


测绘学报 ›› 2025, Vol. 54 ›› Issue (1): 90-103.doi: 10.11947/j.AGCS.2025.20230302
张正华( ), 陈国良()
), 陈国良()
收稿日期:2023-07-21
修回日期:2024-12-05
出版日期:2025-02-17
发布日期:2025-02-17
通讯作者:
陈国良
E-mail:zh_zhang@cumt.edu.cn;chgl_cumt@163.com
作者简介:张正华(1993—),男,博士,博士后,主要研究方向为激光雷达定位与导航。 E-mail:zh_zhang@cumt.edu.cn
基金资助:
Zhenghua ZHANG(), Guoliang CHEN()
Received:2023-07-21
Revised:2024-12-05
Online:2025-02-17
Published:2025-02-17
Contact:
Guoliang CHEN
E-mail:zh_zhang@cumt.edu.cn;chgl_cumt@163.com
About author:ZHANG Zhenghua (1993—), male, PhD, postdoctor, majors in LiDAR-based localization and navigation. E-mail: zh_zhang@cumt.edu.cn
Supported by:摘要:
激光雷达位置识别技术是自动驾驶、机器人导航等领域实现全局定位的关键技术,现有方法注重提升模型特征表达能力,但忽视保持位置识别过程对点云旋转的不变性,且存在参数量大、依赖复杂预处理流程等问题。对此,本文提出一种名为RIP-Net的超轻量级位置识别深度学习网络。首先,快速获取场景局部区域点簇并构建底层旋转不变特征;然后,使用残差结构与注意力机制,融合多尺度信息实现局部区域的增强感知;最后,利用广义平均池化函数聚合场景全局特征,并基于特征距离实现位置识别与定位。在4个大规模场景点云数据集上的试验结果表明:RIP-Net不仅可实现对点云旋转的不变性,各项精度指标均优于现有方法,且模型参数量仅为30万,相比现有方法显著降低;此外,RIP-Net可无须数据预处理,直接使用原始点云实现精准位置识别定位,具备良好的实用性。
中图分类号:
张正华, 陈国良. 一种轻量且旋转不变的激光雷达位置识别网络[J]. 测绘学报, 2025, 54(1): 90-103.
Zhenghua ZHANG, Guoliang CHEN. A lightweight rotation-invariant network for LiDAR-based place recognition[J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(1): 90-103.
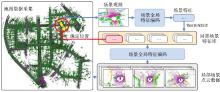
图1
激光雷达位置识别流程"
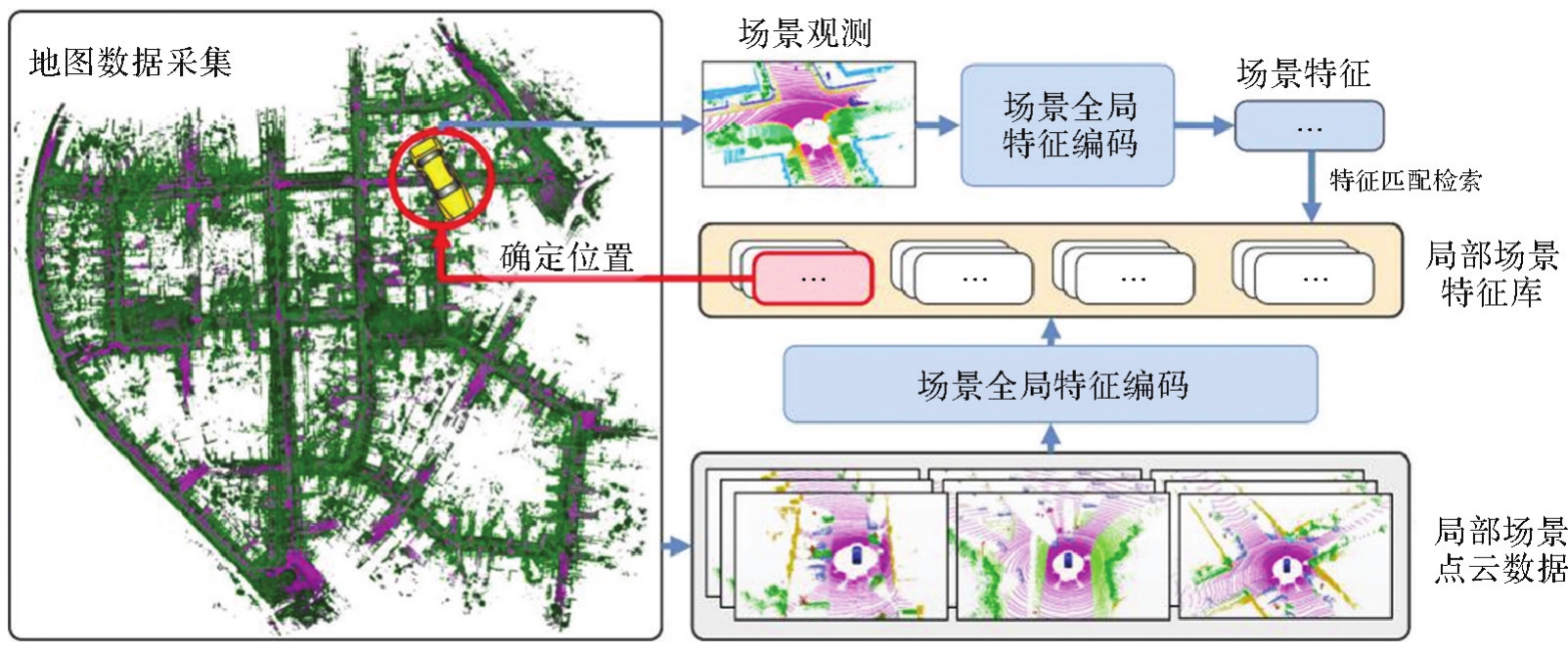
图2
查询场景与先验地图场景姿态变化"
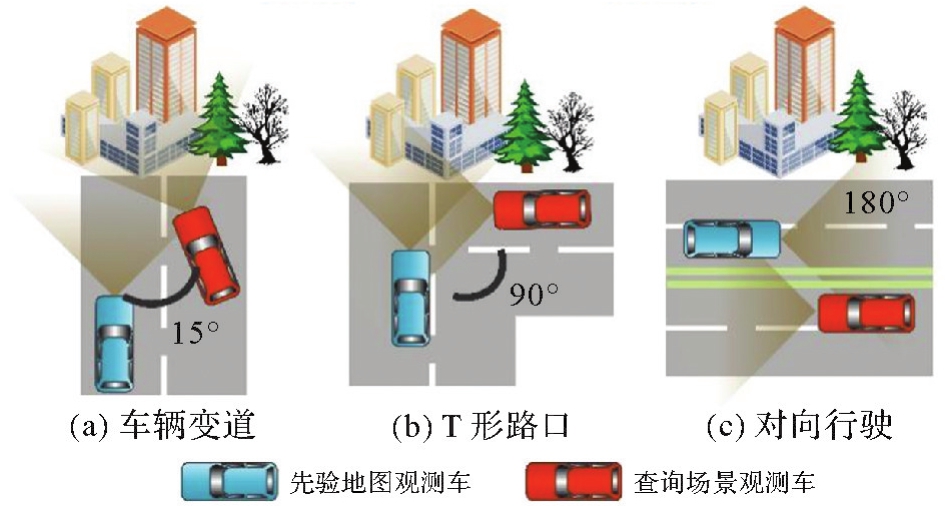
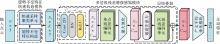
图3
RIP-Net网络架构"

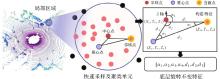
图4
局部区域旋转不变特征构造过程"
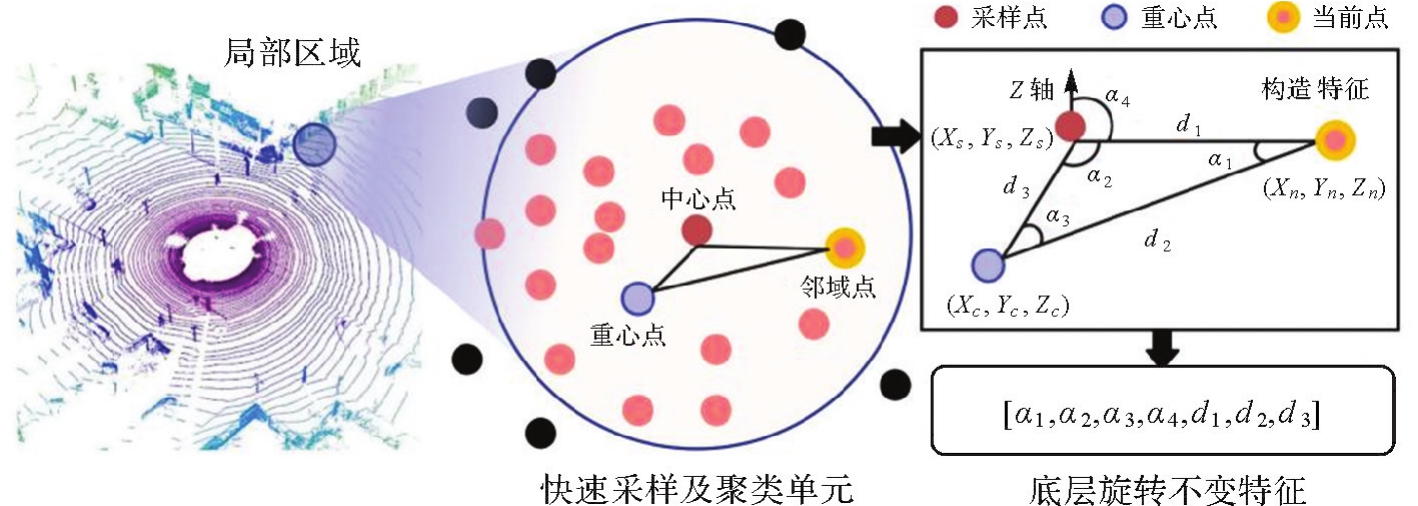
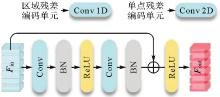
图5
残差编码结构"
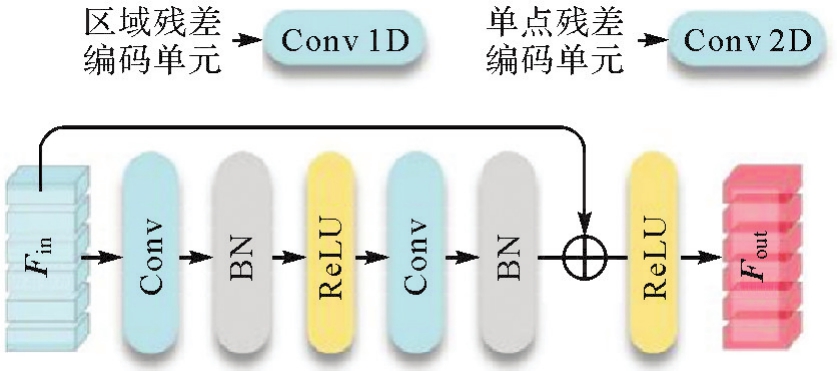

图6
RIP-Net模型部署细节"

表1
试验使用的数据集及相关信息"
| 数据集名称 | 构建时间 | 构建机构 | 场景特征 | 训练集场景数 | 测试集场景数 |
|---|---|---|---|---|---|
| Oxford RobotCar | 2017 | 牛津大学 | 牛津市中心区域场景 | 23 177 | 3030 |
| NUS Inhouse | 2018 | 新加坡国立大学 | 大学校园、居民区与商业区场景 | 0 | 10 813 |
| Mul Ran | 2020 | 韩国科学技术院 | 韩国大田会议中心、科学院及河堤场景 | 26 799 | 43 749 |
| KITTI odometry | 2013 | 德国卡尔斯鲁厄理工学院 | 城市、乡村与公路等场景 | 0 | 18 266 |
表2
Oxford数据集试验结果"
| 方法 | 参数量 | 运算时间/ms | 准确率/(%) | 最近邻召回率/(%) | 前1%召回率/(%) | F1值 |
|---|---|---|---|---|---|---|
| PointNetVLAD | 19.78×106 | 15 | 11.96 | 15.01 | 31.31 | 0.20 |
| PCAN | 20.42×106 | 55 | 12.82 | 14.81 | 32.81 | 0.21 |
| EPC-Net | 4.70×106 | 26 | 59.97 | 59.78 | 80.93 | 0.74 |
| MinkLoc3D | 1.06×106 | 12 | 85.62 | 74.26 | 90.14 | 0.91 |
| MinkLoc++ | 1.06×106 | 12 | 73.70 | 80.79 | 92.75 | 0.84 |
| PPT-Net | 13.39×106 | 22 | 61.03 | 61.55 | 82.82 | 0.75 |
| SVT-Net | 0.94×106 | 11 | 77.23 | 72.21 | 89.41 | 0.86 |
| LWR-Net | 0.44×106 | 10 | 41.39 | 40.93 | 62.80 | 0.57 |
| SOE-Net | 19.40×106 | 22 | 86.56 | 86.72 | 95.60 | 0.92 |
| RPR-Net | 1.10×106 | 238 | — | 81.00 | 92.20 | — |
| VNI-Net | 2.20×106 | 574 | — | 85.50 | 94.40 | — |
| RIP-Net | 0.30×106 | 9 | 87.50 | 87.57 | 95.83 | 0.93 |
表3
Inhouse数据集不同场景下模型泛化性能试验结果"
| 方法 | 大学校园场景 | 居民区场景 | 商业区场景 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 最近邻召回率/(%) | 前1%召回率/(%) | F1值 | 最近邻召回率/(%) | 前1%召回率/(%) | F1值 | 最近邻召回率/(%) | 前1%召回率/(%) | F1值 | |
| PointNetVLAD | 18.16 | 33.76 | 0.20 | 15.17 | 28.42 | 0.20 | 17.39 | 26.12 | 0.27 |
| PCAN | 10.56 | 25.00 | 0.18 | 11.95 | 23.31 | 0.17 | 12.99 | 19.42 | 0.22 |
| EPC-Net | 60.10 | 80.56 | 0.75 | 51.89 | 70.77 | 0.68 | 57.48 | 69.44 | 0.73 |
| MinkLoc3D | 57.17 | 68.27 | 0.81 | 44.88 | 60.54 | 0.77 | 46.13 | 63.79 | 0.82 |
| MinkLoc++ | 65.91 | 81.83 | 0.74 | 65.73 | 75.94 | 0.63 | 57.11 | 76.20 | 0.63 |
| PPT-Net | 42.53 | 69.08 | 0.65 | 54.83 | 68.14 | 0.60 | 40.59 | 61.56 | 0.73 |
| SVT-Net | 53.47 | 69.00 | 0.79 | 52.28 | 68.34 | 0.76 | 67.44 | 78.76 | 0.81 |
| LWR-Net | 41.80 | 64.42 | 0.60 | 41.66 | 62.96 | 0.58 | 56.22 | 68.76 | 0.73 |
| SOE-Net | 77.32 | 90.71 | 0.87 | 76.08 | 89.78 | 0.86 | 76.35 | 81.32 | 0.89 |
| VNI-Net | 85.30 | 95.00 | — | 83.30 | 91.50 | — | 81.40 | 86.80 | — |
| RPR-Net | 83.20 | 94.50 | — | 83.30 | 91.30 | — | 80.40 | 86.40 | — |
| RIP-Net | 85.35 | 95.31 | 0.91 | 83.49 | 92.10 | 0.89 | 77.96 | 84.52 | 0.87 |

图7
点云旋转角变化对现有方法位置识别精度影响"


图8
不同点云噪声及稀疏性下RIP-Net及SOE-Net位置识别精度变化"

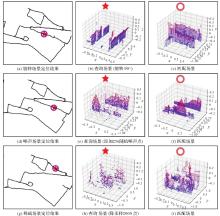
图9
点云旋转、噪声及稀疏性影响下RIP-Net模型场景匹配及定位结果展示"

表4
MulRan数据集下不同场景试验结果"
| 方法 | 韩国大田会议中心场景 | 河堤场景 | 韩国科学技术院场景 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 准确率/(%) | 召回率/(%) | F1值 | 准确率/(%) | 召回率/(%) | F1值 | 准确率/(%) | 召回率/(%) | F1值 | |
| MinkLoc3D | 10.37 | 35.81 | 0.17 | 8.95 | 31.72 | 0.14 | 9.12 | 21.56 | 0.14 |
| MinkLoc++ | 12.54 | 33.24 | 0.19 | 9.86 | 31.43 | 0.15 | 10.55 | 38.21 | 0.17 |
| SVT-Net | 11.21 | 40.79 | 0.18 | 8.37 | 34.62 | 0.13 | 12.45 | 39.18 | 0.19 |
| RIP-Net | 92.17 | 99.31 | 0.96 | 88.37 | 99.19 | 0.94 | 90.66 | 98.79 | 0.95 |
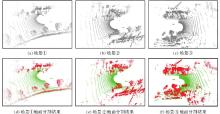
图10
布料滤波算法地面点分割效果"

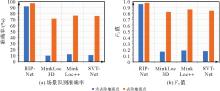
图11
去除及未去除地面点时位置识别准确率及F1值变化"


图12
不同点云旋转、噪声及密度变化下RIP-Net在MulRan数据集位置识别精度变化"
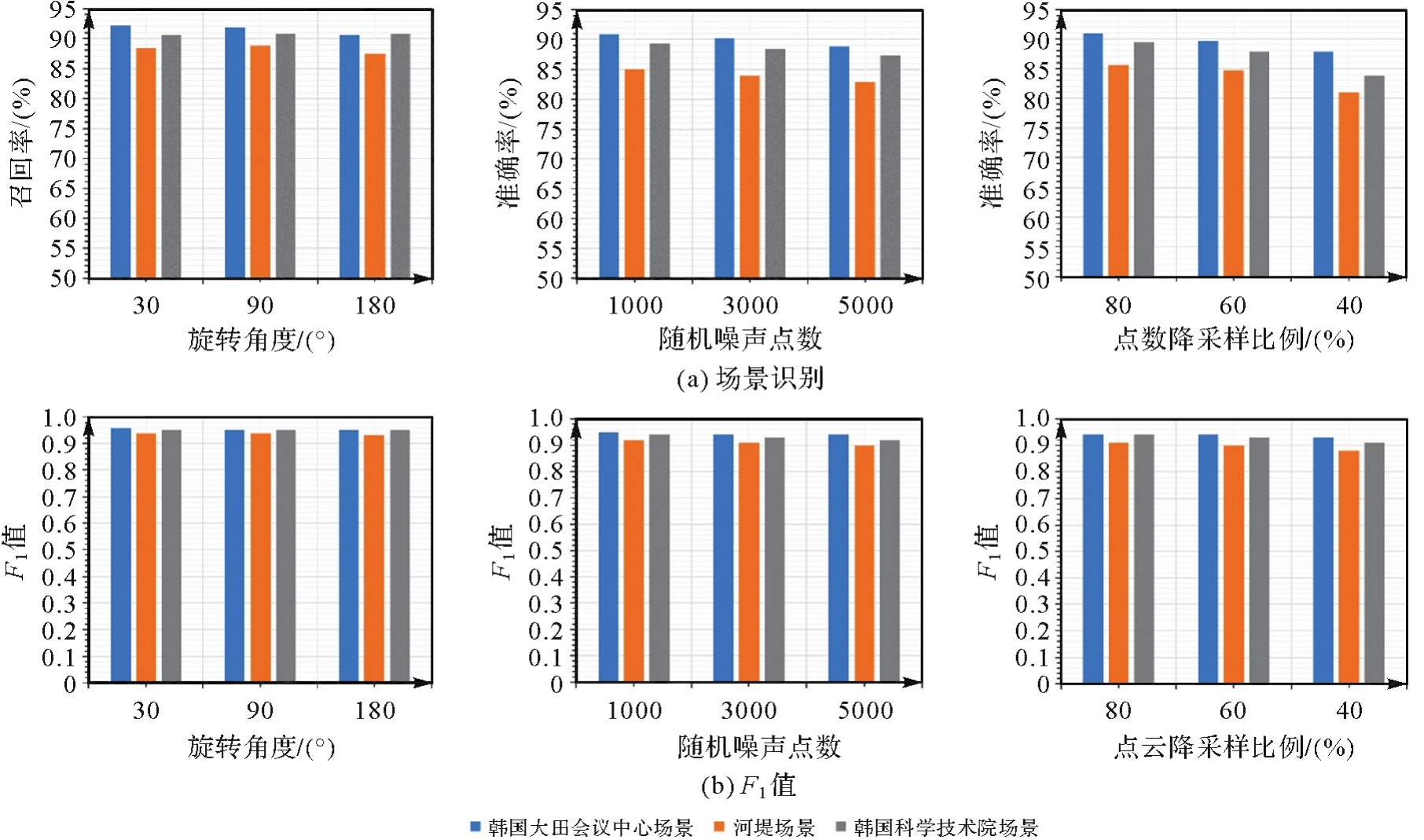
表5
KITTI odometry数据集下不同序列场景泛化性能试验结果"
| 场景序列 | 准确率/(%) | 召回率/(%) | F1值 |
|---|---|---|---|
| 00 | 66.02 | 98.50 | 0.79 |
| 02 | 66.13 | 98.48 | 0.79 |
| 05 | 62.54 | 98.17 | 0.77 |
| 06 | 69.83 | 99.63 | 0.82 |
| 07 | 72.49 | 99.77 | 0.84 |
| 07 | 72.49 | 99.77 | 0.84 |
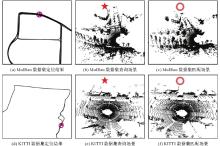
图13
原始点云场景下RIP-Net场景检索及定位结果展示"
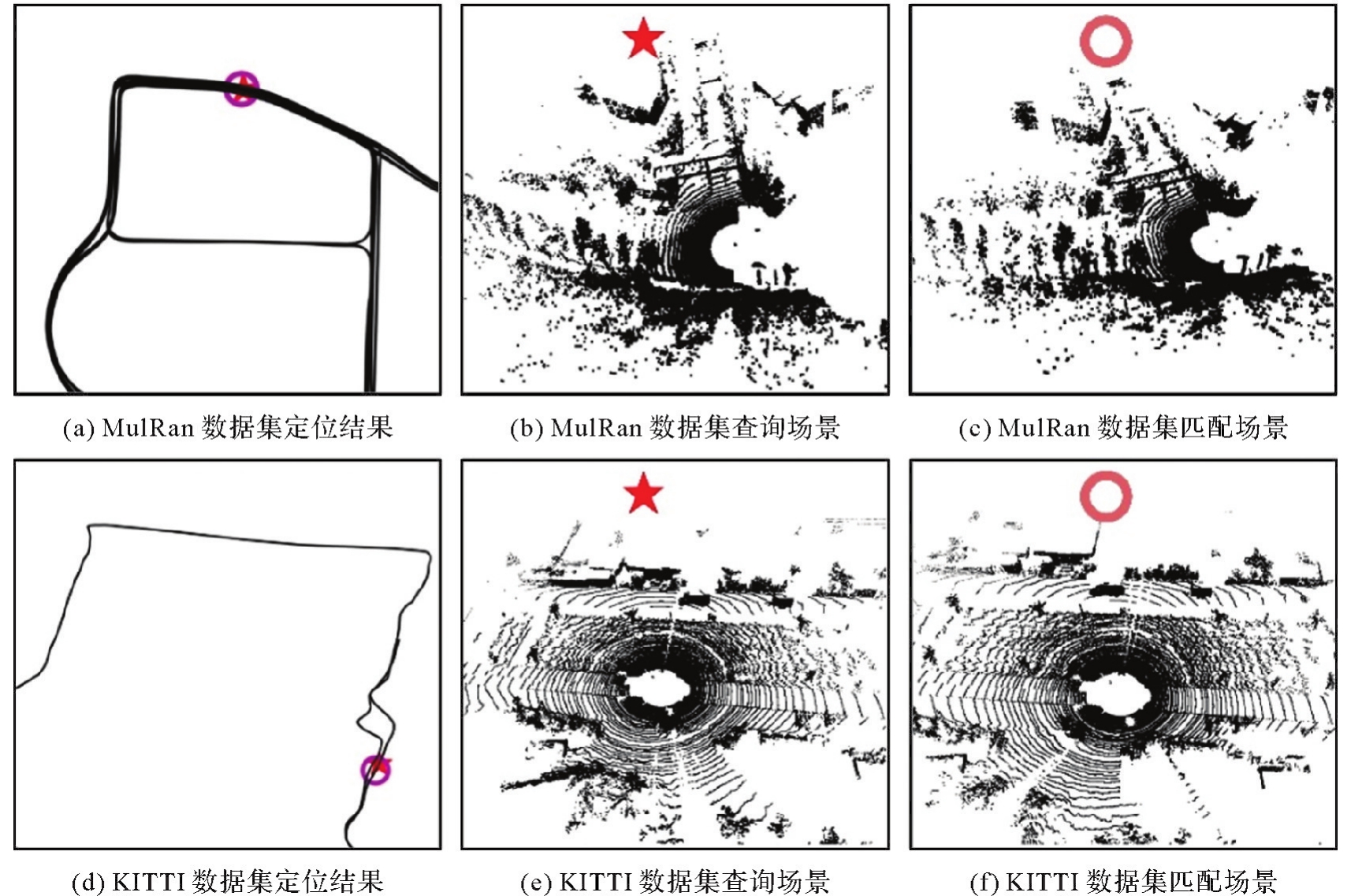
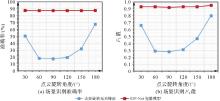
图14
使用坐标信息代替旋转不变特征对模型位置识别精度影响"
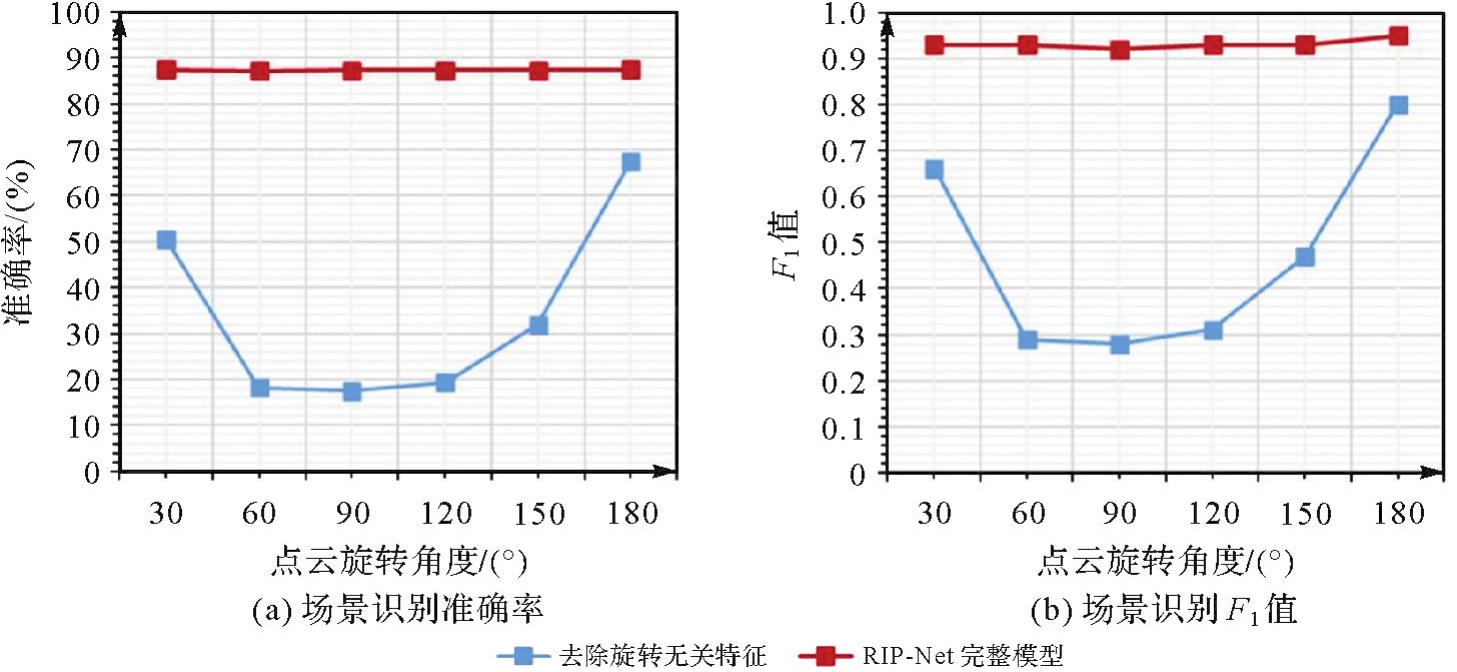

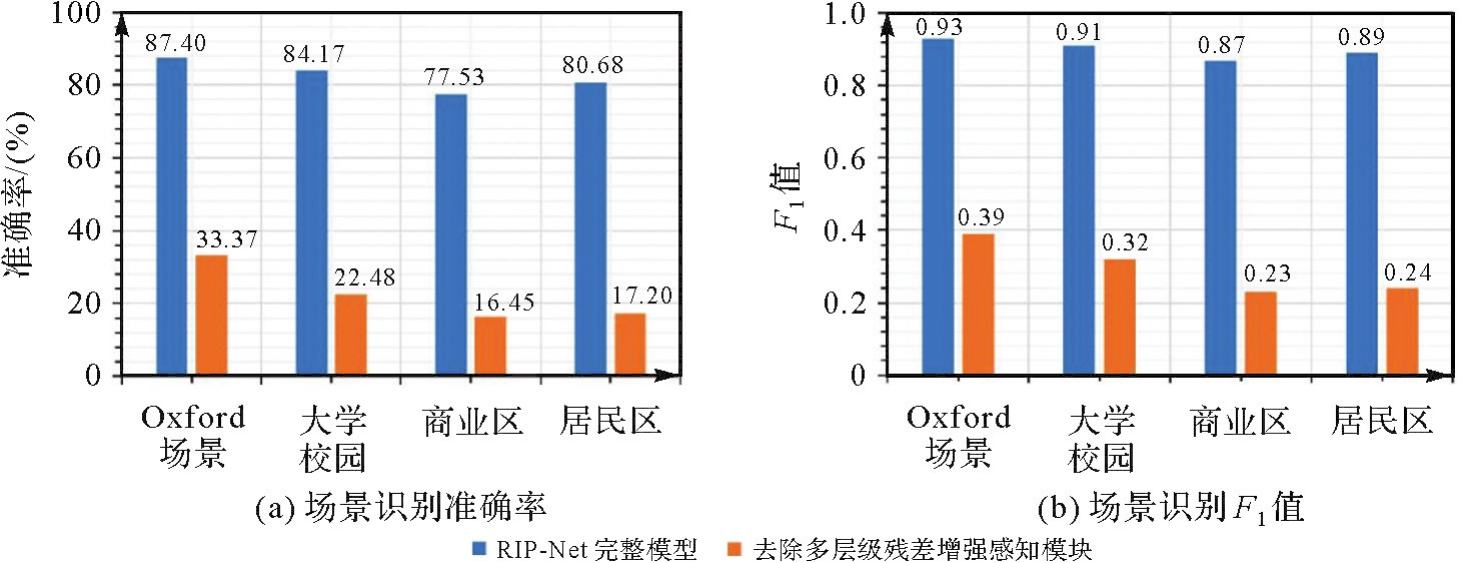
图15
去除多层级残差增强感知模块对模型位置识别精度影响"
| [1] | 戴德云. 基于多元信息融合的场景多层级识别方法研究[D]. 合肥: 中国科学技术大学, 2022. |
| DAI Deyun. Research on multi-level scene recognition method based on multi-information fusion[D]. Hefei: University of Science and Technology of China, 2022. | |
| [2] |
杨元喜. 弹性PNT基本框架[J]. 测绘学报, 2018, 47(7): 893-898. DOI:.
doi: 10.11947/J.AGCS.2018.20180149 |
|
YANG Yuanxi. Resilient PNT concept frame[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(7): 893-898. DOI:.
doi: 10.11947/j.AGCS.2018.20180149 |
|
| [3] |
张星, 林静, 李清泉, 等. 结合感知哈希与空间约束的室内连续视觉定位方法[J]. 测绘学报, 2021, 50(12): 1639-1649.DOI:.
doi: 10.11947/J.AGCS.2021.20200286 |
|
ZHANG Xing, LIN Jing, LI Qingquan, et al. Indoor continuous visual positioning method combining perceptual hashing and spatial constraints[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(12): 1639-1649.DOI:.
doi: 10.11947/J.AGCS.2021.20200286 |
|
| [4] | 张恒才, 蔚保国, 秘金钟, 等. 综合PNT场景增强系统研究进展及发展趋势[J]. 武汉大学学报(信息科学版), 2023, 48(4): 491-505. |
| ZHANG Hengcai, YU Baoguo, BEI Jinzhong, et al. A survey of scene-based augmentation systems for conprehensive PNT[J]. Geomatics and Information Science of Wuhan University, 2023, 48(4): 491-505. | |
| [5] | 张正华. 基于深度学习的激光雷达点云实时配准与场景识别算法研究[D]. 徐州: 中国矿业大学, 2022. |
| ZHANG Zhenghua. Study on deep-learning-based real-time registration and place recognition algorithm for LiDAR point cloud[D]. Xuzhou: China University of Mining and Technology, 2022. | |
| [6] | WOHLKINGER W, VINCZE M. Ensemble of shape functions for 3D object classification[C]//Proceedings of 2011 IEEE International Conference on Robotics and Biomimetics. Karon Beach: IEEE, 2011. |
| [7] | HE Li, WANG Xiaolong, ZHANG Hong. M2DP: a novel 3D point cloud descriptor and its application in loop closure detection[C]//Proceedings of 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems. Daejeon: IEEE, 2016: 231-237. |
| [8] | KIM G, KIM A. Scan context: egocentric spatial descriptor for place recognition within 3D point cloud map[C]//Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid: IEEE, 2018: 4802-4809. |
| [9] |
杨必胜, 董震. 点云智能研究进展与趋势[J]. 测绘学报, 2019, 48(12): 1575-1585.DOI:.
doi: 10.11947/j.AGCS.2019.20190465 |
|
YANG Bisheng, DONG Zhen. Progress and perspective of point cloud intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(12): 1575-1585.DOI:.
doi: 10.11947/j.AGCS.2019.20190465 |
|
| [10] | UY M A, LEE G H. PointNetVLAD: deep point cloud based retrieval for large-scale place recognition[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018. |
| [11] | CHARLES R Q, HAO Su, MO Kaichun, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017. |
| [12] | ARANDJELOVIC R, GRONAT P, TORII A, et al. NetVLAD: CNN architecture for weakly supervised place recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016. |
| [13] | ZHANG Wenxiao, XIAO Chunxia. PCAN: 3D attention map learning using contextual information for point cloud based retrieval[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019. |
| [14] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. [2023-12-10]. https://doi.org/10.48550/arXiv.1706.03762. |
| [15] | LIU Zhe, ZHOU Shunbo, SUO Chuanzhe, et al. LPD-net: 3D point cloud learning for large-scale place recognition and environment analysis[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019. |
| [16] | HUI L, CHENG M, XIE J, et al. Efficient 3D point cloud feature learning for large-scale place recognition[J]. IEEE Transactions on Image Processing, 2022, 31: 1258-1270. |
| [17] | KOMOROWSKI J. MinkLoc3D: point cloud based large-scale place recognition[C]//Proceedings of 2021 IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2021. |
| [18] | RADENOVIC F, TOLIAS G, CHUM O. Fine-tuning CNN image retrieval with no human annotation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(7): 1655-1668. |
| [19] | XU Tianxing, GUO Yuanchen, LI Zhiqiang, et al. TransLoc3D: point cloud based large-scale place recognition using adaptive receptive fields[J]. Communications in Information and Systems, 2023, 23(1): 57-83. |
| [20] | FAN Z, SONG Z, LIU H, et al. SVT-Net: super light-weight sparse voxel transformer for large scale place recognition[J]. AAAI Conference on Artificial Intelligence. 2022, 36(1), 551-560. |
| [21] | TIAN Gengxuan, ZHAO Junqiao, CAI Yingfeng, et al. VNI-Net: vector neurons-based rotation-invariant descriptor for LiDAR place recognition[EB/OL]. [2023-10-15]. https://arxiv.org/abs/2308.12870v1. |
| [22] | FAN Zhaoxin, SONG Zhenbo, LIU Hongyan, et al. SVT-net: super light-weight sparse voxel transformer for large scale place recognition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(1): 551-560. |
| [23] | XIA Yan, XU Yusheng, LI Shuang, et al. SOE-net: a self-attention and orientation encoding network for point cloud based place recognition[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021. |
| [24] | MADDERN W, PASCOE G, LINEGAR C, et al. 1 year, 1000 km: the Oxford RobotCar dataset[J]. The International Journal of Robotics Research, 2017, 36(1): 3-15. |
| [25] | KIM G, PARK Y S, CHO Y, et al. MulRan: multimodal range dataset for urban place recognition[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation. Paris: IEEE, 2020. |
| [26] | LAZANYI K. Are we ready for self-driving cars-a case of principal-agent theory[C]//Proceedings of 2018 IEEE International Symposium on Applied Computational Intelligence and Informatics. Timisoara: IEEE, 2018. |
| [27] | HUI Le, YANG Hang, CHENG Mingmei, et al. Pyramid point cloud transformer for large-scale place recognition[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021. |
| [28] | ZHANG Z, CHEN G, SHU M, et al. LWR-Net: robust and lightweight place recognition network for noisy and low-density point clouds[J]. Sensors (Basel, Switzerland), 2023, 23(21): 8664. |
| [29] | KOMOROWSKI J, WYSOCZANSKA M, TRZCINSKI T. MinkLoc++: LiDAR and monocular image fusion for place recognition[C]//Proceedings of 2021 International Joint Conference on Neural Networks. Shenzhen: IEEE, 2021. |
| [30] | ZHANG W, QI J, WAN P, et al. An easy-to-use airborne LiDAR data filtering method based on cloth simulation[J]. Remote Sensing. 2016, 8(6), 501. |
| [1] | 王家耀, 陈琳, 程士源, 王利军, 熊思奇. 人工智能赋能地图科学数智化[J]. 测绘学报, 2026, 55(3): 381-389. |
| [2] | 禄小敏, 张志义, 闫浩文, 何毅, 苏小宁. 融合深度图信息最大化和多层感知机的建筑物群组模式识别方法[J]. 测绘学报, 2026, 55(3): 425-438. |
| [3] | 季顺平, 刘瑾, 高建, 龚健雅. 多视影像深度学习密集匹配三维重建智能框架[J]. 测绘学报, 2025, 54(9): 1633-1646. |
| [4] | 张继贤, 顾海燕, 倪欢, 李海涛, 杨懿, 丁少鹏, 隋淞蔓. 遥感智能变化检测的深度学习方法:演变与发展趋势[J]. 测绘学报, 2025, 54(8): 1347-1370. |
| [5] | 方帅, 刘加恩, 张晶. 自适应参考特征引入与多尺度特征聚合的时空融合算法[J]. 测绘学报, 2025, 54(8): 1476-1488. |
| [6] | 孟妮娜, 李凤梅, 周校东. 数据与认知双驱动的建筑物群制图综合结果与尺度一致性识别[J]. 测绘学报, 2025, 54(7): 1318-1331. |
| [7] | 王亚青, 王中辉. 异构图卷积网络支持下的河系自动选取方法[J]. 测绘学报, 2025, 54(7): 1332-1345. |
| [8] | 安晓亚, 郭伟茹, 张鹏鑫, 李欣欣, 石磊. 顾及几何位置和移动特征相似性的船舶轨迹聚类方法[J]. 测绘学报, 2025, 54(6): 1107-1121. |
| [9] | 王超, 陈天宇, 张同, AhmedTanvir, 纪立强, 谢涛, 杨佳俊, 王帅. 基于全局差分增强模块和平衡惩罚损失的多源光学遥感影像变化检测[J]. 测绘学报, 2025, 54(5): 873-887. |
| [10] | 罗卿莉, 李雪岩, 黄国满, 陈红辉, 薛铭龙, 李健. AOSN:α-最优网络模型的山区单通道SAR高程重建方法[J]. 测绘学报, 2025, 54(5): 888-898. |
| [11] | 涂伟, 池向沅, 赵天鸿, 杨剑, 朱世平, 陈德莉. 城市排水管网流量预测多视图时空图神经网络模型[J]. 测绘学报, 2025, 54(2): 334-344. |
| [12] | 张志力, 姜慧伟, 胡翔云. 面向极简交互的遥感地物精确批量提取框架[J]. 测绘学报, 2025, 54(10): 1863-1876. |
| [13] | 石岩, 王达, 邓敏, 杨学习. 时空异常探测:从数据驱动到知识驱动的内涵转变与实现路径[J]. 测绘学报, 2024, 53(8): 1493-1504. |
| [14] | 鄢薪, 慎利, 潘俊杰, 戴延帅, 王继成, 郑晓莉, 李志林. 多尺度特征融合与空间优化的弱监督高分遥感建筑变化检测[J]. 测绘学报, 2024, 53(8): 1586-1597. |
| [15] | 布金伟, 余科根, 汪秋兰, 李玲惠, 刘馨雨, 左小清, 常军. 融合星载GNSS-R数据和多变量参数全球海洋有效波高深度学习反演法[J]. 测绘学报, 2024, 53(7): 1321-1335. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||