

Acta Geodaetica et Cartographica Sinica ›› 2025, Vol. 54 ›› Issue (4): 675-687.doi: 10.11947/j.AGCS.2025.20240310
• China's 3D Realistic Model Construction • Previous Articles Next Articles
Qingdong WANG1( ), Tengfei WANG2, Li ZHANG1()
), Tengfei WANG2, Li ZHANG1()
Received:2024-07-29
Online:2025-05-30
Published:2025-05-30
Contact:
Li ZHANG
E-mail:wangqd@casm.ac.cn;zhangl@casm.ac.cn
About author:WANG Qingdong (1986—), male, PhD, associate researcher, majors in intelligent processing of 3D point clouds. E-mail: wangqd@casm.ac.cn
Supported by:CLC Number:
Qingdong WANG, Tengfei WANG, Li ZHANG. Cross-modal contrastive masked autoencoder pre-training for 3D real-scene point cloud[J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(4): 675-687.
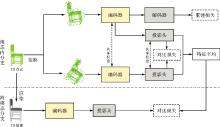
Fig. 1
The overall architecture of the proposed method"
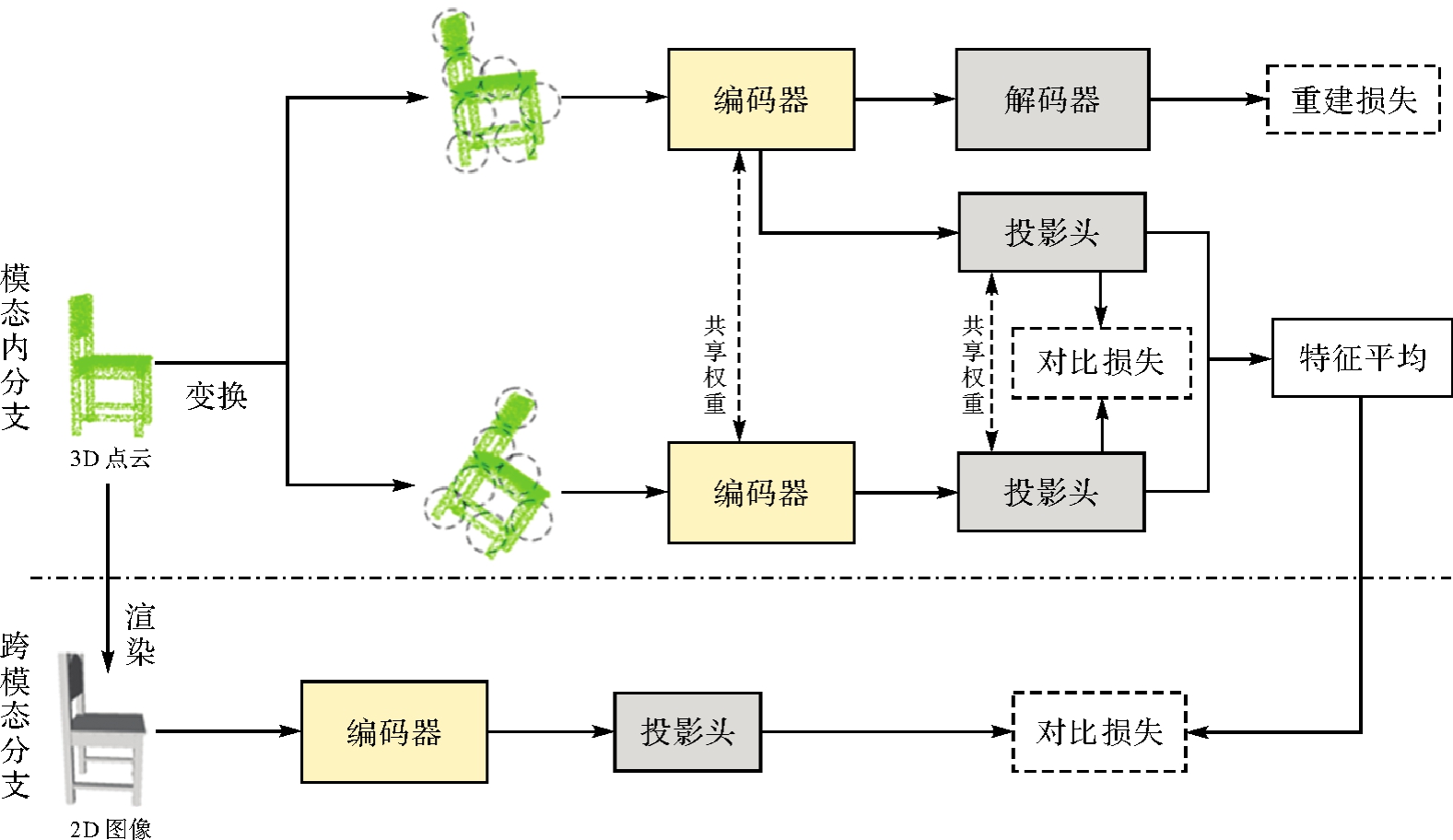
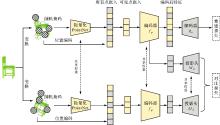
Fig. 2
The architecture of intra-modal branch"
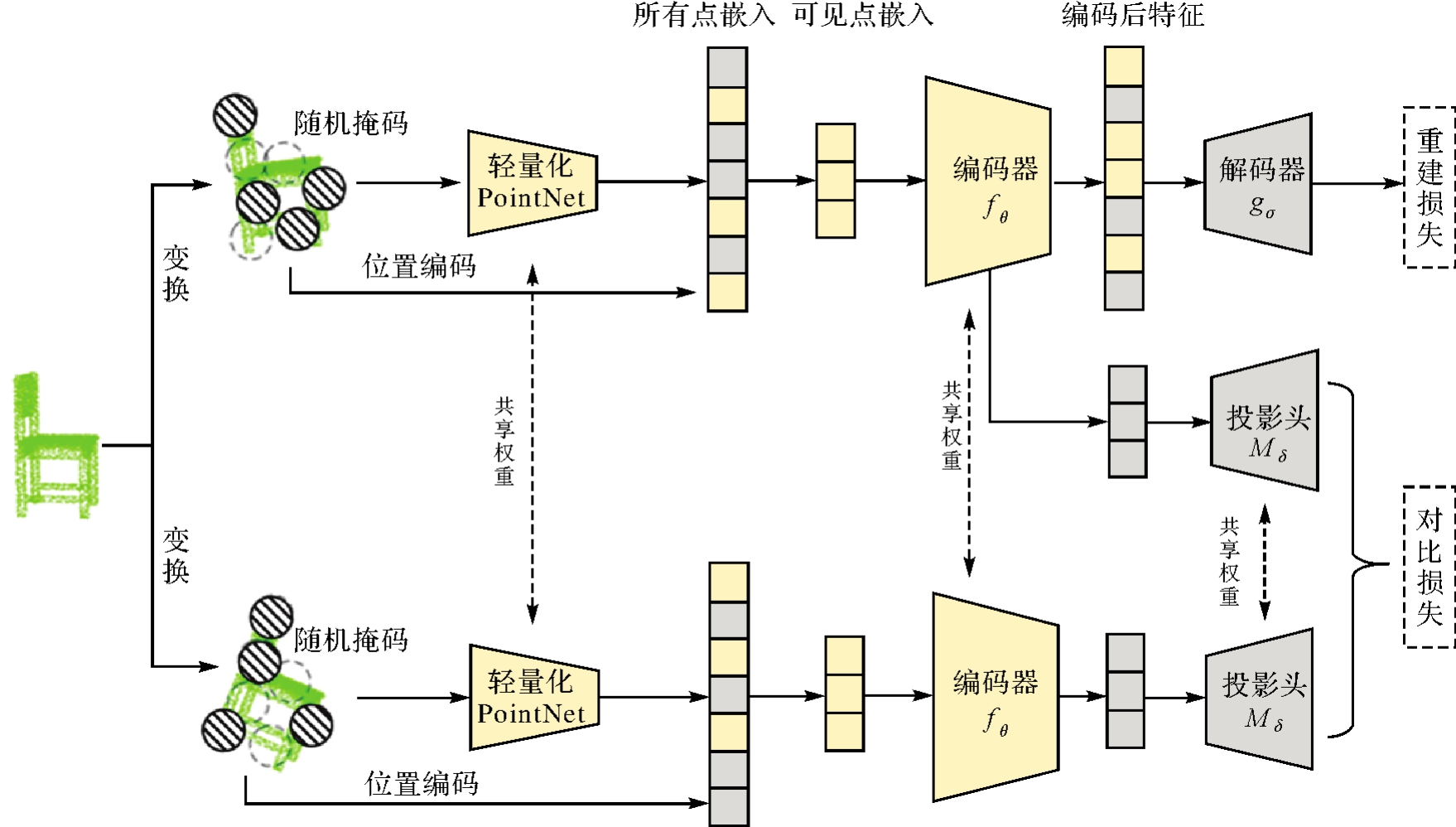
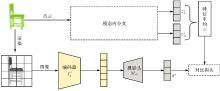
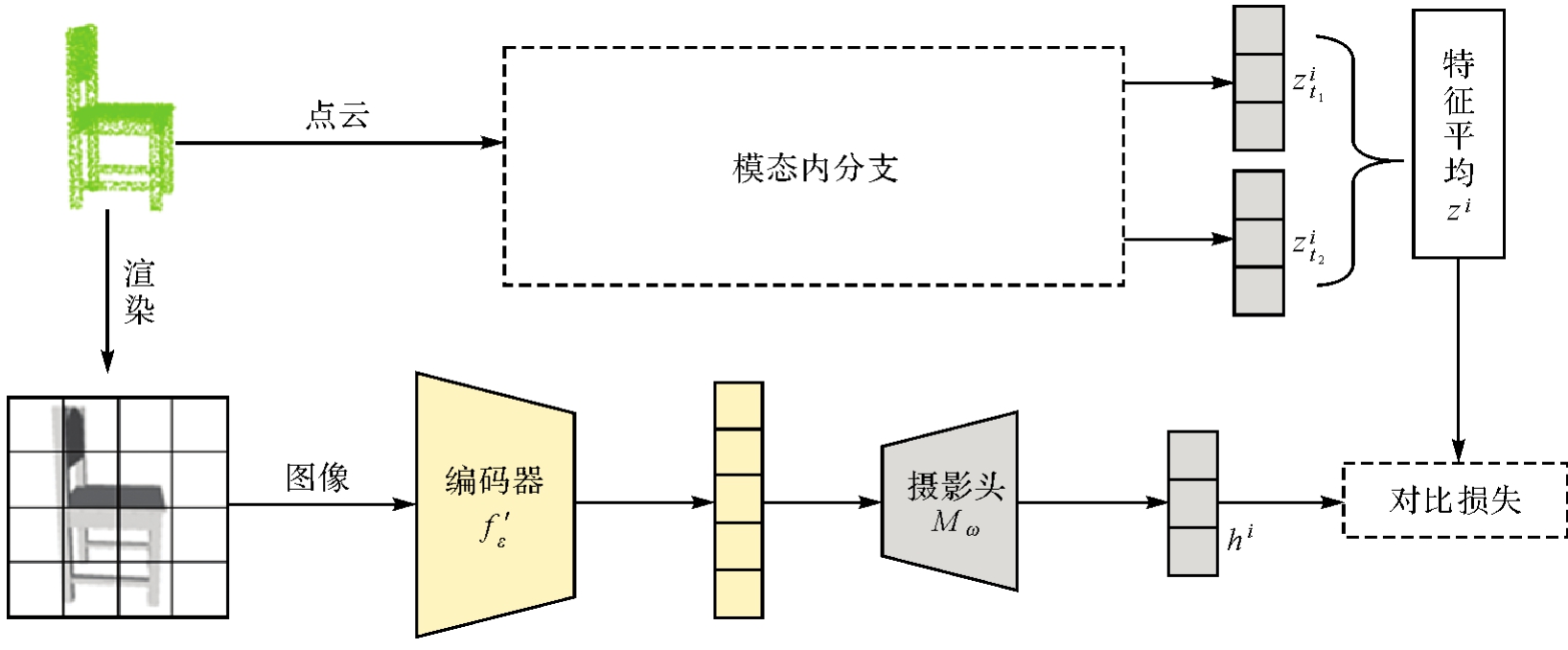
Fig. 3
The architecture of cross-modal branch"
Tab. 1
Error of masked point cloud reconstruction"
| 方法 | average | airplane | table | bag | chair | bed | car | bench | guitar | piano | sofa | microphone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Point-MAE | 17 | 8.9 | 18.7 | 18.5 | 19.2 | 20.3 | 17.2 | 13.1 | 2.9 | 22.3 | 18.2 | 5.8 |
| 本文方法 | 16.5 | 8.9 | 18.8 | 18.6 | 19.3 | 19.9 | 17.1 | 13.2 | 2.9 | 22.0 | 18.2 | 5.6 |

Fig. 4
Masked point cloud reconstruction results"

Tab. 2
Object classification results on ScanObjectNN"
| 方法 | OBJ-ONLY | OBJ-BG | PB-T50-RS |
|---|---|---|---|
| PointNet | 79.2 | 73.3 | 68.0 |
| PointNet++[ | 84.3 | 82.3 | 77.9 |
| DGCNN[ | 86.2 | 82.8 | 78.1 |
| PointCNN[ | 85.5 | 86.1 | 78.5 |
| Transformer[ | 80.6 | 79.9 | 77.2 |
| Point-BERT | 88.1 | 87.4 | 83.1 |
| Point-MAE | 88.3 | 90.0 | 85.2 |
| Point-M2AE | 88.8 | 91.2 | 86.4 |
| 本文方法 | 93.6 | 95.2 | 90.6 |
Tab. 3
The few shot classification results on ModelNet40"
| 方法 | 5-way 10-shot | 5-way 20-shot | 10-way 10-shot | 10-way 20-shot |
|---|---|---|---|---|
| PointNet++ | 38.5±4.4 | 42.4±4.5 | 23.1±2.2 | 18.8±1.7 |
| PointCNN[ | 65.4±2.8 | 68.6±2.2 | 46.6±1.5 | 50.0±2.3 |
| DGCNN-rand[ | 31.6±2.8 | 40.8±4.6 | 19.9±2.1 | 16.9±1.5 |
| CrossPoint[ | 92.5±3.0 | 94.9±2.1 | 83.6±5.3 | 87.9±4.2 |
| Point-BERT | 94.6±3.1 | 96.3±2.7 | 91.0±5.4 | 92.7±5.1 |
| Point-MAE | 96.3±2.5 | 97.8±1.8 | 92.6±4.1 | 95.0±3.0 |
| Point-M2AE | 96.8±1.8 | 98.3±1.4 | 92.3±4.5 | 95.0±3.0 |
| 本文方法 | 97.2±2.0 | 98.6±1.9 | 93.4±3.6 | 95.2±2.9 |
Tab. 4
Part segmentation on ShapeNetPart dataset"
| 类型 | 方法 | MIoU | aero | bag | cap | car | chair | earphone | guitar | knife | lamp | laptop | motor | mug |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 单模态监督 | PointNet | 83.7 | 83.4 | 78.7 | 82.5 | 74.9 | 89.6 | 73.0 | 91.5 | 85.9 | 80.8 | 95.3 | 65.2 | 93.0 |
| PointNet++ | 85.1 | 82.4 | 79.0 | 87.7 | 77.3 | 90.8 | 71.8 | 91.0 | 85.9 | 83.7 | 95.3 | 71.6 | 94.1 | |
| DGCNN | 85.2 | 84.0 | 83.4 | 86.7 | 77.8 | 90.6 | 74.7 | 91.2 | 87.5 | 82.8 | 95.7 | 66.3 | 94.9 | |
| 单模态对比 | PointContrast | 85.1 | — | — | — | — | — | — | — | — | — | — | — | — |
| 跨模态对比 | CrossPoint | 85.5 | — | — | — | — | — | — | — | — | — | — | — | — |
| 单模态掩码自编码 | Point-BERT | 85.6 | 84.3 | 84.8 | 88.0 | 79.8 | 91.0 | 81.7 | 91.6 | 87.9 | 85.2 | 95.6 | 75.6 | 94.7 |
| Point-MAE | 86.1 | 84.3 | 85.0 | 88.3 | 80.5 | 91.3 | 78.5 | 92.1 | 87.4 | 86.1 | 96.1 | 75.2 | 94.6 | |
| — | 本文方法 | 86.3 | 84.7 | 83.1 | 89.0 | 80.0 | 91.5 | 74.5 | 92.0 | 87.4 | 85.8 | 96.0 | 73.6 | 95.2 |
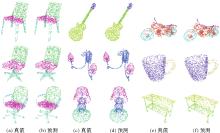
Fig. 5
Examples of point cloud part segmentation"

Tab. 5
Ablation study"
| 方法 | 部件分割(MIoU) | 点云分类(Acc) |
|---|---|---|
| 模态内无掩码自编码 | 85.6 | 85.6 |
| 模态内有掩码自编码 | 86.0 | 89.5 |
| 跨模态 | 86.3 | 90.0 |
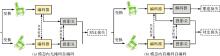
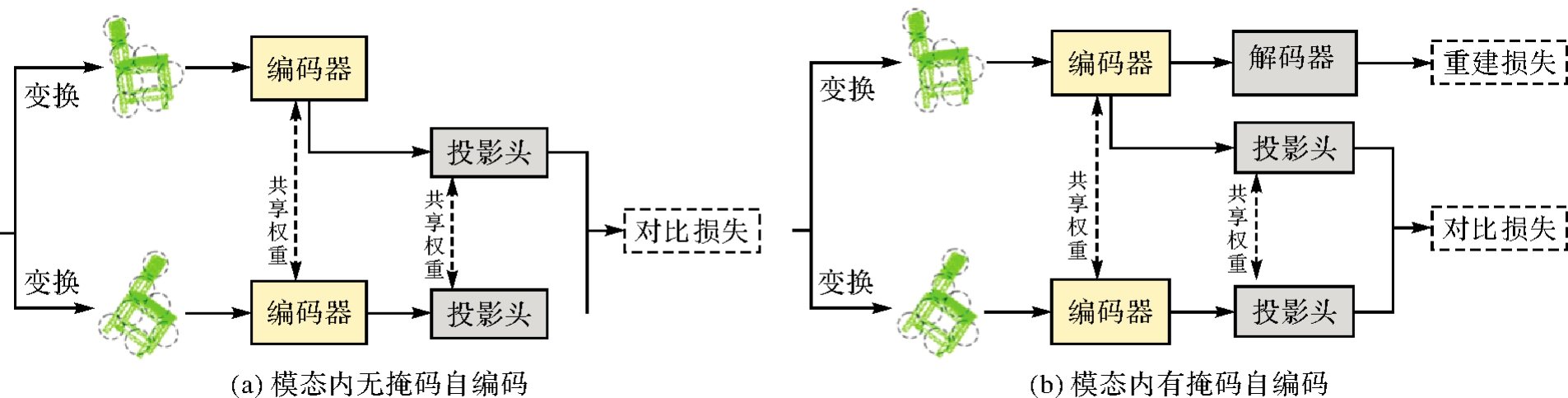
Fig. 6
Different architecture in single modal"
| [1] |
朱庆, 张利国, 丁雨淋, 等. 从实景三维建模到数字孪生建模[J]. 测绘学报, 2022, 51(6): 1040-1049. DOI:.
doi: 10.11947/j.AGCS.2022.20210640 |
|
ZHU Qing, ZHANG Liguo, DING Yulin, et al. From real 3D modeling to digital twin modeling[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(6): 1040-1049. DOI:.
doi: 10.11947/j.AGCS.2022.20210640 |
|
| [2] |
杨必胜, 陈驰, 董震. 面向智能化测绘的城市地物三维提取[J]. 测绘学报, 2022, 51(7): 1476-1484. DOI:.
doi: 10.11947/j.AGCS.2022.20220183 |
|
YANG Bisheng, CHEN Chi, DONG Zhen. 3D geospatial information extraction of urban objects for smart surveying and mapping[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(7): 1476-1484. DOI:.
doi: 10.11947/j.AGCS.2022.20220183 |
|
| [3] |
徐涛, 杨元维, 高贤君, 等. 融合图卷积与多尺度特征的接触网点云语义分割[J]. 测绘学报, 2024, 53(8): 1624-1633. DOI:.
doi: 10.11947/j.AGCS.2024.20230198 |
|
XU Tao, YANG Yuanwei, GAO Xianjun, et al. Integrated graph convolution and multi-scale features for the overhead catenary system point cloud semantic segmentation[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(8): 1624-1633. DOI:.
doi: 10.11947/j.AGCS.2024.20230198 |
|
| [4] | XU Yusheng, HUANG Rong, TONG Xiaohua, et al. Exploiting robust estimators in phase correlation of 3D point clouds for 6 DoF pose estimation[J]. Journal of Geodesy and Geoinformation Science, 2021, 4(3): 72-90. |
| [5] | CHAN Tingon, XIAO Hang, XIA Linyuan, et al. Optimization of the use of spherical targets for point cloud registration using monte carlo simulation[J]. Journal of Geodesy and Geoinformation Science, 2024, 7(2): 18-36. |
| [6] |
WANG Min, WANG Peidong. CFM-UNet: a joint CNN and transformer network via cross feature modulation for remote sensing images segmentation[J]. Journal of Geodesy and Geoinformation Science, 2023, 6(4): 40-47. DOI:.
doi: 10.11947/j.JGGS.2023.0404 |
| [7] | WANG Kaiye, YIN Qiyue, WANG Wei, et al. A comprehensive survey on cross-modal retrieval[EB/OL]. [2024-10-10]. https://arxiv.org/abs/1607.06215v1. |
| [8] | KAUR P, PANNU H S, MALHI A K. Comparative analysis on cross-modal information retrieval: a review[J]. Computer Science Review, 2021, 39: 100336. |
| [9] | WANG Zihao, LIU Xihui, LI Hongsheng, et al. Camp: cross-modal adaptive message passing for text-image retrieval[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5764-5773. |
| [10] | BAI Ye, YI Jiangyan, TAO Jianhua, et al. Fast end-to-end speech recognition via non-autoregressive models and cross-modal knowledge transferring from BERT[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 1897-1911. |
| [11] | GABEUR V, NAGRANI A, SUN Chen, et al. Masking modalities for cross-modal video retrieval[C]//Proceedings of 2022 IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2022: 2111-2120. |
| [12] | MUNOZ D, BAGNELL J A, HEBERT M. Co-inference for multi-modal scene analysis[C]//Proceedings of 2012 Computer Vision. Berlin: Springer Berlin Heidelberg, 2012: 668-681. |
| [13] | KIM H, HILTON A. Influence of colour and feature geometry on multi-modal 3D point clouds data registration[C]//Proceedings of 2014 International Conference on 3D Vision. Washington, D, C: IEEE Computer Society, 2014. |
| [14] | LU Yuheng, XU Chenfeng, WEI Xiaobao, et al. Open-vocabulary 3D detection via image-level class and debiased cross-modal contrastive learning[EB/OL]. [2024-07-08]. https://arxiv.org/abs/2207.01987v1. |
| [15] | LI Jiaxin, LEE G H. DeepI2P: image-to-point cloud registration via deep classification[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 15955-15964. |
| [16] | ZHAO Ziyu, WU Zhenyao, WU Xinyi, et al. Crossmodal few-shot 3D point cloud semantic segmentation[C]//Proceedings of the 30th ACM International Conference on Multimedia. Lisboa Portugal: ACM Press, 2022: 4760-4768. |
| [17] | WANG C, MA C, ZHU M, et al. PointAugmenting: cross-modal augmentation for 3d object detection[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11794-11803. |
| [18] | KOLMET M, ZHOU Q, OŠEP A, et al. Text2Pos: text-to-point-cloud cross-modal localization[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 6687-6696. |
| [19] | TANG Liyao, ZHAN Yibing, CHEN Zhe, et al. Contrastive boundary learning for point cloud segmentation[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 8479-8489. |
| [20] | JIANG Li, SHI Shaoshuai, TIAN Zhuotao, et al. Guided point contrastive learning for semi-supervised point cloud semantic segmentation[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 6403-6412. |
| [21] | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]//Proceedings of the 37th International Conference on Machine Learning. Brookline: Microtome Publishing, 2020: 1597-1607. |
| [22] | CHICCO D. Siamese neural networks: an overview[J]. Methods in Molecular Biology, 2021, 2190: 73-94. |
| [23] | XIE Saining, GU Jiatao, GUO Demi, et al. PointContrast: unsupervised pre-training for 3D point cloud understanding[C]//Proceedings of 2022 Computer Vision-ECCV. Cham: Springer International Publishing, 2020: 574-591. |
| [24] | ZENG Y, WANG C, WANG Y, et al. Learning transferable features for point cloud detection via 3D contrastive co-training[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems. [S.l.]: IEEE, 2021. |
| [25] | LI Zhenyu, CHEN Zehui, LI Ang, et al. SimIPU: simple 2D image and 3D point cloud unsupervised pre-training for spatial-aware visual representations[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(2): 1500-1508. |
| [26] | GRILL J-B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent-a new approach to self-supervised learning[J]. Advances in neural information processing systems, 2020, 33: 21271-21284. |
| [27] | DU Jingfei, GRAVE E, GUNEL B, et al. Self-training improves pre-training for natural language understanding[C]//Proceedings of 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Online. Stroudsburg: ACL, 2021: 5408-5418. |
| [28] | BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901. |
| [29] | HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 15979-15988. |
| [30] | YU Xumin, TANG Lulu, RAO Yongming, et al. Point-BERT: pre-training 3D point cloud transformers with masked point modeling[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 19291-19300. |
| [31] | PANG Yatian, WANG Wenxiao, TAY F E H, et al. Masked autoencoders for point cloud self-supervised learning[C]//Proceedings of 2022 Computer Vision-ECCV. Cham: Springer Nature Switzerland, 2022: 604-621. |
| [32] | ZHANG R, GUO Z, GAO P, et al. Point-m2ae: multi-scale masked autoencoders for hierarchical point cloud pre-training[J]. Advances in neural information processing systems, 2022, 35: 27061-27074. |
| [33] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of 2017 Advances in Neural Information. New York: Curran Associates, 2017: 30, 6000-6010. |
| [34] | ZHAO Hengshuang, JIANG Li, JIA Jiaya, et al. Point transformer[C]//Proceedings of 2021 International Conference on Computer Vision. Montreal: IEEE, 2021: 16239-16248. |
| [35] | GUO Menghao, CAI Junxiong, LIU Zhengning, et al. PCT: point cloud transformer[J]. Computational Visual Media, 2021, 7(2): 187-199. |
| [36] | LIU Haotian, CAI Mu, LEE Y J. Masked discrimination for Self-supervised learning on point clouds[C]//Proceedings of 2022 Computer Vision. Cham: Springer Nature Switzerland, 2022: 657-675. |
| [37] | CHARLES R Q, HAO Su, MO Kaichun, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 77-85. |
| [38] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. |
| [39] | CHANG A X, FUNKHOUSER T, GUIBAS L, et al. ShapeNet: an information-rich 3D model repository[EB/OL]. [2024-5-21]. https://arxiv.org/abs/1512.03012. |
| [40] | WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D ShapeNets: a deep representation for volumetric shapes[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1912-1920. |
| [41] | UY M A, PHAM Q H, HUA B S, et al. Revisiting point cloud classification: a new benchmark dataset and classification model on real-world data[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Los Alamitos: IEEE Computer Society, 2019: 1588-1597. |
| [42] | QI C R, YI L, SU H, et al. Pointnet++ deep hierarchical feature learning on point sets in a metric space[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5105-5114. |
| [43] | WANG Yue, SUN Yongbin, LIU Ziwei, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 1-12. |
| [44] | LI Y, BU R, SUN M, et al. Pointcnn: Convolution on x-transformed points[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 828-838. |
| [45] | WANG Hanchen, LIU Qi, YUE Xiangyu, et al. Unsupervised point cloud pre-training via occlusion completion[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 9762-9772. |
| [46] | SHARMA C, KAUL M. Self-supervised few-shot learning on point clouds[M]. Advances in Neural Information Processing Systems. New York: Curran Associates, 2020: 33, 7212-7221. |
| [47] | AFHAM M, DISSANAYAKE I, DISSANAYAKE D, et al. CrossPoint: self-supervised cross-modal contrastive learning for 3D point cloud understanding[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 9892-9902. |
| [1] | Wenhao YU, Ziyi ZENG, Yifan ZHANG, Haizhong QIAN. Road network grid pattern analysis using a pre-trained model fusing spatial and topological information [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(3): 415-424. |
| [2] | Haopeng HU, Hangbin WU, Shihao ZHAN, Zaihao WEN, Chun LIU. Road pole-like object change detection supported by visual point cloud quality optimization [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(2): 344-358. |
| [3] | Zhuang SUN, Po LIU, Liang ZHAI, Yu HE, Zutao ZHANG. A self-supervised matching method for polygonal geographic entity based on a three-branch attention network [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(1): 169-180. |
| [4] | Wenjian GAN, Yang ZHOU, Xiaofei HU, Luying ZHAO, Gaoshuang HUANG, Mingbo HOU. Combining projective transform and road segmentation for street view-satellite images cross-view geo-localization [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1489-1500. |
| [5] | Yufu ZANG, Shuye WANG, Zhen DONG, Chi CHEN, Ronggang HUANG. High-precision extraction of building point cloud facade structure based on PCF-Net network [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(7): 1243-1253. |
| [6] | Jie WAN, Zhong XIE, Yongyang XU, Liufeng TAO. A U-shaped graph convolution network method for semantic segmentation of vehicle LiDAR point clouds towards urban road scenes [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(7): 1280-1293. |
| [7] | Lianzhong XU, Chuanfa CHEN, Dongxing CHEN, Xingjie WANG, Ziming YANG, Shufan YANG, Zhuangzhuang HONG, Jinda HAO. An efficient filtering method considering terrain features for large-scale airborne LiDAR point clouds [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(6): 1082-1093. |
| [8] | Xin JIA, Qing ZHU, Xuming GE, Ruifeng MA, Han HU. Parametric modeling and deformation identification of highway guardrail driven by MLS point clouds [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(4): 688-701. |
| [9] | Jiaxin GAO, Xin SUI, Changqiang WANG, Aigong XU, Zhengxu SHI. Loop closure detection method for LiDAR SLAM supported by stable static point cloud clusters [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(12): 2194-2205. |
| [10] | Yongjun ZHANG, Changjun ZHU, Siyuan ZOU, Xinyi LIU, Qingzhou MAO, Yi WAN. Registration of aerial images and LiDAR point clouds based on distance field and plane constraints [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(1): 64-74. |
| [11] | Jialing LI, Ji QI, Weipeng LU, Chao TAO. Self-supervised learning based urban functional zone classification by integrating optical remote sensing image-OSM data [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(1): 154-164. |
| [12] | Tao XU, Yuanwei YANG, Xianjun GAO, Zhiwei WANG, Yue PAN, Shaohua LI, Lei XU, Yanjun WANG, Bo LIU, Jing YU, Fengmin WU, Haoyu SUN. Integrated graph convolution and multi-scale features for the overhead catenary system point cloud semantic segmentation [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(8): 1624-1633. |
| [13] | Jicheng WANG, Anmei GUO, Li SHEN, Tian LAN, Zhu XU, Zhilin LI. Multi-level contrastive learning for weakly supervised extraction of urban solid wastes dump from high-resolution remote sensing images [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(6): 1212-1223. |
| [14] | Changqi JI, Zhaojie GUO, Haili SUN, Ruofei ZHONG. Location and rapid detection method of water leakage in subway tunnels based on mobile laser scanning [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(6): 1236-1250. |
| [15] | Zhanlong CHEN, Xiechun LU, Yongyang XU. A building aggregation method based on deep clustering of graph vertices [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(4): 736-749. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||