

Acta Geodaetica et Cartographica Sinica ›› 2024, Vol. 53 ›› Issue (10): 1942-1954.doi: 10.11947/j.AGCS.2024.20240019.
• Remote Sensing Large Model • Previous Articles Next Articles
Yongjun ZHANG1,( ), Yansheng LI1(), Bo DANG1, Kang WU1, Xin GUO2, Jian WANG2, Jingdong CHEN2, Ming YANG2
), Yansheng LI1(), Bo DANG1, Kang WU1, Xin GUO2, Jian WANG2, Jingdong CHEN2, Ming YANG2
Received:2024-01-12
Online:2024-11-26
Published:2024-11-26
Contact:
Yansheng LI
E-mail:zhangyj@whu.edu.cn;yansheng.li@whu.edu.cn
About author:ZHANG Yongjun (1975—), male, PhD, professor, majors in aerospace photogrammetry and remote sensing intelligent interpretation. E-mail: zhangyj@whu.edu.cn
Supported by:CLC Number:
Yongjun ZHANG, Yansheng LI, Bo DANG, Kang WU, Xin GUO, Jian WANG, Jingdong CHEN, Ming YANG. Multi-modal remote sensing large foundation models: current research status and future prospect[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(10): 1942-1954.
Tab.1
Large-scale remote sensing vision pre-training datasets"
| 数据集 | 图像数量 | 图像大小/像素 | 空间分辨率/m | 图像类型 | 图像数据源 | 覆盖地理位置 |
|---|---|---|---|---|---|---|
| fMoW[ | 1 047 691 | — | — | 多光谱(4/8波段) | Digital Globe | 全球 |
| SEN12MS[ | 180 662 | 256 | 10 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| BigEarthNet-MM[ | 1 180 652 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 欧洲 |
| MillionAID[ | 1 000 848 | 110~31 672 | 0.5~153 | 可见光 | Google Earth | — |
| SeCo[ | 1 000 000 | — | 10 | 多光谱 | 哨兵2号 | 全球 |
| fMoW-Sentinel[ | 882 779 | 45~60 | 10 | 多光谱(13波段) | 哨兵2号 | 全球 |
| TOV-RS-Balanced[ | 500 000 | 600 | 1~20 | 可见光 | Google Earth | - |
| SSL4EO-S12[ | 3 012 948 | 20~120 | 10~60 | 合成孔径雷达-多光谱 | 哨兵1号、哨兵2号 | 全球 |
| SSL4EO-L[ | 5 000 000 | 264 | 30 | 多光谱 | Landsat4-5,7-9 | 全球 |
| SatlasPretrain[ | 856 000 | 512 | 0.5~2,10 | 可见光&多光谱 | NAIP、哨兵2号 | 全球 |
Tab.2
Large-scale remote sensing vision-language pre-training datasets"
| 数据集 | 数量 | 属性 |
|---|---|---|
| RSICD[ | 24 333个文本描述、10 921张遥感影像 | 图像-文本描述 |
| RSITMD[ | 23 715个文本描述、4743张遥感影像 | 图像-文本描述 |
| RSVGD[ | 38 320个语言表达、17 402张遥感影像 | 视觉定位 |
| RS5M[ | 500万个图像文本对 | 图像-文本描述 |
| RSICap[ | 2585个图像文本对 | 图像-文本描述 |
| 文献[ | 828 725个图像文本对 | 图像-文本描述 |
| 文献[ | 318 000个图像指令提示对 | 图像-文本描述、定位描述、区域描述、复杂对话 |

Fig.1
Classification of remote sensing foundation models and typical downstream tasks"
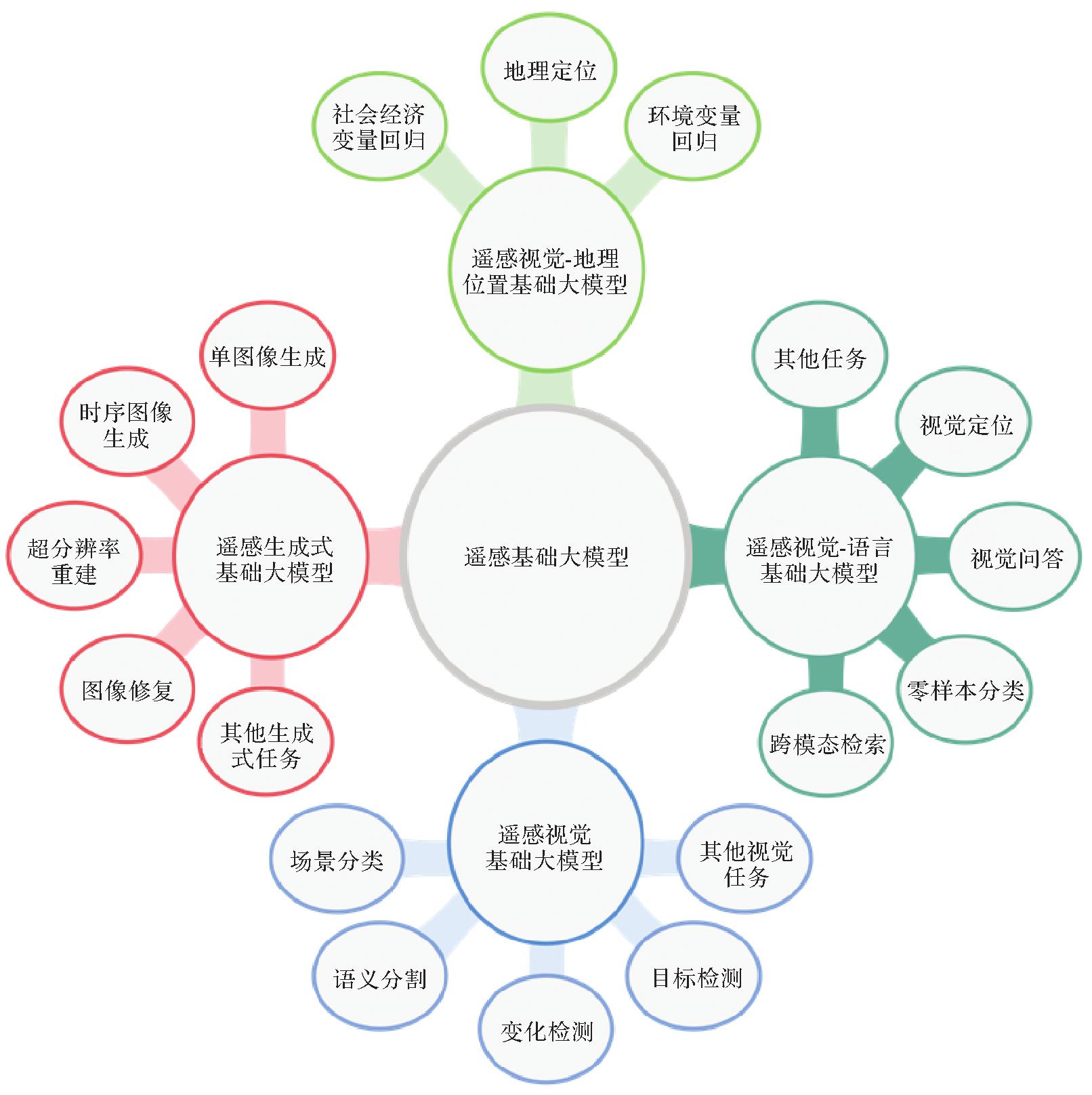

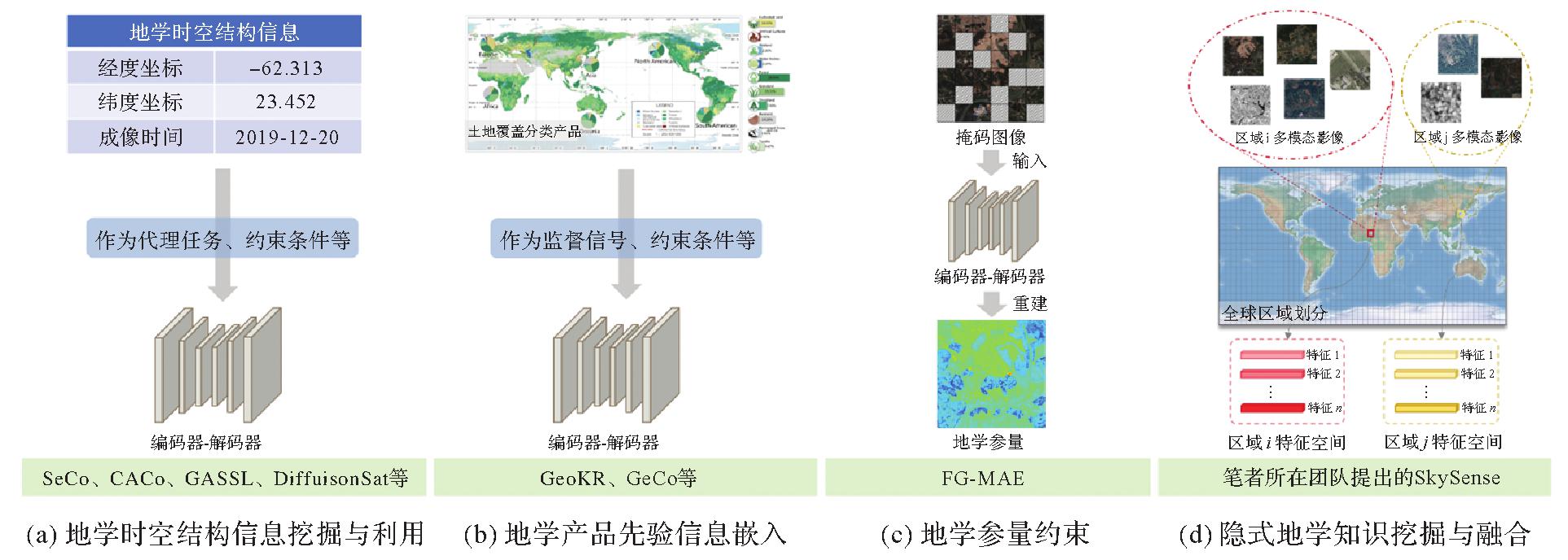
Fig.2
Four ways of mining and utilizing geoscience knowledge for remote sensing foundation model"
| [1] | 付琨, 卢宛萱, 刘小煜, 等. 遥感基础模型发展综述与未来设想[J]. 遥感学报, 2024, 28(7):1667-1680. |
| FU Kun, LU Wanxuan, LIU Xiaoyu, et al. A comprehensive survey and assumption of remote sensing foundation modal[J]. National Remote Sensing Bulletin, 2024, 28(7):1667-1680. | |
| [2] | LI Yansheng, CHEN Wei, HUANG Xin, et al. MFVNet: a deep adaptive fusion network with multiple field-of-views for remote sen-sing image semantic segmentation[J]. Science China Information Sciences, 2023, 66(4):140305. |
| [3] | LI Yansheng, DANG Bo, ZHANG Yongjun, et al. Water body classification from high-resolution optical remote sensing imagery: achievements and perspectives[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 187:306-327. |
| [4] | LI Yansheng, WEI Fanyi, ZHANG Yongjun, et al. HS2P: Hierarchical spectral and structure-preserving fusion network for multimodal remote sensing image cloud and shadow removal[J]. Information Fusion, 2023, 94:215-228. |
| [5] | PENG Daifeng, ZHAI Chenchen, ZHANG Yongjun, et al. High-resolution optical remote sensing image change detection based on dense connection and attention feature fusion network[J]. The Photogrammetric Record, 2023, 38(184):498-519. |
| [6] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[EB/OL]. [2024-01-05]. https://arxiv.org/pdf/2103.00020. |
| [7] | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[EB/OL]. [2024-01-05]. https://arxiv.org/pdf/2304.02643. |
| [8] | YANG Zhengyuan, LI Linjie, LIN K, et al. The dawn of LMMs: preliminary explorations with GPT-4V (ision)[EB/OL]. [2024-01-05]. https://arxiv.org/pdf/2309.17421. |
| [9] | 张良培, 张乐飞, 袁强强. 遥感大模型:进展与前瞻[J]. 武汉大学学报(信息科学版), 2023, 48(10):1574-1581. |
| ZHANG Liangpei, ZHANG Lefei, YUAN Qiangqiang. Large remote sensing model: progress and prospects[J]. Geomatics and Information Science of Wuhan University, 2023, 48(10):1574-1581. | |
| [10] | JIAO Licheng, HUANG Zhongjian, LU Xiaoqiang, et al. Brain-inspired remote sensing foundation models and open problems: a comprehensive survey[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023, 16:10084-10120. |
| [11] | LI Xiang, WEN Congcong, HU Yuan, et al. Vision-language models in remote sensing: current progress and future trends[EB/OL]. [EB/OL]. [2024-01-05]. https://arxiv.org/abs/2305.05726. |
| [12] | MANAS O, LACOSTE A, GIRO-I-NIETO X, et al. Seasonal contrast: unsupervised pre-training from uncurated remote sensing data[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 9414-9423. |
| [13] | MALL U, HARIHARAN B, BALA K. Change-aware sampling and contrastive learning for satellite images[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 5261-5270. |
| [14] | KLEMMER K, ROLF E, ROBINSON C, et al. SatCLIP: global, general-purpose location embeddings with satellite imagery[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2311.17179. |
| [15] | LI Wenyuan, CHEN Keyan, CHEN Hao, et al. Geographical knowledge-driven representation learning for remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60:5405516. |
| [16] | LI Wenyuan, CHEN Keyan, SHI Zhenwei. Geographical supervision correction for remote sensing representation learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60:5411520. |
| [17] | WANG Yi, HERNÁNDEZ H H, ALBRECHT C, et al. Feature guided masked autoencoder for self-supervised learning in remote sensing[EB/OL]. [2024-01-05]. https://arxiv.org/pdf/2310.18653. |
| [18] | GUO Xin, LAO Jiangwei, DANG Bo, et al. SkySense: a multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery[C]//Proceedings of 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 27672-27683. |
| [19] | TAO Chao, QI Ji, GUO Mingning, et al. Self-supervised remote sensing feature learning: learning paradigms, challenges, and future works[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5610426. |
| [20] | TAO Chao, QI Ji, ZHANG Guo, et al. TOV: The original vision model for optical remote sensing image understanding via self-supervised learning[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023, 16:4916-4930. |
| [21] | MUHTAR D, ZHANG Xueliang, XIAO Pengfeng, et al. CMID: a unified self-supervised learning framework for remote sensing image understanding[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5607817. |
| [22] | LONG Yang, XIA Guisong, LI Shengyang, et al. On creating benchmark dataset for aerial image interpretation: reviews, guidances, and million-AID[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14:4205-4230. |
| [23] | BASTANI F, WOLTERS P, GUPTA R, et al. SatlasPretrain: a large-scale dataset for remote sensing image understanding[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2211.15660v3. |
| [24] | CHRISTIE G, FENDLEY N, WILSON J, et al. Functional map of the world[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6172-6180. |
| [25] | SUMBUL G, DE WALL A, KREUZIGER T, et al. BigEarthNet-MM: a large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets][J]. IEEE Geoscience and Remote Sensing Magazine, 2021, 9(3):174-180. |
| [26] | WANG Yi, ALI BRAHAM N A, XIONG Zhitong, et al. SSL4EO-S12: a large-scale multimodal, multitemporal dataset for self-supervised learning in Earth observation [software and data sets][J]. IEEE Geoscience and Remote Sensing Magazine, 2023, 11(3):98-106. |
| [27] | SCHMITT M, HUGHES L H, QIU C, et al. SEN12MS—a curated dataset of georeferenced multi-spectral Sentinel-1/2 imagery for deep learning and data fusion[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2019, 4:153-160. |
| [28] | CONG Yezhen, KHANNA S, MENG Chenlin, et al. SatMAE: pre-training transformers for temporal and multi-spectral satellite imagery[J]. Advances in Neural Information Processing Systems, 2022, 35:197-211. |
| [29] | STEWART A J, LEHMANN N, CORLEY I A, et al. SSL4EO-L: datasets and foundation models for landsat imagery[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2306.09424. |
| [30] | LU Xiaoqiang, WANG Binqiang, ZHENG Xiangtao, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4):2183-2195. |
| [31] | YUAN Zhiqiang, ZHANG Wenkai, FU Kun, et al. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60:4404119. |
| [32] | ZHAN Yang, XIONG Zhitong, YUAN Yuan. RSVG: exploring data and models for visual grounding on remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5604513. |
| [33] | ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M: a large scale vision-language dataset for remote sensing vision-language foundation model[EB/OL]. [2024-01-05]. http://export.arxiv.org/abs/2306.11300v4. |
| [34] | HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: a remote sensing vision language model and benchmark[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2307.15266v1. |
| [35] | LIU Fan, CHEN Delong, GUAN Z, et al. RemoteCLIP: a vision language foundation model for remote sensing[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2306.11029v4. |
| [36] | KUCKREJA K, DANISH M S, NASEER M, et al. GeoChat: grounded large vision-language model for remote sensing[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2311.15826v1. |
| [37] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. |
| [38] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [39] | CARON M, TOUVRON H, MISRA I, et al. Emerging properties in self-supervised vision transformers[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 9650-9660. |
| [40] | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2002.05709v2. |
| [41] | HE Kaiming, FAN Haoqi, WU Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 9729-9738. |
| [42] | TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2302.13971v1. |
| [43] | HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16000-16009. |
| [44] | BAO H, DONG L, PIAO S, et al. BEiT: BERT pre-training of image transformers[EB/OL]. [2024-01-05]. https://arxiv.org/pdf/2106.08254. |
| [45] | PARK N, KIM W, HEO B, et al. What do self-supervised vision transformers learn?[EB/OL]. [2024-01-05]. https://arxiv.org/pdf/2305.00729. |
| [46] | ZHOU Jinghao, WEI Chen, WANG Huiyu, et al. iBOT: image BERT pre-training with online tokenizer[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2111.07832v3. |
| [47] | OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: learning robust visual features without supervision[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2304.07193v2. |
| [48] | AYUSH K, UZKENT B, MENG Chenlin, et al. Geography-aware self-supervised learning[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 10181-10190. |
| [49] | AKIVA P, PURRI M, LEOTTA M. Self-supervised material and texture representation learning for remote sensing tasks[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 8203-8215. |
| [50] | WANYAN Xinye, SENEVIRATNE S, SHEN Shuchang, et al. DINO-MC: self-supervised contrastive learning for remote sensing imagery with multi-sized local crops[EB/OL]. [2024-01-05]. https://ar5iv.labs.arxiv.org/html/2303.06670. |
| [51] | ZHANG Hao, LI Feng, LIU Shilong, et al. DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2203.03605v4. |
| [52] | CHA K, SEO J, LEE T. A billion-scale foundation model for remote sensing images[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2304.05215v4. |
| [53] | WANG Yuelei, ZHANG Ting, ZHAO Liangjin, et al. RingMo-lite: a remote sensing multi-task lightweight network with CNN-transformer hybrid framework[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2309.09003v1. |
| [54] | WANG Di, ZHANG Qiming, XU Yufei, et al. Advancing plain vision transformer toward remote sensing foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5607315. |
| [55] | SUN Xian, WANG Peijin, LU Wanxuan, et al. RingMo: a remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:3194732. |
| [56] | REED C J, GUPTA R, LI S, et al. Scale-MAE: a scale-aware masked autoencoder for multiscale geospatial representation learning[C]//Proceedings of 2023 IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 4088-4099. |
| [57] | HONG D, ZHANG B, LI X, et al. SpectralGPT: spectral foundation modele[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2311.07113. |
| [58] | JAKUBIK J, ROY S, PHILLIPS C E, et al. Foundation models for generalist geospatial artificial intelligence[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2310.18660v2. |
| [59] | IRVIN J, TAO L, ZHOU J, et al. USat: a unified self-supervised encoder for multi-sensor satellite imagery[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2312.02199v1. |
| [60] | MENDIETA M, HAN Boran, SHI Xingjian, et al. Towards geospatial foundation models via continual pretraining[C]//Proceedings of 2023 IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 16806-16816. |
| [61] | TANG M, COZMA A L, GEORGIOU K, et al. Cross-scale MAE: a tale of multiscale exploitation in remote sensing[C]//Proceedings of the 37th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023. |
| [62] | ZHANG Mingming, LIU Qingjie, WANG Yunhong. CtxMIM: context-enhanced masked image modeling for remote sensing image understanding[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2310.00022v4. |
| [63] | YAO Fanglong, LU Wanxuan, YANG Heming, et al. RingMo-sense: remote sensing foundation model for spatiotemporal prediction via spatiotemporal evolution disentangling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:3316166. |
| [64] | FULLER A, MILLARD K, GREEN J R. CROMA: remote sensing representations with contrastive radar-optical masked autoencoders[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2311.00566. |
| [65] | WANG Yi, ALBRECHT C M, ALI BRAHAM N A, et al. Decoupling common and unique representations for multimodal self-supervised learning[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2309.05300v3. |
| [66] | TSENG G, CARTUYVELS R, ZVONKOV I, et al. Lightweight, pre-trained transformers for remote sensing timeseries[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2304.14065v4. |
| [67] | FENG Yingchao, WANG Peijin, DIAO Wenhui, et al. A self-supervised cross-modal remote sensing foundation model with multi-domain representation and cross-domain fusion[C]//Proceedings of 2023 IEEE International Geoscience and Remote Sensing Symposium. Pasadena: IEEE, 2023: 2239-2242. |
| [68] | ZHAO W X, ZHOU Kun, LI Junyi, et al. A survey of large language models[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2303.18223v14. |
| [69] | ROBERTS J, LÜDDECKE T, SHEIKH R, et al. Charting new territories: exploring the geographic and geospatial capabilities of multimodal LLMs[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2311.14656v3. |
| [70] | MALL U, PHOO C P, LIU M K, et al. Remote sensing vision-language foundation models without annotations via ground remote alignment[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2312.06960v1. |
| [71] | LI Yansheng, WANG Linlin, WANG Tingzhu, et al. STAR: a first-ever dataset and a large-scale benchmark for scene graph generation in large-size satellite imagery[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2406.09410v3. |
| [72] | LUO Junwei, PANG Zhen, ZHANG Yongjun, et al. SkySenseGPT: a fine-grained instruction tuning dataset and model for remote sensing vision-language understanding[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2406.10100v2. |
| [73] | CEPEDA V V, NAYAK G K, SHAH M. GeoCLIP: clip-inspired alignment between locations and images for effective worldwide geo-localization[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2309.16020. |
| [74] | MAI Gengchen, LAO Ni, HE Yutong, et al. CSP: self-supervised contrastive spatial pre-training for geospatial-visual representations[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2305.01118v2. |
| [75] | WOLTERS P, BASTANI F, KEMBHAVI A. Zooming out on zooming in: advancing super-resolution for remote sensing[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2311.18082v1. |
| [76] | KHANNA S, LIU P, ZHOU Linqi, et al. DiffusionSat: a generative foundation model for satellite imagery[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2312.03606v2. |
| [77] | ESPINOSA M, CROWLEY E J. Generate your own Scotland: satellite image generation conditioned on maps[EB/OL]. [2024-01-05]. https://arxiv.org/abs/2308.16648v1. |
| [78] |
李彦胜, 吴敏郎, 张永军. 知识图谱约束深度网络的高分辨率遥感影像场景分类[J]. 测绘学报, 2024, 53(4):677-688. DOI:.
doi: 10.11947/j.AGCS.2024.20230125 |
|
LI Yansheng, WU Minlang, ZHANG Yongjun. Knowledge graph-guided deep network for high-resolution remote sensing image scene classification[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(4):677-688. DOI:.
doi: 10.11947/j.AGCS.2024.20230125 |
|
| [79] | LI Yansheng, KONG Deyu, ZHANG Yongjun, et al. Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 179:145-158. |
| [80] | LI Yansheng, ZHU Zhihui, YU Jingang, et al. Learning deep cross-modal embedding networks for zero-shot remote sensing image scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(12):10590-10603. |
| [81] | LI Yansheng, ZHOU Yuhan, ZHANG Yongjun, et al. DKDFN: domain knowledge-guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 186:170-189. |
| [82] | LI Yansheng, OUYANG Song, ZHANG Yongjun. Combining deep learning and ontology reasoning for remote sensing image semantic segmentation[J]. Knowledge-Based Systems, 2022, 243:108469. |
| [83] | LIU Xiaojian, ZHANG Yongjun, ZOU Huimin, et al. Multi-source knowledge graph reasoning for ocean oil spill detection from satellite SAR images[J]. International Journal of Applied Earth Observation and Geoinformation, 2023, 116:103153. |
| [84] | 李彦胜, 张永军. 耦合知识图谱和深度学习的新一代遥感影像解译范式[J]. 武汉大学学报(信息科学版), 2022, 47(8):1176-1190. |
| LI Yansheng, ZHANG Yongjun. A new paradigm of remote sensing image interpretation by coupling knowledge graph and deep learning[J]. Geomatics and Information Science of Wuhan University, 2022, 47(8):1176-1190. | |
| [85] | 李彦胜, 武康, 欧阳松, 等. 地学知识图谱引导的遥感影像语义分割[J]. 遥感学报, 2024, 28(2):455-469. |
| LI Yansheng, WU Kang, OUYANG Song, et al. Geographic knowledge graph-guided remote sensing image semantic segmentation[J]. National Remote Sensing Bulletin, 2024, 28(2):455-469. | |
| [86] | CHEN Jun, CHEN Lijun, CHEN Fei, et al. Collaborative validation of GlobeLand30: methodology and practices[J]. Geo-spatial Information Science, 2021, 24(1):134-144. |
| [87] | GONG Peng, LIU Han, ZHANG Meinan, et al. Stable classification with limited sample: transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017[J]. Science Bulletin, 2019, 64(6):370-373. |
| [88] | ZHANG Lümin, RAO Anyi, AGRAWALA M. Adding conditional control to text-to-image diffusion models[C]//Proceedings of 2023 IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 3836-3847. |
| [89] | 龚健雅, 李彦胜. 定量遥感与机器学习能够融合吗?[J]. 地球科学, 2022, 47(10):3911-3912. |
| GONG Jianya, LI Yansheng. Can quantitative remote sensing and machine learning be integrated?[J]. Earth Science, 2022, 47(10):3911-3912. | |
| [90] | GOODCHILD M F. The validity and usefulness of laws in geographic information science and geography[J]. Annals of the Association of American Geographers, 2004, 94(2):300-303. |
| [91] |
张兵, 杨晓梅, 高连如, 等. 遥感大数据智能解译的地理学认知模型与方法[J]. 测绘学报, 2022, 51(7):1398-1415. DOI:.
doi: 10.11947/j.AGCS.2022.20220279 |
|
ZHANG Bing, YANG Xiaomei, GAO Lianru, et al. Geo-cognitive models and methods for intelligent interpretation of remotely sensed big data[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7):1398-1415. DOI:.
doi: 10.11947/j.AGCS.2022.20220279 |
| [1] | Jia LI, Jing LI, Haiyan LIU, Chuanwei LU, Xiaohui CHEN, Junnan LIU, Wen SHI. Trajectory prediction enhanced by geographic knowledge graph and multi-spatio temporal constraints [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(10): 2021-2033. |
| [2] | GONG Jianya, ZHANG Mi, HU Xiangyun, ZHANG Zhan, LI Yansheng, Jiang Liangcun. The design of deep learning framework and model for intelligent remote sensing [J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(4): 475-487. |
| [3] | SHEN Li, XU Zhu, LI Zhilin, LIU Wanzeng, CUI Bingliang. From geographic information service to geographic knowledge service: research issues and development roadmap [J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(9): 1194-1202. |
| [4] | GONG Jianya, XU Yue, HU Xiangyun, JIANG Liangcun, ZHANG Mi. Status analysis and research of sample database for intelligent interpretation of remote sensing image [J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8): 1013-1022. |
| [5] | JIANG Bingchuan, WAN Gang, XU Jian, LI Feng, WEN Huiqi. Geographic Knowledge Graph Building Extracted from Multi-sourced Heterogeneous Data [J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(8): 1051-1061. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||