


测绘学报 ›› 2024, Vol. 53 ›› Issue (6): 1057-1076.doi: 10.11947/j.AGCS.2024.20230259
郭迟1,2,3( ), 刘阳1, 罗亚荣2, 刘经南2, 张全2
), 刘阳1, 罗亚荣2, 刘经南2, 张全2
收稿日期:2023-09-08
发布日期:2024-07-22
作者简介:郭迟(1983—)男,博士,教授,主要从事北斗技术应用、无人系统智能导航及位置服务理论方法的研究。 E-mail:guochi@whu.edu.cn
基金资助:
Chi GUO1,2,3(), Yang LIU1, Yarong LUO2, Jingnan LIU2, Quan ZHANG2
Received:2023-09-08
Published:2024-07-22
About author:GUO Chi (1983—), male, PhD, professor, majors in the application of BeiDou technology, intelligent navigation of unmanned systems, and theoretical methods of location services. E-mail: guochi@whu.edu.cn
Supported by:摘要:
视觉同步定位与建图(visual simultaneous localization and mapping,VSLAM)技术以相机为主要传感器采集图像数据,基于多视几何、状态估计等算法原理获取载体的位置和姿态,同时构建一张用于导航定位的地图。视觉SLAM是自动驾驶、AR(augmented reality)、VR(virtual reality)、MR(mix reality)、智能机器人、无人机飞控中的关键技术。近年来,随着各个产业对智能导航定位的需求日渐增多,原本以几何测量为主的视觉SLAM逐渐融入对环境的语义理解。语义信息是指能够被人类直观感受和理解的概念,而图像语义信息是指图像中物体的轮廓、类别、显著性等信息。相比于图像中的几何特征,语义信息更具时空一致性,且更贴近人类感知的结果。将图像语义信息引入视觉SLAM,既能促进系统各个模块的性能,还能够提升视觉SLAM的智能感知能力,形成集几何测量、定位定姿、环境理解等多种功能的视觉语义SLAM。本文根据图像语义信息的应用方式,对视觉语义SLAM经典方案和最新研究进展进行归纳梳理。在此基础上,本文总结了视觉语义SLAM的现存问题与挑战,指出该领域未来的研究方向,以推动其面向智能导航定位进一步发展。
中图分类号:
郭迟, 刘阳, 罗亚荣, 刘经南, 张全. 图像语义信息在视觉SLAM中的应用研究进展[J]. 测绘学报, 2024, 53(6): 1057-1076.
Chi GUO, Yang LIU, Yarong LUO, Jingnan LIU, Quan ZHANG. Research progress in the application of image semantic information in visual SLAM[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(6): 1057-1076.

图1
视觉语义SLAM发展趋势"
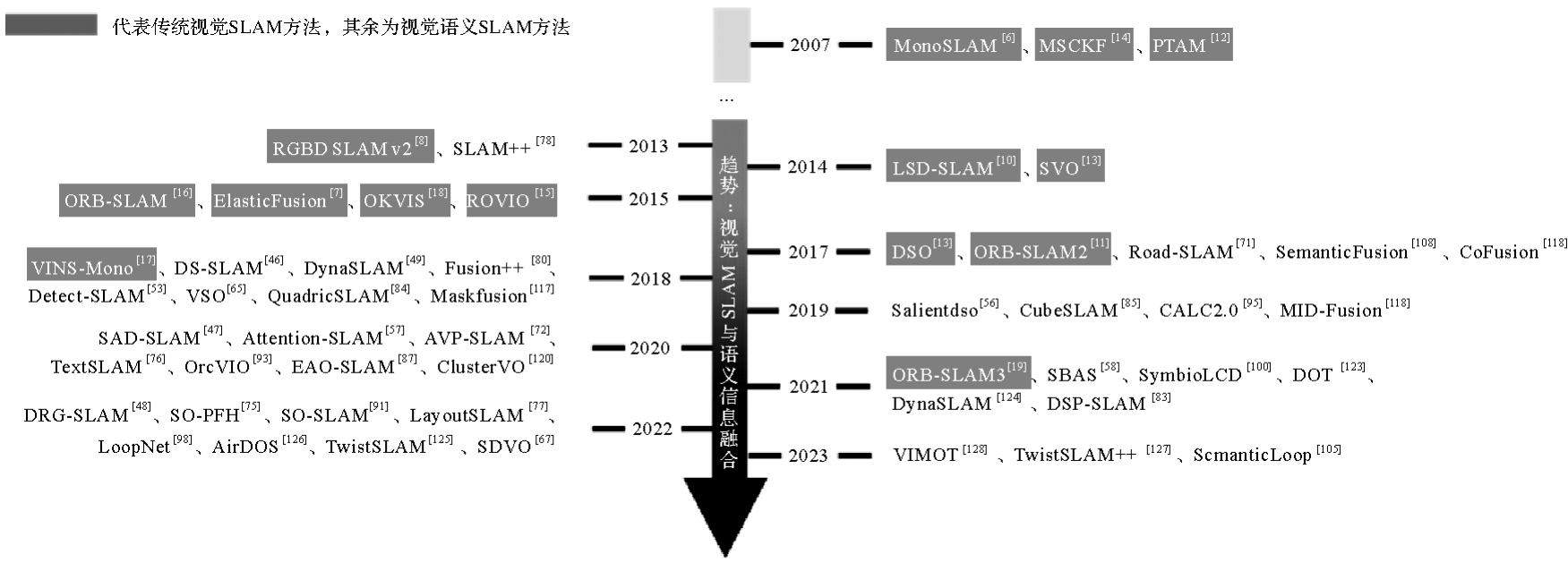
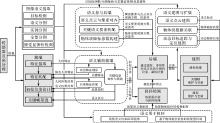
图2
视觉语义SLAM方法框架"
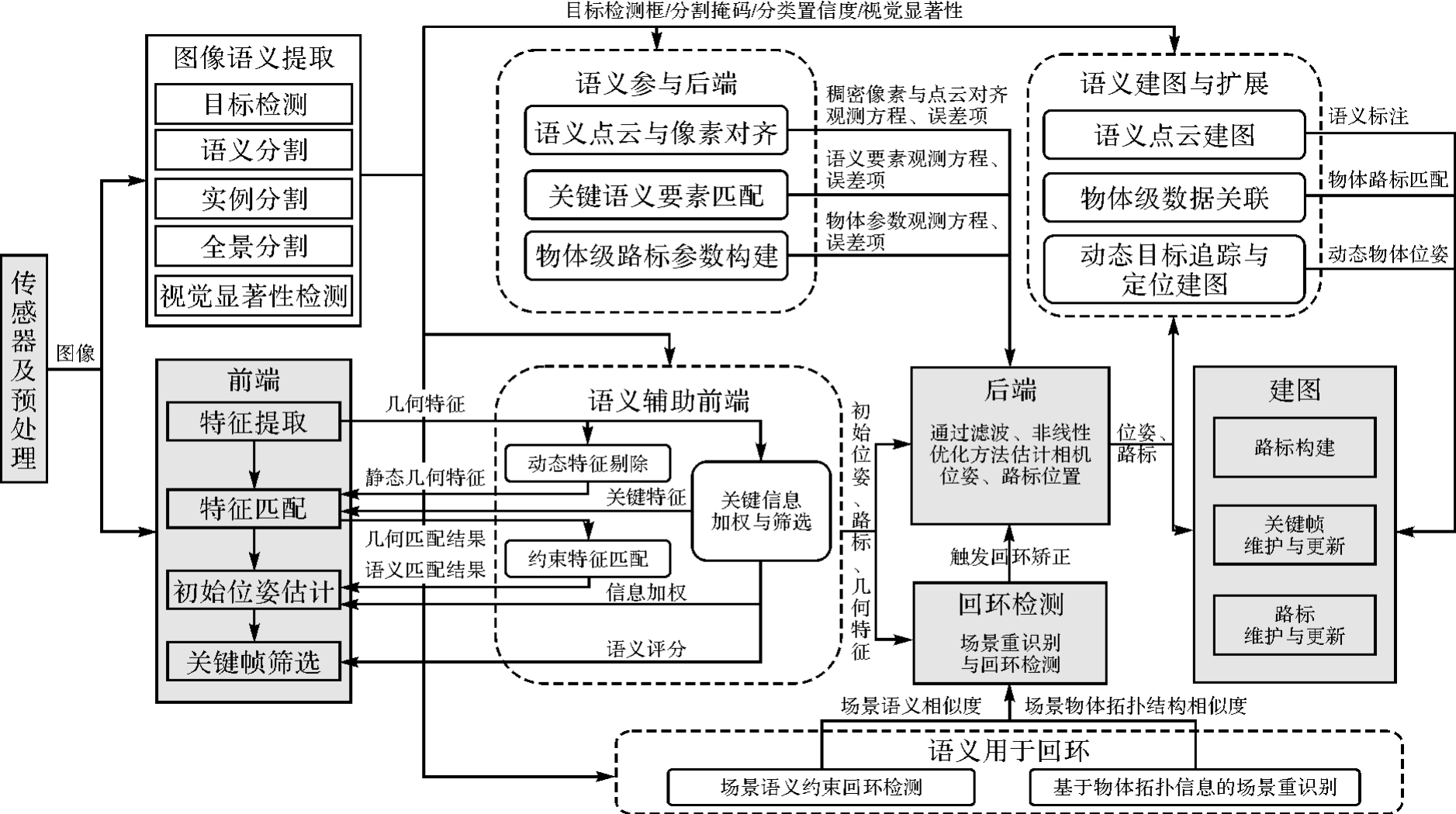
表1
图像语义信息的形式与经典方法"
| 语义获取方法 | 语义形式 | 实例 | 非实例 | 轮廓 | 经典方法 |
|---|---|---|---|---|---|
| 目标检测 | 物体的矩形检测框、类别及分类置信度 | √ | × | × | Faster-RCNN[ |
| 语义分割 | 每个像素的类别及分类置信度 | × | √ | √ | FCN[ |
| 实例分割 | 物体的像素区域掩码、类别及分类置信度 | √ | × | √ | Mask-RCNN[ |
| 全景分割 | 可数物体与不可数物体的像素区域掩码、类别及分类置信度 | √ | √ | √ | Panoptic Segmentation[ |
| 视觉显著性检测 | 图像中每个像素的显著性评分 | — | — | — | SalGAN[ |

图3
检测、分割、视觉显著性方法获取的语义信息形式[37,41]"

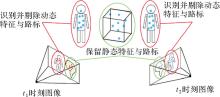
图4
动态特征剔除的视觉SLAM方法"
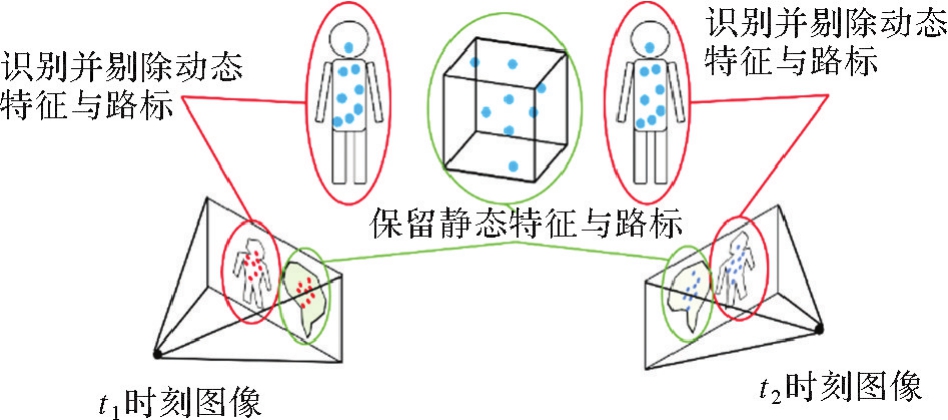
图5
融合语义信息的关键信息筛选与加权"
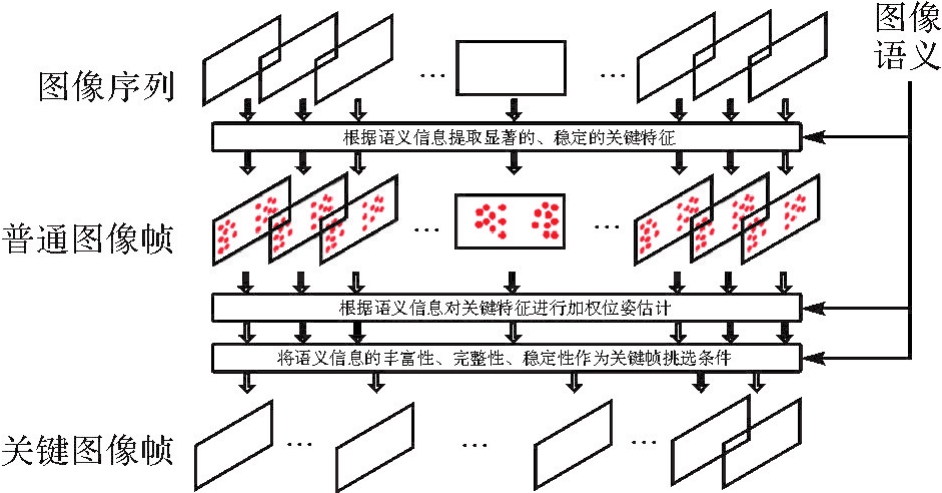
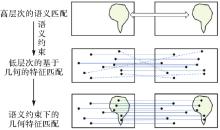
图6
语义信息约束下的特征匹配"
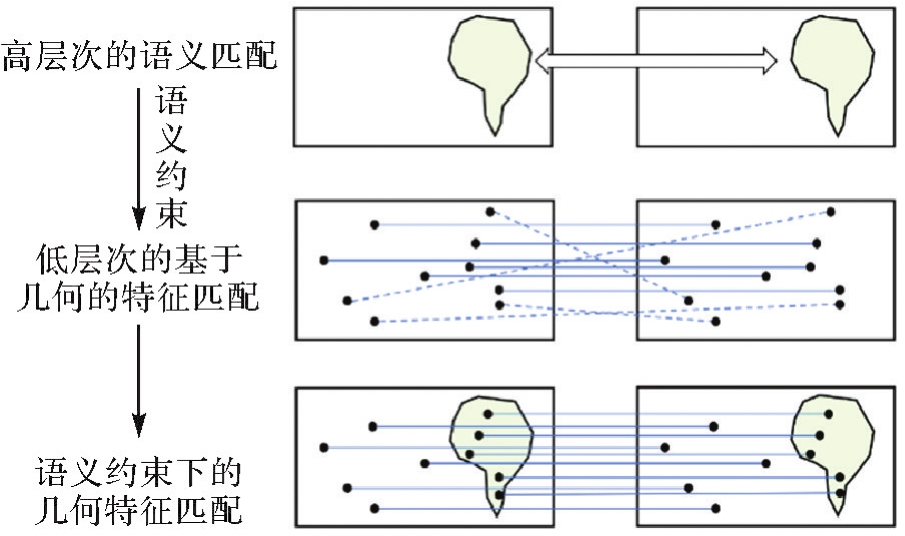
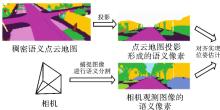
图7
稠密语义像素与点云对齐定位"
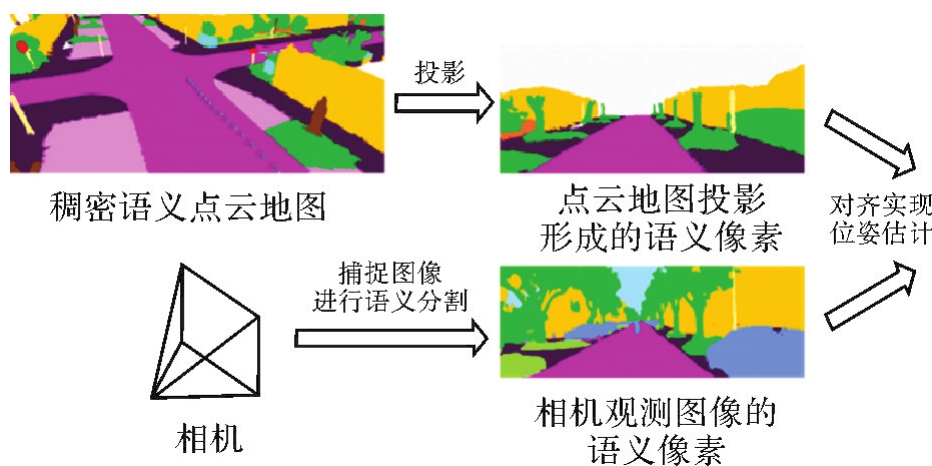
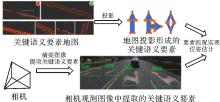
图8
关键语义要素匹配定位"
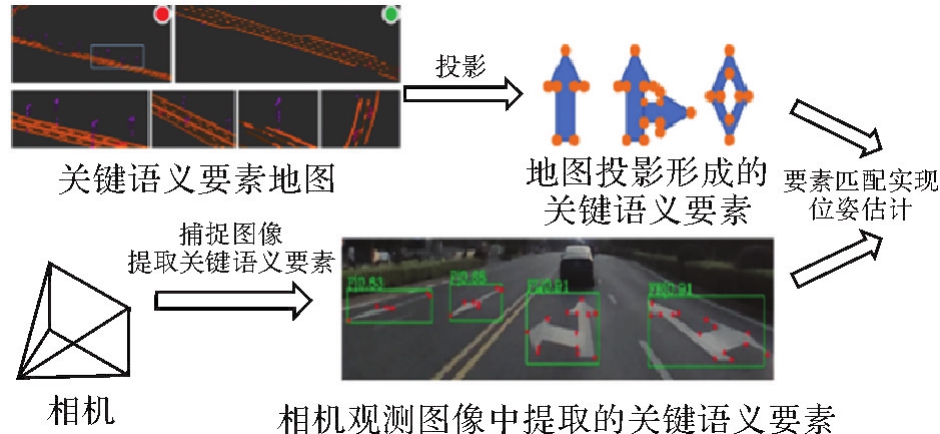
图9
物体路标几何参数定位"
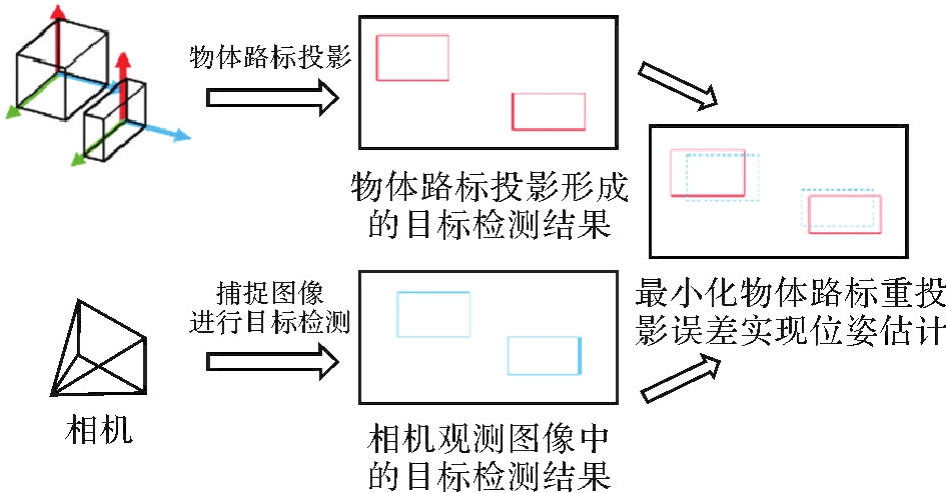
图10
基于物体拓扑信息的场景重识别"
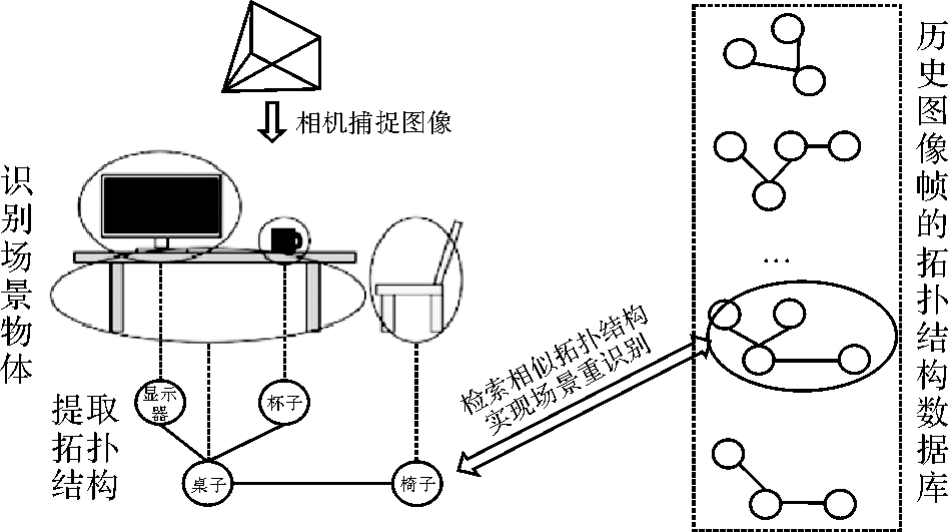
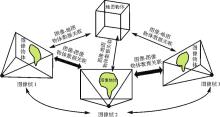
图11
物体级数据关联"
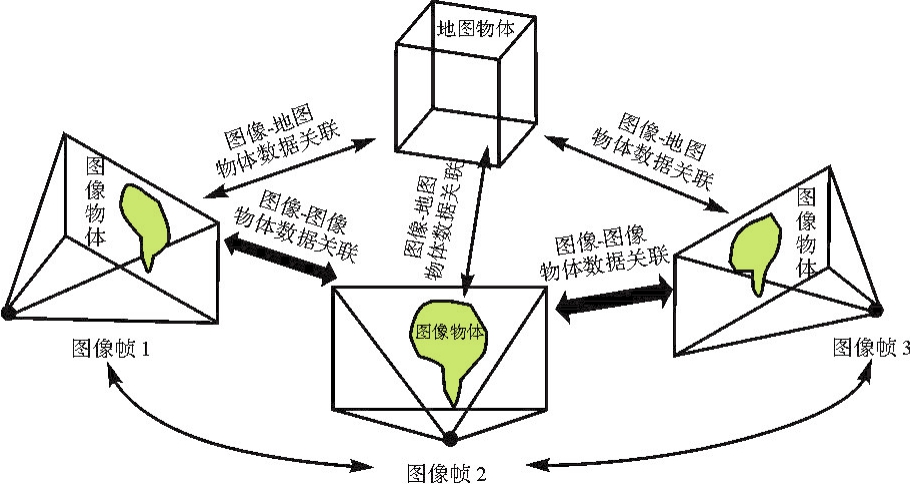
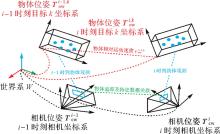
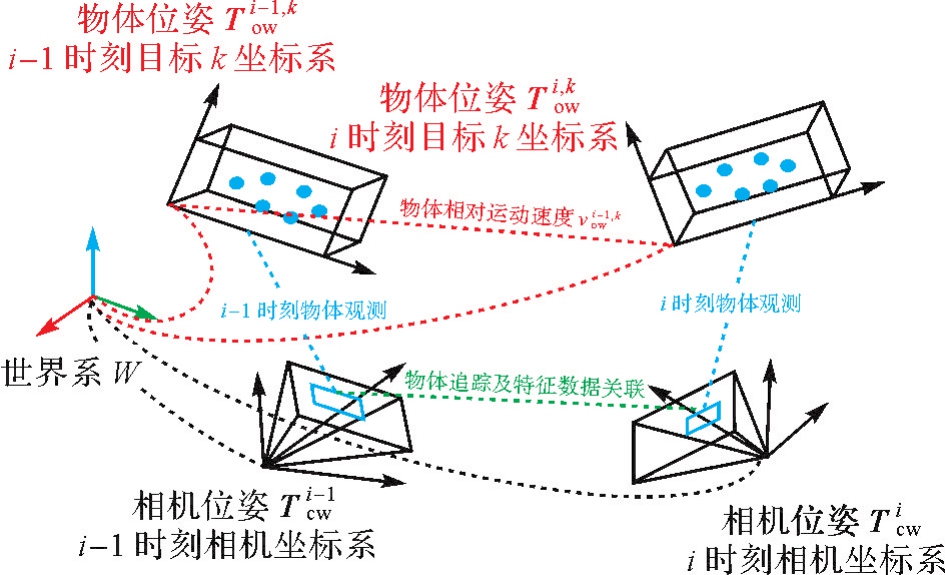
图12
动态物体追踪与位姿估计示意"
| [1] | 刘经南, 罗亚荣, 郭迟, 等. PNT智能与智能PNT[J]. 测绘学报, 2022, 51(6):811-828.DOI:10.11947/j.AGCS.2022.20220152. |
| LIU Jingnan, LUO Yarong, GUO Chi, et al. PNT intelligence and intelligent PNT[J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(6):811-828. DOI:10.11947/j.AGCS.2022.20220152. | |
| [2] | 张继贤, 刘飞. 视觉SLAM环境感知技术现状与智能化测绘应用展望[J]. 测绘学报, 2023, 52(10):1617-1630.DOI:10.11947/j.AGCS.2023.20220240. |
| ZHANG Jixian, LIU Fei. Review of visual SLAM environment perception technology and intelligent surveying and mapping application[J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(10):1617-1630. DOI:10.11947/j.AGCS.2023.20220240. | |
| [3] | CADENA C, CARLONE L, CARRILLO H, et al. Past, present, and future of simultaneous localization and mapping: toward the robust-perception age[J]. IEEE Transactions on Robotics, 2016, 32(6):1309-1332. |
| [4] | 陈军, 艾廷华, 闫利, 等. 智能化测绘的混合计算范式与方法研究[J/OL]. 测绘学报: 1-19 [2024-05-18]. http://kns.cnki.net/kcms/detail/11.2089.P.20240415.1049.002.html. |
| CHEN Jun, AI Tinghua, YAN Li, et al. Hybrid computational paradigm and methods for intelligentized surveying and mapping[J/OL]. Acta Geodaetica et Cartographica Sinica: 1-19 [2024-05-18]. http://kns.cnki.net/kcms/detail/11.2089.P.20240415.1049.002.html. | |
| [5] | 邸凯昌, 万文辉, 赵红颖, 等. 视觉SLAM技术的进展与应用[J]. 测绘学报, 2018, 47(6):770-779.DOI:10.11947/j.AGCS.2018.20170652. |
| DI Kaichang, WAN Wenhui, ZHAO Hongying, et al. Progress and applications of visual SLAM[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(6):770-779. DOI:10.11947/j.AGCS.2018.20170652. | |
| [6] | DAVISON A J, REID I D, MOLTON N D, et al. MonoSLAM: real-time single camera SLAM[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6):1052-1067. |
| [7] | WHELAN T, LEUTENEGGER S, SALAS MORENO R, et al. ElasticFusion: dense SLAM without A pose graph[C]//Proceedings of 2015 Robotics: Science and Systems XI. Robotics: Science and Systems Foundation, 2015. |
| [8] | ENDRES F, HESS J, STURM J, et al. 3-D mapping with an RGB-D camera[J]. IEEE Transactions on Robotics, 2014, 30(1):177-187. |
| [9] | MUR-ARTAL R, TARDÓS J D. ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5):1255-1262. |
| [10] | ENGEL J, SCHÖPS T, CREMERS D. LSD-SLAM: large-scale direct monocular SLAM[M]//FLEET D, PAJDLA T, SCHIELE B, et al, eds. Computer Vision-ECCV 2014. Cham: Springer International Publishing, 2014: 834-849. |
| [11] | ENGEL J, KOLTUN V, CREMERS D. Direct sparse odometry[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(3):611-625. |
| [12] | KLEIN G, MURRAY D. Parallel tracking and mapping for small AR workspaces[C]//Proceedings of 2007 IEEE and ACM International Symposium on Mixed and Augmented Reality. Nara: IEEE, 2007: 225-234. |
| [13] | FORSTER C, PIZZOLI M, SCARAMUZZA D. SVO: fast semi-direct monocular visual odometry[C]//Proceedings of 2014 IEEE International Conference on Robotics and Automation. Hong Kong: IEEE, 2014: 15-22. |
| [14] | MOURIKIS A I, ROUMELIOTIS S I. A multi-state constraint Kalman filter for vision-aided inertial navigation[C]//Proceedings of 2007 IEEE International Conference on Robotics and Automation. Rome: IEEE, 2007: 3565-3572. |
| [15] | BLOESCH M, OMARI S, HUTTER M, et al. Robust visual inertial odometry using a direct EKF-based approach[C]//Proceedings of 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Hamburg: IEEE, 2015: 298-304. |
| [16] | MUR-ARTAL R, MONTIEL J M M, TARDÓS J D. ORB-SLAM: a versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics, 2015, 31(5):1147-1163. |
| [17] | QIN Tong, LI Peiliang, SHEN Shaojie. VINS-mono: a robust and versatile monocular visual-inertial state estimator[J]. IEEE Transactions on Robotics, 2018, 34(4):1004-1020. |
| [18] | LEUTENEGGER S, LYNEN S, BOSSE M, et al. Keyframe-based visual-inertial odometry using nonlinear optimization[J]. The International Journal of Robotics Research, 2015, 34(3):314-334. |
| [19] | CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al. ORB-SLAM3: an accurate open-source library for visual, visual-inertial, and multimap SLAM[J]. IEEE Transactions on Robotics, 2021, 37(6):1874-1890. |
| [20] | DETONE D, MALISIEWICZ T, RABINOVICH A. SuperPoint: self-supervised interest point detection and description[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 337-33712. |
| [21] | LINDENBERGER P, SARLIN P E, POLLEFEYS M. LightGlue: local feature matching at lightspeed[C]//Proceedings of 2023 IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 17627-17638. |
| [22] | SUN Jiaming, SHEN Zehong, WANG Yuang, et al. LoFTR: detector-free local feature matching with transformers[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 8918-8927. |
| [23] | REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149. |
| [24] | LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//LEIBE B, MATAS J, SEBE N, et al, eds. Computer Vision-ECCV 2016. Cham: Springer International Publishing, 2016: 21-37. |
| [25] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788. |
| [26] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6517-6525. |
| [27] | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 7464-7475. |
| [28] | JOCHER G. YOLOv8[EB/OL]. 2024-06-10[2024-06-13]. https://github.com/ultralytics/ultralytics. |
| [29] | SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of 2017 IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE, 2017: 640-651. |
| [30] | BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12):2481-2495. |
| [31] | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848. |
| [32] | CHEN L C, ZHU Yukun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of 2018 Computer Vision European Conference. Munich: ACM Press, , 2018: 833-851. |
| [33] | YU Changqian, WANG Jingbo, PENG Chao, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]//Proceedings of 2018 European Conference on Computer Vision. Cham: Springer, 2018: 334-349. |
| [34] | YU C, GAO C, WANG J, et al. Bisenet v2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129:3051-3068. |
| [35] | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969. |
| [36] | BOLYA D, ZHOU C, XIAO F, et al. Yolact: Real-time instance segmentation[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9157-9166. |
| [37] | KIRILLOV A, HE K, GIRSHICK R, et al. Panoptic segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 9404-9413. |
| [38] | XIONG Y, LIAO R, ZHAO H, et al. Upsnet: A unified panoptic segmentation network[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 8818-8826. |
| [39] | CHANG C Y, CHANG S E, HSIAO P Y, et al. EPSNet: efficient panoptic segmentation network with cross-layer attention fusion[C]//Proceedings of 2020 Asian Conference on Computer Vision. Kyoto: Springer, 2020. |
| [40] | ZHAN Jiao, LUO Yarong, GUO Chi, et al. YOLOPX: anchor-free multi-task learning network for panoptic driving perception[J]. Pattern Recognition, 2024, 148:110152. |
| [41] | PAN Junting, FERRER C C, MCGUINNESS K, et al. SalGAN: visual saliency prediction with generative adversarial networks[EB/OL]. 2019-01-01[2024-06-13]. https://github.com/imatge-upc/salgan. |
| [42] | YANG Sheng, LIN Guosheng, JIANG Qiuping, et al. A dilated inception network for visual saliency prediction[J]. IEEE Transactions on Multimedia, 2020, 22(8):2163-2176. |
| [43] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[M]//Computer Vision-ECCV 2014. Cham: Springer International Publishing, 2014: 740-755. |
| [44] | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223. |
| [45] | GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 3354-3361. |
| [46] | YU Chao, LIU Zuxin, LIU Xinjun, et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]//Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid: IEEE, 2018: 1168-1174. |
| [47] | YUAN Xun, CHEN Song. SaD-SLAM: a visual SLAM based on semantic and depth information[C]//Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 4930-4935. |
| [48] | WANG Yanan, XU Kun, TIAN Yaobin, et al. DRG-SLAM: a Semantic RGB-D SLAM using Geometric Features for Indoor Dynamic Scene[C]//2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Kyoto: IEEE, 2022: 1352-1359. |
| [49] | BESCOS B, FÁCIL J M, CIVERA J, et al. DynaSLAM: tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4):4076-4083. |
| [50] | JI Tete, WANG Chen, XIE Lihua. Towards real-time semantic RGB-D SLAM in dynamic environments[C]//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xian: IEEE, 2021: 11175-11181. |
| [51] | WANG Kai, LIN Yimin, WANG Luowei, et al. A unified framework for mutual improvement of SLAM and semantic segmentation[C]//Proceedings of 2019 International Conference on Robotics and Automation. Montreal: IEEE, 2019: 5224-5230. |
| [52] | BRASCH N, BOZIC A, LALLEMAND J, et al. Semantic monocular SLAM for highly dynamic environments[C]//Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid: IEEE, 2018: 393-400. |
| [53] | ZHONG Fangwei, WANG Sheng, ZHANG Ziqi, et al. Detect-SLAM: making object detection and SLAM mutually beneficial[C]//Proceedings of 2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe: IEEE, 2018: 1001-1010. |
| [54] | GANTI P, WASLANDER S L. Network uncertainty informed semantic feature selection for visual SLAM[C]//Proceedings of 2019 Conference on Computer and Robot Vision. Kingston: IEEE, 2019: 121-128. |
| [55] | ALONSO I, RIAZUELO L, MURILLO A C. Enhancing V-SLAM keyframe selection with an efficient ConvNet for semantic analysis[C]//Proceedings of 2019 International Conference on Robotics and Automation. Montreal: IEEE, 2019: 4717-4723. |
| [56] | LIANG H J, SANKET N J, FERMÜLLER C, et al. SalientDSO: bringing attention to direct sparse odometry[J]. IEEE Transactions on Automation Science and Engineering, 2019, 16(4):1619-1626. |
| [57] | LI Jinquan, PEI Ling, ZOU Danping, et al. Attention-SLAM: a visual monocular SLAM learning from human gaze[J]. IEEE Sensors Journal, 2021, 21(5):6408-6420. |
| [58] | WANG Ke, MA Sai, REN Fan, et al. SBAS: salient bundle adjustment for visual SLAM[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70:5014709. |
| [59] | YE Chenxi, WANG Yiduo, LU Ziwen, et al. Exploiting semantic and public prior information in MonoSLAM[C]//Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 4936-4941. |
| [60] | SHI Tianxin, SHEN Shuhan, GAO Xiang, et al. Visual localization using sparse semantic 3D map[C]//Proceedings of 2019 IEEE International Conference on Image Processing. Taipei: IEEE, 2019: 315-319. |
| [61] | XUE Fei, BUDVYTIS I, CIPOLLA R. SFD2: semantic-guided feature detection and description[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 5206-5216. |
| [62] | ZHANG Yesheng, ZHAO Xu. MESA: matching everything by segmenting anything [C]//Proceedings of 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024. |
| [63] | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 4015-4026. |
| [64] | STENBORG E, TOFT C, HAMMARSTRAND L. Long-term visual localization using semantically segmented images[C]//Proceedings of 2018 IEEE International Conference on Robotics and Automation. Brisbane: IEEE, 2018: 6484-6490. |
| [65] | LIANOS K N, SCHÖNBERGER J L, POLLEFEYS M, et al. VSO: visual semantic odometry[C]//Proceedings of 2018 Computer Vision. Munich: ACM Press, 2018: 246-263. |
| [66] | HERB M, LEMBERGER M, SCHMITT M M, et al. Semantic image alignment for vehicle localization[C]//Proceedings of 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems. Prague, Czech Republic. IEEE, 2021: 1124-1131. |
| [67] | BAO Yaoqi, YANG Zhe, PAN Yun, et al. Semantic-direct visual odometry[J]. IEEE Robotics and Automation Letters, 2022, 7(3):6718-6725. |
| [68] | 刘经南, 詹骄, 郭迟, 等. 智能高精地图数据逻辑结构与关键技术[J]. 测绘学报, 2019, 48(8):939-953.DOI:CNKI:SUN:CHXB.0.2019-08-002. |
| LIU Jingnan, ZHAN Jiao, GUO Chi, et al. Data logic structure and key technologies on intelligent high-precision map[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(8):939-953.DOI:CNKI:SUN:CHXB.0.2019-08-002. | |
| [69] | JEONG J, CHO Y, KIM A. Road-SLAM: Road marking based SLAM with lane-level accuracy[C]//Proceedings of 2017 IEEE Intelligent Vehicles Symposium. Los Angeles: IEEE, 2017: 1736-1473. |
| [70] | QIN Tong, ZHENG Yuxin, CHEN Tongqing, et al. A light-weight semantic map for visual localization towards autonomous driving[C]//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xi'an: IEEE, 2021: 11248-11254. |
| [71] | QIAO Zhijian, YU Zehuan, YIN Huan, et al. Online monocular lane mapping using catmull-rom spline[C]//Proceedings of 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems. Detroit: IEEE, 2023: 7179-7186. |
| [72] | QIN Tong, CHEN Tongqing, CHEN Yilun, et al. AVP-SLAM: semantic visual mapping and localization for autonomous vehicles in the parking lot[C]//Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Las Vegas: IEEE, 2020: 5939-5945. |
| [73] | XIANG Zhenzhen, BAO Anbo, SU Jianbo. Hybrid bird's-eye edge based semantic visual SLAM for automated valet parking[C]//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xi'an: IEEE, 2021: 11546-11552. |
| [74] | CHENG Wentao, YANG Sheng, ZHOU Maomin, et al. Road mapping and localization using sparse semantic visual features[J]. IEEE Robotics and Automation Letters, 2021, 6(4):8118-8125. |
| [75] | LV Jixin, MENG Chao, WANG Yue, et al. SO-PFH: semantic object-based point feature histogram for global localization in parking lot[C]//Proceedings of 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 4431-4438. |
| [76] | LI Boying, ZOU Danping, SARTORI D, et al. TextSLAM: visual SLAM with planar text features[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation. Paris: IEEE, 2020: 2102-2108. |
| [77] | GUNJI K, OHNO K, KOJIMA S, et al. LayoutSLAM: object Layout based Simultaneous Localization and Mapping for Reducing Object Map Distortion[C]//Proceedings of 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 2825-2832. |
| [78] | SALAS-MORENO R F, NEWCOMBE R A, STRASDAT H, et al. SLAM++: simultaneous localisation and mapping at the level of objects[C]//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland: IEEE, 2013: 1352-1359. |
| [79] | PARKHIYA P, KHAWAD R, MURTHY J K, et al. Constructing category-specific models for monocular object-SLAM[C]//Proceedings of 2018 IEEE International Conference on Robotics and Automation. Brisbane: IEEE, 2018: 4517-4524. |
| [80] | MCCORMAC J, CLARK R, BLOESCH M, et al. Fusion++: volumetric object-level SLAM[C]//Proceedings of 2018 International Conference on 3D Vision. Verona: IEEE, 2018: 32-41. |
| [81] | FENG Qiaojun, MENG Yue, SHAN Mo, et al. Localization and Mapping using Instance-specific Mesh Models[C]//Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau: IEEE, 2019: 4985-4991. |
| [82] | SHARMA A, DONG Wei, KAESS M. Compositional and scalable object SLAM[C]//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xi'an: IEEE, 2021: 11626-11632. |
| [83] | WANG Jingwen, RÜNZ M, AGAPITO L. DSP-SLAM: object oriented SLAM with deep shape priors[C]//Proceedings of 2021 International Conference on 3D Vision. London: IEEE, 2021: 1362-1371. |
| [84] | NICHOLSON L, MILFORD M, SÜNDERHAUF N. QuadricSLAM: dual quadrics from object detections as landmarks in object-oriented SLAM[J]. IEEE Robotics and Automation Letters, 2019, 4(1):1-8. |
| [85] | YANG Shichao, SCHERER S. CubeSLAM: monocular 3D object SLAM[J]. IEEE Transactions on Robotics, 2019, 35(4):925-938. |
| [86] | OK K, LIU K, FREY K, et al. Robust object-based SLAM for high-speed autonomous navigation[C]//Proceedings of 2019 International Conference on Robotics and Automation. Montreal: IEEE, 2019: 669-675. |
| [87] | WU Yanmin, ZHANG Yunzhou, ZHU Delong, et al. EAO-SLAM: monocular semi-dense object SLAM based on ensemble data association[C]//Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 4966-4973. |
| [88] | QIAN Zhentian, PATATH K, FU Jie, et al. Semantic SLAM with autonomous object-level data association[C]//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xi'an: IEEE, 2021: 11203-11209. |
| [89] | TIAN Rui, ZHANG Yunzhou, FENG Yonghui, et al. Accurate and robust object SLAM with 3D quadric landmark reconstruction in outdoors[J]. IEEE Robotics and Automation Letters, 2022, 7(2):1534-1541. |
| [90] | SONG Shuangfu, ZHAO Junqiao, FENG Tiantian, et al. Scale estimation with dual quadrics for monocular object SLAM[C]//Proceedings of 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 1374-1381. |
| [91] | LIAO Ziwei, HU Yutong, ZHANG Jiadong, et al. SO-SLAM: semantic object SLAM with scale proportional and symmetrical texture constraints[J]. IEEE Robotics and Automation Letters, 2022, 7(2):4008-4015. |
| [92] | XU Binbin, DAVISON A J, LEUTENEGGER S. Learning to complete object shapes for object-level mapping in dynamic scenes[C]//Proceedings of 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 2257-2264. |
| [93] | SHAN Mo, FENG Qiaojun, ATANASOV N. OrcVIO: object residual constrained visual-inertial odometry[C]//Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas: IEEE, 2020: 5104-5111. |
| [94] | GALVEZ-LÓPEZ D, TARDOS J D. Bags of binary words for fast place recognition in image sequences[J]. IEEE Transactions on Robotics, 2012, 28(5):1188-1197. |
| [95] | MERRILL N, HUANG Guoquan. CALC2.0: combining appearance, semantic and geometric information for robust and efficient visual loop closure[C]//Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau: IEEE, 2019: 4554-4561. |
| [96] | LI J, KOREITEM K, MEGER D, et al. View-invariant loop closure with oriented semantic landmarks[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation. Paris: IEEE, 2020: 7943-7949. |
| [97] | PAPADIMITRIOU A, KLEITSIOTIS I, KOSTAVELIS I, et al. Loop closure detection and SLAM in vineyards with deep semantic cues[C]//Proceedings of 2022 International Conference on Robotics and Automation. Philadelphia: IEEE, 2022: 2251-2258. |
| [98] | OSMAN H, DARWISH N, BAYOUMI A. LoopNet: where to focus? detecting loop closures in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2022, 7(2):2031-2038. |
| [99] | LIN Shiqi, WANG Jikai, XU Meng, et al. Topology aware object-level semantic mapping towards more robust loop closure[J]. IEEE Robotics and Automation Letters, 2021, 6(4):7041-7048. |
| [100] | KIM J J Y, URSCHLER M, RIDDLE P J, et al. SymbioLCD: ensemble-based loop closure detection using CNN-extracted objects and visual bag-of-words[C]//Proceedings of 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems. Prague: IEEE, 2021: 5425. |
| [101] | KIM J J Y, URSCHLER M, RIDDLE P J, et al. Closing the loop: graph networks to unify semantic objects and visual features for multi-object scenes[C]//Proceedings of 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems. Kyoto: IEEE, 2022: 4352-4358. |
| [102] | QIAN Zhentian, FU Jie, XIAO Jing. Towards accurate loop closure detection in semantic SLAM with 3D semantic covisibility graphs[J]. IEEE Robotics and Automation Letters, 2022, 7(2):2455-2462. |
| [103] | DENG Zhiqiang, ZHANG Yunzhou, WU Yanmin, et al. Object-plane co-represented and graph propagation-based semantic descriptor for relocalization[J]. IEEE Robotics and Automation Letters, 2022, 7(4):11023-11030. |
| [104] | YU Junfeng, SHEN Shaojie. SemanticLoop: loop closure with 3D semantic graph matching[J]. IEEE Robotics and Automation Letters, 2023, 8(2):568-575. |
| [105] | MCCORMAC J, HANDA A, DAVISON A, et al. SemanticFusion: dense 3D semantic mapping with convolutional neural networks[C]//Proceedings of 2017 IEEE International Conference on Robotics and Automation. Singapore: IEEE, 2017: 4628-4635. |
| [106] | GRINVALD M, FURRER F, NOVKOVIC T, et al. Volumetric instance-aware semantic mapping and 3D object discovery[J]. IEEE Robotics and Automation Letters, 2019, 4(3):3037-3044. |
| [107] | OLEYNIKOVA H, TAYLOR Z, FEHR M, et al. Voxblox: incremental 3D Euclidean signed distance fields for on-board MAV planning[C]//Proceedings of 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 1366-1373. |
| [108] | POSADA L F, VELASQUEZ-LOPEZ A, HOFFMANN F, et al. Semantic mapping with omnidirectional vision[C]//Proceedings of 2018 IEEE International Conference on Robotics and Automation. Brisbane: IEEE, 2018: 1901-1907. |
| [109] | NAKAJIMA Y, TATENO K, TOMBARI F, et al. Fast and accurate semantic mapping through geometric-based incremental segmentation[C]//Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid: IEEE, 2018: 385-392. |
| [110] | HERB M, WEIHERER T, NAVAB N, et al. Crowd-sourced semantic edge mapping for autonomous vehicles[C]//Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau: IEEE, 2019: 7047-7053. |
| [111] | BOWMAN S L, ATANASOV N, DANIILIDIS K, et al. Probabilistic data association for semantic SLAM[C]//Proceedings of 2017 IEEE International Conference on Robotics and Automation. Singapore. IEEE, 2017: 1722-1729. |
| [112] | ZHANG Jianhua, GUI Mengping, WANG Qichao, et al. Hierarchical topic model based object association for semantic SLAM[J]. IEEE Transactions on Visualization and Computer Graphics, 2019, 25(11):3052-3062. |
| [113] | DOHERTY K J, BAXTER D P, SCHNEEWEISS E, et al. Probabilistic data association via mixture models for robust semantic SLAM[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation. Paris: IEEE, 2020: 1098-1104. |
| [114] | IQBAL A, GANS N R. Localization of classified objects in SLAM using nonparametric statistics and clustering[C]//Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid: IEEE, 2018: 161-168. |
| [115] | LIU Yang, GUO Chi, WANG Yingli. Object-aware data association for the semantically constrained visual SLAM[J]. Intelligent Service Robotics, 2023, 16(2):155-176. |
| [116] | RÜNZ M, AGAPITO L. Co-fusion: real-time segmentation, tracking and fusion of multiple objects[C]//Proceedings of 2017 IEEE International Conference on Robotics and Automation. Singapore. IEEE, 2017: 4471-4478. |
| [117] | RUNZ M, BUFFIER M, AGAPITO L. MaskFusion: real-time recognition, tracking and reconstruction of multiple moving objects[C]//Proceedings of 2018 IEEE International Symposium on Mixed and Augmented Reality. Munich: IEEE, 2018: 10-20. |
| [118] | XU Binbin, LI Wenbin, TZOUMANIKAS D, et al. MID-fusion: octree-based object-level multi-instance dynamic SLAM[C]//Proceedings of 2019 International Conference on Robotics and Automation. Montreal: IEEE, 2019: 5231-5237. |
| [119] | LI Peiliang, QIN Tong, SHEN Shaojie. Stereo vision-based semantic 3D object and ego-motion tracking for autonomous driving[M]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 664-679. |
| [120] | HUANG Jiahui, YANG Sheng, MU Taijiang, et al. ClusterVO: clustering moving instances and estimating visual odometry for self and surroundings[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2165-2174. |
| [121] | HENEIN M, ZHANG Jun, MAHONY R, et al. Dynamic SLAM: the need for speed[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation. Paris: IEEE, 2020: 2123-2129. |
| [122] | ZHANG Jun, HENEIN M, MAHONY R, et al. VDO-SLAM: a visual dynamic object-aware SLAM system[EB/OL]. 2022-01-09[2024-06-13]. https://github.com/halajun/VDO_SLAM. |
| [123] | BALLESTER I, FONTÁN A, CIVERA J, et al. DOT: dynamic object tracking for visual SLAM[C]//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xian: IEEE, 2021: 11705-11711. |
| [124] | BESCOS B, CAMPOS C, TARDÓS J D, et al. DynaSLAM II: tightly-coupled multi-object tracking and SLAM[J]. IEEE Robotics and Automation Letters, 2021, 6(3):5191-5198. |
| [125] | GONZALEZ M, MARCHAND E, KACETE A, et al. Twistslam: constrained SLAM in dynamic environment[J]. IEEE Robotics and Automation Letters, 2022, 7(3):6846-6853. |
| [126] | QIU Yuheng, WANG Chen, WANG Wenshan, et al. AirDOS: dynamic SLAM benefits from Articulated Objects[C]//Proceedings of 2022 International Conference on Robotics and Automation. Philadelphia: IEEE, 2022: 8047-8053. |
| [127] | GONZALEZ M, MARCHAND E, KACETE A, et al. TwistSLAM++: Fusing multiple modalities for accurate dynamic semantic SLAM[C]//Proceedings of 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Detroit: IEEE, 2023: 9126-9132. |
| [128] | FENG Shaoquan, LI Xingxing, XIA Chunxi, et al. VIMOT: a tightly coupled estimator for stereo visual-inertial navigation and multiobject tracking[J]. IEEE Transactions on Instrumentation and Measurement, 1011, 72:8504614. |
| [129] | YANG Linghao, ZHANG Yunzhou, TIAN Rui, et al. Fast, robust, accurate, multi-body motion aware SLAM[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(5):4381-4397. |
| [130] | LIU Yang, GUO Chi, LUO Yarong, et al. DynaMeshSLAM: a mesh-based dynamic visual SLAMMOT method[J]. IEEE Robotics and Automation Letters, 2024, 9(6):5791-5798. |
| [131] | PLACED J A, STRADER J, CARRILLO H, et al. A survey on active simultaneous localization and mapping: state of the art and new frontiers[J]. IEEE Transactions on Robotics, 2023, 39(3):1686-1705. |
| [1] | 王家耀, 陈琳, 程士源, 王利军, 熊思奇. 人工智能赋能地图科学数智化[J]. 测绘学报, 2026, 55(3): 381-389. |
| [2] | 禄小敏, 张志义, 闫浩文, 何毅, 苏小宁. 融合深度图信息最大化和多层感知机的建筑物群组模式识别方法[J]. 测绘学报, 2026, 55(3): 425-438. |
| [3] | 季顺平, 刘瑾, 高建, 龚健雅. 多视影像深度学习密集匹配三维重建智能框架[J]. 测绘学报, 2025, 54(9): 1633-1646. |
| [4] | 张继贤, 顾海燕, 倪欢, 李海涛, 杨懿, 丁少鹏, 隋淞蔓. 遥感智能变化检测的深度学习方法:演变与发展趋势[J]. 测绘学报, 2025, 54(8): 1347-1370. |
| [5] | 方帅, 刘加恩, 张晶. 自适应参考特征引入与多尺度特征聚合的时空融合算法[J]. 测绘学报, 2025, 54(8): 1476-1488. |
| [6] | 孟妮娜, 李凤梅, 周校东. 数据与认知双驱动的建筑物群制图综合结果与尺度一致性识别[J]. 测绘学报, 2025, 54(7): 1318-1331. |
| [7] | 王亚青, 王中辉. 异构图卷积网络支持下的河系自动选取方法[J]. 测绘学报, 2025, 54(7): 1332-1345. |
| [8] | 安晓亚, 郭伟茹, 张鹏鑫, 李欣欣, 石磊. 顾及几何位置和移动特征相似性的船舶轨迹聚类方法[J]. 测绘学报, 2025, 54(6): 1107-1121. |
| [9] | 王超, 陈天宇, 张同, AhmedTanvir, 纪立强, 谢涛, 杨佳俊, 王帅. 基于全局差分增强模块和平衡惩罚损失的多源光学遥感影像变化检测[J]. 测绘学报, 2025, 54(5): 873-887. |
| [10] | 罗卿莉, 李雪岩, 黄国满, 陈红辉, 薛铭龙, 李健. AOSN:α-最优网络模型的山区单通道SAR高程重建方法[J]. 测绘学报, 2025, 54(5): 888-898. |
| [11] | 涂伟, 池向沅, 赵天鸿, 杨剑, 朱世平, 陈德莉. 城市排水管网流量预测多视图时空图神经网络模型[J]. 测绘学报, 2025, 54(2): 334-344. |
| [12] | 张志力, 姜慧伟, 胡翔云. 面向极简交互的遥感地物精确批量提取框架[J]. 测绘学报, 2025, 54(10): 1863-1876. |
| [13] | 张正华, 陈国良. 一种轻量且旋转不变的激光雷达位置识别网络[J]. 测绘学报, 2025, 54(1): 90-103. |
| [14] | 石岩, 王达, 邓敏, 杨学习. 时空异常探测:从数据驱动到知识驱动的内涵转变与实现路径[J]. 测绘学报, 2024, 53(8): 1493-1504. |
| [15] | 鄢薪, 慎利, 潘俊杰, 戴延帅, 王继成, 郑晓莉, 李志林. 多尺度特征融合与空间优化的弱监督高分遥感建筑变化检测[J]. 测绘学报, 2024, 53(8): 1586-1597. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||