

Acta Geodaetica et Cartographica Sinica ›› 2025, Vol. 54 ›› Issue (7): 1280-1293.doi: 10.11947/j.AGCS.2025.20230481
• Photogrammetry and Remote Sensing • Previous Articles Next Articles
Jie WAN1( ), Zhong XIE2,3(), Yongyang XU2, Liufeng TAO2,3
), Zhong XIE2,3(), Yongyang XU2, Liufeng TAO2,3
Received:2023-10-17
Revised:2025-04-17
Online:2025-08-18
Published:2025-08-18
Contact:
Zhong XIE
E-mail:wanjie@cug.edu.cn;xiezhong@cug.edu.cn
About author:WAN Jie (1993—), male, PhD candidate, majors in intelligent analysis and processing of 3D point clouds. E-mail: wanjie@cug.edu.cn
Supported by:CLC Number:
Jie WAN, Zhong XIE, Yongyang XU, Liufeng TAO. A U-shaped graph convolution network method for semantic segmentation of vehicle LiDAR point clouds towards urban road scenes[J]. Acta Geodaetica et Cartographica Sinica, 2025, 54(7): 1280-1293.

Fig. 1
The overall workflow of the proposed method"


Fig. 2
Grid sampling of scene point cloud"


Fig. 3
U-GCN network architecture"

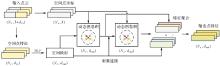
Fig. 4
Local feature aggregation module"


Fig. 5
Dynamic graph convolution operator"


Fig. 6
Multi-scale feature extraction based on U-shaped architecture"

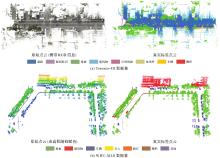
Fig. 7
Samples of test datasets"
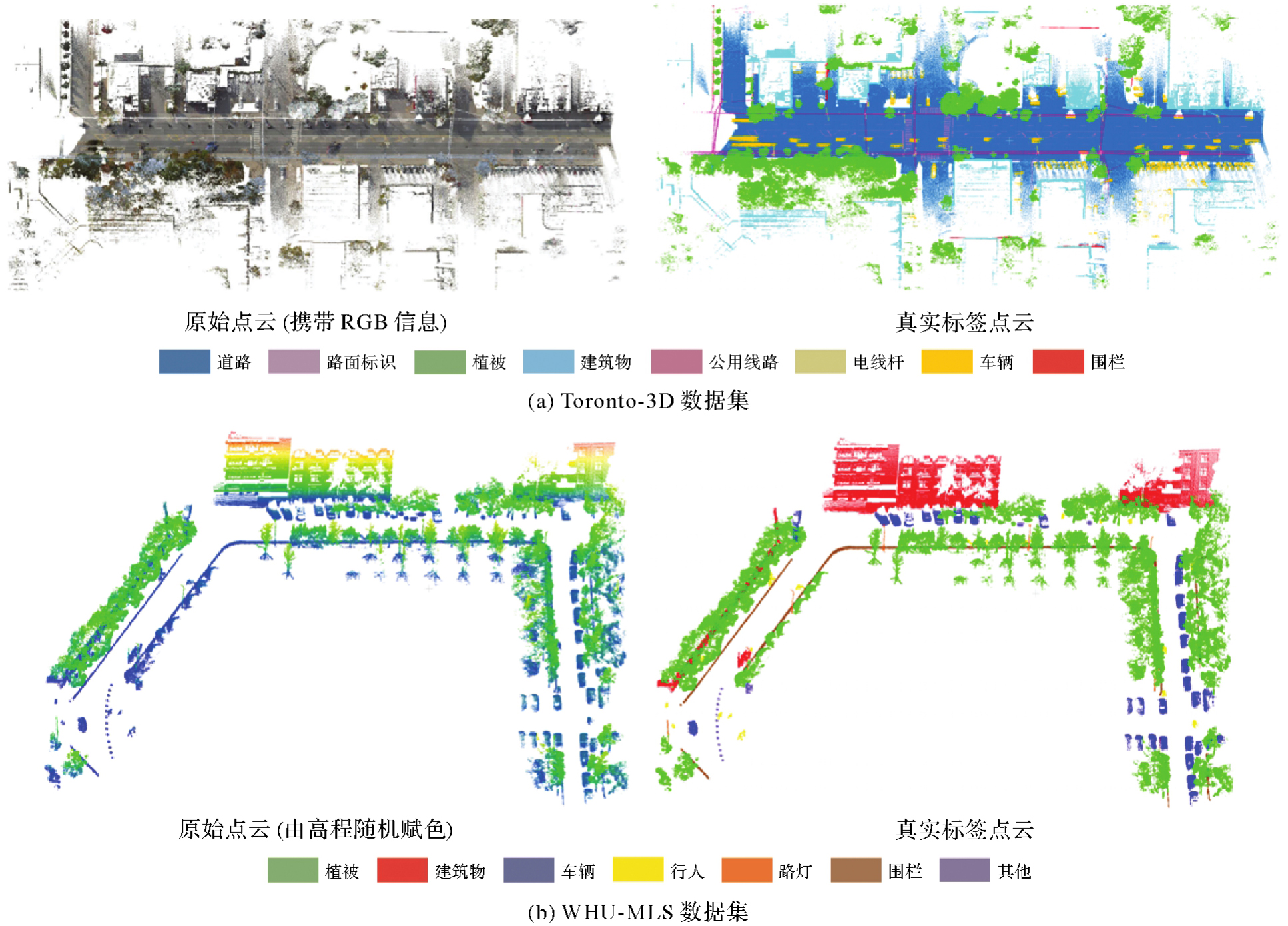

Fig. 8
Comparison of different network visualization results in the whole test scene of the Toronto-3D dataset"


Fig. 9
Comparison of different network visualization results in local areas of the test scene of the Toronto-3D dataset"

Tab. 1
Comparison of quantitative results on the Toronto-3D dataset"
| 方法 | OA | mAcc | mIoU | 单个类别IoU | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 道路 | 路面标识 | 植被 | 建筑物 | 公用线路 | 电线杆 | 汽车 | 围栏 | ||||
| PointNet++(MSG) | 93.3 | 74.3 | 61.6 | 93.5 | 37.3 | 89.6 | 82.4 | 45.1 | 61.1 | 73.1 | 10.3 |
| DGCNN | 95.3 | 78.2 | 69.3 | 95.2 | 33.5 | 95.2 | 91.8 | 78.9 | 72.0 | 72.0 | 16.5 |
| RandLA-Net | 95.4 | 76.3 | 71.4 | 94.8 | 0.0 | 95.3 | 92.6 | 86.4 | 71.4 | 90.7 | 40.3 |
| BAF-LAC | 95.4 | — | 70.2 | 94.8 | 0.0 | 95.8 | 92.3 | 80.2 | 73.8 | 90.5 | 33.8 |
| NeiEA-Net | 95.3 | — | 68.5 | 94.7 | 0.0 | 95.2 | 89.1 | 79.6 | 76.5 | 93.3 | 19.6 |
| 本文方法 | 96.4 | 82.9 | 79.0 | 95.6 | 33.8 | 97.2 | 93.0 | 86.7 | 81.0 | 93.4 | 51.5 |
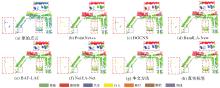
Fig. 10
Comparison of different network visualization results on the WHU-MLS dataset"

Tab. 2
Comparison of quantitative results on the WHU-MLS dataset"
| 方法 | OA | mAcc | mIoU | 单个类别IoU | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 植被 | 建筑物 | 车辆 | 行人 | 路灯 | 围栏 | 其他 | ||||
| PointNet++(MSG) | 85.9 | 57.9 | 44.7 | 80.8 | 73.6 | 82.2 | 30.4 | 0.0 | 45.5 | 0.0 |
| DGCNN | 80.6 | 62.5 | 39.9 | 85.8 | 67.8 | 68.5 | 31.0 | 0.1 | 18.8 | 0.0 |
| RandLA-Net | 83.7 | 57.9 | 51.7 | 71.0 | 68.8 | 90.1 | 7.4 | 50.8 | 74.0 | 0.0 |
| BAF-LAC | 90.7 | — | 56.5 | 85.3 | 88.7 | 69.9 | 15.6 | 47.0 | 67.0 | 0.2 |
| NeiEA-Net | 88.8 | — | 54.8 | 80.3 | 85.1 | 88.7 | 22.4 | 36.7 | 70.5 | 0.0 |
| 本文方法 | 91.3 | 67.8 | 61.2 | 84.4 | 85.0 | 88.4 | 56.4 | 37.9 | 76.3 | 0.0 |
Tab. 3
Impact of different network modules and structural designs for semantic segmentation"
| 消融网络 | 动态图卷积算子 | 局部特征聚合模块 | 跳跃连接 | 深度监督损失 | mIoU/(%) |
|---|---|---|---|---|---|
| A1 | 36.9 | ||||
| A2 | √ | 48.7 | |||
| A3 | √ | √ | 52.4 | ||
| A4 | √ | √ | √ | 58.0 | |
| A5 | √ | √ | √ | √ | 61.2 |

Fig. 11
Comparison of different ablated network feature visualization results"


Fig. 12
The quantitative comparison of different K values in the dynamic graph convolution operator"

Tab. 4
Complexity and performance analysis of the U-GCN network model"
| 方法 | FLOPs/GB | 参数/MB | 推理时间/s | mIoU/(%) |
|---|---|---|---|---|
| PointNet++(MSG) | 8 678.88 | 1.16 | 296.8 | 61.6 |
| DGCNN | 666.7 | 1.84 | 288.5 | 69.3 |
| RandLA-Net | 26.4 | 4.99 | 216.8 | 71.4 |
| BAF-LAC | 66.2 | 11.64 | 366.9 | 70.2 |
| NeiEA-Net | 34.0 | 4.87 | 247.7 | 68.5 |
| 本文方法 | 47.6 | 6.83 | 273.1 | 79.0 |
| [1] |
刘华. 车载激光点云地物提取与分类研究[J]. 测绘学报, 2020, 49(11): 1506. DOI: .
doi: 10.11947/j.AGCS.2020.20190434 |
|
LIU Hua. Object points extraction and classification of mobile LiDAR point clouds[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(11): 1506. DOI: .
doi: 10.11947/j.AGCS.2020.20190434 |
|
| [2] |
杨必胜, 韩旭, 董震. 适用于城市场景大规模点云语义标识的深度学习网络[J]. 测绘学报, 2021, 50(8): 1059-1067. DOI: .
doi: 10.11947/j.AGCS.2021.20210093 |
|
YANG Bisheng, HAN Xu, DONG Zhen. A deep learning network for semantic labeling of large-scale urban point clouds[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(8): 1059-1067. DOI: .
doi: 10.11947/j.AGCS.2021.20210093 |
|
| [3] |
杨必胜, 董震. 点云智能研究进展与趋势[J]. 测绘学报, 2019, 48(12): 1575-1585. DOI: .
doi: 10.11947/j.AGCS.2019.20190465 |
|
YANG Bisheng, DONG Zhen. Progress and perspective of point cloud intelligence[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(12): 1575-1585. DOI: .
doi: 10.11947/j.AGCS.2019.20190465 |
|
| [4] | YANG Bisheng, DONG Zhen, LIU Yuan, et al. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 126: 180-194. |
| [5] | WEINMANN M, SCHMIDT A, MALLET C, et al. Contextual classification of point cloud data by exploiting individual 3D neigbourhoods[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2015, 2(3): 271-278. |
| [6] |
胡鑫, 王心宇, 钟燕飞. 基于自适应上下文聚合网络的双高遥感影像分类[J]. 测绘学报, 2023, 52(7): 1175-1186. DOI: .
doi: 10.11947/j.AGCS.2023.20220237 |
|
HU Xin, WANG Xinyu, ZHONG Yanfei. Adaptive context aggregation network for H2 remote sensing imagery classification[J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(7): 1175-1186. DOI: .
doi: 10.11947/J.AGCS.2023.20220237 |
|
| [7] | SHEN Yanyun, LIU Di, ZHANG Feizhao, et al. Fast and accurate multi-class geospatial object detection with large-size remote sensing imagery using CNN and truncated NMS[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 191: 235-249. |
| [8] | WAN Jie, XIE Zhong, XU Yongyang, et al. DA-RoadNet: a dual-attention network for road extraction from high resolution satellite imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 6302-6315. |
| [9] | JARITZ M, GU Jiayuan, SU Hao. Multi-view PointNet for 3D scene understanding[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshop. Seoul: IEEE, 2019: 3995-4003. |
| [10] | WANG Yanjun, LI Shaochun, WANG Mengjie, et al. A simple deep learning network for classification of 3D mobile LiDAR point clouds[J]. Journal of Geodesy and Geoinformation Science, 2021, 4(3): 49-59. |
| [11] | ROBERT D, VALLET B, LANDRIEU L. Learning multi-view aggregation in the wild for large-scale 3D semantic segmentation[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 5565-5574. |
| [12] | MENG H Y, GAO Lin, LAI Yukun, et al. VV-Net: voxel VAE net with group convolutions for point cloud segmentation[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 8499-8507. |
| [13] | POUX F, BILLEN R. Voxel-based 3D point cloud semantic segmentation: unsupervised geometric and relationship featuring vs deep learning methods[J]. ISPRS International Journal of Geo-Information, 2019, 8(5): 213. |
| [14] | LI Huchen, GUAN Haiyan, MA Lingfei, et al. MVPNet: a multi-scale voxel-point adaptive fusion network for point cloud semantic segmentation in urban scenes[J]. International Journal of Applied Earth Observation and Geoinformation, 2023, 122: 103391. |
| [15] | CHARLES R Q, SU H, KAICHUN M, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 77-85. |
| [16] | HAN Xu, DONG Zhen, YANG Bisheng. A point-based deep learning network for semantic segmentation of MLS point clouds[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 175: 199-214. |
| [17] |
蒋腾平, 王永君, 张林淇, 等. 融合CNN和MRF的激光点云层次化语义分割方法[J]. 测绘学报, 2021, 50(2): 215-225. DOI: .
doi: 10.11947/j.AGCS.2021.20200095 |
|
JIANG Tengping, WANG Yongjun, ZHANG Linqi, et al. A LiDAR point cloud hierarchical semantic segmentation method combining CNN and MRF[J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(2): 215-225. DOI: .
doi: 10.11947/j.AGCS.2021.20200095 |
|
| [18] | WANG Yue, SUN Yongbin, LIU Ziwei, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 1-12. |
| [19] | JIANG Tengping, SUN Jian, LIU Shan, et al. Hierarchical semantic segmentation of urban scene point clouds via group proposal and graph attention network[J]. International Journal of Applied Earth Observation and Geoinformation, 2021, 105: 102626. |
| [20] | WAN Jie, XU Yongyang, QIU Qinjun, et al. A geometry-aware attention network for semantic segmentation of MLS point clouds[J]. International Journal of Geographical Information Science, 2023, 37(1): 138-161. |
| [21] | LIU Yongcheng, FAN Bin, XIANG Shiming, et al. Relation-shape convolutional neural network for point cloud analysis[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 8887-8896. |
| [22] | XU Mutian, DING Runyu, ZHAO Hengshuang, et al. PAConv: position adaptive convolution with dynamic kernel assembling on point clouds[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 3172-3181. |
| [23] | WU Wenxuan, LI Fuxin, SHAN Qi. PointConvFormer: revenge of the point-based convolution[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 21802-21813. |
| [24] | QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]//Proceeding of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5105-5114. |
| [25] | LI Yangyan, BU Rui, SUN Mingchao, et al. PointCNN: convolution x-transformed points[C]//Proceedings of the 32nd Conference on Neural Information Processing Systems. NowYork: Curran Associates, 2018: 820-830. |
| [26] | ZHAO Hengshuang, JIANG Li, FU C W, et al. PointWeb: enhancing local neighborhood features for point cloud processing[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5560-5568. |
| [27] | HU Qingyong, YANG Bo, XIE Linhai, et al. RandLA-Net: efficient semantic segmentation of large-scale point clouds[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11105-11114. |
| [28] | LI Yong, LI Xu, ZHANG Zhenxin, et al. DenseKPNET: dense kernel point convolutional neural networks for point cloud semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-13. |
| [29] | NIE Dong, LAN Rui, WANG Ling, et al. Pyramid architecture for multi-scale processing in point cloud segmentation[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17263-17273. |
| [30] | HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2261-2269. |
| [31] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30: 5998-6008. |
| [32] | LEE C Y, XIE S, GALLAGHER P, et al. Deeply-supervised nets[EB/OL]. [2023-02-04]. https://arxiv.org/abs/1409.5185. |
| [33] | TAN Weikai, QIN Nannan, MA Lingfei, et al. Toronto-3D: a large-scale mobile LiDAR dataset for semantic segmentation of urban roadways[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 797-806. |
| [34] | WANG Lei, HUANG Yuchun, SHAN Jie, et al. MSNet: multi-scale convolutional network for point cloud classification[J]. Remote Sensing, 2018, 10(4): 612. |
| [35] | SHUAI Hui, XU Xiang, LIU Qingshan. Backward attentive fusing network with local aggregation classifier for 3D point cloud semantic segmentation[J]. IEEE Transactions on Image Processing, 2021, 30: 4973-4984. |
| [36] | XU Yongyang, TANG Wei, ZENG Ziyin, et al. NeiEA-NET: semantic segmentation of large-scale point cloud scene via neighbor enhancement and aggregation[J]. International Journal of Applied Earth Observation and Geoinformation, 2023, 119: 103285. |
| [1] | Zejiao WANG, Longgang XIANG, Meng WANG, Xingjuan WANG, Qing LIU. Hierarchical feature and diversified attention fusion network for collaborative extraction of road surface and centerline [J]. Acta Geodaetica et Cartographica Sinica, 2026, 55(3): 548-563. |
| [2] | Bo HU, Hanxin CHEN, Song REN, Yinghao QU, Qingyi LIU, Xinyue TU, Datao WANG. A post-processing algorithm for automatic recognition of tunnel crack diseases based on segmentation masks [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(9): 1715-1724. |
| [3] | Tao XU, Yuanwei YANG, Xianjun GAO, Zhiwei WANG, Yue PAN, Shaohua LI, Lei XU, Yanjun WANG, Bo LIU, Jing YU, Fengmin WU, Haoyu SUN. Integrated graph convolution and multi-scale features for the overhead catenary system point cloud semantic segmentation [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(8): 1624-1633. |
| [4] | LIN Yunhao, WANG Yanjun, LI Shaochun, CAI Hengfan. A coupled DeepLab and Transformer approach for fine classification of crop cultivation types in remote sensing [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(2): 353-366. |
| [5] | Genyun SUN, Chao SUN, Aizhu ZHANG. Road extraction networks fusing multiscale and edge features [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(12): 2233-2243. |
| [6] | Yinsheng ZHANG, Ge CHEN, Xiuxian DUAN, Junyi TONG, Mengjiao SHAN, Huilin SHAN. Landslide image segmentation model based on multi-layer feature information fusion [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(11): 2201-2212. |
| [7] | Jiaxing LIU, Yuchun HUANG, Wenxuan SHI, Xi YE, He YANG. Road markings extraction considering topological structure [J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(11): 2213-2227. |
| [8] | HU Gongming, YANG Chuncheng, XU Li, SHANG Haibin, WANG Zefan, QIN Zhilong. Improved U-Net remote sensing image semantic segmentation method [J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(6): 980-989. |
| [9] | LIU Shuai, LI Xiaoying, YU Meng, XING Guanglong. Dual decoupling semantic segmentation model for high-resolution remote sensing images [J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(4): 638-647. |
| [10] | SHEN Ziyang, NI Huan, GUAN Haiyan. Unsupervised domain adaptation alignment method for cross-domain semantic segmentation of remote sensing images [J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(12): 2115-2126. |
| [11] | ZHANG Rongting, ZHANG Guangyun, YIN Jihao. Semantic segmentation method of 3D scenes using dynamic graph CNN for complex city [J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(10): 1703-1713. |
| [12] | LI Jiatian, YANG Ruchun, YAO Yanji, HE Rixing, A Xiaohui, LÜ Shaoyun. Semantic segmentation of aerial image based on semi-supervised network with multi-scale shared coding [J]. Acta Geodaetica et Cartographica Sinica, 2022, 51(11): 2355-2364. |
| [13] | JIANG Tengping, WANG Yongjun, ZHANG Linqi, LIANG Chong, SUN Jian. A LiDAR point cloud hierarchical semantic segmentation method combining CNN and MRF [J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(2): 215-225. |
| [14] | SHAO Xiaohang, WU Hangbin, LIU Chun, CHEN Chen, CAI Tianchi, CHENG Fanjin. Visual odometry optimizing bounded with semantic elements association in dynamic scenes [J]. Acta Geodaetica et Cartographica Sinica, 2021, 50(11): 1478-1486. |
| [15] | LI Daoji, GUO Haitao, LU Jun, ZHAO Chuan, LIN Yuzhun, YU Donghang. A remote sensing image classification procedure based on multilevel attention fusion U-Net [J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(8): 1051-1064. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||