



2. 武汉大学测绘遥感信息工程国家重点实验室, 湖北 武汉 430079;
3. 武汉大学遥感信息工程学院,湖北 武汉 430079
2. State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan 430079, China;
3. School of Remote Sensing and Information Engineering, Wuhan University, Wuhan 430079, China
高光谱遥感影像具有光谱分辨率高和图谱合一的优势,其丰富的光谱信息可对不同地物的属性信息进行精细的检测和识别[1-2]。目前,高光谱遥感已成为地物精细区分的重要技术手段,在资源调查、农作物分类、树种识别、矿物填图等方面都有着广泛的应用[3]。
早期的高光谱遥感地物精细分类识别主要基于星载和航空有人机载高光谱观测平台[3]。近十年来,随着无人机的有效载荷和续航时间的不断提高,以及轻型高光谱成像传感器的快速发展,无人机高光谱遥感已经成为一种新兴的对地观测技术,实现对星载和航空有人机载高光谱成像系统的有效补充[4]。无人机高光谱观测平台可以同时获得高光谱分辨率(纳米级)和高空间分辨率(厘米级)的遥感影像,也称为“双高影像”[5]。双高影像不仅可以精细表征地物光谱信息,而且包含地物丰富的空间纹理信息。同时,相比于星载和航空有人机载高光谱观测平台,无人机高光谱观测平台具有操作灵活、采集成本低、作业周期短和实时数据采集的优点。
然而,相比于星载或航空有人机载的中低分辨率高光谱遥感影像,无人机双高影像极高的空间分辨率使得地物细节大量凸显出来,同物异谱现象大量发生,地物类内方差明显增大,光谱特征统计分布更加复杂,地物光谱信息的统计可分性严重减弱[5-8]。因此,只利用光谱信息分类的方法(例如支持向量机、随机森林等方法)在双高影像分类结果中存在严重的椒盐噪声[5]。因此,针对无人机双高影像地物分类需要同时考虑双高影像精细的光谱属性信息和丰富的空间纹理信息。传统的空-谱融合策略引入空间信息方法主要分为两种。一种是通过级联光谱信息和手工设计的空间特征作为分类器的输入,其中空间特征包括纹理、形状和对象分割等[9]。另一种是引入空间上下文信息的后处理方法,例如引入马尔可夫随机场[10-11]、条件随机场[12-13]等。然而,这些方法非常依赖专家知识的手工特征设计,其手工特征面向特定分类任务,限制了其在复杂地物分布下的模型泛化能力[14-15]。
随着人工智能的蓬勃发展,深度学习技术因其强大的特征提取和泛化能力,被越来越多的学者应用在高光谱影像分类中。目前深度学习高光谱影像分类主要基于两种策略。一种是基于“空间块”的分类策略,该策略以标记像元为中心选取邻域的三维“空间块”作为网络的输入,输出中心像元的类别标签,例如栈式自动编码器SAE-LR[15]、深度三维卷积网络[16]、图卷积分类网络[17]等。然而,该类分类方法在双高影像分类中面临两个问题。一方面,“空间块”的最优尺寸受到空间分辨率和地物分布等多种因素的影响,导致“空间块”的最优尺寸难以确定,且不同影像的最优尺寸存在差异[6];另一方面,“空间块”仅利用了标记像元周围局部空间信息,缺乏对长距离或全局空间信息的考虑,导致在空谱异质性极高的双高影像分类结果中出现严重的错分孤立区域现象。另一种是将全局影像作为输入的“端到端”分类策略[6]。文献[18]首次提出快速全卷积深度网络实时分类框架FPGA实现全局空谱融合,相比于“空间块”深度学习模型,其速度和精度得到了极大的提升。然而,FPGA方法受到卷积核的限制无法捕获大范围的像素依赖关系,对于类内方差较大的地物仍会存在错分现象,尤其是用于空谱异质性极高的双高影像分类。随后,一些高光谱影像分类网络引入全局上下文信息解决地物类内方差大的问题,例如空-谱全卷积高光谱分类网络SSFCN-CRF[19]、高效非局部全卷积网络ENL-FCN[20]、全上下文感知网络FullyContNets[21]等。然而,仅利用全局上下文信息模型会导致计算复杂,且对一些狭窄或者弱小地物分类时局部上下文信息同样重要。
为此,针对当前高光谱影像分类方法在双高遥感影像分类时缺乏考虑局部上下文信息的情况,本文提出一种局部-全局上下文信息自适应聚合的高精度快速双高影像分类框架,本文称为ACANet(adaptive context aggregation network)。该框架基于全卷积网络架构,分为编码器和解码器。在编码器中,为了充分提取长距离上下文信息并减少网络模型参数,设计局部到全局的长距离上下文提取方式。对于高分辨的输入特征图,采用局部上下文信息模块(local context module,LCM)捕获长距离上下文信息,降低计算复杂度。对于低分辨的高层次语义特征图,采用全局上下文信息模块(global context module,GCM)从局部上下文特征中进一步捕获全局上下文信息。在解码器中,自适应上下文聚合模块(adaptive aggregation module,AAM)对编码器中的局部和全局长距离上下文特征以及解码器中的上一层高级语义特征进行自适应加权聚合,实现双高影像的准确分类。综上所述,本文的创新点如下:
(1) 本文在编码器中设计一种局部到全局上下文信息感知的网络架构,实现顾及长距离上下文信息的高级语义特征提取,缓解双高影像空谱异质性造成错分孤立区域的现象。
(2) 本文在解码器设计的自适应上下文聚合模块可以自适应地关注不同的上下文信息以应对地物尺寸对分类性能的影响。
1 本文方法本文方法(ACANet)的总体流程如图 1所示。该网络以整张高光谱影像作为输入,可以顾及全局空谱信息。在编码器中,本文使用局部到全局的长距离上下文感知模块,可以有效缓解双高影像极高空谱异质性导致的孤立区域错分现象。在解码器中,采用自适应上下文聚合模块自适应对局部上下文特征、全局上下文语义特征和上一层网络输出的高级语义特征进行通道加权融合,最终将特征图输入到Softmax分类器中,输出每个像素的分类结果。

|
| 图 1 基于自适应上下文聚合的双高影像精细网络 Fig. 1 Flowchart of adaptive context aggregation network for H2 imagery classification |
1.1 局部上下文信息模块
局部上下文信息模块采用条带池化操作[22],网络结构如图 2所示,其主要利用条带池化操作来获取局部长距离上下文信息。对于输入特征图X∈RC×H×W的第C个通道Xc∈RH×W,其输出局部上下文特征图Xc∈RH×W公式如下
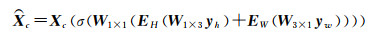 (1)
(1)

|
| 图 2 局部上下文信息模块结构 Fig. 2 Network structure diagram of local context module |
式中, yh∈RH×1和yw∈R1×W分别表示横向条带池化和纵向条带池化输出的特征向量,其公式可以表示为
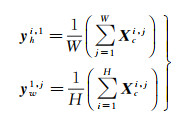 (2)
(2)
如式(2)所示,条带池化操作是对输入特征Xc的行或列中的所有特征值进行平均,因此其可以捕获每个像素长距离横向和纵向的上下文信息。式(1)中,W1×3和W3×1分别表示1维卷积,其分别捕获yh和yw邻域的特征;EH和EW表示对1维卷积输出的特征在横向和纵向进行扩展,使其与输入的特征图Xc尺寸一致;W1×1和σ表示对相加融合的扩展特征y使用1×1的卷积和Sigmod函数,最后将输出每个像素的编码权重与输入特征Xc进行逐像素加权。
1.2 全局上下文信息模块全局上下文信息模块GCM对的网络结构如图 3所示,其假设全局上下文信息受空间位置影响较小,进而将全局上下文信息转换为通道之间的依赖[23]。GCM分为全局上下文建模、通道依赖关系转换和特征融合3部分。对于输入特征图X∈RC×H×W, 其输出的全局上下文特征图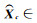
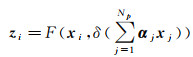 (3)
(3)

|
| 图 3 全局上下文信息模块结构 Fig. 3 Network structure diagram of global context modul |
式中,i=1, 2, …, Np(Np表示特征图的像素个数);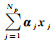
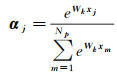 (4)
(4)
式中,Wk表示1个1×1的卷积。
式(3)中δ(·)表示通道依赖关系转换函数,用来捕获通道间的依赖关系,其公式可以表示为
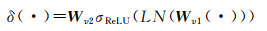 (5)
(5)
式中,Wv1表示r个1×1的卷积;LN表示层归一化;σReLU表示ReLU激活函数;Wv2表示C个1×1的卷积。
式(3)中F(., .)表示特征融合聚合全局上下文特征到每个位置的特征上,具体采用逐通道相加融合的方式。
1.3 自适应上下文信息模块针对地物精细分类所需的场景不同,其对应的局部上下文特征和全局上下文特征对分类性能提升的重要性存在差异。基于此,本文提出自适应上下文信息模块AAM,引入通道注意力机制[24]实现表征底层细节的全局上下文特征和表征高级语义信息的全局上下文特征自适应融合。如图 4所示,该模块的输入包括3部分,分别是局部上下文特征X1、全局上下文特征X2和上一层输出的高级语义信息X3。随后,针对级联后的特征X=X1, X2, X3,首先通过全局平均池化操作建模全局空间信息,输出一维特征向量S∈R1×1×C,其公式可以表示为
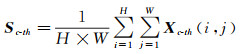 (6)
(6)

|
| 图 4 自适应上下文信息聚合模块结构 Fig. 4 Network structure diagram of adaptive aggregation module |
式中,Xc-th和Sc-th表示第C个通道的特征。为降低模型参数和提升特征提取能力,通过一个两层的神经网络捕获通道间的非线性关系映射,并且对第一层网络的特征通道进行降维。随后,该映射关系通过Sigmod函数输出每个通道的权重,其公式可以表示为
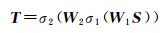 (7)
(7)
式中,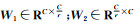
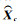
 (8)
(8)
本文试验数据采用WHU-Hi无人机双高影像数据集。WHU-Hi数据集是由武汉大学RSIDEA团队发布的无人机高光谱影像分类基准数据集[5],其包含多个不同的典型地物分类场景。本文选取的WHU-Hi-HongHu和WHU-Hi-HanChuan场景,数据集信息如图 5所示,详细描述如下。

|
| 图 5 WHU-Hi双高影像分类基准数据集 Fig. 5 Wuhan UAV-borne H2 imagery (WHU-Hi) dataset |
(1) WHU-Hi-HongHu数据。数据采集地点为湖北省洪湖市典型的复杂农业区域,采集时间为2017年11月20日16:23—17:37,数据采集期间天气阴天多云,气温约8℃,空气相对湿度约为55%。采集平台为大疆M600pro无人机搭载的Nano-Hyperspec-VNIR成像光谱仪,成像光谱仪采用17 mm焦距的镜头,飞行高度为100 m,空间分辨率为0.043 m,影像尺寸为940×475像素,在400~1000 nm波谱范围内有270个谱段。研究区土地破碎化异常严重,单个地块面积非常小,共种植了棉花、油菜、白菜、包菜等17种作物。
(2) WHU-Hi-HanChuan数据。数据采集地点为湖北省汉川市典型的城乡接合区域,采集时间为2016年6月17日17:57—18:46,数据采集期间天气晴朗无风,气温约30℃,空气相对湿度约70%。采集平台为莱卡Aibot X6无人机搭载的Nano-Hyperspec-VNIR成像光谱仪,成像光谱仪采用17 mm焦距的镜头,飞行高度为250 m,空间分辨率为0.109 m,影像尺寸为1217×303像素,在400~1000 nm波谱范围内有274个谱段。采集区域内共包含房屋、道路、农作物和水体等16类地物,其中包含草莓、豇豆、大豆、高粱等7类农作物。由于数据集采集时间在下午,太阳高度角较低,并且研究区内存在较高的建筑物和树木等,导致影像中有很多阴影覆盖区域。
2.2 参数设置(1) 训练样本设置。如表 1所示,从每个类中随机选取50个标记像素进行模型训练,剩余的标记样本用于模型测试。训练样本占全部标注样本的比例非常小,仅为WHU-Hi-HongHu和WHU-Hi-HanChuan标注像素比例的0.28%和0.31。
| 数据集 | 序号 | 类别名称 | 训练样本 | 测试样本 |
| WHU-Hi-HongHu | C1 | 红色屋顶 | 50 | 13 991 |
| C2 | 道路 | 50 | 3462 | |
| C3 | 裸土 | 50 | 21 771 | |
| C4 | 棉花 | 50 | 163 235 | |
| C5 | 棉花柴 | 50 | 6168 | |
| C6 | 油菜 | 50 | 44 507 | |
| C7 | 白菜 | 50 | 24 053 | |
| C8 | 小白菜 | 50 | 4004 | |
| C9 | 包菜 | 50 | 10 769 | |
| C10 | 榨菜 | 50 | 12 344 | |
| C11 | 菜苔 | 50 | 10 965 | |
| C12 | 青菜 | 50 | 8904 | |
| C13 | 小青菜 | 50 | 22 457 | |
| C14 | 莴苣 | 50 | 7306 | |
| C15 | 青莴苣 | 50 | 952 | |
| C16 | 薄膜覆盖的莴苣 | 50 | 7212 | |
| C17 | 罗马生菜 | 50 | 2960 | |
| C18 | 胡萝卜 | 50 | 3167 | |
| C19 | 白萝卜 | 50 | 8662 | |
| C20 | 蒜苗 | 50 | 3436 | |
| C21 | 蚕豆 | 50 | 1278 | |
| C22 | 柿子树 | 50 | 3990 | |
| WHU-Hi-HanChuan | C1 | 草莓 | 50 | 44 685 |
| C2 | 豇豆 | 50 | 22 703 | |
| C3 | 大豆 | 50 | 10 237 | |
| C4 | 高粱 | 50 | 5303 | |
| C5 | 空心菜 | 50 | 1150 | |
| C6 | 西瓜 | 50 | 4483 | |
| C7 | 绿色植物 | 50 | 5853 | |
| C8 | 树 | 50 | 17 928 | |
| C9 | 草地 | 50 | 9419 | |
| C10 | 红色屋顶 | 50 | 10 466 | |
| C11 | 灰色屋顶 | 50 | 16 861 | |
| C12 | 塑料薄膜 | 50 | 3629 | |
| C13 | 裸土 | 50 | 9066 | |
| C14 | 道路 | 50 | 18 510 | |
| C15 | 明亮物体 | 50 | 1086 | |
| C16 | 水体 | 50 | 75 351 |
(2) 模型参数设置。如表 2所示,ACANet的详细架构包括3个局部上下文信息模块、一个全局上下文信息模块和3个自适应上下文聚合模块。在模型训练中,采用随机梯度下降(SGD)方法模型参数优化,其中训练最大迭代次数、初始学习率、动量、伽马和权重衰减分别设置为:1500、0.003、0.9、0.1和0.001。
| 网络架构 | 输入尺寸 | 模型参数 | 输出尺寸 | |
| 编码器 | Conv 3×3 | H×W×C | 3×3, 64, stride 1 | H×W×64 |
| LCM 1-Conv 3×3 | H×W×64 | 3×3, 128, stride 1 | H×W×128 | |
| Down 2 | H×W×128 | - | 1/2H×1/2W×128 | |
| LCM 2-Conv 3×3 | H×W×128 | 3×3, 192, stride 1 | 1/2H×1/2W×192 | |
| Down 2 | H×W×192 | - | 1/4H×1/4W×192 | |
| LCM 3-Conv 3×3 | 1/4H×1/4W×192 | 3×3, 256, stride 1 | 1/4H×1/4W×256 | |
| Down 2 | 1/4H×1/4W×256 | - | 1/8H×1/8W×256 | |
| GCM | 1/8H×1/8W×256 | - | 1/8H×1/8W×256 | |
| 解码器 | Conv 1×1-Up2 | 1/8H×1/8W×256 | 3×3, 256, stride 1 | 1/4H×1/4W×256 |
| Connect | 1/4H×1/4W×192 | 1×1, 256, stride 1 | 1/4H×1/4W×768 | |
| 1/4H×1/4W×256 | - | |||
| 1/8H×1/8W×256 | 1×1, 256, stride 1, Up 2 | |||
| AAM 1 | 1/4H×1/4W×768 | r=16 | 1/4H×1/4W×768 | |
| Conv1×1-Up2x | 1/4H×1/4W×768 | 1×1, 192, stride 1 | 1/2H×1/2W×192 | |
| Connect | 1/2H×1/2W×128 | 1×1, 192, stride 1 | 1/2H×1/2W×576 | |
| 1/2H×1/2W×192 | - | |||
| 1/8H×1/8W×256 | 1×1, 192, stride 1, Up 4 | |||
| AAM 2 | 1/2H×1/2W×576 | r=16 | 1/2H×1/2W×576 | |
| Conv1×1-Up2x | 1/2H×1/2W×576 | 1×1, 128, stride 1 | H×W×128 | |
| Connect | 1/2H×1/2W×64 | 1×1, 128, stride 1 | H×W×384 | |
| 1/2H×1/2W×128 | - | |||
| 1/8H×1/8W×256 | 1×1, 128, stride 1, Up 8 | |||
| AAM | H×W×384 | 1×1, 384, stride 1 | H×W×384 | |
| Conv 1×1 | H×W×384 | 1×1, 64, stride 1 | H×W×64 | |
| 注:输入尺寸为H×W×C;输出尺寸为H×W。 | ||||
(3) 对比方法设置。本文采用4类不同形式的7种分类方法进行对比试验。第1类方法是逐像素光谱分类的支持向量机(SVM)[25],其采用高斯核函数,利用五折交叉验证的方式进行选择惩罚参数C和核函数的参数g。第2类方法为基于空间取块机制的深度学习方法,包括空谱注意力网络(SSAN)[26]、空谱残差网络(SSRN)[27]和深度残差金字塔网络(PResNet)[28], SSAN方法输入空间块大小和主成分个数分别设置为27×27和4,SSRN和PResNet方法输入空间块大小分别设置为7×7×C和11×11×C,其中C是波段数。第3类方法是引入光谱注意力机制的全卷积高光谱分类网络(FPGA)[18]。第4类方法为联合卷积神经网络和条件随机场的方法,包括联合卷积神经网络和马氏距离约束的条件随机场(CNNCRF)[5]和联合空谱全卷积网络和密集条件随机场的方法(SSFCN-CRF)[19]。其中,CNNCRF方法输入空间块大小设置为9×9×C。最后,本文使用的定量精度评价指标包括总体精度(OA)、平均精度(AA)、Kappa系数和每类地物的生产者精度。
2.3 试验结果分析(1) WHU-Hi-HongHu试验结果。数据集的分类结果如图 6所示,定量评价指标如表 3所示。由于不同地物之间光谱相似和双高影像严重的空谱异质性,SVM的分类结果中出现大量错分的椒盐噪声现象。相比于SVM,基于深度学习的高光谱分类方法在视觉性能和定量评估方面都有很大的提升。基于空间取块机制的SSAN、SSRN和PresNet 3种方法的OA相比于SVM分别提高了11.42%、18.52%和23.99%,但是空间取块机制只能利用局部空间信息,该类方法仍然存在严重的错分孤立区域。CNNCRF和SSFCN-CRF方法引入了空间上下文信息以极大地缓解分类图中的孤立区域,其OA相比SVM分别提升23.59%和22.79%。然而,由于该类方法条件随机场的一元势能存在误差,分类结果中仍存在少量误分类区域。FPGA方法同时顾及全局光谱和空间信息,取得了优异的视觉表现和定量评价指标,其OA相比SVM提升28.29%。但是,该类方法针对一些异质性较大的区域仍会存在一定错分。相比于FPGA, 本文提出的ACANet方法充分利用局部和全局长距离上下文依赖信息改善异质性较大区域的地物错分,取得了最优的视觉表现和定量评价指标。

|
| 图 6 WHU-Hi-HongHu数据分类结果 Fig. 6 The classification results for WHU-Hi-HongHu dataset |
| Class | SVM | SSAN | SSRN | PresNet | CNNCRF | SSFCN-CRF | FPGA | ACANet |
| 红色屋顶 | 85.23 | 96.70 | 95.28 | 95.81 | 95.23 | 96.07 | 96.55 | 96.60 |
| 道路 | 72.30 | 85.50 | 93.88 | 95.21 | 95.70 | 79.87 | 96.65 | 96.01 |
| 裸土 | 75.03 | 81.08 | 88.76 | 86.99 | 88.86 | 87.46 | 95.25 | 97.36 |
| 棉花 | 67.45 | 92.00 | 86.05 | 95.28 | 94.84 | 97.87 | 97.81 | 99.94 |
| 棉花柴 | 71.19 | 93.27 | 87.74 | 93.11 | 93.06 | 92.48 | 97.23 | 98.15 |
| 油菜 | 79.37 | 81.10 | 92.44 | 93.65 | 98.05 | 91.04 | 95.97 | 98.79 |
| 白菜 | 51.41 | 38.39 | 79.71 | 82.91 | 75.57 | 80.57 | 87.57 | 90.20 |
| 小白菜 | 32.74 | 48.28 | 83.74 | 76.27 | 83.97 | 82.27 | 97.45 | 98.25 |
| 包菜 | 85.50 | 88.95 | 96.68 | 96.56 | 99.64 | 96.42 | 99.24 | 98.58 |
| 榨菜 | 44.22 | 67.77 | 76.63 | 78.03 | 92.77 | 78.28 | 94.07 | 91.30 |
| 菜苔 | 38.53 | 47.00 | 76.50 | 82.54 | 74.09 | 54.43 | 92.81 | 90.16 |
| 青菜 | 56.09 | 64.22 | 59.94 | 80.39 | 79.37 | 70.09 | 95.27 | 96.14 |
| 小青菜 | 51.20 | 41.86 | 72.31 | 75.65 | 66.57 | 74.80 | 83.44 | 89.33 |
| 莴苣 | 53.22 | 80.88 | 88.17 | 97.22 | 89.65 | 73.79 | 98.51 | 97.33 |
| 青莴苣 | 82.56 | 89.81 | 96.85 | 100.00 | 100.00 | 95.48 | 99.90 | 100.00 |
| 薄膜覆盖的莴苣 | 78.49 | 56.70 | 92.79 | 96.10 | 93.59 | 93.95 | 99.92 | 99.51 |
| 罗马生菜 | 66.22 | 89.63 | 97.26 | 95.88 | 91.96 | 88.21 | 97.13 | 97.16 |
| 胡萝卜 | 69.21 | 86.58 | 96.72 | 97.44 | 98.55 | 92.93 | 99.53 | 99.43 |
| 白萝卜 | 71.96 | 58.84 | 90.35 | 96.54 | 96.96 | 92.61 | 98.74 | 98.19 |
| 蒜苗 | 76.02 | 85.62 | 95.52 | 98.52 | 96.19 | 95.72 | 99.68 | 99.07 |
| 蚕豆 | 65.96 | 90.61 | 98.20 | 100.00 | 100.00 | 98.04 | 100.00 | 100.00 |
| 柿子树 | 80.75 | 79.77 | 98.32 | 97.57 | 100.00 | 97.52 | 100.00 | 99.92 |
| OA/(%) | 67.47 | 78.89 | 85.99 | 91.46 | 91.06 | 90.26 | 95.76 | 97.42 |
| Kappa | 0.611 6 | 0.738 9 | 0.828 1 | 0.893 2 | 0.888 1 | 0.877 5 | 0.946 7 | 0.967 3 |
| AA/(%) | 66.12 | 74.75 | 88.36 | 91.44 | 91.12 | 86.81 | 96.49 | 96.88 |
| 注:最佳结果以粗体突出显示。 | ||||||||
(2) WHU-Hi-HanChuan试验结果。数据集的分类结果如图 7所示,定量评价指标见表 4。与WHU-Hi-HongHu数据集相似,SVM的分类图中存在大量错分的椒盐噪声现象,同时由于阴影覆盖区域的辐射亮度较低,导致SVM的分类方法在该区域存在严重的错分。与SVM方法相比,SSAN、SSRN和PResNet方法的OA分别提升11.16%、10.54%和17.72%。但是,这类方法的分类图仍存在较为严重的错分,尤其在阴影覆盖区域。CNNCRF和SSFCN-CRF方法的OA相比于SVM分别提升18.24%和15.05%,但是,由于条件随机场的一元势能的不准确,CNNCRF分类结果中,豇豆阴影覆盖区域仍然表现出较差的分类性能,SSFCN-CRF分类图也包含较多孤立的错分区域。FPGA方法的OA相比于SVM提升22.26%,但对阴影覆盖区域的水和豇豆同样存在错误分类。ACANet方法在WHU-Hi-HanChuan数据集中取得了最好的分类性能,分类图中错分的孤立区域得到极大缓解。

|
| 图 7 WHU-Hi-HanChuan数据分类结果 Fig. 7 The classification results for WHU-Hi-HanChuan dataset |
| 分类器 | SVM | SSAN | SSRN | PresNet | CNNCRF | SSFCN-CRF | FPGA | ACANet |
| 草莓 | 67.71 | 83.48 | 69.64 | 89.03 | 93.49 | 89.24 | 93.72 | 98.91 |
| 豇豆 | 46.14 | 85.15 | 83.64 | 83.37 | 76.99 | 71.00 | 90.92 | 98.12 |
| 大豆 | 70.07 | 75.69 | 65.94 | 95.15 | 93.71 | 88.61 | 98.95 | 97.75 |
| 高粱 | 92.61 | 88.16 | 95.38 | 95.64 | 97.91 | 87.93 | 97.30 | 99.74 |
| 空心菜 | 72.78 | 99.65 | 98.43 | 99.22 | 99.13 | 96.96 | 97.65 | 97.86 |
| 西瓜 | 44.77 | 72.36 | 75.28 | 75.49 | 87.31 | 64.20 | 95.05 | 98.75 |
| 绿色植物 | 87.95 | 88.55 | 82.33 | 94.40 | 95.28 | 90.21 | 96.87 | 99.72 |
| 树 | 49.10 | 83.09 | 60.88 | 71.45 | 74.75 | 73.67 | 89.63 | 99.35 |
| 草地 | 44.42 | 56.81 | 76.92 | 80.56 | 82.45 | 67.16 | 90.77 | 100.00 |
| 红色屋顶 | 82.72 | 79.80 | 87.79 | 98.30 | 97.98 | 88.64 | 94.57 | 100.00 |
| 灰色屋顶 | 95.53 | 83.69 | 96.31 | 92.21 | 98.97 | 96.23 | 97.30 | 95.47 |
| 塑料薄膜 | 59.52 | 95.54 | 71.78 | 97.00 | 99.56 | 91.98 | 98.18 | 96.59 |
| 裸土 | 49.11 | 64.36 | 70.26 | 81.93 | 60.90 | 74.03 | 90.19 | 99.12 |
| 道路 | 63.31 | 91.33 | 73.52 | 87.04 | 91.80 | 84.07 | 96.23 | 94.51 |
| 明亮物体 | 69.80 | 88.21 | 80.20 | 90.24 | 89.32 | 81.86 | 90.42 | 99.66 |
| 水体 | 90.78 | 87.87 | 99.31 | 97.81 | 96.87 | 98.42 | 96.70 | 99.90 |
| OA/(%) | 72.47 | 83.63 | 83.01 | 90.19 | 90.71 | 87.52 | 94.73 | 98.80 |
| Kappa | 0.684 | 0.810 9 | 0.802 8 | 0.885 8 | 0.891 7 | 0.854 7 | 0.938 5 | 0.985 9 |
| AA/(%) | 67.89 | 82.73 | 80.48 | 89.30 | 89.78 | 84.01 | 94.66 | 98.47 |
| 注:最佳结果以粗体突出显示。 | ||||||||
2.4 试验参数分析
(1) 训练样本敏感性分析。图 8显示了不同训练样本数量下(25、50、100、150、200、250、300)ACANet和对比方法在WHU-Hi数据集的总体精度。由图 8可以明显看出,ACANet在所有训练样本量下都取得了最高分类精度,并且在训练样本数量较少时(25, 50)表现出更大的优势。

|
| 图 8 不同训练样本下WHU-Hi数据集的总体分类精度 Fig. 8 The Overall accuracy of different numbers of training samples on WHU-Hi dataset |
(2) ACANet的消融试验。表 5显示了ACANet在WHU-Hi数据集上使用每类50个训练样本的消融试验结果。由表 5可知,在Baseline基础上添加LCM和GCM模块都会显著提升分类精度,由此可以证明长距离上下文信息对空谱异质性高的双高影像分类是有效的。在此基础上,LCM和GCM模块两者联合使用对分类精度有进一步增益,并且使用AAM进行上下文信息自适应聚合可以再次实现精度提升。因此,本文所提出的局部和全局上下文自适应聚合框架在双高影像分类具有优异的性能。
| 数据集 | 网络架构 | LCM | GCM | AAM | OA/(%) | AA/(%) | Kappa |
| WHU-Hi-HongHu | Baseline | - | - | - | 89.95 | 90.17 | 0.874 7 |
| + | √ | 97.12 | 96.72 | 0.964 6 | |||
| √ | 96.98 | 96.74 | 0.961 8 | ||||
| √ | √ | 97.29 | 96.87 | 0.965 6 | |||
| √ | √ | √ | 97.42 | 97.84 | 0.967 3 | ||
| WHU-Hi-HanChuan | Baseline | - | - | - | 90.04 | 88.96 | 0.884 0 |
| + | √ | 97.68 | 96.92 | 0.972 8 | |||
| √ | 96.57 | 96.22 | 0.959 9 | ||||
| √ | √ | 98.26 | 97.51 | 0.979 6 | |||
| √ | √ | √ | 98.80 | 98.47 | 0.985 9 |
(3) 模型计算时间复杂度分析。不同分类方法在WHU-Hi数据集上的训练和测试时间见表 6。SVM方法使用的计算机配置:3.0 GHz英特尔至强E3-1220v5CPU,运行环境为Matlab2017。SAE-LR方法使用的计算机配置为:Intel Xeon E5-2690v4 CPU,运行环境为TensorFlow1.7。SSAN、SSRN、CNNCRF、SSFCN-CRF、FPGA和ACANet方法使用的计算机配置:Intel Xeon E5-2690v4 CPU,NVIDIA TeslaP100 GPU,SSAN、SSRN、CNNCRF、SSFCN-CRF的运行环境为TensorFlow1.9,FPGA和ACANet方法的运行环境为Pytorch 1.7,CNNCRF方法中CRF模型后处理基于Matlab2017。SVM方法采用逐像素预测并且未采用GPU运算加速,因此模型推理时间较长。SSAN、SSRN、PresNet 3种方法均采用空间取块方式预测,因此模型推理时间较为相近。CNNCRF模型和SSFCN-CRF模型均需CRF模型进行后处理,因此相比于基准网络CNN和SSFCN运算时间显著增加,而SSFCN采用全卷积网络将整张影像作为模型的输入,相比于CNN方法运算时间显著降低。FPGA和ACANet采用全卷积网络的形式极大提升了模型的推理速度,其中FPGA模型更为简单,推理速度更快。
| 数据集 | SVM | SSAN | SSRN | PresNet | CNNCRF | SSFCN-CRF | FPGA | ACANet |
| WHU-Hi-HongHu | 452.479 | 205.397 | 192.554 | 202.337 | 811.102 | 67.982 | 0.126 | 0.165 |
| WHU-Hi-HanChuan | 216.025 | 156.721 | 144.924 | 153.233 | 412.244 | 59.587 | 0.094 | 0.147 |
3 结论
针对双高影像极高空谱异质性的特点和当前深度学习方法在长距离上下文信息方面利用的不足,本文提出一种局部-全局上下文信息自适应聚合的快速双高影像分类框架ACANet。ACANet采用编码解码的全卷积网络架构,可以同时顾及影像的全局空谱信息。在编码器中,ACANet模仿人类视觉感知机理,构建局部到全局的长距离上下文感知模块,通过引入长距离上下文可以有效缓解双高空谱异质性造成的错分孤立现象;在解码器中,ACANet采用自适应上下文信息模块实现针对不同应用场景的长距离上下文信息自适应聚合。本文方法在WHU-Hi无人机双高数据集地物精细分类中取得了优异的性能,可以很好地缓解双高影像空谱异质性对分类的影响。
| [1] |
童庆禧, 张兵, 郑兰芬. 高光谱遥感: 原理、技术与应用[M]. 北京: 高等教育出版社, 2006. TONG Qingxi, ZHANG Bing, ZHENG Lanfen. Hyperspectral remote sensing: principle, technology and application[M]. Beijing: Higher Education Press, 2006. |
| [2] |
张良培, 张立福. 高光谱遥感[M]. 北京: 测绘出版社, 2011. ZHANG Liangpei, ZHANG Lifu. Hyperspectral remote sensing[M]. Beijing: Surveying and Mapping Press, 2011. |
| [3] |
杜培军, 夏俊士, 薛朝辉, 等. 高光谱遥感影像分类研究进展[J]. 遥感学报, 2016, 20(2): 236-256. DU Peijun, XIA Junshi, XUE Zhaohui, et al. Review of hyperspectral remote sensing image classification[J]. Journal of Remote Sensing, 2016, 20(2): 236-256. |
| [4] |
ZHONG Yanfei, WANG Xinyu, XU Yao, et al. Mini-UAV-borne hyperspectral remote sensing: from observation and processing to applications[J]. IEEE Geoscience and Remote Sensing Magazine, 2018, 6(4): 46-62. DOI:10.1109/MGRS.2018.2867592 |
| [5] |
ZHONG Y, HU X, LUO C, et al. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF[J]. Remote Sensing of Environment, 2020, 250: 112012. DOI:10.1016/j.rse.2020.112012 |
| [6] |
HU Xin, ZHONG Yanfei, WANG Xinyu, et al. SPNet: spectral patching end-to-end classification network for UAV-borne hyperspectral imagery with high spatial and spectral resolutions[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-17. |
| [7] |
HU Xin, WANG Xinyu, ZHONG Yanfei, et al. S3ANet: spectral-spatial-scale attention network for end-to-end precise crop classification based on UAV-borne H2 imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 183: 147-163. DOI:10.1016/j.isprsjprs.2021.10.014 |
| [8] |
MIRZAPOUR F, GHASSEMIAN H. Improving hyperspectral image classification by combining spectral, texture and shape features[J]. International Journal of Remote Sensing, 2015, 36(4): 1070-1096. DOI:10.1080/01431161.2015.1007251 |
| [9] |
GHAMISI P, MAGGIORI E, LI Shutao, et al. New frontiers in spectral-spatial hyperspectral image classification: the latest advances based on mathematical morphology, Markov random fields, segmentation, sparse representation and deep learning[J]. IEEE Geoscience and Remote Sensing Magazine, 2018, 6(3): 10-43. DOI:10.1109/MGRS.2018.2854840 |
| [10] |
LI Wei, PRASAD S, FOWLER J E. Hyperspectral image classification using Gaussian mixture models and Markov random fields[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11(1): 153-157. DOI:10.1109/LGRS.2013.2250905 |
| [11] |
SUN Shujin, ZHONG Ping, XIAO Huaitie, et al. An MRF model-based active learning framework for the spectral-spatial classification of hyperspectral imagery[J]. IEEE Journal of Selected Topics in Signal Processing, 2015, 9(6): 1074-1088. DOI:10.1109/JSTSP.2015.2414401 |
| [12] |
ZHAO J, ZHONG Y, JIA T, et al. Spectral-spatial classification of hyperspectral imagery with cooperative game[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 135: 31-42. DOI:10.1016/j.isprsjprs.2017.10.006 |
| [13] |
魏立飞, 余铭, 钟燕飞, 等. 空-谱融合的条件随机场高光谱影像分类方法[J]. 测绘学报, 2020, 49(3): 343-354. WEI Lifei, YU Ming, ZHONG Yanfei, et al. Hyperspectral image classification method based on space-spectral fusion conditional random field[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(3): 343-354. DOI:10.11947/j.AGCS.2020.20190042 |
| [14] |
LI Shutao, SONG Weiwei, FANG Leyuan, et al. Deep learning for hyperspectral image classification: an overview[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(9): 6690-6709. DOI:10.1109/TGRS.2019.2907932 |
| [15] |
CHEN Yushi, LIN Zhouhan, ZHAO Xing, et al. Deep learning-based classification of hyperspectral data[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(6): 2094-2107. DOI:10.1109/JSTARS.2014.2329330 |
| [16] |
刘冰, 余旭初, 张鹏强, 等. 联合空-谱信息的高光谱影像深度三维卷积网络分类[J]. 测绘学报, 2019, 48(1): 53-63. LIU Bing, YU Xuchu, ZHANG Pengqiang, et al. Deep 3D convolutional network combined with spatial-spectral features for hyperspectral image classification[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(1): 53-63. DOI:10.11947/j.AGCS.2019.20170578 |
| [17] |
左溪冰, 刘冰, 余旭初, 等. 高光谱影像小样本分类的图卷积网络方法[J]. 测绘学报, 2021, 50(10): 1358-1369. ZUO Xibing, LIU Bing, YU Xuchu, et al. Graph convolutional network method for small sample classification of hyperspectral images[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(10): 1358-1369. DOI:10.11947/j.AGCS.2021.20200155 |
| [18] |
ZHENG Zhuo, ZHONG Yanfei, MA Ailong, et al. FPGA: fast patch-free global learning framework for fully end-to-end hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(8): 5612-5626. DOI:10.1109/TGRS.2020.2967821 |
| [19] |
XU Yonghao, DU Bo, ZHANG Liangpei. Beyond the patchwise classification: spectral-spatial fully convolutional networks for hyperspectral image classification[J]. IEEE Transactions on Big Data, 2020, 6(3): 492-506. DOI:10.1109/TBDATA.2019.2923243 |
| [20] |
SHEN Yu, ZHU Sijie, CHEN Chen, et al. Efficient deep learning of nonlocal features for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(7): 6029-6043. DOI:10.1109/TGRS.2020.3014286 |
| [21] |
WANG Di, DU Bo, ZHANG Liangpei. Fully contextual network for hyperspectral scene parsing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-16. |
| [22] |
HOU Qibin, ZHANG Li, CHENG Mingming, et al. Strip pooling: rethinking spatial pooling for scene parsing[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle: IEEE, 2020: 4002-4011.
|
| [23] |
CAO Yue, XU Jiarui, LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). Seoul: IEEE, 2020: 1971-1980.
|
| [24] |
HU Jie, SHEN Li, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023. DOI:10.1109/TPAMI.2019.2913372 |
| [25] |
CHANG C C, LIN C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1-27. |
| [26] |
MEI Xiaoguang, PAN Erting, MA Yong, et al. Spectral-spatial attention networks for hyperspectral image classification[J]. Remote Sensing, 2019, 11(8): 963. DOI:10.3390/rs11080963 |
| [27] |
ZHONG Zilong, LI J, LUO Zhiming, et al. Spectral-spatial residual network for hyperspectral image classification: a 3-D deep learning framework[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(2): 847-858. DOI:10.1109/TGRS.2017.2755542 |
| [28] |
PAOLETTI M E, HAUT J M, FERNANDEZ-BELTRAN R, et al. Deep pyramidal residual networks for spectral-spatial hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(2): 740-754. DOI:10.1109/TGRS.2018.2860125 |