongsheng. Pyramid stereo matching network[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 5410-5418.
|
| [17] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. DOI:10.1109/TPAMI.2015.2389824 |
| [18] |
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 3354-3361.
|
| [19] |
MENZE M, GEIGER A. Object scene flow for autonomous vehicles[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3061-3070.
|
| [20] |
SCHARSTEIN D, HIRSCHMVLLER H, KITAJIMA Y, et al. High-resolution stereo datasets with subpixel-accurate ground truth[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2014: 31-42.
|
| [21] |
MAYER N, ILG E, FISCHER P, et al. What makes good synthetic training data for learning disparity and optical flow estimation?[J]. International Journal of Computer Vision, 2018, 126(9): 942-960. DOI:10.1007/s11263-018-1082-6 |
| [22] |
TAO Rongshu, XIANG Yuming, YOU Hongjian. An edge-sense bidirectional pyramid network for stereo matching of VHR remote sensing images[J]. Remote Sensing, 2020, 12(24): 4025. DOI:10.3390/rs12244025 |
| [23] |
HE Sheng, LI Shenhong, JIANG San, et al. HMSM-Net: hierarchical multi-scale matching network for disparity estimation of high-resolution satellite stereo images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 188: 314-330. DOI:10.1016/j.isprsjprs.2022.04.020 |
| [24] |
RAO Zhibo, HE Mingyi, ZHU Zhidong, et al. Bidirectional guided attention network for 3D semantic detection of remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(7): 6138-6153. DOI:10.1109/TGRS.2020.3029527 |
| [25] |
KHAMIS S, FANELLO S, RHEMANN C, et al. StereoNet: guided hierarchical refinement for real-time edge-aware depth prediction[C]//Proceedings of 2018 ECCV. New York: ACM Press, 2018: 596-613.
|
| [26] |
HE Sheng, ZHOU Ruqin, LI Shenhong, et al. Disparity estimation of high-resolution remote sensing images with dual-scale matching network[J]. Remote Sensing, 2021, 13(24): 5050. DOI:10.3390/rs13245050 |
| [27] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-780.
|
| [28] |
WU T, VALLET B, PIERROT-DESEILLIGNY M, et al. A new stereo dense matching benchmark dataset for deep learning[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2021, XLIII-B2-2021: 405-412. DOI:10.5194/isprs-archives-XLIII-B2-2021-405-2021 |
| [29] |
BOSCH M, FOSTER K, CHRISTIE G, et al. Semantic stereo for incidental satellite images[C]//Proceedings of 2019 IEEE Winter Conference on Applications of Computer Vision. Waikoloa Village: IEEE, 2019: 1524-1532.
|
| [30] |
PATIL S, COMANDUR B, PRAKASH T, et al. A new stereo benchmarking dataset for satellite images[EB/OL]. [2022-10-04]. https://arxiv.org/abs/1907.04404.pdf.
|
| [31] |
LI Shenhong, HE Sheng, JIANG San, et al. WHU-stereo: a challenging benchmark for stereo matching of high-resolution satellite images[EB/OL]. [2022-10-04]. https://arxiv.org/abs/2206.02342.pdf
|
| [32] |
杨幸彬, 吕京国, 江珊, 等. 高分辨率遥感影像DSM的改进半全局匹配生成方法[J]. 测绘学报, 2018, 47(10): 1372-1384. YANG Xingbin, LÜ Jingguo, JIANG Shan, et al. Digital surface model generation for high resolution satellite stereo image based on modified semi-global matching[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(10): 1372-1384. DOI:10.11947/j.AGCS.2018.20180091 |
| [33] |
袁修孝, 曹金山. 高分辨率卫星遥感精确对地目标定位理论与方法[M]. 北京: 科学出版社, 2012: 182-183. YUAN Xiuxiao, CAO Jinshan. Theory and method of precise object positioning of high resolution satellite imagery[M]. Beijing: Science Press, 2012: 182-183. |