

Acta Geodaetica et Cartographica Sinica ›› 2024, Vol. 53 ›› Issue (9): 1817-1828.doi: 10.11947/j.AGCS.2024.20220720
• Cartography and Geoinformation • Previous Articles Next Articles
Wanzeng LIU1,2,3( ), Hang CHEN2,4, Jiaxin REN2,5(), Zhaojiang ZHANG4, Ran LI1,2,3, Tingting ZHAO1,2,3, Xi ZHAI1,2,3, Xiuli ZHU1,2,3
), Hang CHEN2,4, Jiaxin REN2,5(), Zhaojiang ZHANG4, Ran LI1,2,3, Tingting ZHAO1,2,3, Xi ZHAI1,2,3, Xiuli ZHU1,2,3
Received:2022-12-31
Online:2024-10-16
Published:2024-10-16
Contact:
Jiaxin REN
E-mail:luwnzg@163.com;jaycecd@foxmail.com
About author:LIU Wanzeng (1970—), male, PhD, professorate senior engineer, majors in spatio-temporal knowledge service. E-mail: luwnzg@163.com
Supported by:CLC Number:
Wanzeng LIU, Hang CHEN, Jiaxin REN, Zhaojiang ZHANG, Ran LI, Tingting ZHAO, Xi ZHAI, Xiuli ZHU. Research on knowledge extraction from street scene images based on hybrid intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(9): 1817-1828.
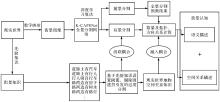
Fig.1
Ideas for street view image knowledge extraction"
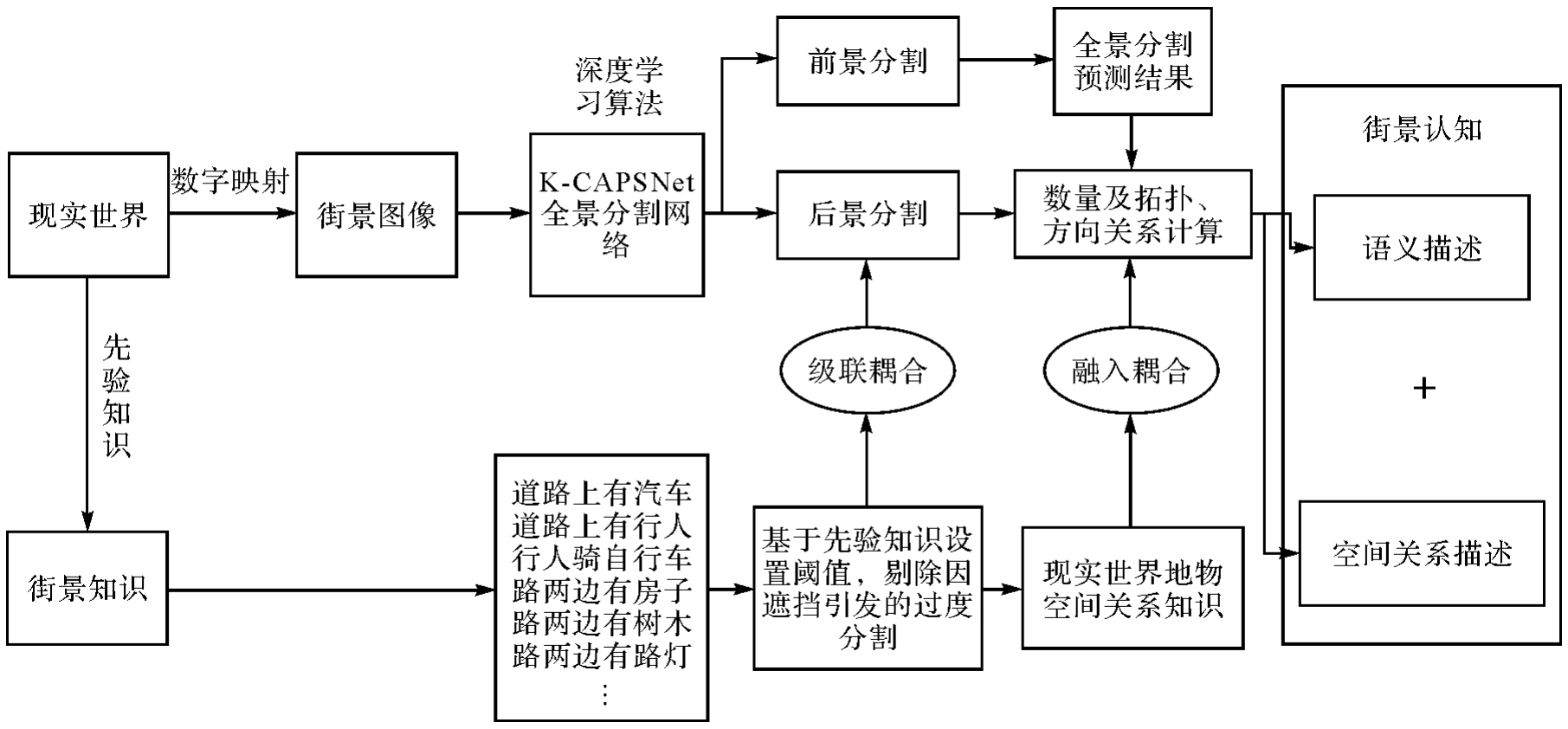

Fig.2
K-CAPSNet panoptic segmentation model"
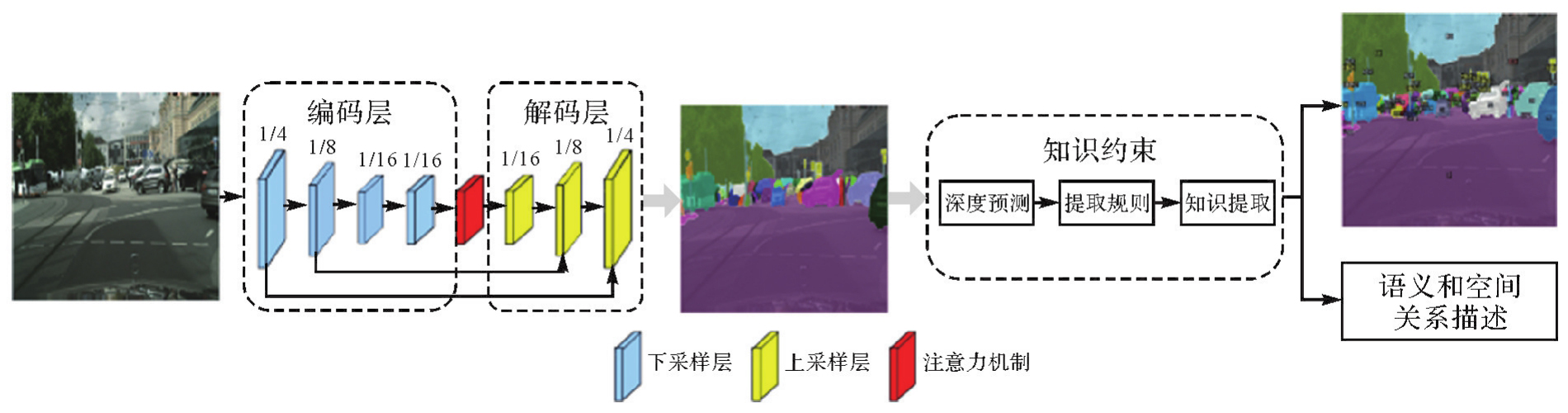
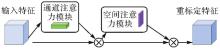
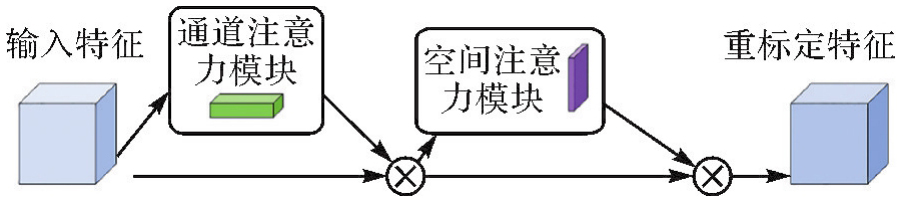
Fig.3
CBAM modules"
Tab.1
Street scene prior knowledge optimization for alleviating over-segmentation of background instances caused by occlusion"
| 知识编号 | 知识描述 | 启发 |
|---|---|---|
| 知识1 | 建筑物、植被等目标较大的面目标,只有足够长度的目标,才会导致同一目标分割成多个连通域 | 需重点关注标志杆等具有足够长度的显著目标 |
| 知识2 | 人行道、绿化带等线状目标紧邻道路,容易被道路上的车辆及行人遮挡 | 人的目标相对较小,需重点关注汽车 |
| 知识3 | 汽车为动态目标,与其他目标的空间关系是可变的;而标志杆为静态目标,与其他目标的空间关系是固定的 | 不同类型的目标需要用不同的方法进行优化,如标志杆选择影像中最显著的实例即可,而汽车由于位置不固定,则需要综合考虑所有汽车实例的影响 |
| 知识4 | 以影像拍摄地点为起点,距离越远越容易发生遮挡 | 需更加关注远处的目标 |
| 知识5 | 足够长或足够宽的后景目标会因为遮挡而被分割成多个连通域 | 较小的目标往往被完全遮挡,无法在影像上体现 |
Fig.4
Flowchart of large area target labeling algorithm"
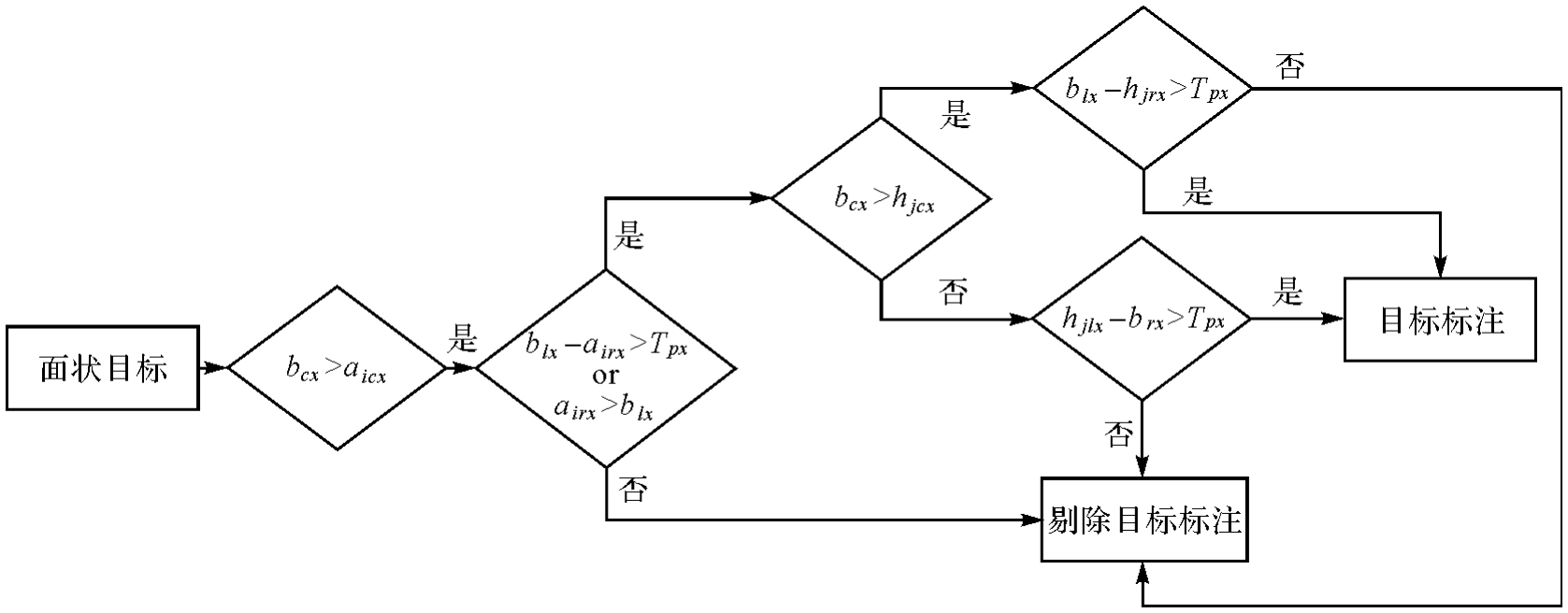
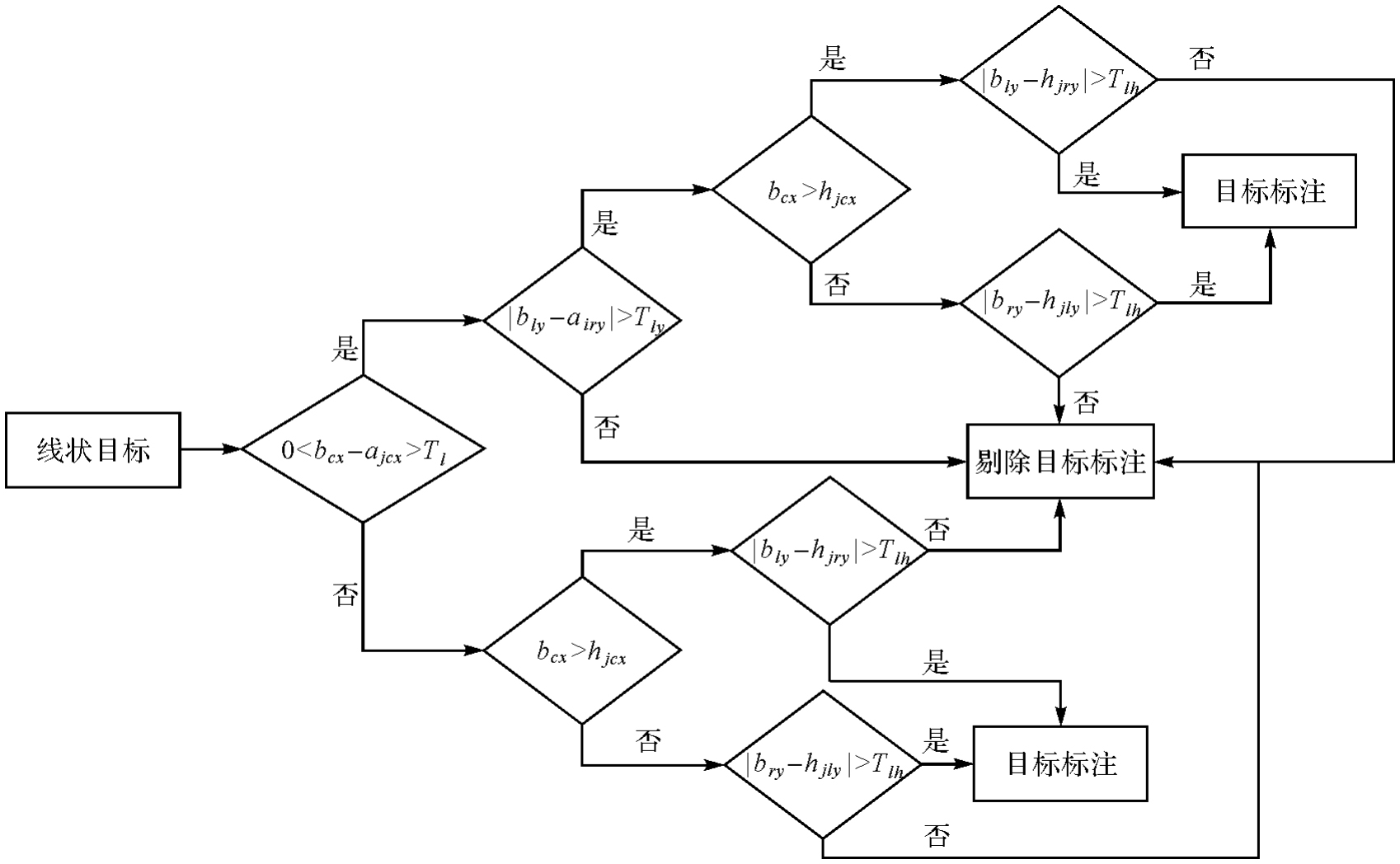
Fig.5
Flowchart of linear object labeling algorithm"
Tab.2
Streetscape prior knowledge for topological relationship verification"
| 影像实体 | 知识描述 | 拓扑关系 | 衍生关系 | 语义描述 |
|---|---|---|---|---|
| 前后遮挡的车辆 | 不应相接,若相接则发生交通事故 | 相接 | 前后相离 | 前后行驶的两辆汽车 |
| 天空和地面汽车 | 天空在上,汽车在下,不可能相接 | 相接 | 上下相离 | 天空下有一辆汽车 |
| 交通信号设施与人行道 | 交通信号设施立于人行道边上 | 相接 | 上下叠置 | 交通信号设施立于人行道边上 |
| 人与自行车 | 自行车不能脱离人的控制,人骑在自行车上 | 相接 | 上下叠置 | 人骑着自行车在路上行驶 |
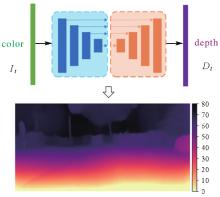
Fig.6
Deep prediction network"
"
| 输入:标注目标a,标注目标b | |||
| 输出:Left, Right, Front, Behind, Attched | |||
| function Rule1(a,b) | |||
| begin | |||
| for i:=0 down to m | |||
| begin | |||
| if x1>x2 then | |||
| begin | |||
| Left(a,b)=True | |||
| end; | |||
| else if x1<x2 then | |||
| begin | |||
| Right(a,b)=True | |||
| end; | |||
| else if d1<d2 then | |||
| begin | |||
| Front(a,b)=True | |||
| end | |||
| else if d1>d2 then | |||
| begin | |||
| Behind(a,b)=True | |||
| end; | |||
| else if x1=x2 and d1=d2 then | |||
| begin | |||
| Attched(a,b)=True | |||
| end; | |||
| end; | |||
| end; | |||
| return Left, Right, Front, Behind, Attched | |||
Tab.3
Comparison of accuracy of street view panoptic segmentation by different methods"
| 方法 | Backbone | PQ/(%) | SQ/(%) | RQ/(%) |
|---|---|---|---|---|
| AUNet | ResNet101 | 59.0 | — | — |
| PanopticFPN | ResNet101 | 58.1 | — | — |
| UPSNet | ResNet50 | 59.3 | 79.7 | 73.0 |
| Panoptic-Deeplab | HRNet48 | 60.4 | 80.7 | 73.6 |
| K-CAPSNet | HRNet48 | 61.8 | 81.6 | 75.4 |
Tab.4
Accuracy of K-CAPSNet ablation experiments"
| Group | Backbone | CBAM | PQ/(%) | SQ/(%) | RQ/(%) |
|---|---|---|---|---|---|
| 试验1 | ResNet50 | 57.6 | 80.1 | 70.6 | |
| 试验2 | ResNet50 | √ | 60.0 | 80.7 | 73.2 |
| 试验3 | Xception65 | 59.2 | 80.5 | 72.9 | |
| 试验4 | Xception65 | √ | 61.2 | 80.9 | 74.5 |
| 试验5 | HRNet48 | 60.4 | 80.7 | 73.6 | |
| 试验6 | HRNet48 | √ | 61.8 | 81.6 | 75.4 |

Fig.7
Comparison of the segmentation results of the streetscape image between this paper and Panoptic-DeepLab"


Fig.8
Comparison of the extraction effect of streetscape objects before and after optimization using the method in this paper"
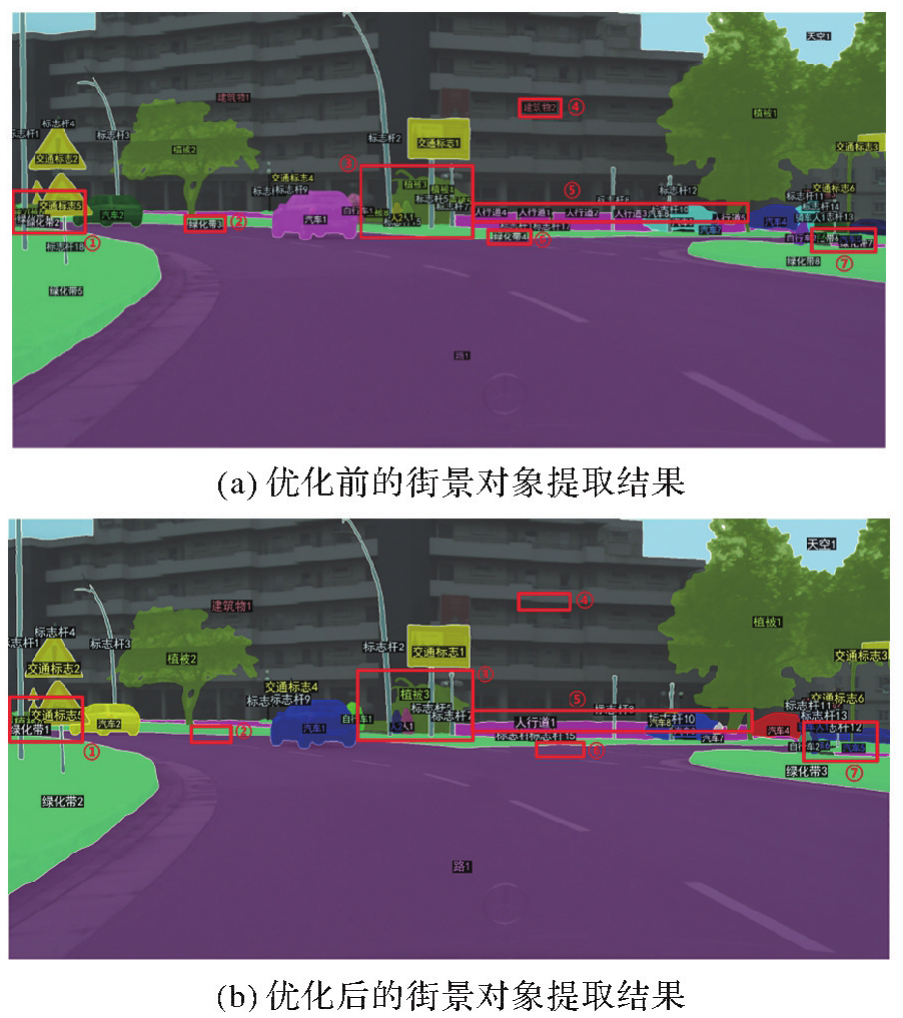
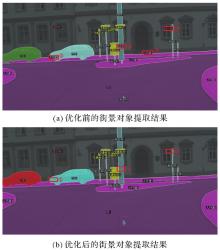
Fig.9
Comparison of the extraction effect of streetscape objects before and after optimization using the method in this paper"
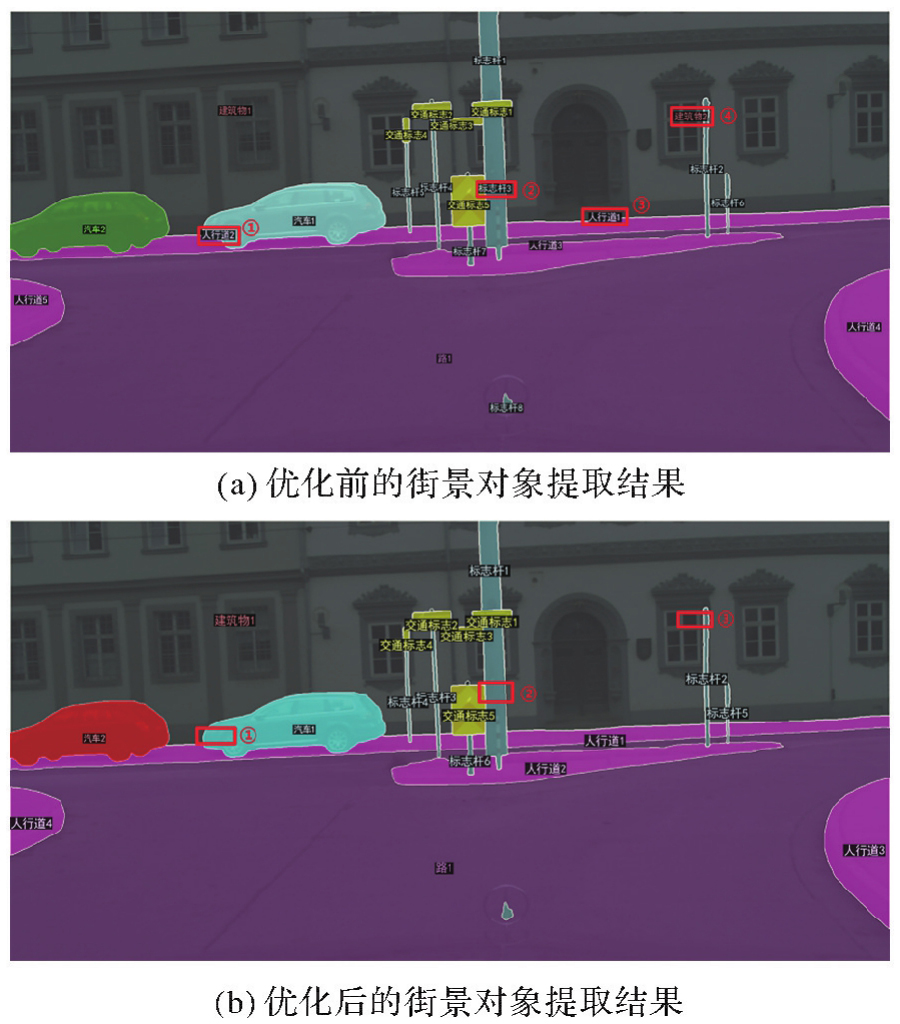

Fig.10
Depth map prediction results"

Tab.5
Image description"
| 语义描述语句 | 空间关系描述语句 |
|---|---|
| 此图像有道路,2辆汽车,1栋建筑物,5个交通标志,4个人行道,6个标志杆 | 汽车1右后方有交通标志1、2、5,汽车1与交通标志1、2、5是相离关系,汽车1右前方有交通标志4,汽车1与交通标志4是相离关系,标志杆1上有交通标志1,标志杆1与交通标志1是相接关系 |
| [1] | 刘万增, 陈军, 翟曦, 等. 时空知识中心的研究进展与应用[J]. 测绘学报, 2021, 50(9):1183-1193. DOI: 10.11947/j.AGCS.2021.20210160. |
| LIU Wanzeng, CHEN Jun, ZHAI Xi, et al. Research progress and application of spatiotemporal knowledge center[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(9):1183-1193. DOI: 10.11947/j.AGCS.2021.20210160. | |
| [2] | YING A O, PENGLONG L I, LI W, et al. Fully convolutional networks for street furniture identification in panorama images[J]. Journal of Geodesy and Geoinformation Science, 2022, 5(4):59-71. |
| [3] | GUSTAFSSON F K, DANELLJAN M, SCHON T B. Evaluating scalable Bayesian deep learning methods for robust computer vision[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 1289-1298. |
| [4] | ZUO Z, ZHANG W, ZHANG D. A remote sensing image semantic segmentation method by combining deformable convolution with conditional random fields[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3):39-49. |
| [5] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788. |
| [6] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6517-6525. |
| [7] | REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2023-09-20]. https://arxiv.org/abs/1804.02767v1. |
| [8] | LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 936-944. |
| [9] | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2023-08-17]. https://arxiv.org/abs/2004.10934v1. |
| [10] | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3431-3440. |
| [11] | HE Kaiming, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969. |
| [12] | KIRILLOV A, HE Kaiming, GIRSHICK R, et al. Panoptic segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 9404-9413. |
| [13] | JOHNSON J, KRISHNA R, STARK M, et al. Image retrieval using scene graphs[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3668-3678. |
| [14] | CHANG X, REN P, XU P, et al. Scene graphs: a survey of generations and applications[EB/OL]. [2024-03-17]http://arxiv.org/abs/2104.01111v1. |
| [15] | TENG Yao, WANG Limin. Structured sparse R-CNN for direct scene graph generation[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 19415-19424. |
| [16] | YANG J, LU J, LEE S, et al. Graph R-CNN for scene graph generation[C]//Proceedings of 2018 European conference on computer vision (ECCV). Munich: Springer, 2018: 690-706. |
| [17] | SHI Jing, ZHONG Yiwu, XU Ning, et al. A simple baseline for weakly-supervised scene graph generation[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 16393-16402. |
| [18] | MALAWADE A V, YU S Y, HSU B, et al. roadscene2vec: a tool for extracting and embedding road scene-graphs[J]. Knowledge-Based Systems, 2022, 242:108245. |
| [19] | CHENG Bowen, COLLINS M D, ZHU Yukun, et al. Panoptic-DeepLab: a simple, strong, and fast baseline for bottom-up panoptic segmentation[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020. |
| [20] | 陈军, 刘万增, 武昊, 等. 智能化测绘的基本问题与发展方向[J]. 测绘学报, 2021, 50(8):995-1005. DOI: 10.11947/j.AGCS.2021.20210235. |
| CHEN Jun, LIU Wanzeng, WU Hao, et al. Smart surveying and mapping:fundamental issues and research agenda[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8):995-1005. DOI: 10.11947/j.AGCS.2021.20210235. | |
| [21] | JUN C, ZHILIN L I, SONGNIAN L I, et al. From digitalized to intelligentized surveying and mapping: fundamental issues and research agenda[J]. Journal of Geodesy and Geoinformation Science, 2022, 5(2):148-160. |
| [22] | 任加新, 刘万增, 陈军, 等. 知识引导的碎片化栅格地形图比例尺智能识别[J]. 测绘学报, 2024, 53(1):146-157. DOI: 10.11947/j.AGCS.2024.20230005. |
| REN Jiaxin, LIU Wanzeng, CHEN Jun, et al. Knowledge-guided intelligent recognition of the scale for fragmented raster topographic maps[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(1):146-157. DOI: 10.11947/j.AGCS.2024.20230005. | |
| [23] | 张帆, 刘瑜. 街景影像:基于人工智能的方法与应用[J]. 遥感学报, 2021, 25(5):1043-1054. |
| ZHANG Fan, LIU Yu. Street view imagery: methods and applications based on artificial intelligence[J]. National Remote Sensing Bulletin, 2021, 25(5):1043-1054. | |
| [24] | HOU Rui, LI Jie, BHARGAVA A, et al. Real-time panoptic segmentation from dense detections[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 8520-8529. |
| [25] | LÜ Zhengyao, LI Xiaoming, LI Xin, et al. Learning semantic person image generation by region-adaptive normalization[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 10801-10810. |
| [26] | SONG Sijie, ZHANG Wei, LIU Jiaying, et al. Unsupervised person image generation with semantic parsing transformation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 2352-2361. |
| [27] | MA Wenguang, MA Wei, XU Shibiao, et al. Pyramid ALKNet for semantic parsing of building facade image[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(6):1009-1013. |
| [28] | 徐鹏斌, 瞿安国, 王坤峰, 等. 全景分割研究综述[J]. 自动化学报, 2021, 47(3):549-568. |
| XU Pengbin, JU Anguo, WANG Kunfeng, et al. A survey of panoptic segmentation methods[J]. Acta Automatica Sinica, 2021, 47(3):549-568. | |
| [29] | WOO S, PARK J, LEE J, et al. CBAM: convolutional block attention module[C]//Proceedings of 2018 European conference on computer vision. Munich: Springer, 2018. |
| [30] | LI Z L, ZHAO R L, CHEN J. A Voronoi-based spatial algebra for spatial relations[J]. Progress in Natural Science-Materials International, 2002, 12(7):528-536. |
| [31] | 魏海涛, 李柯, 赫晓慧, 等. 融入空间关系的矩阵分解POI推荐模型[J]. 武汉大学学报(信息科学版), 2021, 46(5):681-690. |
| WEI Haitao, LI Ke, HE Xiaohui, et al. Integrating spatial relationship into a matrix factorization model for POI recommendation[J]. Geomatics and Information Science of Wuhan University, 2021, 46(5):681-690. | |
| [32] | 陈杰, 戴欣宜, 周兴, 等. 双LSTM驱动的高分遥感影像地物目标空间关系语义描述[J]. 遥感学报, 2021, 25(5):1085-1094. |
| CHEN Jie, DAI Xinyi, ZHOU Xing, et al. Semantic understanding of geo-objects’relationship in high resolution remote sensing image driven by dual LSTM[J]. National Remote Sensing Bulletin, 2021, 25(5):1085-1094. | |
| [33] | GODARD C, MAC AODHA O, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3828-3838. |
| [34] | GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11):1231-1237. |
| [35] | FAROOQ BHAT S, ALHASHIM I, WONKA P. AdaBins: depth estimation using adaptive bins[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 4008-4017. |
| [36] | 徐守坤, 吉晨晨, 倪楚涵, 等. 融合施工场景及空间关系的图像描述生成模型[J]. 计算机工程, 2020, 46(6):256-265. |
| XU Shoukun, JI Chenchen, NI Chuhan, et al. Image description generation model integrating construction scenes and spatial relationship[J]. Computer Engineering, 2020, 46(6):256-265. | |
| [37] | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223. |
| [38] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. |
| [39] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1251-1258. |
| [40] | SUN Ke, XIAO Bin, LIU Dong, et al. Deep high-resolution representation learning for human pose estimation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5686-5696. |
| [41] | MOHAN R, VALADA A. Amodal panoptic segmentation[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 20991-21000. |
| [42] | DAI Xiyang, CHEN Yinpeng, XIAO Bin, et al. Dynamic head: unifying object detection heads with attentions[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 7369-7378. |
| [43] | 张继贤, 刘飞. 视觉SLAM环境感知技术现状与智能化测绘应用展望[J]. 测绘学报, 2023, 52(10):1617-1630. DOI: 10.11947/j.AGCS.2023.20220240. |
| ZHANG Jixian, LIU Fei. Review of visual SLAM environment perception technology and intelligent surveying and mapping application[J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(10):1617-1630. DOI: 10.11947/j.AGCS.2023.20220240. |
| [1] | Jun CHEN, Tinghua AI, Li YAN, Wanzeng LIU, Zhilin LI, Qiang ZHU, Jingxiang GAO, Hong XIE, Hao WU, Jun ZHANG. Hybrid computational paradigm and methods for intelligentized surveying and mapping [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(6): 985-998. |
| [2] | REN Jiaxin, LIU Wanzeng, CHEN Jun, ZHANG Lan, TAO Yuan, ZHU Xiuli, ZHAO Tingting, LI Ran, ZHAI Xi, WANG Haiqing, ZHOU Xiaoguang, HOU Dongyang, WANG Yong. Knowledge-guided intelligent recognition of the scale for fragmented raster topographic maps [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(1): 146-157. |
| [3] | Lü Kefeng, ZHANG Yongsheng, YU Ying, MIN Jie. Instance object localization based on semantic information and geo-registration [J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(8): 1375-1386. |
| [4] | YANG Juntao, KANG Zhizhong. Multi-scale Features and Markov Random Field Model for Powerline Scene Classification [J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(2): 188-197. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||