

Acta Geodaetica et Cartographica Sinica ›› 2024, Vol. 53 ›› Issue (10): 1955-1966.doi: 10.11947/j.AGCS.2024.20240068.
• Remote Sensing Large Model • Previous Articles Next Articles
Mi WANG1,( ), Xu CHENG1(), Jun PAN1, Yingdong PI1, Jing XIAO2
), Xu CHENG1(), Jun PAN1, Yingdong PI1, Jing XIAO2
Received:2024-02-18
Online:2024-11-26
Published:2024-11-26
Contact:
Xu CHENG
E-mail:wangmi@whu.edu.cn;xucheng@whu.edu.cn
About author:WANG Mi (1974—), male, PhD, professor, PhD supervisor, majors in high precision satellite remote sensing technology. E-mail: wangmi@whu.edu.cn
Supported by:CLC Number:
Mi WANG, Xu CHENG, Jun PAN, Yingdong PI, Jing XIAO. Large models enabling intelligent photogrammetry: status, challenges and prospects[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(10): 1955-1966.
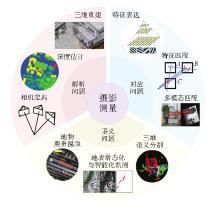
Fig.1
Applications of deep learning in photogrammetry"
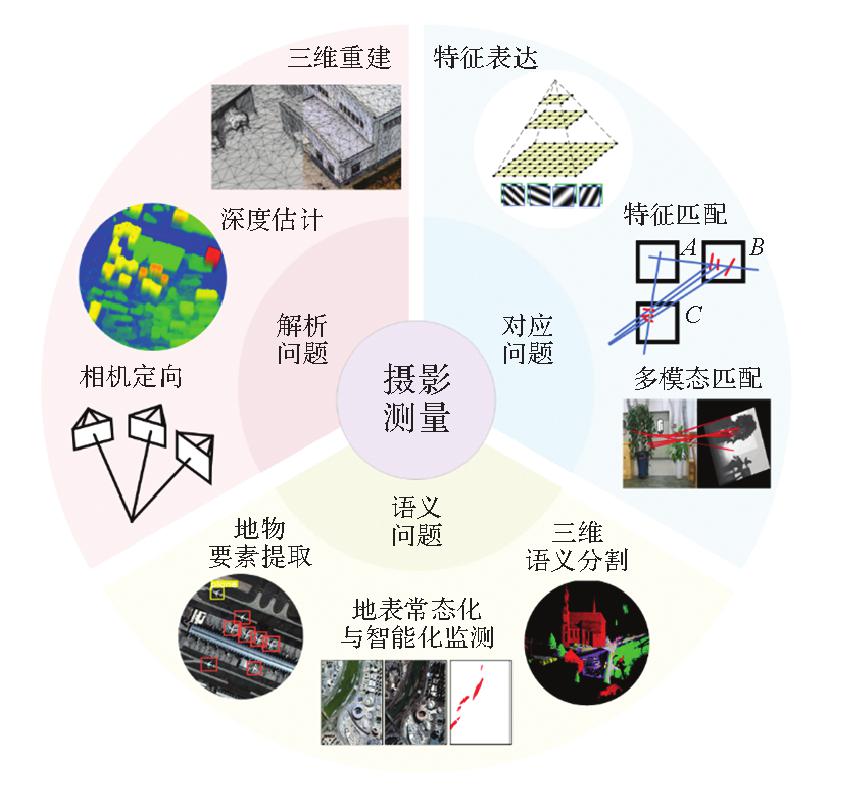
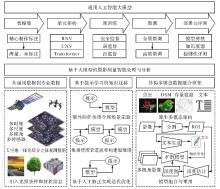
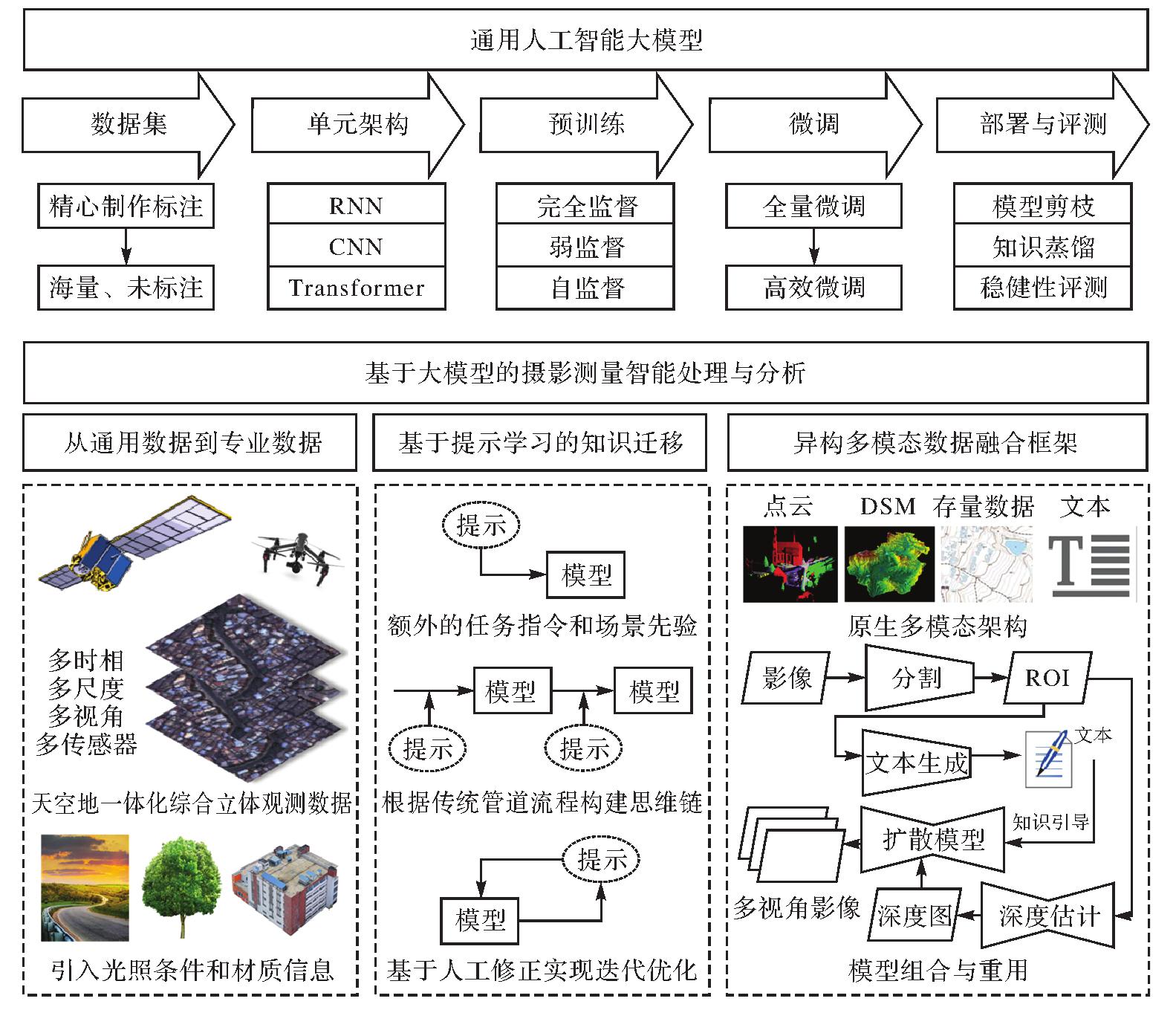
Fig.2
Intelligent processing and analysis of photogrammetry based on large models"
| [1] | 李德仁. 摄影测量与遥感的现状及发展趋势[J]. 武汉测绘科技大学学报, 2000, 25(1):1-6. |
| LI Deren. Towards photogrammetry and remote sensing: status and future development[J]. Journal of Wuhan Technical University of Surveying and Mapping, 2000, 25(1):1-6. | |
| [2] | 宁津生, 杨凯. 从数字化测绘到信息化测绘的测绘学科新进展[J]. 测绘科学, 2007, 32(2):5-11. |
| NING Jinsheng, YANG Kai. The newest progress of surveying & mapping discipline from digital style to informatization stage[J]. Science of Surveying and Mapping, 2007, 32(2):5-11. | |
| [3] |
李德仁. 从测绘学到地球空间信息智能服务科学[J]. 测绘学报, 2017, 46(10):1207-1212. DOI:.
doi: 10.11947/j.AGCS.2017.20170263 |
|
LI Deren. From geomatics to geospatial intelligent service science[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(10):1207-1212. DOI:.
doi: 10.11947/j.AGCS.2017.20170263 |
|
| [4] |
张永军, 万一, 史文中, 等. 多源卫星影像的摄影测量遥感智能处理技术框架与初步实践[J]. 测绘学报, 2021, 50(8):1068-1083. DOI:.
doi: 10.11947/j.AGCS.2021.20210079 |
|
ZHANG Yongjun, WAN Yi, SHI Wenzhong, et al. Technical framework and preliminary practices of photogrammetric remote sensing intelligent processing of multi-source satellite images[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8):1068-1083. DOI:.
doi: 10.11947/j.AGCS.2021.20210079 |
|
| [5] | DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//Proceedings of 2009 IEEE Confe-rence on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248-255. |
| [6] | BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33:1877-1901. |
| [7] | BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models[EB/OL]. [2023-11-28]. http://arxiv.org/abs/2108.07258. |
| [8] |
龚健雅, 季顺平. 摄影测量与深度学习[J]. 测绘学报, 2018, 47(6):693-704. DOI:.
doi: 10.11947/j.AGCS.2018.20170640 |
|
GONG Jianya, JI Shunping. Photogrammetry and deep learning[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6):693-704. DOI:.
doi: 10.11947/j.AGCS.2018.20170640 |
|
| [9] | 张良培, 张乐飞, 袁强强. 遥感大模型:进展与前瞻[J]. 武汉大学学报(信息科学版), 2023, 48(10):1574-1581. |
| ZHANG Liangpei, ZHANG Lefei, YUAN Qiangqiang. Large remote sensing model: progress and prospects[J]. Geomatics and Information Science of Wuhan University, 2023, 48(10):1574-1581. | |
| [10] | 杨必胜, 陈一平, 邹勤. 从大模型看测绘时空信息智能处理的机遇和挑战[J]. 武汉大学学报(信息科学版), 2023, 48(11):1756-1768. |
| YANG Bisheng, CHEN Yiping, ZOU Qin. Opportunities and challenges of spatiotemporal information intelligent processing of surveying and mapping in the era of large models[J]. Geomatics and Information Science of Wuhan University, 2023, 48(11):1756-1768. | |
| [11] | DETONE D, MALISIEWICZ T, RABINOVICH A. SuperPoint: self-supervised interest point detection and description[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 224-236. |
| [12] | SARLIN P E, DETONE D, MALISIEWICZ T, et al. SuperGlue: learning feature matching with graph neural networks[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 4938-4947. |
| [13] | 赵伍迪, 李山山, 李安, 等. 结合深度学习的高光谱与多源遥感数据融合分类[J]. 遥感学报, 25(7):1489-1502. |
| ZHAO Wudi, LI Shanshan, LI An, et al. Deep fusion of hyperspectral images and multi-source remote sensing data for classification with convolutional neural network[J]. National Remote Sensing Bulletin, 25(7):1489-1502. | |
| [14] | YANG Y, JIAO L, LIU F, et al. An explainable spatial-frequency multi-scale transformer for remote sensing scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5907515. |
| [15] |
张祖勋, 姜慧伟, 庞世燕, 等. 多时相遥感影像的变化检测研究现状与展望[J]. 测绘学报, 2022, 51(7):1091-1107. DOI:.
doi: 10.11947/j.AGCS.2022.20220070 |
|
ZHANG Zuxun, JIANG Huiwei, PANG Shiyan, et al. Review and prospect in change detection of multi-temporal remote sensing images[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7):1091-1107. DOI:.
doi: 10.11947/j.AGCS.2022.20220070 |
|
| [16] | SU Hang, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3D shape recognition[C]//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 945-953. |
| [17] | KALOGERAKIS E, AVERKIOU M, MAJI S, et al. 3D shape segmentation with projective convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3779-3788. |
| [18] | WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D ShapeNets: a deep representation for volumetric shapes[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1912-1920. |
| [19] | BROCK A, LIM T, RITCHIE J, et al. Generative and discriminative voxel modeling with convolutional neural networks[EB/OL]. [2024-02-15]. https://arxiv.org/abs/1608.04236. |
| [20] | CHARLES R Q, HAO Su, MO Kaichun, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 652-660. |
| [21] | QI C R, YI Li, SU Hao, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[EB/OL]. [2024-02-15]. https://arxiv.org/abs/1706.02413v1. |
| [22] | HANOCKA R, HERTZ A, FISH N, et al. MeshCNN: a network with an edge[J]. ACM Transactions on Graphics, 2019, 38(4):1-12. |
| [23] | YAO Yao, LUO Zixin, LI Shiwei, et al. MVSNet: depth inference for unstructured multi-view stereo[C]//Proceedings of the European Conference on Computer Vision. Cham: Springer, 2018: 767-783. |
| [24] | GU Xiaodong, FAN Zhiwen, ZHU Siyu, et al. Cascade cost volume for high-resolution multi-view stereo and stereo matching[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Seattle: IEEE, 2020: 2495-2504. |
| [25] | YANG Jiayu, MAO Wei, ALVAREZ J M, et al. Cost volume pyramid based depth inference for multi-view stereo[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 4877-4886. |
| [26] | LUO Keyang, GUAN Tao, JU Lili, et al. P-MVSNet: learning patch-wise matching confidence aggregation for multi-view stereo[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 10452-10461. |
| [27] | XU Qingshan, SU Wanjuan, QI Yuhang, et al. Learning inverse depth regression for pixelwise visibility-aware multi-view stereo networks[J]. International Journal of Computer Vision, 2022, 130(8):2040-2059. |
| [28] | ZHANG Jingyang, LI Shiwei, LUO Zixin, et al. Vis-MVSNet: visibility-aware multi-view stereo network[J]. International Journal of Computer Vision, 2023, 131(1):199-214. |
| [29] | GKIOXARI G, JOHNSON J, MALIK J. Mesh R-CNN[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9785-9795. |
| [30] | EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2366-2374. |
| [31] | CHOY C B, XU Danfei, GWAK J, et al. 3D-R2N2: a unified approach for single and multi-view 3D object reconstruction[M]//Lecture notes in computer science. Cham: Springer International Publishing, 2016: 628-644. |
| [32] | FAN Haoqiang, SU Hao, GUIBAS L. A point set generation network for 3D object reconstruction from a single image[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 605-613. |
| [33] | WANG Nanyang, ZHANG Yinda, LI Zhuwen, et al. Pixel2Mesh: generating 3D mesh models from single RGB images[M]//Lecture notes in computer science. Cham: Springer International Publishing, 2018: 55-71. |
| [34] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2103.00020. |
| [35] | ZHAI Xiaohua, WANG Xiao, MUSTAFA B, et al. LiT: zero-shot transfer with locked-image text tuning[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 18123-18133. |
| [36] | TSIMPOUKELLI M, MENICK J L, CABI S, et al. Multimodal few-shot learning with frozen language models[J]. Advances in Neural Information Processing Systems, 2021, 34:200-212. |
| [37] | ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: a visual language model for few-shot learning[J]. Advances in Neural Information Processing Systems, 2022, 35:23716-23736. |
| [38] | YAO Lewei, HUANG Runhu, HOU Lu, et al. FILIP: fine-grained interactive language-image pre-training[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2111.07783. |
| [39] | WANG X, ZHANG X, CAO Y, et al. SegGPT: segmenting everything in context[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2304.03284. |
| [40] | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2304.02643v1. |
| [41] | LYU Chenyang, WU Minghao, WANG Longyue, et al. Macaw-LLM: multi-modal language modeling with image, audio, video, and text integration[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2306.09093v1. |
| [42] | GIRDHAR R, EL-NOUBY A, LIU Zhuang, et al. ImageBind one embedding space to bind them all[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 15180-15190. |
| [43] | ZHANG Yiyuan, GONG Kaixiong, ZHANG Kaipeng, et al. Meta-transformer: a unified framework for multimodal learning[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2307.10802v1. |
| [44] | XUE Le, GAO Mingfei, XING Chen, et al. ULIP: learning a unified representation of language, images, and point clouds for 3D understanding[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 1179-1189. |
| [45] | ZHOU J, WANG J, MA B, et al. Uni3D: exploring unified 3D representation at scale[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2310.06773. |
| [46] | SHORTEN C, KHOSHGOFTAAR T M. A survey on image data augmentation for deep learning[J]. Journal of Big Data, 2019, 6(1):60. |
| [47] | TRABUCCO B, DOHERTY K, GURINAS M, et al. Effective data augmentation with diffusion models[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2302.07944v2. |
| [48] | SHUMAILOV I, SHUMAYLOV Z, ZHAO Yiren, et al. The curse of recursion: training on generated data makes models forget[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2305.17493v3. |
| [49] | SUN Xian, WANG Peijin, LU Wanxuan, et al. RingMo: a remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5612822. |
| [50] | JIA Chao, YANG Yinfei, XIA Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2102.05918. |
| [51] | XIANG Shouxing, YE Xi, XIA Jiazhi, et al. Interactive correction of mislabeled training data[C]//Proceedings of 2019 IEEE Confe-rence on Visual Analytics Science and Technology. Vancouver: IEEE, 2019: 57-68. |
| [52] | REIF E, KAHNG M, PETRIDIS S. Visualizing linguistic diversity of text datasets synthesized by large language models[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2305.11364v2. |
| [53] | KOLVE E, MOTTAGHI R, HAN W, et al. AI2-THOR: an interactive 3D environment for visual AI[EB/OL]. [2024-02-15]. https://arxiv.org/abs/1712.05474v4. |
| [54] | LI Chengshu, XIA Fei, MARTÍN-MARTÍN R, et al. iGibson 2.0: object-centric simulation for robot learning of everyday household tasks[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2108.03272v4. |
| [55] | RAMRAKHYA R, UNDERSANDER E, BATRA D, et al. Habitat-web: learning embodied object-search strategies from human demonstrations at scale[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 5173-5183. |
| [56] | SZOT A, CLEGG A, UNDERSANDER E, et al. Habitat 2.0: training home assistants to rearrange their habitat[J]. Advances in Neural Information Processing Systems, 2021, 34:251-266. |
| [57] | DEITKE M, SCHWENK D, SALVADOR J, et al. Objaverse: a universe of annotated 3D objects[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 13142-13153. |
| [58] | LING Lu, SHENG Yichen, TU Zhi, et al. DL3DV-10K: a large-scale scene dataset for deep learning-based 3D vision[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2312.16256v2. |
| [59] | YANG Y, WU X, HE T, et al. SAM3D: segment anything in 3D scenes[EB/OL]. [2023-11-27]. http://arxiv.org/abs/2306.03908. |
| [60] | CEN J, ZHOU Z, FANG J, et al. Segment anything in 3D with NeRFs[EB/OL]. [2023-11-27]. http://arxiv.org/abs/2304.12308. |
| [61] | MARI R, FACCIOLO G, EHRET T. Sat-NeRF: learning multi-view satellite photogrammetry with transient objects and shadow modeling using RPC cameras[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 1311-1321. |
| [62] | XU Linning, XIANGLI Yuanbo, PENG Sida, et al. Grid-guided neural radiance fields for large urban scenes[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023. |
| [63] | TANCIK M, CASSER V, YAN Xinchen, et al. Block-NeRF: scalable large scene neural view synthesis[C]//2022 IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 8248-8258. |
| [64] | LIALIN V, DESHPANDE V, RUMSHISKY A. Scaling down to scale up: a guide to parameter-efficient fine-tuning[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2303.15647v1. |
| [65] | HU J E, SHEN Yelong, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2106.09685. |
| [66] | HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP[EB/OL]. [2024-02-15]. https://arxiv.org/abs/1902.00751. |
| [67] | PFEIFFER J, RÜCKLÉ A, POTH C, et al. AdapterHub: a framework for adapting transformers[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2007.07779v3. |
| [68] | WANG Xinlong, WANG Wen, CAO Yue, et al. Images speak in images: a generalist painter for in-context visual learning[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 6830-6839. |
| [69] | SAITO K, SOHN K, ZHANG Xiang, et al. Prefix conditioning unifies language and label supervision[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 2861-2870. |
| [70] | CHEN Keyan, LIU Chenyang, CHEN Hao, et al. RSPrompter: learning to prompt for remote sensing instance segmentation based on visual foundation model[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2306.16269v2. |
| [71] | WEI J, WANG Xuezhi, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2201.11903v6. |
| [72] | OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35:27730-27744. |
| [73] | GAN Zhe, LI Linjie, LI Chunyuan, et al. Vision-language pre-training: basics, recent advances, and future trends[J]. Foundations and Trends® in Computer Graphics and Vision, 2022, 14(3/4):163-352. |
| [74] | SHEN Qiuhong, YANG Xingyi, WANG Xinchao. Anything-3D: towards single-view anything reconstruction in the wild[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2304.10261v1. |
| [75] | YANG X, ZHOU D, LIU S, et al. Deep model reassembly[J]. Advances in Neural Information Processing Systems, 2022, 35:25739-25753. |
| [76] | XI Zhiheng, CHEN Wenxiang, GUO Xin, et al. The rise and potential of large language model based agents: a survey[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2309.07864v3. |
| [77] | CONG Y, KHANNA S, MENG C, et al. Satmae: pre-training transformers for temporal and multi-spectral satellite imagery[J]. Advances in Neural Information Processing Systems, 2022, 35:197-211. |
| [78] | WANG Di, ZHANG Qiming, XU Yufei, et al. Advancing plain vision transformer toward remote sensing foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:5607315. |
| [79] | LIU Fan, CHEN Delong, GUAN Z, et al. RemoteCLIP: a vision language foundation model for remote sensing[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2306.11029v4. |
| [80] | ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M: a large scale vision-language dataset for remote sensing vision-language foundation model[EB/OL]. [2024-02-15]. http://export.arxiv.org/abs/2306.11300v4. |
| [81] | WANG Di, ZHANG Jing, DU Bo, et al. SAMRS: scaling-up remote sensing segmentation dataset with segment anything model[EB/OL]. [2024-02-15]. https://arxiv.org/abs/2305.02034. |
| [1] | Jiayao WANG, Lin CHEN, Shiyuan CHENG, Lijun WANG, Siqi XIONG. Artificial intelligence empowering the digital-intelligent transformation of cartographic science [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(3): 381-389. |
| [2] | Xiaomin LU, Zhiyi ZHANG, Haowen YAN, Yi HE, Xiaoning SU. A recognition method for building group pattern integrating deep graph infomax and multilayer perceptron [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(3): 425-438. |
| [3] | Shunping JI, Jin LIU, Jian GAO, Jianya GONG. An intelligent 3D reconstruction framework via deep learning based multi-view image matching [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(9): 1633-1646. |
| [4] | Jixian ZHANG, Haiyan GU, Huan NI, Haitao LI, Yi YANG, Shaopeng DING, Songman SUI. Deep learning methods for remote sensing intelligent change detection: evolution and development [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1347-1370. |
| [5] | Shuai FANG, Jiaen LIU, Jing ZHANG. Spatio-temporal fusion algorithm based on adaptive reference feature incorporation and multi-scale feature aggregation [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1476-1488. |
| [6] | Nina MENG, Fengmei LI, Xiaodong ZHOU. Data and cognition dual-driven building group generalization results and scale consistency assessment [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(7): 1318-1331. |
| [7] | Yaqing WANG, Zhonghui WANG. River network automated selection method based on heterogeneous graph convolutional networks [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(7): 1332-1345. |
| [8] | Xiaoya AN, Weiru GUO, Pengxin ZHANG, Xinxin LI, Lei SHI. Ship trajectories clustering method considering similarity in geometric position and mobility features [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(6): 1107-1121. |
| [9] | Chao WANG, Tianyu CHEN, Tong ZHANG, Tanvir AHMED, Liqiang JI, Tao XIE, Jiajun YANG, Shuai WANG. Multi-sensor optical remote sensing images change detection based on global differential enhancement module and balance penalty loss [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 873-887. |
| [10] | Qingli LUO, Xueyan LI, Guoman HUANG, Honghui CHEN, Minglong XUE, Jian LI. AOSN: alpha optimal structure network for height estimation from a single SAR image in mountain areas [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 888-898. |
| [11] | Yiming ZHAO, Kelin HU, Kelong TU, Yaxian QING, Chao YANG, Kunlun QI, Huayi WU. Multi-label scene classification method based on fusion of SAR and optical remote sensing images [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 911-923. |
| [12] | Wei TU, Xiangyuan CHI, Tianhong ZHAO, Jian YANG, Shiping ZHU, Deli CHEN. Multi-view spatio-temporal graph convolutional networks model for urban drainage networks flow prediction [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(2): 334-344. |
| [13] | Zhili ZHANG, Huiwei JIANG, Xiangyun HU. A minimal-interaction framework for accurate and batch extraction of geospatial objects from remote sensing imagery [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(10): 1863-1876. |
| [14] | Haoyu WU, Qing ZHU, Yulin DING, Liu BAO, Li LIU. High-precision digital twin modeling of tunnel surrounding rock driven by data model knowledge collaboration [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(10): 1893-1906. |
| [15] | Zhenghua ZHANG, Guoliang CHEN. A lightweight rotation-invariant network for LiDAR-based place recognition [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(1): 90-103. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||