

Acta Geodaetica et Cartographica Sinica ›› 2024, Vol. 53 ›› Issue (10): 1967-1980.doi: 10.11947/j.AGCS.2024.20240053.
• Remote Sensing Large Model • Previous Articles Next Articles
Qin YAN1,2,( ), Haiyan GU1,2, Yi YANG1,2(), Haitao LI1,2, Hengtong SHEN1,2, Shiqi LIU1,2
), Haiyan GU1,2, Yi YANG1,2(), Haitao LI1,2, Hengtong SHEN1,2, Shiqi LIU1,2
Received:2024-01-31
Online:2024-11-26
Published:2024-11-26
Contact:
Yi YANG
E-mail:yanqin@casm.ac.cn;yangyi@casm.ac.cn
About author:YAN Qin (1968—), female, PhD, researcher, majors in natural resource surveying and monitoring, territorial spatial planning and land use control, and aerospace remote sensing mapping. E-mail: yanqin@casm.ac.cn
Supported by:CLC Number:
Qin YAN, Haiyan GU, Yi YANG, Haitao LI, Hengtong SHEN, Shiqi LIU. Research progress and trend of intelligent remote sensing large model[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(10): 1967-1980.
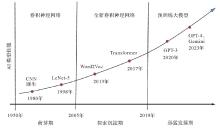
Fig.1
The development history of AI models"
Tab.1
Domestic and international remote sensing large model platform"
| 名称 | 机构 | 技术特点 |
|---|---|---|
| GeoForge | Ageospatial | 基于大语言模型(GeoLLMs)开发的地理空间分析平台,可以实现空间数据处理和遥感数据智能分析 |
| ArcGIS pro | ESRI | 提供了大量遥感AI算法和在大规模数据上训练的预训练模型,可以完成要素提取、变化检测和时间序列分析等业务 |
| Segment-geospatial | UniversityTennessee | 基于视觉大模型Segment Anything开发的工具库,可以简化用户利用SAM进行遥感影像分割和地理空间数据分析的过程 |
| AI Earth | 阿里达摩院 | 遥感AI算法工具累计达16类,公开数据集规模达70余类 |
| SkySense | 武汉大学、蚂蚁集团 | 10亿参数量的多模态遥感基础模型,从单模态到多模态、静态到时序、分类到定位,灵活适应各种下游任务,具有显著泛化能力 |
| 空天·灵眸 | 空天院、华为 | 训练数据集包含了200多万幅遥感影像,数据集中包含了1亿多具有任意角度分布的目标实例 |
| 天权大模型 | 航天宏图 | 立足开源大模型基础结构,融合PIE-Engine AI 43类语义分割及变化检测模型,适配10余类重点目标检测识别业务 |
| SenseEarth 3.0 | 商汤科技 | 具有3.5亿规模的遥感大模型,涵盖25个语义分割模型,其中地物分割能力在百万级图斑验证集上的平均精度超过80% |
| 长城大模型 | 数慧时空 | 综合自然资源领域文本、图像、视频等多种模态的数据,通过学习能够有效对自然资源业务进行理解和生成 |
| 星图地球智脑 | 中科星图 | 提供地球数据智能处理能力、地球信息智能感知能力、地球场景智能重建能力等 |
| 珞珈灵感 | 武汉大学 | 遥感智能解译训推一体平台,13亿参数多模态大模型,集成了场景分类、目标检测、变化检测等典型下游任务模型库 |
Tab.2
Multimodal dataset"
| 数据集名称 | 发布年份 | 数据类型 | 数据量 | 描述 |
|---|---|---|---|---|
| MillionAID[ | 2021 | Google Earth影像 | 百万张实例 | 一个用于遥感场景分类的大型基准数据集,包含了广泛的语义类别,具有空间分辨率高、规模大、分布全球等优势 |
| Satlas[ | 2022 | 中分辨率Sentinel-2影像、高分辨率NAIP影像 | 2.9亿个标签 | 覆盖场景广、数据规模大 |
| RSICap[ | 2023 | 遥感图像、文本描述数据 | 2585个高质量字幕 | 用于遥感图像精细描述的数据集,包括图像场景描述,(如住宅区、机场或农田)以及对象信息(如颜色、形状、数量、绝对位置等) |
| RSIEval[ | 2023 | 人工注释的字幕-视觉问答 | 31.8万个图像指令对 | 图像-问答三元组,可以全面评估VLMs在遥感环境下的性能 |
| SpaceNet[ | 2018 | WorldView-2/3等光学影像 | 1500万张影像 | 全球第一个公开发布的高分辨率大型遥感数据集,用于目标检测、语义分割和道路网络映射等任务 |
| SkyScript[ | 2023 | 遥感图像-文本描述数据 | 260万张图像文本对 | 一个用于遥感的大型且语义多样化的图像文本数据集,通过GEE和OpenStreetMap获取,全球覆盖,语义信息跨越对象类别、子类别和详细属性 |
| fMoW[ | 2018 | 多种传感器的时间序列影像、多光谱影像 | 70万张影像 | 一个用于多种遥感任务的大型数据集,旨在激发机器学习模型的开发,使模型能够从卫星图像的时间序列中预测建筑物的功能用途和土地利用 |
| SkySense[ | 2024 | 高分辨率WorldView-3/4影像,中分辨率Sentinel-1/2影像 | 2150万个训练样本 | 涵盖了不同分辨率、光谱和成像机制的各种情景,每个样本包括具有纹理细节的静态HSROI,包含时态和多光谱数据的TMsI,在云覆盖下提供散射极化的标准校准TSARI,以及用于地理上下文建模的元数据 |
| BigEarthNet-MM[ | 2021 | Sentinel SAR和多光谱数据 | 59万个多模态样本 | 支持多模态多标签遥感图像检索和分类研究 |
| SEN12MS[ | 2019 | Sentinel-1/2,MODIS传感器的SAR和多光谱数据 | 18万个多模态样本 | 由全球42个城市群的数据组成,能够应用于最先进的机器学习方法,以应对城市化和气候变化等全球挑战 |
| RingMo[ | 2023 | Sentinel-1/2,Google Earth,WorldView,高分二号等多种光学遥感影像 | 200万张影像 | 数据集图像数量众多、分辨率变化范围大,更适合遥感领域下游任务 |
Fig.2
Data augmentation methods"
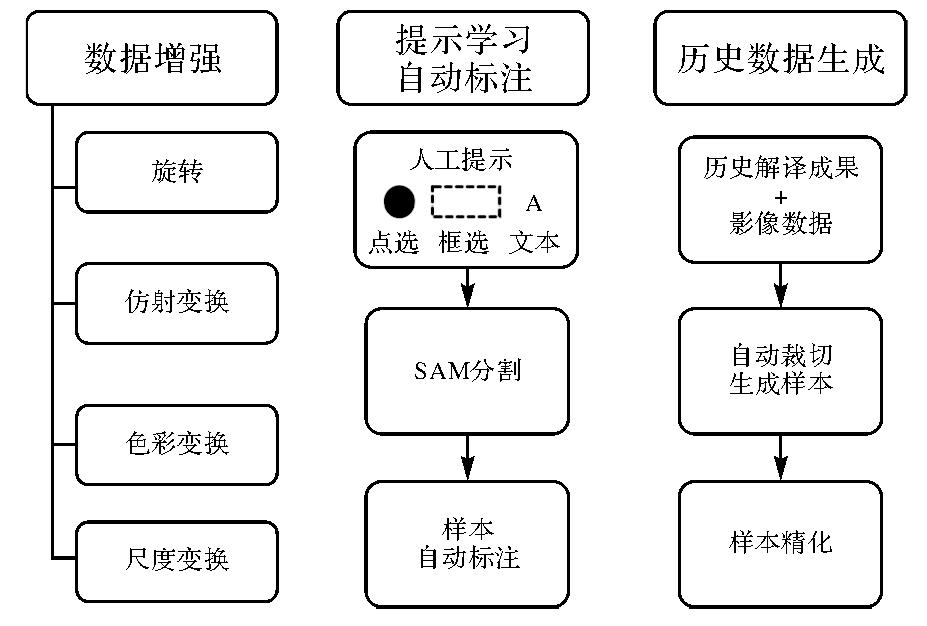
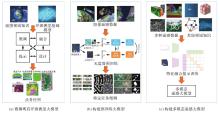
Fig.3
Construction methods of remote sensing large models"
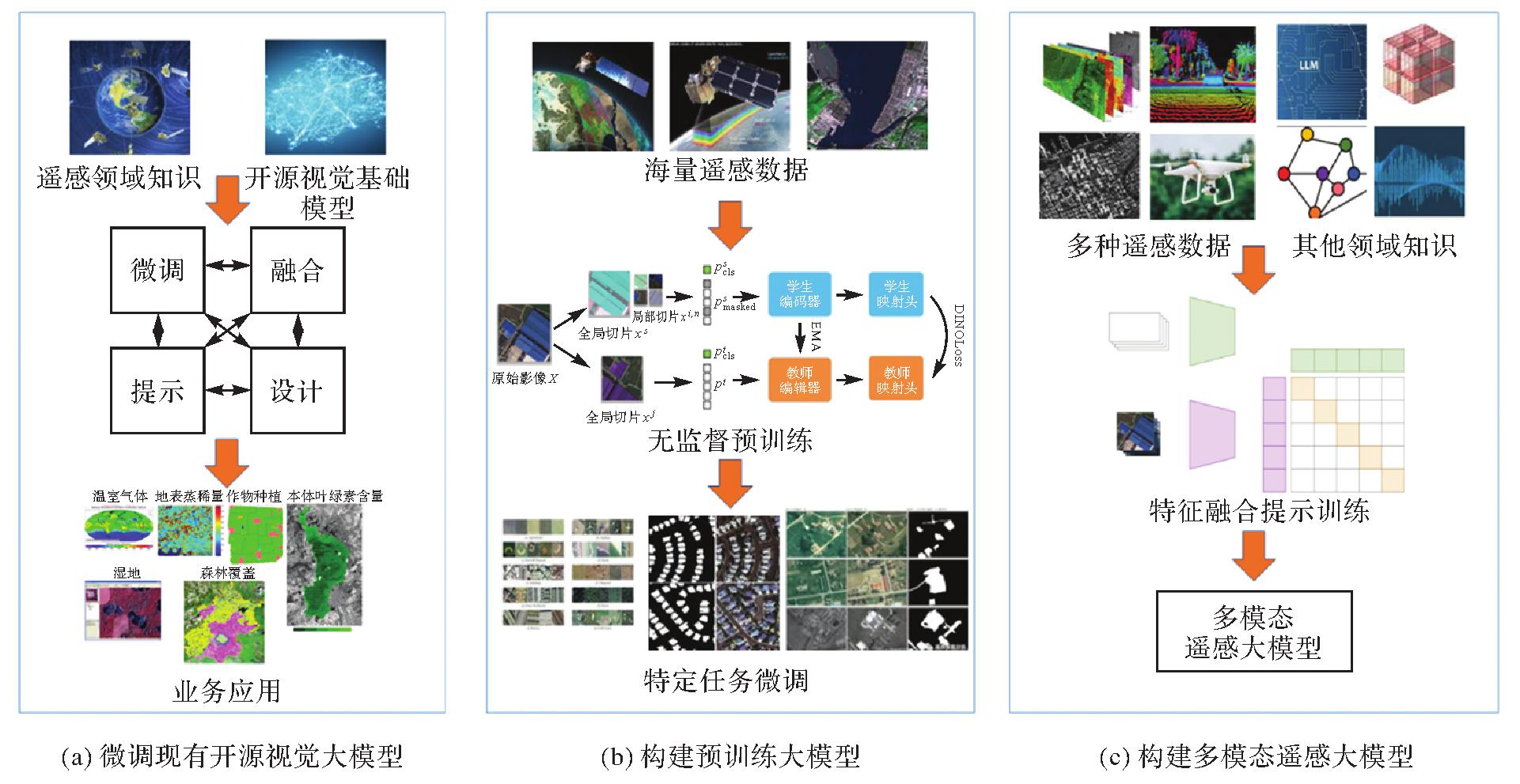
Tab.3
Typical remote sensing large models"
| 遥感大模型 | 代表模型 | 特点 | |
|---|---|---|---|
| 遥感视觉大模型 | RS-BYOL[ | 使用无标签光学影像作为训练数据,通过自监督学习预训练具有丰富语义的视觉特征,但需要微调才能实际应用 | |
| 遥感生成大模型 | DiffusionSat[ | 使用自监督学习,可以生成逼真的遥感影像,可以解决多种生成任务 | |
| 遥感多模态大模型 | 视觉+语言 | 紫东太初、MCRN[ | 将文本与遥感视觉特征对齐,具有无缝下游应用的潜力,但数据收集需要文本与遥感图像对应,成本较高 |
| 视觉+位置 | CSP[ | 可从公开可用的遥感卫星图像结合其附带的位置信息中学习特征表示 | |
| 视觉+音频 | SoundingEarth[ | 同时利用视觉和听觉理解应用场景 | |
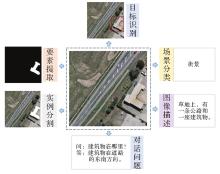
Fig.4
Example of multitask processing"
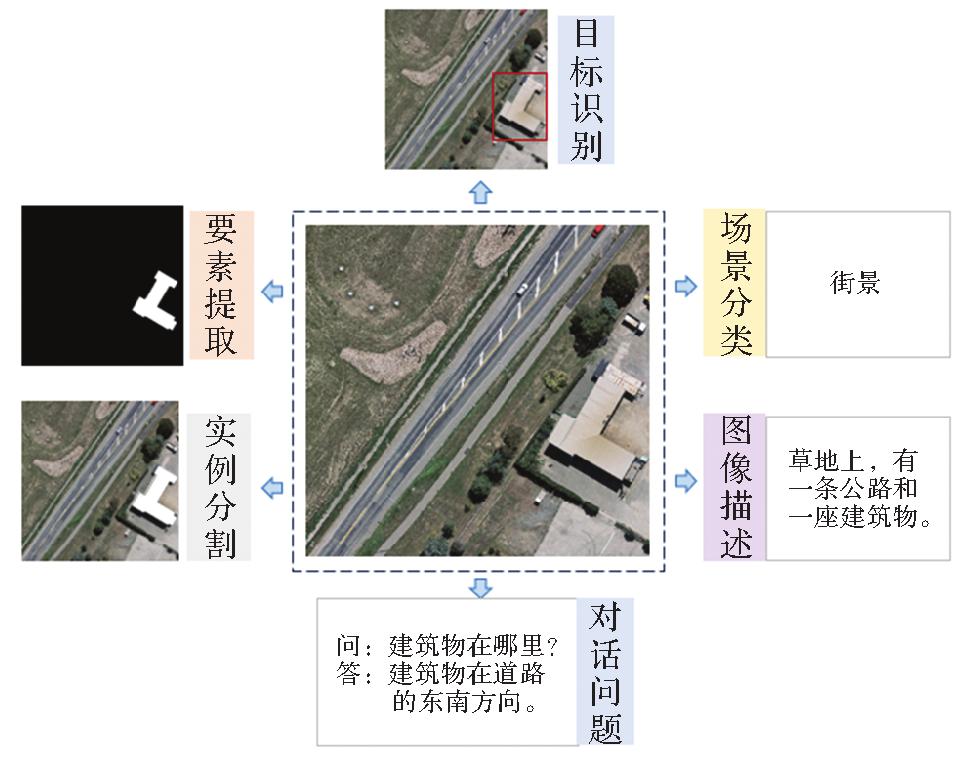

Fig.5
Multimodal remote sensing large model"
Fig.6
Construction methods of interpretable remote sensing large models"
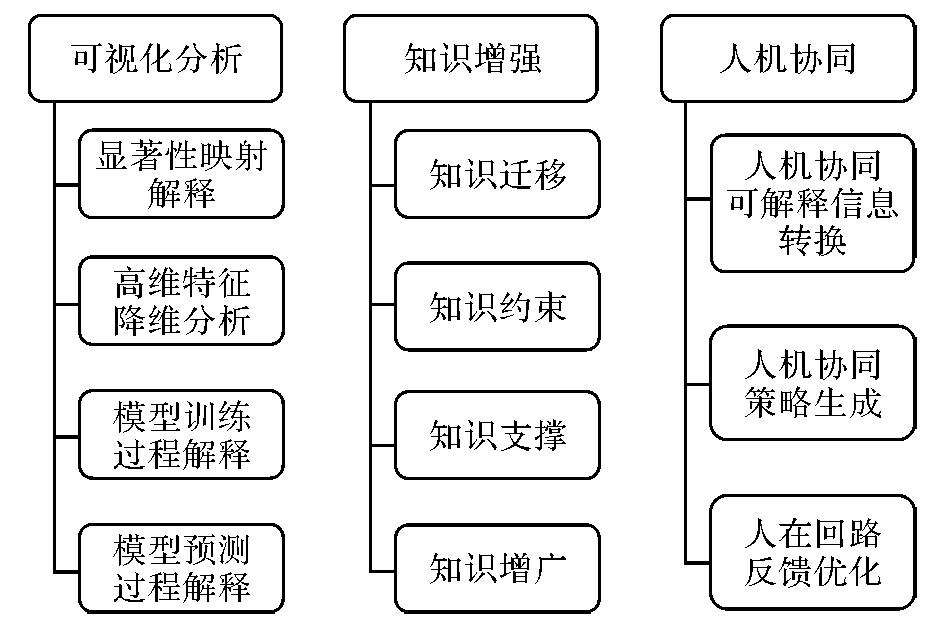
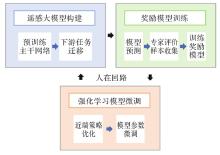
Fig.7
Human feedback reinforcement learning process"
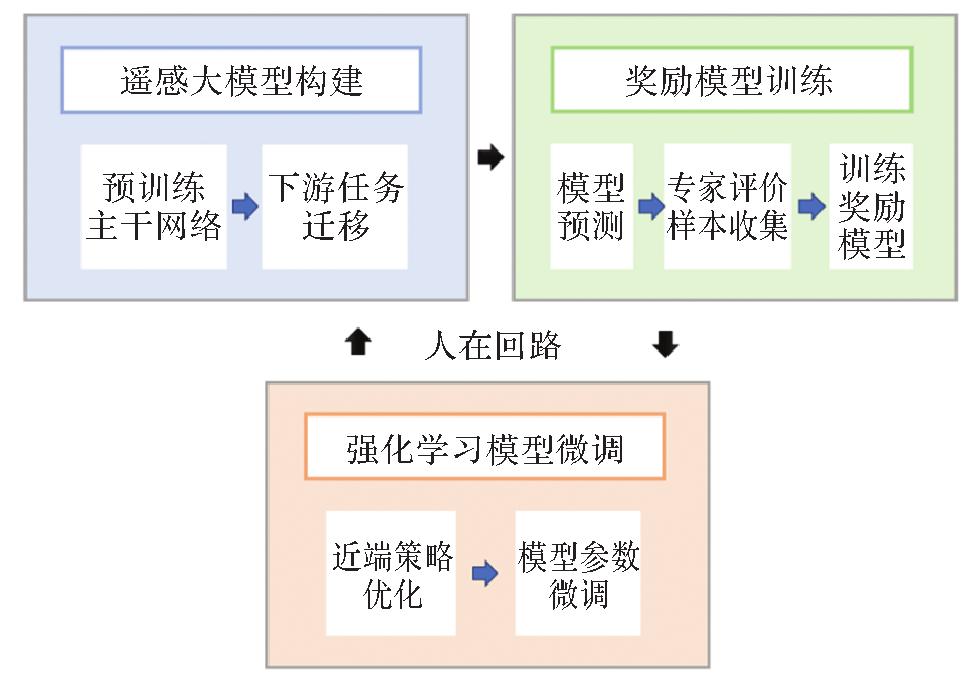
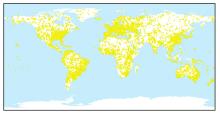
Fig.8
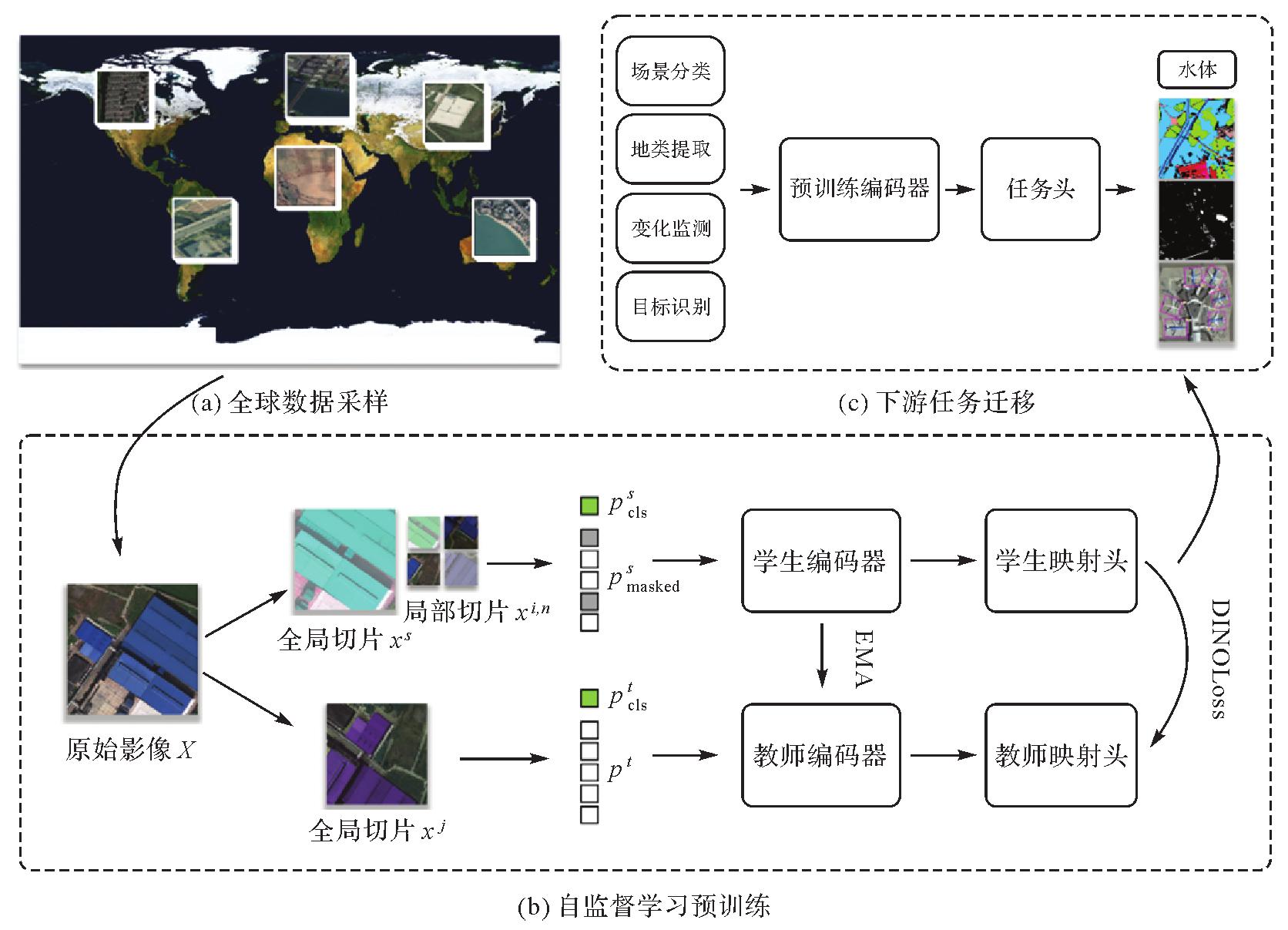
Global sample collection"
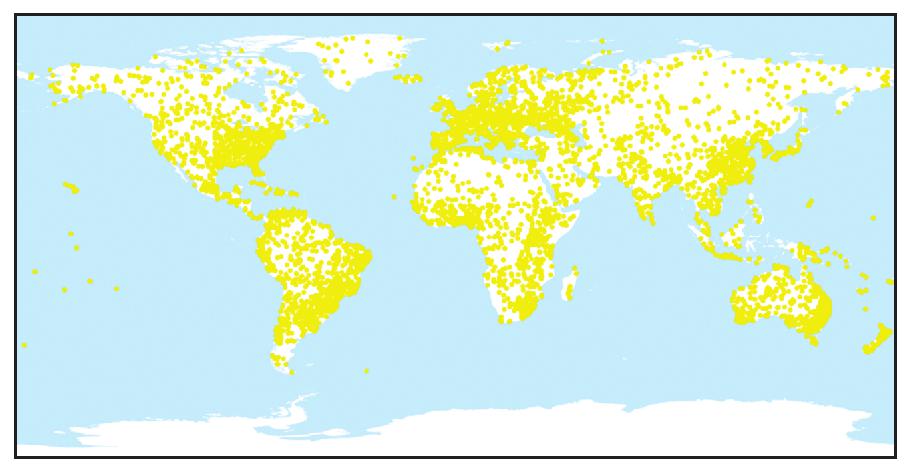
Fig.9
Self-supervised model construction process"
Tab.4
Evaluation results for scene classification"
| 数据集 | 类别数 | 训练集 | 验证集 | Top-1准确率/(%) | Top-5准确率/(%) |
|---|---|---|---|---|---|
| AID | 30 | 7000 | 3000 | 89.2 | 98.8 |
| SIRI-WHU | 12 | 1680 | 720 | 94.7 | 99.9 |

Fig.10
Results of feature extraction"

Tab.5
Evaluation results for feature extraction"
| 数据集 | 训练集 | 验证集 | 准确率/(%) | 精确率/(%) | 回报率/(%) | 交并比/(%) | F1值/(%) |
|---|---|---|---|---|---|---|---|
| GF1_WHU_CLOUD | 7000 | 3000 | 96.6 | 94.6 | 95.1 | 90.4 | 94.9 |
| Potsdam | 1680 | 720 | 94.5 | 92.9 | 92.7 | 86.8 | 92.8 |
| GID | 22 048 | 9450 | 98.8 | 95.4 | 93.7 | 90.0 | 94.5 |
Tab.6
Evaluation results for change detection"
| 数据集 | 训练集 | 验证集 | 准确率/(%) | 精确率/(%) | 回报率/(%) | 交并比/(%) | F1值/(%) |
|---|---|---|---|---|---|---|---|
| LEVIR-CD | 1780 | 256 | 97.9 | 90.0 | 82.2 | 77.3 | 85.6 |

Fig.11
Results of change detection"

| [1] | JIAO Licheng, HUANG Zhongjian, LU Xiaoqiang, et al. Brain-inspired remote sensing foundation models and open problems: a comprehensive survey[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023, 16:10084-10120. |
| [2] | DIAS P, POTNIS A, GUGGILAM S, et al. An agenda for multimodal foundation models for earth observation[C]//Proceedings of 2023 IEEE International Geoscience and Remote Sensing Symposium. Pasadena: IEEE, 2023: 1237-1240. |
| [3] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324. |
| [4] | MIKOLOV T, CHEN Kai, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1301.3781v3. |
| [5] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1706.03762. |
| [6] | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]//Proceedings of the 34th International Confe-rence on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020. |
| [7] | OpenAI. GPT-4 technical report[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2303.08774. |
| [8] | ANIL R, BORGEAUD S, WU Yonghui, et al. Gemini: a family of highly capable multimodal models[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2312.11805v4. |
| [9] | BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2108.07258v3. |
| [10] | TAO Chao, QI Ji, GUO Mingning, et al. Self-supervised remote sensing feature learning: learning paradigms, challenges, and future works[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5610426. |
| [11] | HONG Danfeng, ZHANG Bing, LI Xuyang, et al. SpectralGPT: spectral remote sensing foundation model[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2311.07113v3. |
| [12] | 张良培, 张乐飞, 袁强强. 遥感大模型:进展与前瞻[J]. 武汉大学学报(信息科学版), 2023, 48(10):1574-1581. |
| ZHANG Liangpei, ZHANG Lefei, YUAN Qiangqiang. Large remote sensing model: progress and prospects[J]. Geomatics and Information Science of Wuhan University, 2023, 48(10):1574-1581. | |
| [13] | LI Xiang, WEN Congcong, HU Yuan, et al. Vision-language models in remote sensing: current progress and future trends[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2305.13456. |
| [14] | CHEN M, RADFORD A, CHILD R, et al. Generative pretraining from pixels[C]//Proceedings of the 37th International Conference on Machine Learning. [S.l.]: JMLR, 2020: 1691-1703. |
| [15] | DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1810.04805. |
| [16] | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2304.02643v1. |
| [17] | 乐鹏, 刘瑞祥, 上官博屹, 等. 地理人工智能样本:模型、质量与服务[J]. 武汉大学学报(信息科学版), 2023, 48(10):1616-1631. |
| YUE Peng, LIU Ruixiang, SHANGGUAN Boyi, et al. GeoAI training data: model, quality, and services[J]. Geomatics and Information Science of Wuhan University, 2023, 48(10):1616-1631. | |
| [18] | 付琨, 卢宛萱, 刘小煜, 等. 遥感基础模型发展综述与未来设想[J]. 遥感学报, 2023, 28(7):1667-1680. |
| FU Kun, LU Wanxuan, LIU Xiaoyu, et al. A comprehensive survey and assumption of remote sensing foundation modal[J]. National Remote Sensing Bulletin, 2023, 28(7):1667-1680. | |
| [19] | LONG Yang, XIA Guisong, LI Shengyang, et al. On creating benchmark dataset for aerial image interpretation: reviews, guidances, and million-AID[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14:4205-4230. |
| [20] | BASTANI F, WOLTERS P, GUPTA R, et al. SatlasPretrain: a large-scale dataset for remote sensing image understanding[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2211.15660v3. |
| [21] | HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: a remote sensing vision language model and benchmark[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2307.15266v1. |
| [22] | KUCKREJA K, DANISH M S, NASEER M, et al. GeoChat: grounded large vision-language model for remote sensing[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2311.15826v1. |
| [23] | VAN ETTEN A, LINDENBAUM D, BACASTOW T M. SpaceNet: a remote sensing dataset and challenge series[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1807.01232v3. |
| [24] | WANG Zhecheng, PRABHA R, HUANG Tianyuan, et al. SkyScript: a large and semantically diverse vision-language dataset for remote sensing[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2312.12856v1. |
| [25] | CHRISTIE G, FENDLEY N, WILSON J, et al. Functional map of the world[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018. |
| [26] | GUO Xin, LAO Jiangwei, DANG Bo. SkySense: a multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2312.10115. |
| [27] | SUMBUL G, DE WALL A, KREUZIGER T, et al. BigEarthNet-MM: a large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval[J]. IEEE Geoscience and Remote Sensing Magazine, 2021, 9(3):174-180. |
| [28] | SCHMITT M, HUGHES L H, QIU C, et al. SEN12MS—a curated dataset of georeferenced multi-spectral Sentinel-1/2 imagery for deep learning and data fusion[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2019, Ⅳ-2/W7:153-160. |
| [29] | SUN Xian, WANG Peijin, LU Wanxuan, et al. RingMo: a remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:3194732. |
| [30] | WU Qiusheng, OSCO L P. Samgeo: a Python package for segmenting geospatial datawith the segment anything model (SAM)[J]. Journal of Open Source Software, 2023, 8(89):5663. |
| [31] | WANG Di, ZHANG Jing, DU Bo, et al. SAMRS: scaling-up remote sensing segmentation dataset with segment anything model[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2305.02034v4. |
| [32] | CHEN Keyan, LIU Chenyang, CHEN Hao, et al. RSPrompter: learning to prompt for remote sensing instance segmentation based on visual foundation model[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2306.16269. |
| [33] | HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2111.06377v3. |
| [34] | GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent: a new approach to self-supervised Learning[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2006.07733v3. |
| [35] | CHEN Xinlei, XIE Saining, HE Kaiming. An empirical study of training self-supervised vision transformers[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2104.02057v4. |
| [36] | CARON M, TOUVRON H, MISRA I, et al. Emerging properties in self-supervised vision transformers[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2104.14294v2. |
| [37] | 向鹏. 周成虎院士:从遥感大数据到遥感大模型[J]. 高科技与产业化, 2023, 29(9):16-19. |
| XIANG Peng. Academician ZHOU Chenghu: from remote sensing big data to remote sensing big model[J]. High-Technology & Commercialization, 2023, 29(9):16-19. | |
| [38] | 杨必胜, 陈一平, 邹勤. 从大模型看测绘时空信息智能处理的机遇和挑战[J]. 武汉大学学报(信息科学版), 2023, 48(11):1756-1768. |
| YANG Bisheng, CHEN Yiping, ZOU Qin. Opportunities and challenges of spatiotemporal information intelligent processing of sur-veying and mapping in the era of large models[J]. Geomatics and Information Science of Wuhan University, 2023, 48(11):1756-1768. | |
| [39] | 罗锦钊, 孙玉龙, 钱增志, 等. 人工智能大模型综述及展望[J]. 无线电工程, 2023, 53(11):2461-2472. |
| LUO Jinzhao, SUN Yulong, QIAN Zengzhi, et al. Overview and prospect of artificial intelligence large models[J]. Radio Engineering, 2023, 53(11):2461-2472. | |
| [40] | LIU Fan, CHEN Delong, GUAN Zhangqingyun, et al. RemoteCLIP: a vision language foundation model for remote sensing[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2306.11029v4. |
| [41] | JAIN P, SCHOEN-PHELAN B, ROSS R. Self-supervised learning for invariant representations from multi-spectral and SAR images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15:7797-7808. |
| [42] | ZHAO Dong, YANG Ruizhi, WANG Shuang, et al. Semantic connectivity-driven pseudo-labeling for cross-domain segmentation[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2312.06331v1. |
| [43] | CONG Yezhen, KHANNA S, MENG Chenlin, et al. SatMAE: pre-training transformers for temporal and multi-spectral satellite imagery[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2207.08051v3. |
| [44] | WANG Di, ZHANG Qiming, XU Yufei, et al. Advancing plain vision transformer toward remote sensing foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5607315. |
| [45] | WANG Di, ZHANG Jing, DU Bo, et al. An empirical study of remote sensing pretraining[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5608020. |
| [46] | REED C J, GUPTA R, LI Shufan, et al. Scale-MAE: a scale-aware masked autoencoder for multiscale geospatial representation learning[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2212.14532v4. |
| [47] | WANYAN Xinye, SENEVIRATNE S, SHEN Shuchang, et al. DINO-MC: self-supervised contrastive learning for remote sensing imagery with multi-sized local crops[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2303.06670. |
| [48] | KHANNA S, LIU P, ZHOU Linqi, et al. DiffusionSat: a generative foundation model for satellite imagery[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2312.03606v2. |
| [49] | YUAN Zhiqiang, ZHANG Wenkai, TIAN Changyuan, et al. MCRN: a multi-source cross-modal retrieval network for remote sensing[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 115:103071. |
| [50] | MAI Gengchen, LAO Ni, HE Yutong, et al. CSP: self-supervised contrastive spatial pre-training for geospatial-visual representations[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2305.01118v2. |
| [51] | CEPEDA V V, NAYAK G K, SHAH M. GeoCLIP: clip-inspired alignment between locations and images for effective worldwide geo-localization[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2309.16020. |
| [52] | KLEMMER K, ROLF E, ROBINSON C, et al. SatCLIP: global, general-purpose location embeddings with satellite imagery[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2311.17179v3. |
| [53] | HEIDLER K, MOU Lichao, HU Di, et al. Self-supervised audiovisual representation learning for remote sensing data[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2108.00688v2. |
| [54] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2103.00020. |
| [55] | KIM W, SON B, KIM I. ViLT: vision-and-language transformer without convolution or region supervision[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2102.03334. |
| [56] | BAO Hangbo, WANG Wenhui, DONG Li, et al. VLMo: unified vision-language pre-training with mixture-of-modality-experts[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2111.02358v2. |
| [57] | SU Weijie, ZHU Xizhou, CAO Yue, et al. VL-BERT: pre-training of generic visual-linguistic representations[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1908.08530v4. |
| [58] | CHEN Y C, LI Linjie, YU Licheng, et al. UNITER: universal image-text representation learning[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1909.11740. |
| [59] | LU Jiasen, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1908.02265v1. |
| [60] | JIA Chao, YANG Yinfei, XIA Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2102.05918v2. |
| [61] | AKBARI H, YUAN Liangzhe, QIAN Rui, et al. VATT: transformers for multimodal self-supervised learning from raw video, audio and text[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2104.11178v3. |
| [62] | RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical text-conditional image generation with CLIP latents[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2204.06125v1. |
| [63] | DING Ming, YANG Zhuoyi, HONG Wenyi, et al. CogView: mastering text-to-image generation via transformers[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2105.13290v3. |
| [64] | HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33:6840-6851. |
| [65] | ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2112.10752v2. |
| [66] | WANG Xiao, CHEN Guangyao, QIAN Guangwu, et al. Large-scale multi-modal pre-trained models: a comprehensive survey[J]. Machine Intelligence Research, 2023, 20(4):447-482. |
| [67] | 付琨, 王佩瑾, 冯瑛超, 等. 遥感跨模态智能解译:模型、数据与应用[J]. 中国科学:信息科学, 2023, 53(8):1529-1559. |
| FU Kun, WANG Peijin, FENG Yingchao, et al. Cross-modal remote sensing intelligent interpretation: method, data, and application[J]. Scientia Sinica (Informationis), 2023, 53(8):1529-1559. | |
| [68] | ZHU Deyao, CHEN Jun, SHEN Xiaoqian, et al. MiniGPT-4: enhancing vision-language understanding with advanced large language models[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2304.10592v2. |
| [69] | YE Qinghao, XU Haiyang, XU Guohai, et al. mPLUG-Owl: modularization empowers large language models with multimodality[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2304.14178v3. |
| [70] | DRIESS D, XIA F, SAJJADI M S M, et al. PaLM-E: an embodied multimodal language model[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2303.03378. |
| [71] | ZHOU Bolei, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2921-2929. |
| [72] | SHRIKUMAR A, GREENSIDE P, KUNDAJE A. Learning important features through propagating activation differences[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1704.02685v2. |
| [73] | CHEN Jiaoyan, LÉCUÉ F, PAN J Z, et al. Knowledge graph embeddings for dealing with concept drift in machine learning[J]. Journal of Web Semantics, 2021, 67:100625. |
| [74] |
张继贤, 李海涛, 顾海燕, 等. 人机协同的自然资源要素智能提取方法[J]. 测绘学报, 2021, 50(8):1023-1032. DOI:.
doi: 10.11947/j.AGCS.2021.20210102 |
|
ZHANG Jixian, LI Haitao, GU Haiyan, et al. Study on man-machine collaborative intelligent extraction for natural resource features[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8):1023-1032. DOI:.
doi: 10.11947/j.AGCS.2021.20210102 |
|
| [75] | 张继贤, 顾海燕, 杨懿, 等. 高分辨率遥感影像智能解译研究进展与趋势[J]. 遥感学报, 2021, 25(11):2198-2210. |
| ZHANG Jixian, GU Haiyan, YANG Yi, et al. Research progress and trend of high-resolution remote sensing imagery intelligent interpretation[J]. National Remote Sensing Bulletin, 2021, 25(11):2198-2210. | |
| [76] |
张继贤, 顾海燕, 杨懿, 等. 自然资源要素智能解译研究进展与方向[J]. 测绘学报, 2022, 51(7):1606-1617. DOI:.
doi: 10.11947/j.AGCS.2022.20220109 |
|
ZHANG Jixian, GU Haiyan, YANG Yi, et al. Research progress and trend of intelligent interpretation for natural resources features[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7):1606-1617. DOI:.
doi: 10.11947/j.AGCS.2022.20220109 |
|
| [77] |
张广运, 张荣庭, 戴琼海, 等. 测绘地理信息与人工智能2.0融合发展的方向[J]. 测绘学报, 2021, 50(8):1096-1108. DOI:.
doi: 10.11947/j.AGCS.2021.20210200 |
|
ZHANG Guangyun, ZHANG Rongting, DAI Qionghai, et al. The direction of integration surveying and mapping geographic information and artificial intelligence 2.0[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8):1096-1108. DOI:.
doi: 10.11947/j.AGCS.2021.20210200 |
|
| [78] | 张俊, 李灵犀, 林懿伦, 等. 虚实系统互驱的混合增强智能开放创新平台的架构与方案[J]. 智能科学与技术学报, 2019, 1(4):379-391. |
| ZHANG Jun, LI Lingxi, LIN Yilun, et al. The architecture and scheme of the hybrid-augmented intelligence open innovation platform based on the virtual and real systems[J]. Chinese Journal of Intelligent Science and Technology, 2019, 1(4):379-391. | |
| [79] | LI Zihao, YANG Zhuoran, WANG Mengdi. Reinforcement learning with human feedback: learning dynamic choices via pessimism[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2305.18438v3. |
| [80] | WIRTH C, AKROUR R, NEUMANN G, et al. A survey of preference-based reinforcement learning methods[J]. Journal of Machine Learning Research, 2017, 18(1):4945-4990. |
| [81] | OpenAI. ChatGPT: optimizing language models for dialogue[EB/OL]. [2024-01-29]. https://blog.cloudhq.net/openais-chatgpt-optimizing-language-models-for-dialogue/. |
| [82] | LEE K, LIU Hao, RYU M, et al. Aligning text-to-image models using human feedback[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2302.12192v1. |
| [83] | METCALF K, SARABIA M, THEOBALD B J. Rewards encoding environment dynamics improves preference-based reinforcement learning[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2211.06527. |
| [84] | RUSSO D, VAN ROY B. Eluder dimension and the sample complexity of optimistic exploration[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2013: 2256-2264. |
| [85] | CHRISTIANO P, LEIKE J, BROWN T B, et al. Deep reinforcement learning from human preferences[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1706.03741v4. |
| [86] | IBARZ B, LEIKE J, POHLEN T, et al. Reward learning from human preferences and demonstrations in Atari[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1811.06521v1. |
| [87] | LEIKE J, KRUEGER D, EVERITT T, et al. Scalable agent alignment via reward modeling: a research direction[EB/OL]. [2024-01-29]. https://arxiv.org/abs/1811.07871v1. |
| [88] | OUYANG Long, WU J, XU Jiang, et al. Training language models to follow instructions with human feedback[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2203.02155v1. |
| [89] | 赵朝阳, 朱贵波, 王金桥. ChatGPT给语言大模型带来的启示和多模态大模型新的发展思路[J]. 数据分析与知识发现, 2023, 7(3):26-35. |
| ZHAO ChaoYang, ZHU Guibo, WANG Jinqiao. The inspiration brought by ChatGPT to LLM and the new development ideas of multi-modal large model[J]. Data Analysis and Knowledge Discovery, 2023, 7(3):26-35. | |
| [90] | OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: learning robust visual features without supervision[EB/OL]. [2024-01-29]. https://arxiv.org/abs/2304.07193v2. |
| [91] | GOU Jianping, YU Baosheng, MAYBANK S J, et al. Knowledge distillation: a survey[J]. International Journal of Computer Vision, 2021, 129(6):1789-1819. |
| [92] | 燕琴, 刘纪平, 董春, 等. 地理空间视角下自然资源认知探讨[J]. 测绘科学, 2022, 47(8):9-17. |
| YAN Qin, LIU Jiping, DONG Chun, et al. Natural resources cognition from the perspective of geographic space[J]. Science of Sur-veying and Mapping, 2022, 47(8):9-17. |
| [1] | Peng LI, Jiahan ZHANG, Zhihan WANG, Houjie WANG, Zhenhong LI. A review of intertidal topography reconstruction methods: current status, challenges and trends [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(4): 571-587. |
| [2] | Jiayao WANG, Lin CHEN, Shiyuan CHENG, Lijun WANG, Siqi XIONG. Artificial intelligence empowering the digital-intelligent transformation of cartographic science [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(3): 381-389. |
| [3] | Shaohua WANG, Haojian LIANG, Cheng SU, Dachuan XU, Liang ZHOU, Kun QIN. Advances and prospects in urban facility allocation optimization through coupling spatio-temporal big data and artificial intelligence [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(2): 222-235. |
| [4] | Zhuang SUN, Po LIU, Liang ZHAI, Yu HE, Zutao ZHANG. A self-supervised matching method for polygonal geographic entity based on a three-branch attention network [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(1): 169-180. |
| [5] | Jixian ZHANG, Haiyan GU, Huan NI, Haitao LI, Yi YANG, Shaopeng DING, Songman SUI. Deep learning methods for remote sensing intelligent change detection: evolution and development [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1347-1370. |
| [6] | Wenjian GAN, Yang ZHOU, Xiaofei HU, Luying ZHAO, Gaoshuang HUANG, Mingbo HOU. Combining projective transform and road segmentation for street view-satellite images cross-view geo-localization [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1489-1500. |
| [7] | Yiming ZHAO, Kelin HU, Kelong TU, Yaxian QING, Chao YANG, Kunlun QI, Huayi WU. Multi-label scene classification method based on fusion of SAR and optical remote sensing images [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 911-923. |
| [8] | Qingdong WANG, Tengfei WANG, Li ZHANG. Cross-modal contrastive masked autoencoder pre-training for 3D real-scene point cloud [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(4): 675-687. |
| [9] | Xiaohua TONG, Rong HUANG, Jiarui CAO, Chen LIU, Rong WANG, Yusheng XU, Zhen YE, Yanmin JIN, Shijie LIU, Sicong LIU, Yongjiu FENG, Huan XIE. Intelligent methods for 3D terrain reconstruction of the Moon and near-Earth planets: a review of current advances and future perspectives [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(11): 1917-1933. |
| [10] | Haoyu WU, Qing ZHU, Yulin DING, Liu BAO, Li LIU. High-precision digital twin modeling of tunnel surrounding rock driven by data model knowledge collaboration [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(10): 1893-1906. |
| [11] | Jialing LI, Ji QI, Weipeng LU, Chao TAO. Self-supervised learning based urban functional zone classification by integrating optical remote sensing image-OSM data [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(1): 154-164. |
| [12] | Xiaogang NING, Hanchao ZHANG, Ruiqian ZHANG. Practical framework and methodology for high-performance intelligent invariant detection in remote sensing imagery [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(6): 1098-1112. |
| [13] | Zhanlong CHEN, Xiechun LU, Yongyang XU. A building aggregation method based on deep clustering of graph vertices [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(4): 736-749. |
| [14] | XUE Zhixiang, YU Xuchu, LIU Jingzheng, YANG Guopeng, LIU Bing, YU Anzhu, ZHOU Jianan, JIN Shanghong. A self-supervised pre-training scheme for multi-source heterogeneous remote sensing image land cover classification [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(3): 512-525. |
| [15] | CAO Fanzhi, SHI Tianxin, HAN Kaiyang, WANG Pu, AN Wei. Log-Gabor filter-based high-precision multi-modal remote sensing image matching [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(3): 526-536. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||