遥感基础模型发展综述与未来设想
1
2024
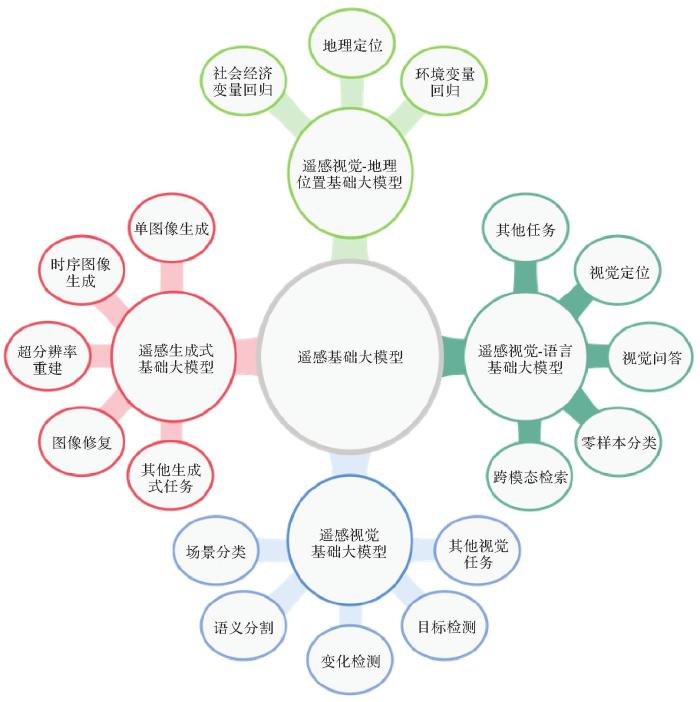
... 在遥感大数据时代,爆炸式增长的遥感影像数据为地球观测信息提取及知识发现带来了新的挑战和机遇[1].目前,深度学习等先进人工智能技术能够从海量的多模态、多尺度、多时相遥感数据中自动学习特征表达与判别模型,进而提高遥感解译任务的效率和准确性.虽然众多任务特定的智能遥感解译算法已经被提出并在特定应用场景上取得了一定的进展[2-5],但是任务之间的差异和任务特定解译模型的有限泛化能力使得每项任务都需要投入大量资源构建任务特定,甚至是场景特定的解译模型,导致算法解译效率低下和泛化应用困难. ...
遥感基础模型发展综述与未来设想
1
2024
... 在遥感大数据时代,爆炸式增长的遥感影像数据为地球观测信息提取及知识发现带来了新的挑战和机遇[1].目前,深度学习等先进人工智能技术能够从海量的多模态、多尺度、多时相遥感数据中自动学习特征表达与判别模型,进而提高遥感解译任务的效率和准确性.虽然众多任务特定的智能遥感解译算法已经被提出并在特定应用场景上取得了一定的进展[2-5],但是任务之间的差异和任务特定解译模型的有限泛化能力使得每项任务都需要投入大量资源构建任务特定,甚至是场景特定的解译模型,导致算法解译效率低下和泛化应用困难. ...
MFVNet: a deep adaptive fusion network with multiple field-of-views for remote sen-sing image semantic segmentation
1
2023
... 在遥感大数据时代,爆炸式增长的遥感影像数据为地球观测信息提取及知识发现带来了新的挑战和机遇[1].目前,深度学习等先进人工智能技术能够从海量的多模态、多尺度、多时相遥感数据中自动学习特征表达与判别模型,进而提高遥感解译任务的效率和准确性.虽然众多任务特定的智能遥感解译算法已经被提出并在特定应用场景上取得了一定的进展[2-5],但是任务之间的差异和任务特定解译模型的有限泛化能力使得每项任务都需要投入大量资源构建任务特定,甚至是场景特定的解译模型,导致算法解译效率低下和泛化应用困难. ...
Water body classification from high-resolution optical remote sensing imagery: achievements and perspectives
0
2022
HS2P: Hierarchical spectral and structure-preserving fusion network for multimodal remote sensing image cloud and shadow removal
1
2023
... 遥感影像超分辨率重建、云去除等生成式解译方法能够帮助人类更完整、更细致地观察地表自然环境和人类活动的变化,吸引了众多学者的关注[4,75].然而,先前的研究主要集中在为特定生成任务设计专用模型上,导致在实际应用中灵活性和通用性相对不足.稳定扩散模型(stable diffusion)在图像重建、视频生成等任务上取得显著进展,这使得诸多学者将其应用于多种遥感图像生成式任务,并取得了一定的进展.文献[76]采用文本描述、遥感影像以及附带的地理元信息(包括地理坐标、成像时间、空间分辨率等)训练了遥感生成式基础模型DiffusionSat.该模型在单个遥感图像生成、多光谱图像超分辨率重建、时序图像生成和图像修复等多个下游任务上取得了先进的性能表现.文献[77]则采用预训练扩散模型学习公开地图数据,可以生成视觉效果逼真、地物类别可控的合成卫星图像.该技术可以为数据缺失任务场景补充额外样本数据.尽管目前遥感生成式基础大模型仍处于初步发展阶段,研究成果相对较少,但其应用潜力巨大,预计将吸引更多学者深入研究.未来,我们可以期待这一领域的快速发展,为遥感生成式解译提供更为灵活、通用且性能卓越的模型. ...
High-resolution optical remote sensing image change detection based on dense connection and attention feature fusion network
1
2023
... 在遥感大数据时代,爆炸式增长的遥感影像数据为地球观测信息提取及知识发现带来了新的挑战和机遇[1].目前,深度学习等先进人工智能技术能够从海量的多模态、多尺度、多时相遥感数据中自动学习特征表达与判别模型,进而提高遥感解译任务的效率和准确性.虽然众多任务特定的智能遥感解译算法已经被提出并在特定应用场景上取得了一定的进展[2-5],但是任务之间的差异和任务特定解译模型的有限泛化能力使得每项任务都需要投入大量资源构建任务特定,甚至是场景特定的解译模型,导致算法解译效率低下和泛化应用困难. ...
Learning transferable visual models from natural language supervision
2
... 近期,随着各类自然语言大模型、视觉基础大模型、多模态基础大模型的涌现和发展[6-8],基础大模型在各个领域的探索成为研究热点.鉴于任务特定遥感解译模型的适用局限,许多学者开始探索针对地球观测任务的遥感基础大模型构建与应用.遥感基础大模型旨在利用大量未标注的遥感数据进行预训练,创建一个任务通用模型,即从大规模遥感数据中学习通用特征表达模型.进一步,通过迁移学习提高多种下游遥感解译任务的性能和效率[9-11].然而,在遥感对地观测这个具有高度复杂性的领域中,仅依赖深度网络非线性映射模型难以全面理解地球的复杂特征,地学知识的挖掘与运用显得愈加关键.地学知识不仅包括丰富的时空信息、地形地貌等测绘地理信息数据,还涵盖了场景先验知识(如开放街道地图等)及领域专家知识(如领域常识等). ...
... 在计算机视觉领域中,一些学者采用了配对的自然图像和GPS数据训练位置编码器,以解决全球图像地理定位的挑战.如,GeoCLIP[73]设计了位置编码器,将GPS坐标映射为高维特征嵌入,并使用经过预训练的CLIP模型[6]作为图像编码器提取图像特征.随后,该研究将位置特征与图像特征映射到共享嵌入空间进行对比学习.不同地理位置的遥感影像的视觉特征受到与地理位置相关的气候、人口密度等自然环境和社会因素的密切影响.在这一背景下,CSP[74]采用多种方式构造正负样本对,并通过遥感数据集预训练后的图像编码器与提出的位置编码器进行对比学习.SatCLIP[14]则致力于捕捉全球不同地区的哨兵2号卫星影像的空间异质性,通过对比预训练的方式学习位置编码特征表示.相关试验证明,SatCLIP模型的位置编码器成功学习到了与特定区域的社会经济与环境等因素高度相关的特征表示.上述技术为进一步深入分析地理位置与遥感影像之间的关联提供了有力支持. ...
The dawn of LMMs: preliminary explorations with GPT-4V (ision)
1
... 近期,随着各类自然语言大模型、视觉基础大模型、多模态基础大模型的涌现和发展[6-8],基础大模型在各个领域的探索成为研究热点.鉴于任务特定遥感解译模型的适用局限,许多学者开始探索针对地球观测任务的遥感基础大模型构建与应用.遥感基础大模型旨在利用大量未标注的遥感数据进行预训练,创建一个任务通用模型,即从大规模遥感数据中学习通用特征表达模型.进一步,通过迁移学习提高多种下游遥感解译任务的性能和效率[9-11].然而,在遥感对地观测这个具有高度复杂性的领域中,仅依赖深度网络非线性映射模型难以全面理解地球的复杂特征,地学知识的挖掘与运用显得愈加关键.地学知识不仅包括丰富的时空信息、地形地貌等测绘地理信息数据,还涵盖了场景先验知识(如开放街道地图等)及领域专家知识(如领域常识等). ...
遥感大模型:进展与前瞻
1
2023
... 近期,随着各类自然语言大模型、视觉基础大模型、多模态基础大模型的涌现和发展[6-8],基础大模型在各个领域的探索成为研究热点.鉴于任务特定遥感解译模型的适用局限,许多学者开始探索针对地球观测任务的遥感基础大模型构建与应用.遥感基础大模型旨在利用大量未标注的遥感数据进行预训练,创建一个任务通用模型,即从大规模遥感数据中学习通用特征表达模型.进一步,通过迁移学习提高多种下游遥感解译任务的性能和效率[9-11].然而,在遥感对地观测这个具有高度复杂性的领域中,仅依赖深度网络非线性映射模型难以全面理解地球的复杂特征,地学知识的挖掘与运用显得愈加关键.地学知识不仅包括丰富的时空信息、地形地貌等测绘地理信息数据,还涵盖了场景先验知识(如开放街道地图等)及领域专家知识(如领域常识等). ...
遥感大模型:进展与前瞻
1
2023
... 近期,随着各类自然语言大模型、视觉基础大模型、多模态基础大模型的涌现和发展[6-8],基础大模型在各个领域的探索成为研究热点.鉴于任务特定遥感解译模型的适用局限,许多学者开始探索针对地球观测任务的遥感基础大模型构建与应用.遥感基础大模型旨在利用大量未标注的遥感数据进行预训练,创建一个任务通用模型,即从大规模遥感数据中学习通用特征表达模型.进一步,通过迁移学习提高多种下游遥感解译任务的性能和效率[9-11].然而,在遥感对地观测这个具有高度复杂性的领域中,仅依赖深度网络非线性映射模型难以全面理解地球的复杂特征,地学知识的挖掘与运用显得愈加关键.地学知识不仅包括丰富的时空信息、地形地貌等测绘地理信息数据,还涵盖了场景先验知识(如开放街道地图等)及领域专家知识(如领域常识等). ...
Brain-inspired remote sensing foundation models and open problems: a comprehensive survey
0
2023
Vision-language models in remote sensing: current progress and future trends
2
... 近期,随着各类自然语言大模型、视觉基础大模型、多模态基础大模型的涌现和发展[6-8],基础大模型在各个领域的探索成为研究热点.鉴于任务特定遥感解译模型的适用局限,许多学者开始探索针对地球观测任务的遥感基础大模型构建与应用.遥感基础大模型旨在利用大量未标注的遥感数据进行预训练,创建一个任务通用模型,即从大规模遥感数据中学习通用特征表达模型.进一步,通过迁移学习提高多种下游遥感解译任务的性能和效率[9-11].然而,在遥感对地观测这个具有高度复杂性的领域中,仅依赖深度网络非线性映射模型难以全面理解地球的复杂特征,地学知识的挖掘与运用显得愈加关键.地学知识不仅包括丰富的时空信息、地形地貌等测绘地理信息数据,还涵盖了场景先验知识(如开放街道地图等)及领域专家知识(如领域常识等). ...
... 在自然语言处理领域,大型语言基础模型在自然语言理解、文本生成、智能问答等任务中取得了显著的成效[68].特别是ChatGPT取得的巨大成功进一步推动了相关研究的发展.视觉-语言基础模型则集成了图像的视觉感知信息和语言的语义信息,旨在从视觉与语言的相互关系中学习通用特征,以更好地完成复杂场景的理解任务[11]. ...
Seasonal contrast: unsupervised pre-training from uncurated remote sensing data
5
2021
... 目前,已经有一些遥感基础大模型开始尝试引入地学知识.具体来说,早期工作尝试利用时空信息(如成像时间和地理坐标)进行预训练算法建模[12-14].后来,研究学者将地学产品嵌入基础模型预训练过程,利用公开获取的土地覆盖分类产品提供的地学知识优化基础模型[15-16].结合地学参量约束模型参数更新也被验证是有效的[17].最近,笔者所在团队提出的SkySense[18]通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,可以隐式挖掘时空敏感的地学知识,辅助提升解译精度.总体来说,上述方法涵盖了多样化地学知识整合方式,为提高模型性能和可解释性提供了有效途径.随着地学知识引导的强化,遥感基础大模型有望能够更好地适应不同地域、不同地貌、不同尺度、不同模态的智能遥感解译需求. ...
... 如表1所示,目前已经涌现出大量各具特色的遥感视觉预训练数据集.在这些数据集中,MillionAID[22]和SatlasPretrain[23]包含了超高分辨率卫星影像,但仅涵盖可见光波段.通过这些数据集训练的遥感基础模型可能在依赖丰富光谱信息的任务(如农作物识别)等方面存在一定的缺陷.然而,超高分辨率影像所包含的细节纹理信息使得预训练模型在基于高分影像的实例分割、目标检测等下游任务上具有一定优势.相比之下,fMoW[24]、SeCo[12]等数据集利用哨兵2号获得的中分辨率多光谱影像作为数据源.众所周知,遥感观测数据包括多种模态影像类型,这些数据具有独特的优势和相互补充的特性.如,光学图像提供了丰富的光谱信息和纹理细节,但容易受到天气及云层的影响.合成孔径雷达传感器能够在恶劣的天气条件下成像.为了满足更多需要依赖多种模态信息的下游任务,BigEarthNet-MM[25]和SSL4EO-S12[26]数据集致力于构建成对的合成孔径雷达-多光谱影像数据集.这类数据集旨在提供更全面、多样化的信息,以支持多模态遥感基础大模型的训练和性能提升,有望促进多模态遥感技术的进步,使其在实际应用中更为灵活和有效. ...
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
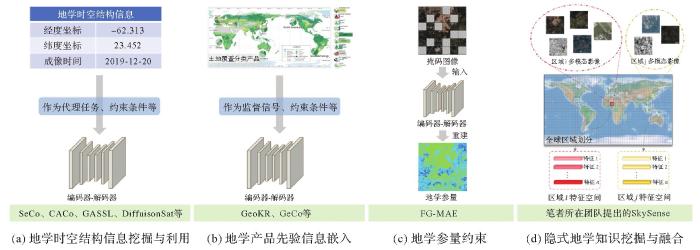
... (1)时空结构信息挖掘与利用.遥感影像附带成像时间、经纬度坐标等元信息,这些地学时空信息能够有效改善遥感基础模型预训练性能.如,拍摄自同一地点但不同成像时间的遥感影像可用于对比预训练[12-13];地理坐标编码可作为预训练的代理任务[48];地理坐标、成像时间等时空信息可用作预训练约束条件[76];结合视觉信息学习的地理位置编码器[14]可进行特定区域的变量回归等任务. ...
Change-aware sampling and contrastive learning for satellite images
2
2023
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
... (1)时空结构信息挖掘与利用.遥感影像附带成像时间、经纬度坐标等元信息,这些地学时空信息能够有效改善遥感基础模型预训练性能.如,拍摄自同一地点但不同成像时间的遥感影像可用于对比预训练[12-13];地理坐标编码可作为预训练的代理任务[48];地理坐标、成像时间等时空信息可用作预训练约束条件[76];结合视觉信息学习的地理位置编码器[14]可进行特定区域的变量回归等任务. ...
SatCLIP: global, general-purpose location embeddings with satellite imagery
3
... 目前,已经有一些遥感基础大模型开始尝试引入地学知识.具体来说,早期工作尝试利用时空信息(如成像时间和地理坐标)进行预训练算法建模[12-14].后来,研究学者将地学产品嵌入基础模型预训练过程,利用公开获取的土地覆盖分类产品提供的地学知识优化基础模型[15-16].结合地学参量约束模型参数更新也被验证是有效的[17].最近,笔者所在团队提出的SkySense[18]通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,可以隐式挖掘时空敏感的地学知识,辅助提升解译精度.总体来说,上述方法涵盖了多样化地学知识整合方式,为提高模型性能和可解释性提供了有效途径.随着地学知识引导的强化,遥感基础大模型有望能够更好地适应不同地域、不同地貌、不同尺度、不同模态的智能遥感解译需求. ...
... 在计算机视觉领域中,一些学者采用了配对的自然图像和GPS数据训练位置编码器,以解决全球图像地理定位的挑战.如,GeoCLIP[73]设计了位置编码器,将GPS坐标映射为高维特征嵌入,并使用经过预训练的CLIP模型[6]作为图像编码器提取图像特征.随后,该研究将位置特征与图像特征映射到共享嵌入空间进行对比学习.不同地理位置的遥感影像的视觉特征受到与地理位置相关的气候、人口密度等自然环境和社会因素的密切影响.在这一背景下,CSP[74]采用多种方式构造正负样本对,并通过遥感数据集预训练后的图像编码器与提出的位置编码器进行对比学习.SatCLIP[14]则致力于捕捉全球不同地区的哨兵2号卫星影像的空间异质性,通过对比预训练的方式学习位置编码特征表示.相关试验证明,SatCLIP模型的位置编码器成功学习到了与特定区域的社会经济与环境等因素高度相关的特征表示.上述技术为进一步深入分析地理位置与遥感影像之间的关联提供了有力支持. ...
... (1)时空结构信息挖掘与利用.遥感影像附带成像时间、经纬度坐标等元信息,这些地学时空信息能够有效改善遥感基础模型预训练性能.如,拍摄自同一地点但不同成像时间的遥感影像可用于对比预训练[12-13];地理坐标编码可作为预训练的代理任务[48];地理坐标、成像时间等时空信息可用作预训练约束条件[76];结合视觉信息学习的地理位置编码器[14]可进行特定区域的变量回归等任务. ...
Geographical knowledge-driven representation learning for remote sensing images
2
2022
... 目前,已经有一些遥感基础大模型开始尝试引入地学知识.具体来说,早期工作尝试利用时空信息(如成像时间和地理坐标)进行预训练算法建模[12-14].后来,研究学者将地学产品嵌入基础模型预训练过程,利用公开获取的土地覆盖分类产品提供的地学知识优化基础模型[15-16].结合地学参量约束模型参数更新也被验证是有效的[17].最近,笔者所在团队提出的SkySense[18]通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,可以隐式挖掘时空敏感的地学知识,辅助提升解译精度.总体来说,上述方法涵盖了多样化地学知识整合方式,为提高模型性能和可解释性提供了有效途径.随着地学知识引导的强化,遥感基础大模型有望能够更好地适应不同地域、不同地貌、不同尺度、不同模态的智能遥感解译需求. ...
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
Geographical supervision correction for remote sensing representation learning
2
2022
... 目前,已经有一些遥感基础大模型开始尝试引入地学知识.具体来说,早期工作尝试利用时空信息(如成像时间和地理坐标)进行预训练算法建模[12-14].后来,研究学者将地学产品嵌入基础模型预训练过程,利用公开获取的土地覆盖分类产品提供的地学知识优化基础模型[15-16].结合地学参量约束模型参数更新也被验证是有效的[17].最近,笔者所在团队提出的SkySense[18]通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,可以隐式挖掘时空敏感的地学知识,辅助提升解译精度.总体来说,上述方法涵盖了多样化地学知识整合方式,为提高模型性能和可解释性提供了有效途径.随着地学知识引导的强化,遥感基础大模型有望能够更好地适应不同地域、不同地貌、不同尺度、不同模态的智能遥感解译需求. ...
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
Feature guided masked autoencoder for self-supervised learning in remote sensing
3
... 目前,已经有一些遥感基础大模型开始尝试引入地学知识.具体来说,早期工作尝试利用时空信息(如成像时间和地理坐标)进行预训练算法建模[12-14].后来,研究学者将地学产品嵌入基础模型预训练过程,利用公开获取的土地覆盖分类产品提供的地学知识优化基础模型[15-16].结合地学参量约束模型参数更新也被验证是有效的[17].最近,笔者所在团队提出的SkySense[18]通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,可以隐式挖掘时空敏感的地学知识,辅助提升解译精度.总体来说,上述方法涵盖了多样化地学知识整合方式,为提高模型性能和可解释性提供了有效途径.随着地学知识引导的强化,遥感基础大模型有望能够更好地适应不同地域、不同地貌、不同尺度、不同模态的智能遥感解译需求. ...
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
... (3)地学参量约束.定量遥感旨在将多源遥感观测数据定量反演或推算为地学目标参量,形成时空遥感数据产品[89].相关地学参量(如归一化指数等)通过物理机理、成像光谱信息反映地表的属性信息,FG-MAE[17]结合经典的掩码图像建模算法重建相关地学参量,从而约束大模型参数更新. ...
SkySense: a multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery
4
2024
... 目前,已经有一些遥感基础大模型开始尝试引入地学知识.具体来说,早期工作尝试利用时空信息(如成像时间和地理坐标)进行预训练算法建模[12-14].后来,研究学者将地学产品嵌入基础模型预训练过程,利用公开获取的土地覆盖分类产品提供的地学知识优化基础模型[15-16].结合地学参量约束模型参数更新也被验证是有效的[17].最近,笔者所在团队提出的SkySense[18]通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,可以隐式挖掘时空敏感的地学知识,辅助提升解译精度.总体来说,上述方法涵盖了多样化地学知识整合方式,为提高模型性能和可解释性提供了有效途径.随着地学知识引导的强化,遥感基础大模型有望能够更好地适应不同地域、不同地貌、不同尺度、不同模态的智能遥感解译需求. ...
... 除了仅依靠单模态图像预训练的工作外,CROMA[64]和De-CUR[65]研究了使用静态影像进行单模态和多模态图像源的多模态预训练.Presto[66]同时利用时间和地理位置信息,联合多光谱、合成孔径雷达、高程等多模态信息训练了轻量级基础模型.遗憾的是,Presto的预训练数据未包含高分辨率卫星图像,且缺乏在基于高分辨率影像的下游任务上广泛的测试以验证模型的泛化性.文献[67]则关注到跨模态协同解译中异构模态特征的空间相关性问题,采用不同的度量空间(即欧氏空间、复数空间和双曲空间)提取不同模态图像的特征,然后采用统一的编码器进行多模态特征融合.笔者所在团队则发展了目前参数量规模最大的多模态时序遥感基础大模型——SkySense[18](20亿参数量),通过时空解耦、时间感知嵌入等机制联合高分光学遥感影像、时序光学遥感影像、时序合成孔径雷达影像等多模态数据进行多粒度对比学习.值得说明的是,灵活可插拔性和通用特征的强大泛化性使得SkySense在涵盖单模态图像级分类、目标级检测、像素级分割以及多模态农作物时序分类等8项任务(共计16个数据集)中均取得了最先进的水平. ...
... (4)隐式地学知识挖掘与融合.地理景观的形成是气候、地质、水文、生物多样性和人类活动等多种因素的错综复杂相互作用[90].这些因素共同促使地理区域呈现出特定的地理特征,即不同地区的遥感影像往往呈现出明显的地理异质性.笔者所在团队提出的SkySense[18]发展了地理空间敏感的上下文学习范式,旨在从遥感大数据中隐式挖掘与融合地学知识.具体而言,将全球划分为众多子区域,通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,以隐式挖掘时空敏感的聚类特征,这些聚类特征一定程度上可以较好地反映不同区域的语义先验.在推理阶段,可以通过注意力机制融合视觉特征和语义先验来改善遥感影像的解译性能. ...
... (1)多模态预训练数据稀缺与评估基准不足.在自然语言处理和计算机视觉等领域,大量卓越基础模型的成功案例均揭示预训练数据集的规模和质量是影响模型泛化性的重要因素[47].尽管遥感领域逐渐涌现出规模较大的预训练数据集(详见第1节),但仍然缺乏不同卫星源、不同波段组合、不同空间分辨率、不同成像模式的多模态预训练数据集,无法支撑多模态遥感基础大模型的充分训练.此外,全面、统一、可靠的评估基准能够帮助全面衡量遥感基础模型的能力.早期遥感基础模型评估所选用的数据集、下游任务、评估方式各不相同,未形成系统全面的评估数据集及指标体系.笔者所在团队提出的SkySense[18]在单模态图像级分类、目标级识别、像素级分割、多模态时序分类等众多数据集上建立了统一的评估基准结果,以方便后续方法进行对比.未来还应该不断补充更多任务类型.此外,在弱监督下游任务的条件下评估预训练模型的泛化性更加符合实际应用场景的需求,如评估在少样本、含大量噪声标签等下游数据条件下遥感基础大模型的稳健性. ...
Self-supervised remote sensing feature learning: learning paradigms, challenges, and future works
1
2023
... 大规模预训练数据是基础大模型的数据引擎.研究表明,在广泛而多样化的数据上进行预训练对于模型学习判别性通用特征表示具有显著促进作用[19-21],有助于加速预训练模型在各种下游任务的微调收敛过程,减少对有标签数据的依赖,进而提升任务性能.这种任务通用的特征表示为模型在理解和处理不同场景数据时提供了坚实的基础,使其具备强大的泛化能力.在遥感领域,已有一系列相关研究致力于构建大规模预训练遥感数据集.根据数据模态的不同,接下来对大规模预训练数据集进行了归纳和总结. ...
TOV: The original vision model for optical remote sensing image understanding via self-supervised learning
3
2023
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
CMID: a unified self-supervised learning framework for remote sensing image understanding
2
2023
... 大规模预训练数据是基础大模型的数据引擎.研究表明,在广泛而多样化的数据上进行预训练对于模型学习判别性通用特征表示具有显著促进作用[19-21],有助于加速预训练模型在各种下游任务的微调收敛过程,减少对有标签数据的依赖,进而提升任务性能.这种任务通用的特征表示为模型在理解和处理不同场景数据时提供了坚实的基础,使其具备强大的泛化能力.在遥感领域,已有一系列相关研究致力于构建大规模预训练遥感数据集.根据数据模态的不同,接下来对大规模预训练数据集进行了归纳和总结. ...
... 近期,CMID[21]、GFM[60]、Cross-Scale MAE[61]等研究将对比学习范式与掩码图像重建范式相结合,在场景分类、目标检测、语义分割、变化检测等众多图像级、对象级、像素级的典型遥感解译任务中展现出明显性能优势.类似地,CtxMIM[62]则在重建掩码图像损失的基础上增加上下文一致性约束,以提供额外的上下文信息.与大多数基础模型采用自监督预训练方法不同,SatLas[23]依托自建的具有丰富标注类型的大规模数据集SatlasPretrain进行有监督预训练,并将模型应用于热带雨林砍伐检测、可再生能源基础设施检测等任务.文献[63]面向遥感时空预测任务设计了包含空间、时间、时空建模3个分支的基础模型,并在雷达回波外推、卫星视频多目标跟踪和遥感视频预测等下游任务中取得了具有竞争力的结果. ...
On creating benchmark dataset for aerial image interpretation: reviews, guidances, and million-AID
2
2021
... 如表1所示,目前已经涌现出大量各具特色的遥感视觉预训练数据集.在这些数据集中,MillionAID[22]和SatlasPretrain[23]包含了超高分辨率卫星影像,但仅涵盖可见光波段.通过这些数据集训练的遥感基础模型可能在依赖丰富光谱信息的任务(如农作物识别)等方面存在一定的缺陷.然而,超高分辨率影像所包含的细节纹理信息使得预训练模型在基于高分影像的实例分割、目标检测等下游任务上具有一定优势.相比之下,fMoW[24]、SeCo[12]等数据集利用哨兵2号获得的中分辨率多光谱影像作为数据源.众所周知,遥感观测数据包括多种模态影像类型,这些数据具有独特的优势和相互补充的特性.如,光学图像提供了丰富的光谱信息和纹理细节,但容易受到天气及云层的影响.合成孔径雷达传感器能够在恶劣的天气条件下成像.为了满足更多需要依赖多种模态信息的下游任务,BigEarthNet-MM[25]和SSL4EO-S12[26]数据集致力于构建成对的合成孔径雷达-多光谱影像数据集.这类数据集旨在提供更全面、多样化的信息,以支持多模态遥感基础大模型的训练和性能提升,有望促进多模态遥感技术的进步,使其在实际应用中更为灵活和有效. ...
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
SatlasPretrain: a large-scale dataset for remote sensing image understanding
3
... 如表1所示,目前已经涌现出大量各具特色的遥感视觉预训练数据集.在这些数据集中,MillionAID[22]和SatlasPretrain[23]包含了超高分辨率卫星影像,但仅涵盖可见光波段.通过这些数据集训练的遥感基础模型可能在依赖丰富光谱信息的任务(如农作物识别)等方面存在一定的缺陷.然而,超高分辨率影像所包含的细节纹理信息使得预训练模型在基于高分影像的实例分割、目标检测等下游任务上具有一定优势.相比之下,fMoW[24]、SeCo[12]等数据集利用哨兵2号获得的中分辨率多光谱影像作为数据源.众所周知,遥感观测数据包括多种模态影像类型,这些数据具有独特的优势和相互补充的特性.如,光学图像提供了丰富的光谱信息和纹理细节,但容易受到天气及云层的影响.合成孔径雷达传感器能够在恶劣的天气条件下成像.为了满足更多需要依赖多种模态信息的下游任务,BigEarthNet-MM[25]和SSL4EO-S12[26]数据集致力于构建成对的合成孔径雷达-多光谱影像数据集.这类数据集旨在提供更全面、多样化的信息,以支持多模态遥感基础大模型的训练和性能提升,有望促进多模态遥感技术的进步,使其在实际应用中更为灵活和有效. ...
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
... 近期,CMID[21]、GFM[60]、Cross-Scale MAE[61]等研究将对比学习范式与掩码图像重建范式相结合,在场景分类、目标检测、语义分割、变化检测等众多图像级、对象级、像素级的典型遥感解译任务中展现出明显性能优势.类似地,CtxMIM[62]则在重建掩码图像损失的基础上增加上下文一致性约束,以提供额外的上下文信息.与大多数基础模型采用自监督预训练方法不同,SatLas[23]依托自建的具有丰富标注类型的大规模数据集SatlasPretrain进行有监督预训练,并将模型应用于热带雨林砍伐检测、可再生能源基础设施检测等任务.文献[63]面向遥感时空预测任务设计了包含空间、时间、时空建模3个分支的基础模型,并在雷达回波外推、卫星视频多目标跟踪和遥感视频预测等下游任务中取得了具有竞争力的结果. ...
Functional map of the world
2
2018
... 如表1所示,目前已经涌现出大量各具特色的遥感视觉预训练数据集.在这些数据集中,MillionAID[22]和SatlasPretrain[23]包含了超高分辨率卫星影像,但仅涵盖可见光波段.通过这些数据集训练的遥感基础模型可能在依赖丰富光谱信息的任务(如农作物识别)等方面存在一定的缺陷.然而,超高分辨率影像所包含的细节纹理信息使得预训练模型在基于高分影像的实例分割、目标检测等下游任务上具有一定优势.相比之下,fMoW[24]、SeCo[12]等数据集利用哨兵2号获得的中分辨率多光谱影像作为数据源.众所周知,遥感观测数据包括多种模态影像类型,这些数据具有独特的优势和相互补充的特性.如,光学图像提供了丰富的光谱信息和纹理细节,但容易受到天气及云层的影响.合成孔径雷达传感器能够在恶劣的天气条件下成像.为了满足更多需要依赖多种模态信息的下游任务,BigEarthNet-MM[25]和SSL4EO-S12[26]数据集致力于构建成对的合成孔径雷达-多光谱影像数据集.这类数据集旨在提供更全面、多样化的信息,以支持多模态遥感基础大模型的训练和性能提升,有望促进多模态遥感技术的进步,使其在实际应用中更为灵活和有效. ...
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
BigEarthNet-MM: a large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets]
2
2021
... 如表1所示,目前已经涌现出大量各具特色的遥感视觉预训练数据集.在这些数据集中,MillionAID[22]和SatlasPretrain[23]包含了超高分辨率卫星影像,但仅涵盖可见光波段.通过这些数据集训练的遥感基础模型可能在依赖丰富光谱信息的任务(如农作物识别)等方面存在一定的缺陷.然而,超高分辨率影像所包含的细节纹理信息使得预训练模型在基于高分影像的实例分割、目标检测等下游任务上具有一定优势.相比之下,fMoW[24]、SeCo[12]等数据集利用哨兵2号获得的中分辨率多光谱影像作为数据源.众所周知,遥感观测数据包括多种模态影像类型,这些数据具有独特的优势和相互补充的特性.如,光学图像提供了丰富的光谱信息和纹理细节,但容易受到天气及云层的影响.合成孔径雷达传感器能够在恶劣的天气条件下成像.为了满足更多需要依赖多种模态信息的下游任务,BigEarthNet-MM[25]和SSL4EO-S12[26]数据集致力于构建成对的合成孔径雷达-多光谱影像数据集.这类数据集旨在提供更全面、多样化的信息,以支持多模态遥感基础大模型的训练和性能提升,有望促进多模态遥感技术的进步,使其在实际应用中更为灵活和有效. ...
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
SSL4EO-S12: a large-scale multimodal, multitemporal dataset for self-supervised learning in Earth observation [software and data sets]
2
2023
... 如表1所示,目前已经涌现出大量各具特色的遥感视觉预训练数据集.在这些数据集中,MillionAID[22]和SatlasPretrain[23]包含了超高分辨率卫星影像,但仅涵盖可见光波段.通过这些数据集训练的遥感基础模型可能在依赖丰富光谱信息的任务(如农作物识别)等方面存在一定的缺陷.然而,超高分辨率影像所包含的细节纹理信息使得预训练模型在基于高分影像的实例分割、目标检测等下游任务上具有一定优势.相比之下,fMoW[24]、SeCo[12]等数据集利用哨兵2号获得的中分辨率多光谱影像作为数据源.众所周知,遥感观测数据包括多种模态影像类型,这些数据具有独特的优势和相互补充的特性.如,光学图像提供了丰富的光谱信息和纹理细节,但容易受到天气及云层的影响.合成孔径雷达传感器能够在恶劣的天气条件下成像.为了满足更多需要依赖多种模态信息的下游任务,BigEarthNet-MM[25]和SSL4EO-S12[26]数据集致力于构建成对的合成孔径雷达-多光谱影像数据集.这类数据集旨在提供更全面、多样化的信息,以支持多模态遥感基础大模型的训练和性能提升,有望促进多模态遥感技术的进步,使其在实际应用中更为灵活和有效. ...
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
SEN12MS—a curated dataset of georeferenced multi-spectral Sentinel-1/2 imagery for deep learning and data fusion
1
2019
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
SatMAE: pre-training transformers for temporal and multi-spectral satellite imagery
2
2022
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
SSL4EO-L: datasets and foundation models for landsat imagery
1
... Large-scale remote sensing vision pre-training datasets
Tab.1| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|
| fMoW[24] | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[27] | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[25] | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[22] | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[12] | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[28] | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[20] | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[26] | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[29] | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[23] | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
1.2 遥感视觉-语言预训练数据集目前,能够用于训练遥感视觉-语言基础大模型的数据集较少,其数据规模相对有限.如表2所示,多数预训练数据集集中于提供图像-文本描述. ...
Exploring models and data for remote sensing image caption generation
2
2018
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval
1
2022
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
RSVG: exploring data and models for visual grounding on remote sensing data
2
2023
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
RS5M: a large scale vision-language dataset for remote sensing vision-language foundation model
1
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
RSGPT: a remote sensing vision language model and benchmark
3
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
RemoteCLIP: a vision language foundation model for remote sensing
3
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
GeoChat: grounded large vision-language model for remote sensing
3
... Large-scale remote sensing vision-language pre-training datasets
Tab.2| 数据集 | 数量 | 属性 |
|---|
| RSICD[30] | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[31] | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[32] | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[33] | 500万个图像文本对 | 图像-文本描述 |
| RSICap[34] | 2585个图像文本对 | 图像-文本描述 |
| 文献[35] | 828 725个图像文本对 | 图像-文本描述 |
| 文献[36] | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |
具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 具体来说,早期的遥感图像-文本描述数据集多为特定任务构建[30-32],其中的文本描述较为简短,包含的有限语义信息不足以训练泛化性强的基础模型.RSICap[34]致力于创建高质量图像-文本描述信息,其中,每幅遥感影像带有场景、目标形状、目标绝对位置、相对位置、颜色和数量等细节信息的描述.文献[35]设计了“掩码转定位框”“定位框转文本描述”的转换流程,将遥感领域常用的3个图像检索数据集、10个目标检测数据集、4个语义分割数据集转换为图像-文本描述数据对,有效提升了遥感视觉-语言基础大模型的预训练数据多样性.相似地,文献[36]整合了一些遥感视觉问答、目标检测数据集,将其重构成图像-文本描述、定位描述和复杂对话等形式,以满足多功能对话智能体训练的需求. ...
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
Deep residual learning for image recognition
1
2016
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
Attention is all you need
1
2017
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
Emerging properties in self-supervised vision transformers
1
2021
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
A simple framework for contrastive learning of visual representations
0
Momentum contrast for unsupervised visual representation learning
1
2020
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
LLaMA: open and efficient foundation language models
1
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
Masked autoencoders are scalable vision learners
1
2022
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
BEiT: BERT pre-training of image transformers
1
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
What do self-supervised vision transformers learn?
1
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
iBOT: image BERT pre-training with online tokenizer
1
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
DINOv2: learning robust visual features without supervision
2
... 在计算机视觉领域,视觉基础模型的研究重点已经从早期的利用大量标记数据的监督学习[37-38](如在ImageNet数据集上进行预训练)发展到最近的对比学习范式[39-41](在大规模未标记图像上开展无监督预训练).随着自然语言处理领域中大语言模型的巨大成功[42],掩码图像建模方法(如MAE[43]、BEiT[44]等)受到广泛关注.研究指出[45],基于对比学习的模型关注全局结构和形状等低频空间信息,而基于掩码图像建模的模型则更加侧重于挖掘高频空间信息(如局部结构和精细的纹理).ibot、DINOv2[46-47]成功地结合了上述两种范式的优势,取得了先进的性能表现. ...
... (1)多模态预训练数据稀缺与评估基准不足.在自然语言处理和计算机视觉等领域,大量卓越基础模型的成功案例均揭示预训练数据集的规模和质量是影响模型泛化性的重要因素[47].尽管遥感领域逐渐涌现出规模较大的预训练数据集(详见第1节),但仍然缺乏不同卫星源、不同波段组合、不同空间分辨率、不同成像模式的多模态预训练数据集,无法支撑多模态遥感基础大模型的充分训练.此外,全面、统一、可靠的评估基准能够帮助全面衡量遥感基础模型的能力.早期遥感基础模型评估所选用的数据集、下游任务、评估方式各不相同,未形成系统全面的评估数据集及指标体系.笔者所在团队提出的SkySense[18]在单模态图像级分类、目标级识别、像素级分割、多模态时序分类等众多数据集上建立了统一的评估基准结果,以方便后续方法进行对比.未来还应该不断补充更多任务类型.此外,在弱监督下游任务的条件下评估预训练模型的泛化性更加符合实际应用场景的需求,如评估在少样本、含大量噪声标签等下游数据条件下遥感基础大模型的稳健性. ...
Geography-aware self-supervised learning
2
2021
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
... (1)时空结构信息挖掘与利用.遥感影像附带成像时间、经纬度坐标等元信息,这些地学时空信息能够有效改善遥感基础模型预训练性能.如,拍摄自同一地点但不同成像时间的遥感影像可用于对比预训练[12-13];地理坐标编码可作为预训练的代理任务[48];地理坐标、成像时间等时空信息可用作预训练约束条件[76];结合视觉信息学习的地理位置编码器[14]可进行特定区域的变量回归等任务. ...
Self-supervised material and texture representation learning for remote sensing tasks
1
2022
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
DINO-MC: self-supervised contrastive learning for remote sensing imagery with multi-sized local crops
1
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection
1
... 相较于自然图像,遥感影像往往附带时空地理元信息,并呈现出不同的空间尺度.遥感领域专家学者利用遥感数据的时空基准信息改造基础模型,将其扩展应对遥感数据分析.如,GASSL[48]利用地理位置预测作为MoCo-v2框架中的额外代理任务.SeCo[12]和CACo[13]通过使用时间序列的时空结构来感知影像中地物的短期和长期变化.文献[20]使用自然图像和遥感图像作为初步和后续的预训练数据,构建正、负样本对进行对比学习,试验结果表明预训练数据的类别平衡性对于预训练模型学习有效通用表征是十分关键的.MATTER[49]对照明和视角不变性进行建模,以确保纹理在不变区域上的一致表示.DINO-MC[50]则利用不同大小的多个视图在DINO框架[51]内进行自监督学习. ...
A billion-scale foundation model for remote sensing images
1
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
RingMo-lite: a remote sensing multi-task lightweight network with CNN-transformer hybrid framework
1
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
Advancing plain vision transformer toward remote sensing foundation model
1
2023
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
RingMo: a remote sensing foundation model with masked image modeling
1
2023
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
Scale-MAE: a scale-aware masked autoencoder for multiscale geospatial representation learning
1
2023
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
SpectralGPT: spectral foundation modele
1
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
Foundation models for generalist geospatial artificial intelligence
1
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
USat: a unified self-supervised encoder for multi-sensor satellite imagery
1
... 此外,许多研究致力于改进基于掩码图像建模的框架,或者探索模型规模扩展[52]以及模型轻量化部署[53].在可见光遥感影像为预训练数据的背景下,文献[54]提出了旋转可变大小窗口注意力方法处理遥感图像中大尺寸和任意方向的地物,并利用MillionAID设计了遥感亿级参数量的视觉大模型.RingMo[55]对MAE进行修改,更好地应对遥感影像密集目标检测任务.Scale-MAE[56]构建了一个带有尺度感知位置编码和拉普拉斯金字塔解码器的框架,实现了多尺度解码低频和高频特征.对于拥有更加丰富光谱信息的多光谱遥感影像数据,SpectralGPT[57]将多光谱图像作为3D张量数据进行掩码图像建模,提出多目标重建损失,有效捕捉空间光谱耦合特征和光谱顺序信息.考虑到卫星传感器能够以非规则和一定频率获取某一地点的时序多光谱影像,Prithiv[58]将常规的2D位置编码适应性改造为3D版本,由于其具有处理遥感时序数据的能力,该模型被成功应用于洪水检测、多时相农作物分割等场景.相似地,SatMAE[28]则利用时序多光谱数据来提高和验证基础模型处理时间序列的表现.为解决多光谱影像引起显存占用大的问题,现有遥感基础模型无法应对任意波段数据输入的缺陷,USat[59]首先对光学遥感影像的每个波段独立编码,然后使用光谱组池化操作聚合不同光谱波段的信息,同时保留不同空间分辨率的图像地理位置对齐位置编码.文献[17]借鉴掩码图像建模思想,提出特征引导的掩码自编码器,分别利用多光谱和合成孔径雷达影像重建人工特征描述符(如归一化指数、方向梯度直方图),结果表明相较于直接重建图像通过重建抽象特征可以获得更好的特征学习能力. ...
Towards geospatial foundation models via continual pretraining
1
2023
... 近期,CMID[21]、GFM[60]、Cross-Scale MAE[61]等研究将对比学习范式与掩码图像重建范式相结合,在场景分类、目标检测、语义分割、变化检测等众多图像级、对象级、像素级的典型遥感解译任务中展现出明显性能优势.类似地,CtxMIM[62]则在重建掩码图像损失的基础上增加上下文一致性约束,以提供额外的上下文信息.与大多数基础模型采用自监督预训练方法不同,SatLas[23]依托自建的具有丰富标注类型的大规模数据集SatlasPretrain进行有监督预训练,并将模型应用于热带雨林砍伐检测、可再生能源基础设施检测等任务.文献[63]面向遥感时空预测任务设计了包含空间、时间、时空建模3个分支的基础模型,并在雷达回波外推、卫星视频多目标跟踪和遥感视频预测等下游任务中取得了具有竞争力的结果. ...
Cross-scale MAE: a tale of multiscale exploitation in remote sensing
1
2023
... 近期,CMID[21]、GFM[60]、Cross-Scale MAE[61]等研究将对比学习范式与掩码图像重建范式相结合,在场景分类、目标检测、语义分割、变化检测等众多图像级、对象级、像素级的典型遥感解译任务中展现出明显性能优势.类似地,CtxMIM[62]则在重建掩码图像损失的基础上增加上下文一致性约束,以提供额外的上下文信息.与大多数基础模型采用自监督预训练方法不同,SatLas[23]依托自建的具有丰富标注类型的大规模数据集SatlasPretrain进行有监督预训练,并将模型应用于热带雨林砍伐检测、可再生能源基础设施检测等任务.文献[63]面向遥感时空预测任务设计了包含空间、时间、时空建模3个分支的基础模型,并在雷达回波外推、卫星视频多目标跟踪和遥感视频预测等下游任务中取得了具有竞争力的结果. ...
CtxMIM: context-enhanced masked image modeling for remote sensing image understanding
1
... 近期,CMID[21]、GFM[60]、Cross-Scale MAE[61]等研究将对比学习范式与掩码图像重建范式相结合,在场景分类、目标检测、语义分割、变化检测等众多图像级、对象级、像素级的典型遥感解译任务中展现出明显性能优势.类似地,CtxMIM[62]则在重建掩码图像损失的基础上增加上下文一致性约束,以提供额外的上下文信息.与大多数基础模型采用自监督预训练方法不同,SatLas[23]依托自建的具有丰富标注类型的大规模数据集SatlasPretrain进行有监督预训练,并将模型应用于热带雨林砍伐检测、可再生能源基础设施检测等任务.文献[63]面向遥感时空预测任务设计了包含空间、时间、时空建模3个分支的基础模型,并在雷达回波外推、卫星视频多目标跟踪和遥感视频预测等下游任务中取得了具有竞争力的结果. ...
RingMo-sense: remote sensing foundation model for spatiotemporal prediction via spatiotemporal evolution disentangling
1
2023
... 近期,CMID[21]、GFM[60]、Cross-Scale MAE[61]等研究将对比学习范式与掩码图像重建范式相结合,在场景分类、目标检测、语义分割、变化检测等众多图像级、对象级、像素级的典型遥感解译任务中展现出明显性能优势.类似地,CtxMIM[62]则在重建掩码图像损失的基础上增加上下文一致性约束,以提供额外的上下文信息.与大多数基础模型采用自监督预训练方法不同,SatLas[23]依托自建的具有丰富标注类型的大规模数据集SatlasPretrain进行有监督预训练,并将模型应用于热带雨林砍伐检测、可再生能源基础设施检测等任务.文献[63]面向遥感时空预测任务设计了包含空间、时间、时空建模3个分支的基础模型,并在雷达回波外推、卫星视频多目标跟踪和遥感视频预测等下游任务中取得了具有竞争力的结果. ...
CROMA: remote sensing representations with contrastive radar-optical masked autoencoders
1
... 除了仅依靠单模态图像预训练的工作外,CROMA[64]和De-CUR[65]研究了使用静态影像进行单模态和多模态图像源的多模态预训练.Presto[66]同时利用时间和地理位置信息,联合多光谱、合成孔径雷达、高程等多模态信息训练了轻量级基础模型.遗憾的是,Presto的预训练数据未包含高分辨率卫星图像,且缺乏在基于高分辨率影像的下游任务上广泛的测试以验证模型的泛化性.文献[67]则关注到跨模态协同解译中异构模态特征的空间相关性问题,采用不同的度量空间(即欧氏空间、复数空间和双曲空间)提取不同模态图像的特征,然后采用统一的编码器进行多模态特征融合.笔者所在团队则发展了目前参数量规模最大的多模态时序遥感基础大模型——SkySense[18](20亿参数量),通过时空解耦、时间感知嵌入等机制联合高分光学遥感影像、时序光学遥感影像、时序合成孔径雷达影像等多模态数据进行多粒度对比学习.值得说明的是,灵活可插拔性和通用特征的强大泛化性使得SkySense在涵盖单模态图像级分类、目标级检测、像素级分割以及多模态农作物时序分类等8项任务(共计16个数据集)中均取得了最先进的水平. ...
Decoupling common and unique representations for multimodal self-supervised learning
1
... 除了仅依靠单模态图像预训练的工作外,CROMA[64]和De-CUR[65]研究了使用静态影像进行单模态和多模态图像源的多模态预训练.Presto[66]同时利用时间和地理位置信息,联合多光谱、合成孔径雷达、高程等多模态信息训练了轻量级基础模型.遗憾的是,Presto的预训练数据未包含高分辨率卫星图像,且缺乏在基于高分辨率影像的下游任务上广泛的测试以验证模型的泛化性.文献[67]则关注到跨模态协同解译中异构模态特征的空间相关性问题,采用不同的度量空间(即欧氏空间、复数空间和双曲空间)提取不同模态图像的特征,然后采用统一的编码器进行多模态特征融合.笔者所在团队则发展了目前参数量规模最大的多模态时序遥感基础大模型——SkySense[18](20亿参数量),通过时空解耦、时间感知嵌入等机制联合高分光学遥感影像、时序光学遥感影像、时序合成孔径雷达影像等多模态数据进行多粒度对比学习.值得说明的是,灵活可插拔性和通用特征的强大泛化性使得SkySense在涵盖单模态图像级分类、目标级检测、像素级分割以及多模态农作物时序分类等8项任务(共计16个数据集)中均取得了最先进的水平. ...
Lightweight, pre-trained transformers for remote sensing timeseries
1
... 除了仅依靠单模态图像预训练的工作外,CROMA[64]和De-CUR[65]研究了使用静态影像进行单模态和多模态图像源的多模态预训练.Presto[66]同时利用时间和地理位置信息,联合多光谱、合成孔径雷达、高程等多模态信息训练了轻量级基础模型.遗憾的是,Presto的预训练数据未包含高分辨率卫星图像,且缺乏在基于高分辨率影像的下游任务上广泛的测试以验证模型的泛化性.文献[67]则关注到跨模态协同解译中异构模态特征的空间相关性问题,采用不同的度量空间(即欧氏空间、复数空间和双曲空间)提取不同模态图像的特征,然后采用统一的编码器进行多模态特征融合.笔者所在团队则发展了目前参数量规模最大的多模态时序遥感基础大模型——SkySense[18](20亿参数量),通过时空解耦、时间感知嵌入等机制联合高分光学遥感影像、时序光学遥感影像、时序合成孔径雷达影像等多模态数据进行多粒度对比学习.值得说明的是,灵活可插拔性和通用特征的强大泛化性使得SkySense在涵盖单模态图像级分类、目标级检测、像素级分割以及多模态农作物时序分类等8项任务(共计16个数据集)中均取得了最先进的水平. ...
A self-supervised cross-modal remote sensing foundation model with multi-domain representation and cross-domain fusion
1
2023
... 除了仅依靠单模态图像预训练的工作外,CROMA[64]和De-CUR[65]研究了使用静态影像进行单模态和多模态图像源的多模态预训练.Presto[66]同时利用时间和地理位置信息,联合多光谱、合成孔径雷达、高程等多模态信息训练了轻量级基础模型.遗憾的是,Presto的预训练数据未包含高分辨率卫星图像,且缺乏在基于高分辨率影像的下游任务上广泛的测试以验证模型的泛化性.文献[67]则关注到跨模态协同解译中异构模态特征的空间相关性问题,采用不同的度量空间(即欧氏空间、复数空间和双曲空间)提取不同模态图像的特征,然后采用统一的编码器进行多模态特征融合.笔者所在团队则发展了目前参数量规模最大的多模态时序遥感基础大模型——SkySense[18](20亿参数量),通过时空解耦、时间感知嵌入等机制联合高分光学遥感影像、时序光学遥感影像、时序合成孔径雷达影像等多模态数据进行多粒度对比学习.值得说明的是,灵活可插拔性和通用特征的强大泛化性使得SkySense在涵盖单模态图像级分类、目标级检测、像素级分割以及多模态农作物时序分类等8项任务(共计16个数据集)中均取得了最先进的水平. ...
A survey of large language models
1
... 在自然语言处理领域,大型语言基础模型在自然语言理解、文本生成、智能问答等任务中取得了显著的成效[68].特别是ChatGPT取得的巨大成功进一步推动了相关研究的发展.视觉-语言基础模型则集成了图像的视觉感知信息和语言的语义信息,旨在从视觉与语言的相互关系中学习通用特征,以更好地完成复杂场景的理解任务[11]. ...
Charting new territories: exploring the geographic and geospatial capabilities of multimodal LLMs
1
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
Remote sensing vision-language foundation models without annotations via ground remote alignment
1
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
STAR: a first-ever dataset and a large-scale benchmark for scene graph generation in large-size satellite imagery
1
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
SkySenseGPT: a fine-grained instruction tuning dataset and model for remote sensing vision-language understanding
1
... 在遥感领域,已有学者开始视觉-语言基础大模型相关研究工作.文献[69]专注于探索前沿的基础大模型(如GPT-4V等)在地理空间领域相关任务上的表现,为后续的研究提供基准参考.文献[34]利用构建的RSICap数据集微调了InstructionBLIP模型得到RSGPT模型,并在图像描述生成、视觉问答任务中显示出具有潜力的效果.RemoteCLIP[35]则采用对比语言-图像预训练(CLIP)方法在创建的视觉-语言数据集上进行了训练,获得的预训练模型在跨模态检索、零/少样本图像分类、目标计数等下游任务中进行了评估.GeoChat[36]致力于构建一个允许用户对给定的遥感影像视觉内容进行对话的多功能视觉-语言基础模型,能够完成图像级、区域级(指定图像中的特定区域)、定位式的对话任务.遗憾的是,目前GeoChat仅支持高分辨率的可见光影像,局限了其在众多下游场景的普适性.由于基于卫星影像的图像文本标注过程需要专家知识的干预,成本消耗巨大,目前已有的图像-文本描述数据相较于计算机视觉领域规模小很多.最近,GRAFT[70]考虑利用大规模带有地理位置信息的互联网数据作为数据中介,通过训练对齐相同地理位置的卫星影像和互联网图像的视觉特征,从卫星影像中抽取的视觉特征、互联网图像对应的视觉特征与已经训练好的文本语义特征共享至同一特征空间,从而在不需要文本标注的条件下实现影像编码与文本编码的关联.这大大降低了遥感视觉-语言模型训练的数据标注成本,为该方向提供了一个思路.此外,笔者所在团队创建了一个大规模遥感场景图数据集STAR[71],并在此基础上延伸拓展出细粒度视觉-语言指令微调数据集FIT-RS及相应的视觉-语言基础模型SkySenseGPT[72].SkySenseGPT具有对实例间关系的细粒度感知能力,能够基于用户指令完成复杂的图文交互任务. ...
GeoCLIP: clip-inspired alignment between locations and images for effective worldwide geo-localization
1
... 在计算机视觉领域中,一些学者采用了配对的自然图像和GPS数据训练位置编码器,以解决全球图像地理定位的挑战.如,GeoCLIP[73]设计了位置编码器,将GPS坐标映射为高维特征嵌入,并使用经过预训练的CLIP模型[6]作为图像编码器提取图像特征.随后,该研究将位置特征与图像特征映射到共享嵌入空间进行对比学习.不同地理位置的遥感影像的视觉特征受到与地理位置相关的气候、人口密度等自然环境和社会因素的密切影响.在这一背景下,CSP[74]采用多种方式构造正负样本对,并通过遥感数据集预训练后的图像编码器与提出的位置编码器进行对比学习.SatCLIP[14]则致力于捕捉全球不同地区的哨兵2号卫星影像的空间异质性,通过对比预训练的方式学习位置编码特征表示.相关试验证明,SatCLIP模型的位置编码器成功学习到了与特定区域的社会经济与环境等因素高度相关的特征表示.上述技术为进一步深入分析地理位置与遥感影像之间的关联提供了有力支持. ...
CSP: self-supervised contrastive spatial pre-training for geospatial-visual representations
1
... 在计算机视觉领域中,一些学者采用了配对的自然图像和GPS数据训练位置编码器,以解决全球图像地理定位的挑战.如,GeoCLIP[73]设计了位置编码器,将GPS坐标映射为高维特征嵌入,并使用经过预训练的CLIP模型[6]作为图像编码器提取图像特征.随后,该研究将位置特征与图像特征映射到共享嵌入空间进行对比学习.不同地理位置的遥感影像的视觉特征受到与地理位置相关的气候、人口密度等自然环境和社会因素的密切影响.在这一背景下,CSP[74]采用多种方式构造正负样本对,并通过遥感数据集预训练后的图像编码器与提出的位置编码器进行对比学习.SatCLIP[14]则致力于捕捉全球不同地区的哨兵2号卫星影像的空间异质性,通过对比预训练的方式学习位置编码特征表示.相关试验证明,SatCLIP模型的位置编码器成功学习到了与特定区域的社会经济与环境等因素高度相关的特征表示.上述技术为进一步深入分析地理位置与遥感影像之间的关联提供了有力支持. ...
Zooming out on zooming in: advancing super-resolution for remote sensing
1
... 遥感影像超分辨率重建、云去除等生成式解译方法能够帮助人类更完整、更细致地观察地表自然环境和人类活动的变化,吸引了众多学者的关注[4,75].然而,先前的研究主要集中在为特定生成任务设计专用模型上,导致在实际应用中灵活性和通用性相对不足.稳定扩散模型(stable diffusion)在图像重建、视频生成等任务上取得显著进展,这使得诸多学者将其应用于多种遥感图像生成式任务,并取得了一定的进展.文献[76]采用文本描述、遥感影像以及附带的地理元信息(包括地理坐标、成像时间、空间分辨率等)训练了遥感生成式基础模型DiffusionSat.该模型在单个遥感图像生成、多光谱图像超分辨率重建、时序图像生成和图像修复等多个下游任务上取得了先进的性能表现.文献[77]则采用预训练扩散模型学习公开地图数据,可以生成视觉效果逼真、地物类别可控的合成卫星图像.该技术可以为数据缺失任务场景补充额外样本数据.尽管目前遥感生成式基础大模型仍处于初步发展阶段,研究成果相对较少,但其应用潜力巨大,预计将吸引更多学者深入研究.未来,我们可以期待这一领域的快速发展,为遥感生成式解译提供更为灵活、通用且性能卓越的模型. ...
DiffusionSat: a generative foundation model for satellite imagery
2
... 遥感影像超分辨率重建、云去除等生成式解译方法能够帮助人类更完整、更细致地观察地表自然环境和人类活动的变化,吸引了众多学者的关注[4,75].然而,先前的研究主要集中在为特定生成任务设计专用模型上,导致在实际应用中灵活性和通用性相对不足.稳定扩散模型(stable diffusion)在图像重建、视频生成等任务上取得显著进展,这使得诸多学者将其应用于多种遥感图像生成式任务,并取得了一定的进展.文献[76]采用文本描述、遥感影像以及附带的地理元信息(包括地理坐标、成像时间、空间分辨率等)训练了遥感生成式基础模型DiffusionSat.该模型在单个遥感图像生成、多光谱图像超分辨率重建、时序图像生成和图像修复等多个下游任务上取得了先进的性能表现.文献[77]则采用预训练扩散模型学习公开地图数据,可以生成视觉效果逼真、地物类别可控的合成卫星图像.该技术可以为数据缺失任务场景补充额外样本数据.尽管目前遥感生成式基础大模型仍处于初步发展阶段,研究成果相对较少,但其应用潜力巨大,预计将吸引更多学者深入研究.未来,我们可以期待这一领域的快速发展,为遥感生成式解译提供更为灵活、通用且性能卓越的模型. ...
... (1)时空结构信息挖掘与利用.遥感影像附带成像时间、经纬度坐标等元信息,这些地学时空信息能够有效改善遥感基础模型预训练性能.如,拍摄自同一地点但不同成像时间的遥感影像可用于对比预训练[12-13];地理坐标编码可作为预训练的代理任务[48];地理坐标、成像时间等时空信息可用作预训练约束条件[76];结合视觉信息学习的地理位置编码器[14]可进行特定区域的变量回归等任务. ...
Generate your own Scotland: satellite image generation conditioned on maps
2
... 遥感影像超分辨率重建、云去除等生成式解译方法能够帮助人类更完整、更细致地观察地表自然环境和人类活动的变化,吸引了众多学者的关注[4,75].然而,先前的研究主要集中在为特定生成任务设计专用模型上,导致在实际应用中灵活性和通用性相对不足.稳定扩散模型(stable diffusion)在图像重建、视频生成等任务上取得显著进展,这使得诸多学者将其应用于多种遥感图像生成式任务,并取得了一定的进展.文献[76]采用文本描述、遥感影像以及附带的地理元信息(包括地理坐标、成像时间、空间分辨率等)训练了遥感生成式基础模型DiffusionSat.该模型在单个遥感图像生成、多光谱图像超分辨率重建、时序图像生成和图像修复等多个下游任务上取得了先进的性能表现.文献[77]则采用预训练扩散模型学习公开地图数据,可以生成视觉效果逼真、地物类别可控的合成卫星图像.该技术可以为数据缺失任务场景补充额外样本数据.尽管目前遥感生成式基础大模型仍处于初步发展阶段,研究成果相对较少,但其应用潜力巨大,预计将吸引更多学者深入研究.未来,我们可以期待这一领域的快速发展,为遥感生成式解译提供更为灵活、通用且性能卓越的模型. ...
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
知识图谱约束深度网络的高分辨率遥感影像场景分类
1
2024
... 地学知识主要包括地表人类活动与自然演变呈现的规律性时空先验信息和领域专家知识[78].基于深度学习的智能遥感解译模型往往以数据驱动为主,解译模型的泛化性较低,同时缺乏足够的可解释性.为了弥补这一不足,引入地学知识成为提升解译模型性能的有效手段.本节首先回顾了地学知识引导的智能遥感解译技术,然后着重探讨了地学知识在提高智能遥感解译模型性能和可解释性等方面的潜在作用,最后对目前遥感基础大模型挖掘和利用地学知识的方法进行了分类阐述,旨在为未来相关研究提供参考和启示. ...
知识图谱约束深度网络的高分辨率遥感影像场景分类
1
2024
... 地学知识主要包括地表人类活动与自然演变呈现的规律性时空先验信息和领域专家知识[78].基于深度学习的智能遥感解译模型往往以数据驱动为主,解译模型的泛化性较低,同时缺乏足够的可解释性.为了弥补这一不足,引入地学知识成为提升解译模型性能的有效手段.本节首先回顾了地学知识引导的智能遥感解译技术,然后着重探讨了地学知识在提高智能遥感解译模型性能和可解释性等方面的潜在作用,最后对目前遥感基础大模型挖掘和利用地学知识的方法进行了分类阐述,旨在为未来相关研究提供参考和启示. ...
Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification
2
2021
... 近年来,面向遥感影像智能解译的地学知识引导技术受到国内外研究学者的广泛关注.在这一方向,笔者所在团队取得了若干研究进展[79-85]. ...
... (1)利用自然语言嵌入模型或知识图谱表征模型引导的零样本遥感影像场景分类.如,文献[79]创建了遥感知识图谱SR-RSKG并开展知识图谱语义表征学习,进一步提出一种深度对齐网络在隐式空间中稳健地匹配视觉特征和语义特征,从而实现零样本遥感图像场景分类.SR-RSKG包含丰富的显式关系信息(即“实体-关系-实体”或“实体-属性-属性值”),有助于更准确地描述复杂遥感场景. ...
Learning deep cross-modal embedding networks for zero-shot remote sensing image scene classification
0
2021
DKDFN: domain knowledge-guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification
1
2022
... (3)经验知识引导的多模态遥感影像土地覆盖分类.通过融合光学、合成孔径雷达和高程等多模态信息,文献[81]提出了遥感指数等领域知识引导的深度协作融合网络(DKDFN).该网络通过多头编码器协作融合多模态数据,利用多分支解码器创建多任务学习策略重建地学知识,显著提高了在土地覆盖分类任务上的精度和稳健性. ...
Combining deep learning and ontology reasoning for remote sensing image semantic segmentation
1
2022
... (2)耦合知识图谱和深度网络的光学遥感影像语义分割.鉴于数据驱动的深度学习技术在可解释性方面存在不足,文献[82]借助遥感知识图谱的丰富语义关系建模与强大推理能力,引入高层次专家知识修正深度网络输出结果,并将知识推理输出用于进一步辅助深度学习模型的训练.此外,地物空间共生知识[85]也被用于提升遥感影像语义分割精度. ...
Multi-source knowledge graph reasoning for ocean oil spill detection from satellite SAR images
1
2023
... (4)多模态知识图谱推理驱动的合成孔径雷达影像溢油监测.文献[83]通过整合遥感影像、矢量、文本信息和大气-海洋模型信息等构建了海洋溢油监测知识图谱,结合规则推理和图神经网络方法可以在数据类别极不平衡的条件下得到优异的海洋溢油监测结果.通过构建多模态知识图谱,可以将与溢油监测相关的先验知识有效地组织在一起,从而克服传统方法存在的信息孤岛问题.在知识推理后,所有推理结果可以集成到知识图谱中,使知识图谱能够不断迭代演进,进而实现高精度溢油检测. ...
耦合知识图谱和深度学习的新一代遥感影像解译范式
2
2022
... 从上述的代表性地学知识引导的遥感影像解译算法可以看出,耦合地学知识的方式是多种多样的.由于结构化知识图谱具备可计算、可推理、可进化等优势,耦合地学知识图谱和深度学习有望成为新一代遥感智能解译范式[84],为地学知识引导的遥感基础大模型研究提供有益的参考. ...
... (4)地学知识图谱构建与引导.在具体的遥感智能解译任务中引入地学知识以提升深度网络的性能和可解释性已经受到许多学者关注.地学知识图谱的构建和利用也被认为是未来遥感解译的发展趋势之一[84,91].通过将源自文本语料库、时空信息、地形地貌、场景先验与专家知识等的地学知识整合,以知识图谱的统一形式进行重构并融入遥感基础模型的训练和推理过程是提升基础模型的性能和可解释性的重要方向之一.地学知识图谱的构建与融入不仅可以提升遥感基础大模型的实际性能表现,还有望为遥感下游应用提供更为全面和深度的结果溯源解释. ...
耦合知识图谱和深度学习的新一代遥感影像解译范式
2
2022
... 从上述的代表性地学知识引导的遥感影像解译算法可以看出,耦合地学知识的方式是多种多样的.由于结构化知识图谱具备可计算、可推理、可进化等优势,耦合地学知识图谱和深度学习有望成为新一代遥感智能解译范式[84],为地学知识引导的遥感基础大模型研究提供有益的参考. ...
... (4)地学知识图谱构建与引导.在具体的遥感智能解译任务中引入地学知识以提升深度网络的性能和可解释性已经受到许多学者关注.地学知识图谱的构建和利用也被认为是未来遥感解译的发展趋势之一[84,91].通过将源自文本语料库、时空信息、地形地貌、场景先验与专家知识等的地学知识整合,以知识图谱的统一形式进行重构并融入遥感基础模型的训练和推理过程是提升基础模型的性能和可解释性的重要方向之一.地学知识图谱的构建与融入不仅可以提升遥感基础大模型的实际性能表现,还有望为遥感下游应用提供更为全面和深度的结果溯源解释. ...
地学知识图谱引导的遥感影像语义分割
2
2024
... 近年来,面向遥感影像智能解译的地学知识引导技术受到国内外研究学者的广泛关注.在这一方向,笔者所在团队取得了若干研究进展[79-85]. ...
... (2)耦合知识图谱和深度网络的光学遥感影像语义分割.鉴于数据驱动的深度学习技术在可解释性方面存在不足,文献[82]借助遥感知识图谱的丰富语义关系建模与强大推理能力,引入高层次专家知识修正深度网络输出结果,并将知识推理输出用于进一步辅助深度学习模型的训练.此外,地物空间共生知识[85]也被用于提升遥感影像语义分割精度. ...
地学知识图谱引导的遥感影像语义分割
2
2024
... 近年来,面向遥感影像智能解译的地学知识引导技术受到国内外研究学者的广泛关注.在这一方向,笔者所在团队取得了若干研究进展[79-85]. ...
... (2)耦合知识图谱和深度网络的光学遥感影像语义分割.鉴于数据驱动的深度学习技术在可解释性方面存在不足,文献[82]借助遥感知识图谱的丰富语义关系建模与强大推理能力,引入高层次专家知识修正深度网络输出结果,并将知识推理输出用于进一步辅助深度学习模型的训练.此外,地物空间共生知识[85]也被用于提升遥感影像语义分割精度. ...
Collaborative validation of GlobeLand30: methodology and practices
1
2021
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
Stable classification with limited sample: transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017
1
2019
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
Adding conditional control to text-to-image diffusion models
1
2023
... (2)土地覆盖分类产品嵌入学习.土地覆盖分类产品(如GlobeLand30[86]、FROM_GLC10[87]等)蕴含着丰富的地学先验知识.这些地学先验信息的嵌入建模正成为遥感基础大模型研究热点.GeoKR[15]通过对齐视觉特征与公开地学产品提取出的知识特征促进骨干网络学习,以缓解遥感影像和地理知识之间的时间与空间分辨率差异的影响.GeCo[16]根据地学产品中“时序变化小”“空间聚合性高”的先验信息定义可学习的纠正矩阵,以学习地学产品中的类别分布特点.此外,利用地学先验信息干预参与预训练的遥感数据的类别平衡,能够在一定程度上改善基础模型学习到的通用特征的有效性[20].结合地学先验知识和生成式基础模型,文献[77]将开放街道图(OSM)提供的道路、建筑物等地物目标信息作为输入条件,基于ControlNet[88]生成内容可控的遥感合成影像,有望应用于众多下游任务的有监督数据扩展. ...
定量遥感与机器学习能够融合吗?
1
2022
... (3)地学参量约束.定量遥感旨在将多源遥感观测数据定量反演或推算为地学目标参量,形成时空遥感数据产品[89].相关地学参量(如归一化指数等)通过物理机理、成像光谱信息反映地表的属性信息,FG-MAE[17]结合经典的掩码图像建模算法重建相关地学参量,从而约束大模型参数更新. ...
定量遥感与机器学习能够融合吗?
1
2022
... (3)地学参量约束.定量遥感旨在将多源遥感观测数据定量反演或推算为地学目标参量,形成时空遥感数据产品[89].相关地学参量(如归一化指数等)通过物理机理、成像光谱信息反映地表的属性信息,FG-MAE[17]结合经典的掩码图像建模算法重建相关地学参量,从而约束大模型参数更新. ...
The validity and usefulness of laws in geographic information science and geography
1
2004
... (4)隐式地学知识挖掘与融合.地理景观的形成是气候、地质、水文、生物多样性和人类活动等多种因素的错综复杂相互作用[90].这些因素共同促使地理区域呈现出特定的地理特征,即不同地区的遥感影像往往呈现出明显的地理异质性.笔者所在团队提出的SkySense[18]发展了地理空间敏感的上下文学习范式,旨在从遥感大数据中隐式挖掘与融合地学知识.具体而言,将全球划分为众多子区域,通过对地理位置特定的大规模多模态时序遥感影像进行无监督学习,以隐式挖掘时空敏感的聚类特征,这些聚类特征一定程度上可以较好地反映不同区域的语义先验.在推理阶段,可以通过注意力机制融合视觉特征和语义先验来改善遥感影像的解译性能. ...
遥感大数据智能解译的地理学认知模型与方法
1
2022
... (4)地学知识图谱构建与引导.在具体的遥感智能解译任务中引入地学知识以提升深度网络的性能和可解释性已经受到许多学者关注.地学知识图谱的构建和利用也被认为是未来遥感解译的发展趋势之一[84,91].通过将源自文本语料库、时空信息、地形地貌、场景先验与专家知识等的地学知识整合,以知识图谱的统一形式进行重构并融入遥感基础模型的训练和推理过程是提升基础模型的性能和可解释性的重要方向之一.地学知识图谱的构建与融入不仅可以提升遥感基础大模型的实际性能表现,还有望为遥感下游应用提供更为全面和深度的结果溯源解释. ...
遥感大数据智能解译的地理学认知模型与方法
1
2022
... (4)地学知识图谱构建与引导.在具体的遥感智能解译任务中引入地学知识以提升深度网络的性能和可解释性已经受到许多学者关注.地学知识图谱的构建和利用也被认为是未来遥感解译的发展趋势之一[84,91].通过将源自文本语料库、时空信息、地形地貌、场景先验与专家知识等的地学知识整合,以知识图谱的统一形式进行重构并融入遥感基础模型的训练和推理过程是提升基础模型的性能和可解释性的重要方向之一.地学知识图谱的构建与融入不仅可以提升遥感基础大模型的实际性能表现,还有望为遥感下游应用提供更为全面和深度的结果溯源解释. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}