

Acta Geodaetica et Cartographica Sinica ›› 2026, Vol. 55 ›› Issue (5): 927-940.doi: 10.11947/j.AGCS.2026.20250521
• Photogrammetry and Remote Sensing • Previous Articles Next Articles
Rui YU1( ), Jie LI1,2, Huihui LIU1(), Meiru WU1, Liupeng LIN3, Qiangqiang YUAN1, Li ZHENG1
), Jie LI1,2, Huihui LIU1(), Meiru WU1, Liupeng LIN3, Qiangqiang YUAN1, Li ZHENG1
Received:2025-12-15
Revised:2026-04-21
Online:2026-06-23
Published:2026-06-23
Contact:
Huihui LIU
E-mail:rui.yu@whu.edu.cn;hhliu@sgg.whu.edu.cn
About author:YU Rui (2002—), male, postgraduate, majors in remote sensing change detection and deep learning-based multi-task learning. E-mail: rui.yu@whu.edu.cn
Supported by:CLC Number:
Rui YU, Jie LI, Huihui LIU, Meiru WU, Liupeng LIN, Qiangqiang YUAN, Li ZHENG. Heterogeneous remote sensing change detection based on vision-language collaborative representation for flood disasters[J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(5): 927-940.
Tab. 1
Category library for flood disaster monitoring"
| 类别分类 | 基础地物实体 | 洪水灾害状态描述 |
|---|---|---|
| 对象级 | 河流、湖泊、池塘、湿地、海洋 | 河流溢出、水体扩张、浑浊水域、深水区 |
| 森林、农田、草地、裸土、植被、沙漠、山脉、丛林、岛屿 | 被淹没的农田、植被受损、泥泞土地、浸水区 | |
| 道路、桥梁、建筑物、住宅区、商业区、工业区、校园、广场、停车场、不透水地表 | 被淹没的道路、切断的交通、房屋被围困、城市内涝 | |
| 场景级 | 乡村场景、城市景观、沿海地区、沿河地区 | 大范围淹没、洪水灾害区域、灾后废墟 |
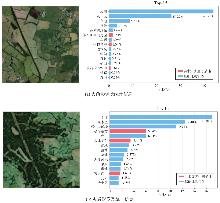
Fig. 1
CLIP inference on heterogeneous images"
Fig. 2
The architecture of MCE-CLIP"
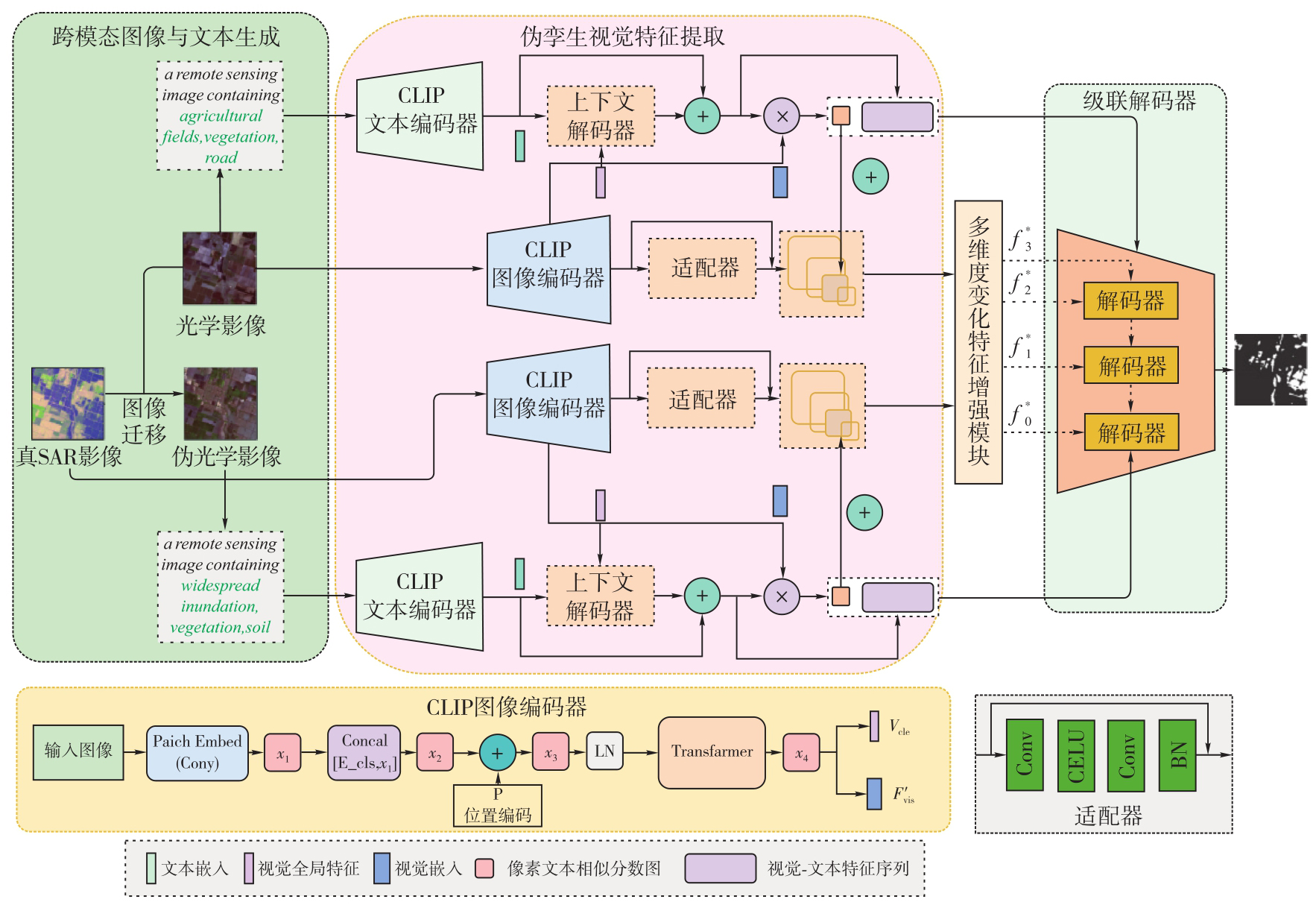

Fig. 3
Cross-modal image and text generation"
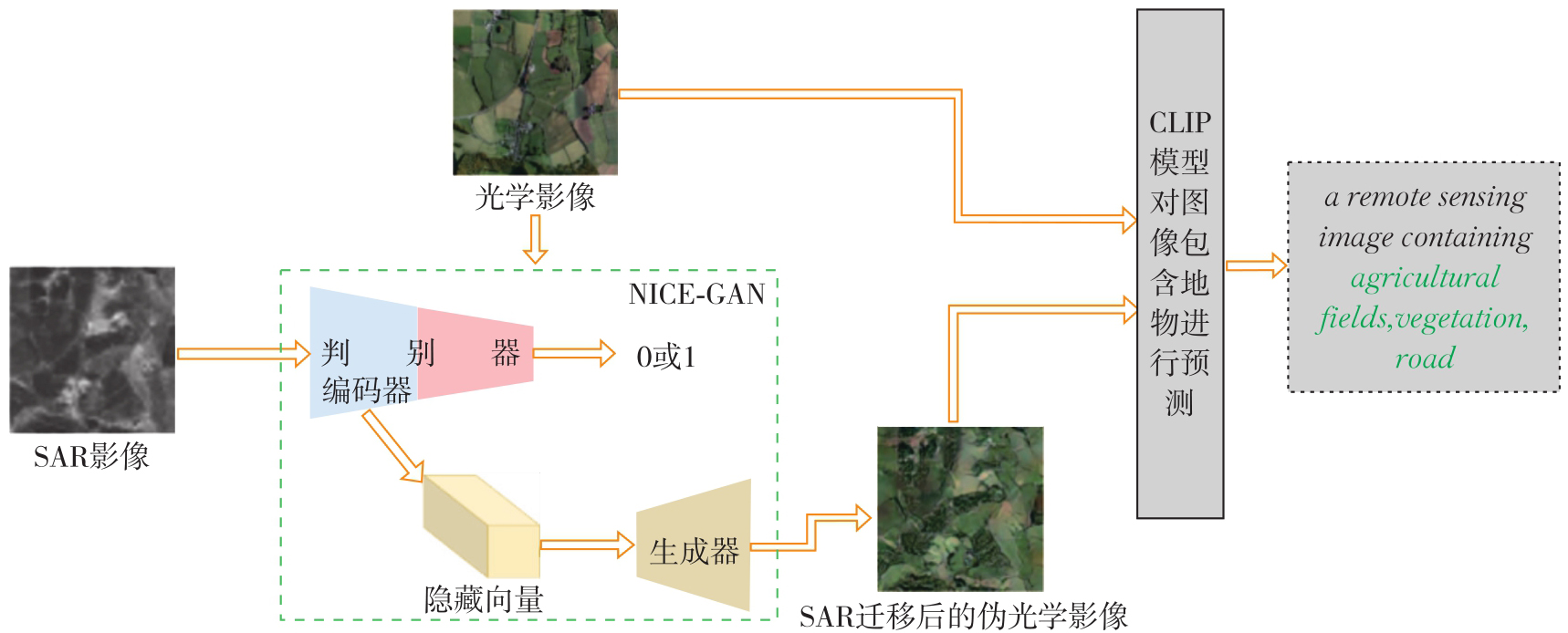
Fig. 4
Text-pixel association measurement module"
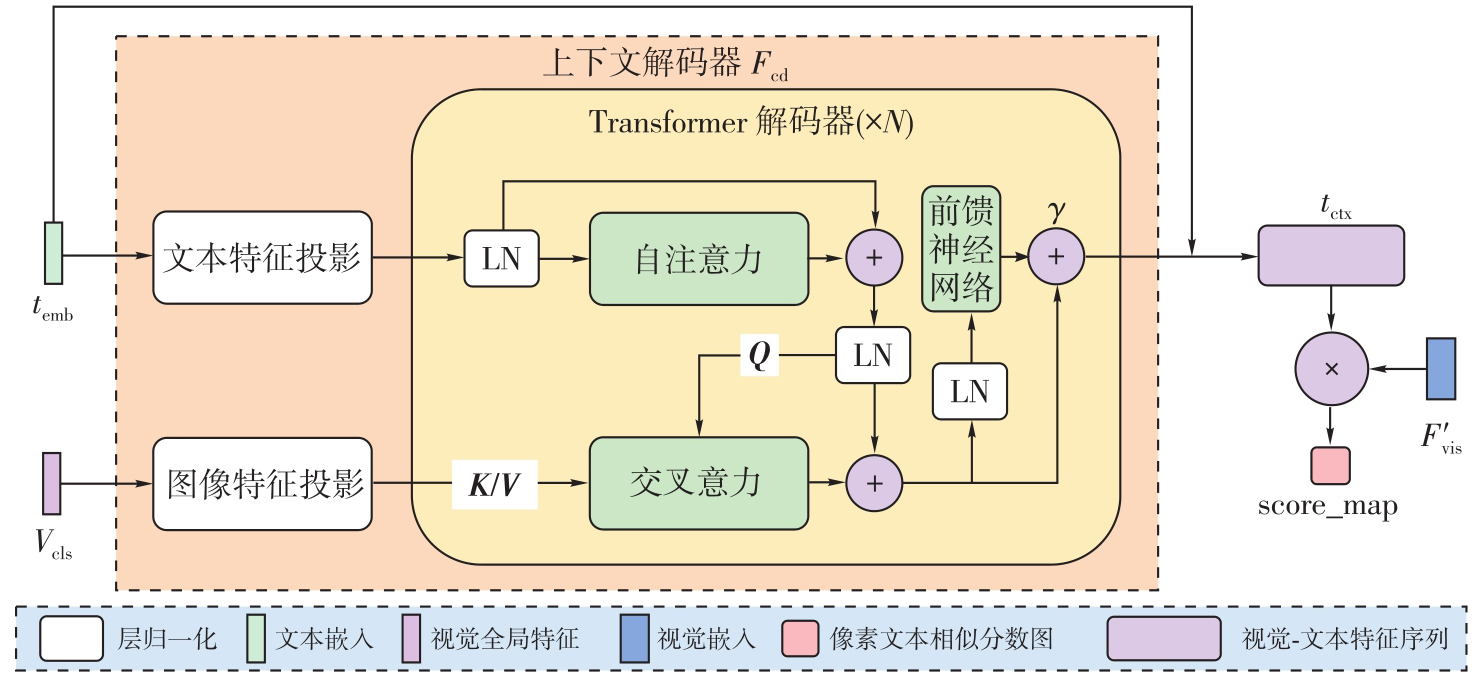
Fig. 5
Structure of MCFEM"

Fig. 6
Gloucester Ⅰ dataset"


Fig. 7
California dataset"

Tab. 2
Comparative quantitative results on the Gloucester Ⅰ"
| 类型 | 方法 | OA | Pr | Re | F1值 | IoU |
|---|---|---|---|---|---|---|
| 无监督 | INLPG | 88.84 | 42.90 | 40.81 | 41.83 | 26.44 |
| SCCN | 80.22 | 29.67 | 71.98 | 42.02 | 26.60 | |
| ACE-Net | 91.02 | 54.04 | 57.68 | 55.80 | 38.70 | |
| 风格迁移 | FC-EF | 97.18 | 90.90 | 79.93 | 85.06 | 74.00 |
| E-UNet | 97.17 | 85.22 | 86.20 | 85.71 | 74.99 | |
| DTCDN | 98.98 | 94.98 | 94.89 | 94.93 | 90.34 | |
| GLCD-DA | 99.20 | 95.24 | 96.65 | 95.94 | 92.20 | |
| VLM | ChangeCLIP | 98.65 | 95.75 | 90.30 | 92.94 | 86.82 |
| VLCD | 98.43 | 97.84 | 85.93 | 91.50 | 84.33 | |
| MCE-CLIP | 99.22 | 96.23 | 95.87 | 96.05 | 92.84 |
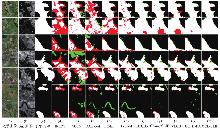
Fig. 8
Qualitative visualization results on the Gloucester Ⅰ"
Tab. 3
Comparative quantitative results on the California"
| 类型 | 方法 | OA | Pr | Re | F1值 | IoU |
|---|---|---|---|---|---|---|
| 无监督 | INLPG | 91.99 | 45.66 | 58.81 | 51.41 | 34.60 |
| SCCN | 88.02 | 39.15 | 89.85 | 54.54 | 37.49 | |
| ACE-Net | 92.26 | 47.31 | 65.36 | 54.89 | 37.82 | |
| 风格迁移 | FC-EF | 94.55 | 70.60 | 60.42 | 65.12 | 48.28 |
| E-UNet | 95.69 | 70.84 | 68.55 | 69.67 | 53.46 | |
| DTCDN | 95.19 | 64.15 | 75.09 | 69.19 | 52.90 | |
| GLCD-DA | 95.76 | 68.68 | 75.62 | 71.98 | 56.23 | |
| VLM | ChangeCLIP | 95.65 | 70.74 | 67.55 | 69.11 | 52.80 |
| VLCD | 95.86 | 76.06 | 62.08 | 68.36 | 51.93 | |
| MCE-CLIP | 96.02 | 72.56 | 71.97 | 72.27 | 56.58 |

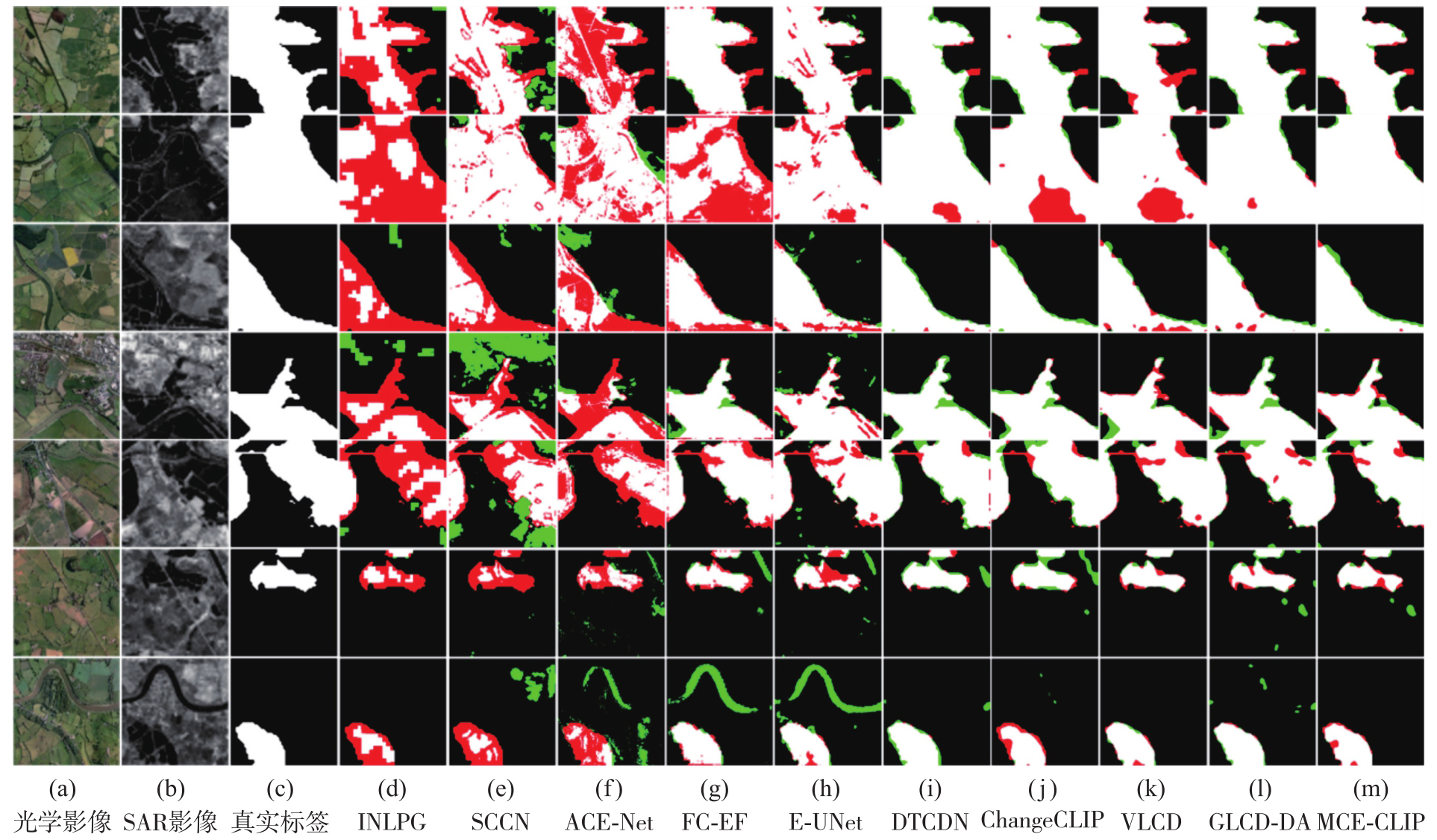
Fig. 9
Qualitative visualization results on the California"
Tab. 4
Significance analysis of multiple independent training"
| 数据集 | 指标 | GLCD-DA | MCE-CLIP | p值 | 显著性 |
|---|---|---|---|---|---|
| Gloucester Ⅰ | F1值 | 95.32±0.38 | 95.98±0.17 | p<0.01 | 显著 |
| IoU | 91.05±0.45 | 92.27±0.21 | p<0.01 | 显著 | |
| California | F1值 | 71.35±0.42 | 72.18±0.11 | p<0.01 | 显著 |
| IoU | 55.45±0.51 | 56.40±0.15 | p<0.01 | 显著 |
Tab. 5
MCE-CLIP ablation results of the core module on two datasets"
| 输入影像类型 | 核心模块 | Gloucester Ⅰ数据集 | California数据集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文本提示 | 模态适配器 | MCFEM | OA | Pr | Re | F1值 | IoU | OA | Pr | Re | F1值 | IoU | |
| 光学/SAR | × | × | × | 98.69 | 98.48 | 88.06 | 92.98 | 86.88 | 94.86 | 61.27 | 77.91 | 68.59 | 52.20 |
| 光学/SAR | √ | × | × | 98.89 | 98.00 | 90.57 | 94.14 | 88.93 | 94.81 | 60.62 | 79.86 | 68.92 | 52.58 |
| 光学/SAR | √ | √ | × | 98.92 | 97.11 | 91.76 | 94.36 | 89.32 | 95.90 | 76.77 | 61.73 | 68.44 | 52.02 |
| 光学/SAR | √ | × | √ | 99.14 | 96.45 | 94.75 | 95.59 | 91.56 | 95.88 | 75.35 | 63.57 | 68.96 | 52.63 |
| 光学/伪光学 | √ | √ | √ | 99.18 | 97.29 | 94.05 | 95.79 | 91.92 | 95.61 | 66.76 | 77.89 | 71.90 | 56.13 |
| 光学/SAR | √ | √ | √ | 99.22 | 96.23 | 95.87 | 96.05 | 92.84 | 96.02 | 72.56 | 71.97 | 72.27 | 56.58 |
Tab. 6
Sensitivity analysis of Top-K parameters on Gloucester Ⅰ dataset"
| K | OA | Pr | Re | F1值 | IoU |
|---|---|---|---|---|---|
| 3 | 98.86 | 96.46 | 91.83 | 94.09 | 88.83 |
| 5 | 99.19 | 97.59 | 94.05 | 95.79 | 91.92 |
| 7 | 99.22 | 96.23 | 95.87 | 96.05 | 92.84 |
| 9 | 99.21 | 97.21 | 94.64 | 95.91 | 92.13 |
| 11 | 99.16 | 96.28 | 95.13 | 95.7 | 91.76 |
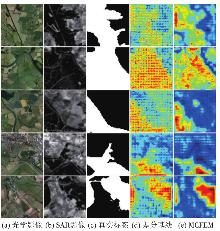
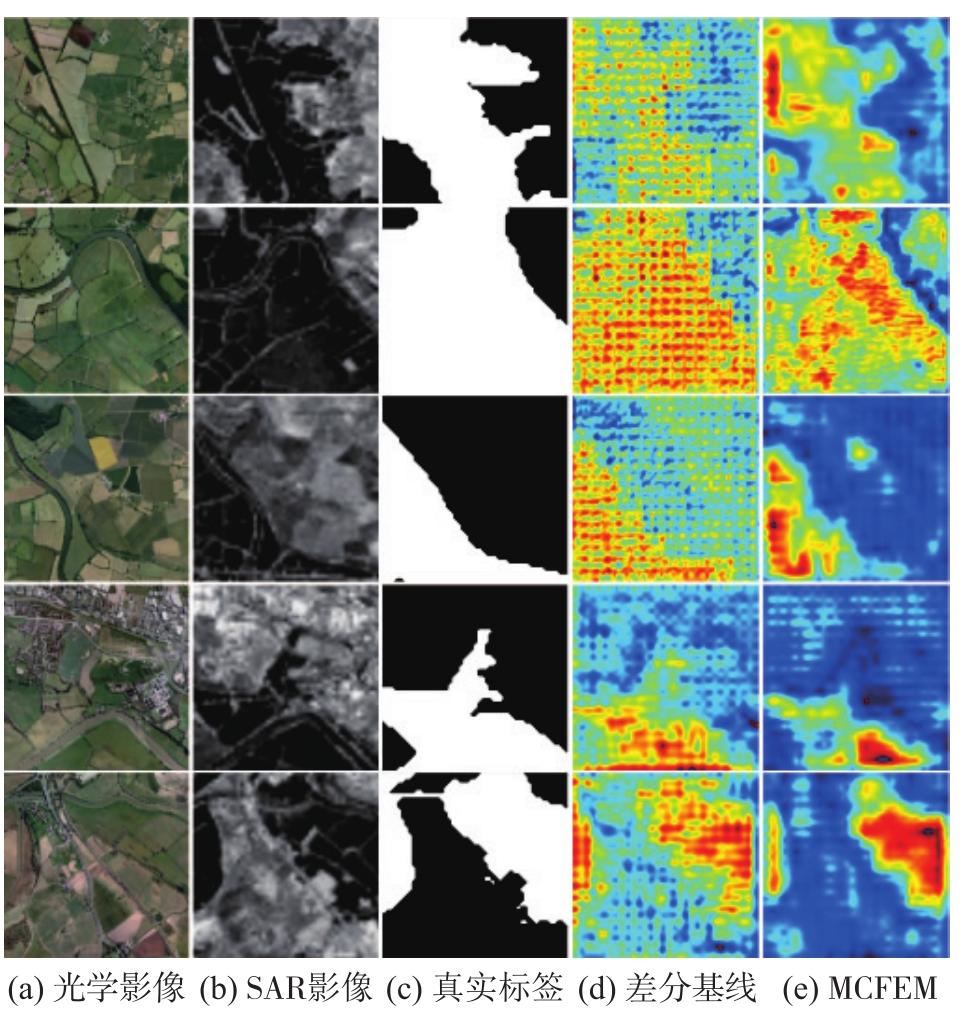
Fig. 10
Heatmap visualization results of MCFEM"
| [1] |
张继贤, 顾海燕, 倪欢, 等. 遥感智能变化检测的深度学习方法:演变与发展趋势[J]. 测绘学报, 2025, 54(8): 1347-1370. DOI: .
doi: 10.11947/j.AGCS.2025.20240417 |
|
ZHANG Jixian, GU Haiyan, NI Huan, et al. Deep learning methods for remote sensing intelligent change detection: evolution and development[J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1347-1370. DOI: .
doi: 10.11947/j.AGCS.2025.20240417 |
|
| [2] |
龚良雄, 李星华, 程远明, 等. 时空差异增强与自适应特征融合的轻量级遥感影像变化检测网络[J]. 测绘学报, 2025, 54(1): 136-153. DOI: .
doi: 10.11947/j.AGCS.2025.20240299 |
|
GONG Liangxiong, LI Xinghua, CHENG Yuanming, et al. A lightweight remote sensing images change detection network utilizing spatio-temporal difference enhancement and adaptive feature fusion[J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(1): 136-153. DOI: .
doi: 10.11947/j.AGCS.2025.20240299 |
|
| [3] | 李健慷, 张桂欣, 祝善友, 等. 融合多尺度特征Transformer的高分辨率遥感图像变化检测[J]. 遥感学报, 2025, 29(1): 266-278. |
| LI Jiankang, ZHANG Guixin, ZHU Shanyou, et al. Change detection for high-resolution remote sensing images with multi-scale feature transformer[J]. National Remote Sensing Bulletin, 2025, 29(1): 266-278. | |
| [4] | LIU W, JI X, LIU J, et al. A novel unsupervised change detection method with structure consistency and GFLICM based on UAV images[J]. Journal of Geodesy and Geoinformation Science, 2022, 5(1): 91-102. |
| [5] | 杨彬, 毛银, 陈晋, 等. 深度学习的遥感变化检测综述:文献计量与分析[J]. 遥感学报, 2023, 27(9): 1988-2005. |
| YANG Bin, MAO Yin, CHEN Jin, et al. Review of remote sensing change detection in deep learning: bibliometric and analysis[J]. National Remote Sensing Bulletin, 2023, 27(9): 1988-2005. | |
| [6] | 柳思聪, 都科丞, 郑永杰, 等. 人工智能时代的遥感变化检测技术:继承、发展与挑战[J]. 遥感学报, 2023, 27(9): 1975-1987. |
| LIU Sicong, DU Kecheng, ZHENG Yongjie, et al. Remote sensing change detection technology in the era of artificial intelligence: inheritance, development and challenges[J]. Journal of Remote Sensing, 2023, 27(9): 1975-1987. | |
| [7] | 成飞飞, 付志涛, 黄亮, 等. 深度学习在光学和SAR影像融合研究进展[J]. 遥感学报, 2022, 26(9): 1744-1756. |
| CHENG Feifei, FU Zhitao, HUANG Liang, et al. Review of deep learning in optical and SAR image fusion[J]. National Remote Sensing Bulletin, 2022, 26(9): 1744-1756. | |
| [8] | MA Zongfang, WANG Ruiqi, HAO Fan, et al. Heterogeneous image change detection based on dual image translation and dual contrastive learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4704714. |
| [9] | 汤玉奇, 林泽锋, 韩特, 等. 基于对称网络的光学和SAR影像变化检测[J]. 遥感学报, 2024, 28(6): 1560-1575. |
| TANG Yuqi, LIN Zefeng, HAN Te, et al. Optical and SAR image change detection based on a symmetric network[J]. National Remote Sensing Bulletin, 2024, 28(6): 1560-1575. | |
| [10] | LIU Jia, GONG Maoguo, QIN Kai, et al. A deep convolutional coupling network for change detection based on heterogeneous optical and radar images[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(3): 545-559. |
| [11] | LI Xinghua, DU Zhengshun, HUANG Yanyuan, et al. A deep translation (GAN) based change detection network for optical and SAR remote sensing images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 179: 14-34. |
| [12] | LI Jie, WU Meiru, LIN Liupeng, et al. GLCD-DA: change detection from optical and SAR imagery using a global-local network with diversified attention[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 226: 396-414. |
| [13] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]//Proceedings of 2021 International Conference on Machine Learning. San Diego: IEEE, 2021. |
| [14] | ELGENDY H, SHARSHAR A, ABOEITTA A, et al. GeoLLaVA: efficient fine-tuned vision-language models for temporal change detection in remote sensing[EB/OL]. [2025-10-12]. https://arxiv.org/abs/2410.19552. |
| [15] | DONG Sijun, WANG Libo, DU Bo, et al. ChangeCLIP: remote sensing change detection with multimodal vision-language representation learning[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2024, 208: 53-69. |
| [16] | QIU Junlong, LIU Wei, ZHANG Hui, et al. A novel change detection method based on visual language from high-resolution remote sensing images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 4554-4567. |
| [17] | CHEN Runfa, HUANG Wenbing, HUANG Binghui, et al. Reusing discriminators for encoding: towards unsupervised image-to-image translation[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 8165-8174. |
| [18] | PANG Yingxue, LIN Jianxin, QIN Tao, et al. Image-to-image translation: methods and applications[J]. IEEE Transactions on Multimedia, 2022, 24: 3859-3881. |
| [19] | ZAN Yujie, JI Shunping, CHAO Songtao, et al. Open-vocabulary generative vision-language models for creating a large-scale remote sensing change detection dataset[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 225: 275-290. |
| [20] | MIGNOTTE M. A fractal projection and Markovian segmentation-based approach for multimodal change detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(11): 8046-8058. |
| [21] | LUPPINO L T, BIANCHI F M, MOSER G, et al. Unsupervised image regression for heterogeneous change detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(12): 9960-9975. |
| [22] | SUN Yuli, LEI Lin, LI Xiao, et al. Structure consistency-based graph for unsupervised change detection with homogeneous and heterogeneous remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4700221. |
| [23] | LUPPINO L T, KAMPFFMEYER M, BIANCHI F M, et al. Deep image translation with an affinity-based change prior for unsupervised multimodal change detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4700422. |
| [24] | CAYE DAUDT R, LE SAUX B, BOULCH A. Fully convolutional Siamese networks for change detection[C]//Proceedings of the 25th IEEE International Conference on Image Processing. Athens: IEEE, 2018: 4063-4067. |
| [25] | LÜ Zhiyong, HUANG Haitao, SUN Weiwei, et al. Novel enhanced UNet for change detection using multi-modal remote sensing image[J]. IEEE Geoscience and Remote Sensing Letters, 2023, 20: 2505405. |
| [1] | Hongmei WANG, Lihua WANG, Benhua TAN, Xiaoyi JIANG, Lili SONG, Weiwei SUN. SAR high-precision inversion of sea surface current over offshore China [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(4): 588-603. |
| [2] | Lanxin WU, Jiangtao PENG, Weiwei SUN, Bing YANG. An Euler embedding and complementary feature modeling framework for hyperspectral change detection in coastal wetlands [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(4): 618-631. |
| [3] | Jingxuan LIU, Xuexi LIU, Kefei ZHANG, Chao YANG, Suqin WU, Shouqing ZHU, Fudong GUO. A prediction method for LOD based on combined LSTM and WLS [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(3): 477-489. |
| [4] | Zhong LU, Jinqi ZHAO, Yufen NIU, Liquan CHEN, Qianyou FAN, Jinzhao SI, Zixuan WANG, Yuan GAO, Shuai WANG, Feifei QU, Hongtao SHI, Shiyong YAN, Yun SHI, Zheng ZHAO. The NISAR mission: innovations in earth observation and applications in surface deformation monitoring [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(2): 261-274. |
| [5] | Daifeng PENG, Xuelian LIU, Mengfei LU, Haiyan GUAN. Heterogeneous remote sensing image flood change detection based on multi-scale cross-modal feature fusion [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(2): 328-343. |
| [6] | Haopeng HU, Hangbin WU, Shihao ZHAN, Zaihao WEN, Chun LIU. Road pole-like object change detection supported by visual point cloud quality optimization [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(2): 344-358. |
| [7] | Bin HAN, Xin HUANG, Fengyi LI, Xiaozhen LU. Water body segmentation network for SAR images combining dual-encoder and adaptive feature fuse [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(1): 101-113. |
| [8] | Jixian ZHANG, Haiyan GU, Huan NI, Haitao LI, Yi YANG, Shaopeng DING, Songman SUI. Deep learning methods for remote sensing intelligent change detection: evolution and development [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(8): 1347-1370. |
| [9] | Peng LI, Jianbo BAI, Zhenhong LI, Houjie WANG. Wide area coastal subsidence monitoring and driver analysis with multi tracks of TS-InSAR—a case study of Shandong province [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(7): 1178-1191. |
| [10] | Kefu WU, Haiqiang FU, Jianjun ZHU, Qijin HAN, Aichun WANG, Mingxia ZHANG, Zhiwei LI. LT-1 InSAR block adjustment considering the impact of penetration depth in forest areas [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(6): 1009-1020. |
| [11] | Chao WANG, Tianyu CHEN, Tong ZHANG, Tanvir AHMED, Liqiang JI, Tao XIE, Jiajun YANG, Shuai WANG. Multi-sensor optical remote sensing images change detection based on global differential enhancement module and balance penalty loss [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 873-887. |
| [12] | Qingli LUO, Xueyan LI, Guoman HUANG, Honghui CHEN, Minglong XUE, Jian LI. AOSN: alpha optimal structure network for height estimation from a single SAR image in mountain areas [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 888-898. |
| [13] | Guangao XING, Guanming LU, Bin HAN. MAFUNet: water body segmentation algorithm for SAR images combining attention mechanisms and active contour loss [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(5): 924-936. |
| [14] | Zhaofeng DU, Guopeng LI, Zhanke LIU, Xiaming SHANG, Shengjun KANG, Xiaoqiang WANG. Comprehensive analysis of multiple monitoring methods in main subsidence areas [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(3): 481-492. |
| [15] | Ziqing WEI. Talk about X-ray pulsar navigation [J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(2): 207-212. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||