



2. 北京航空气象研究所, 北京 100085;
3. 华北水利水电大学, 河南 郑州 450046;
4. 93110部队, 北京 100843;
5. 93116部队, 辽宁 沈阳 110000
2. Beijing Aviation Meteorological Institute, Beijing 100085, China;
3. North China University of Water Resources and Electric Power, Zhengzhou 450046, China;
4. Troops 93110, Beijing 100843, China;
5. Troops 93116, Shenyang 110000, China
随着遥感技术的快速发展,同一观测场景中存在多种类型的遥感数据。被动式遥感技术可以获取地物的波谱反射特性,其得到的高光谱图像(HSI)、多光谱图像(MSI)和高空间分辨率图像(VHR)包含丰富的光谱和空间结构信息。主动遥感技术通过发射并接收电磁波的方式以探测目标场景,合成孔径雷达(SAR)及机载激光雷达(LiDAR)数据能够记录目标在特定波谱段的辐射特性,并且具有全天时和全天候的观测特点。多源遥感数据在表征内容上具有互补性和冗余性,在获取时间上具有很强的互补性,多源异质遥感数据融合旨在克服单一传感器在观测内容和获取时间上的局限性,综合利用多维度的观测信息对观测场景进行更加精准的解译,已成功应用于土地覆盖分类[1]和农作物精细分类[2]等领域。不同类型的遥感数据包含互补的地物信息,综合利用多源异质遥感影像进行地物分类具有重要意义[3]。
监督分类方法是遥感影像地物分类中常用的学习范式。早期的研究工作主要集中在图像分析技术上,如波段选择[4]、特征提取[5]和分类器设计[6]等方面。深度学习模型具有强大的特征提取能力,卷积神经网络(CNN)可以提取层次化的空间特征,1D CNN[7]、2D CNN[8]和3D CNN[9]模型成功应用于高光谱影像分类。为了更好地挖掘高光谱影像中的光谱序列信息,循环神经网络(RNN)[10]及Transformer结构[11]也用于地物分类任务。同时,注意力机制[12]、知识蒸馏[13]和多尺度学习[14]等机器学习策略旨在进一步提升分类性能。对于多源遥感影像协同分类,主要有高光谱和LiDAR数据分类[15]、高光谱和多光谱图像分类[16],以及高光谱图像和SAR影像协同分类[17]。这些模型都是数据驱动的方法,其分类精度严重依赖于标签样本的数量,因此解决标记样本稀缺性的难题是遥感影像分类领域的重要研究方向之一[18]。半监督学习范式同时利用标签样本和无标签样本进行分类,图卷积神经网络[19]和生成对抗网络[20]通过构图和样本生成的方式来同时利用标签样本和无标签样本,但是这些半监督分类方法在解决样本生成和大影像构图方面存在不足。深度小样例方法在大量预收集的标签样本上进行预训练,然后将训练好的特征提取器迁移至目标数据集进行特征提取[21]。这种预训练方案是监督学习方法,同样需要搜集大量的标签样本,并且不同数据集在光谱分辨率和空间分辨率方面存在很大的差异,因而其特征学习能力有限。
尽管目前的监督学习模型和半监督学习模型取得了较好效果,但这些方法仍然无法解决最突出的问题,即分类过程中存在大量的无标签多源遥感数据,但是有标签的样本数量有限。自监督学习利用数据的固有特性来学习高级关键特征,并将学习到的特征用于下游的分类识别任务,主要分为对比式和生成式两类方法[22]。对比学习通过比对样本增强后的视图,旨在学习到一个潜在特征空间,其中同类的样本聚集在一起,不同类别的样本相互分离,从而学习到兼具不变形和区分性的特征表示。对比学习已成功应用于高光谱影像分类[23]、遥感图像场景分类[24]、PolSAR地物分类[25]及遥感图像变化检测[26]等领域。这些对比学习模型通常使用CNN作为特征提取器,在长距离特征提取和异构特征处理方面存在局限性[27]。生成式自监督学习通过恢复人为破坏后的数据来达到特征学习的目的,其动机是如果模型可以从受损的数据中恢复到原始信号,这意味着模型学习到表征原始信号的关键特征。通过将整幅影像切分为若干子块,并使用视觉Transformer模型来获取影像的全局感受野,掩膜自编码器(MAE)[28]和SimMIM模型[29]能够从掩膜后的图像中学习到高级特征表示,这类方法在自然图像自监督学习领域取得较好的结果。此外,为了从视频数据和多模态数据中学习到有意义的特征,面向多维数据的自监督学习模型尝试在这些数据中进行自监督学习[30-32]。由于遥感影像在内容和结构上与自然图像存在较大差异,遥感图像覆盖的地物类型更加复杂,并且光谱特征和空间特征在结构上存在很大的不同,现有的自监督预训练和分类模型无法有效地利用多源遥感影像中的空间和光谱信息进行特征学习,造成其异构特征学习能力有限。
标注高质量的样本费时费力,使用自监督预训练的方法可以从大量无标记样本中进行特征学习,能够为解决标签样本不足的问题提供一种解决思路。本文提出一种多源遥感影像自监督预训练和微调分类方案,用于多源异质遥感影像的地物协同分类。即面向多源遥感影像的自监督学习模型由非对称的编码器和解码器组成,其中深层编码器利用掩膜后的局部遥感影像进行特征学习,对应每类遥感数据的浅层解码器用于重建原始影像,从而学习到刻画原始多源遥感数据的关键特征。为进一步提升特征的表示能力,采用交叉注意力机制对编码器提取的异质特征进行信息融合。在微调分类阶段,构建基于Transformer结构的轻量级分类器,利用预训练好的编码器作为特征提取器,将提取的特征与光谱特征进行融合并用于地物分类。与常用的监督、半监督和自监督学习方法相比,所提自监督预训练和微调分类方案具有更优的特征学习和分类性能。
1 本文方法本文方法主要包括多源异质遥感影像自监督预训练和微调分类这两个阶段。在预训练过程中,以局部多源异质遥感影像(如HSI、DSM和VHR)作为处理单元进行特征学习,首先将每种影像在空间维度上划分为若干规则的子块,随机选取一部分的子块进行掩膜处理,未掩膜的影像子块进行特征嵌入,并将所有类型影像的嵌入特征进行堆叠并输入深层编码器进行特征学习;交叉注意力机制模型在学习到的异质特征之间进行信息交换和融合,以进一步提升特征表示能力;任务特定的解码器将每种影像对应的特征和掩膜数据重建为原始的遥感数据。在微调分类阶段,使用预训练好的编码器和交叉注意力机制模型作为无监督特征提取器,利用轻量级分类器将学习到的特征和光谱信息进行融合并分类。由于自监督预训练过程不需要任何人工标注信息,试验中使用所有的遥感数据进行自监督特征学习,在分类阶段,利用学习到的特征和对应的标签进行监督分类。
1.1 多源异质影像自监督预训练模型由于多源遥感数据包含观测场景冗余且互补的信息,预训练过程直接对多源异质数据进行生成式自监督学习,如图 1所示。该学习模型采用非对称的编码器-解码器结构,编码器和解码器主要由Transformer结构组成,深层编码器结构利用多源遥感影像块进行特征学习,任务特定的解码器完成每类遥感数据的重建任务,交叉注意力机制模型进行异质特征的信息融合。

|
| 图 1 多源异质遥感影像自监督预训练模型 Fig. 1 The self-supervised pre-training model for multi-source remote sensing heterogeneous images |
以遥感图像中的每个像素为中心,裁剪空间大小为H×W的局部影像块作为自监督学习的处理单元。令xi∈RH×W×Bi表示第i种影像(如HSI、DSM和VHR)的样本,其中H、W和Bi分别代表样本的高度、宽度和波段个数。每种类型的局部影像划分为多个规则的影像子块,并使用大小为m的掩膜率随机对这些影像子块进行掩膜。对于每种类型的影像,未掩膜的影像子块经过线性变换得到对应的嵌入特征,将所有类型影像的嵌入特征进行堆叠作为编码器的输入,表示为Tv。每个掩膜的影像子块用一个可训练的向量来表示,该向量仅仅作为解码器中的占位符,表示为Tm。
自监督学习模型中的编码器由多层Transformer结构组成,用于从多源遥感影像的嵌入特征中提取高阶关键特征。如图 1所示,相对位置编码操作可以为堆叠后的嵌入特征提供位置关系信息,并为每种类型的嵌入特征添加类别特征,用于表示对应类型遥感影像的高级特征信息,然后将全部的嵌入特征输入深层编码器进行特征学习,可表示为
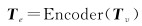 (1)
(1)
在编码器进行特征学习之后,使用交叉注意力模块在异质特征之间进行信息融合,从而进一步提升特征的表示能力。如图 1所示,预训练模型中存在多个解码器,分别完成每种类型遥感数据的重建任务。每个解码器的输入是未掩膜的特征Tei及掩膜特征Tmi,同样使用位置编码操作为重建任务中的嵌入特征提供相对位置信息,每个解码器可以表示为
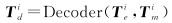 (2)
(2)
式中,Tei和Tmi分别表示第i种遥感数据的未掩膜嵌入特征和掩膜特征。在每个编码器的最后一层,预测头在像素空间中重建原始遥感数据,模型使用全连接层(FC)作为预测头将Tdi中的类别特征Cdi投影为特征向量,该向量与输入样本的维数相同。然后通过矩阵变换操作,得到对应的预测图像子块
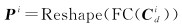 (3)
(3)
重建目标函数计算原始遥感数据与重建数据在像素空间中的均方误差,对原始数据和重建后的数据进行归一化操作,然后计算掩膜区域的影像与重建后对应区域影像之间的损失,模型的总体损失函数为所有类型遥感数据的重建损失总和。本文提出的多源遥感数据自监督学习模型是对掩膜后的数据进行重建,通过深层编码器的特征学习和任务特定的解码操作以后,可以从人为破坏后的数据中学习到刻画原始多源异质遥感数据的高阶关键特征。由于自监督学习过程不需要任何的人工标注信息,在预训练任务中,使用所有的多源遥感数据样本进行自监督学习,将学习到的特征表示作为原始数据的表征,然后将其用于后续的地物分类任务。
1.2 网络结构面向多源异质遥感影像的自监督学习模型主要由非对称的编码器-解码器结构组成,详细的网络结构如图 2所示。

|
| 图 2 自监督学习模型网络结构 Fig. 2 The network structure of self-supervised learning model |
编码器的输入为多源遥感影像中未掩膜的特征嵌入,类别特征对应每种影像的特征信息。编码器由多个Transformer结构组成,Transformer结构主要包括多层感知机(MLP)和多头注意力(MHA)层。多头注意力机制旨在从异质特征中构建多个子空间来学习复杂的依赖关系,公式化表示为
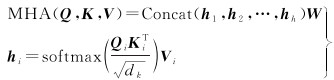 (4)
(4)
式中,Qi、Ki和Vi分别表示第i个头的查询矩阵、索引矩阵和值矩阵;h为头数量。此外,Transformer中还使用层归一化和残差连接结构,以利于模型的优化。
为了提升特征的表示能力,利用交叉注意力层在编码器之后进行异质特征的信息融合。如图 2所示,将来自一种类型的类别特征xcls1作为代理,与来自另一种类型的嵌入特征xpatch2连接,表示为
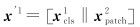 (5)
(5)
对xcls1和xpatch2进行多头注意力机制运算,公式化表示为
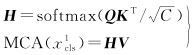 (6)
(6)
式中,Q、K和V分别表示交叉注意力操作中的查询矩阵、索引矩阵和值矩阵;C表示嵌入特征的维度。在交叉注意力模块中,同样采用层归一化和残差连接操作,公式化表示为
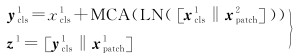 (7)
(7)
在交叉注意力机制融合层中,成对的异质特征以内容感知的方式进行融合,进一步提升了异质特征的表示能力。经过交叉注意力机制融合后的特征与对应的掩膜特征相结合,输入对应的解码器结构进行重建。解码器由Transformer结构和全连接层组成,将每类遥感数据的类别特征转换到像素空间,然后经过矩阵变换操作,得到与原始遥感影像大小相同的重建数据。
1.3 微调分类模型在预训练结束以后,训练好的编码器和交叉注意力层作为多源异质特征提取器,构造轻量级的分类器进行下游的地物分类任务,图 3为自监督预训练和微调分类方案。

|
| 图 3 自监督预训练和微调分类模型 Fig. 3 The self-supervised pre-training and fine-tuning scheme |
在微调阶段,交叉注意力层后的异质特征作为局部多源遥感影像的特征表示,构造一层Transformer结构和全连接层作为轻量级分类器。这些异质特征和对应的类别标签用于训练该分类模型,将每种类型的特征经过Transformer层后的类别特征进行堆叠,然后与对应的光谱信息进行连接,最后经过全连接层得到地物的类别。由于自监督预训练后学习到的特征具有更强的判别能力,使用少量的标签样本训练轻量级分类器进行监督分类可以得到更优的分类精度,从而缓解了监督分类模型对标记样本的严重依赖,为多源影像协同分类提供了新颖的解决方案。
2 试验与分析 2.1 试验数据本文使用Berlin、Augsburg和Houston 2018这3组多源异质遥感数据集进行对比试验分析,这些基准数据集和对应的真实地物分布如图 4所示。

|
| 图 4 3组基准遥感数据集的可视化显示 Fig. 4 The visualization for three benchmark remote sensing datasets |
Berlin数据集包含德国柏林及周边地区的高光谱影像和对应的PolSAR数据,高光谱数据包含地物的几何空间信息和精细光谱特征,PolSAR通过多通道、多种极化组合的方式对目标场景进行探测,极化矩阵能够有效地刻画目标的物理属性和几何特性。该数据集中的高光谱数据包含244个波段,光谱覆盖范围在400~2500 nm之间,空间大小为380×2384像素,空间分辨率为30 m,该数据集的覆盖范围内共包含8类典型地物[1](图 4(a))。
Augsburg数据集覆盖德国奥格斯堡城市及周边地区的模拟星载高光谱图像、PolSAR及DSM数据,DSM包含观测场景的精确高程信息。该数据集中的高光谱数据包含188个波段,光谱覆盖范围在400~2500 nm之间,影像空间大小为332×485像素,空间分辨率为30 m,该数据集的覆盖范围内共有7种典型城市建筑物和农作物地物类型(图 4(b))。
Houston 2018数据集覆盖美国休斯敦大学街区场景,包含机载高光谱影像、DSM数据和VHR影像,其中高光谱数据包含48个波段,光谱范围在380~1050 nm之间,影像空间大小为601×2384像素,空间分辨率为1 m,DSM和VHR影像经过空间采样操作与高光谱的空间分辨率保持一致,该数据集为典型的城市街区场景,共包含20种典型城市地物(图 4(c))。
高光谱遥感可以获取观测场景丰富的光谱和空间信息,其在地物精细分类中具有独特优势,但是仅仅使用高光谱影像很难区分光谱特征相同或者相似但属于不同类型的地物,DSM数据包含观测场景的精确高程信息,通过联合使用HSI和DSM数据可以有效提升地物分类性能。PolSAR获取的极化散射矩阵包含地物的极化散射信息,由于不同地物的极化散射特性各异,可以使用PolSAR数据进行地物精细分类,并且PolSAR受天气的影响很小。HSI、DSM和PolSAR在观测内容和获取时间上具有较强的互补性,本文使用的3组数据集主要包含这3类遥感数据。
2.2 试验设置试验硬件环境为Intel Xeon(R) Silver 4214处理器,196 GB内存,NVIDIA GeForce RTX 3090显卡,所提模型使用Python编程语言在PyTorch框架中实现。在预训练阶段,使用Adam算法来优化自监督学习模型,学习率和批大小分别设置为0.000 1和128。在Berlin数据集和Houston 2018数据集中,迭代次数设置为50;在Augsburg数据集中迭代次数设置为100。预训练过程中,首先将多源异质遥感影像进行空间采样操作,使不同影像保持相同的空间分辨率,使用IAPs[35]从DSM数据中提取3个属性特征进行自监督学习,对于PolSAR和VHR影像,分别使用原始的散射矩阵和3波段影像作为预训练模型的输入,由于高光谱影像波段数量众多,且波段间的冗余很大,为了从高光谱数据中提取信息的同时降低波段之间的冗余,试验中使用PCA提取高光谱影像的前9个波段进行自监督特征学习。为了保持不同类型的遥感数据在数据和内容上的均衡性,在进行预训练之前,对每种类型的遥感数据进行归一化,然后输入预训练模型进行特征学习。
由于预训练阶段不需要人工标注信息,在预训练过程中使用所有的样本进行自监督特征学习;在微调分类阶段,轻量级分类器利用学习到的特征和对应的标签进行监督学习,3组基准数据集上的训练集、验证集和测试集的划分情况见表 1—表 3。采用常用的分类评价指标,即总体分类精度(OA)、平均分类精度(AA)和Kappa系数来定量评估分类精度,还利用分类结果图进行视觉效果评价。
| 编号 | 地物类别 | 训练集 | 验证集 | 测试集 |
| C1 | 森林 | 200 | 40 | 54 714 |
| C2 | 居民区 | 200 | 40 | 268 402 |
| C3 | 工业区 | 200 | 40 | 19 326 |
| C4 | 低矮植物 | 200 | 40 | 59 042 |
| C5 | 裸土 | 200 | 40 | 17 186 |
| C6 | 私家菜地 | 200 | 40 | 13 065 |
| C7 | 商业区 | 200 | 40 | 24 584 |
| C8 | 水体 | 200 | 40 | 6432 |
| 编号 | 地物类别 | 训练集 | 验证集 | 测试集 |
| C1 | 森林 | 100 | 20 | 13 387 |
| C2 | 居民区 | 100 | 20 | 30 209 |
| C3 | 工业区 | 100 | 20 | 3731 |
| C4 | 低矮植物 | 100 | 20 | 26 737 |
| C5 | 私家菜地 | 100 | 20 | 455 |
| C6 | 商业区 | 100 | 20 | 1525 |
| C7 | 水体 | 100 | 20 | 1410 |
| 编号 | 地物类别 | 训练集 | 验证集 | 测试集 |
| C1 | 健康草地 | 300 | 60 | 9444 |
| C2 | 受损草地 | 300 | 60 | 32 147 |
| C3 | 人造草地 | 300 | 60 | 329 |
| C4 | 常青树木 | 300 | 60 | 13 233 |
| C5 | 阔叶树木 | 300 | 60 | 4693 |
| C6 | 裸土 | 300 | 60 | 4161 |
| C7 | 水体 | 80 | 60 | 131 |
| C8 | 居民建筑 | 300 | 60 | 39 407 |
| C9 | 非居民建筑 | 300 | 60 | 223 329 |
| C10 | 道路 | 300 | 60 | 45 455 |
| C11 | 人行道 | 300 | 60 | 33 647 |
| C12 | 人行横道 | 300 | 60 | 1161 |
| C13 | 主干街道 | 300 | 60 | 46 003 |
| C14 | 高速公路 | 300 | 60 | 9494 |
| C15 | 铁路 | 300 | 60 | 6582 |
| C16 | 砌面停车场 | 300 | 60 | 11 120 |
| C17 | 非砌面停车场 | 40 | 40 | 74 |
| C18 | 汽车 | 300 | 60 | 6223 |
| C19 | 火车 | 300 | 60 | 5010 |
| C20 | 体育场座位 | 300 | 60 | 6469 |
2.3 对比试验分析
为了验证所提自监督预训练和微调分类方案的有效性和先进性,在对比试验中,选取常用的分类方法进行对比分析,包括经典的基于特征工程的监督和半监督方法、端到端的深度学习模型及基于特征学习的方法。基于特征工程的方法包括经典的SVM[33]、半监督SVM[34]及IAPs-SVM方法[35],深度神经网络方法包括长短时记忆网络(LSTM)[36]和空谱多尺度网络(ASSMN)[37]、多源影像分类模型SepDG[38]及代表性Transformer模型SpectralFormer[11],基于特征学习的方法为深度少样例方法(DFSL)[21]及深度多视角自监督学习方法(DMVL)[39]。对比方法中的一些模型是针对高光谱影像提出的,为了增强试验结果的公平性,将基准数据集中的多源遥感数据进行堆叠,然后进行地物分类,对比方法中的模型参数分别按照对应文章进行设置。不同分类方法在3组基准数据集上的分类结果见表 4—表 6。
| 类别 | 特征工程方法 | 深度神经网络方法 | 特征学习方法 | 本文方法 | ||||||||
| SVM | IAPs | TSVM | LSTM | ASSMN | SepDG | SpectralFormer | DFSL | DMVL | ||||
| C1 | 75.81 | 78.50 | 76.74 | 80.97 | 79.83 | 85.16 | 79.85 | 74.36 | 85.45 | 87.74 | ||
| C2 | 93.46 | 94.03 | 93.75 | 52.65 | 96.23 | 93.99 | 45.27 | 93.33 | 95.91 | 96.05 | ||
| C3 | 36.23 | 34.15 | 37.30 | 55.76 | 63.13 | 44.24 | 47.43 | 37.03 | 61.45 | 74.50 | ||
| C4 | 86.18 | 83.31 | 86.85 | 85.87 | 88.17 | 85.70 | 74.32 | 82.95 | 91.96 | 88.69 | ||
| C5 | 64.46 | 65.17 | 67.17 | 92.73 | 74.84 | 66.11 | 91.55 | 62.34 | 82.69 | 83.97 | ||
| C6 | 19.77 | 17.04 | 21.98 | 70.89 | 36.37 | 19.11 | 72.49 | 11.75 | 29.65 | 33.23 | ||
| C7 | 23.86 | 21.81 | 26.82 | 50.47 | 33.41 | 20.48 | 45.67 | 25.36 | 25.85 | 42.85 | ||
| C8 | 38.47 | 45.92 | 33.86 | 54.80 | 50.98 | 56.12 | 87.22 | 42.74 | 55.61 | 53.09 | ||
| OA | 67.41 | 65.37 | 69.94 | 62.71 | 79.14 | 66.70 | 56.25 | 62.29 | 76.09 | 82.82 | ||
| AA | 54.78 | 54.99 | 55.56 | 68.02 | 65.37 | 58.86 | 67.98 | 53.73 | 66.07 | 70.02 | ||
| Kappa系数 | 55.81 | 53.78 | 58.60 | 50.92 | 69.76 | 54.70 | 44.36 | 50.12 | 66.48 | 74.58 | ||
| 类别 | 特征工程方法 | 深度神经网络方法 | 特征学习方法 | 本文方法 | ||||||||
| SVM | IAPs | TSVM | LSTM | ASSMN | SepDG | SpectralFormer | DFSL | DMVL | ||||
| C1 | 88.10 | 87.75 | 89.62 | 92.97 | 83.18 | 90.26 | 93.34 | 71.63 | 90.20 | 93.46 | ||
| C2 | 88.27 | 89.14 | 88.10 | 50.12 | 90.19 | 95.44 | 60.91 | 81.33 | 88.41 | 91.40 | ||
| C3 | 33.04 | 37.42 | 30.64 | 45.64 | 65.68 | 55.69 | 46.52 | 37.27 | 59.78 | 72.92 | ||
| C4 | 93.15 | 91.22 | 94.02 | 87.19 | 86.24 | 91.11 | 75.35 | 76.75 | 89.97 | 92.52 | ||
| C5 | 5.49 | 8.17 | 8.26 | 62.74 | 15.47 | 9.08 | 94.31 | 6.52 | 15.26 | 15.17 | ||
| C6 | 13.77 | 18.34 | 14.40 | 40.13 | 29.21 | 19.92 | 45.56 | 14.32 | 32.38 | 44.63 | ||
| C7 | 30.67 | 35.54 | 26.93 | 66.29 | 27.10 | 23.76 | 63.35 | 17.30 | 36.43 | 38.90 | ||
| OA | 69.86 | 73.89 | 71.32 | 70.39 | 77.27 | 74.88 | 70.74 | 60.71 | 78.79 | 83.74 | ||
| AA | 50.36 | 52.51 | 50.28 | 63.58 | 56.72 | 55.04 | 68.48 | 43.59 | 58.92 | 64.14 | ||
| Kappa系数 | 60.70 | 65.26 | 62.44 | 61.32 | 69.15 | 66.63 | 61.33 | 48.81 | 71.31 | 77.64 | ||
| 类别 | 特征工程方法 | 深度神经网络方法 | 特征学习方法 | 本文方法 | ||||||||
| SVM | IAPs | TSVM | LSTM | ASSMN | SepDG | SpectralFormer | DFSL | DMVL | ||||
| C1 | 85.48 | 69.77 | 90.24 | 83.35 | 57.17 | 81.96 | 97.94 | 63.72 | 43.03 | 71.67 | ||
| C2 | 90.91 | 86.82 | 89.35 | 86.49 | 96.23 | 91.42 | 87.99 | 68.10 | 82.19 | 91.72 | ||
| C3 | 97.23 | 13.55 | 87.69 | 58.64 | 78.36 | 54.17 | 88.06 | 7.68 | 78.89 | 92.43 | ||
| C4 | 81.19 | 86.62 | 79.52 | 83.23 | 81.02 | 90.25 | 96.50 | 84.94 | 65.48 | 86.19 | ||
| C5 | 35.48 | 35.90 | 36.08 | 84.53 | 82.47 | 35.56 | 80.88 | 12.85 | 43.68 | 69.11 | ||
| C6 | 60.62 | 34.10 | 77.29 | 93.45 | 89.43 | 63.82 | 67.65 | 18.11 | 76.67 | 99.10 | ||
| C7 | 91.94 | 99.80 | 99.68 | 48.54 | 38.99 | 90.86 | 49.46 | 4.71 | 29.07 | 77.33 | ||
| C8 | 56.31 | 66.01 | 56.11 | 71.53 | 85.14 | 62.37 | 76.45 | 50.47 | 93.78 | 93.94 | ||
| C9 | 96.81 | 96.45 | 96.95 | 62.17 | 96.84 | 97.41 | 67.09 | 98.16 | 97.72 | 98.76 | ||
| C10 | 56.87 | 55.77 | 50.74 | 38.36 | 56.16 | 59.11 | 42.34 | 43.16 | 69.50 | 83.38 | ||
| C11 | 49.31 | 48.61 | 46.56 | 40.14 | 51.31 | 50.00 | 47.05 | 42.91 | 47.18 | 59.64 | ||
| C12 | 5.00 | 5.13 | 6.51 | 62.43 | 4.01 | 6.62 | 52.13 | 2.18 | 15.81 | 17.90 | ||
| C13 | 65.86 | 63.90 | 62.85 | 42.78 | 98.09 | 71.35 | 53.54 | 40.04 | 89.35 | 91.87 | ||
| C14 | 48.00 | 53.65 | 50.61 | 82.85 | 96.93 | 61.00 | 89.01 | 16.06 | 76.03 | 94.09 | ||
| C15 | 79.96 | 64.68 | 83.68 | 87.45 | 98.45 | 82.30 | 89.00 | 18.64 | 91.00 | 98.04 | ||
| C16 | 69.58 | 73.68 | 72.94 | 83.08 | 76.86 | 68.39 | 88.24 | 21.73 | 84.91 | 94.96 | ||
| C17 | 39.00 | 45.82 | 26.41 | 38.17 | 62.74 | 33.26 | 7.24 | 1.10 | 18.78 | 54.18 | ||
| C18 | 29.03 | 46.65 | 40.91 | 76.79 | 85.13 | 43.13 | 89.28 | 17.99 | 62.16 | 92.88 | ||
| C19 | 41.01 | 65.31 | 42.93 | 88.33 | 96.12 | 57.49 | 66.18 | 39.36 | 91.97 | 97.22 | ||
| C20 | 62.56 | 62.98 | 70.15 | 84.64 | 29.22 | 79.58 | 76.68 | 27.51 | 86.91 | 98.93 | ||
| OA | 70.57 | 69.43 | 71.15 | 63.57 | 76.33 | 72.42 | 68.46 | 41.46 | 81.69 | 89.78 | ||
| AA | 62.11 | 58.76 | 63.36 | 69.85 | 73.03 | 64.00 | 70.64 | 33.97 | 67.21 | 83.17 | ||
| Kappa系数 | 64.06 | 63.24 | 64.79 | 56.39 | 70.42 | 66.44 | 61.81 | 35.53 | 76.85 | 86.94 | ||
当使用相同数量的标记样本进行分类时,利用无标记样本的半监督学习和特征学习方法具有更优的分类性能。在基于特征工程的对比方法中,半监督分类方法TSVM在3组数据集上的总体分类精度要高于监督学习模型SVM,在Berlin数据集和Houston 2018数据集上的分类精度要优于IAPs方法,说明了无标签样本的联合使用能够提升地物分类性能。在监督深度神经网络方法中,由于ASSMN同时从光谱和空间维度提取多尺度特征进行联合分类,其对应的分类精度要明显优于其他两种深度神经网络方法。多源异质遥感数据包含丰富且互补的观测信息,基于迁移学习的DFSL在预先搜集的有标签的样本上进行预训练,然后将特征提取网络迁移到目标数据集上,由于该方法没有充分考虑多源遥感数据的特点,其得到的地物分类精度有限。基于对比学习的DMVL方法首先在数据集上进行自监督特征学习,能够从大量无标签样本中学习到有意义的特征表示,并使用学习到的特征进行分类,其分类精度要优于其他对比方法,说明了基于自监督特征学习的方法在遥感影像地物分类领域具有较大的优势和潜力,但它没有考虑多源异质遥感数据在内容和结构上的特点进行特征学习。
本文所提的面向多源遥感影像的自监督预训练和微调分类方案是一种有效的地物分类方法。在使用相同数量的标签样本进行分类时,所提分类方案在每类地物分类精度和主要评价系数方面能够取得更优的结果,在3组数据集上的总体分类精度分别达到了82.82%、83.74%和89.78%。对于Houston 2018数据集,现有的监督分类模型和基于特征学习的方法在该数据集上的分类精度普遍较低,而本文方法在该数据集上的分类精度有较大程度的提升,其原因在于所提分类方法能够有效地利用多源异质遥感数据中的丰富信息进行自监督特征学习,从大量的无标注样本中学习到表征原始数据的关键特征,然后利用提取的特征进行下游的地物分类。该分类范式为解决多源异质影像地物分类提供一种新颖的分类模式,能够有效地缓解深度神经网络方法对于标签样本的严重依赖。
除了上述定量分析以外,不同分类方法得到的分类结果图用于进行视觉评估,在3组基准数据集上的分类图如图 5—图 7所示,其中每种类别的地物使用不同的颜色进行标识,每组数据的真实地物分布图用于进行对比分析。同时使用标签样本和无标签样本的半监督分类方法TSVM的分类图中“类别噪声”要少于SVM方法对应的分类图,联合使用空间和光谱维度信息的ASSMN模型能够得到更加平滑的分类图,它的分类图要比LSTM和SepDG模型分类图的空间连续性更强,在Berlin数据集和Augsburg数据集上表现明显,原因在于空间和光谱信息可以提供互补的判别信息。本文提出的自监督预训练方法得到的分类图更加符合真实地物标记,表明了本文方法能够以自监督的方式从多源异质遥感影像中学习到判别能力更强的特征,在使用同样数量的标记样本情况下取得更优的分类效果。

|
| 图 5 不同模型在Berlin数据集上的分类结果 Fig. 5 Resulting classification maps of different models on the Berlin dataset |

|
| 图 6 不同模型在Augsburg数据集上的分类结果 Fig. 6 Resulting classification maps of different models on the Augsburg dataset |

|
| 图 7 不同模型在Houston 2018数据集上的分类结果 Fig. 7 Resulting classification maps of different models on the Houston 2018 dataset |
2.4 模型参数分析
本文模型中的部分超参数在很大程度上影响自监督特征学习能力,进而影响地物分类精度,本节分析这些超参数对于分类精度的影响。
(1) 网络结构。由于自监督学习模型采用非对称的编码器-解码器结构,不同的网络结构对应不同的特征学习性能。模型中编码器和解码器主要由Transformer结构组成,为其设置不同层数的Transformer,候选器分别设置为(6、8、10、12)和(1、2、3)。不同的自监督预训练网络结构在3组基准数据集上的总体分类精度如图 8所示。可以看出,较深的编码器和较浅的解码器结构搭配具有更高的分类精度,表明这种非对称的结构具有更强的自监督特征学习能力。根据试验结果,3组数据集对应的最优编码器-解码器结构分别为(8,2)、(12,3)和(8,2)。

|
| 图 8 网络结构敏感性分析 Fig. 8 Sensitivity analysis of the model structure |
(2) 掩膜率。在本文所提的生成式自监督学习模型中,使用大小为m的掩膜率对局部遥感影像进行掩膜处理,然后使用未掩膜的影像子块进行特征嵌入并输入编码器-解码器结构进行数据重建。模型中的掩膜率决定了输入编码器的子块数量,进而影响编码器对于图像的感受野范围。在3组基准数据集上使用不同掩膜率得到的总体分类精度如图 9所示,由试验结果可以观测到掩膜率对分类精度具有较大的影响,较大的掩膜率使模型只能使用很少的影像子块进行特征学习,其分类精度较低;较小的掩膜率对应更多的影像输入,但其自监督特征学习能力也较弱,其原因在于图像具有较大的空间冗余,使用较小的掩膜率很难使模型学习到刻画原始遥感数据的关键特征。适中的掩膜率使模型从适量的影像子块中学习到刻画原始影像的关键特征,3个数据集对应的最优的掩膜率分别为40%、50%和40%。

|
| 图 9 掩膜率敏感性分析 Fig. 9 Sensitivity analysis of the mask ratio |
(3) 邻域大小。由于模型使用局部多源遥感影像作为处理单元进行特征学习,影像的邻域大小影响编码器的空间感受野,进而影响特征学习和分类性能。在3组基准数据集上使用不同邻域大小的分类结果如图 10所示,分类精度随着邻域的增加而提升,因为大的影像块具有更大的感受野,但是过大的局部影像包含不相关的冗余信息同样会干扰特征学习和分类性能。同时邻域大小与影像空间分辨率也有关联,空间分辨率越高的图像对应的最优空间邻域更大,在Houston 2018数据集中,分类精度随着邻域大小的增加而逐步提升。

|
| 图 10 邻域大小敏感性分析 Fig. 10 Sensitivity analysis of the spatial size |
(4) 模型复杂度分析。模型复杂度是评价模型的重要指标,包括空间复杂度和时间复杂度,试验中,使用模型参数的数量来衡量空间复杂度,用浮点计算量(FLOPs)来分析模型的时间复杂度,不同方法在3组基准数据集上的参数量和FLOPs见表 7。
| 数据集 | 复杂度/兆 | LSTM | ASSMN | SepDG | Spectral Former | DMVL | 本文方法 | |
| 预训练模型 | 分类模型 | |||||||
| Berlin | 参数量 | 0.16 | 3.60 | 0.19 | 0.45 | 24.62 | 30.41 | 1.61 |
| FLOPs | 2.77 | 121.21 | 1.90 | 44.84 | 1054.19 | 1458.85 | 40.93 | |
| Augsburg | 参数量 | 0.11 | 3.54 | 0.19 | 0.29 | 24.62 | 47.73 | 1.21 |
| FLOPs | 2.56 | 121.20 | 1.90 | 28.68 | 1054.19 | 2449.66 | 22.44 | |
| Houston 2018 | 参数量 | 0.09 | 3.41 | 0.19 | 0.11 | 24.62 | 33.02 | 1.20 |
| FLOPs | 2.16 | 121.17 | 1.96 | 5.28 | 1054.19 | 1654.51 | 22.43 | |
由于不同方法中批处理大小和迭代次数不同,对应的训练时间和测试时间不同,为了更好地进行比较分析,试验中每种方法的批处理大小设置为1,并将其对应的FLOPs作为时间复杂度评价指标。由表 7的统计结果可知,基于Transformer结构的分类模型对应的参数量和FLOPs要高于CNN分类模型,原因在于CNN具有局部连接和权重共享的特性,而Transformer结构建立长距离依赖关系,该模型具有更多的参数。在自监督学习模型中,一般采用深层的网络结构从大量的无标签数据中学习高阶特征表示,预训练模型对应的模型参数量和运算量一般较大,由于本文使用视觉Transformer模型进行自监督预训练,其对应的模型参数量要大于基于残差网络的DMVL模型,微调分类模型使用单层的Transformer模型和全连接层进行分类,其对应的模型参数量要远远小于预训练阶段的模型。自监督预训练方法使用深层的网络模型从大量的无标注样本中学习高阶关键特征,在预训练阶段需要较长的时间进行特征学习,由于学习到的特征更有利于下游的分类任务,在分类阶段使用轻量级的分类器可以达到更优的分类性能。
2.5 消融试验由于自监督预训练模型利用多源异质遥感影像进行特征学习,然后使用学习到的特征代替原始的数据进行地物分类,为提升特征的表示能力,所提模型利用交叉注意力机制进行异质特征的信息融合。为验证自监督特征学习的有效性,试验中直接使用轻量级Transformer分类器对原始数据进行分类,同时,为证明交叉注意力机制对于特征增强的有效性,同样对交叉注意力层进行消融试验,消融试验结果见表 8。由表中的试验结果可知,直接使用原始数据得到的分类精度很低,原因在于轻量级分类器并不能从原始数据中提取有效的特征进行分类,而使用自监督特征学习的方法能够显著提升分类精度,证明了自监督预训练过程能够学习到刻画原始数据的关键特征。通过比较有无交叉注意力机制融合的试验结果,可以观察到使用交叉注意力层的特征学习方法在3组数据集的分类精度上均有提升,在Augsburg数据集上的提升最为明显,验证了交叉注意力机制在多源异质遥感影像的自监督学习中的有效性。
| 参数 | Berlin数据集 | Augsburg数据集 | Houston 2018数据集 | ||||||||
| OA | AA | Kappa系数 | OA | AA | Kappa系数 | OA | AA | Kappa系数 | |||
| 原始数据 | 74.62 | 64.04 | 63.57 | 65.66 | 46.77 | 56.07 | 72.00 | 69.31 | 70.77 | ||
| 自监督学习(无特征融合) | 81.44 | 69.35 | 73.35 | 81.98 | 61.46 | 75.44 | 88.69 | 82.33 | 86.12 | ||
| 自监督学习(特征融合) | 82.82 | 70.02 | 74.58 | 83.74 | 64.14 | 77.64 | 89.78 | 83.17 | 86.94 | ||
3 结论
为缓解监督学习模型对标签样本的依赖并提升多源异质遥感影像地物协同分类的精度,本文提出了用于多源异质遥感影像地物分类的自监督预训练和微调分类方案。由于在同一观测场景中存在多源异质的遥感数据,这些数据中包含丰富且互补的地物信息,但是有限数量的标记样本并不能训练深层的网络模型进行地物分类,本文提出利用自监督预训练的方案从无标记样本中学习有利于下游分类任务的关键特征,从而缓解深度学习模型对于标记样本的严重依赖。面向多源遥感影像的自监督学习架构采用非对称的编码器-解码器结构从所有无标签样本中学习高级关键特征,利用Transformer结构进行特征学习和数据重建,并使用交叉注意力层在异质特征之间进行信息融合,以进一步提升特征表示能力。构建的轻量级分类模型利用学习到的特征和光谱信息进行地物分类,在使用相同数量的标记样本情况下,本文方法在基准数据集上得到更优的分类结果,验证了本文方法的有效性和先进性,为缓解深度学习模型对标签样本的依赖提供了有效的解决方案。
| [1] |
HONG Danfeng, HU Jingliang, YAO Jing, et al. Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model[J]. ISPRS Journal of Photogrammetry and Remote Sensing: Official Publication of the International Society for Photogrammetry and Remote Sensing (ISPRS), 2021, 178: 68-80. |
| [2] |
LEI Lei, WANG Xinyu, ZHONG Yanfei, et al. DOCC: deep one-class crop classification via positive and unlabeled learning for multi-modal satellite imagery[J]. International Journal of Applied Earth Observation and Geoinformation, 2021, 105: 102598. DOI:10.1016/j.jag.2021.102598 |
| [3] |
张良培, 何江, 杨倩倩, 等. 数据驱动的多源遥感信息融合研究进展[J]. 测绘学报, 2022, 51(7): 1317-1337. ZHANG Liangpei, HE Jiang, YANG Qianqian, et al. Data-driven multi-source remote sensing data fusion: progress and challenges[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7): 1317-1337. DOI:10.11947/j.AGCS.2022.20220171 |
| [4] |
施蓓琦, 刘春, 孙伟伟, 等. 应用稀疏非负矩阵分解聚类实现高光谱影像波段的优化选择[J]. 测绘学报, 2013, 42(3): 351-358, 366. SHI Beiqi, LIU Chun, SUN Weiwei, et al. Sparse nonnegative matrix factorization for hyperspectral optimal band selection[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(3): 351-358, 366. |
| [5] |
余岸竹, 刘冰, 邢志鹏, 等. 面向高光谱影像分类的显著性特征提取方法[J]. 测绘学报, 2019, 48(8): 985-995. YU Anzhu, LIU Bing, XING Zhipeng, et al. Salient feature extraction method for hyperspectral image classification[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(8): 985-995. DOI:10.11947/j.AGCS.2019.20180499 |
| [6] |
张良培, 李家艺. 高光谱图像稀疏信息处理综述与展望[J]. 遥感学报, 2016, 20(5): 1091-1101. ZHANG Liangpei, LI Jiayi. Development and prospect of sparse representation-based hyperspectral image processing and analysis[J]. Journal of Remote Sensing, 2016, 20(5): 1091-1101. |
| [7] |
CHEN Yushi, JIANG Hanlu, LI Chunyang, et al. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(10): 6232-6251. DOI:10.1109/TGRS.2016.2584107 |
| [8] |
LEE H, KWON H. Going deeper with contextual CNN for hyperspectral image classification[J]. IEEE Transactions on Image Processing: a Publication of the IEEE Signal Processing Society, 2017, 26(10): 4843-4855. DOI:10.1109/TIP.2017.2725580 |
| [9] |
WANG Kexian, ZHENG Shunyi, LI Rui, et al. A deep double-channel dense network for hyperspectral image classification[J]. Journal of Geodesy and Geoinformation Science, 2021, 4(4): 46-62. |
| [10] |
MOU Lichao, GHAMISIP, ZHU Xiaoxiang. Deep recurrent neural networks for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3639-3655. DOI:10.1109/TGRS.2016.2636241 |
| [11] |
HONG Danfeng, HAN Zhu, YAO Jing, et al. SpectralFormer: rethinking hyperspectral image classification with transformers[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 5518615. |
| [12] |
HANG Renlong, LI Zhu, LIU Qingshan, et al. Hyperspectral image classification with attention-aided CNNs[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(3): 2281-2293. DOI:10.1109/TGRS.2020.3007921 |
| [13] |
YUE Jun, FANG Leyuan, RAHMANI H, et al. Self-supervised learning with adaptive distillation for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 5501813. |
| [14] |
YANG Lina, ZHANG Fengqi, WANGP S P, et al. Multi-scale spatial-spectral fusion based on multi-input fusion calculation and coordinate attention for hyperspectral image classification[J]. Pattern Recognition, 2022, 122: 108348. DOI:10.1016/j.patcog.2021.108348 |
| [15] |
XUE Zhixiang, YU Xuchu, TAN Xiong, et al. Multiscale deep learning network with self-calibrated convolution for hyperspectral and LiDAR data collaborative classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 5514116. |
| [16] |
LI Wei, WANG Junjie, GAO Yunhao, et al. Graph-feature-enhanced selective assignment network for hyperspectral and multispectral data classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5526914. |
| [17] |
WANG Junjie, LI Wei, GAO Yunhao, et al. Hyperspectral and SAR image classification via multiscale interactive fusion network[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(12): 10823-10837. DOI:10.1109/TNNLS.2022.3171572 |
| [18] |
张兵, 杨晓梅, 高连如, 等. 遥感大数据智能解译的地理学认知模型与方法[J]. 测绘学报, 2022, 51(7): 1398-1415. ZHANG Bing, YANG Xiaomei, GAO Lianru, et al. Geo-cognitive models and methods for intelligent interpretation of remotely sensed big data[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7): 1398-1415. DOI:10.11947/j.AGCS.2022.20220279 |
| [19] |
左溪冰, 刘冰, 余旭初, 等. 高光谱影像小样本分类的图卷积网络方法[J]. 测绘学报, 2021, 50(10): 1358-1369. ZUO Xibing, LIU Bing, YU Xuchu, et al. Graph convolutional network method for small sample classification of hyperspectral images[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(10): 1358-1369. DOI:10.11947/j.AGCS.2021.20200155 |
| [20] |
ZHU Lin, CHEN Yushi, GHAMISI P, et al. Generative adversarial networks for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(9): 5046-5063. DOI:10.1109/TGRS.2018.2805286 |
| [21] |
刘冰, 左溪冰, 谭熊, 等. 高光谱影像分类的深度少样例学习方法[J]. 测绘学报, 2020, 49(10): 1331-1342. LIU Bing, ZUO Xibing, TAN Xiong, et al. A deep few-shot learning algorithm for hyperspectral image classification[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(10): 1331-1342. DOI:10.11947/j.AGCS.2020.20190486 |
| [22] |
陶超, 阴紫薇, 朱庆, 等. 遥感影像智能解译: 从监督学习到自监督学习[J]. 测绘学报, 2021, 50(8): 1122-1134. TAO Chao, YIN Ziwei, ZHU Qing, et al. Remote sensing image intelligent interpretation: from supervised learning to self-supervised learning[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8): 1122-1134. DOI:10.11947/j.AGCS.2021.20210089 |
| [23] |
ZHU Mingzhen, FAN Jiayuan, YANG Qihang, et al. SC-EADNet: a self-supervised contrastive efficient asymmetric dilated network for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 5519517. |
| [24] |
LI Xiaomin, SHI Daqian, DIAO Xiaolei, et al. SCL-MLNet: boosting few-shot remote sensing scene classification via self-supervised contrastive learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 5801112. |
| [25] |
ZHANG Lamei, ZHANG Siyu, ZOU Bin, et al. Unsupervised deep representation learning and few-shot classification of PolSAR images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5100316. |
| [26] |
CHEN Yuxing, BRUZZONE L. Self-supervised change detection in multiview remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5402812. |
| [27] |
XUE Zhixiang, YU Xuchu, YU Anzhu, et al. Self-supervised feature learning for multimodal remote sensing image land cover classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 1809, 60: 5533815. |
| [28] |
HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 15979-15988.
|
| [29] |
XIE Zhenda, ZHANG Zheng, CAO Yue, et al. SimMIM: a simple framework for masked image modeling[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 9643-9653.
|
| [30] |
FEICHTENHOFER C, FAN Haoqi, LI Yanghao, et al. Masked autoencoders as spatiotemporal learners[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems. New Orleans: ACM Press, 2022: 35946-35958.
|
| [31] |
BACHMANNR, MIZRAHI D, ATANOV A, et al. MultiMAE: multi-modal multi-task masked autoencoders[C]//Proceedigns of 2022 European Conference on Computer Vision. Cham: Springer, 2022: 348-367.
|
| [32] |
XUE Zhixiang, LIU Bing, YU Anzhu, et al. Self-supervised feature representation and few-shot land cover classification of multimodal remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-118. |
| [33] |
MELGANIF, BRUZZONE L. Classification of hyperspectral remote sensing images with support vector machines[J]. IEEE Transactions on Geoscience and Remote Sensing, 2004, 42(8): 1778-1790. |
| [34] |
BRUZZONEL, CHI M, MARCONCINI M. A novel transductive SVM for semisupervised classification of remote-sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2006, 44(11): 3363-3373. |
| [35] |
HONG Danfeng, WU Xin, GHAMISI P, et al. Invariant attribute profiles: a spatial-frequency joint feature extractor for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(6): 3791-3808. |
| [36] |
XU Yonghao, ZHANG Liangpei, DU Bo, et al. Spectral-spatial unified networks for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(10): 5893-5909. |
| [37] |
WANG Di, DU Bo, ZHANG Liangpei, et al. Adaptive spectral-spatial multiscale contextual feature extraction for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(3): 2461-2477. |
| [38] |
YANG Yi, ZHU Daoye, QU Tengteng, et al. Single-stream CNN with learnable architecture for multisource remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5409218. |
| [39] |
LIU Bing, YU Anzhu, YU Xuchu, et al. Deep multiview learning for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(9): 7758-7772. |