Brain-inspired remote sensing foundation models and open problems: a comprehensive survey
1
2023
... AI大模型(也称“基础模型”)是人工智能预训练大模型的简称,其主要采用卷积神经网络、循环神经网络、自注意力机制、Transformer等架构,在海量数据上进行训练,能适应多种下游任务,具有很好的泛化性、通用性和实用性,是计算机视觉、自然语言处理等各类AI应用的基石[1-2]. ...
An agenda for multimodal foundation models for earth observation
1
2023
... AI大模型(也称“基础模型”)是人工智能预训练大模型的简称,其主要采用卷积神经网络、循环神经网络、自注意力机制、Transformer等架构,在海量数据上进行训练,能适应多种下游任务,具有很好的泛化性、通用性和实用性,是计算机视觉、自然语言处理等各类AI应用的基石[1-2]. ...
Gradient-based learning applied to document recognition
1
1998
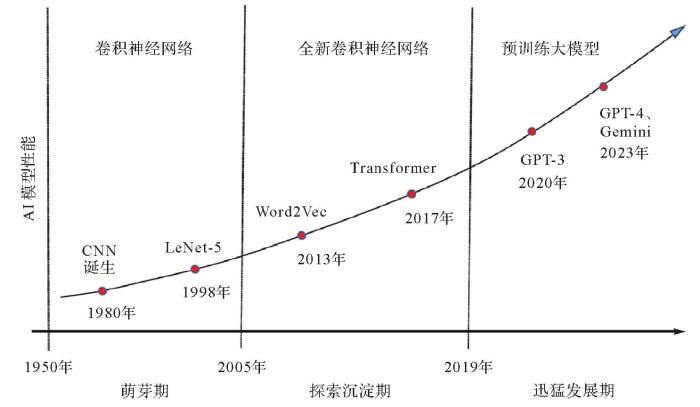
... AI模型的发展历程(图1)如下:第一个阶段是萌芽期(1950—2005年),该阶段是以CNN为代表的卷积神经网络阶段.1980年,卷积神经网络的雏形诞生;1998年,现代卷积神经网络的基本结构LeNet-5[3]诞生.此阶段的AI模型以简单的浅层神经网络为主,不具备处理复杂任务的能力.第二个阶段是探索沉淀期(2006—2019年),该阶段是以Transformer为代表的全新神经网络模型阶段.2013年,自然语言处理模型Word2Vec[4]诞生,首次提出将单词转换为向量的“词向量模型”;2017年,Google颠覆性地提出了自注意力机制神经网络结构Transformer[5],奠定了大模型预训练算法架构的基础.在此阶段,深度神经网络受到了广泛关注,但提出的模型一般针对的是单一任务,模型的通用性和泛化性不足.第三个阶段是迅猛发展期(2020年至今),该阶段是以GPT为代表的预训练大模型阶段.2020年,OpenAI公司推出了GPT-3[6],模型参数规模达到了1750亿,成为当时最大的语言模型;2023年3月,发布的超大规模多模态预训练大模型GPT-4[7],具备了多模态理解与多类型内容生成能力;2023年12月,谷歌推出全新大语言模型Gemini[8],具备多模态理解、逻辑推理等能力.此阶段AI模型逐渐落地应用,在生产和生活中发挥越来越重要的作用. ...
Efficient estimation of word representations in vector space
1
... AI模型的发展历程(图1)如下:第一个阶段是萌芽期(1950—2005年),该阶段是以CNN为代表的卷积神经网络阶段.1980年,卷积神经网络的雏形诞生;1998年,现代卷积神经网络的基本结构LeNet-5[3]诞生.此阶段的AI模型以简单的浅层神经网络为主,不具备处理复杂任务的能力.第二个阶段是探索沉淀期(2006—2019年),该阶段是以Transformer为代表的全新神经网络模型阶段.2013年,自然语言处理模型Word2Vec[4]诞生,首次提出将单词转换为向量的“词向量模型”;2017年,Google颠覆性地提出了自注意力机制神经网络结构Transformer[5],奠定了大模型预训练算法架构的基础.在此阶段,深度神经网络受到了广泛关注,但提出的模型一般针对的是单一任务,模型的通用性和泛化性不足.第三个阶段是迅猛发展期(2020年至今),该阶段是以GPT为代表的预训练大模型阶段.2020年,OpenAI公司推出了GPT-3[6],模型参数规模达到了1750亿,成为当时最大的语言模型;2023年3月,发布的超大规模多模态预训练大模型GPT-4[7],具备了多模态理解与多类型内容生成能力;2023年12月,谷歌推出全新大语言模型Gemini[8],具备多模态理解、逻辑推理等能力.此阶段AI模型逐渐落地应用,在生产和生活中发挥越来越重要的作用. ...
Attention is all you need
1
... AI模型的发展历程(图1)如下:第一个阶段是萌芽期(1950—2005年),该阶段是以CNN为代表的卷积神经网络阶段.1980年,卷积神经网络的雏形诞生;1998年,现代卷积神经网络的基本结构LeNet-5[3]诞生.此阶段的AI模型以简单的浅层神经网络为主,不具备处理复杂任务的能力.第二个阶段是探索沉淀期(2006—2019年),该阶段是以Transformer为代表的全新神经网络模型阶段.2013年,自然语言处理模型Word2Vec[4]诞生,首次提出将单词转换为向量的“词向量模型”;2017年,Google颠覆性地提出了自注意力机制神经网络结构Transformer[5],奠定了大模型预训练算法架构的基础.在此阶段,深度神经网络受到了广泛关注,但提出的模型一般针对的是单一任务,模型的通用性和泛化性不足.第三个阶段是迅猛发展期(2020年至今),该阶段是以GPT为代表的预训练大模型阶段.2020年,OpenAI公司推出了GPT-3[6],模型参数规模达到了1750亿,成为当时最大的语言模型;2023年3月,发布的超大规模多模态预训练大模型GPT-4[7],具备了多模态理解与多类型内容生成能力;2023年12月,谷歌推出全新大语言模型Gemini[8],具备多模态理解、逻辑推理等能力.此阶段AI模型逐渐落地应用,在生产和生活中发挥越来越重要的作用. ...
Language models are few-shot learners
1
2020
... AI模型的发展历程(图1)如下:第一个阶段是萌芽期(1950—2005年),该阶段是以CNN为代表的卷积神经网络阶段.1980年,卷积神经网络的雏形诞生;1998年,现代卷积神经网络的基本结构LeNet-5[3]诞生.此阶段的AI模型以简单的浅层神经网络为主,不具备处理复杂任务的能力.第二个阶段是探索沉淀期(2006—2019年),该阶段是以Transformer为代表的全新神经网络模型阶段.2013年,自然语言处理模型Word2Vec[4]诞生,首次提出将单词转换为向量的“词向量模型”;2017年,Google颠覆性地提出了自注意力机制神经网络结构Transformer[5],奠定了大模型预训练算法架构的基础.在此阶段,深度神经网络受到了广泛关注,但提出的模型一般针对的是单一任务,模型的通用性和泛化性不足.第三个阶段是迅猛发展期(2020年至今),该阶段是以GPT为代表的预训练大模型阶段.2020年,OpenAI公司推出了GPT-3[6],模型参数规模达到了1750亿,成为当时最大的语言模型;2023年3月,发布的超大规模多模态预训练大模型GPT-4[7],具备了多模态理解与多类型内容生成能力;2023年12月,谷歌推出全新大语言模型Gemini[8],具备多模态理解、逻辑推理等能力.此阶段AI模型逐渐落地应用,在生产和生活中发挥越来越重要的作用. ...
GPT-4 technical report
1
... AI模型的发展历程(图1)如下:第一个阶段是萌芽期(1950—2005年),该阶段是以CNN为代表的卷积神经网络阶段.1980年,卷积神经网络的雏形诞生;1998年,现代卷积神经网络的基本结构LeNet-5[3]诞生.此阶段的AI模型以简单的浅层神经网络为主,不具备处理复杂任务的能力.第二个阶段是探索沉淀期(2006—2019年),该阶段是以Transformer为代表的全新神经网络模型阶段.2013年,自然语言处理模型Word2Vec[4]诞生,首次提出将单词转换为向量的“词向量模型”;2017年,Google颠覆性地提出了自注意力机制神经网络结构Transformer[5],奠定了大模型预训练算法架构的基础.在此阶段,深度神经网络受到了广泛关注,但提出的模型一般针对的是单一任务,模型的通用性和泛化性不足.第三个阶段是迅猛发展期(2020年至今),该阶段是以GPT为代表的预训练大模型阶段.2020年,OpenAI公司推出了GPT-3[6],模型参数规模达到了1750亿,成为当时最大的语言模型;2023年3月,发布的超大规模多模态预训练大模型GPT-4[7],具备了多模态理解与多类型内容生成能力;2023年12月,谷歌推出全新大语言模型Gemini[8],具备多模态理解、逻辑推理等能力.此阶段AI模型逐渐落地应用,在生产和生活中发挥越来越重要的作用. ...
Gemini: a family of highly capable multimodal models
1
... AI模型的发展历程(图1)如下:第一个阶段是萌芽期(1950—2005年),该阶段是以CNN为代表的卷积神经网络阶段.1980年,卷积神经网络的雏形诞生;1998年,现代卷积神经网络的基本结构LeNet-5[3]诞生.此阶段的AI模型以简单的浅层神经网络为主,不具备处理复杂任务的能力.第二个阶段是探索沉淀期(2006—2019年),该阶段是以Transformer为代表的全新神经网络模型阶段.2013年,自然语言处理模型Word2Vec[4]诞生,首次提出将单词转换为向量的“词向量模型”;2017年,Google颠覆性地提出了自注意力机制神经网络结构Transformer[5],奠定了大模型预训练算法架构的基础.在此阶段,深度神经网络受到了广泛关注,但提出的模型一般针对的是单一任务,模型的通用性和泛化性不足.第三个阶段是迅猛发展期(2020年至今),该阶段是以GPT为代表的预训练大模型阶段.2020年,OpenAI公司推出了GPT-3[6],模型参数规模达到了1750亿,成为当时最大的语言模型;2023年3月,发布的超大规模多模态预训练大模型GPT-4[7],具备了多模态理解与多类型内容生成能力;2023年12月,谷歌推出全新大语言模型Gemini[8],具备多模态理解、逻辑推理等能力.此阶段AI模型逐渐落地应用,在生产和生活中发挥越来越重要的作用. ...
On the opportunities and risks of foundation models
1
... AI大模型具有以下价值:①高泛化通用性.大模型由多个专家模型集成,通过学习大量数据和任务获得广泛知识,捕捉更多细节,具有解决多种下游任务的能力,并且可以更好地泛化到新的数据集中.②高精度.具有更多参数和更深层次结构,能对复杂的模式和规律进行准确建模,并通过不断学习和更新参数提高性能和准确度.③降低门槛.大模型可以自动学习更多特征和规律,减少手动特征工程的需求,使开发者能更轻松地构建高质量模型,节省了大量的训练时间和计算资源,并且用户可以通过唯一接口轻松调用各项功能,执行各项下游任务[9-11]. ...
Self-supervised remote sensing feature learning: learning paradigms, challenges, and future works
0
2023
SpectralGPT: spectral remote sensing foundation model
2
... AI大模型具有以下价值:①高泛化通用性.大模型由多个专家模型集成,通过学习大量数据和任务获得广泛知识,捕捉更多细节,具有解决多种下游任务的能力,并且可以更好地泛化到新的数据集中.②高精度.具有更多参数和更深层次结构,能对复杂的模式和规律进行准确建模,并通过不断学习和更新参数提高性能和准确度.③降低门槛.大模型可以自动学习更多特征和规律,减少手动特征工程的需求,使开发者能更轻松地构建高质量模型,节省了大量的训练时间和计算资源,并且用户可以通过唯一接口轻松调用各项功能,执行各项下游任务[9-11]. ...
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
遥感大模型:进展与前瞻
2
2023
... 遥感大模型是利用卷积神经网络、循环神经网络、自注意力机制、Transformer等先进的深度学习结构,通过对大规模遥感数据进行训练,实现对地物分类、目标检测、语义分割、变化检测等任务的高效处理[12-13].国内外遥感领域的商业公司、高校及科研院所陆续推出遥感大模型平台,在一定程度上能满足城市规划、耕地保护、灾害监测等实际应用需求.部分国内外遥感大模型平台见表1. ...
... 对于遥感大模型的研究进展及面临的挑战,武汉大学张良培教授团队以遥感大模型的预训练技术为主线,归纳分析了有监督单模态、无监督单模态、视觉-文本联合多模态预训练遥感大模型的研究进展,探讨了结合遥感领域知识与物理约束、提高数据泛化性、扩展应用场景、降低数据成本4个方面的展望[12].本文从数据、模型、下游任务3个方面阐述其研究进展,探讨多模态、可解释、人类反馈强化学习3个重要研究方向,并开展自监督单模态遥感大模型初步试验,旨在推动遥感大模型的研究应用实践,赋能遥感智能化发展. ...
遥感大模型:进展与前瞻
2
2023
... 遥感大模型是利用卷积神经网络、循环神经网络、自注意力机制、Transformer等先进的深度学习结构,通过对大规模遥感数据进行训练,实现对地物分类、目标检测、语义分割、变化检测等任务的高效处理[12-13].国内外遥感领域的商业公司、高校及科研院所陆续推出遥感大模型平台,在一定程度上能满足城市规划、耕地保护、灾害监测等实际应用需求.部分国内外遥感大模型平台见表1. ...
... 对于遥感大模型的研究进展及面临的挑战,武汉大学张良培教授团队以遥感大模型的预训练技术为主线,归纳分析了有监督单模态、无监督单模态、视觉-文本联合多模态预训练遥感大模型的研究进展,探讨了结合遥感领域知识与物理约束、提高数据泛化性、扩展应用场景、降低数据成本4个方面的展望[12].本文从数据、模型、下游任务3个方面阐述其研究进展,探讨多模态、可解释、人类反馈强化学习3个重要研究方向,并开展自监督单模态遥感大模型初步试验,旨在推动遥感大模型的研究应用实践,赋能遥感智能化发展. ...
Vision-language models in remote sensing: current progress and future trends
1
... 遥感大模型是利用卷积神经网络、循环神经网络、自注意力机制、Transformer等先进的深度学习结构,通过对大规模遥感数据进行训练,实现对地物分类、目标检测、语义分割、变化检测等任务的高效处理[12-13].国内外遥感领域的商业公司、高校及科研院所陆续推出遥感大模型平台,在一定程度上能满足城市规划、耕地保护、灾害监测等实际应用需求.部分国内外遥感大模型平台见表1. ...
Generative pretraining from pixels
1
2020
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
BERT: pre-training of deep bidirectional transformers for language understanding
1
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
Segment anything
1
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
地理人工智能样本:模型、质量与服务
1
2023
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
地理人工智能样本:模型、质量与服务
1
2023
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
遥感基础模型发展综述与未来设想
1
2023
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
遥感基础模型发展综述与未来设想
1
2023
... 由于观测场景、地物类型、成像条件、遥感器设计与地面相机的差异,遥感影像呈现出多传感器、多时相、多分辨率、多要素等特点,使遥感大模型构建存在如下挑战.①高质量样本体量很小.如在遥感监测业务中,国土三调积累了2.7亿个地类图斑,常态化监测积累了4000万个变化图斑,但这些业务中积累的样本量远小于计算机视觉领域的数十亿图像数据集,亟须盘活现有的各类数据资源,构建亿级高质量样本.②语言、视觉大模型在遥感领域应用研究比较缺乏.如常用的Image GPT[14]、BERT[15]、SAM[16]等大模型,主要应用于自然语言处理和自然图像处理领域,亟须借鉴视觉、语言大模型的思路发展遥感大模型.③模型迭代优化技术亟待突破.由于从零开始训练数十亿参数的大模型需要大量算力,难以满足日益细分的业务需求,需要利用微调及人类反馈强化学习等技术增强大模型的学习能力.④多源数据融合不足,需将不同分辨率、不同传感器和不同时间点的遥感数据与传感视频、文本等异构数据整合,利用多源信息提升遥感大模型的性能.⑤物理、地理、物候、专家等知识未有效利用,可解释性不强,需要更多地利用多源知识进行引导,提升模型的可信度、可解释性、场景适应性,以提高模型的决策认知能力[17-18]. ...
On creating benchmark dataset for aerial image interpretation: reviews, guidances, and million-AID
1
2021
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
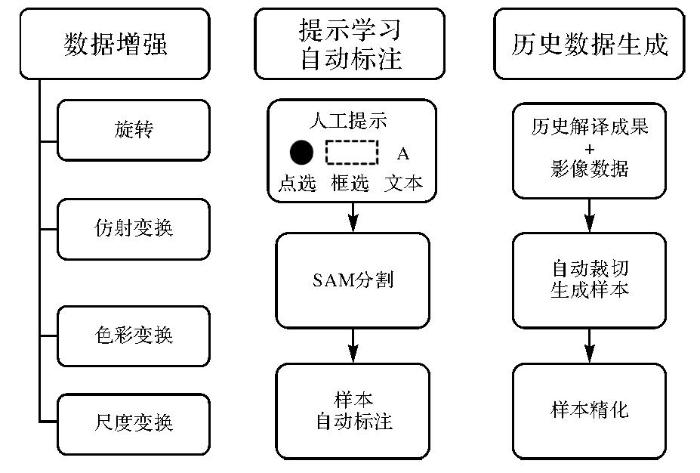
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
SatlasPretrain: a large-scale dataset for remote sensing image understanding
1
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
RSGPT: a remote sensing vision language model and benchmark
1
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
GeoChat: grounded large vision-language model for remote sensing
1
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
SpaceNet: a remote sensing dataset and challenge series
1
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
SkyScript: a large and semantically diverse vision-language dataset for remote sensing
2
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
... 在目前典型遥感大模型[40-53](表3)中,紫东太初为全球首个千亿参数多模态大模型,突破跨模态多任务自监督学习技术,实现多模态数据的统一表示与相互生成,形成了完整的智能表示、推理和生成能力.RemoteCLIP[40]是第一个用于遥感的视觉语言基础模型,旨在学习具有丰富语义视觉特征以及对齐的文本嵌入,以实现无缝的下游应用.SkySense是一个通用的十亿级遥感基础模型,在2150万个时间序列的多模态遥感图像数据集上进行预训练,在涵盖7个遥感任务的16个数据集上展示了卓越的泛化能力,性能大幅领先于其他模型.SkyScript[24]是大规模遥感视觉语言数据集,包括260万个遥感图像-文本对,覆盖2.9万个不同的语义标签,可以助力VLM在遥感中的各种多模态任务发展. ...
Functional map of the world
1
2018
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
SkySense: a multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery
1
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
BigEarthNet-MM: a large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval
1
2021
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
SEN12MS—a curated dataset of georeferenced multi-spectral Sentinel-1/2 imagery for deep learning and data fusion
1
2019
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
RingMo: a remote sensing foundation model with masked image modeling
1
2023
... Multimodal dataset
Tab.2| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|
| MillionAID[19] | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[20] | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[21] | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[22] | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[23] | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[24] | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[25] | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[26] | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[27] | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[28] | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[29] | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
Samgeo: a Python package for segmenting geospatial datawith the segment anything model (SAM)
1
2023
... 遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
SAMRS: scaling-up remote sensing segmentation dataset with segment anything model
1
... 遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
RSPrompter: learning to prompt for remote sensing instance segmentation based on visual foundation model
1
... 遥感业务需要大量的遥感影像数据支持,训练一个对目标任务有良好表达的模型所需的数据量随着业务需求的提升逐渐增加,而传统人工标注耗时长、成本高、效率低,难以满足训练多模态大模型的数据需求,必然需要数据扩充.数据快速扩充方式(图2)有:①数据增强.通过对原始数据集进行旋转变换、仿射变换、色彩变换、尺度变换等方法进行数据扩充;②提示学习自动标注.利用SAM、segment-anything-eo[30]、SAMRS[31]、RSPrompter[32]等进行实例分割、语义分割、目标检测等,生成高质量的数据集;③历史解译成果自动生成样本.利用开源地理数据、业务生产解译成果数据及相应遥感影像,自动生成高质量的样本数据. ...
Masked autoencoders are scalable vision learners
1
... 自监督学习是通过特定的代理任务生成伪标签来从未标记的数据中获取有用的表示信息.主流方法分为预测、对比学习两大类.预测的自监督学习主要是通过预测重建数据从而使模型学习到数据中的深层特征,BERT通过“完形填空”的方式训练大型语言模型;GPT通过预测给定的一系列字符后续可能出现的字符,来学习字符之间的语义关联信息;MAE[33]通过预测重建随机掩码后的图片块抽取特征训练视觉模型.对比的自监督学习方法是通过对比学习不同数据视角之间的一致性或差异性,进而学习到数据中的特征表达,BYOL[34]首次舍弃了负样本,在主流对比学习框架中加入了预测层训练模型;Moco V3[35]使用动量编码器训练ViT(vision transformer)模型,在ImageNet上达到了81.0%的Top-1准确率;DINO[36]加入中心聚集层增加模型稳定性,从网络中“蒸馏”知识以训练视觉模型. ...
Bootstrap your own latent: a new approach to self-supervised Learning
1
... 自监督学习是通过特定的代理任务生成伪标签来从未标记的数据中获取有用的表示信息.主流方法分为预测、对比学习两大类.预测的自监督学习主要是通过预测重建数据从而使模型学习到数据中的深层特征,BERT通过“完形填空”的方式训练大型语言模型;GPT通过预测给定的一系列字符后续可能出现的字符,来学习字符之间的语义关联信息;MAE[33]通过预测重建随机掩码后的图片块抽取特征训练视觉模型.对比的自监督学习方法是通过对比学习不同数据视角之间的一致性或差异性,进而学习到数据中的特征表达,BYOL[34]首次舍弃了负样本,在主流对比学习框架中加入了预测层训练模型;Moco V3[35]使用动量编码器训练ViT(vision transformer)模型,在ImageNet上达到了81.0%的Top-1准确率;DINO[36]加入中心聚集层增加模型稳定性,从网络中“蒸馏”知识以训练视觉模型. ...
An empirical study of training self-supervised vision transformers
1
... 自监督学习是通过特定的代理任务生成伪标签来从未标记的数据中获取有用的表示信息.主流方法分为预测、对比学习两大类.预测的自监督学习主要是通过预测重建数据从而使模型学习到数据中的深层特征,BERT通过“完形填空”的方式训练大型语言模型;GPT通过预测给定的一系列字符后续可能出现的字符,来学习字符之间的语义关联信息;MAE[33]通过预测重建随机掩码后的图片块抽取特征训练视觉模型.对比的自监督学习方法是通过对比学习不同数据视角之间的一致性或差异性,进而学习到数据中的特征表达,BYOL[34]首次舍弃了负样本,在主流对比学习框架中加入了预测层训练模型;Moco V3[35]使用动量编码器训练ViT(vision transformer)模型,在ImageNet上达到了81.0%的Top-1准确率;DINO[36]加入中心聚集层增加模型稳定性,从网络中“蒸馏”知识以训练视觉模型. ...
Emerging properties in self-supervised vision transformers
1
... 自监督学习是通过特定的代理任务生成伪标签来从未标记的数据中获取有用的表示信息.主流方法分为预测、对比学习两大类.预测的自监督学习主要是通过预测重建数据从而使模型学习到数据中的深层特征,BERT通过“完形填空”的方式训练大型语言模型;GPT通过预测给定的一系列字符后续可能出现的字符,来学习字符之间的语义关联信息;MAE[33]通过预测重建随机掩码后的图片块抽取特征训练视觉模型.对比的自监督学习方法是通过对比学习不同数据视角之间的一致性或差异性,进而学习到数据中的特征表达,BYOL[34]首次舍弃了负样本,在主流对比学习框架中加入了预测层训练模型;Moco V3[35]使用动量编码器训练ViT(vision transformer)模型,在ImageNet上达到了81.0%的Top-1准确率;DINO[36]加入中心聚集层增加模型稳定性,从网络中“蒸馏”知识以训练视觉模型. ...
周成虎院士:从遥感大数据到遥感大模型
1
2023
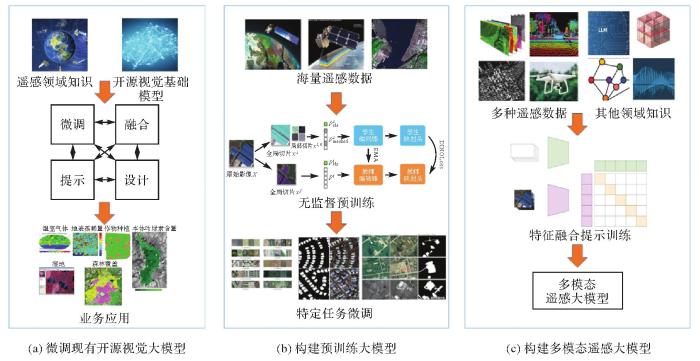
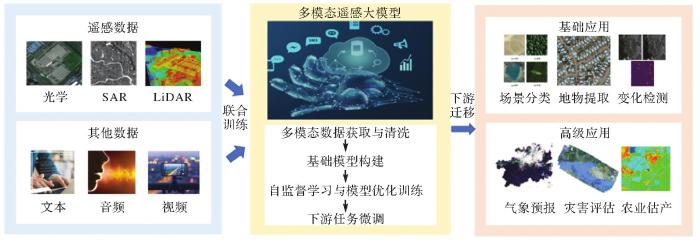
... 遥感领域主要利用3种方式构建遥感大模型(图3):①微调现有开源视觉大模型.通过微调、提示学习、特征融合等方法,将已有大模型迁移到遥感领域.②构建预训练大模型.使用无标签海量遥感数据,构建大型无标签数据集,利用自监督学习方法构建遥感大模型,通过微调技术使其适配多种业务场景.③构建多模态遥感大模型.将多源遥感数据与有关文本、声音、视频、矢量等数据进行融合,充分利用多种数据知识,使模型真正理解遥感[37-39]. ...
周成虎院士:从遥感大数据到遥感大模型
1
2023
... 遥感领域主要利用3种方式构建遥感大模型(图3):①微调现有开源视觉大模型.通过微调、提示学习、特征融合等方法,将已有大模型迁移到遥感领域.②构建预训练大模型.使用无标签海量遥感数据,构建大型无标签数据集,利用自监督学习方法构建遥感大模型,通过微调技术使其适配多种业务场景.③构建多模态遥感大模型.将多源遥感数据与有关文本、声音、视频、矢量等数据进行融合,充分利用多种数据知识,使模型真正理解遥感[37-39]. ...
从大模型看测绘时空信息智能处理的机遇和挑战
0
2023
从大模型看测绘时空信息智能处理的机遇和挑战
0
2023
人工智能大模型综述及展望
1
2023
... 遥感领域主要利用3种方式构建遥感大模型(图3):①微调现有开源视觉大模型.通过微调、提示学习、特征融合等方法,将已有大模型迁移到遥感领域.②构建预训练大模型.使用无标签海量遥感数据,构建大型无标签数据集,利用自监督学习方法构建遥感大模型,通过微调技术使其适配多种业务场景.③构建多模态遥感大模型.将多源遥感数据与有关文本、声音、视频、矢量等数据进行融合,充分利用多种数据知识,使模型真正理解遥感[37-39]. ...
人工智能大模型综述及展望
1
2023
... 遥感领域主要利用3种方式构建遥感大模型(图3):①微调现有开源视觉大模型.通过微调、提示学习、特征融合等方法,将已有大模型迁移到遥感领域.②构建预训练大模型.使用无标签海量遥感数据,构建大型无标签数据集,利用自监督学习方法构建遥感大模型,通过微调技术使其适配多种业务场景.③构建多模态遥感大模型.将多源遥感数据与有关文本、声音、视频、矢量等数据进行融合,充分利用多种数据知识,使模型真正理解遥感[37-39]. ...
RemoteCLIP: a vision language foundation model for remote sensing
3
... 在目前典型遥感大模型[40-53](表3)中,紫东太初为全球首个千亿参数多模态大模型,突破跨模态多任务自监督学习技术,实现多模态数据的统一表示与相互生成,形成了完整的智能表示、推理和生成能力.RemoteCLIP[40]是第一个用于遥感的视觉语言基础模型,旨在学习具有丰富语义视觉特征以及对齐的文本嵌入,以实现无缝的下游应用.SkySense是一个通用的十亿级遥感基础模型,在2150万个时间序列的多模态遥感图像数据集上进行预训练,在涵盖7个遥感任务的16个数据集上展示了卓越的泛化能力,性能大幅领先于其他模型.SkyScript[24]是大规模遥感视觉语言数据集,包括260万个遥感图像-文本对,覆盖2.9万个不同的语义标签,可以助力VLM在遥感中的各种多模态任务发展. ...
... [40]是第一个用于遥感的视觉语言基础模型,旨在学习具有丰富语义视觉特征以及对齐的文本嵌入,以实现无缝的下游应用.SkySense是一个通用的十亿级遥感基础模型,在2150万个时间序列的多模态遥感图像数据集上进行预训练,在涵盖7个遥感任务的16个数据集上展示了卓越的泛化能力,性能大幅领先于其他模型.SkyScript[24]是大规模遥感视觉语言数据集,包括260万个遥感图像-文本对,覆盖2.9万个不同的语义标签,可以助力VLM在遥感中的各种多模态任务发展. ...
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
Self-supervised learning for invariant representations from multi-spectral and SAR images
1
2022
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
Semantic connectivity-driven pseudo-labeling for cross-domain segmentation
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
SatMAE: pre-training transformers for temporal and multi-spectral satellite imagery
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
Advancing plain vision transformer toward remote sensing foundation model
1
2023
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
An empirical study of remote sensing pretraining
1
2023
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
Scale-MAE: a scale-aware masked autoencoder for multiscale geospatial representation learning
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
DINO-MC: self-supervised contrastive learning for remote sensing imagery with multi-sized local crops
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
DiffusionSat: a generative foundation model for satellite imagery
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
MCRN: a multi-source cross-modal retrieval network for remote sensing
1
2022
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
CSP: self-supervised contrastive spatial pre-training for geospatial-visual representations
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
GeoCLIP: clip-inspired alignment between locations and images for effective worldwide geo-localization
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
SatCLIP: global, general-purpose location embeddings with satellite imagery
1
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
Self-supervised audiovisual representation learning for remote sensing data
2
... 在目前典型遥感大模型[40-53](表3)中,紫东太初为全球首个千亿参数多模态大模型,突破跨模态多任务自监督学习技术,实现多模态数据的统一表示与相互生成,形成了完整的智能表示、推理和生成能力.RemoteCLIP[40]是第一个用于遥感的视觉语言基础模型,旨在学习具有丰富语义视觉特征以及对齐的文本嵌入,以实现无缝的下游应用.SkySense是一个通用的十亿级遥感基础模型,在2150万个时间序列的多模态遥感图像数据集上进行预训练,在涵盖7个遥感任务的16个数据集上展示了卓越的泛化能力,性能大幅领先于其他模型.SkyScript[24]是大规模遥感视觉语言数据集,包括260万个遥感图像-文本对,覆盖2.9万个不同的语义标签,可以助力VLM在遥感中的各种多模态任务发展. ...
... Typical remote sensing large models
Tab.3| 遥感大模型 | 代表模型 | 特点 |
|---|
| 遥感视觉大模型 | RS-BYOL[41]、SeCo[42]、SatMAE[43]、RingMo、RVSA[44]、RSP[45]、Scale-MAE[46]、SpectralGPT[11]、DINO-MC[47]等 | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 |
| 遥感生成大模型 | DiffusionSat[48]等 | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[49]、RemoteCLIP[40]、GeoChat等 | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[50]、GeoCLIP[51]、SatCLIP[52]等 | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 |
| 视觉+音频 | SoundingEarth[53]等 | 同时利用视觉和听觉理解应用场景 |
1.3 下游任务:从单任务向多任务发展多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
Learning transferable visual models from natural language supervision
2
... 多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
ViLT: vision-and-language transformer without convolution or region supervision
0
VLMo: unified vision-language pre-training with mixture-of-modality-experts
1
... 多模态大模型的最终目标是适配并提升特定下游任务上的性能表现,通过提示学习、特征微调等方式将大模型的能力迁移到多任务场景中,适配下游任务的模型微调方式如下:①提示学习微调.利用提示学习让上游的预训练模型在尽量不需要标注数据的情况下适配下游任务,从而节省训练时间和计算资源.②设置适配层.通过微调更新适配层的网络参数实现不同任务之间的参数共享.③特定任务微调.将多模态大模型的权重作为初始参数,在任务特定数据上进行有监督的微调以适应特定任务需求[54-56]. ...
VL-BERT: pre-training of generic visual-linguistic representations
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
UNITER: universal image-text representation learning
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
Scaling up visual and vision-language representation learning with noisy text supervision
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
VATT: transformers for multimodal self-supervised learning from raw video, audio and text
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
Hierarchical text-conditional image generation with CLIP latents
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
CogView: mastering text-to-image generation via transformers
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
Denoising diffusion probabilistic models
1
2020
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
High-resolution image synthesis with latent diffusion models
1
... 目前,多模态遥感大模型(图5)正向面向理解任务和生成任务发展.面向理解任务的多模态大模型可再分为单流和多流两种结构.单流结构是指不同模态的特征在拼接后由一个共享的Transformer网络进行处理,如VL-BERT[57]、UNITER[58];在多流结构中,不同模态则分别由Transformer网络进行编码处理,这些网络之间存在一些特征上的交互融合机制,如ViLBERT[59]、CLIP[54]、ALIGN[60]、VATT[61].面向生成任务的多模态大模型能够实现文本、图片、视频、音频等多种模态内容的生成应用,目前主要有序列生成模型(DALL-E2[62]、CogView[63])和扩散模型(DDPM[64]、Stable Diffusion[65])等. ...
Large-scale multi-modal pre-trained models: a comprehensive survey
1
2023
... 多模态大模型需要解决的科学问题包括多模态数据对齐、多模态关联建模、跨模态预训练模型特征耦合和解耦等.需要突破的核心技术包括多模态数据语义统一表示、多模态特征融合、联合学习训练、多任务跨模态自监督学习、模态理解与模态生成统一建模、模型参数迁移等[66-70]. ...
遥感跨模态智能解译:模型、数据与应用
0
2023
遥感跨模态智能解译:模型、数据与应用
0
2023
MiniGPT-4: enhancing vision-language understanding with advanced large language models
0
mPLUG-Owl: modularization empowers large language models with multimodality
0
PaLM-E: an embodied multimodal language model
1
... 多模态大模型需要解决的科学问题包括多模态数据对齐、多模态关联建模、跨模态预训练模型特征耦合和解耦等.需要突破的核心技术包括多模态数据语义统一表示、多模态特征融合、联合学习训练、多任务跨模态自监督学习、模态理解与模态生成统一建模、模型参数迁移等[66-70]. ...
Learning deep features for discriminative localization
1
2016
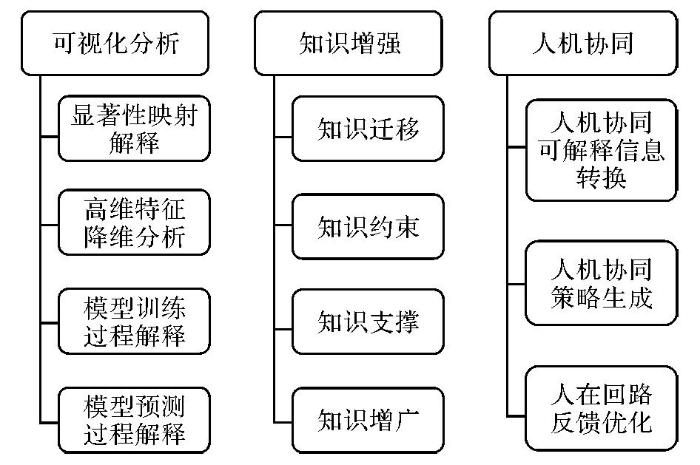
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
Learning important features through propagating activation differences
1
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
Knowledge graph embeddings for dealing with concept drift in machine learning
1
2021
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
人机协同的自然资源要素智能提取方法
1
2021
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
人机协同的自然资源要素智能提取方法
1
2021
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
高分辨率遥感影像智能解译研究进展与趋势
0
2021
高分辨率遥感影像智能解译研究进展与趋势
0
2021
自然资源要素智能解译研究进展与方向
1
2022
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
自然资源要素智能解译研究进展与方向
1
2022
... 可解释遥感大模型构建一般通过3种方式(图6):①可视化解释分析.利用显著性映射解释[71-72]、高维特征降维分析等可解释技术,对大模型网络内部结构、运行过程、决策过程进行渐进式可视化解释分析.②知识增强.利用知识增广、知识支撑、知识约束、知识迁移等方式,增强模型与知识的一致性,提升遥感大模型的可解释性[73].③人机协同.强化人类智能与机器智能的交互协作,实现对复杂问题的人机协同求解,形成人机协同混合智能增强形态及场景应用解决方案,提升遥感大模型的问题解决能力[74-76]. ...
测绘地理信息与人工智能2.0融合发展的方向
1
2021
... 现有数据驱动的遥感大模型难以融合领域知识,推理与自学习不足,可解释性不强,缺乏对遥感数据的深层理解与逻辑推理能力,可解释遥感大模型可提高预测结果的信任度,减少偏差,促进模型调优.需要解决知识表示学习、数据-模型-知识耦合机制、人机协同策略、可解释信息转化等科学问题.需要突破大规模隐式表达的知识获取、多源异构知识融合、知识融入的预训练模型构建、知识数据双驱动的决策推理、人在回路反馈优化等[77-78]等核心技术. ...
测绘地理信息与人工智能2.0融合发展的方向
1
2021
... 现有数据驱动的遥感大模型难以融合领域知识,推理与自学习不足,可解释性不强,缺乏对遥感数据的深层理解与逻辑推理能力,可解释遥感大模型可提高预测结果的信任度,减少偏差,促进模型调优.需要解决知识表示学习、数据-模型-知识耦合机制、人机协同策略、可解释信息转化等科学问题.需要突破大规模隐式表达的知识获取、多源异构知识融合、知识融入的预训练模型构建、知识数据双驱动的决策推理、人在回路反馈优化等[77-78]等核心技术. ...
虚实系统互驱的混合增强智能开放创新平台的架构与方案
1
2019
... 现有数据驱动的遥感大模型难以融合领域知识,推理与自学习不足,可解释性不强,缺乏对遥感数据的深层理解与逻辑推理能力,可解释遥感大模型可提高预测结果的信任度,减少偏差,促进模型调优.需要解决知识表示学习、数据-模型-知识耦合机制、人机协同策略、可解释信息转化等科学问题.需要突破大规模隐式表达的知识获取、多源异构知识融合、知识融入的预训练模型构建、知识数据双驱动的决策推理、人在回路反馈优化等[77-78]等核心技术. ...
虚实系统互驱的混合增强智能开放创新平台的架构与方案
1
2019
... 现有数据驱动的遥感大模型难以融合领域知识,推理与自学习不足,可解释性不强,缺乏对遥感数据的深层理解与逻辑推理能力,可解释遥感大模型可提高预测结果的信任度,减少偏差,促进模型调优.需要解决知识表示学习、数据-模型-知识耦合机制、人机协同策略、可解释信息转化等科学问题.需要突破大规模隐式表达的知识获取、多源异构知识融合、知识融入的预训练模型构建、知识数据双驱动的决策推理、人在回路反馈优化等[77-78]等核心技术. ...
Reinforcement learning with human feedback: learning dynamic choices via pessimism
1
... 针对遥感大模型调整优化困难的问题,人类反馈强化学习是一种有效方法,它是一种结合计算机视觉的学习范式,旨在通过人类的反馈来进行强化学习优化模型,此方法将人类专家的知识引入大模型的学习过程中,人类专家可以对模型进行评估与指导,指出预测行为的优劣,并给予相应的奖励或惩罚.该方法可以帮助模型快速收敛到较好的策略,减少试错过程和学习时间,使得模型能够更好地遵循用户意图,生成符合用户偏好的内容,进而能够更有效地完成特定任务[79-84]. ...
A survey of preference-based reinforcement learning methods
0
2017
ChatGPT: optimizing language models for dialogue
0
Aligning text-to-image models using human feedback
0
Rewards encoding environment dynamics improves preference-based reinforcement learning
0
Eluder dimension and the sample complexity of optimistic exploration
1
2013
... 针对遥感大模型调整优化困难的问题,人类反馈强化学习是一种有效方法,它是一种结合计算机视觉的学习范式,旨在通过人类的反馈来进行强化学习优化模型,此方法将人类专家的知识引入大模型的学习过程中,人类专家可以对模型进行评估与指导,指出预测行为的优劣,并给予相应的奖励或惩罚.该方法可以帮助模型快速收敛到较好的策略,减少试错过程和学习时间,使得模型能够更好地遵循用户意图,生成符合用户偏好的内容,进而能够更有效地完成特定任务[79-84]. ...
Deep reinforcement learning from human preferences
1
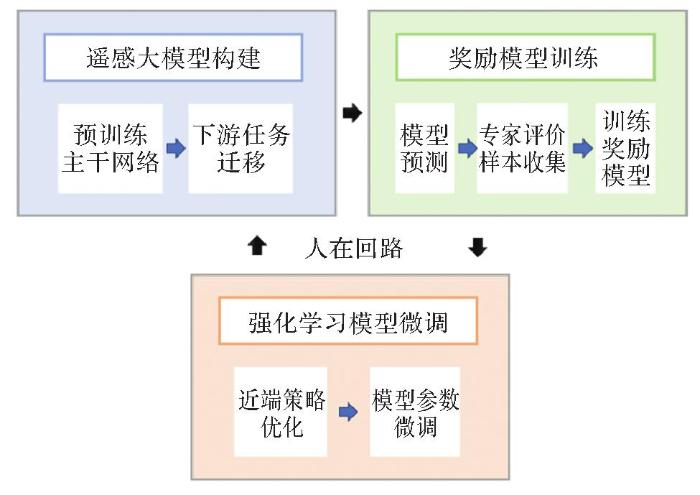
... 人类反馈强化学习需要解决的科学问题包括模型与人类意图对齐、试错与开发权衡机制、学习奖励函数优化、增强学习优化决策等,需要突破的核心技术包括奖励模型训练、奖励模型精调、强化学习指令微调、人在回路反馈优化等[85-89].基本思路是:首先,利用大规模数据训练遥感预训练大模型,并迁移至实际应用中的场景分类、地物提取、变化检测等下游任务;然后,在多次应用过程中收集人类专家的偏好标注数据,如专家对遥感影像的地物提取效果的评分,数据收集完成之后,利用这些偏好数据训练奖励模型,确保模型可以准确学习到人类专家的评价和奖励行为;最后,运用强化学习中的近端策略优化方法微调初始的遥感大模型,使遥感大模型与人类的价值观相对齐,整个流程构成人在回路式的模型训练优化过程,有利于遥感大模型充分运用人类专家知识,达到持续学习、持续优化的效果(图7). ...
Reward learning from human preferences and demonstrations in Atari
0
Scalable agent alignment via reward modeling: a research direction
0
Training language models to follow instructions with human feedback
0
ChatGPT给语言大模型带来的启示和多模态大模型新的发展思路
1
2023
... 人类反馈强化学习需要解决的科学问题包括模型与人类意图对齐、试错与开发权衡机制、学习奖励函数优化、增强学习优化决策等,需要突破的核心技术包括奖励模型训练、奖励模型精调、强化学习指令微调、人在回路反馈优化等[85-89].基本思路是:首先,利用大规模数据训练遥感预训练大模型,并迁移至实际应用中的场景分类、地物提取、变化检测等下游任务;然后,在多次应用过程中收集人类专家的偏好标注数据,如专家对遥感影像的地物提取效果的评分,数据收集完成之后,利用这些偏好数据训练奖励模型,确保模型可以准确学习到人类专家的评价和奖励行为;最后,运用强化学习中的近端策略优化方法微调初始的遥感大模型,使遥感大模型与人类的价值观相对齐,整个流程构成人在回路式的模型训练优化过程,有利于遥感大模型充分运用人类专家知识,达到持续学习、持续优化的效果(图7). ...
ChatGPT给语言大模型带来的启示和多模态大模型新的发展思路
1
2023
... 人类反馈强化学习需要解决的科学问题包括模型与人类意图对齐、试错与开发权衡机制、学习奖励函数优化、增强学习优化决策等,需要突破的核心技术包括奖励模型训练、奖励模型精调、强化学习指令微调、人在回路反馈优化等[85-89].基本思路是:首先,利用大规模数据训练遥感预训练大模型,并迁移至实际应用中的场景分类、地物提取、变化检测等下游任务;然后,在多次应用过程中收集人类专家的偏好标注数据,如专家对遥感影像的地物提取效果的评分,数据收集完成之后,利用这些偏好数据训练奖励模型,确保模型可以准确学习到人类专家的评价和奖励行为;最后,运用强化学习中的近端策略优化方法微调初始的遥感大模型,使遥感大模型与人类的价值观相对齐,整个流程构成人在回路式的模型训练优化过程,有利于遥感大模型充分运用人类专家知识,达到持续学习、持续优化的效果(图7). ...
DINOv2: learning robust visual features without supervision
1
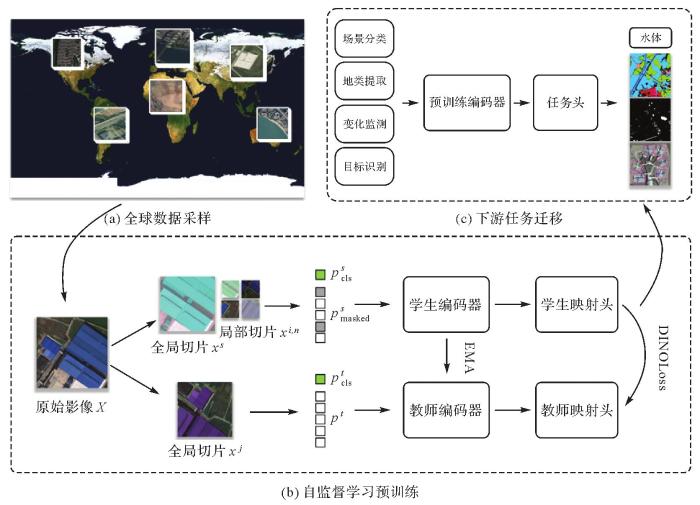
... 以DINO V2[90]自监督学习网络为基础,该网络使用了教师-学生知识蒸馏框架[91],利用对比学习方法实现遥感图像中的特征表达.将ViT-Huge作为骨干模型和编码器对输入学生模型和教师模型的特征进行编码,设置batch size为10,使用BFloat16数据类型加速.学习率最大值设置为5×10-4,在初始的10个epoch会从0预热到最大值,使用Cosine Scheduler逐渐递减到1×10-6,使用Fused-AdamW优化器在Nvidia A100 GPU上预训练共200个epoch,自监督模型构建流程如图9所示. ...
Knowledge distillation: a survey
1
2021
... 以DINO V2[90]自监督学习网络为基础,该网络使用了教师-学生知识蒸馏框架[91],利用对比学习方法实现遥感图像中的特征表达.将ViT-Huge作为骨干模型和编码器对输入学生模型和教师模型的特征进行编码,设置batch size为10,使用BFloat16数据类型加速.学习率最大值设置为5×10-4,在初始的10个epoch会从0预热到最大值,使用Cosine Scheduler逐渐递减到1×10-6,使用Fused-AdamW优化器在Nvidia A100 GPU上预训练共200个epoch,自监督模型构建流程如图9所示. ...
地理空间视角下自然资源认知探讨
1
2022
... 以遥感智能认知为方向,以应用任务为导向,将遥感大模型的理论方法、工程技术、应用迭代进行结合[92],构建大规模高质量的预训练数据,设计高效计算的大模型网络结构,突破模型压缩与推理加速、下游任务高效适配等技术,实现遥感大模型的低成本训练、高效快速推理、轻量化部署及工程化应用,是未来的发展目标. ...
地理空间视角下自然资源认知探讨
1
2022
... 以遥感智能认知为方向,以应用任务为导向,将遥感大模型的理论方法、工程技术、应用迭代进行结合[92],构建大规模高质量的预训练数据,设计高效计算的大模型网络结构,突破模型压缩与推理加速、下游任务高效适配等技术,实现遥感大模型的低成本训练、高效快速推理、轻量化部署及工程化应用,是未来的发展目标. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}