



2. 武汉大学灾害监测与防治研究中心, 湖北 武汉 430079;
3. 广州市城市规划勘测设计研究院, 广东 广州 510060;
4. 南昌大学信息工程学院, 江西 南昌 330031
2. Research Center for Hazard Monitoring and Prevention, Wuhan University, Wuhan 430079, China;
3. Guangzhou Urban Planning & Design Survey Research Institute, Guangzhou 510060, China;
4. School of Information Engineering, Nanchang University, Nanchang 330031, China
点云场景语义标注为场景中每个数据基元赋予一个语义标签,是城市规划、自动驾驶、导航定位和数字城市等应用的基础[1-4],也是各种监督学习方法[5-7]真实数据的来源。手动标注建筑物、树木、车辆等点云场景对象是一项费时费力的工作,为此已经有很多学者致力于研究如何减少点云场景手动标注的人工成本。传统的策略是利用条件随机场、马尔科夫随机场等概率图模型[8-9]来进行语义标注,如低阶马尔科夫模型[10]、Potts模型[11]、Robust Potts[12]模型等。这些方法虽然很好地利用了目标邻域间的上下文信息,能较好地拟合真实的三维场景,但普遍存在着分类准确率不够高、需要特定先验信息等缺点,不具有通用性。另外一种策略是通过直接引入其他数据源的标签来减少手动标注的工作量,如直接从标注好的二维图片数据中提取对应三维点云场景的标签[13]、利用运动结构恢复(structure from motion, SFM)算法和视频图片数据重建三维场景进行联合标注[14]等。这类策略虽然利用了二维图片和物体的三维信息,但需要事先手工标注大量的图片数据,且利用SFM算法重建的三维场景并不能准确地描述物体的三维信息。除了上述两种策略,还有一类策略是识别并标注部分对改善模型作用最大的样本,利用少量高价值样本快速提高模型性能。每个样本的价值并不相同,高价值的样本对模型性能的改善起较大的作用,部分低价值样本不仅不能提高模型性能,甚至会对模型产生干扰[15]。因此,需要一种能够识别并选择高价值样本的学习策略对模型进行优化,进而减少手工标注量。主动学习就是为解决这一问题而提出的一种有效的学习策略。
主动学习的目的是通过创建最小训练子集来达到与全监督方法相当的标注精度。它是通过迭代选择最有价值的样本进行人工标注,将其加入到训练集中,以较少的标注样本获得更好的分类模型。主动学习在自然语言处理[16]、目标检测[17]、图像分类[18]和图像语义分割[19]等许多领域中都有应用,然而将主动学习应用于点云场景语义标注[20-21]方面的研究较少。传统的主动学习方法每次只采样一个样本进行模型更新,是目前结合主动学习进行点云场景语义标注的主流方法,这种方法在样本量较少时能获得较好的结果,但在样本量过大时需要进行多次人工标注才能获得最小训练子集。为解决上述问题,文献[22]将点云先过分割为超体素,然后通过采样超体素的方式来减少采样次数,但是这种方法依旧十分耗时,且模型精度也有待提升。
综上考虑,本文提出了一种结合排序批处理模式的主动学习点云场景语义标注方法。该方法在特征选择阶段通过改进的递归特征增加法来筛选特征子集,在保持性能不下降的情况下,避免了维度灾难,加快了运算速度;在主动学习模型训练阶段通过改进的排序批处理模式采样算法来一次采样多个样本,大大减少了主动学习迭代次数,并且能在较短时间内完成采样,减少算法本身耗时,同时这些样本可以独立并行地进行人工标注,这也变相减少了人工标注的时间。
1 点云场景语义标注方法本文提出的结合排序批处理模式的主动学习点云场景语义标注方法主要包括点云数据预处理、特征提取、特征选择、主动学习模型训练和完整点云标注5部分,算法流程如图 1所示。

|
| 图 1 本文算法 Fig. 1 The proposed method |
1.1 预处理
首先,通过孤立森林去噪滤波算法[23]剔除采集原始点云数据中的噪声;对于千万级以上的大场景点云还应进行下采样,以克服逐点标注方法对数据量敏感的缺点。然后手动选取一小部分点云数据(数量占总体的5%以内,且包含所有需要语义标注的地物类型)进行人工标注,作为主动学习模型的初始标注集,剩余点云作为未标注集。最后,为了能够获取更加具有辨识性的局部特征,采用最优邻域定义[24]来恢复每个点的局部邻域。
1.2 特征提取目前公开的点云数据集所包含的点云信息有多有少,且大多数公开数据集只包含空间三维坐标信息,因此本文只提取与三维空间信息有关的特征,以增强本文所提方法的通用性。
利用在点云的三维空间信息以及与其周围点构成的最优邻域,可以为每个点提取线性度Lλ、平面度Pλ、散射度Sλ、垂直度V和局部点密度D[24]等3D特征和2D特征值比率、2D特征熵、基于2D点及其k个邻近点形成的圆形邻域半径rk-NN,2D、局部2D点密度及积累图特征[25]等2D特征。除了上述单点特征外,本文引入FPFH[26-27]特征描述符来为点云提供更多局部特征的相关信息,FPFH特征一种基于点及其邻域点之间法向夹角、点间连线夹角关系的特征描述子,它在保留PFH特征对点描述主要几何特性的同时,降低了计算复杂度。
1.3 特征选择冗余特征和不相关的特征会增加机器学习的负担,使模型过拟合,因此进行特征选择很有必要。传统特征选择方法一般分为过滤法、包装法和嵌入法[28]。递归特征增加法[29]集合了包装法与机器学习模型交互和嵌入法推导特征重要性的优点,但是也存在着时间复杂度过高、结果不够稳定的缺陷。相关系数法能快速剔除相关性高的特征,但由于它只考虑特征而不考虑模型,并不能很好地保持模型精度;随机森林重要性方法[30]能在模型训练的同时进行特征选择,但容易过拟合。综合3种方法的优缺点,本文对递归特征增加法进行了改进,在初始阶段利用相关系数法对所有特征进行初步筛选,进而利用随机森林重要性方法对筛选特征按照特征重要性进行排序,最后运用递归特征增加法筛选出具有最佳性能的特征子集。其中,使用随机森林分类器作为递归特征增加法的基本分类器,采用F1 score作为衡量特征重要性的指标。改进的递归特征增加法(modified recursive feature addition,MRFA)流程如下:
(1) 计算特征之间的相关系数,若相关系数大于阈值,将后加入特征舍去,否则保留。
(2) 利用随机森林重要性方法对筛选特征进行排序。
(3) 构建只包含最重要特征的随机森林模型,并计算其F1 score,记为f1。
(4) 在剩余特征中选取一个最重要的特征,并利用选取的特征和之前保留的特征构建随机森林模型,并计算其F1 score,记为f2。
(5) 如果Δf=f2-f1大于所设阈值Tol,则将所选取特征保留,否则将其舍去。
(6) 重复步骤(2)—步骤(5)直到所有特征选择完毕。
1.4 主动学习模型训练主动学习模型训练是一个多次迭代的过程。在每次迭代中,由更新后的标注集对主动学习分类模型进行训练,利用分类模型对未标注集进行预测,根据预测结果和主动学习采样算法来选取一批有价值的样本交由人工标注,将人工标注好的样本加入标注集更新模型并开始下一次迭代,直到满足迭代停止条件为止,其整个流程如图 2所示。

|
| 图 2 主动学习模型训练流程 Fig. 2 Flowchart of active learning model training |
排序批处理模式采样算法[31](ranked batch-mode sampling,RBMS)是目前较为前沿的主动学习算法,但该算法也存在着时间复杂度高、精度提升慢、不适用于大规模点云数据处理的缺陷。为此,本文针对算法存在的问题,对算法3个步骤进行改进,形成了改进的排序批处理模式采样算法(modified ranked batch-mode sampling,MRBMS):
(1) 分类间距估计。排序批处理模式采样算法采用的是不确定度估计,这种方法只关注样本的最大概率类,而忽略其他类的潜在价值,为此本文引入分类间距估计[32],通过关注现有分类器最优类和次优类之间的间距来衡量样本的价值,从而弥补原算法的不足。可由式(1)导出分类间距得分Ms(x)
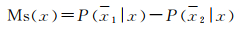 (1)
(1)
式中,x1是样本x最可能属于的类;x2是样本x第二可能属于的类;Ms(x)越小,说明样本的不确定性和价值越大。
(2) 相似度估计。相似度一般通过计算未标注样本U到标注样本L的特征空间距离来度量二者之间的相似程度,原算法直接计算所有样本之间的距离不但严重浪费内存、耗时严重,而且无法保证主动学习过程的连续性。为此本文首先采用快速最近邻逼近搜索[31]来查找与未标注样本在特征空间上最邻近的标注样本点,通过建立优先搜索K-means树来对特征的所有维度进行聚类,快速计算未标注样本U到标注样本L的特征空间距离,进而计算相似度,其计算公式为
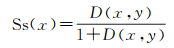 (2)
(2)
式中,x是未标注样本,y是离样本x特征空间距离最近的标注样本点,D(x, y)为x与y之间的特征空间距离,一般为欧氏距离。随着D(x, y)的增大,相似性得分Ss(x)也会增大,表明未标注样本U与已标注样本L相似度越低。
(3) 排序选择。排序批处理模式采样算法采用排序函数Fs(x)来选择有价值样本,可由式(3)来表示
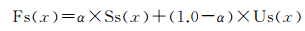 (3)
(3)
式中,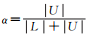
原算法通过权重α来确定不确定度得分和相似度得分的权重,可是当|U|远大于|L|且采样数量较少时,α因子几乎不变。为此本文引入新的权重因子β,权重β针对数据比例失衡问题做出了调整,随着采样次数的增加,相似度得分的权重越来越小,分类间距得分权重越来越大。新的排序函数Rs(x)可由式(4)来表示
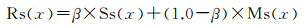 (4)
(4)
式中,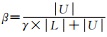
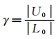
对于没有下采样的点云,只需用主动学习训练模型对未标注样本集进行预测,然后人工修正小部分标注错误的点云即可完成语义标注;而对于下采样过的点云,首先利用主动学习训练模型完成初步标注,人工修正小部分错误点,然后利用邻域等权标签传播[34]算法标注完整点云。该算法的基本思想是距离越近的点越可能具有相同的语义标签,即原始点云中的每个点的标签与该点在下采样点云中最近点的标签相同。
2 试验与分析 2.1 试验设置与评价指标为了验证本文方法的有效性,在3个不同的大规模室外场景点云上进行了试验验证。前两个场景Dataset Ⅰ、Dataset Ⅱ来自著名的Semantic 3D激光点云公开基准数据集[35];第3个场景Dataset Ⅲ来自由FARO三维激光雷达扫描仪在武汉大学校园内自采集的数据集,如图 3所示。这3个场景都存在数据集不均衡问题,例如Dataset Ⅰ、Dataset Ⅱ设施和车辆类的数量要远远小于其他类的数量,Dataset Ⅲ自行车、电动车、设施和行人4类之和不足所有类的1%。除了数据集不均衡问题外,还存在着同类变异、类间相似、相互遮挡、扫描不全等多种挑战。

|
| 图 3 试验数据集原始数据 Fig. 3 The original data of the experimental dataset |
本文试验平台为英特尔Core i5-10400F @2.90 GHZ处理器,16 GB内存,Python3.7,在开源工具(CloudCompare)上标注数据。在预处理阶段,首先将3个场景的原始点云下采样到100万点左右,然后从采样后的点云里每类分割出一小部分,进行人工标注制作成初始标注集,如图 4所示。将剩余采样后的点云制作成未标注集。Dataset Ⅰ、Dataset Ⅱ和Dataset Ⅲ初始标注集与未标注集各类具体数量可见表 1。在特征选择阶段,相关系数阈值设定为0.8,Tol= -0.01。在主动学习模型训练阶段,随机森林模型参数为默认参数,每批次采样点数量BatchSize=1000,迭代停止条件设置为迭代次数N=30。

|
| 图 4 Dataset Ⅰ—Dataset Ⅲ的初始标注集 Fig. 4 Initial annotation set of Dataset Ⅰ—Dataset Ⅲ |
| 类别 | Dataset Ⅰ | Dataset Ⅱ | Dataset Ⅲ | ||||||||
| Precision | Recall | F1 score | Precision | Recall | F1 score | Precision | Recall | F1 score | |||
| 地面 | 97.9 | 98.3 | 98.1 | 97.7 | 97.9 | 97.8 | 99.7 | 99.9 | 99.8 | ||
| 草坪 | 98.9 | 98.6 | 98.8 | 99.0 | 98.9 | 98.9 | - | - | - | ||
| 树木 | 95.2 | 95 | 95.1 | 98.6 | 97.8 | 98.2 | - | - | - | ||
| 灌木 | 92.5 | 93.8 | 93.1 | 65.2 | 84.7 | 73.6 | - | - | - | ||
| 建筑 | 90.8 | 93.5 | 92.1 | 98.5 | 98.5 | 98.5 | 97.4 | 95.3 | 96.3 | ||
| 花坛 | 99.1 | 98.3 | 98.7 | 95.1 | 93.5 | 94.3 | - | - | - | ||
| 设施 | 85.4 | 70.3 | 77.1 | 95.6 | 81.2 | 87.8 | 99.6 | 60.7 | 75.5 | ||
| 汽车 | 95.7 | 89.6 | 92.6 | 96.1 | 91.6 | 93.8 | 94.5 | 98.3 | 96.4 | ||
| 针叶林 | - | - | - | - | - | - | 96.5 | 75.9 | 85.0 | ||
| 阔叶林 | - | - | - | - | - | - | 96.3 | 98.7 | 97.5 | ||
| 自行车 | - | - | - | - | - | - | 80.1 | 50.6 | 62.0 | ||
| 电动车 | - | - | - | - | - | - | 76.6 | 42.1 | 54.3 | ||
| 行人 | - | - | - | - | - | - | 94.9 | 57.6 | 71.7 | ||
| 算术平均 | 94.4 | 92.2 | 93.2 | 93.2 | 93.0 | 92.9 | 92.8 | 75.5 | 82.1 | ||
本文主要从两方面来对点云语义标注工作进行质量评价:第一方面是通过精度(Precision)、召回率(Recall)、F1 score 3个指标来衡量本文所提方法的正确性和准确性;第二方面本文用指标SavedPoints来对语义标注方法减少的人工标注工作进行量化,它代表的是从手动标注初始标注集开始到整个点云场景标注工作完成这个过程中,机器学习算法相较于全程手工标注减少的工作量,如式(5)所示
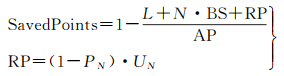 (5)
(5)
式中,AP为需要语义标注的目标总数;L为初始人工标注的样本数;N为主动学习采样次数;BS为一次采样所需人工纠正的样本个数;RP为模型完成语义标注后需要人工修正的样本个数;PN为N次查询后模型的预测精度;UN为N次查询后未标注样本个数。SavedPoints在(0, 1)之间取值,值越大说明节省人工标注工作量越大,方法效果越好。
2.2 试验结果与分析为验证本文方法的可行性,本节首先给出了本文方法在Dataset Ⅰ—Dataset Ⅲ场景下的语义标注结果,对本文方法在Dataset Ⅲ场景少数类识别结果差的原因进行了探讨,然后分析了下采样和特征选择方法对语义标注结果的影响,最终分析了主动学习模型训练部分中每批次采样点数量BatchSize对试验结果的影响。
2.2.1 试验结果初步分析图 5、图 6和图 7分别给出了Dataset Ⅰ—Dataset Ⅲ场景下采样点云与完整点云的标注结果。图 7中,不同颜色表示不同类别,从上到下依次为前视图、俯视图、侧视图及内部图。由图 5、图 6和图 7可以看出,Dataset Ⅰ和Dataset Ⅱ下采样点云基本上都能正确标注,Dataset Ⅲ的下采样点云标注结果稍差但也能将大部分类正确标注,需要人工修正的部分较少。由邻域等权标签传播算法标注的Dataset Ⅰ—Dataset Ⅲ完整点云标注结果较好,能够满足语义标注工作的需求。这也证明了本文方法在大幅减少人工标注成本方面的可行性。

|
| 图 5 Dataset Ⅰ下采样点云与完整点云标注结果 Fig. 5 Dataset Ⅰ down-sampled point cloud and complete point cloud labeling results |

|
| 图 6 Dataset Ⅱ下采样点云与完整点云标注结果 Fig. 6 Dataset Ⅱ down-sampled point cloud and complete point cloud labeling results |

|
| 图 7 Dataset Ⅲ下采样点云与完整点云标注结果 Fig. 7 Dataset Ⅲ down-sampled point cloud and complete point cloud labeling results |
表 1给出了本文算法在这3个场景下的语义标注性能。由表 1可以看出:Dataset Ⅰ和Dataset Ⅱ场景的各项性能指标都较好, 大部分类平均F1 score都在0.950以上;而Dataset Ⅲ场景的平均召回率与F1 score稍低,分别为0.755和0.821。为了解释本文算法在Dataset Ⅲ上表现稍逊的原因,统计了Dataset Ⅰ—Dataset Ⅲ每一类错误点的数量,及其占未标注类的比例,见表 2。
| 类别 | Dataset Ⅰ | Dataset Ⅱ | Dataset Ⅲ | |||||
| 错误点云 | 百分比/(%) | 错误点云 | 百分比/(%) | 错误点云 | 百分比/(%) | |||
| 地面 | 2755 | 1.94 | 1913 | 1.47 | 542 | 0.14 | ||
| 草坪 | 2336 | 0.58 | 5014 | 2.69 | - | - | ||
| 树木 | 4303 | 3.3 | 5619 | 2.38 | - | - | ||
| 灌木 | 2215 | 3.02 | 3731 | 27.20 | - | - | ||
| 建筑 | 5566 | 9.11 | 3755 | 1.06 | 9688 | 4.81 | ||
| 花坛 | 5913 | 3.76 | 2863 | 2.76 | - | - | ||
| 设施 | 289 | 42.94 | 173 | 6.14 | 974 | 33.23 | ||
| 车辆 | 377 | 3.49 | 1206 | 25.57 | - | - | ||
| 自行车 | - | - | - | - | 888 | 52.48 | ||
| 汽车 | - | - | - | - | 737 | 1.40 | ||
| 电动车 | - | - | - | - | 1208 | 51.60 | ||
| 行人 | - | - | - | - | 887 | 43.22 | ||
| 针叶林 | - | - | - | - | 4387 | 24.40 | ||
| 阔叶林 | - | - | - | - | 4247 | 1.20 | ||
由表 2可以看出,Dataset Ⅲ自行车、电动车、设施和行人类错分点数量少但所占比例高;建筑和阔叶林类所占比例低但错分点数量多。对于这一现象,一方面是由于数据集的极度不平衡导致的,自行车、电动车、设施和行人4类之和不足所有类的1%,加之本文算法在采样次数较少时更为关注数量较多的类以快速提高精度,从而导致数量较少的类标注结果变差,对于这一问题可以通过适当增加采样次数来解决。图 8给出了每次采样后Dataset Ⅲ少数类的平均F1 score变化情况。如图 8所示,随着采样次数的增加,Dataset Ⅲ少数类的平均F1 score也逐渐增加,即少数类的标注结果在逐渐变好。

|
| 图 8 Dataset Ⅲ少数类不同采样次数下的标注结果 Fig. 8 Dataset Ⅲ annotated results of minority types with different sampling times |
另一方面原因可以从Dataset Ⅲ错误点分布情况(图 9)看出,Dataset Ⅲ错分点分布大致遵循两个规律:一是相似类更容易被错分;二是孤立点更容易错分。例如自行车类与电动车类,二者大致特征本就比较相似,加之扫描不全、下采样等因素的影响,细节信息损失严重,二者错分的概率大大增加。针叶林与建筑物内部都存在着扫描不全导致的孤立点问题,由于主动学习本来利用的训练样本就少,再加上孤立点群没有明显的特征,故其更容易被错分。除此之外,类与类的边缘也是错分点分布较多的地方,可是类的边缘点所属类本就难以定义,特别是在所属类没有明显边缘特征的情况下,边缘点的分类结果对整体标注结果影响不大。

|
| 注:红色表示错误标注的点,灰色表示正确标注的点。 图 9 Dataset Ⅲ场景标注错误点分布 Fig. 9 Dataset Ⅲ scene labeling error points distribution |
2.2.2 下采样对语义标注结果影响分析
为分析下采样处理对语义标注结果的影响,本节分别用直接对完整点云进行标注和先下采样后标签传播两种处理模式对Dataset Ⅲ场景进行标注,其中完整点云的采样点数量BatchSize=5800,其他条件设置与下采样点云一致,具体结果见表 3。
| Dataset Ⅲ | 数量 | 精度 | 平均F1 score | 最大SavedPoints | 时间成本/min | 人工成本 |
| 下采样点云+标签传播 | 1 044 234 | 0.976 9 | 0.821 | 0.941 7 | 99.0 | 60 879 |
| 完整点云 | 5 846 343 | 0.986 6 | 0.851 | 0.952 1 | 598.0 | 280 040 |
| 注:人工成本为完成整个标注工作所需人工标注点的数量,越小越好;下采样处理模式的标签传播精度接近100%,这是因为在传播之前,下采样点云已经进行了人工修正。 | ||||||
由表 3可知,对点云下采样会使标注精度有所下降,但在精度和时间成本之间取得均衡,下采样处理模式相比于直接处理模式能节省近5倍的时间成本和近4倍的人工成本,对于大场景点云来说,采用下采样处理模式能更省时、省力。
2.2.3 特征选择对语义标注结果影响分析为评估本文所提出的特征选择方法的有效性,本节测试了经过特征选择后的特征子集与全部特征集合各自的语义标注结果,具体见表 4。
| 指标 | 特征选择+主动学习 | 主动学习 | |||||
| Dataset Ⅰ | Dataset Ⅱ | Dataset Ⅲ | Dataset Ⅰ | Dataset Ⅱ | Dataset Ⅲ | ||
| 特征个数 | 20 | 21 | 16 | 59 | 59 | 59 | |
| 平均F1 score | 0.932 | 0.929 | 0.821 | 0.934 | 0.931 | 0.806 | |
| SavedPoints | 0.925 | 0.927 | 0.942 | 0.928 | 0.925 | 0.943 | |
| 采样次数N | 17 | 12 | 8 | 17 | 13 | 8 | |
| 每次采样时间/s | 62.3 | 65.6 | 71.8 | 93.8 | 95.4 | 109.3 | |
| 注:采样次数为达到最大SavedPoints所需采样次数。 | |||||||
由表 4可知,经过特征选择后的特征子集能在保持性能基本不变的情况下,为采样算法缩短将近1/3的时间,这无疑能帮助本文算法在时间成本上获得优势。
2.2.4 采样点数量BatchSize对语义标注结果影响分析为分析每批次采样点数量BatchSize不同取值对语义标注结果的影响,本节统计了不同BatchSize值所对应的节省人工成本SavedPoints、平均F1 score和完成采样所需时间,其中总采样点数TN不变(TN=30 000),结果如图 10所示。

|
| 图 10 每批次采样点数量BatchSize对语义标注工作的影响 Fig. 10 The influence of the number of sampling points in each batch BatchSize on semantic annotation work |
由图 10可知,随着BatchSize的增大,平均F1 score和采样时间呈下降趋势,SavedPoints先增加后减少。这是因为主动学习算法依赖于小批次的多次迭代来改善模型精度。当一次采样过多样本后反而会产生较差的结果。综合考虑采样时间、平均F1 score及SavedPoints值,本文选取BatchSize=1000作为理想批次采样点数量。
2.3 标注结果和节省人工成本对比分析为进一步分析本文算法的有效性,将本文方法与RBS[30]、EBS[36]、RBMS[31] 3种方法进行了对比分析。RBS、EBS、RBMS和本文方法的初始样本集、未标注样本集、参数设置等外在条件均相同。首先对比了4种方法在不同采样次数下的标注平均精度和节省的人工成本情况,然后对比了4种方法在相同采样次数下标注结果以及时间成本。
2.3.1 不同采样次数下对比分析图 11—图 13给出了本文方法与其他3种方法每次采样后Dataset Ⅰ—Dataset Ⅲ的标注平均精度和节省的人工成本情况。其中,每次采样所需人工纠正的样本个数都按最坏情况算,即取BS=1000,在实际情况下,每次需要人工纠正的样本数要小于它,且随着采样次数增加,每次需要纠正样本数会越来越少,即节省的人工成本SavedPoints比实际情况偏小。

|
| 图 11 RBS、EBS、本文方法、RBMS在Dataset Ⅰ的标注结果 Fig. 11 Average labeling results achieved by the RBS、EBS、ours、RBMS on Dataset Ⅰ |

|
| 图 12 RBS、EBS、本文方法、RBMS在Dataset Ⅱ的标注结果 Fig. 12 Average labeling results achieved by the RBS、EBS、ours、RBMS on Dataset Ⅱ |

|
| 图 13 RBS、EBS、本文方法、RBMS在Dataset Ⅲ的标注结果 Fig. 13 Average labeling results achieved by the RBS、EBS、ours、RBMS on Dataset Ⅲ |
由图 11—图 13可以看出,Dataset Ⅰ—Dataset Ⅲ分别在采样次数N=12、17、8时,达到最大SavedPoints,分别为0.925 0、0.926 5和0.941 7, 这代表着利用本文方法最多只需人工标注7.50%、7.35%、5.83%的点云即可完成Dataset Ⅰ—Dataset Ⅲ下采样点云的标注工作。除此之外,Dataset Ⅰ—Dataset Ⅲ场景的平均精度随着采样次数增加而不断增加,而SavedPoints却随着采样次数的增加先增加后减少。这是因为随着采样次数的不断增加,模型慢慢趋于稳定,未标注集数量也在不断减少,当达到峰值之后,每次人工标注样本带来的精度提升并不足以抵消人工标注样本本身带来的人工成本。而且通过对比,本文方法在精度和节省的人工成本方面相较于其他3种方法都有较大的优势,达到最大SavedPoints所需采样次数也少于其他方法,这也表明了本文方法在减少人工成本方面的优越性。
2.3.2 相同采样次数下对比分析表 5显示了4种方法在相同采样次数下的平均精度、召回率、F1 score及运行时间。其中,选取在Dataset Ⅰ—Dataset Ⅲ场景里达到最大SavedPoints所需采样次数N作为试验参数。由表 5可知,本文方法在Dataset Ⅰ、Dataset Ⅱ场景下的平均精度、召回率和F1 score比其他3种方法高5%~8%;即使在难度较大的Dataset Ⅲ场景下,本文方法也比另外3种方法表现要好。这也进一步表明本文方法在标注结果精度方面的优越性。
| 数据集 | 算法 | 评价指标/(%) | 运行时间/min | ||
| Precision | Recall | F1 score | |||
| Dataset Ⅰ (N=12) |
RBS | 86.3 | 84.6 | 84.0 | 59.0 |
| EBS | 83.8 | 82.1 | 81.2 | 59.0 | |
| RBMS | 85.8 | 84.1 | 83.3 | 61.0 | |
| 本文方法 | 94.4 | 92.2 | 93.2 | 61.3 | |
| Dataset Ⅱ (N=17) |
RBS | 88.4 | 87.8 | 87.0 | 72.5 |
| EBS | 81.9 | 82.5 | 79.3 | 72.4 | |
| RBMS | 84.7 | 88.1 | 86.3 | 76.3 | |
| 本文方法 | 93.2 | 93.0 | 92.9 | 76.9 | |
| Dataset Ⅲ (N=8) |
RBS | 93.1 | 72.5 | 79.8 | 69.0 |
| EBS | 90.3 | 64.4 | 71.9 | 68.7 | |
| RBMS | 92.7 | 74.1 | 81.0 | 70.5 | |
| 本文方法 | 92.8 | 75.5 | 82.1 | 71.1 | |
在时间成本方面,本文方法在相同采样次数下的时间上虽不占优,但与其他方法相差不大,若以达到各自最大节省人工成本的时间为标准(本文方法达到最大节省人工成本所需采样次数小于其他方法),本文方法在时间上还会优于其他方法。总体而言,本文方法能在较短时间内,利用小部分人工标注样本完成整个点云的标注,大大减少了场景点云语义标注的人工成本。
3 结语为了减少点云场景语义标注的人工成本,本文提出了一种结合排序批处理模式的主动学习点云场景语义标注方法。该方法具有很好的通用性,只需要点云的三维空间信息即可完成整个标注过程;提出了改进的递归特征增加法来筛选特征子集,在保持性能不下降的情况下,避免了维度灾难,加快了运算速度;在点云场景语义标注中引入了主动学习方法,只需要人工标注很小部分样本即可完成整个场景点云的语义标注工作;提出了改进的排序批处理模式采样算法,能够更快速、有效地挑选出最有价值的样本;利用邻域等权标签传播算法能够由标注好的下采样点云快速、准确地获取整个场景点云的语义标注结果。在3个数据集上,利用本文方法只需人工标注7.50%、7.35%、5.83%的点云即可完成下采样点云的标注工作。而且通过相关指标比较表明,本文方法在标注精度和减少人工成本方面优于其他方法。综上所述,本文方法能为点云语义标注工作节省大量人工成本。
| [1] |
李德仁, 邵振峰, 于文博, 等. 基于时空位置大数据的公共疫情防控服务让城市更智慧[J]. 武汉大学学报(信息科学版), 2020, 45(4): 475-487, 556. LI Deren, SHAO Zhenfeng, YU Wenbo, et al. Public epidemic prevention and control services based on big data of spatio-temporal location make cities more smart[J]. Geomatics and Information Science of Wuhan University, 2020, 45(4): 475-487, 556. |
| [2] |
刘经南, 詹骄, 郭迟, 等. 智能高精地图数据逻辑结构与关键技术[J]. 测绘学报, 2019, 48(8): 939-953. LIU Jingnan, ZHAN Jiao, GUO Chi, et al. Data logic structure and key technologies on intelligent high-precision map[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(8): 939-953. DOI:10.11947/j.AGCS.2019.20190125 |
| [3] |
李德仁, 姚远, 邵振峰. 智慧城市中的大数据[J]. 武汉大学学报(信息科学版), 2014, 39(6): 631-640. LI Deren, YAO Yuan, SHAO Zhenfeng. Big data in smart city[J]. Geomatics and Information Science of Wuhan University, 2014, 39(6): 631-640. |
| [4] |
杨必胜, 董震. 点云智能研究进展与趋势[J]. 测绘学报, 2019, 48(12): 1575-1585. YANG Bisheng, DONG Zhen. Progress and perspective of point cloud intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(12): 1575-1585. DOI:10.11947/j.AGCS.2019.20190465 |
| [5] |
ZHAO Bufan, HUA Xianghong, YU Kegen, et al. Indoor point cloud segmentation using iterative Gaussian mapping and improved model fitting[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(11): 7890-7907. DOI:10.1109/TGRS.2020.2984943 |
| [6] |
ZHANG Liangpei, ZHANG Yun, CHEN Zhenzhong, et al. Splitting and merging based multi-model fitting for point cloud segmentation[J]. Journal of Geodesy and Geoinformation Science, 2020, 2(2): 78-89. |
| [7] |
蒋腾平, 王永君, 张林淇, 等. 融合CNN和MRF的激光点云层次化语义分割方法[J]. 测绘学报, 2021, 50(2): 215-225. JIANG Tengping, WANG Yongjun, ZHANG Linqi, et al. A LiDAR point cloud hierarchical semantic segmentation method combining CNN and MRF[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(2): 215-225. DOI:10.11947/j.AGCS.2021.20220095 |
| [8] |
LI S Z. Markov random field modeling in image analysis[M]. London: Springer Science & Business Media, 2009.
|
| [9] |
LI Yan, DAI Jicheng, TAN Junxiang, et al. Global fine registration of point cloud in LiDAR SLAM based on pose graph[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(2): 26-35. |
| [10] |
ANAND A, KOPPULA H S, JOACHIMS T, et al. Contextually guided semantic labeling and search for 3D point clouds[J]. International Journal of Robotics Research, 2011, 32(1): 19-34. |
| [11] |
MUNOZ D, VANDAPEL N, HEBERT M. Onboard contextual classification of 3D point clouds with learned high-order Markov random fields[C]//Proceedings of 2009 IEEE International Conference on Robotics and Automation. Kobe, Japan: IEEE, 2009.
|
| [12] |
LI Zhuqiang, ZHANG Liqiang, ZHONG Ruofei, et al. Classification of urban point clouds: a robust supervised approach with automatically generating training data[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2016, 10(3): 1207-1220. |
| [13] |
WANG Yan, JI Rongrong, CHANG Shifu. Label propagation from imagenet to 3D point clouds[C]//Proceedings of 2013 IEEE conference on computer vision and pattern recognition. Portland, OR, USA: IEEE, 2013: 3135-3142.
|
| [14] |
FLOROS G, LEIBE B. Joint 2D-3D temporally consistent semantic segmentation of street scenes[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012: 2823-2830.
|
| [15] |
FU Yifan, ZHU Xingquan, LI Bin. A survey on instance selection for active learning[J]. Knowledge and Information Systems, 2013, 35(2): 249-283. DOI:10.1007/s10115-012-0507-8 |
| [16] |
WANG Yu, MENDEZ A E M, CARTWRIGHT M, et al. Active learning for efficient audio annotation and classification with a large amount of unlabeled data[C]//Proceedings of 2019 ICASSP International Conference on Acoustics, Speech and Signal Processing. Brighton, UK: IEEE, 2019: 880-884.
|
| [17] |
THOMAS H, QI C R, DESCHAUD J E, et al. Kpconv: flexible and deformable convolution for point clouds[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019: 6411-6420.
|
| [18] |
YANG L, MACEACHREN A M, MITRA P, et al. Visually-enabled active deep learning for (geo) text and image classification: a review[J]. ISPRS International Journal of Geo-Information, 2018, 7(2): 65. DOI:10.3390/ijgi7020065 |
| [19] |
VEZHNEVETS A, BUHMANN J M, FERRARI V. Active learning for semantic segmentation with expected change[C]//Proceedings of 2012 IEEE conference on computer vision and pattern recognition. Providence, RI, USA: IEEE, 2012: 3162-3169.
|
| [20] |
LIN Y, VOSSELMAN G, CAO Y, et al. Active and incremental learning for semantic ALS point cloud segmentation[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 169: 73-92. DOI:10.1016/j.isprsjprs.2020.09.003 |
| [21] |
罗欢. 高分辨率激光扫描点云语义标注研究[D]. 厦门: 厦门大学, 2017. LUO Huan. Research on semantic labeling of high-resolution laser scanning point clouds[D]. Xiamen: Xiamen University, 2017. |
| [22] |
LUO H, WANG C, Wen C, et al. Semantic labeling of mobile LiDAR point clouds via active learning and higher order MRF[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(7): 3631-3644. DOI:10.1109/TGRS.2018.2802935 |
| [23] |
ADAMS A, GELFAND N, DOLSON J, et al. Gaussian kd-trees for fast high-dimensional filtering[M]. New York: ACM press, 2009: 1-12.
|
| [24] |
WEINMANN M, JUTZI B, HINZ S, et al. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 105: 286-304. DOI:10.1016/j.isprsjprs.2015.01.016 |
| [25] |
MALLET C, BRETAR F, ROUX M, et al. Relevance assessment of full-waveform LiDAR data for urban area classification[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2011, 66(6): S71-S84. DOI:10.1016/j.isprsjprs.2011.09.008 |
| [26] |
TAO Wuyong, HUA Xianghong, WANG Ruisheng, et al. Quintuple local coordinate images for local shape description[J]. Photogrammetric Engineering & Remote Sensing, 2020, 86(2): 121-132. |
| [27] |
TAO Wuyong, HUA Xianghong, YU Kegen, et al. A pipeline for 3D object recognition based on local shape description in cluttered scenes[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 59(1): 801-816. |
| [28] |
WEINMANN M, JUTZI B, MALLET C. Feature relevance assessment for the semantic interpretation of 3D point cloud data[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2013, 5(W2): 1. |
| [29] |
GUYON I, WESTON J, BARNHILL S, et al. Gene selection for cancer classification using support vector machines[J]. Machine learning, 2002, 46(1): 389-422. |
| [30] |
GR MPING U. Variable importance assessment in regression: linear regression versus random forest[J]. The American Statistician, 2009, 63(4): 308-319. |
| [31] |
CARDOSO T N C, SILVA R M, CANTUO S, et al. Ranked batch-mode active learning[J]. Information Sciences, 2017, 379: 313-337. |
| [32] |
LEWIS D D, GALE W A. A sequential algorithm for training text classifiers[C]//Proceedings of 1994 SIGIR. London, UK: Springer, 1994: 3-12.
|
| [33] |
BRANDT J. Transform coding for fast approximate nearest neighbor search in high dimensions[C]//Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010: 1815-1822.
|
| [34] |
XU S, WANG R, WANG H, et al. An optimal hierarchical clustering approach to mobile LiDAR point clouds[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(7): 2765-2776. |
| [35] |
HACKEL T, SAVINOV N, LADICKY L, et al. Semantic 3D.net: a new large-scale point cloud classification benchmark[J]. ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2017, IV-1/W1: 91-98. |
| [36] |
PATRA S, BRUZZONE L. A batch-mode active learning technique based on multiple uncertainty for SVM classifier[J]. IEEE Geoscience and Remote Sensing Letters, 2011, 9(3): 497-501. |