


测绘学报 ›› 2025, Vol. 54 ›› Issue (5): 853-872.doi: 10.11947/j.AGCS.2025.20240244
李海峰1( ), 郭旺1, 吴梦伟1, 彭程里1, 朱庆2, 刘瑜3, 陶超1()
), 郭旺1, 吴梦伟1, 彭程里1, 朱庆2, 刘瑜3, 陶超1()
收稿日期:2024-06-18
修回日期:2025-03-27
出版日期:2025-06-23
发布日期:2025-06-23
通讯作者:
陶超
E-mail:lihaifeng@csu.edu.cn;kingtaochao@csu.edu.cn
作者简介:李海峰(1980—),男,博士,教授,研究方向为多模态时空通用大模型、多模态时空信息记忆模型。E-mail:lihaifeng@csu.edu.cn
基金资助:
Haifeng LI1(), Wang GUO1, Mengwei WU1, Chengli PENG1, Qing ZHU2, Yu LIU3, Chao TAO1()
Received:2024-06-18
Revised:2025-03-27
Online:2025-06-23
Published:2025-06-23
Contact:
Chao TAO
E-mail:lihaifeng@csu.edu.cn;kingtaochao@csu.edu.cn
About author:LI Haifeng (1980—), male, PhD, professor, majors in general-purpose multimodal spatio-temporal foundation models and multimodal spatio-temporal memory models. E-mail: lihaifeng@csu.edu.cn
Supported by:摘要:
当前遥感智能解译主要依赖视觉模型在遥感影像与语义标签之间建立映射关系,但受限于有限类别的语义标注,模型难以学习地物及其关系的深层语义,进而无法涌现对世界知识的理解能力。随着大语言模型的兴起,依托其对语言中蕴含的人类知识的强大编码能力,有望突破遥感视觉模型知识获取的局限。通过大语言模型引导视觉模型,可显著拓展其知识学习范围,推动遥感智能解译从语义匹配向世界知识理解跃迁。本文认为,视觉-语言联合的多模态遥感解译模型将引发新一轮范式变革。在此基础上,本文进一步围绕遥感地物概念表达展开系统分析。通过深入分析遥感地物的概念内涵与外延,揭示了单纯依赖视觉模态在表达复杂遥感地物特征方面的不足,剖析了联合视觉-语言两种模态数据进行遥感地物概念表达的价值和意义。在此基础上,详细分析了遥感地物概念表达范式背后所面临的模态对齐问题及其代表性解决方法,探讨了该范式如何催化遥感解译模型新能力的涌现,并对该能力的产生原因和实际应用价值进行分析。最后,本文总结并讨论了在这种遥感地物概念表达框架下遥感影像智能解译领域所面临的机遇与挑战。
中图分类号:
李海峰, 郭旺, 吴梦伟, 彭程里, 朱庆, 刘瑜, 陶超. 视觉-语言联合的遥感地物概念表达与智能解译:原理、挑战与机遇[J]. 测绘学报, 2025, 54(5): 853-872.
Haifeng LI, Wang GUO, Mengwei WU, Chengli PENG, Qing ZHU, Yu LIU, Chao TAO. Visual-language joint representation and intelligent interpretation of remote sensing geo-objects: principles, challenges and opportunities[J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 853-872.
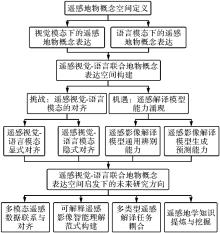
图1
本文的整体组织结构"
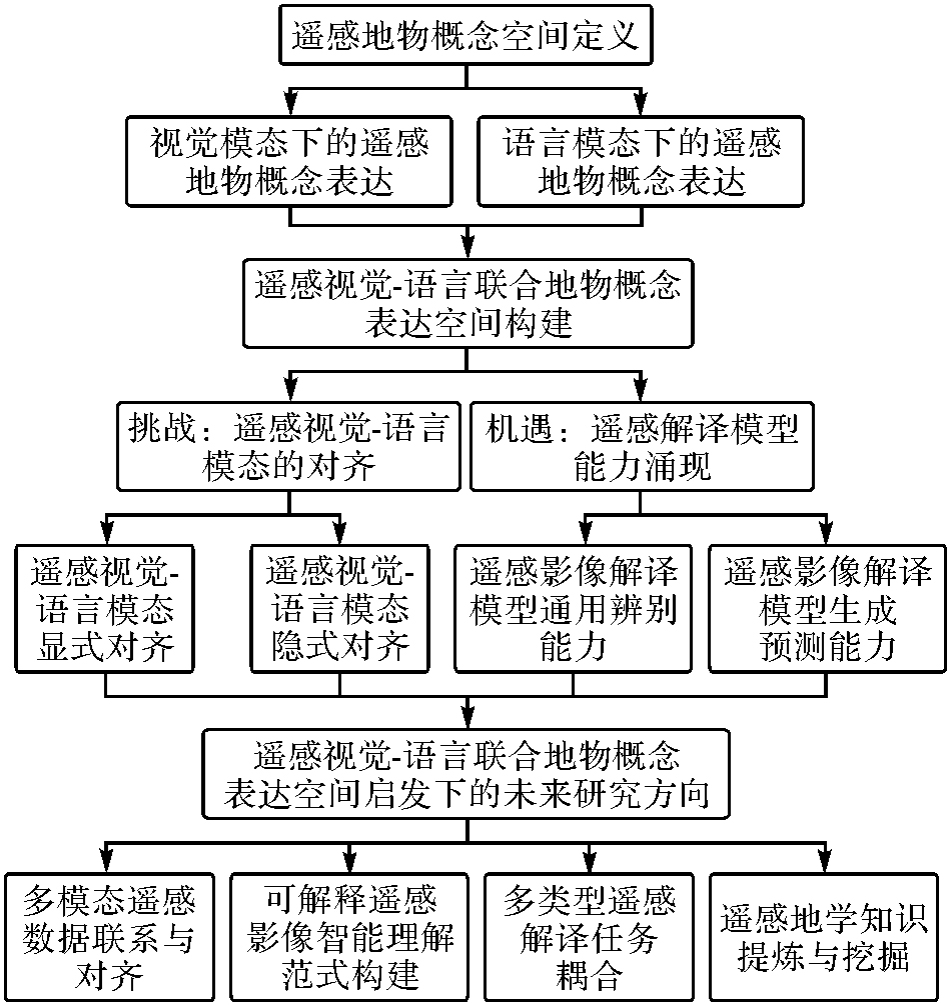
图2
遥感地物概念空间组成及相互关系"
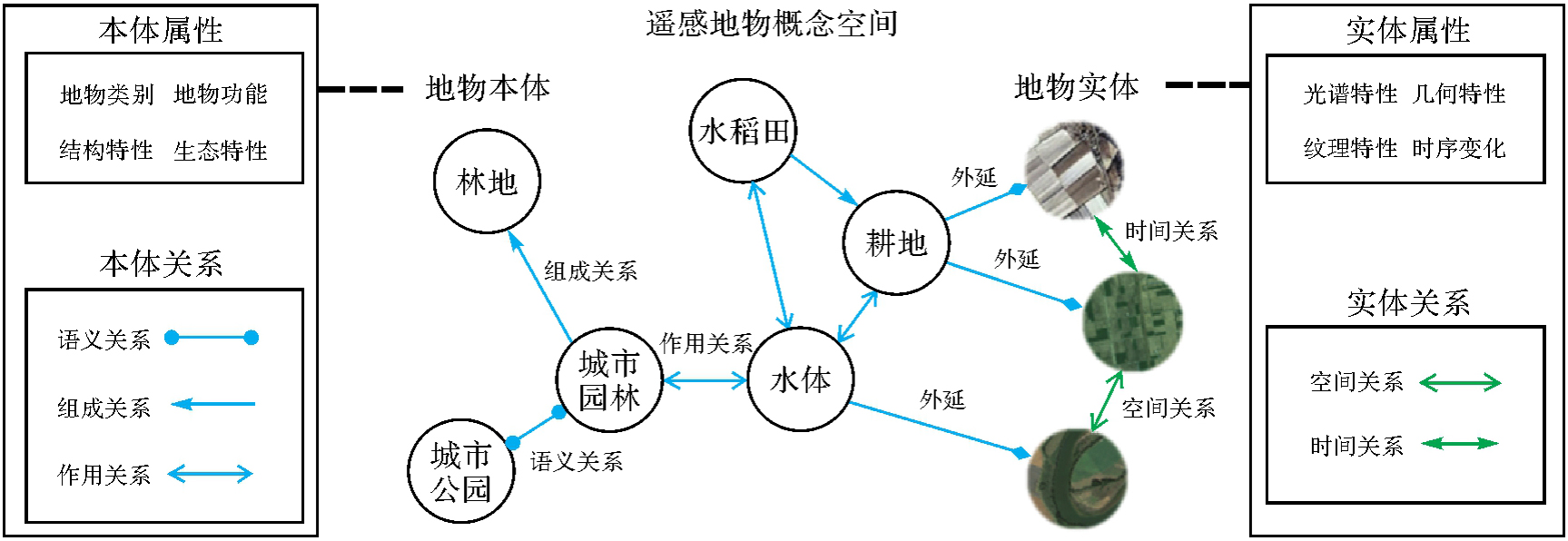
表1
视觉模态与语言模态对地物实体及地物本体表达"
| 地物概念 | 关系属性 | 视觉模态 | 语言模态 | ||
|---|---|---|---|---|---|
| 感知性 | 解析性 | 描述性 | 逻辑性 | ||
| 地物 | 实体属性 | √ | √ | × | × |
| 实体 | 实体关系 | √ | √ | × | × |
| 地物 | 本体属性 | × | √ | √ | √ |
| 本体 | 本体关系 | × | × | × | √ |
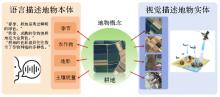
图3
视觉-语言联合地物概念表达空间下的地物概念描述"
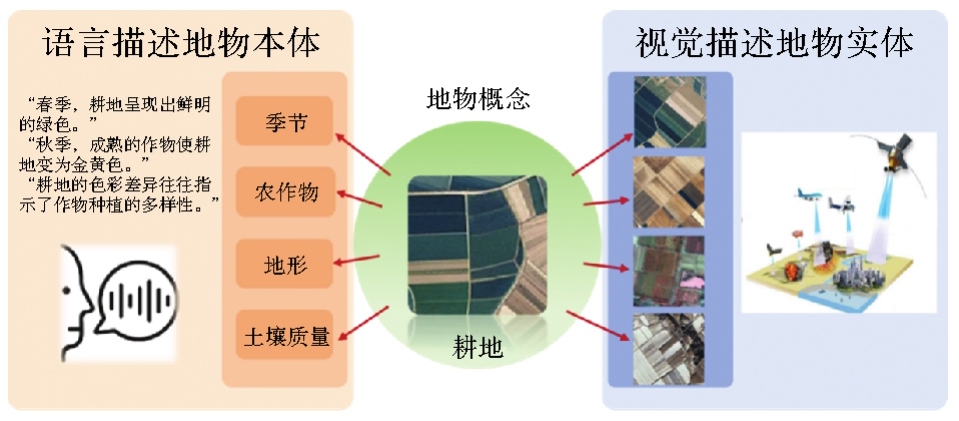
图4
视觉影像相似地物存在不同地物本体属性情况"
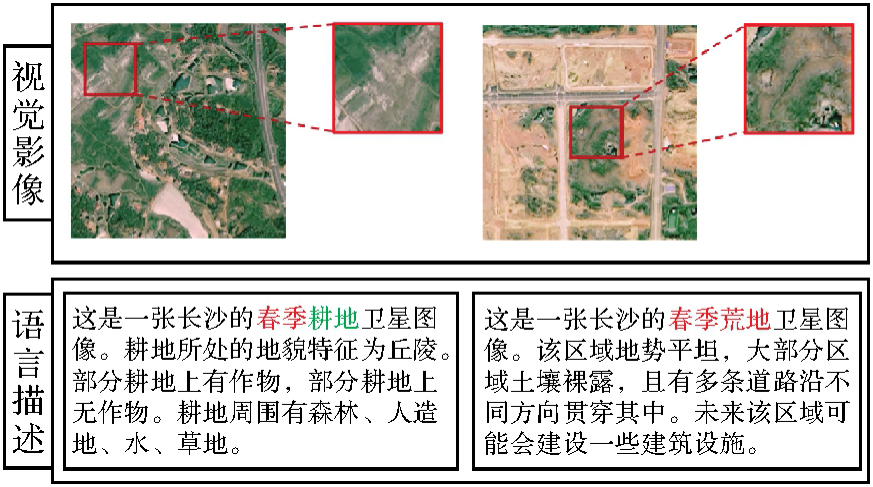

图5
遥感视觉-语言模态对齐现有研究工作组织结构"
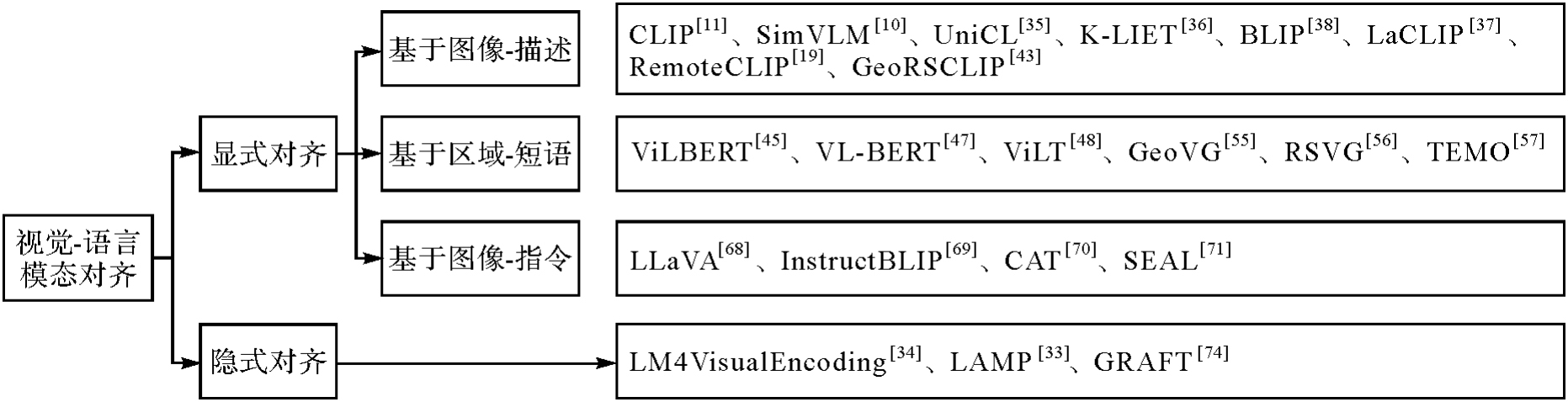
图6
显式对齐方法"
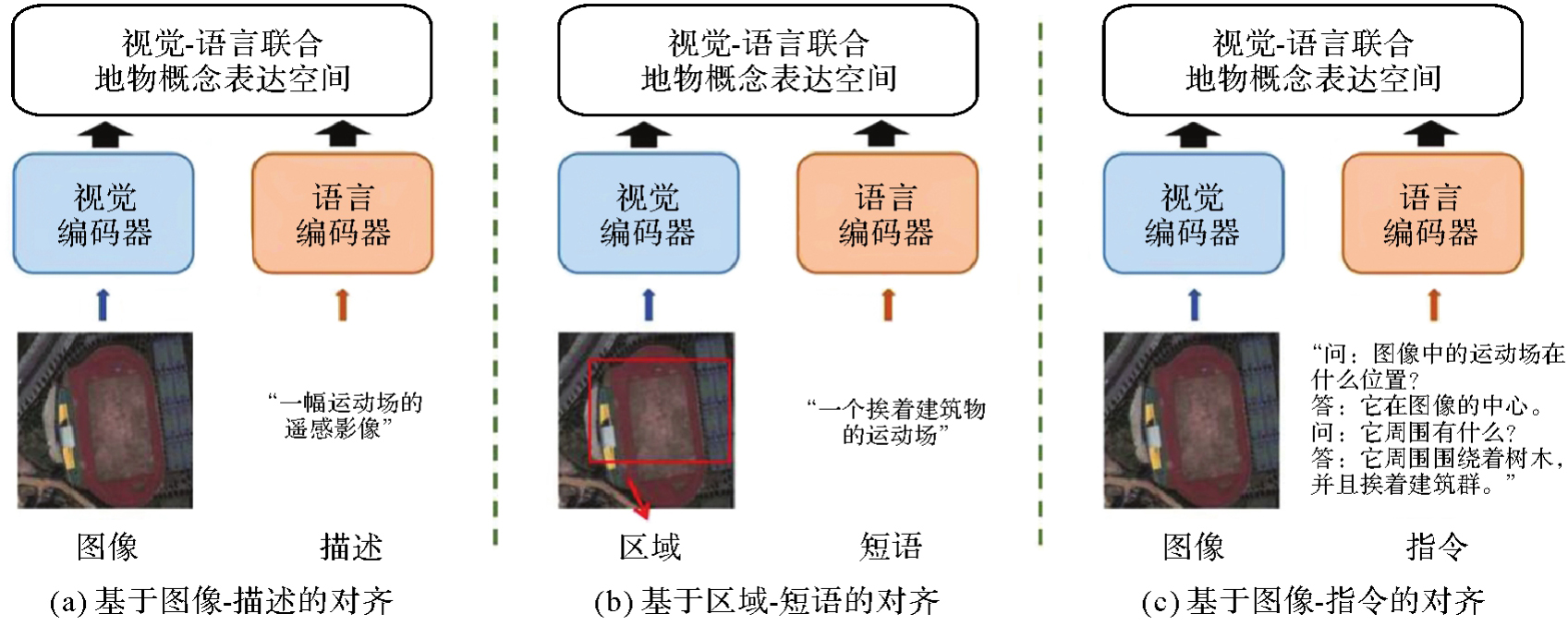
图7
视觉-语言模型能力涌现"

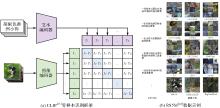
图8
零样本识别方法及训练数据集"
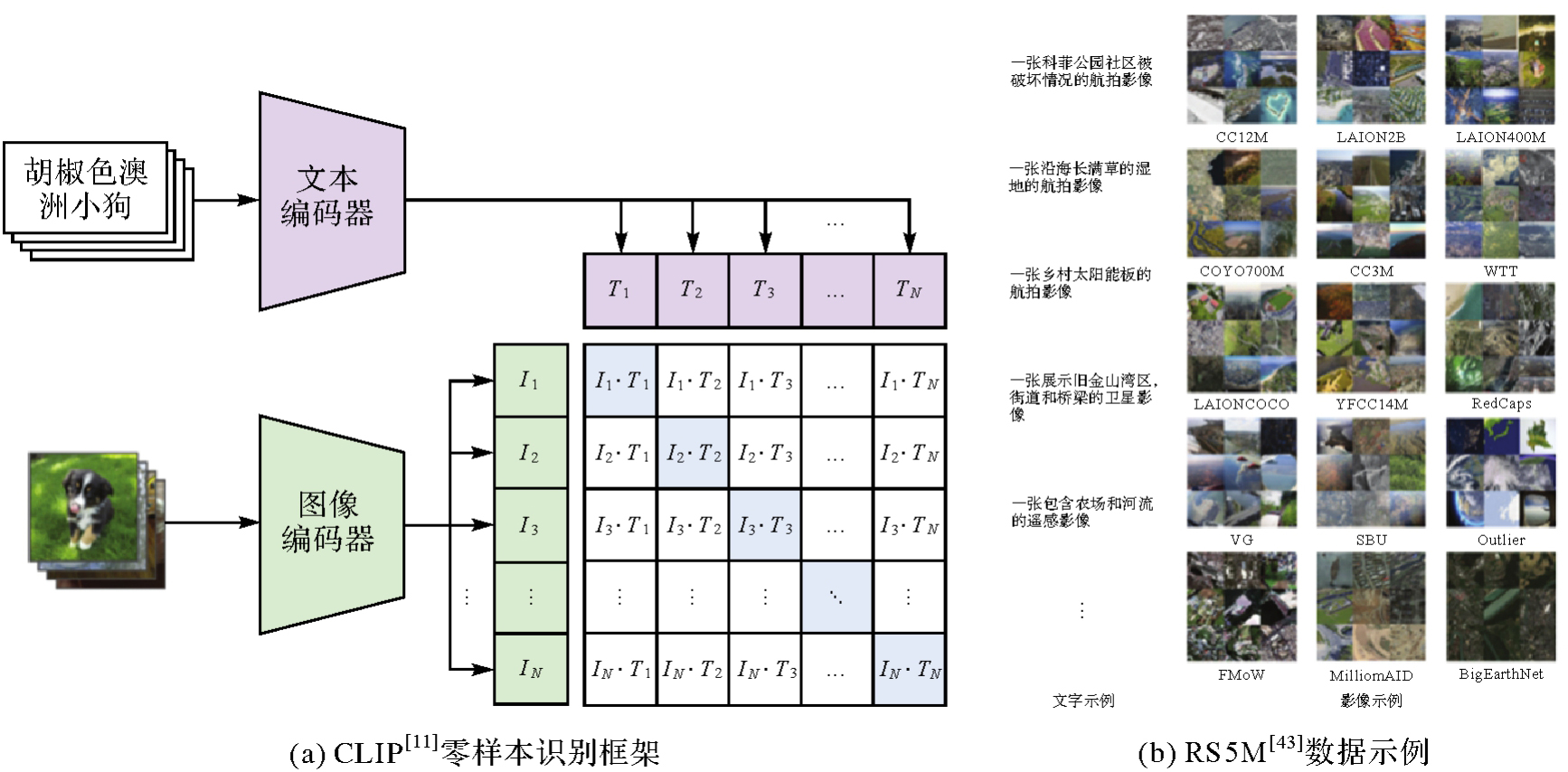

图9
扩散模型扩散过程概念"


图10
语言描述及遥感影像生成结果示例"

表2
分类精度(OA)对比"
| 模型 | 方法 | 视觉骨干网络 | 数据集 | ||
|---|---|---|---|---|---|
| AID | RSC11 | WHU-RS19 | |||
| 视觉模型 | ImageNet[ | 83.00 | 79.68 | 95.63 | |
| SwAV[ | 86.00 | 84.86 | 96.12 | ||
| Barlow Twins[ | ResNet50[ | 88.25 | 85.26 | 97.09 | |
| VICReg[ | 88.10 | 84.46 | 96.60 | ||
| 视觉语言模型 | CLIP[ | 90.95 | 87.65 | 97.57 | |
| RemoteCLIP[ | 94.35 | 91.63 | 98.06 | ||
| 视觉模型 | ImageNet[ | 83.55 | 80.88 | 94.17 | |
| ViTAE[ | ViT-Base[ | 88.30 | 71.31 | 91.74 | |
| 视觉语言模型 | CLIP[ | 94.95 | 86.85 | 97.09 | |
| RemoteCLIP[ | 95.95 | 89.24 | 97.57 | ||
表3
零样本场景识别精度(OA)对比"
| 方法 | 数据集 | ||
|---|---|---|---|
| SIRI-WHU | AID | WHU-RS19 | |
| GeoChat[ | 66.63 | 72.03 | 86.47 |
| LHRS-Bot[ | 62.66 | 91.26 | 93.17 |
| H2RSVLM[ | 68.50 | 89.33 | 97.00 |
| SkySenseGPT[ | 74.75 | 92.25 | 97.02 |
表4
小样本目标检测性能对比(mAP)"
| 模型 | 方法 | 视觉骨干网络 | DIOR | NWPU VHR-10 | ||||
|---|---|---|---|---|---|---|---|---|
| 3例样本 | 5例样本 | 10例样本 | 3例样本 | 5例样本 | 10例样本 | |||
| 视觉模型 | Meta RCNN[ | 14.7 | 15.4 | 19.9 | 6.5 | 11.6 | 15.4 | |
| TFA[ | 20.8 | 21.9 | 26.7 | 13.2 | 16.5 | 14.5 | ||
| FSCE[ | ResNet101[ | 24.9 | 28.3 | 34.8 | 45.6 | 59.0 | 69.5 | |
| 视觉语言模型 | TEMO[ | 30.9 | 37.2 | 42.8 | 57.6 | 66.8 | 75.1 | |
| TSF-RGR[ | — | 42.0 | 49.0 | 57.0 | 66.0 | 77.0 | ||
表5
小样本语义分割性能对比(mIoU)"
| 模型 | 方法 | 视觉骨干网络 | ISAID-5I | |
|---|---|---|---|---|
| 1例样本 | 5例样本 | |||
| 视觉模型 | PANet[ | 23.13 | 26.27 | |
| SDM[ | 25.92 | 28.27 | ||
| TBPN[ | ResNet50[ | 23.88 | 26.49 | |
| R2Net[ | 32.71 | 37.36 | ||
| PCNet[ | 32.06 | 36.95 | ||
| 视觉语言模型 | HSE[ | 39.72 | 43.15 | |
表6
零样本遥感影像语义分割性能(mIoU)"
| 方法 | 数据集 | |||
|---|---|---|---|---|
| UAVid | LoveDA | Vaihingen | Potsdam | |
| SAM[ | 22.6 | 23.7 | 9.9 | 21.5 |
| SAM[ | 24.1 | 10.2 | 11.5 | 19.7 |
| GDINO[ | 49.4 | 30.5 | 32.2 | 45.3 |
表7
场景识别精度(OA)对比"
| 方法 | 训练数据 | 识别精度 |
|---|---|---|
| VGG19[ | 真实数据 | 95.72 |
| 生成数据 | 97.28 | |
| ResNet34[ | 真实数据 | 96.11 |
| 生成数据 | 99.22 | |
| ViT-B/32[ | 真实数据 | 93.77 |
| 生成数据 | 94.55 | |
| ViT-B/16[ | 真实数据 | 93.77 |
| 生成数据 | 95.33 |
| [1] |
龚健雅, 许越, 胡翔云, 等. 遥感影像智能解译样本库现状与研究[J]. 测绘学报, 2021, 50(8): 1013-1022. DOI: .
doi: 10.11947/j.AGCS.2021.20210085 |
|
GONG Jianya, XU Yue, HU Xiangyun, et al. Status analysis and research of sample database for intelligent interpretation of remote sensing image[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8): 1013-1022. DOI: .
doi: 10.11947/j.AGCS.2021.20210085 |
|
| [2] | 刘大伟, 韩玲, 韩晓勇. 基于深度学习的高分辨率遥感影像分类研究[J]. 光学学报, 2016, 36(4): 428001. |
| LIU Dawei, HAN Ling, HAN Xiaoyong. High spatial resolution remote sensing image classification based on deep learning[J]. Acta Optica Sinica, 2016, 36(4): 428001. | |
| [3] | 李石华, 王金亮, 毕艳, 等. 遥感图像分类方法研究综述[J]. 国土资源遥感, 2005, 17(2): 1-6. |
| LI Shihua, WANG Jinliang, BI Yan, et al. A review of methods for classification of remote sensing images[J]. Remote Sensing for Land & Resources, 2005, 17(2): 1-6. | |
| [4] | 徐丰, 王海鹏, 金亚秋. 深度学习在SAR目标识别与地物分类中的应用[J]. 雷达学报, 2017, 6(2): 136-148. |
| XU Feng, WANG Haipeng, JIN Yaqiu. Deep learning as applied in SAR target recognition and terrain classification[J]. Journal of Radars, 2017, 6(2): 136-148. | |
| [5] | 聂光涛, 黄华. 光学遥感图像目标检测算法综述[J]. 自动化学报, 2021, 47(8): 1749-1768. |
| NIE Guangtao, HUANG Hua. A survey of object detection in optical remote sensing images[J]. Acta Automatica Sinica, 2021, 47(8): 1749-1768. | |
| [6] | ZHANG Xiangrong, ZHANG Tianyang, WANG Guanchun, et al. Remote sensing object detection meets deep learning: a metareview of challenges and advances[J]. IEEE Geoscience and Remote Sensing Magazine, 2023, 11(4): 8-44. |
| [7] | SUBRAMANYAM R, JAYRAM T S, ANIRUDH R, et al. CREPE: learnable prompting with CLIP improves visual relationship prediction[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2307.04838v2. |
| [8] | 农元君, 王俊杰, 赵雪冰, 等. 遥感目标空间关系检测方法[J]. 光学学报, 2021, 41(16): 1628001. |
| NONG Yuanjun, WANG Junjie, ZHAO Xuebing, et al. Spatial relationship detection method of remote sensing objects[J]. Acta Optica Sinica, 2021, 41(16): 1628001. | |
| [9] | DU Yifan, LIU Zikang, LI Junyi, et al. A survey of vision-language pre-trained models[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2202.10936v2. |
| [10] | WANG Z R, YU J H, YU A W, et al. SimVLM: simple visual language model pretraining with weak supervision[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2108.10904v3. |
| [11] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural languagesupervision[C]//Proceedings of 2021 International Conference on Machine Learning. [S.l.]: PMLR, 2021: 8748-8763. |
| [12] | YANG Z Y, LI L J, LIN K, et al. The dawn of LMMs: preliminary explorations with GPT-4V (ision)[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2309.17421v2. |
| [13] | ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning[J]. Advances in Neural Information Processing Systems, 2022, 35: 23716-23736. |
| [14] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//Proceedings of 2014 ECCV. Zurich: Springer International Publishing, 2014: 740-755. |
| [15] | KRISHNA R, ZHU Y K, GROTH O, et al. Visual genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. |
| [16] | SCHUHMANN C, BEAUMONT R, VENCU R, et al. LAION-5B: an open large-scale dataset for training next generation image-text models[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 25278-25294. |
| [17] | 张良培, 张乐飞, 袁强强. 遥感大模型:进展与前瞻[J]. 武汉大学学报(信息科学版), 2023, 48(10): 1574-1581. |
| ZHANG Liangpei, ZHANG Lefei, YUAN Qiangqiang. Large remote sensing model: progress and prospects[J]. Geomatics and Information Science of Wuhan University, 2023, 48(10): 1574-1581. | |
| [18] | SHAO Run, YANG Cheng, LI Qiujun, et al. AllSpark: a multimodal spatio-temporal general intelligence model with ten modalities via language as a reference framework[EB/OL]. [2023-12-20]. https://arxiv.org/abs/2401.00546v3. |
| [19] | LIU F, CHEN D L, GUAN Z, et al. RemoteCLIP: a vision language foundation model for remote sensing[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2306.11029v4. |
| [20] | ZHANG Jingyi, HUANG Jiaxing, JIN Sheng, et al. Vision-language models for vision tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5625-5644. |
| [21] | LI Xiang, WEN Congcong, HU Yuan, et al. Vision-language models in remote sensing: current progress and future trends[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2305.05726v2. |
| [22] | 诸云强, 孙凯, 王曙, 等. 顾及复杂时空特征及关系的地球科学知识图谱自适应表达模型[J]. 中国科学:地球科学, 2023, 53(11): 2609-2622. |
| ZHU Yunqiang, SUN Kai, WANG Shu, et al. An adaptive representation model for geoscience knowledge graphs considering complex spatiotemporal features and relationships[J]. Scientia Sinica (Terrae), 53(11): 2609-2622. | |
| [23] | 顾海燕, 李海涛, 闫利, 等. 地理本体驱动的遥感影像面向对象分析方法[J]. 武汉大学学报(信息科学版), 2018, 43(1): 31-36. |
| GU Haiyan, LI Haitao, YAN Li, et al. A geographic object-based image analysis methodology based on geo-ontology[J]. Geomatics and Information Science of Wuhan University, 2018, 43(1): 31-36. | |
| [24] | 孙敏, 陈秀万, 张飞舟. 地理信息本体论[J]. 地理与地理信息科学, 2004, 20(3): 6-11. |
| SUN Min, CHEN Xiuwan, ZHANG Feizhou. Geo-ontology[J]. Geography and Geo-Information Science, 2004, 20(3): 6-11. | |
| [25] | 李霖, 王红, 赵宁, 等. 基于本体论的基础地理信息分类研究[J]. 地理信息世界, 2004 (6): 21-25. |
| LI Lin, WANG Hong, ZHAO Ning, et al. Classification of fundamental geographical information based on ontology[J]. Geomatics World, 2004 (6): 21-25. | |
| [26] | 李彦胜, 张永军. 耦合知识图谱和深度学习的新一代遥感影像解译范式[J]. 武汉大学学报(信息科学版), 2022, 47(8): 1176-1190. |
| LI Yansheng, ZHANG Yongjun. A new paradigm of remote sensing image interpretation by coupling knowledge graph and deep learning[J]. Geomatics and Information Science of Wuhan University, 2022, 47(8): 1176-1190. | |
| [27] | 王志华, 杨晓梅, 周成虎. 面向遥感大数据的地学知识图谱构想[J]. 地球信息科学学报, 2021, 23(1): 16-28. |
| WANG Zhihua, YANG Xiaomei, ZHOU Chenghu. Geographic knowledge graph for remote sensing big data[J]. Journal of Geo-information Science, 2021, 23(1): 16-28. | |
| [28] | 刘峤, 李杨, 段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600. |
| LIU Qiao, LI Yang, DUAN Hong, et al. Knowledge graph construction techniques[J]. Journal of Computer Research and Development, 2016, 53(3): 582-600. | |
| [29] | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3156-3164. |
| [30] | REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis[EB/OL]//Proceedings of 2016 International Conference on Machine Learning. [S.l.]: PMLR, 2016: 1060-1069. |
| [31] | ALEC R, KIM J M, CHRIS H. Learning transferable visual models from natural language supervision[C]//Proceedings of 2021 International Conference on Machine Learning. [S.l.]: ICML, 2021: 1-16. |
| [32] | LIU Jing, ZHU Xinxin, LIU Fei, et al. OPT: omni-perception pre-trainer for cross-modal understanding and generation[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2107.00249v2. |
| [33] | ADENIJI A, XIE A, SFERRAZZA C, et al. Language reward modulation for pretraining reinforcement learning[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2308.12270v1. |
| [34] | PANG Ziqi, XIE Ziyang, MAN Yunze, et al. Frozen transformers in language models are effective visual encoder layers[EB/OL]. [2024-01-20]. https://arxiv.org/abs/2310.12973v2. |
| [35] | YANG Jianwei, LI Chunyuan, ZHANG Pengchuan, et al. Unified contrastive learning in image-text-label space[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022. |
| [36] | SHEN S, LI C, HU X, et al. K-lite: learning transferable visual models with external knowledge[J]. Advances in Neural Information Processing Systems, 2022, 35: 15558-15573. |
| [37] | FAN L, KRISHNAN D, ISOLA P, et al. Improving CLIP training with language rewrites[EB/OL]. [2024-01-02]. https://arxiv.org/pdf/2305.20088. |
| [38] | LI Junnan, LI Dongxu, XIONG Caiming, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[EB/OL]. [2024-01-02]. https://arxiv.org/pdf/2201.12086. |
| [39] | QU Bo, LI Xuelong, TAO Dacheng, et al. Deep semantic understanding of high resolution remote sensing image[C]//Proceedings of 2016 International Conference on Computer, Information and Telecommunication Systems. Kunming: IEEE, 2016: 1-5. |
| [40] | YANG Y, NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]//Proceedings of 2020 SIGSPA-TIAL International Conference on Advances in Geographic Information Systems. San Jose: ACM Press, 2010: 270-279. |
| [41] | LU Xiaoqiang, WANG Binqiang, ZHENG Xiangtao, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183-2195. |
| [42] | YUAN Zhiqiang, ZHANG Wenkai, FU Kun, et al. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2204.09868. |
| [43] | ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M: a large scale vision-language dataset for remote sensing vision-language foundation model[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2306.11300. |
| [44] | VASWANI A. Attention is all you need[EB/OL]. [2023-12-02]. https://arxiv.org/abs/1706.03762. |
| [45] | LU J S, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[EB/OL]. [2024-02-01]. https://arxiv.org/abs/1908.02265. |
| [46] | HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017. |
| [47] | SU Weijie, ZHU Xizhou, CAO Yue, et al. VL-BERT: pre-training of generic visual-linguistic representations[EB/OL]. [2023-12-02]. https://arxiv.org/abs/1908.08530. |
| [48] | KIM W, SON B, KIM I. ViLT: vision-and-language transformer without convolution or region supervision[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2102.03334. |
| [49] | YANG Lingfeng, WANG Yueze, LI Xiang, et al. Fine-grained visual prompting[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2306.04356. |
| [50] | SUN Zeyi, FANG Ye, WU Tong, et al. Alpha-CLIP: a clip model focusing on wherever you want[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2312.03818. |
| [51] | WANG Weiyun, SHI Min, LI Qingyun, et al. The all-seeing project: towards panoptic visual recognition and understanding of the open world[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2308.01907. |
| [52] | SHI Zhenwei, ZOU Zhengxia. Can a machine generate humanlike language descriptions for a remote sensing image?[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(6): 3623-3634. |
| [53] | ZHANG Xueting, WANG Qi, CHEN Shangdong, et al. Multi-scale cropping mechanism for remote sensing image captioning[C]//Proceedings of 2019 IEEE International Geoscience and Remote Sensing Symposium. Yokohama: IEEE, 2019: 10039-10042. |
| [54] | ZHAO Rui, SHI Zhenwei, ZOU Zhengxia. High-resolution remote sensing image captioning based on structured attention[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5603814. |
| [55] | SUN Yuxi, FENG Shanshan, LI Xutao, et al. Visual grounding in remote sensing images[C]//Proceedings of the 30th ACM International Conference on Multimedia. Lisboa: ACM Press, 2022: 404-412. |
| [56] | ZHAN Yang, XIONG Zhitong, YUAN Yuan. RSVG: exploring data and models for visual grounding on remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-13. |
| [57] | LU Xiaonan, SUN Xian, DIAO Wenhui, et al. Few-shot object detection in aerial imagery guided by text-modal knowledge[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 3250448. |
| [58] | LIU C, YANG S, SABA-SADIYA S, et al. Jointly learning grounded task structures from language instruction and visual demonstration[C]//Proceedings of 2016 Conference on Empirical Methods in Natural Language Processing. Austin: ACL, 2016: 1482-1492. |
| [59] | REN M, KIROS R, ZEMEL R. Exploring models and data for image question answering[EB/OL]. [2024-01-02]. https://arxiv.org/abs/1505.02074. |
| [60] | YAMASHITA R, NISHIO M, DO R K G, et al. Convolutional neural networks: an overview and application in radiology[J]. Insights into Imaging, 2018, 9: 611-629. |
| [61] | MEDSKER L R, JAIN L. Recurrent neural networks[J]. Design and Applications, 2001, 5(64-67): 2. |
| [62] | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780. |
| [63] | LOBRY S, MARCOS D, MURRAY J, et al. RSVQA: visual question answering for remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(12): 8555-8566. |
| [64] | OpenAI. Introduction ChatGPT[EB/OL]. [2024-01-20]. https://openai.com/blog/chatgpt/. |
| [65] | LI L H, YATSKAR M, YIN D, et al. VisualBERT: a simple and performant baseline for vision and language[EB/OL]. [2024-01-02]. https://arxiv.org/abs/1908.03557v1. |
| [66] | TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from transformers[EB/OL]. [2024-01-02]. https://arxiv.org/abs/1908.07490v3. |
| [67] | AL RAHHAL M M, BAZI Y, ALSALEH S Oingyang, et al. Open-ended remote sensing visual question answering with transformers[J]. International Journal of Remote Sensing, 2022, 43(18): 6809-6823. |
| [68] | LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2304.08485. |
| [69] | DAI Wenliang, LI Junnan, LI Dorgxu, et al. InstructBLIP: towards general-purpose vision-language models with instruction tuning[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2305.06500. |
| [70] | WANG Teng, ZHANG Jinrui, FEI Junjie, et al. Caption anything: interactive image description with diverse multimodal controls[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2305.02677v3. |
| [71] | WU Penghao, XIE Saining. V*: guided visual search as a core mechanism in multimodal LLMs[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2312.14135v2. |
| [72] | HUH M, CHEUNG B, WANG Tongzhou, et al. The platonic representation hypothesis[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2405.07987v5. |
| [73] | MANIPARAMBIL M, AKSHULAKOV R, DJILALI Y A D, et al. Do vision and language encoders represent the world similarly?[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2401.05224v2. |
| [74] | MALL U, PHOO C P, LIU M K, et al. Remote sensing vision-language foundation models without annotations via ground remote alignment[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2312.06960v1. |
| [75] | CHURCH K W. Word2Vec[J]. Natural Language Engineering, 2017, 23(1): 155-162. |
| [76] | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation[C]//Proceedings of 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. |
| [77] | JOULIN A, GRAVE E, BOJANOWSKI P, et al. FastText.zip: compressing text classification models[EB/OL]. [2024-01-02]. https://arxiv.org/abs/1612.03651v1. |
| [78] | KODIROV E, XIANG Tao, GONG Shaogang. Semantic autoencoder for zero-shot learning[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3174-3183. |
| [79] | 吴晨, 王宏伟, 袁昱纬, 等. 基于图像特征融合的遥感场景零样本分类算法[J]. 光学学报, 2019, 39(6): 0610002. |
| WU Chen, WANG Hongwei, YUAN Yuwei, et al. Image feature fusion based remote sensing scene zero-shot classification algorithm[J]. Acta Optica Sinica, 2019, 39(6): 0610002. | |
| [80] |
李彦胜, 孔德宇, 张永军, 等. 联合稳健跨域映射和渐进语义基准修正的零样本遥感影像场景分类[J]. 测绘学报, 2020, 49(12): 1564-1574. DOI: .
doi: 10.11947/j.AGCS.2020.20200139 |
|
LI Yansheng, KONG Deyu, ZHANG Yongjun, et al. Zero-shot remote sensing image scene classification based on robust cross- domain mapping and gradual refinement of semantic space[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(12): 1564-1574. DOI: .
doi: 10.11947/j.AGCS.2020.20200139 |
|
| [81] | SARZYNSKA-WAWER J, WAWER A, PAWLAK A, et al. Detecting formal thought disorder by deep contextualized word representations[J]. Psychiatry Research, 2021, 304: 114135. |
| [82] | DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2024-01-02]. https://arxiv.org/abs/1810.04805v2. |
| [83] | BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in Neural Information Processing Systems, 2020, 33: 1877-1901. |
| [84] | JIA Chao, YANG Yinfei, XIA Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2102.05918. |
| [85] | HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851. |
| [86] | CAO Zihan, CAO Shiqi, WU Xiao, et al. DDRF: denoising diffusion model for remote sensing image fusion[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2304.04774v1. |
| [87] | LIU Jinzhe, YUAN Zhiqiang, PAN Zhaoying, et al. Diffusion model with detail complement for super-resolution of remote sensing[J]. Remote Sensing, 2022, 14(19): 4834. |
| [88] | KASODEKAR K S. Remote diffusion[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2405.04717v1. |
| [89] | TANG Datao, CAO Xiangyong, HOU Xingsong, et al. CRS-Diff: controllable generative remote sensing foundation model[EB/OL]. [2023-12-02]. https://arxiv.org/html/2403.11614v3. |
| [90] | KHANNA S, LIU P, ZHOU Linqi, et al. DiffusionSat: a generative foundation model for satellite imagery[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2312.03606v2. |
| [91] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. |
| [92] | DOSOVITSKIY A. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2010.11929. |
| [93] | XIA Guisong, HU Jingwen, HU Fan, et al. AID: a benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965-3981. |
| [94] | ZHAO Lijun, TANG Ping, HUO Lianzhi. Feature significance-based multibag-of-visual-words model for remote sensing image scene classification[J]. Journal of Applied Remote Sensing, 2016, 10(3): 035004. |
| [95] | XIA Guisong, YANG Wen, DELON J, et al. Structural high-resolution satellite image indexing[C]//Proceedings of 2010 ISPRS TC VII Symposium-100 Years ISPRS. Vienna: [s.n.], 2010: 298-303. |
| [96] | DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248-255. |
| [97] | CARON M, MISRA I, MAIRAL J, et al. Unsupervised learning of visual features by contrasting cluster assignments[J]. Advances in Neural Information Processing Systems, 2020, 33: 9912-9924. |
| [98] | ZBONTAR J, JING L, MISRA I, et al. Barlow twins: self-supervised learning via redundancy reduction[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2103.03230. |
| [99] | DBARDES A, PONCE J, LECUN Y. VICReg: variance-invariance-covariance regularization for self-supervised learning[EB/OL]. [2024-01-02]. https://arxiv.org/abs/2105.04906v3. |
| [100] | XU Yufei, ZHANG Qiming, ZHANG Jing, et al. ViTAE: vision transformer advanced by exploring intrinsic inductive bias[J]. Advances in Neural Information Processing Systems, 2021, 34: 28522-28535. |
| [101] | KUCKREJA K, DANISH M S, NASEER M, et al. GeoChat: grounded large vision-language model for remote sensing[C]//Proceedings of 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2024: 27831-27840. |
| [102] | MUHTAR D, LI Zhenshi, GU Feng, et al. LHRS-bot: empowering remote sensing with VGI-enhanced large multimodal language model[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2402.02544v4. |
| [103] | PANG Chao, WU Jiang, LI Jiayu, et al. H2RSVLM: towards helpful and honest remote sensing large vision language model[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2403.20213. |
| [104] | LUO Junwei, PANG Zhen, ZHANG Yongjun, et al. SkySenseGPT: a fine-grained instruction tuning dataset and model for remote sensing vision-language understanding[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2406.10100v2. |
| [105] | ZHU Qiqi, ZHONG Yanfei, ZHAO Bei, et al. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(6): 747-751. |
| [106] | ZHANG Sanxing, SONG Fei, LIU Xianyuan, et al. Text semantic fusion relation graph reasoning for few-shot object detection on remote sensing images[J]. Remote Sensing, 2023, 15(5): 1187. |
| [107] | YAN Xiaopeng, CHEN Ziliang, XU Anni, et al. Meta R-CNN: towards general solver for instance-level low-shot learning[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9577-9586. |
| [108] | WANG Xin, HUANG T E, DARRELL T, et al. Frustratingly simple few-shot object detection[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2003.06957v1. |
| [109] | SUN Bo, LI Banghuai, CAI Shengcai, et al. FSCE: few-shot object detection via contrastive proposal encoding[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021. |
| [110] | LI Xiang, DENG Jingyu, FANG Yi. Few-shot object detection on remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5601614. |
| [111] | LI Ke, WAN Gang, CHENG Gong, et al. Object detection in optical remote sensing images: a survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296-307. |
| [112] | WANG Kaixin, LIEW J H, ZOU Yingtian, et al. PANet: few-shot image semantic segmentation with prototype alignment[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019. |
| [113] | PUTHUMANAILLAM G, VERMA U. Texture based prototypical network for few-shot semantic segmentation of forest cover: generalizing for different geographical regions[J]. Neurocomputing, 2023, 538: 126201. |
| [114] | LANG Chunbo, WANG Junyi, CHENG Gong, et al. Progressive parsing and commonality distillation for few-shot remote sensing segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 3286183. |
| [115] | JIA Yuyu, HUANG Wei, GAO Junyu, et al. Embedding generalized semantic knowledge into few-shot remote sensing segmentation[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2405.13686v1. |
| [116] | YAO Xiwen, CAO Qinglong, FENG Xiaoxu, et al. Scale-aware detailed matching for few-shot aerial image semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 3119852. |
| [117] | XIE Guosen, LIU Jie, XIONG Huan, et al. Scale-aware graph neural network for few-shot semantic segmentation[C]//Proceedings of 2021 EEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021. |
| [118] | LANG Chunbo, CHENG Gong, TU Binfei, et al. Global rectification and decoupled registration for few-shot segmentation in remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 3301003. |
| [119] | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]//Proceedings of 2023 IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 4015-4026. |
| [120] | LIU Shilong, ZENG Zhaoyang, REN Tianhe, et al. Grounding DINO: marrying DINO with grounded pre-training for open-set object detection[C]//Proceedings of 2025 European Conference on Computer Vision. Cham: Springer, 2025: 38-55. |
| [121] | ZHANG Jielu, ZHOU Zhongliang, MAI Gengchen, et al. Text2Seg: zero-shot remote sensing image semantic segmentation via text-guided visual foundation models[C]//Proceedings of the 7th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery. Atlanta: ACM Press, 2024: 63-66. |
| [122] | LI Yi, WANG Hualiang, DUAN Yiqun, et al. Clip surgery for better explainability with enhancement in open-vocabulary tasks[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2304.05653. |
| [123] | LÜ Ye, VOSSELMAN G, XIA Guisong, et al. UAVid: a semantic segmentation dataset for UAV imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 165: 108-119. |
| [124] | WANG Junjue, ZHENG Zhuo, MA Ailong, et al. LoveDA: a remote sensing land-cover dataset for domain adaptive semantic segmentation[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2110.08733v6. |
| [125] | ROTTENSTEINER F, SOHN G, JUNG J, et al. The ISPRS benchmark on urban object classification and 3D building reconstruction[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2012, 1(1): 293-298. |
| [126] | YU Zhiping, LIU Chenyang, LIU Liqin, et al. MetaEarth: a generative foundation model for global-scale remote sensing image generation[EB/OL]. [2023-12-02]. https://arxiv.org/abs/2405.13570v3. |
| [127] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2023-12-02]. https://arxiv.org/abs/1409.1556. |
| [128] | KOERNER E F. The Sapir-Whorf hypothesis: a preliminary history and a bibliographical essay[J]. Journal of Linguistic Anthropology, 1992, 2(2): 173-198. |
| [1] | 廖钊宏, 张依晨, 杨飚, 林明春, 孙文博, 高智. 基于Swin Transformer-CNN的单目遥感影像高程估计方法及其在公路建设场景中的应用[J]. 测绘学报, 2024, 53(2): 344-352. |
| [2] | 陶超, 阴紫薇, 朱庆, 李海峰. 遥感影像智能解译:从监督学习到自监督学习[J]. 测绘学报, 2021, 50(8): 1122-1134. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||